1.本发明设计事件检测方法,具体来讲是一种基于图片和句子的多模态联合事件检测的方法,属于多模态信息抽取领域。
背景技术:
2.随着电脑、手机等现代科技逐渐走入寻常百姓家,参与社交平台互动、浏览新闻网站等行为已成为人们获取网络信息的主要途径,这也极大简化了网民获取信息的流程。随之而来的是消费信息的网络用户不断增加,据中国互联网络信息中心发布的第47次《中国互联网络发展状况统计报告》1显示,截至2020年12月,中国网民人数达到98900万,相较于去年3月份,网民人数增加了8540万人。因此,每天都会有大量新的信息涌入网络,这些信息通常以文本、图片、音频等多种形式在大众之间进行传播。在面对如此海量且杂乱无章的网络信息时,信息抽取技术能对数据进行处理,并将结构化的信息展示给用户,从而准确地为用户提供有价值、感兴趣的信息。
3.信息抽取是为了从图片、文本或音频中抽取出结构化的信息,进行存储和展示,同时也是构建知识图谱的重要技术手段,通常由命名实体识别、关系抽取和事件抽取三个子任务构成。以文本为例,命名实体识别任务是为了发现描述地缘政治、设施、人名的实体。关系抽取任务的目的是确定两个实体之间的二元语义关系。而事件抽取任务包括事件检测(找出句中的触发词,并确定它们的事件类型)和论元识别(为每个参与事件的实体分配论元角色)两个环节。相比关系抽取,事件抽取任务能够同时抽取多实体间的相互关系,从而获得更加细粒度的结构化信息。因此,事件抽取任务更具挑战性。
4.事件检测是事件抽取任务的重要环节,该环节可以识别出标志着事件发生的图片动作和文本触发词,并将其分类为预定义的事件类型。在网络舆情分析、情报收集等领域有着广泛的应用。
技术实现要素:
5.本发明主要针对于图片或句子等单模态数据提供的信息往往不足以进行正确的事件分类,通常需要借助于其他模态的特征信息。提出了一种基于图片和句子的多模态联合事件检测方法,同时从图片和句子中识别事件。提出的一种基于图片和句子的多模态联合事件检测的方法。
6.基于图片和句子的多模态联合事件检测的方法,按照如下步骤进行:
7.步骤1、文本事件检测模块首先对文本特征进行编码,获取句中单词的特征表示序列对于第j个候选触发词,然后将其对应的特征向量输入文本事件分类器softmax
t
,获取第j个候选触发词触发的事件类型概率分布,其中,文本事件分类器的损失函数定义为l
t
;
8.步骤2、对图片特征进行编码,获取图片中描述动作以及多个实体的特征表示序列然后将图片实体特征向量输入图片事件分类器softmax
i
,获取当
前图片描述的事件类型概率分布,其中,图片事件分类器的损失函数定义为l
i
;
9.步骤3、图片句子匹配模块首先利用跨模态注意力机制(cross
‑
modal attention mechanism,cmam)计算每一对图片实体与单词之间的关联权值。根据第j个单词,cmam能够定位重要的图片实体并分配权重,通过加权平均聚合与单词相关的视觉特征,获取单词在图片模态的特征表示另一方面,对于图片中的第i个实体,首先在待匹配的句子中搜索相关的单词,并为它们分配权重,通过加权平均捕获与图片实体相关的语义信息,从而获取图片实体在文本模态的特征表示然后将每个句子与其在图片模态中的特征表示序列的欧氏距离d
t
←
i
以及图片中所有实体与其在文本模态中的特征表示序列的欧氏距离d
i
←
t
进行相加,作为图片和句子的相似度。其中,图片句子匹配模块的损失函数定义为l
m
;
10.步骤4、通过联合优化文本事件检测模块、图片事件检测模块以及图片句子匹配模块,从而获取共享事件分类器;
11.步骤5、在测试阶段,对于多模态文本,首先利用图片句子匹配模块找出相似度最高的图片和句子,并获取第i个图片实体在文本模态的特征表示以及第j个单词在图片模态的特征表示然后利用门控注意力机制为图片实体特征向量和分配权重,通过加权平均获取第i个图片实体对应的多模态特征向量,接着利用共享事件分类器获取图片描述的事件类型。同样,利用另外一个门控注意力机制为和分配权重,通过加权平均获取第j个单词的多模态特征表示,接着利用共享事件分类器获取第j个单词触发的事件类型;
12.进一步的,步骤1具体实现如下:
[0013]1‑
1.在kbp 2017英文数据集上训练文本事件分类器,首先对标注数据进行预处理,获取实体类型、事件触发词、实体关系,其中,一共5种实体类型,18种事件类型,然后利用stanford corenlp对原始文本进行分句、分词,获取词性和句子的语法依存结构。并分别创建词性向量表、实体类型向量表,其中每一种向量表都有类型“空”对应的初始化向量。
[0014]1‑
2.查询预训练的glove词向量矩阵,获取句子中每个词的词向量w
emd
,然后查询词性向量表得到词性向量w
pos
和查询实体类型向量表得到实体类型向量w
entity
,每个词的实值向量x={w
emd
,w
pos
,w
entity
},因此句子实值向量序列表示为w={x1,x2,...,x
n
‑1,x
n
},其中n是句子的长度。
[0015]1‑
3.将句子实值向量序列w={x1,x2,...,x
n
‑1,x
n
}作为bi
‑
lstms的输入,获取句子的隐含状态向量序列构建基于句子语法依存结构的图卷积网络,接着将h
l
输入gcns中,获取句子的卷积向量序列最后利用注意力计算序列h
t
中的每个元素对候选触发词的影响权重,从而获取句子的编码序列同时将c
t
作为单词序列在公共空间的特征表示序列。
[0016]1‑
4.将句子中的每个单词视为候选触发词,对于第j(j≤n)个候选触发词,然后将其对应的特征向量输入文本事件分类器:
[0017]
[0018][0019]
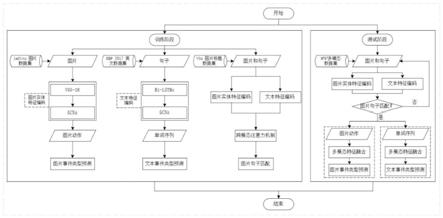
其中,w
t
和b
t
作为文本事件分类器softmax
t
的权重矩阵和偏置项,表示句子s中第j个候选触发词w
j
触发的事件类型概率分布,而type
w,j
表示w
j
触发的事件类型。同时,文本事件分类器的损失函数定义为:
[0020][0021]
其中,t是kbp 2017英文数据集中标注的句子数量,作为单词w
j
标注的事件类型,s
i
表示数据集中第i个句子,句子长度为n。
[0022]
进一步的,步骤2具体实现如下:
[0023]2‑
1.在imsitu图片数据集上训练图片事件分类器,其中,一共定义了504个动词记录图片描述的动作,以及11538种实体类型描述图片中出现的实体。首先利用vgg16
v
去提取图片中的动作特征,并利用多层感知机mlp
v
将动词特征转换成动词向量同时,利用另外一个vgg16
o
提取图片中的实体集合o={o1,o2,...,o
m
‑1,o
m
},然后通过多层感知机mlp
o
将所有实体转换成它们对应的名词向量序列然后用网状结构表示每张图片,根据其描述的动作和实体构建网状结构。其中,图片描述的动作作为网状结构的中心节点,同时将实体与动作节点进行连接。接着采用图卷积网络对图片特征对应的单词向量序列进行编码,从而使得动作节点卷积计算后的向量保存实体特征信息。其中,编码后的图片实体特征向量序列为其中,用来表示图片动作节点的卷积向量(为了方便计算,本发明将图片动作视为一个图片实体),同样,h
i
被视图片动作以及实体集合在公共空间的特征表示序列。
[0024]2‑
2.将图片i中动作卷积向量作为图片事件分类器的输入,获取图片描述事件类型的概率分布为:
[0025][0026][0027]
其中,w
i
和b
i
作为图片事件分类器softmax
i
的权重矩阵和偏置项,p(y
i
|i)表示图片i触发的事件类型概率分布,而type
i
表示图片i中描述的事件类型。同时,图片事件分类器的损失函数定义为:
[0028][0029]
其中,n代表着imsitu中图片标注事件样例的个数,y
i
作为图片i
i
标注的事件类型,i
i
表示图片数据集中第i个图片样例。
[0030]
进一步的,步骤3具体实现如下:
[0031]3‑
1.图片句子匹配模块是为了从包含多张图片和多个句子的多模态文档中找出语义相似度最高的图片和句子。首先利用跨模态注意力机制计算每一对图片实体与单词之间的关联权值,学习基于单词的图片实体特征表示和基于图片实体的单词特征表示。更具
体地说,根据每个单词,cmam能够定位重要的图片实体并分配权重,通过加权平均聚合与单词相关的视觉特征,获取单词在图片模态的特征表示。另一方面,对于图片中的每个实体,首先在待匹配的句子中搜索相关的单词,并为它们分配权重,通过加权平均捕获与图片实体相关的语义信息,从而获取图片实体在文本模态的特征表示。给出图片i对应的实体特征向量序列以及句子s的单词特征向量序列首先利用跨模态注意力机制获取单词和图片实体在其他模态的特征表示。
[0032]3‑
2.为了获取基于单词的图片实体特征表示,首先利用跨模态注意力机制计算图片中第i个实体与第j单词的关联程度score
ij
:
[0033][0034][0035]
其中,表示图片中第i个实体的特征向量与第j单词的特征能量的余弦相似度,值域为[0,1]。然后根据score
ij
,计算第i个图片实体对第j单词的影响权重a
ij
为:
[0036][0037]
最后,通过加权平均的方式聚合基于第j个单词的图片实体特征表示因此,本发明用表示整个句子在图片模态的特征表示序列。
[0038]3‑
3.为了获得基于图片实体的单词特征表示,采用和获取向量相同的计算过程,对于图片中第i个实体,根据第j个单词与当前图片实体的相关性,为第j个单词分配注意力权重:
[0039][0040][0041]
然后,通过加权平均捕获基于图片第i个实体的单词特征表示:
[0042][0043]
同样,图片中所有实体在文本模态的表示为:
[0044][0045]3‑
4.为了获取图片与句子的语义相似度,采用弱一致性的对齐方式,将图片和句子的相似度定义为图片中所有实体与其在文本模态中的特征表示序列的欧氏距离,以及每
个句子与其在图片模态中的特征表示序列的欧氏距离之和。
[0046]
首先,计算每个句子与其在图片模态中的特征表示序列的欧氏距离:
[0047][0048]
然后图片中所有实体与其在文本模态中的特征表示序列的欧氏距离为:
[0049][0050]
因此,图片i和句子s的语义相似度定义为<i,s>=d
t
←
i
d
i
←
t
。最后,为了获取语义相似度最高的图片句子对<i,s>,然后使用triplet loss优化图片句子匹配模块。对于每一对正确匹配的图片和句子,本发明额外抽取一个与句子s不匹配的图片i
‑
,以及一个与图片i不匹配的句子s
‑
,构成两个否定对<i,s
‑
>和<i
‑
,s>。最后图片句子匹配模块的损失函数定义为:
[0051]
l
m
=max(0,1 <i,s>
‑
<i,s
‑
>) max(0,1 <i,s>
‑
<i
‑
,s>)
ꢀꢀ
(15)
[0052]
进一步的,步骤4具体实现如下:
[0053]4‑
1.为了获取共享权重和偏置项的事件分类器,本发明将单词和图片动作在公共空间的特征表示分别作为文本和图片事件分类器的输入,最后通过最小化目标函数l=l
t
l
i
l
m
,对模型进行联合优化。使文本事件分类器softmax
t
和图片事件分类器softmax
i
能够共享权重矩阵和偏置项。从而,在测试阶段,利用共享事件分类器同时预测图片和句子描述的事件类型。
[0054]
进一步的,步骤5具体实现如下:
[0055]5‑
1.利用m2e2多模态标注数据对训练好的模型进行测试,对于包含k个句子s1,s2...,s
k
‑1,s
k
和l张图片i1,i2...,i
l
‑1,i
l
的文章,首先利用图片句子匹配模块找出语义相似度最高的图片句子对<i,s>,同时获取基于图片实体的单词特征表示序列h
i
←
t
、以及基于单词的图片实体特征表示序列h
t
←
i
。
[0056]5‑
2.在特征融合时,对于单词w
j
,本发明认为和对触发词w
j
的事件类型预测贡献不同程度的特征信息。因此,本发明利用门控注意力机制为不同的特征信息分配权重,的权值计算方式如下:
[0057][0058][0059]
其中,表示第j个单词特征向量与其在图片模态中的特征表示的余弦相似度,值域为[
‑
1,1]。然后,通过加权平均的方式融合与w
j
相关的图片特征信息,获取w
j
对应的多模态特征表示向量
[0060]
[0061]
其中,的结果通常为0至1间的数值,控制着对融合后的多模态特征的影响程度。当较小时,融合后的特征保存更多的文本信息,而较大时,说明图片特征对单词w
j
在事件分类过程中贡献更多的信息。
[0062]
最后将候选触发词w
j
对应的多模态特征输入共享事件分类器,从而获取单词w
j
触发的事件类型
[0063]5‑
3.同样,对于图片i,利用另外一个门控注意力控制着单词特征对图片事件分类的影响。首先利用门控注意力机制为图片动作对应的原始特征与其在文本模态的特征表示分配权重和其中,的计算方式为:
[0064][0065]
然后,通过加权平均融合第i个图片实体的原始特征及其在文本模态中的特征表示获取更新后的多模态特征向量最后利用共享事件分类器对进行分类,获取图片描述动作所属的事件类型argmax(p(y
i
|i),其中,i=1。
[0066]
本发明有益效果如下:
[0067]
针对现有技术的不足,提出了一种基于图片和句子的多模态联合事件检测方法,同时从图片和句子中识别事件。但是,由于缺少足够的多模态标注数据,本发明采用联合优化的方式,一方面利用现有的单模态数据集(imsitu图片数据集和kbp 2017英文数据集)分别学习图片和文本事件分类器,另一方面,利用已有的图片与标题对训练图片句子匹配模块,找出多模态文章中语义相似度最高的图片和句子,从而获取图片实体和单词在公共空间的特征表示。这些特征有助于图片和文本事件分类器之间共享参数,得到共享事件分类器。最后,利用少量的多模态标注数据(m2e2多模态数据集)对模型进行测试,利用共享事件分类器分别获取图片和句子描述的事件及其类型。本发明从图片和句子中识别事件,利用视觉特征和文本特征的互补性,不仅提高了单模态事件分类的性能,而且可以发现文章中更完整的事件信息。
附图说明
[0068]
图1是本发明的整体实施流程图。
[0069]
图2是本发明模型训练阶段的结构图
具体实施方式
[0070]
附图非限制性地公开了本发明所涉及优选实例的流程示意图;以下将结合附图详细地说明本发明的技术方案。
[0071]
事件检测是事件抽取任务的重要环节,该环节可以识别出标志着事件发生的图片动作和文本触发词,并将其分类为预定义的事件类型。在网络舆情分析、情报收集等领域有着广泛的应用。随着传播网络信息的载体越来越多样化,研究人员开始关注不同领域的事件检测任务,即如何自动的从非结构化的图片、文本等不同的信息载体中获取感兴趣的事
件。并且,同一个事件可能以不同的形式出现在图片和句子中。但现有的模型要么只针对基于句子或图片的单模态事件检测,要么只考虑图片特征对文本事件检测的影响,忽略了文本语境对图片事件分类的影响。针对上述问题,本发明提出了基于图片和句子的多模态联合事件检测方法。
[0072]
如图1
‑
2所示,一种基于图片和句子的多模态联合事件检测的方法,按照如下步骤进行:
[0073]
步骤1、文本事件检测模块首先对文本特征进行编码,获取句中单词的特征表示序列对于第j个候选触发词,然后将其对应的特征向量输入文本事件分类器softmax
t
,获取第j个候选触发词触发的事件类型概率分布,其中,文本事件分类器的损失函数定义为l
t
;
[0074]
步骤2、对图片特征进行编码,获取图片中描述动作以及多个实体的特征表示序列然后将图片实体特征向量输入图片事件分类器softmax
i
,获取当前图片描述的事件类型概率分布,其中,图片事件分类器的损失函数定义为l
i
;
[0075]
步骤3、图片句子匹配模块首先利用跨模态注意力机制(cross
‑
modalattention mechanism,cmam)计算每一对图片实体与单词之间的关联权值。根据第j个单词,cmam能够定位重要的图片实体并分配权重,通过加权平均聚合与单词相关的视觉特征,获取单词在图片模态的特征表示另一方面,对于图片中的第i个实体,首先在待匹配的句子中搜索相关的单词,并为它们分配权重,通过加权平均捕获与图片实体相关的语义信息,从而获取图片实体在文本模态的特征表示然后将每个句子与其在图片模态中的特征表示序列的欧氏距离d
t
←
i
以及图片中所有实体与其在文本模态中的特征表示序列的欧氏距离d
i
←
t
进行相加,作为图片和句子的相似度。其中,图片句子匹配模块的损失函数定义为l
m
;
[0076]
步骤4、通过联合优化文本事件检测模块、图片事件检测模块以及图片句子匹配模块,从而获取共享事件分类器;
[0077]
步骤5、在测试阶段,对于多模态文本,首先利用图片句子匹配模块找出相似度最高的图片和句子,并获取第i个图片实体在文本模态的特征表示以及第j个单词在图片模态的特征表示然后利用门控注意力机制为图片实体特征向量和分配权重,通过加权平均获取第i个图片实体对应的多模态特征向量,接着利用共享事件分类器获取图片描述的事件类型。同样,利用另外一个门控注意力机制为和分配权重,通过加权平均获取第j个单词的多模态特征表示,接着利用共享事件分类器获取第j个单词触发的事件类型;
[0078]
进一步的,步骤1具体实现如下:
[0079]1‑
1.在kbp 2017英文数据集上训练文本事件分类器,首先对标注数据进行预处理,获取实体类型、事件触发词、实体关系,其中,一共5种实体类型,18种事件类型,然后利用stanford corenlp对原始文本进行分句、分词,获取词性和句子的语法依存结构。并分别创建词性向量表、实体类型向量表,其中每一种向量表都有类型“空”对应的初始化向量。
[0080]1‑
2.查询预训练的glove词向量矩阵,获取句子中每个词的词向量w
emd
,然后查询
词性向量表得到词性向量w
pos
和查询实体类型向量表得到实体类型向量w
entity
,每个词的实值向量x={w
emd
,w
pos
,w
entity
},因此句子实值向量序列表示为w={x1,x2,...,x
n
‑1,x
n
},其中n是句子的长度。
[0081]1‑
3.将句子实值向量序列w={x1,x2,...,x
n
‑1,x
n
}作为bi
‑
lstms的输入,获取句子的隐含状态向量序列构建基于句子语法依存结构的图卷积网络,接着将h
l
输入gcns中,获取句子的卷积向量序列最后利用注意力计算序列h
t
中的每个元素对候选触发词的影响权重,从而获取句子的编码序列同时将c
t
作为单词序列在公共空间的特征表示序列。
[0082]1‑
4.将句子中的每个单词视为候选触发词,对于第j(j≤n)个候选触发词,然后将其对应的特征向量输入文本事件分类器:
[0083][0084][0085]
其中,w
t
和b
t
作为文本事件分类器softmax
t
的权重矩阵和偏置项,表示句子s中第j个候选触发词w
j
触发的事件类型概率分布,而type
w,j
表示w
j
触发的事件类型。同时,文本事件分类器的损失函数定义为:
[0086][0087]
其中,t是kbp 2017英文数据集中标注的句子数量,作为单词w
j
标注的事件类型,s
i
表示数据集中第i个句子,句子长度为n。
[0088]
进一步的,步骤2具体实现如下:
[0089]2‑
1.在imsitu图片数据集上训练图片事件分类器,其中,一共定义了504个动词记录图片描述的动作,以及11538种实体类型描述图片中出现的实体。首先利用vgg16
v
去提取图片中的动作特征,并利用多层感知机mlp
v
将动词特征转换成动词向量同时,利用另外一个vgg16
o
提取图片中的实体集合o={o1,o2,...,o
m
‑1,o
m
},然后通过多层感知机mlp
o
将所有实体转换成它们对应的名词向量序列然后用网状结构表示每张图片,根据其描述的动作和实体构建网状结构。其中,图片描述的动作作为网状结构的中心节点,同时将实体与动作节点进行连接。接着采用图卷积网络对图片特征对应的单词向量序列进行编码,从而使得动作节点卷积计算后的向量保存实体特征信息。其中,编码后的图片实体特征向量序列为其中,用来表示图片动作节点的卷积向量(为了方便计算,本发明将图片动作视为一个图片实体),同样,h
i
被视图片动作以及实体集合在公共空间的特征表示序列。
[0090]2‑
2.将图片i中动作卷积向量作为图片事件分类器的输入,获取图片描述事件类型的概率分布为:
[0091]
[0092]
type
i
=argmax(p(y
i
|i))
[0093]
其中,w
i
和b
i
作为图片事件分类器softmax
i
的权重矩阵和偏置项,p(y
i
|i)表示图片i触发的事件类型概率分布,而type
i
表示图片i中描述的事件类型。同时,图片事件分类器的损失函数定义为:
[0094][0095]
其中,n代表着imsitu中图片标注事件样例的个数,y
i
作为图片i
i
标注的事件类型,i
i
表示图片数据集中第i个图片样例。
[0096]
进一步的,步骤3具体实现如下:
[0097]3‑
1.图片句子匹配模块是为了从包含多张图片和多个句子的多模态文档中找出语义相似度最高的图片和句子。首先利用跨模态注意力机制计算每一对图片实体与单词之间的关联权值,学习基于单词的图片实体特征表示和基于图片实体的单词特征表示。更具体地说,根据每个单词,cmam能够定位重要的图片实体并分配权重,通过加权平均聚合与单词相关的视觉特征,获取单词在图片模态的特征表示。另一方面,对于图片中的每个实体,首先在待匹配的句子中搜索相关的单词,并为它们分配权重,通过加权平均捕获与图片实体相关的语义信息,从而获取图片实体在文本模态的特征表示。给出图片i对应的实体特征向量序列以及句子s的单词特征向量序列首先利用跨模态注意力机制获取单词和图片实体在其他模态的特征表示。
[0098]3‑
2.为了获取基于单词的图片实体特征表示,首先利用跨模态注意力机制计算图片中第i个实体与第j单词的关联程度score
ij
:
[0099][0100][0101]
其中,表示图片中第i个实体的特征向量与第j单词的特征能量的余弦相似度,值域为[0,1]。然后根据score
ij
,计算第i个图片实体对第j单词的影响权重a
ij
为:
[0102][0103]
最后,通过加权平均的方式聚合基于第j个单词的图片实体特征表示因此,本发明用表示整个句子在图片模态的特征表示序列。
[0104]3‑
3.为了获得基于图片实体的单词特征表示,采用和获取向量相同的计算过程,对于图片中第i个实体,根据第j个单词与当前图片实体的相关性,为第j个单词分配注意力权重:
[0105][0106][0107]
然后,通过加权平均捕获基于图片第i个实体的单词特征表示同样,图片中所有实体在文本模态的表示为:
[0108]3‑
4.为了获取图片与句子的语义相似度,采用弱一致性的对齐方式,将图片和句子的相似度定义为图片中所有实体与其在文本模态中的特征表示序列的欧氏距离,以及每个句子与其在图片模态中的特征表示序列的欧氏距离之和。
[0109]
首先,计算每个句子与其在图片模态中的特征表示序列的欧氏距离:
[0110][0111]
然后图片中所有实体与其在文本模态中的特征表示序列的欧氏距离为:
[0112][0113]
因此,图片i和句子s的语义相似度定义为<i,s>=d
t
←
i
d
i
←
t
。最后,为了获取语义相似度最高的图片句子对<i,s>,然后使用triplet loss优化图片句子匹配模块。对于每一对正确匹配的图片和句子,本发明额外抽取一个与句子s不匹配的图片i
‑
,以及一个与图片i不匹配的句子s
‑
,构成两个否定对<i,s
‑
>和<i
‑
,s>。最后图片句子匹配模块的损失函数定义为:
[0114]
l
m
=max(0,1 <i,s>
‑
<i,s
‑
>) max(0,1 <i,s>
‑
<i
‑
,s>)
[0115]
进一步的,步骤4具体实现如下:
[0116]4‑
1.为了获取共享权重和偏置项的事件分类器,本发明将单词和图片动作在公共空间的特征表示分别作为文本和图片事件分类器的输入,最后通过最小化目标函数l=l
t
l
i
l
m
,对模型进行联合优化。使文本事件分类器softmax
t
和图片事件分类器softmax
i
能够共享权重矩阵和偏置项。从而,在测试阶段,利用共享事件分类器同时预测图片和句子描述的事件类型。
[0117]
进一步的,步骤5具体实现如下:
[0118]5‑
1.利用m2e2多模态标注数据对训练好的模型进行测试,对于包含k个句子s1,s2...,s
k
‑1,s
k
和l张图片i1,i2...,i
l
‑1,i
l
的文章,首先利用图片句子匹配模块找出语义相似度最高的图片句子对<i,s>,同时获取基于图片实体的单词特征表示序列h
i
←
t
、以及基于单词的图片实体特征表示序列h
t
←
i
。
[0119]5‑
2.在特征融合时,对于单词w
j
,本发明认为c
jt
和h
jt
←
i
对触发词w
j
的事件类型预测贡献不同程度的特征信息。因此,本发明利用门控注意力机制为不同的特征信息分配权重,的权值计算方式如下:
[0120][0121][0122]
其中,表示第j个单词特征向量与其在图片模态中的特征表示的余弦相似度,值域为[
‑
1,1]。然后,通过加权平均的方式融合与w
j
相关的图片特征信息,获取w
j
对应的多模态特征表示向量
[0123][0124]
其中,的结果通常为0至1间的数值,控制着对融合后的多模态特征的影响程度。当较小时,融合后的特征保存更多的文本信息,而较大时,说明图片特征对单词w
j
在事件分类过程中贡献更多的信息。
[0125]
最后将候选触发词w
j
对应的多模态特征输入共享事件分类器,从而获取单词w
j
触发的事件类型
[0126]5‑
3.同样,对于图片i,利用另外一个门控注意力控制着单词特征对图片事件分类的影响。首先利用门控注意力机制为图片动作对应的原始特征与其在文本模态的特征表示分配权重和其中,的计算方式为:
[0127][0128]
然后,通过加权平均融合第i个图片实体的原始特征及其在文本模态中的特征表示获取更新后的多模态特征向量最后利用共享事件分类器对进行分类,获取图片描述动作所属的事件类型argmax(p(y
i
|i),其中,i=1。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
