1.本公开涉及图像处理技术领域,具体涉及一种训练数据的生成方法、训练数据的生成装置、计算机可读介质和电子设备。
背景技术:
2.深度图广泛应用于计算机视觉任务,比如视觉里程计、视觉建图、视觉slam、三维重建、场景感知、光斑渲染、自由视点渲染等等。在相关技术中,深度图中深度真值的获取方法一般有以下三种:第一种是通过深度传感器捕获真值数据,包括time
‑
of
‑
flight(tof)、结构光和双目立体匹配;第二种是在彩色图像上手工标注两点之间的远近关系;第三种则是基于自监督学习等机器学习或深度学习的方法,通过帧间位姿预测网络的协助获取位姿一致的深度图。
3.在上述方法中,第一种方法需要专业的采集设备,且每次采集只能获得单一的场景种类。同时,用于采集的传统深度传感器(比如tof、结构光和双目立体匹配)设备成本较高且功耗较大;第二种方法则依赖大量人工操作,而且只能获得稀疏点对的远近关系;第三种方法则需要大量训练数据,且对训练数据还有一定的要求。例如,在基于posenet depthnet的自监督学习方法中,要求用于训练的视频数据需要采用一镜到底的拍摄方式。然而,深度学习算法高度依赖于训练数据,但通过深度传感器对无限多的场景进行数据采集又显得不切实际。
技术实现要素:
4.本公开的目的在于提供一种训练数据的生成方法、训练数据的生成装置、计算机可读介质和电子设备,进而至少在一定程度上实现提供数量丰富、质量较高的训练数据的目标。
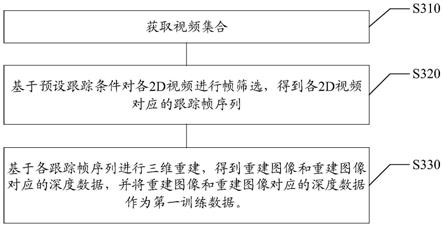
5.根据本公开的第一方面,提供一种训练数据的生成方法,包括:获取视频集合;视频集合中包括至少一个2d视频;基于预设跟踪条件对各2d视频进行帧筛选,得到各2d视频对应的跟踪帧序列;基于各跟踪帧序列进行三维重建,得到重建图像和重建图像对应的深度数据,并将重建图像和重建图像对应的深度数据作为第一训练数据。
6.根据本公开的第二方面,提供一种训练数据的生成装置,包括:视频获取模块,用于获取视频集合;视频集合中包括至少一个2d视频;数据筛选模块,用于基于预设跟踪条件对各2d视频进行帧筛选,得到各2d视频对应的跟踪帧序列;数据生成模块,用于基于各跟踪帧序列进行三维重建,得到重建图像和重建图像对应的深度数据,并将重建图像和重建图像对应的深度数据作为第一训练数据。
7.根据本公开的第三方面,提供一种计算机可读介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述的方法。
8.根据本公开的第四方面,提供一种电子设备,其特征在于,包括:处理器;以及存储器,用于存储一个或多个程序,当一个或多个程序被一个或多个处理器执行时,使得一个或
多个处理器实现上述的方法。
9.本公开的一种实施例所提供的训练数据的生成方法,通过基于预设跟踪条件对获取到的视频集合中的每一个2d视频进行帧筛选,可以得到满足预设跟踪条件的2d视频对应的跟踪序列帧,然后基于跟踪帧序列进行三维重建,得到重建图像和重建图像对应的深度数据,进而将重建图像和深度数据作为第一训练数据。通过上述方法,可以基于互联网上已有的,不同设备拍摄的,场景丰富的视频转换为深度真值,生成数量巨大、场景丰富的训练数据,以便于基于这些数据对与深度数据有关机器学习或深度学习网络进行训练。例如,上述数量巨大、场景丰富的训练数据非常适合用于训练出泛化性强的单目深度预测网络。
10.应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
11.此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。在附图中:
12.图1示出了可以应用本公开实施例的一种示例性系统架构的示意图;
13.图2示出了可以应用本公开实施例的一种电子设备的示意图;
14.图3示意性示出本公开示例性实施例中一种训练数据的生成方法的流程图;
15.图4示意性示出本公开示例性实施例中一种帧筛选处理方法的流程图;
16.图5示意性示出本公开示例性实施例中2d视频基于不同初始化方法的稠密三维结果的效果对比图;
17.图6示意性示出本公开示例性实施例中另一2d视频基于不同初始化方法的稠密三维结果的效果对比图;
18.图7示意性示出常见的4种错误或不符合真实运动情况的稀疏重建结果的示意图;
19.图8示意性示出本公开示例性实施例中一种重建图像和重建图像对应的语义分割图像;
20.图9示意性示出本公开示例性实施例中深度掺杂消除前后的对比图;
21.图10示意性示出本公开示例性实施例中一种稠密重建结果对应的重建图像、几何一致性深度图像和光度一致性深度图像;
22.图11示意性示出本公开示例性实施例中一种对无效碎片进行清洗的清洗方法的流程图;
23.图12示意性示出本公开示例性实施例中一种对边缘部分进行清洗的清洗方法的流程图;
24.图13示意性示出本公开示例性实施例中一种第一置信度区域和第二置信度区域;
25.图14示意性示出本公开示例性实施例中一种第三置信度区域和第四置信度区域;
26.图15示意性示出本公开示例性实施例中对边缘部分进行清洗前后的对比图;
27.图16示意性示出本公开示例性实施例中一种生成相对深度数据的过程的示意图;
28.图17示意性示出本公开示例性实施例中一种消除假人挑战视频对应重建图像的
深度掺杂的过程的示意图;
29.图18示意性示出本公开示例性实施例中一种对稠密重建结果进行清洗的方法的流程图;
30.图19示意性示出本公开示例性实施例中一种基于3d视频生成第二训练数据的原理示意图;
31.图20示意性示出本公开示例性实施例中两种不同场景类别对应的重建图像数据集;
32.图21示意性示出本公开示例性实施例中对图20中的两种重建图像数据集进行降维后得到的重建图像数据集;
33.图22示意性示出本公开示例性实施例中另一种训练数据的生成方法的流程图;
34.图23示意性示出本公开示例性实施例中训练数据的生成装置的组成示意图。
具体实施方式
35.现在将参考附图更全面地描述示例实施方式。然而,示例实施方式能够以多种形式实施,且不应被理解为限于在此阐述的范例;相反,提供这些实施方式使得本公开将更加全面和完整,并将示例实施方式的构思全面地传达给本领域的技术人员。所描述的特征、结构或特性可以以任何合适的方式结合在一个或更多实施方式中。
36.此外,附图仅为本公开的示意性图解,并非一定是按比例绘制。图中相同的附图标记表示相同或类似的部分,因而将省略对它们的重复描述。附图中所示的一些方框图是功能实体,不一定必须与物理或逻辑上独立的实体相对应。可以采用软件形式来实现这些功能实体,或在一个或多个硬件模块或集成电路中实现这些功能实体,或在不同网络和/或处理器装置和/或微控制器装置中实现这些功能实体。
37.图1示出了可以应用本公开实施例的一种训练数据的生成方法及装置的示例性应用环境的系统架构的示意图。
38.如图1所示,系统架构100可以包括终端设备101、102、103中的一个或多个,网络104和服务器105。网络104用以在终端设备101、102、103和服务器105之间提供通信链路的介质。网络104可以包括各种连接类型,例如有线、无线通信链路或者光纤电缆等等。终端设备101、102、103可以是各种具有图像处理功能的电子设备,包括但不限于台式计算机、便携式计算机、智能手机和平板电脑等等。应该理解,图1中的终端设备、网络和服务器的数目仅仅是示意性的。根据实现需要,可以具有任意数目的终端设备、网络和服务器。比如服务器105可以是多个服务器组成的服务器集群等。
39.本公开实施例所提供的训练数据的生成方法可以由终端设备101、102、103中执行,相应地,训练数据的生成装置可以设置于终端设备101、102、103中。但本领域技术人员容易理解的是,本公开实施例所提供的训练数据的生成方法也可以由服务器105执行,相应的,训练数据的生成装置也可以设置于服务器105中,本示例性实施例中对此不做特殊限定。举例而言,在一种示例性实施例中,可以是用户通过终端设备101、102拍摄视频,并通过网络104将视频上传至互联网上各种视频服务器后,终端设备103通过网络104从各种视频网站上下载视频得到视频集合,并基于视频集合生成第一训练数据。
40.本公开的示例性实施方式提供一种用于实现训练数据的生成方法的电子设备,其
可以是图1中的终端设备101、102、103或服务器105。该电子设备至少包括处理器和存储器,存储器用于存储处理器的可执行指令,处理器配置为经由执行可执行指令来执行训练数据的生成方法。
41.下面以图2中的移动终端200为例,对电子设备的构造进行示例性说明。本领域技术人员应当理解,除了特别用于移动目的的部件之外,图2中的构造也能够应用于固定类型的设备。在另一些实施方式中,移动终端200可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。图示的部件可以以硬件、软件或软件和硬件的组合实现。各部件间的接口连接关系只是示意性示出,并不构成对移动终端200的结构限定。在另一些实施方式中,移动终端200也可以采用与图2不同的接口连接方式,或多种接口连接方式的组合。
42.如图2所示,移动终端200具体可以包括:处理器210、内部存储器221、外部存储器接口222、通用串行总线(universal serial bus,usb)接口230、充电管理模块240、电源管理模块241、电池242、天线1、天线2、移动通信模块250、无线通信模块260、音频模块270、扬声器271、受话器272、麦克风273、耳机接口274、传感器模块280、显示屏290、摄像模组291、指示器292、马达293、按键294以及用户标识模块(subscriber identification module,sim)卡接口295等。其中传感器模块280可以包括深度传感器2801、压力传感器2802、陀螺仪传感器2803等。
43.处理器210可以包括一个或多个处理单元,例如:处理器210可以包括应用处理器(application processor,ap)、调制解调处理器、图形处理器(graphics processing unit,gpu)、图像信号处理器(image signal processor,isp)、控制器、视频编解码器、数字信号处理器(digital signal processor,dsp)、基带处理器和/或神经网络处理器(neural
‑
network processing unit,npu)等。其中,不同的处理单元可以是独立的器件,也可以集成在一个或多个处理器中。
44.npu为神经网络(neural
‑
network,nn)计算处理器,通过借鉴生物神经网络结构,例如借鉴人脑神经元之间传递模式,对输入信息快速处理,还可以不断的自学习。通过npu可以实现移动终端200的智能认知等应用,例如:图像识别,人脸识别,语音识别,文本理解等。在一些实施例中,npu可以用于进行语义分割、对预设的参数进行自适应调整、以及三维重建等步骤中。
45.处理器210中设置有存储器。存储器可以存储用于实现六个模块化功能的指令:检测指令、连接指令、信息管理指令、分析指令、数据传输指令和通知指令,并由处理器210来控制执行。
46.移动终端200通过gpu、显示屏290及应用处理器等实现显示功能。gpu为图像处理的微处理器,连接显示屏290和应用处理器。gpu用于执行数学和几何计算,用于图形渲染。处理器210可包括一个或多个gpu,其执行程序指令以生成或改变显示信息。
47.移动终端200可以通过isp、摄像模组291、视频编解码器、gpu、显示屏290及应用处理器等实现拍摄功能。其中,isp用于处理摄像模组291反馈的数据;摄像模组291用于捕获静态图像或视频;数字信号处理器用于处理数字信号,除了可以处理数字图像信号,还可以处理其他数字信号;视频编解码器用于对数字视频压缩或解压缩,移动终端200还可以支持一种或多种视频编解码器。
48.在一些实施例中,可以基于上述gpu、显示屏290、应用处理器、isp、摄像模组291、视频编解码器等对视频进行渲染、分割等处理过程。
49.深度图广泛应用于计算机视觉任务,比如视觉里程计、视觉建图、视觉slam、三维重建、场景感知、光斑渲染、自由视点渲染等等。传统深度传感器(比如tof、结构光和双目立体匹配)成本较高且功耗较大。通过单张彩色图像恢复深度图仅需要一个摄像头,能最大限度降低生产成本和使用成本。根据工作时是否主动发射信号,深度传感器又分为主动传感器和被动传感器。主动传感器需要使用激光或图案投影仪向目标场景投射出特殊信号,通过分析传感器对信号的响应来恢复深度。被动传感器仅需要目标在自然光照或者肉眼可见的光照条件下。传统被动单目深度估计算法对场景和拍摄方式有特殊的要求,比如需要特定光照、特殊对焦方式、目标物体局部纹理等等,不适用于通用的使用场景。
50.基于深度学习的算法通过对大规模数据的模型参数更新(训练),学习到目标场景到深度图的非线性映射关系,进而预测较为准确的深度。然而,深度学习算法高度依赖于训练数据。例如,仅用车载数据训练的模型很难处理室内影像。为了训练出泛化性强的模型,我们需要数量巨大且场景丰富的训练数据。使用深度传感器对无限多的场景进行数据采集又显得不切实际。
51.基于上述一个或多个问题,本示例实施方式提供了一种训练数据的生成方法。该训练数据的生成方法可以基于网民上传的用不同设备拍摄的场景丰富的视频生成数量巨大、场景丰富的训练数据。该训练数据的生成方法可以应用于上述终端设备101、102、103中的一个或多个,也可以应用于上述服务器105,本示例性实施例中对此不做特殊限定。参考图3所示,该训练数据的生成方法可以包括以下步骤s310至s330:
52.在步骤s310中,获取视频集合。
53.其中,视频集合中包括至少一个2d视频。
54.在一示例性实施例中,由于互联网流媒体的兴起,每天都有数以万计的网民把用不同设备拍摄的场景丰富的视频上传到视频网站。这些视频所拍摄的场景具有内容丰富、时间地点跨度大、拍摄风格多样化、拍摄装置多样化等优点,因此若能利用互联网流媒体视频生成训练数据,得到训练数据也会具有场景类型丰富等特点,进而得到试用场景更广的机器学习、深度学习模型。基于上述原因,在获取视频集合时,可以基于网络爬虫在互联网上爬取视频数据。
55.具体的,可以使用网页抓包分析、动态加载json数据解析、youtube
‑
dl等相关技术实现对多个视频网站的自动视频检索和批量下载的过程。需要说明的是,为了得到场景丰富的视频集合,可以在爬取视频之前,先确定一些能够提供丰富场景、类型的视频网站,然后基于关键词、视频来源等方式进行检索和批量下载。
56.例如,在一基于关键词检索结果批量下载的实施例中,可以先自动化测试框架selenium模拟浏览器操作自动进行指定关键词的开放视频网站数据检索,然后通过抓包分析,从检索结果页面接收请求后返回的json数据中解析出各个视频子页面的url,以及从视频子页面接收请求后返回的json数据中解析出视频的真实地址,然后基于编写好的脚本通过requests库模拟网页请求、自动解析json数据获取视频文件真实地址、视频下载、格式化命名及视频信息输出。
57.再如,在一基于指定视频作者批量下载的实施例中,同样可以通过抓包分析寻找
开放的指定作者主页的url规则、视频子页面url规则等,然后从视频子页面接收请求后返回的json数据中解析出视频的真实地址,然后基于编写好的脚本完成指定视频作者的主页url生成、主页访问请求、视频子页面url解析、视频文件真实地址解析、视频下载、格式化命名及视频信息输出。
58.需要说明的是,其中开放视频网站或者开放的指定作者主页是指没有版权等限制,或者已经与版权方或者其他方商榷后,可以获取的网站或者主页。
59.在步骤s320中,基于预设跟踪条件对各2d视频进行帧筛选,得到各2d视频对应的跟踪帧序列。
60.在一示例性实施例中,由于三维重建是一个耗时较长,且输出文件非常大的的过程,因此在进行三维重建之前,可以先对视频数据进行筛选,将视频中重建失败概率较大或者相似度较高的视频帧滤除,以缩短三维重建的耗时,使得输出文件更小。具体的,针对每一个2d视频可以做帧筛选处理。其中,帧筛选处理可以包括:先在2d视频中抽取第1个视频帧,判断第1个视频帧是否满足预设跟踪条件,在第1个视频帧满足预设跟踪条件时,将第1个视频帧加入视频子序列;基于预设步长继续抽取第2个视频帧,并继续确定第2个视频帧是否满足预设跟踪条件,在第2个视频帧满足预设跟踪条件时,将第2个视频帧也加入视频子序列;循环执行上述抽取和判断的过程,在抽取的第i个视频帧满足预设跟踪条件时,将第i个视频帧加入至视频子序列,并继续抽取第i 1个视频帧;在抽取的第i个视频帧不满足预设跟踪条件时,将第i个视频帧之前的所有满足预设跟踪条件的视频帧生成的视频子序列确定为2d视频对应的跟踪帧序列。其中,i取正整数。
61.需要说明的是,在视频拍摄时,拍摄者运动缓慢或静止,或者拍摄对象运动缓慢或禁止,可能造成视频中存在高相似度连续帧、大角度纯旋转等容易导致跟踪失败的视频帧,因此可以基于各视频帧的特点,以及与前一个抽取的视频帧的联系进行筛选。具体的,预设跟踪条件可以包括:视频帧中的特征点数量大于数量阈值、视频帧对应的光流匹配向量的平均模长小于模长范围的最大值、视频帧对应的内点数量大于内点阈值,以及视频帧对应的帧间旋转角小于角度阈值。
62.特殊地,在视频帧对应的光流匹配向量的平均模长小于模长范围的最小值时,可以认为相邻两帧之间几乎静止,为避免抽取相似度过高的视频帧,可以不将第i个视频帧加入视频帧子序列,直接抽取第i 1个视频帧。
63.此外,由于第1个视频帧无法基于预设步长确定,因此可以提前设置固定帧数为第1个视频帧,然后以第1个视频帧为基准,通过预设步长进行后续视频帧的抽取。例如,可以设置抽取视频的第n帧为第1个视频帧;还可以通过其他方式确定第1个视频帧,本公开对此不做特殊限定。
64.在一示例性实施例中,由于三维重建过程需要足够数量的视频帧,因此需要对2d视频筛选出的视频子序列进行帧数控制。具体的,在视频子序列的帧数小于最低阈值时,为了避免无法在三维重建过程中输出满足需求的重建结果,可以将该序列丢弃,即该2d视频没有对应的跟踪序列,无法构建训练数据;而在视频子序列的帧数大于或等于最低阈值时,可以直接将该视频子序列确定为2d视频对应的跟踪帧序列;此外,为了防止跟踪帧序列帧数过多导致三维重建耗时过长,还可以设置最高阈值,在视频子序列的帧数大于最高阈值时,可以对视频子序列进行切割,将帧数等于最高阈值的视频子序列作为该2d视频对应的
跟踪帧序列进行后续处理。
65.需要说明的是,在对视频子序列进行切割时,需要在视频子序列中切割出帧数等于最高阈值的连续序列作为跟踪帧序列,本公开对具体的切割方法不做特殊限定。例如,在最高阈值10帧时,若视频子序列中包括从2d视频中抽取的第1个至第15个视频帧,此时可以抽取第1个至第10个视频帧作为跟踪帧序列,也可以抽取第2个至第11个,第3个至第12个等,本公开对此不做特殊限定。
66.以下以预设跟踪条件同时包括上述所有条件为例,参照图4所示,对帧筛选处理过程进行详细阐述:
67.步骤s401,根据预设步长提取第i个视频帧;其中,i取1、2、
…
的正整数。
68.其中,预设步长可以是根据正常的视频拍摄经验选择一个经验值,也可以通过增加一个基于视频确定自适应生成对应的预设步长的模型或算法确定预设步长。例如,可以基于视频中,各视频帧之间的匹配点对的向量平均模长确定对应的预设步长。匹配点对的向量平均模长越小,说明各视频帧之间的相似度越大,因此可以选择更大的预设步长,以避免筛选出较多相似度较高的相邻视频帧。
69.步骤s403,提取第i个视频帧中的特征点。
70.步骤s405,判断第i个视频帧中的特征点数量是否大于数量阈值。
71.其中,数量阈值可以根据经验值进行设定。由于视频帧中的特征点通常用于进行跟踪,如果特征点数量过少,则可能导致该视频帧中缺乏足够的特征点进行跟踪,三维重建时在该视频帧位置容易出现跟踪丢失的问题,进而可能会引起三维重建失败。因此,可以基于特征点数量对视频帧进行筛选。
72.步骤s407,在第i个视频帧中的特征点数量大于数量阈值时,对第i个视频帧进行光流计算,以获取光流匹配向量的平均模长。
73.在能够提取到足够数量的特征点时,可以通过光流计算的方法在第i个视频帧和第i
‑
1个视频帧之间构建点对应关系,并计算匹配点对之间的匹配向量的平均模长。
74.步骤s409,判断光流匹配向量的平均模长是否在模长范围内。
75.如果平均模长小于模长范围的最小值,则认为相邻两帧之间几乎静止,为避免相似度过高则跳过当前帧,继续按照预设步长在视频中抽取第i 1个视频帧。如果平均模长大于预设范围最大值,则认为相邻两帧之间视差过大,容易造成跟踪丢失。因此,可以基于平均模长对视频帧进行筛选。
76.步骤s411,在光流匹配向量的平均模长在模长范围内时,基于匹配点对进行基础矩阵求解,并计算视频帧包含的匹配点对中内点的数量。
77.如果匹配点对之间的匹配向量的平均模长满足预设的模长范围,可以继续基于匹配点对进行基础矩阵求解,以确定求解得到的内点。其中,求解的方法可以包括ransac方法,内点是指使估计的基础矩阵误差较小的匹配点对。
78.步骤s413,判断视频帧中包含匹配点对中内点的数量是否超过内点阈值。
79.如果内点数量过少,则认为相邻两帧之间无法构建足够数量的特征匹配关系进行帧间位姿求解,容易造成跟踪丢失。因此,可以基于内点数量对视频帧进行筛选。
80.步骤s415,在内点数量超过内点阈值时,分解步骤s411中得到的基础矩阵求解帧间位姿,并计算帧间旋转角。
81.帧间旋转角用于表征相邻帧之间位姿的旋转变化,在相邻帧之间发生了大角度旋转时,容易造成跟踪过程中帧间位姿求解的错误或者失败的问题,进而可能导致跟踪丢失。因此,可以基于帧间旋转角对视频帧进行筛选。
82.步骤s417,判断帧间旋转角是否小于角度阈值。
83.步骤s419,在帧间旋转角小于角度阈值时,可以将第i个视频帧加入视频子序列,并返回步骤s401继续抽取第i 1个视频帧。
84.如果第i个视频帧符合上述串行的各个预设跟踪条件,则认为当前视频帧处在三维重建的过程中大概率可以稳定的进行跟踪,因此将该帧加入当前子序列中,并开始下一个视频帧的抽取和处理。
85.步骤s421,在第i个视频帧不满足上述任意一个条件,或者当前2d视频无法抽取第i 1个视频帧时,判断已有的视频子序列的帧数是否小于最低阈值。
86.如果第i个视频帧不符合上述预设跟踪条件中的任意一个,则可以判断若将第i个视频帧加入视频子序列中,后续三维重建时很可能在第i个视频帧处出现跟踪丢失的问题,因此不能将第i个视频帧加入视频子序列中。需要说明的是,在视频子序列中,视频帧的排序与抽取时的顺序,以及该视频帧在2d视频中的顺序一致。其中,当前2d视频无法抽取第i 1个视频帧是指在抽取第i个视频帧时,已经抽取到了2d视频的最后几帧视频帧,按照预设步长继续抽取无法获取第i 1个视频帧;在第i个视频帧不满足上述任意一个条件,已有的视频子序列是指第1个视频帧至第i
‑
1个视频帧形成的视频子序列;在当前2d视频无法抽取第i 1个视频帧时,已有的视频子序列是指第1个视频帧至第i个视频帧形成的视频子序列。
87.此外,由于三维重建过程需要足够数量的视频帧,因此需要对2d视频筛选出的视频子序列进行帧数控制。
88.步骤s423,在视频子序列的帧数小于最低阈值时,丢弃该视频子序列,并确定2d视频帧的跟踪帧序列为空。
89.如果视频子序列的帧数小于最低阈值,则认为该视频子序列帧数过少,无法在后续的三维重建中输出满足需求的重建结果,因此丢弃该子序列,将该2d视频帧的跟踪帧序列确定为空,即无法继续基于该2d视频生成训练数据。
90.步骤s425,在视频子序列的帧数大于或等于最低阈值时,将视频子序列作为跟踪帧序列。
91.需要说明的是,还可以设置最高阈值,如果视频子序列的帧数大于最高阈值,为防止视频子序列帧数过多导致三维重建耗时过长,可以对视频子序列进行切割,并将切割后的视频子序列作为该2d视频对应的跟踪帧序列进行后续处理。
92.在步骤s330中,基于各跟踪帧序列进行三维重建,得到重建图像和重建图像对应的深度数据,并将重建图像和重建图像对应的深度数据作为第一训练数据。
93.其中,重建图像是指与通过三维重建后得到的深度图像对应的rgb等格式的图像,该图像中不包括深度数据,是基于多帧视频帧复原的完整的场景图像,如图5和6中的图5a和图6a;第一训练数据作为利用预训练数据(第二训练数据)训练的模型的输入,进行进一步训练,可以得到更加精细的模型。
94.在一示例性实施例中,在得到跟踪帧序列后,针对每一个跟踪帧序列,可以先进行稀疏三维重建,得到稀疏三维重建结果;然后基于稀疏三维重建结果继续进行稠密三维重
建,得到稠密重建结果;之后可以基于稠密重建结果生成重建图像和重建图像对应的深度数据。其中,稠密重建结果生成的重建图像对应的深度数据可以包括深度图像。
95.在一示例性实施例中,在进行稀疏三维重建时,可以通过运动结构恢复(structure from motion,sfm)的方法,基于跟踪帧序列进行多视角稀疏重建。此外,还可以通过其他方法进行稀疏三维重建,本公开对此不做特殊限定。
96.需要说明的是,在实际使用时,由于进行多视角稀疏重建时,部分序列虽然可以正常输出稀疏重建结果,仍然存在部分稀疏重建结果是错误的,或者不符合真实运动情况的。参照图7所示,错误或不符合真实运动情况的稀疏重建结果包括以下几种可能:地图点数量少(如图7a),相机数量少(如图7b),帧间旋转异常(如图7c),帧间平移异常(如图7d)等;其中颜色最深的表示相机轨迹,其余表示恢复出的稀疏点云。因此可以基于运动轨迹连续性对稀疏重建结果进行筛选,将错误的或者不符合真实运动情况的稀疏重建结果删除,得到筛选后的稀疏重建结果,以基于筛选后的稀疏重建结果进行稠密三维重建。
97.具体的,由于稀疏重建过程中,输入的跟踪帧序列为从视频中筛选出来的有序连续图像序列,这类序列的真实运动轨迹具有连续且一致的特点。因此,可以基于点云的数量、相机数量、帧间旋转和帧间位移等参数对稀疏重建结果进行联合判断,以滤除掉运动轨迹连续性较差的稀疏重建结果,以提升后续稠密重建的成功率。举例而言,可以通过对点云的数量、相机数量、帧间旋转和帧间位移等参数设置阈值实现联合判断的目标。在点云数量和相机数量低于阈值,帧间旋转和帧间位移大于阈值时,确定其运动轨迹连续性较差,进而将该稀疏重建结果删除。
98.在一示例性实施例中,在得到稀疏重建结果之后,可以基于稀疏重建结果进行稠密三维重建,得到稠密重建结果。在进行稠密三维重建时,可以采用各种多视图稠密重建的方法进行重建,本公开对此不做特殊限制。
99.在一示例性实施例中,可以采用深度传播的方法进行深度恢复,该方法对未知的深度利用随机值进行初始化,然后基于期望最大化方法逐步对深度进行迭代更新,从而获得精度较高的深度估计结果。但是选用随机初值容易导致估计深度与真值相差较大甚至恢复失败的情况。为了解决这个问题,可以获取稀疏重建结果中各稀疏点对应的坐标和稀疏深度值;然后以稀疏深度值为该作为对应的初始深度值进行三维稠密重建,得到稠密重建结果。通过稀疏重建结果中的稀疏深度值,可以利用相对准确的初值进行初始化,使得稠密重建的结果更加的趋于真值,且对于稠密重建失败的区域也有很好的重建效果。
100.例如,参照图5和图6所示,图5a和图6a为rgb图像,图5b和图6b是利用随机值进行初始化对rgb图像进行稠密重建的效果图,图5c和6c是利用稀疏深度值进行初始化对rgb图像进行稠密重建的效果图。通过对比可知,与利用随机值进行初始化相比,利用稀疏深度值进行初始化的稠密三维重建结果可以恢复更多区域的深度值,如图中框出部分所示。
101.在一示例性实施例中,稠密重建生成的深度数据可能存在一些容易产生较大误差的区域,比如支离破碎的区域、反光区域以及弱纹理区域等。这些问题都会对最终生成的训练数据产生污染,进而导致模型训练变慢以及训练结果为次优结果等问题。因此,在基于稠密重建结果确定重建图像和重建图像对应的深度数据之前,可以基于语义分割算法对稠密重建结果进行清洗,获取清洗后的稠密重建结果,以基于清洗后的稠密重建结果确定重建图像和重建图像对应的深度数据。
102.其中,语义分割算法是计算机视觉的基本课题之一,其目标是为图像的每个像素值分配一个语义标签。语义标签主要包括任务、动物、植物、建筑、天空、水面等语义分类。针对语义分割类型的任务,其输入是一张rgb图像,输出的则是一张为每个像素值分配好类别标签的mask图像。例如,图8b示出了对图8a进行语义分割得到的语义分割图。
103.在一示例性实施例中,在多帧三维重建的前提下,若重建图像中存在背景物体被前景物体遮挡的情况,例如远处的建筑物被近处的人物遮挡时,由于多帧数据中背景物体被观测的帧数往往要大于前景物体,因此可能导致深度图像中前景物体对应区域中会掺杂背景像素。针对这一问题,在基于语义分割算法对稠密重建结果进行清洗时,可以先通过稠密重建结果中深度数据确定一个深度图像,然后通过语义风格算法在该深度图像中确定第一区域,之后基于预设算法对第一区域进行处理,以消除第二区域对第一区域的深度掺杂,得到清洗后的稠密重建结果。其中,第二区域的深度大于第一区域。
104.在一示例性实施例中,在第一区域的语义标签对应的是非生物时,可以基于光度一致性和几何一致性来对第一区域进行处理。具体的,稠密三维重建可以得到两个结果,分别是光度一致性结果和几何一致性结果。可以直接判断几何一致性深度值是否超过光度一致性深度值的预设倍数,在几何一致性深度值超过光度一致性深度值的预设倍数,使用光度一致性深度值,否则使用几何一致性深度值。由于只有在背景深度值比前景深度值大足够倍数才会产生背景深度值掺杂前景深度值的问题,因此可以通过预设倍数的方式消除第二区域(背景区域)对第一区域(前景区域)的深度掺杂。例如,图9显示了通过预设比例为1.1的上述方法消除深度掺杂之前(图9a)和消除之后(图9b)的对比图像,可以看到前景中树木区域的背景掺杂在一定程度上被消除了。
105.其中,光度一致性结果仅受到图像局部区域的光度一致性来约束匹配度,而几何一致性结果则在光度一致性的基础上,利用多帧匹配关系来约束当前匹配。因此,几何一致性结果可以过滤掉大部分的弱纹理区域,例如天空和纯色的地面,如图10中的原图(图10a)和几何一致性深度图像(图10b)所示。需要说明的是,由于弱纹理区域难以寻找匹配关系,因此三维重建结果得到的深度图像只有部分区域的深度值是可靠的,对应的,只有这部分可靠的深度值才可以作为有效的训练数据进行序列,例如,图10中的重建图像(图10a)、几何一致性深度图像(图10b)和光度一致性深度图像(图10c)中的天空和路面部分对应的深度值是无效的。
106.在一示例性实施例中,在第一区域的语义标签对应的是生物时,对于不同的生物对象,由于背景深度往往大于前景深度,而同一个生物对象中的深度变化一般较小,因此可以采用中值滤波的方式消除第二区域(背景区域)对生物区域(第一区域)的掺杂。具体的,可以先根据语义分割结果确定不同的生物,例如不同的人;然后针对每个生物区域,分别对该生物区域进行中值滤波,以消除背景区域对该生物区域的深度掺杂。
107.在一示例性实施例中,除了上述深度掺杂的问题,还可能出现无效深度值碎片化的出现在深度图像中的问题,因此需要对这些碎片化的无效深度值进行清洗,以基于清洗后的稠密重建结果确定重建图像和重建图像对应的深度数据。针对这个问题,在对无效碎片进行清洗时,具体的,参照图11所示,可以包括以下步骤s1110至s1140:
108.在步骤s1110中,基于中值滤波算法在稠密重建结果中的深度数据中确定无效深度值和有效深度值。
109.在一示例性实施例中,可以使用大小为预设像素的窗口对深度图像进行中值滤波,可以得到滤波前的深度图像a和滤波后的深度图像b,然后基于设置的误差比例n,将a/b大于nb的区域或者b/a大于nb的区域归类为误差较大的像素,即深度值无效的像素。需要说明的是,为了在后续步骤中可以区分无效深度值和有效深度值,可以在确定深度值无效的像素之后,将该像素对应的深度值设置为非数。其中,上述误差比例n可以取1.1,也可以根据需求进行不同的设定。通过对深度图局部窗口区域的分析可知,通常情况下与中值相差过大的深度值往往误差较大,因此可以基于上述中值滤波的方式区分误差较大的无效深度值。
110.在步骤s1120中,通过语义分割算法在稠密重建结果确定的深度图像中确定连通区域。
111.在一示例性实施例中,由于在语义分割得到各个语义标签后,如果同一个语义标签对应的连通区域中的无效深度值较多,则可以确定该连通区域的深度值误差较大,因此需要将该连通区域对应的深度值全部作为无效深度值进行后续处理。此时,可以先基于语义分割算法得到的语义分割图计算每一个分割类别对应的连通区域,然后针对每个进行进一步处理。具体的,可以先从语义分割图中提取静态前景掩膜,例如,可以包括树、生物、喷泉、雕塑等;然后针对每个类别,例如针对树这种类别,计算得到若干个连通区域;其中连通区域是指在该区域内的每个像素都为同一类别,且这些像素能够上、下、左、右相互连通。
112.在步骤s1130中,基于无效深度值和有效深度值计算连通区域对应的无效占比;
113.在步骤s1140中,在无效占比大于第一占比时,将连通区域对应的深度值确定为无效深度值,得到清洗后的稠密重建结果。
114.在一示例性实施例中,在确定了连通区域、无效深度值和有效深度值之后,针对每个连通区域分别计算该连通区域中无效深度值的占比,以确定各个连通区域中的无效占比是否大于第一占比。如果大于第一占比,说明该连通区域中无效深度值过多,可以将该连通区域中的深度值确定为无效深度值,得到清洗后的稠密重建结果。同样的,为了在后续处理时能够准确分辨无效深度值,可以将该连通区域中的深度值全部设置为非数。
115.在一示例性实施例中,除了上述问题之外,还可能在深度值的置信度较低和置信度较高的区域边缘可能存在不可靠的深度值,因此也需要对边缘部分进行清洗。针对这个问题,在对边缘部分清洗时,参照图12所示,可以包括以下步骤s1210至s1240:
116.在步骤s1210中,通过语义分割算法对稠密重建结果确定的重建图像进行语义分割,得到语义分割图像。
117.在一示例性实施例中,由于无穷远区域(如天空)、狭长结构区域(如路灯)、人造图案区域(如海报)、动态物体区域(如旗臶)、反光区域(如玻璃)、以及动态反光区域(如水面)等区域往往难以获取正确的深度值,同时也存在其他容易重建的区域。基于此,可以先通过语义分割算法对稠密重建结果确定的重建图像进行语义分割,得到语义分割图像,进而基于语义分割图像确定重建图像中各区域的置信度。
118.在步骤s1220中,基于置信度分类方法对语义分割图像包含的语义标签进行分类,以通过语义分割图像将稠密重建结果确定的重建图像划分为第一置信度区域和第二置信度区域。
119.其中,第一置信度区域的置信度低于第二置信度区域的置信度。
120.在一示例性实施例中,得到语义分割图像,可以基于预先设定的置信度分类方法对语义分割图像中包含的语义标签进行分类,得到置信度低的一类语义标签和置信度高的一类语义标签,然后将置信度低的一类语义标签在重建图像中的对应区域确定为第一置信度区域,将置信度高的一类语义标签在重建图像中的对应区域确定为第二置信度区域。需要说明的是,为了后续步骤能够直接确定哪些区域是第一置信度区域哪些区域是第二置信度区域,可以分别对两个区域的像素标记不同的标签。例如,可以将第一置信度区域包含的像素标记为1,将第二置信度区域包含的像素标记为2。
121.举例而言,针对如图8a所示的重建图像,可以将其进行语义分割得到如图8b所示的语义分割图像,然后对语义分割标签进行分类,将天空和路灯划分为一类,其余划分为一类。对应的,可以得到如图13a所示的第一置信度区域和如图13b所示的第二置信度区域。
122.在步骤s1230中,对第一置信度区域进行形态学膨胀处理,以获取膨胀后的第三置信度区域,并将第三置信度区域对应的深度值确定为无效深度值。
123.在一示例性实施例中,在得到置信度较低的第一置信度区域之后,可以对第一置信度区域进行形态学膨胀处理,以将原第一置信度区域的边缘包含在膨胀后的第三置信度区域中,然后将第三置信度区域对应的深度值确定为无效深度值。需要说明的是,与上面一样,为了便于后续步骤可以区分无效深度值和有效深度值,可以在确定深度值无效的像素之后,将该像素对应的深度值设置为非数。
124.举例而言,针对图13a所示的第一置信度区域(浅色区域),可以先对第一置信度区域进行半径为4像素的形态学膨胀,膨胀后得到如图14a所示的第三置信度区域(浅色区域),并把第三置信度区域的所有深度值置为非数。
125.在步骤s1240中,对第二置信度区域进行形态学收缩处理,以获取收缩后的第四置信度区域,并将第四置信度区域之外的区域对应的深度值确定为无效深度值,得到清洗后的稠密重建结果。
126.在一示例性实施例中,在得到置信度较高的第二置信度区域之后,可以对第二置信度区域进行形态学闭运算和形态学腐蚀处理,以将包含在原第二置信度区域的边缘排除在收缩后的第四置信度区域中,然后将第三四置信度区域之外的区域对应的深度值确定为无效深度值,得到清洗后的稠密重建结果。需要说明的是,与上面一样,为了便于后续步骤可以区分无效深度值和有效深度值,可以在确定深度值无效的像素之后,将该像素对应的深度值设置为非数。
127.举例而言,针对图13b所示的第二置信度区域(浅色区域),可以先对第二置信度区域对进行半径为2像素的形态学闭运算,再进行半径为4像素的形态学腐蚀。
128.需要说明的是,为了可以剔除面积小于特定大小的区域,以提高有效深度的可训练性,可以在形态学闭运算后再进行一次面积开运算。举例而言,经过上述形态学闭运算、形态学腐蚀和面积开运算,可以将如图13b所示的第二置信度区域转换为如图14b所示的第四置信度区域(浅色区域)。
129.经过置信度清洗后,可以实现清洗深度值的置信度较低和置信度较高的区域边缘的目的,效果参照图15a(边缘清洗前的深度图像)和图15b(边缘清洗后的深度图像)所示。
130.在一示例性实施例中,在经过上述清洗过后,可以得到清洗之后的稠密重建结果。然而,在深度图像中有效区域的面积占比(有效区域像素数量除以深度图像素数量)过小,
该深度图像中可以用于训练的数据也相对有限。此时,可以根据深度数据生成相对深度数据作为训练数据。具体的,在重建图像中有效深度值对应的面积占比小于第二占比时,可以基于重建图像对应的深度数据生成相对深度数据,然后将重建图像和重建图像对应的相对深度数据作为第一训练数据。
131.在一示例性实施例中,在生成相对深度数据时,如果重建图像中存在大面积的没有重建成功(像素对应的深度值为无效深度值,即像素对应的深度值为非数),且在语义分割图中的语义标签为特定标签(可以包括通常情况下为前景的人物或者动物等标签)的区域,可以假设这些区域为前景区域,并基于该前景区域与原本的深度数据生成相对深度数据。
132.举例而言,假设前景区域的深度要小于有效深度中大小超过75%的区域的静态物体,即当语义分割图显示画面中存在大面积的人物区域,可以假设这个人物区域的深度值要小于比较远的建筑物的深度值。基于这种假设,可以将基于特定标签确定的前景区域和重建图像对应的深度数据,生成包含三个取值,即远、近和无效值的相对深度数据。然后在训练时,基于相对深度数据,通过顺序损失进行训练。由于动态物体很少保持静止,sfm和mvs难以重建这些物体的深度,使用相对深度数据可以在缺乏静态人物数据的情况下让网络利用这种远近约束(即顺序损失)学出大致的远近信息(即大面积人物要比远处建筑物近)。
133.举例而言,参照图16所示,可以通过语义分割对如图16a所示的重建图像进行语义分割得到人物、建筑和天空三种标签(如图16b所示),该重建图像对应的深度图像如图16c所示,然后将任务这种标签对应区域确定为前景区域,即取值为近的区域,然后基于前景区域的深度要小于有效深度中大小超过75%的区域的静态物体的假设和图16c中人物深度和建筑深度确定建筑为取值为远的区域,同时基于上面的清洗过程可以将天空区域的深度值确定为无效深度值,进而得到取值为远、近和无效值的相对深度数据,对应的相对深度图像如图16d所示。
134.特殊地,互联网上存在一种特殊的视频,该视频中的人物会摆出各种各样有趣的姿势,并在原地保持不动,拍摄者需要手持摄像头在场景中进行一镜到底的拍摄,这种视频被称为假人挑战视频,是一种流行网络视频。针对这种视频,由于任人物在视频拍摄过程中保持静止,因此可以通过sfm和mvs算法恢复精确的相机位姿和稠密深度。这种视频中的深度掺杂可以通过以下方式进行消除。
135.具体的,可以先基于语义分割算法对重建图像进行语义分割,以分割出不同的人物区域并标记;然后针对每个人物对应的人物区域对应的深度图像中的区域进行遍历,并获取该区域内的有效深度值,得到该人物区域内的深度值分布直方图;之后根据预设的百分比计算该人物区域对应的深度阈值,并将大于深度阈值的深度值全部滤除,从而消除深度掺杂。
136.举例而言,参照图17所示,对如图17a所示的重建图像进行语义分割,可以得到2个人物区域(如图17b所示),然后参照该人物区域对深度图像(如图17c)中的每个人物区域进行遍历,记录区域内有效点的深度值,得到各人物区域内的深度值分布直方图。此时,假设预设的百分比为75%,假设该人物区域共有100个有效点的深度值,可以基于深度值分布直方图确定100个有效点中,深度值从小到大排列时的第75个有效点的深度值,然后将该深度
值作为深度阈值,并将大于该深度阈值的深度值(如图17d中灰色部分所示)滤除,得到消除深度掺杂的深度图像(如图17e)。例如,在100个点中,有50个深度值为1,有30个深度值2,有20个深度值10,可以确定第75个点的深度值为2,则将大于2的深度值,即深度值为10的部分滤除。
137.以下以非假人挑战视频的2d视频需要进行上述3中清洗为例,参照图18所示,对本公开实施例的技术方案进行详细阐述:
138.步骤s1801,基于稠密重建结果确定的光度一致性深度图像和几何一致性深度图像进行比值判断,得到在一定程度上消除深度掺杂的深度图像;
139.步骤s1803,基于中值滤波算法在稠密重建结果中的深度数据中确定无效深度值和有效深度值,并将无效深度值配置为非数;
140.步骤s1805,对重建图像的深度图像进行语义分割,得到不同语义标签对应的区域;
141.步骤s1807,针对每个标签对应的区域,计算至少一个连通区域;
142.步骤s1809,针对每个连通区域,基于上述无效深度值和有效深度值计算连通区域中无效深度值的占比,在无效深度值占比大于第一占比时,将消除深度掺杂的深度图像中,该连通区域对应的深度值配置为非数(即确定其为无效深度值),得到碎片清洗后的深度图像;其中,针对连通区域中已经被配置为非数的部分,无需重复设定;
143.步骤s1811,基于语义分割算法得到的语义标签,将稠密重建结果确定的重建图像划分为第一置信度区域(低置信度区域)和第二置信度区域(高置信度区域);
144.步骤s1813,基于形态学图像处理对第一置信度区域和第二置信度区域分别进行形态学图像处理得到第三置信度区域和第四置信度区域;
145.步骤s1815,将碎片清洗后的深度图像中,在上述第三置信度区域的深度值配置为非数(即确定其为无效深度值),得到无低置信度区域的深度图像;其中,针对第三置信度区域中已经被配置为非数的部分,无需重复设定;
146.步骤s1817,将无低置信度区域的深度图像中,不在上述第四置信度区域的深度值配置为非数(即确定其为无效深度值),得到清洗后的稠密重建结果。
147.在一示例性实施例中,除了2d视频外,在获取视频集合时,还可能获取到3d视频,即用立体相机拍摄的三维视频。此时,可以基于3d视频生成第二训练数据,该第二训练数据可以作为预训练数据,用于训练一个粗略的初始模型,然后可以基于第一训练数据对初始模型进行进一步训练,得到更加精细的模型。
148.具体的,针对视频集合中的每个3d视频,对该3d视频中的每一视频帧进行双目相机标定和对齐,得到双目图像;然后基于双目图像计算视差图,并将双目图像和基于视差图计算的深度数据作为第二训练数据。
149.举例而言,用立体相机拍摄的3d视频通常可以分解成并排放置的同一时刻拍摄的左右两个视角图像。针对每一帧视频,可以先进行求解双目图像的单应矩阵,然后使用单应矩阵对两个视角图像进行变形,以对齐双目图像,然后基于对齐后的双目图像求解视差图,并将双目图像和基于视差图计算的深度数据作为第二训练数据。
150.其中,在求解单应矩阵时可以采用非标定双目矫正(uncalibrated stereo image rectification)等算法,在求解视差图时可以采用光流网络(比如raft、flownet2)求解视
embedding,tsne)对输出的1024维的特征向量进行降维。
159.tsne是一种数据降维算法,该算法把数据点间的相似度转换成联合概率,并试图最小化低维度和高维度空间中联合概率之间的kl散度(kullback
‑
leibler divergence)。在本实施例中,将1024维的特征向量降维成2维的特征向量。参照图20a和20b,分别显示了两个场景类别的数据集降维后的可视化示意图。其中,图20a为简单场景,包含19287张重建图像;图20b为复杂场景,包含2690张重建图像;
160.之后,使用网格(grid)对每个场景数据集的图像做降采样。
161.具体的,根据该场景标准差选择合适的网格大小,将降维后的特征向量对应的视图按照该网格大小划分区域;在得到划分区域后,在网格划分的每个区域中进行随机采样,知道图像质量满足要求。
162.其中,场景标准差可以表示场景类型的丰富度,并基于该丰富度对不同丰富度的场景类型选择不同的降采样力度。因此,针对每个场景类别可以利用之前得到的1024维特征向量,针对每一位度计算标准差,然后计算所有维度对应标准差的平均数,将计算得到的平均数作为该场景的标准差。
163.其中,根据该场景标准差选择合适的网格大小时,可以提前设定场景标准差与网格大小的对应关系,根据对应关系进行选择。例如,对应关系可以包括:如果标准差小于0.4,则使用3x3网格;如果大于0.4且小于0.45则使用4x4网格;如果标准差大于0.45且小于0.55,则使用16*16网格;如果标准差大于0.55且小于0.65,则使用20*20网格;如果标准差大于0.65则使用24*24网格。
164.基于上述方法对图20a和图20b的数据集进行降采样,得到了如图21a和图21b所示的两个场景类别的数据集降采样后的可视化示意图。其中,简单场景的图像数由图20a中的19287张图像变为图21a中的15张图像;复杂场景的图像数由图20b中的2690张图像变为图21b中的27张图像;简单场景和复杂场景对应的图像数的比例从7.16:1降低为0.55:1,有效均衡了各个场景类型的数据量。
165.需要说明的是,在对重建图像进行降采样后,可以将降采样之后剩余的重建图像和这部分重建图像对应的深度数据作为第一训练数据。
166.以下参照图22所示,以视频集合同时包括2d视频和3d视频为例,对本公开实施例的技术方案进行详细阐述:
167.步骤s2201,基于网络爬虫在流媒体中爬取视频集合;视频集合中包括2d视频和3d视频;
168.步骤s2203,对各2d视频进行帧筛选得到各2d视频对应的跟踪帧序列;
169.步骤s2205,对跟踪帧序列进行稀疏三维重建,得到稀疏重建结果;
170.步骤s2207,基于运动轨迹连续性对稀疏重建结果进行筛选,得到筛选后的稀疏重建结果;
171.步骤s2209,基于筛选后的稀疏重建结果进行稠密三维重建,得到稠密重建结果;
172.步骤s2211,基于语义分割算法对稠密重建结果进行清洗,得到清洗后的稠密重建结果;
173.步骤s2213,基于清洗后的稠密重建结果确定重建图像和重建图像对应的深度数据,得到第一训练数据;
174.步骤s2215,对第一训练数据中的重建图像进行降采样,得到降采样后的重建图像,将降采样后的重建图像和降采样后的重建图像对应的深度数据确定为降采样后的第一训练数据;
175.步骤s2217,对各3d视频中的每一视频帧进行双目相机标定和对齐,得到双目图像;
176.步骤s2219,基于双目图像计算视差图,并基于视差图计算双目图像对应的深度数据;
177.步骤s2221,基于双目图像和双目图像对应的深度数据确定为第二训练数据;
178.步骤s2223,对第二训练数据中的双目图像进行降采样,得到降采样后的双目图像,将降采样后的双目图像和降采样后的双目图像对应的深度数据确定为降采样后的第二训练数据。
179.综上,本示例性实施方式中,通过网络爬虫可以获取无限多不同场景类型的视频;基于预设跟踪条件对视频进行帧筛选,可以高效地过滤不适合三维重建的视频帧,得到适合进行稀疏三维重建的跟踪序列帧;随后为了减少稠密重建的耗时,在稀疏重建后,通过运动轨迹连续性对稀疏重建结果的筛选,可以剔除不适合进行稠密重建的跟踪帧序列,进而生成第一训练数据;此外,使用互联网上的3d视频进行双目立体匹配能低成本获取场景丰富的,用于进行预训练的第二训练数据。之后,为了消除不同场景类型数据量差别大造成的模型偏移效应,通过降采样的方式对第一训练数据和第二训练数据分别进行自适应降采样,使得各种场景类型的数据量更加均衡。特殊地,在采集到3d假人挑战数据时,通过对人物的分割可以生成包含人物的场景类型丰富的训练数据。
180.需要注意的是,上述附图仅是根据本公开示例性实施例的方法所包括的处理的示意性说明,而不是限制目的。易于理解,上述附图所示的处理并不表明或限制这些处理的时间顺序。另外,也易于理解,这些处理可以是例如在多个模块中同步或异步执行的。
181.进一步的,参考图23所示,本示例的实施方式中还提供一种训练数据的生成装置2300,包括视频获取模块2310,数据筛选模块2320和数据生成模块2330。其中:
182.视频获取模块2310可以用于获取视频集合;视频集合中包括至少一个2d视频。
183.数据筛选模块2320可以用于基于预设跟踪条件对各2d视频进行帧筛选,得到各2d视频对应的跟踪帧序列。
184.数据生成模块2330可以用于基于各跟踪帧序列进行三维重建,得到重建图像和重建图像对应的深度数据,并将重建图像和重建图像对应的深度数据作为第一训练数据。
185.在一示例性实施例中,数据筛选模块2320可以用于针对每一个2d视频分别进行帧筛选处理,帧筛选处理包括:基于预设步长在2d视频中抽取第i个视频帧;其中i取正整数;在第i个视频帧满足预设跟踪条件时,将第i个视频帧加入视频子序列,并继续基于预设步长抽取第i 1个视频帧;在第i个视频帧不满足预设跟踪条件时,将第i个视频帧之前的视频帧生成的视频子序列确定为2d视频对应的跟踪帧序列。
186.在一示例性实施例中,预设跟踪条件包括以下条件中的一种或多种的组合:视频帧中的特征点数量大于数量阈值、视频帧对应的光流匹配向量的平均模长小于模长范围的最大值、视频帧对应的内点数量大于内点阈值,以及视频帧对应的帧间旋转角小于角度阈值。
187.在一示例性实施例中,数据筛选模块2320可以用于在视频子序列的帧数小于最低阈值时,确定2d视频帧对应的跟踪帧序列为空;在视频子序列的帧数大于或等于最低阈值时,确定视频子序列为2d视频帧对应的跟踪帧序列。
188.在一示例性实施例中,数据生成模块2330可以用于基于各跟踪帧序列进行稀疏三维重建,得到稀疏重建结果;基于稀疏重建结果进行稠密三维重建,得到稠密重建结果;基于稠密重建结果确定重建图像和重建图像对应的深度数据。
189.在一示例性实施例中,数据生成模块2330可以用于获取稀疏重建结果中各稀疏点对应的坐标和稀疏深度值;以稀疏深度值为坐标对应的初始深度值进行稠密三维重建,得到稠密重建结果。
190.在一示例性实施例中,数据筛选模块2320可以用于基于运动轨迹连续性对稀疏重建结果进行筛选,得到筛选后的稀疏重建结果,以基于筛选后的稀疏重建结果进行稠密三维重建。
191.在一示例性实施例中,数据筛选模块2320可以用于基于语义分割算法对稠密重建结果进行清洗,获取清洗后的稠密重建结果,以基于清洗后的稠密重建结果确定重建图像和重建图像对应的深度数据。
192.在一示例性实施例中,数据筛选模块2320可以用于通过语义分割算法在稠密重建结果确定的深度图像中确定第一区域;基于预设算法对第一区域进行处理,以消除第二区域对第一区域的深度掺杂,得到清洗后的稠密重建结果;其中,第二区域的深度大于第一区域。
193.在一示例性实施例中,数据筛选模块2320可以用于基于中值滤波算法在稠密重建结果中的深度数据中确定无效深度值和有效深度值;通过语义分割算法在稠密重建结果确定的深度图像中确定连通区域;基于无效深度值和有效深度值计算连通区域对应的无效占比;在无效占比大于第一占比时,将连通区域对应的深度值确定为无效深度值,得到清洗后的稠密重建结果。
194.在一示例性实施例中,数据筛选模块2320可以用于通过语义分割算法对稠密重建结果确定的重建图像进行语义分割,得到语义分割图像;基于置信度分类方法对语义分割图像包含的语义标签进行分类,以通过语义分割图像将稠密重建结果确定的重建图像划分为第一置信度区域和第二置信度区域;其中,第一置信度区域的置信度低于第二置信度区域的置信度;对第一置信度区域进行形态学膨胀处理,以获取膨胀后的第三置信度区域,并将第三置信度区域对应的深度值确定为无效深度值;对第二置信度区域进行形态学收缩处理,以获取收缩后的第四置信度区域,并将第四置信度区域之外的区域对应的深度值确定为无效深度值,得到清洗后的稠密重建结果。
195.在一示例性实施例中,数据生成模块2330可以用于在重建图像中有效深度值对应的面积占比小于第二占比时,基于重建图像对应的深度数据生成相对深度数据;将重建图像和重建图像对应的相对深度数据作为第一训练数据。
196.在一示例性实施例中,数据筛选模块2320可以用于对第一训练数据进行数据降采样,以获取降采样后的第一训练数据。
197.在一示例性实施例中,视频集合还包括至少一个3d视频时,数据生成模块2330可以用于针对各3d视频中的每一视频帧进行双目相机标定和对齐,得到双目图像;基于双目
图像计算视差图,并将双目图像和基于视差图计算的深度数据作为第二训练数据。
198.在一示例性实施例中,数据筛选模块2320可以用于对第二训练数据进行数据降采样,以获取降采样后的第二训练数据。
199.上述装置中各模块的具体细节在方法部分实施方式中已经详细说明,未披露的细节内容可以参见方法部分的实施方式内容,因而不再赘述。
200.所属技术领域的技术人员能够理解,本公开的各个方面可以实现为系统、方法或程序产品。因此,本公开的各个方面可以具体实现为以下形式,即:完全的硬件实施方式、完全的软件实施方式(包括固件、微代码等),或硬件和软件方面结合的实施方式,这里可以统称为“电路”、“模块”或“系统”。
201.本公开的示例性实施方式还提供了一种计算机可读存储介质,其上存储有能够实现本说明书上述方法的程序产品。在一些可能的实施方式中,本公开的各个方面还可以实现为一种程序产品的形式,其包括程序代码,当程序产品在终端设备上运行时,程序代码用于使终端设备执行本说明书上述“示例性方法”部分中描述的根据本公开各种示例性实施方式的步骤,例如可以执行图3至图4、图11至图12、图18、图22中任意一个或多个步骤。
202.需要说明的是,本公开所示的计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质或者是上述两者的任意组合。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子可以包括但不限于:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机访问存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd
‑
rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。
203.在本公开中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本公开中,计算机可读信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、电线、光缆、rf等等,或者上述的任意合适的组合。
204.此外,可以以一种或多种程序设计语言的任意组合来编写用于执行本公开操作的程序代码,程序设计语言包括面向对象的程序设计语言—诸如java、c 等,还包括常规的过程式程序设计语言—诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任意种类的网络,包括局域网(lan)或广域网(wan),连接到用户计算设备,或者,可以连接到外部计算设备(例如利用因特网服务提供商来通过因特网连接)。
205.本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其他实施例。本技术旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者
适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由权利要求指出。
206.应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
