1.本发明涉及审计技术领域,具体为一种基于模型的新词发现方法。
背景技术:
2.近年来,随着大数据、人工智能、云计算、物联网和移动应用等信息技术不断应用与发展,逐渐改变着人们的生活和工作,给审计监督带了机遇和挑战,内部审计工作正面临着审计信息化的深刻变革。
3.在审计信息化过程中,需要对领域词进行抽取,如基于规则的抽取方法是根据词语的自身组成结构和外部上下文联系等建立相应的规则,并利用模式匹配来抽取领域词汇,这种抽取方式大多都是通过人工制定规则,很难用计算机自动发现规则,特别是如今网络流行语千奇百怪更难发现其规则性,所以十分困难,又如基于统计的属于抽取方法主要依赖于词频度、似然比、假设检验和互信息等,此种方法对单独的领域词汇和低频领域词汇的识别效果并不是很理想,因此亟需一种高质量的基于模型的新词发现方法。
技术实现要素:
4.本发明提供的发明目的在于提供一种基于模型的新词发现方法,实现审计领域词的持续发现、能够在很大程度上减轻纯人工从文档内提取审计领域专业词汇的工作量。提高审计专业词库构建效率的效果。
5.为了实现上述效果,本发明提供如下技术方案:一种基于模型的新词发现方法,包括以下步骤:
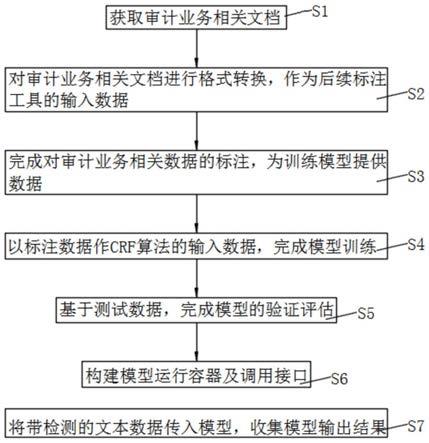
6.s1、获取审计业务相关文档。
7.s2、对审计业务相关文档进行格式转换,将转换后的审计业务相关文档数据作为后续标注工具的输入数据。
8.s3、完成对审计业务相关数据的标注,为训练模型提供数据。
9.s4、以标注数据作crf算法的输入数据,完成模型训练。
10.s5、基于测试数据,完成模型的验证评估。
11.s6、构建模型运行容器及调用接口。
12.s7、将带检测的文本数据传入模型,收集模型输出结果。
13.进一步的,根据s1中的操作步骤,所述审计业务相关文档包括审计报告、底稿、记录、法律法规及规章制度。
14.进一步的,根据s2中的操作步骤,将审计业务相关文档均转换成txt格式。
15.进一步的,根据s3中的操作步骤,采用标注工具进行数据标注,所述标注工具为精灵标注。
16.进一步的,根据s3中的操作步骤,采用bio标注格式,完成对审计业务相关数据的标注。
17.进一步的,根据s4中的操作步骤,包括以下步骤:
18.s401、观察语料,编写正则表达式。
19.s402、执行正则表达式抽取,获得匹配的文本及其关键字段信息。
20.s403、将抽取的到的关键字段信息,提取前后30个字,一并导入crf算法,训练抽取模型。
21.进一步的,根据s401中的操作步骤,所述正则表达式为待抽取目标。
22.进一步的,根据s5中的操作步骤,包括以下步骤:
23.s501、准备分类语料库。
24.s502、将语料库分解为训练集和测试集,训练集和测试集的占比为8:2。
25.s503、将集合中的各文档都转换为数学向量。
26.s504、利用测试集对所构建出来的模型进行评估。
27.进一步的,根据s504中的操作步骤,效果评估包括两个指标,分别是正确率和召回率,召回率和正确率分别采用以下公式计算:
28.召回率r=a/(a c)*100%
29.正确率p=a/(a b)*100%,
30.其中a表示分类器将输入的即测试集正确分类到某个类别的个数,b表示分类器将输入测试集错误分类到某个类别的个数,c表示分类器将输入测试集错误地排除在某个类别之外的个数,d表示分类器将输入测试集正确地排除在某个类别之外的个数。
31.进一步的,根据s6中的操作步骤,应用各种成熟的分类算法基于训练集构建分类模型、基于测试集评估分类模型,不断迭代不同的算法并基于评价指标发现最优的分类器。
32.本发明提供了一种基于模型的新词发现方法,具备以下有益效果:
33.(1)本发明中,基于审计数据,利用新词发现技术,实现审计领域词的持续发现,结合梳理的现有行业词库,初步构建审计领域专业词库,后续将通过专业人员对词库进行审核,最终形成审计领域专业词库,为后续审计数据分析提供有效支撑。
34.(2)本发明中,对文本进行初步的“新词”发现,再由人工发现的“新词”进行审核,提取出真正的审计领域专业词汇,能够在很大程度上减轻纯人工从文档内提取审计领域专业词汇的工作量,提高审计专业词库构建效率。
附图说明
35.图1为一种基于模型的新词发现方法的流程图。
具体实施方式
36.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述;显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
37.本发明提供一种技术方案:请参阅图1,一种基于模型的新词发现方法,包括以下步骤:
38.(1)、获取审计业务相关文档。
39.(2)、对审计业务相关文档进行格式转换,将转换后的审计业务相关文档数据作为
后续标注工具的输入数据。
40.(3)、完成对审计业务相关数据的标注,为训练模型提供数据。
41.(4)、以标注数据作crf算法的输入数据,完成模型训练。
42.(5)、基于测试数据,完成模型的验证评估。
43.(6)、构建模型运行容器及调用接口。
44.(7)、将带检测的文本数据传入模型,收集模型输出结果。
45.进一步的,根据(1)中的操作步骤,审计业务相关文档包括审计报告、底稿、记录、法律法规及规章制度。
46.进一步的,根据(2)中的操作步骤,将审计业务相关文档均转换成txt格式。
47.进一步的,根据(3)中的操作步骤,采用标注工具进行数据标注,标注工具为精灵标注。
48.进一步的,根据(3)中的操作步骤,采用bio标注格式,完成对审计业务相关数据的标注。
49.进一步的,根据(4)中的操作步骤,包括以下步骤:
50.(401)、观察语料,编写正则表达式。
51.(402)、执行正则表达式抽取,获得匹配的文本及其关键字段信息。
52.(403)、将抽取的到的关键字段信息,提取前后30个字,一并导入crf算法,训练抽取模型。
53.进一步的,根据(401)中的操作步骤,正则表达式为待抽取目标。
54.进一步的,根据(5)中的操作步骤,包括以下步骤:
55.(501)、准备分类语料库。
56.(502)、将语料库分解为训练集和测试集,训练集和测试集的占比为8:2。
57.(503)、将集合中的各文档都转换为数学向量。
58.(504)、利用测试集对所构建出来的模型进行评估。
59.进一步的,根据(504)中的操作步骤,效果评估包括两个指标,分别是正确率和召回率,召回率和正确率分别采用以下公式计算:
60.召回率r=a/(a c)*100%
61.正确率p=a/(a b)*100%,
62.其中a表示分类器将输入的即测试集正确分类到某个类别的个数,b表示分类器将输入测试集错误分类到某个类别的个数,c表示分类器将输入测试集错误地排除在某个类别之外的个数,d表示分类器将输入测试集正确地排除在某个类别之外的个数。
63.进一步的,根据(6)中的操作步骤,应用各种成熟的分类算法基于训练集构建分类模型、基于测试集评估分类模型,不断迭代不同的算法并基于评价指标发现最优的分类器。
64.实施例的方法进行检测分析,并与现有技术进行对照,得出如下数据:
[0065] 新词持续发现情况工作量审计专业词库构建效率实施例持续发现较小较高现有技术无法持续发现较大较低
[0066]
根据上述表格数据可以得出,当实施实施例时,通过本发明一种基于模型的新词发现方法获得新词持续发现、工作量较小及审计专业词库构建效率较高的效果。
[0067]
一种基于模型的新词发现方法,包括以下步骤:
[0068]
(1)、获取审计业务相关文档,审计业务相关文档包括审计报告、底稿、记录、法律法规及规章制度。
[0069]
(2)、对审计业务相关文档进行格式转换,将转换后的审计业务相关文档数据作为后续标注工具的输入数据,将审计业务相关文档均转换成txt格式。
[0070]
(3)、完成对审计业务相关数据的标注,为训练模型提供数据,采用标注工具进行数据标注,标注工具为精灵标注,采用bio标注格式,完成对审计业务相关数据的标注。
[0071]
(4)、基于python语言,以标注数据作crf算法的输入数据,完成模型训练,crf即为条件随机场算法,是一种无向图模型,包括以下步骤:(401)、观察语料,编写正则表达式,正则表达式为待抽取目标,如:投标地址:xxxxx,(402)、执行正则表达式抽取,获得匹配的文本及其关键字段信息,(403)、将抽取的到的关键字段信息,提取前后30个字,一并导入crf算法,训练抽取模型。
[0072]
(5)、基于测试数据,完成模型的验证评估,包括以下步骤:(501)、准备分类语料库,(502)、将语料库分解为训练集和测试集,训练集和测试集的占比为8:2,即训练集训练集80%,测试集20%,(503)、将集合中的各文档都转换为数学向量,(504)、利用测试集对所构建出来的模型进行评估,效果评估包括两个指标,分别是正确率和召回率,召回率和正确率分别采用以下公式计算:
[0073]
召回率r=a/(a c)*100%
[0074]
正确率p=a/(a b)*100%,
[0075]
其中a表示分类器将输入的即测试集正确分类到某个类别的个数,b表示分类器将输入测试集错误分类到某个类别的个数,c表示分类器将输入测试集错误地排除在某个类别之外的个数,d表示分类器将输入测试集正确地排除在某个类别之外的个数,从上述定义可知,正确率是评价分类器找到的属于某个分类的文档是否正确的指标,而召回率是评价分类器在发现属于该分类文档过程中是否存在“遗漏”的指标,两个指标值均为越高越好,特别是当正确率和召回率都为100%时,表示该分类器发现了所有属于特定分类的文档(没有遗漏),并且发现的文档全部都是属于该分类(全部正确),故,在实际过程中,可以结合业务目标基于上述两个数值对分类器效果进行评价,对于不超过10个分类,在语料库质量较好的情况下,分类模型的召回率和正确率一般都可以超过70%。
[0076]
(6)、构建模型运行容器及调用接口,应用各种成熟的分类算法基于训练集构建分类模型、基于测试集评估分类模型,不断迭代不同的算法并基于评价指标发现最优的分类器。
[0077]
(7)、将带检测的文本数据传入模型,收集模型输出结果。
[0078]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
