1.本发明涉及语言情感分析技术领域,特别涉及一种针对互联网信息情感倾向性的自动研判方法。
背景技术:
2.根据中国互联网络信息中心(cnnic)发布的第47期《中国互联网发展统计报告》显示,截至2020年12月20日,中国互联网用户数量达到9.89亿。因此,互联网给我们网罗和提供了大量的数据信息,其中对于网民舆论的分析是应对网络舆情分析必不可少的步骤。
3.随着互联网时代的不断深入发展,互联网舆情情感分析已经成为了解社情民意、把握舆情动向、对突发事件做出快速响应和处理的不可或缺的手段。互联网舆情的情感倾向自动研判,是大数据与人工智能结合的一个生动运用。
4.但现有的情感分析方案普遍采用传统机器学习、支持向量机、逻辑回归、 cnn神经网络、lstm神经网络等技术,现有技术在情感倾向性的自动研判的核心——自然语言处理方面,面对如隐晦、歧义等复杂的中文语境时表现欠佳,模型泛化效果差、情感倾向性判别准确率存在很大提升空间。
5.针对现有技术存在的问题,本技术提供了一种针对互联网信息情感倾向性的自动研判方法,解决传统舆情情感研判工作中出现的准确率不高、研判模型泛化效果不够好、应对隐晦、歧义等复杂中文语境时表现欠佳的问题。
技术实现要素:
6.本发明的目的在于提供一种针对互联网信息情感倾向性的自动研判方法,解决传统舆情情感研判工作中出现的准确率不高、研判模型泛化效果不够好、应对隐晦、歧义等复杂中文语境时表现欠佳的问题。
7.本发明提供了一种针对互联网信息情感倾向性的自动研判方法,包括以下步骤:
8.建立舆情语料数据集;
9.建立roberta模型,导入舆情语料数据集进行预训练,改进roberta 模型的bert,获得预训练模型;
10.基于下游任务数据集微调预训练模型的参数,微调后保存最终模型;
11.经最终模型预测后输出情感倾向概率,实现自动研判。
12.进一步地,对舆情语料数据集进行预处理,该预处理的步骤为:
13.收集舆情语料数据集中标注情感倾向性的舆情数据,对该数据进行数据清洗;
14.对舆情数据进行格式化;
15.使用中文字符词典文件,按需转换舆情数据;
16.对舆情数据进行多进程预处理。
17.进一步地,对舆情语料数据集的预训练基于深度学习进行,训练过程中使用混合精度,多机多gpu训练模式。
18.进一步地,对舆情语料数据集的预训练包括对bert进行改进,具体包括:
19.移去nsp任务;
20.指定bert遮罩类型;
21.静态mask变动态mask。
22.进一步地,微调预训练模型的learning rate参数为3e
‑
4,batch size参数为 64,epochs参数为12,遮罩类型设置为fully_visible。
23.进一步地,最终模型配置http接口,http接口采用的数据提交方式为 post,传输格式为json。
24.进一步地,经模型预测后输出的情感倾向包括正面情感倾向、负面情感倾向、中性情感倾向和不相关情感倾向。
25.与现有技术相比,本发明具有如下显著优点:
26.(一)本发明提出的一种针对互联网信息情感倾向性的自动研判方法,采用了在通用语料上使用roberta模型预训练并对下游任务进行微调的方法。并在深度学习训练过程中使用混合精度,多机多gpu训练模式。寻找超参训练完成后,部署模型并提供接口以完成自动研判的工作,此方法鲁棒性好、模型泛化能力强、面对特殊中文语境也可提供高准确率的研判结果。
27.(二)本发明提出的一种针对互联网信息情感倾向性的自动研判方法,在预训练过程中对bert进行改进,将静态mask变动态mask,间接的增加了训练数据,有助于提高模型性能。消除nsp损失在下游任务的性能上能够与原始bert持平或略有提高。
28.(三)本发明提出的一种针对互联网信息情感倾向性的自动研判方法, roberta模型(160g)使用了比bert模型(16g)多10倍的数据。更多的训练数据增加了词汇量、句法结构和语法结构数据的多样性。
附图说明
29.图1为本发明实施例提供的微调预训练模型的结构图;
30.图2为本发明实施例提供的训练前模型架构差异图;
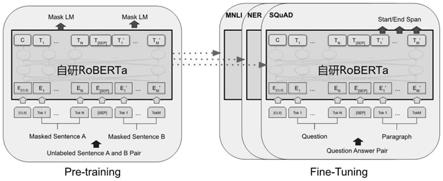
31.图3为本发明实施例提供的roberta在不同任务上的微调原理示意图;
32.图4为本发明实施例提供的微调后的mnli精度图;
33.图5为本发明实施例提供的bert输入部分表示图。
具体实施方式
34.下面结合本发明中的附图,对本发明实施例的技术方案进行清楚、完整的描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
35.参照图1
‑
5,本发明提供了一种针对互联网信息情感倾向性的自动研判方法,包括以下步骤:
36.建立舆情语料数据集,并对舆情语料数据集进行预处理;
37.建立roberta模型,指定模型的目标任务,导入预处理后的舆情语料数据集进行预
训练,改进roberta模型的bert,获得预训练模型;
38.基于下游任务数据集微调预训练模型的参数,微调后保存最终模型;
39.经最终模型预测后输出情感倾向概率,实现自动研判。
40.其中,最终模型配置http接口,http接口采用的数据提交方式为 post,传输格式为json,经模型预测后输出情感倾向概率,实现自动研判。
41.经模型预测后输出的情感倾向包括正面情感倾向、负面情感倾向、中性情感倾向和不相关情感倾向。
42.实施例1
43.对舆情语料数据集进行预处理,该预处理的步骤为:
44.收集舆情语料数据集中标注情感倾向性的舆情数据,对该数据进行数据清洗;
45.对舆情数据进行格式化;
46.使用中文字符词典文件,按需转换舆情数据;
47.对舆情数据进行多进程预处理。
48.实施例2
49.参照图2,训练前模型架构之间的差异:bert使用双向 transformer。openai gpt使用从左到右的transformer。elmo使用独立训练的从左到右和从右到左lstms的连接来生成下游任务的特征。在这三种表示中,只有bert表示是联合表示在所有层上都有左、右两个上下文的条件。除了架构上的差异,bert和openai gpt是一种微调方法,而elmo是一种基于特征的方法。
50.本发明对舆情语料数据集的预训练基于深度学习进行,训练过程中使用混合精度,多机多gpu训练模式。本技术使用160g训练舆情语料,使用roberta模型训练一周、batch size为64,总共3机每机8个gpu(nvidiatesla v100 16g)进行预训练。
51.对舆情语料数据集的预训练包括对bert进行改进,具体包括:
52.移去nsp任务;
53.指定bert遮罩类型;
54.静态mask变动态mask。
55.roberta在训练方法上对bert进行改进,主要体现在改变mask的方式、丢弃nsp任务、训练超参数优化和使用更大规模的训练数据四个方面。其改进点如下:(1)静态mask变动态mask:动态mask相当于间接的增加了训练数据,有助于提高模型性能;(2)移去nsp任务:bert为了捕捉句子之间的关系,使用nsp任务进行预训练,就是输入一对句子a和b,判断这两个句子是否是连续的,两句子最大长度之和为512,roberta去除了nsp后,每次输入连续的多个句子,直到最大长度512(且可以跨文章)。消除nsp损失在下游任务的性能上能够与原始bert持平或略有提高。由于bert一单句子为单位输入,模型无法学习到词之间的远程依赖关系,而roberta输入为连续的多个句子,模型更能俘获更长的依赖关系,这对长序列的下游任务比较友好;(3)更大的 batch size:roberta的batch size是8k。借鉴了在了机器翻译中的训练策略,用更大的batch size配合更大学习率能提升模型优化速率和模型性能的现象,并且也用实验证明了确实bert还能用更大的batch size。(4)更多的训练数据:更长的训练时间,roberta(160g)用了比bert(16g)多10倍的数据。更多的训练数据增加了词汇量、句法结构和语法结构数据的多样性。
56.实施例3
57.如图1和图3,在下游任务数据集上微调预训练模型的learning rate参数为3e
‑
4,batch size参数为64,epochs参数为12,遮罩类型设置为 fully_visible。
58.roberta模型对bert进行全面的预训练和微调。除了输出层,在预训练和微调中都使用相同的架构。使用相同的预训练模型参数进行初始化不同下游任务的模型。在微调过程中,所有参数都会微调。[cls]是一种特殊的在每个输入示例前都添加的符号,[sep]是一个特殊的分隔符标记,用于分隔问题/答案。
[0059]
本技术最终模型的预测任务如下所示:
[0060]
input=[cls]the man went to[mask]store[sep]he bought a gallon [mask]milk[sep]
[0061]
label=isnext
[0062]
input=[cls]the man[mask]to the store[sep]penguin[mask]are flight ##less birds[sep]
[0063]
label=notnext
[0064]
如图4,显示了微调后的mnli精度,从预先为k步训练的模型参数开始。 x轴是k的值。
[0065]
实施例4
[0066]
以中性新闻为例,其bert输入部分表示为如图5所示,其中bert的输入表示说明输入嵌入是标记嵌入、分段嵌入和位置嵌入的总和。
[0067]
经本技术的模型预测,结果为:
[0068]
{"label":"__label__neutral","probability":0.99930811524391174}
[0069]
其中"__label__neutral"表示模型预测为中性情感,概率为99%,判定为中性新闻。
[0070]
以负面新闻为例,经模型预测,结果为:
[0071]
{"label":"__label__negative","probability":0.9227299332618713}
[0072]
其中"__label__negative"表示模型预测为负面情感,概率为92%,判定为负面新闻。
[0073]
以正面新闻为例,经模型预测,结果为:
[0074]
{"label":"__label__positive","probability":0.9998956918716431}
[0075]
其中"__label__positive"表示模型预测为正面情感,概率为99%,判定为正面新闻。
[0076]
实际应用场景中舆情事件复杂多变、舆情焦点不单一、舆情进展多层次,本发明仍能十分准确地完成舆情文本情感倾向性判断。
[0077]
以上公开的仅为本发明的几个具体实施例,但是,本发明实施例并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
