1.本发明属于数据采集技术领域,尤其涉及一种大规模数据中心数据采集的自适应抽样模型优化方法。
背景技术:
2.目前,数据中心运行数据用来进行能耗分析和管理、工作流调度、任务调度的多项数据中心智能管理任务,随着云数据中心的规模越来越大,数据驱动的数据中心运行数据采集成为一个重要的研究问题。现有的大规模云数据中心采集方法分为两类:一类方法通过动态调整采集策略或采集频率来减少采集的开销,另一类方法主要是利用分布式处理机制来进行运行数据采集。例如,专利号为cn201310028813.7所公开的一种云数据中心信息差量采集方法。又例如,专利号为cn201611128567.2所公开的用于数据中心监控系统的数据采集和处理方法及系统。但是以上方法都不能实现数据驱动的自适应实时采集,提高了采集数据的价值密度,在运行数据波动较小时降低了采集任务的代价,但是并没有改变大规模数据中心数十万节点采集的难度,因为当数据波动较大时,采集任务依旧是难以达到实时性的;没有利用运行数据的内在特征,容易在上级节点产生响应瓶颈或者需要大量的数据采集中心和处理中心,从而在响应时间方面不能达到实时性要求或者在计算资源耗费太大,监控系统难以承受。
技术实现要素:
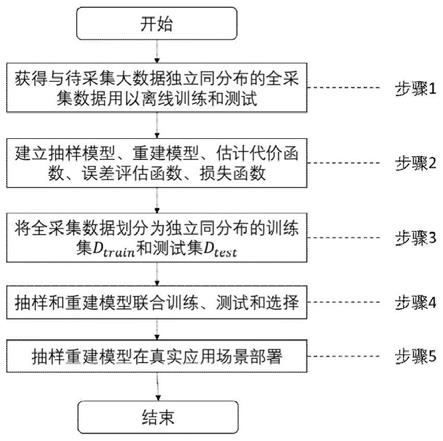
3.本发明的目的在于提供一种能够克服上述技术问题的大规模数据中心数据采集的自适应抽样模型优化方法,本发明所述方法包括以下步骤:
4.步骤1,本发明应用场景的形式化表述是:待采集同构个体总数量n,采集指标数量k,采集持续时间0~t,每个时刻t时,针对全部个体,以固定抽样率r抽样采集的当前时刻数据,采集的个体i的数据表示为其中,x0,...,x
k
均为实数,在时刻t采集到的全体数据表示为未采集的个体j的数据表示为在时刻t的抽样决策向量表示为其中,对于决定采集的个体i,对于决定不采集的个体j,在时刻t的采集代价表示为c
t
=cost(b
t
),其中c
t
为实数,cost为未知的代价函数,在采集时由环境反馈给出,在时刻t的重建数据表示为在时刻t,重建误差表示为error为误差评估函数,优化目标为最小化l=f(c
t
,e
t
),f为损失函数,均衡考虑采集代价、重建误差、正则项,获得与待采集运行数据独立同分布的全采集数据用以离线训练和测试,所用的全采集数据d
tt
=<d>与部署后应用时场景中的真实数据集d
real
独立同分布;采集数据集中的全部的有限的单个个体的数据用来计算重建误差e
tt
以准确评估重建结果;
5.步骤2,建立抽样模型、重建模型、估计代价函数、误差评估函数、损失函数:
6.抽样模型sampling、重建模型reconstruct、估计代价函数cost、误差评估函数error、损失函数loss、梯度更新优化算法optimize的具体输入输出是:抽样模型sampling在时刻t,输入记忆张量m
t
,维度为h*n*k,抽样率r,其中h为记忆的时间序列长度,输出抽样决策向量,重建模型reconstruct在时刻t输入记忆张量m
t
,在时刻t采集的数据d
t
,抽样决策向量b
t
,输出重建数据估计代价函数cost在时刻t输入抽样决策向量b
t
,大数据采集模拟环境s
t
=simulate(d
tt
;p,t),输出抽样代价c
t
,simulate是大数据采集环境模拟器,p是模拟配置参数,simulate输出采集数据d
t
和真实数据
7.误差函数error在时刻t输入重建数据真实数据输出重建误差e
t
,
8.损失函数loss在时刻t输入抽样采集代价c
t
,重建误差e
t
,正则参数z
t
,输出损失值l,
9.梯度更新算法optimize在时刻t参数为po
t
,输入模型参数的梯度值g,原模型参数值pm
t
,输出更新后的参数值pm
t 1
,模型和函数依据不同场景采用不同计算公式;
10.步骤3,将全采集数据划分为独立同分布的训练集d
train
和测试集d
test
:
11.将数据划分为训练集和测试集的具体步骤是:设定训练比例α,将数据集从时间维度前后划分为d
α
,d1‑
α
,也能够采用其他数据划分方法,但要保证d
α
和d1‑
α
满足独立同分布假设;
12.步骤4,抽样和重建模型联合训练、测试和选择:
13.步骤401,初始化迭代次数epoch=1,最大迭代次数epoch,数据集d=d
train
,总时长t=t
train
;
14.步骤402,初始化采集时刻t=h,m
t
=m
h in d;
15.步骤403,将记忆张量m
h
、抽样率r输入抽样模型sampling,输出抽样决策二值向量b
t
,记录抽样模型各参数值ps
t
,各参数对应的局部梯度为简化表达,gs
t
指的是模型下的各个操作的局部梯度并列所组成的长向量且并非单独一个实值,以下所述局部梯度同理;
16.步骤404,将抽样决策二值向量b
t
输入采集模拟环境s
t
和采集代价函数cost,输出采集数据d
t
、真实数据采集代价c
t
;
17.步骤405,将采集数据d
t
、记忆矩阵m
t
、抽样决策向量b
t
输入重建模型reconstruct,输出重建数据记录重建模型各参数值pr
t
,各参数对应的局部梯度
18.步骤406,将重建数据和真实数据输入误差函数error,输出重建误差e
t
,记录误差函数各参数pe
t
,各参数的局部梯度
19.步骤407,将抽样采集代价c
t
、重建误差e
t
、正则参数z
t
输入损失函数loss,输出损失值l,记录损失函数各参数pl
t
,各参数的局部梯度
20.步骤408,按照梯度更新算法optimize进行损失回传,计算损失值关于各参数的梯度,并进行损失函数loss、误差函数error、重建模型reconstruct、抽样模型sampling的参数更新,重建模型梯度回传至抽样模型时按照如下公式(1)计算损失值l关于二值向量b
t
的
梯度值:
[0021][0022]
步骤409,按照如下公式(2)更新记忆矩阵,
[0023][0024]
m
t 1
=m
t
<<1 in dim=0
……
(2),
[0025][0026]
其中,<<为循环左移操作;
[0027]
步骤410,当t<t,则t=t 1,保存抽样模型和重建模型参数ps
epoch
和pr
epoch
,保存损失值l
t
,转至步骤402,否则转至步骤411;
[0028]
步骤411,当epoch<epoch,令d=d
test
,t=t
train
,执行步骤402,否则转至步骤412;
[0029]
步骤412,选择当d=d
test
时,使得l
t
最小的抽样模型sampling和重建模型reconstruct作为输出的模型;
[0030]
步骤5,在真实应用场景部署抽样重建模型:
[0031]
步骤501,以抽样率r随机抽样h个时刻,获得初始化记忆张量m
h
,m
h
=(d1,...d
h
);
[0032]
步骤502,初始化采集时刻t=h,记忆张量m
t
=m
h
;
[0033]
步骤503,将记忆张量m
h
、抽样率r输入抽样模型sampling,输出抽样决策二值向量b
t
;
[0034]
步骤504,依抽样决策二值向量b
t
在真实部署环境中进行大数据抽样采集,输出采集数据d
t
、采集代价c
t
;
[0035]
步骤505,将采集数据d
t
、记忆矩阵m
t
、抽样决策向量b
t
输入重建模型reconstruct,输出重建数据
[0036]
步骤506,按照如下公式(3)、公式(4)更新记忆矩阵,
[0037][0037][0038][0039]
m
t 1
=m
t
<<1indim=0
……
(4),
[0040]
其中,<<为循环左移操作;
[0041]
步骤507,当未达到采集次数要求,即t<t
max
,则t=t 1,返回步骤503,否则结束大数据抽样采集。
[0042]
本发明所述方法具有如下的有益效果:
[0043]
1、与现有的大规模数据中心运行数据采集技术方法相比,本发明所述方法能够建立抽样模型并实现基于梯度的抽样模型的优化,在大规模数据中心的场景下和现有数据集中,通过优化完成的抽样模型降低了所需采集目标的数量,同时降低了采集代价并保持了重建精度;
[0044]
2、本发明所述方法抽样模型根据残缺历史数据自适应学习参数,输出抽样决策向量,在个体数量规模大的大数据采集场景中,能够动态地根据场景数据特征自适应的给出抽样决策;
[0045]
3、本发明所述方法从残缺的历史数据中学习数据特征,优化目标综合考虑采集代
价和重建误差,端到端地优化抽样模型和重建模型,实现了数据驱动的抽样模型优化,在抽样降低采集数据量并进而降低采集延迟的基础上,进一步实现了抽样模型和重建模型的端到端优化,提供了一种抽样模型优化策略;
[0046]
4、本发明所述方法针对大规模数据中心的数据采集场景,通过显式建模抽样、重建过程,结合真实的数据采集结果,在抽样决策的最后一步添加可导的二值化层,得到抽样决策向量,从而降低了采集延迟的采集代价,通过综合评估重建结果和采集代价,使得能够通过梯度下降法同时优化抽样模型和重建模型,提供了一种抽样模型优化方法,从而解决了大规模数据中心运行数据采集场景中抽样方法评价难问题和抽样模型优化无目标的问题,解决了大规模运行数据中心的实时采集问题,提供了一种根据历史采集数据进行自适应抽样的方法;
[0047]
5、本发明所述方法能够降低采集延迟,同时针对运行数据的多个潜在应用提出了统一的采集优化目标,充分利用数据内存在特征,在综合考虑采集代价和重建精度并在采集前未观测全部数据的情况下,通过建立并优化抽样模型,根据残缺的历史记录自适应地进行数据中心运行数据的抽样采集。
附图说明
[0048]
图1是本发明所述方法的大规模数据中心运行数据的抽样模型优化步骤示意图;
[0049]
图2是本发明所述方法的抽样和重建模型联合训练、测试和选择步骤示意图;
[0050]
图3是本发明所述方法的抽样采集模型在真实应用场景部署步骤示意图;
[0051]
图4是本发明所述方法的大规模云数据中心抽样采集实例示意图。
具体实施方式
[0052]
下面结合附图对本发明的实施方式进行详细描述。
[0053]
如图1
‑
4所示,本发明所述方法包括以下步骤:
[0054]
步骤1,本发明应用场景的形式化表述是:待采集同构个体总数量n,采集指标数量k,采集持续时间0~t,每个时刻t时,针对全部个体,以固定抽样率r抽样采集的当前时刻数据,采集的个体i的数据表示为其中,x0,
…
,x
k
均为实数,在时刻t采集到的全体数据表示为未采集的个体j的数据表示为在时刻t的抽样决策向量表示为其中,对于决定采集的个体i,对于决定不采集的个体j,在时刻t的采集代价表示为c
t
=cost(b
t
),其中c
t
为实数,cost为未知的代价函数,在采集时由环境反馈给出,在时刻t的重建数据表示为在时刻t,重建误差表示为error为误差评估函数,优化目标为最小化l=f(c
t
,e
t
),f为损失函数,均衡考虑采集代价、重建误差、正则项,获得与待采集运行数据独立同分布的全采集数据用以离线训练和测试,所用的全采集数据d
tt
=<d>与部署后应用时场景中的真实数据集d
real
独立同分布;采集数据集中的全部的有限的单个个体的数据用来计算重建误差e
tt
以准确评估重建结果;
[0055]
步骤2,建立抽样模型、重建模型、估计代价函数、误差评估函数、损失函数:
[0056]
抽样模型sampling、重建模型reconstruct、估计代价函数cost、误差评估函数error、损失函数loss、梯度更新优化算法optimize的具体输入输出是:抽样模型sampling在时刻t,输入记忆张量m
t
,维度为h*n*k,抽样率r,其中h为记忆的时间序列长度,输出抽样决策向量,重建模型reconstruct在时刻t输入记忆张量m
t
,在时刻t采集的数据d
t
,抽样决策向量b
t
,输出重建数据估计代价函数cost在时刻t输入抽样决策向量b
t
,大数据采集模拟环境s
t
=simulate(d
tt
;p,t),输出抽样代价c
t
,simulate是大数据采集环境模拟器,p是模拟配置参数,simulate输出采集数据d
t
和真实数据
[0057]
误差函数error在时刻t输入重建数据真实数据输出重建误差e
t
,
[0058]
损失函数loss在时刻t输入抽样采集代价c
t
,重建误差e
t
,正则参数z
t
,输出损失值l,
[0059]
梯度更新算法optimize在时刻t参数为po
t
,输入模型参数的梯度值g,原模型参数值pm
t
,输出更新后的参数值pm
t 1
,模型和函数依据不同场景采用不同计算公式;
[0060]
步骤3,将全采集数据划分为独立同分布的训练集d
train
和测试集d
test
:
[0061]
将数据划分为训练集和测试集的具体步骤是:设定训练比例α,将数据集从时间维度前后划分为d
α
,d1‑
α
,也能够采用其他数据划分方法,但要保证d
α
和d1‑
α
满足独立同分布假设;
[0062]
步骤4,抽样和重建模型联合训练、测试和选择:
[0063]
步骤401,初始化迭代次数epoch=1,最大迭代次数epoch,数据集d=d
train
,总时长t=t
train
;
[0064]
步骤402,初始化采集时刻t=h,m
t
=m
h
ind;
[0065]
步骤403,将记忆张量m
h
、抽样率r输入抽样模型sampling,输出抽样决策二值向量b
t
,记录抽样模型各参数值ps
t
,各参数对应的局部梯度为简化表达,gs
t
指的是模型下的各个操作的局部梯度并列所组成的长向量且并非单独一个实值,以下所述局部梯度同理;
[0066]
步骤404,将抽样决策二值向量b
t
输入采集模拟环境s
t
和采集代价函数cost,输出采集数据d
t
、真实数据采集代价c
t
;
[0067]
步骤405,将采集数据d
t
、记忆矩阵m
t
、抽样决策向量b
t
输入重建模型reconstruct,输出重建数据记录重建模型各参数值pr
t
,各参数对应的局部梯度
[0068]
步骤406,将重建数据和真实数据输入误差函数error,输出重建误差e
t
,记录误差函数各参数pe
t
,各参数的局部梯度
[0069]
步骤407,将抽样采集代价c
t
、重建误差e
t
、正则参数z
t
输入损失函数loss,输出损失值l,记录损失函数各参数pl
t
,各参数的局部梯度
[0070]
步骤408,按照梯度更新算法optimize进行损失回传,计算损失值关于各参数的梯度,并进行损失函数loss、误差函数error、重建模型reconstruct、抽样模型sampling的参数更新,重建模型梯度回传至抽样模型时按照如下公式(1)计算损失值l关于二值向量b
t
的
梯度值:
[0071][0072]
步骤409,按照如下公式(2)更新记忆矩阵,
[0073][0074]
m
t 1
=m
t
<<1 in dim=0
……
(2),
[0075]
其中,<<为循环左移操作;
[0076]
步骤410,当t<t,则t=t 1,保存抽样模型和重建模型参数ps
epocl
和pr
epocl
,保存损失值l
t
,转至步骤402,否则转至步骤411;
[0077]
步骤411,当epoch<epoch,令d=d
test
,t=t
train
,执行步骤402,否则转至步骤412;
[0078]
步骤412,选择当d=d
test
时,使得l
t
最小的抽样模型sampling和重建模型reconstruct作为输出的模型;
[0079]
步骤5,在真实应用场景部署抽样重建模型:
[0080]
步骤501,以抽样率r随机抽样h个时刻,获得初始化记忆张量m
h
,m
h
=(d1,...d
h
);
[0081]
步骤502,初始化采集时刻t=h,记忆张量m
t
=m
h
;
[0082]
步骤503,将记忆张量m
h
、抽样率r输入抽样模型sampling,输出抽样决策二值向量b
t
;
[0083]
步骤504,依抽样决策二值向量b
t
在真实部署环境中进行大数据抽样采集,输出采集数据d
t
、采集代价c
t
;
[0084]
步骤505,将采集数据d
t
、记忆矩阵m
t
、抽样决策向量b
t
输入重建模型reconstruct,输出重建数据
[0085]
步骤506,按照如下公式(3)、公式(4)更新记忆矩阵,
[0086][0087]
m
t 1
=m
t
<<1 in dim=0
……
(4),
[0088]
其中,<<为循环左移操作;
[0089]
步骤507,当未达到采集次数要求,即t<t
max
,则t=t 1,返回步骤503,否则结束大数据抽样采集。
[0090]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明公开的范围内,能够轻易想到的变化或替换,都应涵盖在本发明权利要求的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
