1.本发明属于区块链技术领域,更为具体地讲,涉及一种区块链的可扩展共识方法。
背景技术:
2.区块链根据权限控制不同,一般分为三类:私有链,公有链和联盟链。私有链只对单独的个体或组织开放,如企业内部使用。公有链对所有人开放,链上的所有节点可随时加入或退出。目前在公有链系统中,默认所有参与节点不可信,故采用pow(proof of work)等bft算法解决分布式共识问题,其代价是海量计算导致共识速度缓慢、系统吞吐量下降。典型代表如bitcoin,受其选取的pow共识算法限制,平均出块时长为10分钟,tps仅为7。是选择了去中心化和安全性而牺牲性能的典型代表之一。相比之下,联盟链增加了准入机制弱化了去中心化特性。典型代表如hyperledger fabric,所有参与者均需通过ca认证才能相互通信。这样的优势在于,整个系统原则上无恶意节点,故可以委托某可信服务负责出块,相比于公链可以极大缩短共识时间,提高了性能。同时,为了保证系统容错性,联盟链的共识服务也支持多实例同时运行:其共识服务的实现通过paxos/raft等协议选举leader,由leader实际负责将交易打包形成区块。虽然联盟链的交易速度天然要比公链快,但单个leader串行出块的扩展性不佳,不能支持高并发事务系统。
3.联盟链排序服务主要功能是将client接收到的交易进行排序后打包出块,其流程为:管理系统通道和应用通道、维护通道账本和配置、提供broadcast广播服务接收交易,启动对应的orderer共识排序服务打包出块、deliver区块分发服务处理区块请求、orderer从本地账本中返回请求范围内的区块数据。
4.现有的联盟链在排序服务阶段使用的共识服务技术通常为solo、kafka、raft等共识算法,solo算法只适用于测试环境。kafka算法因配置繁琐与额外的管理开销等原因逐渐被弃用。默认采用的raft共识算法有着复杂的选举机制,增加了系统开销。联盟链在排序服务阶段主要功能是将交易进行排序并打包成块。raft共识算法是严格的单个leader打包区块,多个follower参与共识的算法。单个节点串行化出块会造成事务阻塞,严重降低了系统性能。
5.在联盟链排序服务中,不同的通道单独运行一套raft协议的示例,该协议允许每个实例选择不同的leader。通道的创建者和通道管理员能够选择当前系统中可用排序节点的子集,并根据需要添加或删除排序节点(暂不支持一次增删多个节点)。如其工作流程如下:
6.1)client给orderer发送交易,所有交易根据判断是配置交易还是普通交易转发给raft集群中的leader节点进行相应处理。
7.2)如果当前的orderer是leader节点,对交易进行打包出块。普通交易根据区块容量和超时时间进行打包出块,对于配置交易单独出块。如果orderer不是leader节点,则会通过rpc转发给leader节点。
8.3)leader节点将打包好的区块传递给底层的raft状态机,将该日志广播给其他的
follower节点,收到半数以上的节点响应,leader节点提交该日志,区块被写入本地账本。
9.然而,现有的raft算法raft是基于cft的共识算法,为了达到分布式一致性,当出现1个orderer故障时,系统需要保证存在至少3个可用节点才能正常工作,如果leader节点故障,系统还需要重新进行leader选举,candidate节点将选举信息广播给所有节点,需获得半数以上的投票才能选举成功。并且leader节点需要定期发送心跳消息给其他节点证明自己存活。其复杂的选举机制增加了额外开销,影响系统性能。其次,raft算法的排序服务中区块的打包出块环节实质上只由leader节点负责,无法实现并行化出块,在高并发系统中,leader节点的负载也会成为排序服务的性能瓶颈。
技术实现要素:
10.本发明的目的在于克服现有技术的不足,提供一种区块链的可扩展共识方法,基于dht的一致性哈希理论,将所有交易通过dht算法路由到环中具体的节点进行处理,环中所有的排序节点再独立进行打包出块,实现多节点并行化出块,这样解决现有的区块链共识方法在实现上造成的系统开销、串行化出块上存在的问题和不足。
11.为实现上述发明目的,本发明一种区块链的可扩展共识方法,其特征在于,包括以下步骤:
12.(1)、启动dht
‑
orderer服务并初始化配置;
13.启动dht
‑
orderer服务,将参与排序的dht节点通过哈希算法形成一个二进制数组hash_node,每个dht节点通过hash_node加入到dht
‑
orderer的哈希环中;
14.通过写入配置文件方式对区块推荐容量preferredsize和区块最大容量preferredmaxsize、区块容纳交易最大数量maxmessagecount、区块超时时间batchtimeout进行初始化;
15.(2)、定义区块结构并初始化;
16.区块结构分为:区块头与数据域;区块头又包含previoushash、number、datahash三个字段,其中,previoushash用于记录了当前区块在区块链中的上一个区块的哈希值,初始化为空;区块高度number用于记录当前区块在区块链中的顺序,初始化为0;datahash记录了本区块在区块链中的哈希值,初始化为空;数据域用于记录该区块包含的所有的交易消息,初始化为空;
17.(3)、选举mainnode节点;
18.通过一致性哈希算法定位dht环中key=0的后继节点,将该节点选举为主节点mainnode;mainnode节点包含lastblockhash与blocknum两个字段,其中,lastblockhash字段赋值为区块链中最后一个区块的哈希值datahash,blocknum字段赋值为区块链中最后一个区块的区块高度number;
19.(4)、消息预处理;
20.接收从客户端发来的交易消息tx,先通过过滤器进行过滤处理,将交易消息tx超过区块最大容量preferredmaxsize过滤掉,再进入步骤(5);
21.(5)、交易路由;
22.经过预处理后的交易消息tx通过哈希算法映射到由排序节点组成的哈希环,通过查询本地排序节点的路由表,得到该交易的后继节点的地址,如果本地节点未记录后继节
点地址,在本地的路由表中找到距离后继节点最近的节点closenode,远程连接该节点,再通过迭代方式查询closenode的路由表中的后继节点,并记录后继节点地址,再进入步骤(6);
23.(6)、通过步骤(5)得到的地址,将交易消息tx转发给相应的排序节点,并对交易消息tx进行区块打包;
24.(6.1)、设置缓存pendingbatch,初始化为空;为缓存pendingbatch设置一个计时器timer,初始化为0,当缓存清空时,启动计时器;
25.(6.2)、定义区块打包法;
26.将缓存中的所有交易打包并作为返回值写入到区块的数据域,使用哈希算法对区块的数据域输出定长数组,再将该数组的长度值作为当前区块的哈希值,在datahash字段中进行填充,从而生成包含多条交易消息的一个区块;区块打包完成后,将打包后的区块转发给mainnode;
27.(6.3)、将预处理后的交易消息tx通过dht的一致性哈希算法路由到指定的dht节点,判断计时器timer的值是否到达预设的超时时间batchtimeout,如果达到,则按照步骤(6.2)所述方法进行区块打包并转发给mainnode,然后重置计时器,清空缓存,并跳转至步骤(7);否则,进入步骤(6.4);
28.(6.4)、判断当前的交易消息tx的大小messagesize是否大于区块打包的推荐容量preferredsize,如果messagesize>preferredsize,则进一步判断缓存是否为空,如果缓存为空,则再按照步骤(6.2)所述方法进行区块打包并转发给mainnode,然后重置计时器,清空缓存,并跳转至步骤(7);如果缓存不为空,则按照步骤(6.2)所述方法将缓存中的所有交易打包为一个区块转发给mainnode,然后重置计时器,清空缓存,并跳转至步骤(7);如果不满足messagesize>preferredsize,进入步骤(6.5);
29.(6.5)、判断当前的交易消息tx的大小messagesize与当前缓存大小pendingbatchsizebytes之和是否大于最大容量preferredmaxsize,如果超过了最大容量,则按照步骤(6.2)所述方法进行区块打包并转发给mainnode,然后重置计时器,清空缓存,并跳转至步骤(7);否则,进入步骤(6.6);
30.(6.6)、将当前的交易消息tx存放到缓存pendingbatch中,新的缓存大小pendingbatchsizebytes为未加入当前交易的缓存大小pendingbatchsizebytes与当前的普通交易tx的大小messagesizebytes之和;然后判断缓存中的交易消息tx的个数是否超过区块容纳交易最大数量maxmessagecount,如果超过,执行步骤(6.2),按照步骤(6.2)所述方法进行区块打包并转发给mainnode,然后重置计时器,清空缓存,并跳转至步骤(7);
31.(7)、mainnode依次对接收的区块进行更新;
32.(7.1)、mainnode节点收到区块后,读取该区块的number字段和previoushash字段,再通过mainnode本地的blocknum和lastblockhash字段对该区块的区块高度number与上一个区块的哈希值previoushash进行赋值操作,然后进入步骤(7.2);
33.(7.2)、mainnode更新本地的lastblockhash和blocknum字段,其中,lastblockhash更新为该区块的哈希值datahash,blocknum更为blocknum加1;从而完成该区块的更新操作;
34.(7.3)、当mainnode收到下一个区块时,循环执行步骤(7.1)
‑
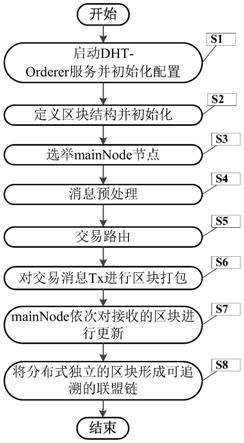
(7.2),直到最后一个
区块更新完成,然后进入步骤(8);
35.(8)、mainnode将更新完毕的区块写入本地账本,最终将分布式独立的区块形成可追溯的区块链。
36.本发明的发明目的是这样实现的:
37.本发明一种区块链的可扩展共识方法,通过dht路由思想,将所有的排序节点映射到哈希环,利用一致性哈希算法将交易tx路由到指定区块,以此实现区块的并行化出块。同时,为了保证并行化出块的区块顺序一致性。在哈希环中排序节点选举一个主节点mainnode负责将所有区块编号。使用单个节点mainnode对区块进行排序保证分布式出块的区块顺序一致性。使得区块打包具有非常好的扩展性和灵活性,符合当今企业级区块链应用的需求。
38.同时,本发明一种区块链的可扩展共识方法还具有以下有益效果:
39.(1)、本发明基于dht
‑
orderer中的一致性哈希原理,主节点mainnode由哈希环上的资源key=0所路由到的节点当选,这是由算法本身所天然达成的共识,不需要多余的选举与心跳机制。并且主节点可动态退出,退出后的主节点由下一个key=0所映射的节点当选。
40.(2)、dht算法通过定位收到的交易信息所属节点,在该节点进行打包操作,真正实现了节点的分布式出块。并且在所实现的dht
‑
orderer中,支持节点动态加入和退出,系统容错性增强。
41.(3)、本发明基于dht的一致性哈希理论,所有交易和排序节点都可通过哈希算法映射环中,交易通过dht算法路由到环中具体的节点进行处理。因此,环中所有的排序节点均可独立进行打包出块工作,实现多节点并行化出块。
附图说明
42.图1是本发明一种区块链的可扩展共识方法流程图;
具体实施方式
43.下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
44.实施例
45.在本实施例中,如图1所示,一种区块链的可扩展共识方法,包括以下步骤:
46.s1、启动dht
‑
orderer服务并初始化配置;
47.在本实施例中,系统命名为dht
‑
orderer,启动该服务,通过写入配置文件方式对区块推荐容量preferredsize和区块最大容量preferredmaxsize、区块容纳交易最大数量maxmessagecount、区块超时时间batchtimeout进行初始化;
48.s2、定义区块结构并初始化;
49.区块结构分为:区块头与数据域;区块头又包含previoushash、number、datahash三个字段,其中,previoushash用于记录了当前区块在区块链中的上一个区块的哈希值,初始化为空;区块高度number用于记录当前区块在区块链中的顺序,初始化为0;datahash记
录了本区块在区块链中的哈希值,初始化为空;数据域用于记录该区块包含的所有的交易消息,初始化为空;
50.s3、选举mainnode节点;
51.在本实施例中,将参与排序的dht节点加入dht
‑
orderer的哈希环中,每个dht节点通过哈希算法形成一个二进制数组hash_node,每个dht节点通过hash_node在环中一一对应;
52.通过一致性哈希算法定位dht环中key=0的后继节点,将该节点选举为mainnode节点;mainnode节点包含lastblockhash与blocknum两个字段,其中,lastblockhash字段赋值为区块链中最后一个区块的哈希值datahash,blocknum字段赋值为区块链中最后一个区块的区块高度number;
53.s4、消息预处理;
54.客户端发起交易消息tx,通过哈希算法得到交易的哈希值hash_tx;dht
‑
orderer接收交易消息tx,然后通过过滤器进行过滤处理,将交易消息tx超过区块最大容量preferredmaxsize过滤掉,交易消息tx通过哈希算法映射到由排序节点组成的哈希环上,进入步骤s5;
55.s5、交易路由;
56.每个哈希环中的排序节点本地维护一张路由表,记录一部分哈希值的后继节点,当本地的排序节点接收到交易消息tx时,通过查询本地路由表寻找交易的哈希值hash_tx的后继节点,如交易消息tx的后继节点为本地节点进入步骤s5.1,否则,进入步骤s5.2。
57.s5.1、在本地节点进行区块打包;
58.s5.2、查询本地节点的路由表中是否记录了交易消息tx的后继节点。如有,将交易消息tx通过路由表记录的节点地址转发给该后继节点进行区块打包工作。如没有,进入步骤s5.3;
59.s5.3、在本地的路由表中找到距离后继节点最近的节点closenode,远程连接该节点,返回步骤s5.2查询closenode的路由表中是否记录后继节点。直到找到该后继节点。
60.s6、对交易消息tx进行区块打包;
61.s6.1、设置缓存pendingbatch,初始化为空;为缓存pendingbatch设置一个计时器timer,初始化为0,当缓存清空时,启动计时器;
62.s6.2、定义区块打包法;
63.将缓存中的所有交易打包并作为返回值写入到区块的数据域,使用哈希算法对区块的数据域输出定长数组,再将该数组的长度值作为当前区块的哈希值,在datahash字段中进行填充。生成包含多条交易消息的一个区块。区块打包完成,将打包后的区块转发给mainnode;
64.s6.3、将预处理后的交易消息tx通过dht的一致性哈希算法路由到指定的dht节点,判断计时器timer的值是否到达预设的超时时间batchtimeout,如果达到,则按照步骤s6.2所述方法进行区块打包并转发给mainnode,然后重置计时器,清空缓存,并跳转至步骤s7;否则,进入步骤s6.4;
65.s6.4、判断当前的交易消息tx的大小messagesize是否大于区块打包的推荐容量preferredsize,如果messagesize>preferredsize,则进一步判断缓存是否为空,如果缓
存为空,则再按照步骤s6.2所述方法进行区块打包并转发给mainnode,然后重置计时器,清空缓存,并跳转至步骤s7;如果缓存不为空,则按照步骤(6.2)所述方法,先将缓存中的所有交易打包为一个区块,再将当前的交易消息tx打包成另一个区块,最后将两个区块转发给mainnode,,然后重置计时器,清空缓存,并跳转至步骤s7;如果不满足messagesize>preferredsize,进入步骤s6.5;
66.s6.5、判断当前的交易消息tx的大小messagesize与当前缓存大小pendingbatchsizebytes之和是否大于最大容量preferredmaxsize,如果超过了最大容量,则按照步骤s62所述方法进行区块打包并转发给mainnode,然后重置计时器,清空缓存,并跳转至步骤s8;否则,进入步骤s6.6;
67.s6.6、将当前的交易消息tx存放到缓存pendingbatch中,新的缓存大小pendingbatchsizebytes为未加入当前交易的缓存大小pendingbatchsizebytes与当前的交易消息tx的大小messagesizebytes之和;然后判断缓存中的交易消息tx的个数是否超过区块容纳交易最大数量maxmessagecount,如果超过,执行步骤s6.2,按照步骤s6.2所述方法进行区块打包并转发给mainnode,然后重置计时器,清空缓存,并跳转至步骤s8;
68.s7、mainnode依次对接收的区块进行更新;
69.s7.1、mainnode节点收到区块后,读取该区块的number字段和previoushash字段,再通过mainnode本地的blocknum和lastblockhash字段对该区块的区块高度number与上一个区块的哈希值previoushash进行赋值操作,然后进入步骤s7.2;
70.s7.2、mainnode更新本地的lastblockhash和blocknum字段,其中,lastblockhash更新为该区块的哈希值datahash,blocknum更为blocknum加1;从而完成该区块的更新操作;
71.s7.3、当mainnode收到下一个区块时,循环执行步骤s7.1
‑
s7.2,直到最后一个区块更新完成,然后进入步骤s8;
72.s8、mainnode将更新完毕的区块写入本地账本,最终将分布式独立的区块形成可追溯的区块链。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
