1.本发明属于空间信息技术领域,具体涉及一种逐位置快速估算各类地物概率分布的方法。
背景技术:
2.模拟一直是研究地理现象的一种常用技术和方法。例如对在气象、地质等很多方面,很多研究都是关于如何从有限样本点模拟出研究对象在研究区域的实际分布。20世纪90年代guardiano,srivastava和joumel等提出了使用多点统计学来对进行地理现象建模的这一理论方法,即多点模拟。这一方法可以弥补传统地质统计学变差函数的不足:仅考虑两点之间的统计关系。基于这一思想,专家们提出了很多相关算法并进行了验证。目前这些模拟算法已经被广泛的用于石油和矿物探测、超分辨率制图以及遥感图像分类等各个方面。尤其是在矿物储层模拟方面,通常只能通过有限的几十个样本去估计整个区域不同位置的石油分布情况。
3.目前,多点模拟方法可以分为三个类别。第一个类别是基于正则方程的方法,例如enesim,snesim以及impala。这些方法通过训练图像来学习不同空间近邻条件下各类别的空间分布。这些方法主要针对的是类别数据。第二个类别是基于模式匹配的方法。这些方法从训练图像中直接学习结构模式,然后将这些模式直接粘贴到模拟格网中。代表性的方法有filtersim,simpat 和rpafsim。第三种类型的方法是基于抽样或者信息论的方法,例如ds算法。这类算法通常需要大量的运算才能获得比较好的模拟结果。
4.在实际应用中,通常单次的模拟结果是没有任何参考价值的,必须要通过多次模拟来获得研究区域不同位置各个类别出现的概率。通常需要成百上千次的模拟才能较为准确的估算不同位置各类别出现的概率。然而,如此多的模拟需要大量的计算时间。然而在很多情况下,时间效率尤为关键,因此需要新方法能够快速直接的推算出不同位置的各类别概率。
5.本发明提出了快速估估算不同类别地物复杂空间概率分布的方法。这一方法首先将训练图像和目标目标规则格网分别转换到从粗到细多个不同分辨率规则格网上。不同分辨率规则格网上的每个像元的值被设置为一个类别矢量。矢量的每个元素都是这一元素所对应类别在这一像元空间范围内出现的数目。
6.其次,该方法分别在不同分辨率规则格网上,根据训练图像,在给定的距离范围内,分别统计每个近邻位置出现不同类别组合时,中心像元出现各类别的数目。然后,在每个分辨率规则格网上,将这一统计结果存储下来。
7.最后,从最粗的规则格网开始,根据样本数据构建当前像元的条件数据,并以此为依据估计当前格网的每个像元上不同位置近邻条件下各个类别的出现的概率。然后,把各类别的边缘概率作为各类别先验概率,再融合所有位置近邻的推断结果,并得出当前像元各类别出现的概率。最后将这一概率作为下一层较细规则格网对应像元的先验概率,使用同样的方法推导出这一层规则格网的不同位置出现不同类别的概率。依次类推,得到最细
规则格网上每个像元不同类别的概率分布。
技术实现要素:
8.本发明的目的是面向对具有复杂几何特征的多类别地物,解决现有多点模拟方法难以根据少数样本数据在研究区域内快速逐位置计算各类地物概率分布的问题,提供一种逐位置快速估算各类地物概率分布的方法。
9.为解决上述技术问题,本发明采用的技术方案包含以下步骤:
10.步骤1.给定估算的所需参数,包括最大粒度g,近邻搜索半径τ,以及包含m个样本的样本数据集合h={h1,h2,
…
,h
m
},给出研究区域的所有地物类别,并将c个类别组成的集合记为{s1,s2,
…
,s
c
},g为一个正整数参数,τ为一个正实数参数;
11.步骤2.根据目标区域大小,设定目标规则格网tg,并根据目标地物的空间结构特征选择和目标规则格网具有相同空间分辨率的训练图像ti,其中空间分辨率为每个格网单元所表示的地面实际尺寸的大小;
12.步骤3.将ti缩放到从1到g的不同粒度大小,并分别记为ti1,ti2,
…
, ti
g
;在将ti缩放到粒度1≤g≤g过程中,选定ti的某个顶点格网单元o为坐标原点,其坐标为(0,0,0);对于每个ti中的像元p,将p在三个坐标方向上在ti 规则格网上和o相差的格网单元数记为p的坐标(p
x
,p
y
,p
z
);同时,选定ti
g
中对应于o的顶点格网单元o
g
为坐标原点,其坐标为(0,0,0);对于每个ti
g
中的像元 p
g
,将p
g
在三个坐标方向上在ti
g
规则格网上同o
g
相差的格网单元数记为p
g
的坐标(p
gx
,p
gy
,p
gz
);
13.步骤4.对每个ti
g
中的网格单元p
g
,ti中与其对应的像元组成一个集合 f(p
g
)={p∈ti|2
g
‑1×
p
gx
≤p
x
<2
g
‑1×
(p
gx
1)λ2
g
‑1×
p
gy
≤p
y
< 2
g
‑1×
(p
gy
1)λ2
g
‑1×
p
gz
≤p
z
<2
g
‑1×
(p
gz
1)};当计算出f(p
g
)后,将网格单元p
g
对应的值设定为(s1(p
g
),s2(p
g
),
…
,s
c
(p
g
)),其中s
i
(p
g
)表示 f(p
g
)中被标识为s
i
类别的网格单元个数有多少;
14.步骤5.将tg缩放到从1到g的不同粒度大小,并分别记为tg1,tg2,
…
, tg
g
;在将tg缩放到粒度1≤g≤g过程中,选定tg的某个顶点格网单元o
′
为坐标原点,其坐标为(0,0,0);对于每个tg中的像元q,将q在三个坐标方向上在tg规则格网上和o
′
相差的格网单元数记为q的坐标(q
x
,q
y
,q
z
);同时,选定tg
g
中对应于o
′
的顶点格网单元o
′
g
为坐标原点,其坐标为(0,0,0);对于每个tg
g
中的像元q
g
,将q
g
在三个坐标方向上在tg
g
规则格网上同o
′
g
相差的格网单元数记为q
g
的坐标(q
gx
,q
gy
,q
gz
);
15.步骤6.将样本数据集合h中的每个样本h指定到距离其最近的tg网格单元中;对每个tg中的网格单元q,样本数据中被指定到网格单元q中的样本集合记为h
q
,q所对应的值为一个向量(s1(q),s2(q),
…
,s
c
(q)),其中s
i
(q)表示h
q
中被标识为s
i
类别的样本数有多少;
16.步骤7.对每个tg
g
中的网格单元q
g
,tg中与其对应的像元组成一个集合 f(q
g
)={q∈tg|2
g
‑1×
q
gx
≤q
x
<2
g
‑1×
(q
gx
1)λ2
g
‑1×
q
gy
≤q
y
< 2
g
‑1×
(q
gy
1)λ2
g
‑1×
q
gz
≤q
z
<2
g
‑1×
(q
gz
1)};当计算出f(q
g
)后,将网格单元q
g
对应的值设定为(s1(q
g
),s2(q
g
),
…
,s
c
(q
g
)),其中s
i
(q
g
)表示 f(q
g
)中具有s
i
类别标识的网格单元个数有多少;
17.步骤8.根据给定的近邻搜索半径τ,初始化近邻模板t;t由距离坐标原点不超过τ个网格单元的整数位置矢量构成;对于t中的每个元素t,初始化类别矩阵为0;
每一行表示一个类别组合;例如有两个类别s1和 s2,则有三行,分别表示t中只出现类别s1,只出现类别s2以及同时出现类别s1和s2;第i列代表各种组合下s
i
类别在中心像元出现的个数;
18.步骤9.设定g=g,并将ti中各类别的比例作为各类别在训练图像中的概率质量函数,记为{p
ti
(s1),p
ti
(s2),
…
,p
ti
(s
c
)},同时设置tg
g
中每个网格单元q
g
各类别的先验概率质量函数为
[0019][0020]
步骤10.初始化所有类别矩阵为0,t∈t;对于ti
g
上的每个网格单元p
g
,在ti
g
中寻找同p
g
距离不超过τ个网格单元集合p
g
;对于p
g
中的每个网格单元δ,其坐标为(δ
x
,δ
y
,δ
z
),在近邻模板t中找到δ对应的元素t
δ
=(δ
x
‑ꢀ
p
gx
,δ
y
‑
p
gy
,δ
z
‑
p
gz
);在中找到网格单元δ所有出现类别所对应的类别组合所在行i,并将p
g
所对应的值(s1(p
g
),s2(p
g
),
…
,s
c
(p
g
))累加到的i行;
[0021]
步骤11.对于tg
g
中的每个网格单元q
g
计算各类别的概率质量函数,具体方法如下:
[0022]
(1)将(p(s1(q
g
)),p(s2(q
g
)),
…
,p(s
c
(q
g
)))初始化为0;
[0023]
(2)在tg
g
中寻找同q
g
距离不超过τ个网格单元集合tq
g
;
[0024]
(3)对于tq
g
中的每个网格单元γ,其坐标为(γ
x
,γ
y
,γ
z
);如果 (s1(γ),s2(γ),
…
,s
c
(γ))为0向量,则从tq
g
中去除γ;如果(s1(γ),s2(γ),
…
,s
c
(γ)) 不为0向量,则在近邻模板t中找到γ对应的元素t
γ
=(γ
x
‑
p
gx
,γ
y
‑
p
gy
,γ
z
‑ꢀ
p
gz
);在中找到网格单元γ所有出现类别所对应的类别组合所在行j,然后设置为第j行的值。
[0025]
(4)对每个类别s
i
使用公式
[0026][0027]
融合tq
g
中不同网格单元所推导出的类别概率,其中
[0028][0029]
计算出所有的p(s
i
(q
g
))后,使用
[0030][0031]
对p(s
i
(q
g
))进行归一化得到每个类别的概率。
[0032]
(5)如果g≠1,在tg
g
‑1中找到和q
g
对应的网格单元集合q
g
‑1= {q
g
‑1∈tg
g
‑1|2
×
q
gx
≤q
(g
‑
1)x
<2
×
(q
gx
1)λ2
×
q
gy
≤q
(g
‑
1)y
< 2
×
(q
gy
1)λ2
×
q
gz
≤q
(g
‑
1)z
<2
×
(q
gz
1)},并将
q
g
‑1各类别的先验概率质量函数设置为 {p(s1(q
g
)),p(s2(q
g
)),
…
,p(s
c
(q
g
))},设定g=g
‑
1,跳转到步骤10;
[0033]
步骤12.将tg1,tg2,
…
,tg
g
上每个网格单元的各类别概率质量函数结果输出。
附图说明
[0034]
图1为本发明的流程图;
[0035]
图2为训练图像;
[0036]
图3为粒度为2的训练图像(ti2)构建方法示意图;
[0037]
图4为粒度为2的目标规则格网构建方法示意图;
[0038]
图5为粒度为2的目标规则格网在每个网格单元上的各类别概率质量估计结果。
具体实施方式
[0039]
本实施实例中使用了一个多类别训练图像进行说明,为了方便演示起见,采用了二维情况进行说明,但本方法同样适用于三维情况。同时在二维情况估算过程中,设置所有像元的z轴坐标为0,并不影响其计算结果。结合图 1,具体包括以下步骤:
[0040]
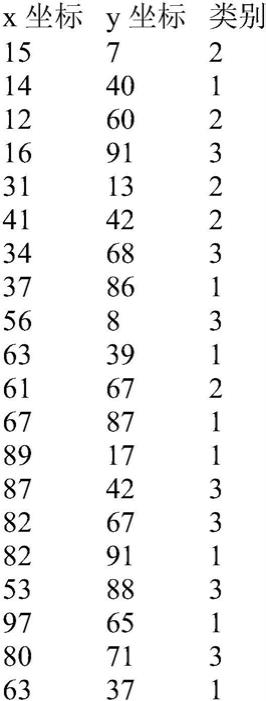
步骤1.给定估算所需的最大粒度g=2,近邻搜索半径τ=20,研究区域的地物类别数目c=3,记这些类别分别为{s1,s2,s3}。研究区域包含m=20个样本的样本数据集合,样本数据如下所示:
[0041][0042]
为了表示和计算方便,样本数据的最后一列使用了s1,s2,s3的下标来表示这三个
类别。
[0043]
步骤2.根据目标区域大小,我们设定了目标规则格网tg为大小100
×
100 像元,并根据目标地物的空间结构特征选择和目标规则格网相同空间分辨率的训练图像ti,其大小为250
×
250像元。训练图像和目标规则格网每个像元所表示的地面实际尺寸的大小相同。训练图像如图2所示:
[0044]
步骤3.将ti缩放到从1到2的不同粒度大小,并分别记为ti1和ti2。将ti 缩放到粒度1≤g≤2过程中,选定ti的某个顶点格网单元o为坐标原点,其坐标为(0,0,0);对于每个ti中的像元p,将p在三个坐标方向上在ti规则格网上和θ相差的格网单元数记为p的坐标(p
x
,p
y
,p
z
);同时,选定ti
g
中对应于o的顶点格网单元o
g
为坐标原点,其坐标为(0,0,0);对于每个ti
g
中的像元p
g
,将p
g
在三个坐标方向上在ti
g
规则格网上和o
g
相差的格网单元数记为p
g
的坐标 (p
gx
,p
gy
,p
gz
);
[0045]
步骤4.对每个ti
g
中的网格单元p
g
,ti中与其对应的像元组成一个集合 f(p
g
)={p∈ti|2
g
‑1×
p
gx
≤p
x
<2
g
‑1×
(p
gx
1)λ2
g
‑1×
p
gy
≤p
y
< 2
g
‑1×
(p
gy
1)λ2
g
‑1×
p
gz
≤p
z
<2
g
‑1×
(p
gz
1)};当计算出f(p
g
)后,将网格单元p
g
对应的值设定为(s1(p
g
),s2(p
g
),s3(p
g
)),其中s
i
(p
g
)表示f(p
g
)中被标识为s
i
类别的网格单元个数有多少,如图3例子所示。
[0046]
图3左面子图是一个简单的训练图像,包含b(黑色),w(白色)两个类别,每一个黑色或白色方框代表一个像元。上图右面子图是左面子图缩放到粒度为2的训练图像,每个方框代表该粒度下的一个像元。都以最左上角顶点作为原点,那么两个子图中左上角顶点的坐标都为(0,0),并且右面子图中左上角顶点对应的f((0,0))集合为{(0,0),(0,1),(1,0),(1,1)}这四个左面子图中的像元。因此粒度为2的训练图像中左上角顶点的所对应的值为矢量(1,3)。这一矢量的含义是出现1个黑色类别和3个白色类别。
[0047]
步骤5.将tg缩放到从1到g的不同粒度大小,并分别记为tg1,tg2,
…
, tg
g
;在将tg缩放到粒度1≤g≤g过程中,选定tg的某个顶点格网单元o
′
为坐标原点,其坐标为(0,0,0);对于每个tg中的像元q,将q在三个坐标方向上在tg规则格网上和o
′
相差的格网单元数记为q的坐标(q
x
,q
y
,q
z
);同时,选定tg
g
中对应于o
′
的顶点格网单元o
′
g
为坐标原点,其坐标为(0,0,0);对于每个tg
g
中的像元q
g
,将q
g
在三个坐标方向上在tg
g
规则格网上和o
′
g
相差的格网单元数记为q
g
的坐标(q
gx
,q
gy
,q
gz
);
[0048]
步骤6.将样本数据集合h中的每个样本h指定到距离其最近的tg网格单元中;对每个tg中的网格单元q,样本数据中被指定到网格单元q中的样本集合记为h
q
,q所对应的值为一个向量(s1(q),s2(q),s3(q)),其中s
i
(q)表示h
q
中被标识为s
i
类别的样本数有多少。
[0049]
本实例的这一步骤中20个样本分别被指定到其对应的20个不同的像元中。例如第一个样本其x和y坐标为15和7,类别为s2,这一样本被赋值到 tg坐标为(15,7)的像元处,该像元对应的值设置为(0,1,0)。
[0050]
步骤7.对每个tg
g
中的网格单元q
g
,tg中与其对应的像元组成一个集合 f(q
g
)={q∈tg|2
g
‑1×
q
gx
≤q
x
<2
g
‑1×
(q
gx
1)λ2
g
‑1×
q
gy
≤q
y
< 2
g
‑1×
(q
gy
1)λ2
g
‑1×
q
gz
≤q
z
<2
g
‑1×
(q
gz
1)};当计算出f(q
g
)后,将网格单元q
g
对应的值设定为(s1(q
g
),s2(q
g
),s3(q
g
)),其中s
i
(q
g
)表示f(q
g
)中具有s
i
类别标识的网格单元个数有多少。
[0051]
以图4为例,该图左面子图为已经将样本指定之后的目标规则格网,其中虚线框表示的像元不包含任何样本,白色实线框表示的像元表示包含只出现一次w类地物,黑色实线
框表示的像元表示只出现一次b类地物。图4右面子图为粒度为2的目标规则格网。每个方框代表该粒度下的一个像元。都以最左上角顶点作为原点,那么两个子图中左上角顶点的坐标都为(0,0),并且图4右面子图中左上角顶点对应的f((0,0))集合为{(0,0),(0,1),(1,0),(1,1)}这四个左面子图中的像元。以左上角为例,其值为一个向量(0,1),表示只出现w类地物。以右面子图中间位置在坐标为的像元为例,其在粒度为2的目标规则格网中的坐标为(1,2),f((1,2))集合为{(2,4),(3,4),(2,5),(3,5)}。左面子图中这四个像元中b 类地物和w类地物分别出现一次,因此在粒度为2的目标规则格网中的坐标为(1,2)的像元对应的值为一个向量(1,1),表示w类地物和b类地物各出现一次。
[0052]
步骤8.根据给定的近邻搜索半径,初始化近邻模板t;t由距离坐标原点不超过τ个网格单元的整数位置矢量构成;对于t中的每个元素t,初始化类别矩阵为0;每一行表示一个类别组合;例如有两个类别s1和 s2,则有三行,分别表示t中只出现类别s1,只出现类别s2以及同时出现类别s1和s2;第i列代表各种组合下s
i
类别在中心像元出现的个数;
[0053]
二维情况下,当近邻搜索半径为20时,该模板共有1257个元素。对于每个元素,需要初始化一个类别矩阵,由于类别数为3,其大小为7
×
3。从第一行到第七行分别表示类别组合{s1},{s2},{s3},{s1,s2},{s1,s3},{s2,s3}和 {s1,s2,s3}。以第一行为例,其表示{s1}类别组合出现时,中心像元出现s1,s2,s3三个类别的数目分别是多少。
[0054]
步骤9.设定g=2,并将ti中各类别的比例作为各类别在训练图像中的概率质量函数,其值为{p
ti
(s1),p
ti
(s2),
…
,p
ti
(s
c
)}={0.3122,0.4333,0.2545},同时设置tg
g
中每个网格单元q
g
各类别的先验概率质量函数
[0055][0056]
步骤10.初始化所有类别矩阵为0,t∈t;对于ti
g
上的每个网格单元p
g
,在ti
g
中寻找同p
g
距离不超过τ个网格单元集合p
g
;对于p
g
中的每个网格单元δ,其坐标为(δ
x
,δ
y
,δ
z
),在近邻模板t中找到δ对应的元素t
δ
=(δ
x
‑ꢀ
p
gx
,δ
y
‑
p
gy
,δ
z
‑
p
gz
);在中找到网格单元δ所有出现类别所对应的类别组合所在行i,并将p
g
所对应的值(s1(p
g
),s2(p
g
),s3(p
g
))累加到的i行。
[0057]
例如,对于训练图像的每个像元如果发现当其x轴右侧侧紧邻(模板中对应的矢量为t
δ
=(1,0))的像元类别组合为{s1}时,则将该像元的三个类别出现次数的值累加到这一模板元素对应的的第1行的三个类别数目的值上。
[0058]
步骤11.对于tg
g
中的每个网格单元q
g
计算各类别的概率质量函数,具体方法如下:
[0059]
(6)将(p(s1(q
g
)),p(s2(q
g
)),p(s3(q
g
)))初始化为0;
[0060]
(7)在tg
g
中寻找同q
g
距离不超过τ个网格单元集合tq
g
;
[0061]
(8)对于tq
g
中的每个网格单元γ,其坐标为(γ
x
,γ
y
,γ
z
);如果 (s1(γ),s2(γ),s3(γ))为0向量,则从tq
g
中去除γ;如果(s1(γ),s2(γ),s3(γ))不为 0向量,则在近邻模
板t中找到γ对应的元素t
γ
=(γ
x
‑
p
gx
,γ
y
‑
p
gy
,γ
z
‑
p
gz
);在中找到网格单元γ所有出现类别所对应的类别组合所在行j,然后设置为第j行的值。
[0062]
(9)对每个类别s
i
使用公式
[0063][0064]
融合tq
g
中不同网格单元所推导出的类别概率,其中
[0065][0066]
计算出所有的p(s
i
(q
g
))后,使用
[0067][0068]
(10)对p(s
i
(q
g
))进行归一化得到每个类别的概率。如果g≠1,在tg
g
‑1中找到和q
g
对应的网格单元集合q
g
‑1={q
g
‑1∈tg
g
‑1|2
×
q
gx
≤q
(g
‑
1)x
< 2
×
(q
gx
1)λ2
×
q
gy
≤q
(g
‑
1)y
<2
×
(q
gy
1)λ2
×
q
gz
≤q
(g
‑
1)z
< 2
×
(q
gz
1)},并将q
g
‑1各类别的先验概率质量函数设置为{p(s1(q
g
)),p(s2(q
g
)),p(s3(q
g
))},设定 g=g
‑
1,跳转到步骤10;
[0069]
在这一步中,每个粒度为g的目标规则格网中像元上所估算出的概率质量函数都作为粒度为g
‑
1的目标规则格网中相应像元在下一次估算中的先验。
[0070]
步骤12.将tg1,tg2上每个网格单元的各类别概率质量函数结果输出。图5为tg2上每个网格单元的各类别概率质量函数结果。该图从左到右依次为 s1,s2,s3三个类别的概率估算结果。最后一个图例为概率值。
[0071]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
