1.本文讨论的实施方式涉及更新系统的局部字段矩阵。
背景技术:
2.组合优化问题通常被归类为np问题(非确定性多项式时间问题),例如np难度(np
‑
hard)问题或np完全(np
‑
complete)问题,在这些问题中通常没有已知的算法来在多项式时间内求解这样的问题。这样的组合优化问题可能出现在许多应用中,例如,使布局设计中通孔的数量最小化、使股票投资组合收益最大化、航线安排和调度以及无线传感器网络。
3.本文要求保护的主题不限于解决任何缺点或仅在诸如以上描述的环境中操作的实施方式。相反,提供该背景技术仅是为了说明可以实践本文所描述的一些实施方式的一个示例技术领域。
技术实现要素:
4.根据实施方式的一方面,操作可以包括:获得与和系统相关联的优化问题相关联的第一矩阵,以及获得与该优化问题相关联的第二矩阵。第一矩阵和第二矩阵可以与赋予系统的各个变量的对应权重有关,其中,所述对应权重与各个变量和一个或更多个其他变量之间的关系有关。所述操作可以包括获得局部字段矩阵,该局部字段矩阵指示系统中变量之间的受他们的相应权重影响的相互作用。相互作用可以与在求解优化问题期间变量的状态变化有关。响应于在求解优化问题期间系统中的一个或更多个变量的状态变化,所述操作可以包括更新局部字段矩阵。更新局部字段矩阵可以包括针对第一矩阵的第一部分和第二矩阵的第二部分执行一个或更多个算术运算,第一矩阵的第一部分和第二矩阵的第二部分与局部字段矩阵的对应于一个或更多个变量的第三部分相对应。所述操作可以包括基于更新的局部字段矩阵来更新系统的能量值,以及基于该能量值来确定针对优化问题的解。
5.实施方式的目的和优点将至少通过权利要求书中具体指出的元素、特征和组合来实现和完成。
6.前面的总体描述和下面的详细描述两者均作为示例给出,并且是说明性的且不限制所要求保护的本发明。
附图说明
7.将通过使用附图、利用附加的特征和细节来描述和说明示例实施方式,在附图中:
8.图1a是表示被配置成求解优化问题的示例环境的图;
9.图1b示出了与更新局部字段矩阵有关的示例技术;
10.图1c示出了与更新局部字段矩阵有关的其他示例技术;
11.图1d示出了与更新局部字段矩阵有关的其他示例技术;
12.图1e示出了与更新局部字段矩阵有关的其他示例技术;
13.图1f示出了与更新局部字段矩阵有关的其他示例技术;
14.图2示出了被配置成执行副本交换处理的示例计算系统的框图;以及
15.图3示出了求解优化问题的示例方法的流程图。
具体实施方式
16.组合优化问题可以包括可以用于确定系统的能量或成本函数的最大值或最小值的一类优化问题。例如,组合优化可以用于使电路布局设计的通孔的数量最小化、使股票收益最大化、改善航线安排和调度、配置无线传感器网络以及其他应用中。
17.在一些情况下,伊辛(ising)模型可用于求解优化问题。特别地,伊辛模型的伊辛能量(“能量”)可以是对应于特定优化问题的特定系统的总体状态空间的表示。确定能量的最小值的最小化技术或确定能量的最大值的最大化技术可以用于求解优化问题。例如,可以将特定系统的与所确定的最小或最大能量相对应的状态用作特定优化问题的解。对确定最小能量或最大能量的引用不限于确定系统的绝对最小能量或绝对最大能量。替代地,对确定最小能量或最大能量的引用可以包括针对系统的能量执行最小化或最大化操作,其中,将来自这样的操作的输出用作对应优化问题的解。
18.如以下详细描述的,局部字段矩阵可以用于指示特定系统的能量在特定系统的变量的状态变化时的变化量。局部字段矩阵包括基于特定系统的变量之间的相互作用的值,相互作用相对于一个或更多个变量的状态变化受他们的相应权重影响。如以下详细讨论的,根据本公开内容的一个或更多个实施方式,可以以减少存储器需求和/或处理需求的方式,在求解相应的优化问题期间使用特定技术来确定和更新系统的局部字段矩阵和/或能量。例如,如上面所指示的,局部字段矩阵可以基于与特定系统的变量相对应的权重。此外,能量可以基于权重。如以下详细描述的,可以通过在求解优化问题期间确定相关权重的值,来在求解优化问题期间更新局部字段矩阵和/或能量。因此,可以基本上实时地完成对权重的确定,而不是通过保存包括权重的值的权重矩阵并且然后访问这些权重以更新局部字段矩阵和/或能量来完成对权重的确定。
19.避免存储权重矩阵的能力可以节省大量存储器,因为权重矩阵可能是非常大的矩阵。替代地,如以下详细描述的,可以存储更小的矩阵并且可以使用其对应值来确定权重值。这样,可以减少用于求解优化问题中使用的存储器的数量。另外地或可替选地,在一些实施方式中,存储需求的减少使得能够在单个处理芯片上执行所有存储(例如,经由该芯片的缓存),这可以通过减少或避免调用可能存储在片外的存储器来提高求解优化问题的处理速度。因此,可以通过减少求解优化问题的计算系统的关于求解优化问题的存储器需求来改善这些系统中使用的计算系统。
20.参照附图对本公开内容的实施方式进行说明。
21.图1a是表示根据本公开内容中描述的至少一个实施方式布置的被配置成求解优化问题的示例环境100的图。环境100可以包括能量确定引擎102(“能量引擎102”),能量确定引擎102被配置成更新和输出系统106的系统更新104。在这些或其他实施方式中,环境100可以包括局部字段矩阵引擎108(“lfm引擎108”),局部字段矩阵引擎108被配置成基于系统更新104来更新局部字段矩阵110(“lfm 110”)。
22.系统106可以包括可以求解的优化问题的任何合适的表示。例如,在一些实施方式
中,系统106可以包括状态向量x,状态向量x可以包括各自分别表示与优化问题有关的特征的一组变量。因此,状态向量x可以表示系统106的不同状态。例如,包括各自具有第一值的变量的第一状态向量x1可以表示系统106的第一状态,并且包括各自具有第二值的变量的第二状态向量x2可以表示系统106的第二状态。在这些或其他实施方式中,状态向量x1与状态向量x1之间的差异可以是从x1和x2两者中仅有一个对应变量具有不同的值到x1和x2中的每个变量均具有不同值。
23.举例来说,系统106可以是可以包括任何合适数量的节点(也称为“神经元”)的神经网络。在这些或其他实施方式中,系统106的状态向量x可以表示神经网络中的每个神经元的状态。例如,每个神经元可以是可以具有“0”或“1”值的位,并且状态向量x可以包括针对神经网络中的每个神经元的“1”值或“0”值。在这些或其他实施方式中,神经网络可以被配置成以任何合适的方式求解一种或更多种不同类型的优化问题。
24.在一些实施方式中,系统106的神经网络可以被配置为玻尔兹曼机(boltzmann machine)。在这些或其他实施方式中,玻尔兹曼机可以被配置为可以将玻耳兹曼机的神经元分组为聚类(cluster)的聚类式玻尔兹曼机(cbm)。可以形成聚类使得同一聚类内的神经元之间可以不存在连接(例如,聚类的神经元之间的权重可以是“0”)。在这些或其他实施方式中,cbm可以被配置成具有至多n位(at
‑
most
‑
n)约束,其中,在任何给定聚类中仅“n”个神经元可以处于激活状态(例如,具有“1”的位值)。例如,cbm可以具有恰好1位(exactly
‑
1)(也称为“独热编码”)约束,使得在任何时候,在聚类中恰好一个神经元处于激活状态(例如,具有“1”的位值)并且该聚类中的其他神经元必须处于去激活状态(例如,具有“0”的位值)。可以使用的示例聚类是针对状态矩阵x的行和列的行聚类和/或列聚类。在这些或其他实施方式中,聚类可以被组合以形成交叉聚类。例如,行聚类可以与列聚类组合以形成交叉聚类。这样的具有恰好1位约束的交叉聚类配置可以约束状态矩阵x,使得在状态矩阵x的每一行和每一列中仅一个神经元处于激活状态。
25.在一些实施方式中,可以使用聚类来减小状态矩阵x的大小。例如,对于具有恰好1位约束的给定聚类(例如,特定行),仅一个神经元可以处于激活状态,这样,不是存储指示聚类中的每个神经元的状态的值,而是替代地可以存储指示聚类中哪个神经元处于激活状态的单个索引值。在这种情况下,状态矩阵x可以由状态向量x表示。
26.另外地或可替选地,系统106可以包括被映射至优化问题以表示与系统106相对应的优化问题的伊辛能量的伊辛模型。例如,可以通过如下式(1)表示包括具有二值状态(binary states)的变量的系统的伊辛能量:
[0027][0028]
在上式(1)中,x
i
是表示对应的状态矩阵x的状态向量x的第i个变量并且可以是0或1;x
j
是个状态向量x的第j个变量并且可以是0或1;w
ij
是x的第i个变量与第j个变量之间的连接权重;并且b
i
是与第i个元素相关联的偏置。
[0029]
能量引擎102可以包括被配置成使计算系统能够执行针对其描述的一个或更多个操作的代码和例程。另外地或可替选地,可以使用硬件来实现能量引擎102,所述硬件包括
任何数目的处理器、微处理器(例如,用于执行或控制一个或更多个操作的性能)、现场可编程门阵列(fpga)、专用集成电路(asic)或其中两者或两者以上的任何合适的组合。
[0030]
可替选地或另外地,可以使用硬件和软件的组合来实现能量引擎102。在本公开内容中,被描述为由能量引擎102执行的操作可以包括能量引擎102可以引导对应系统执行的操作。
[0031]
在一些实施方式中,能量引擎102可以被配置成针对状态向量x中的一个或更多个变量随机产生(例如,经由随机处理)所提议的改变。例如,在一些实施方式中,在具有恰好1位约束的cbm中,所提议的改变可以包括将去激活的神经元改变为处于激活状态,并且因此将激活的神经元改变为处于去激活状态。因此,针对任何给定聚类,可以发生两种变化(例如,位翻转(bit filps))。另外地或可替选地,在具有恰好1位约束的交叉聚类配置(例如,行组合聚类和列组合聚类)配置中,所提议的改变可以包括四位翻转,这是因为改变特定行中的神经元的状态也影响被改变的神经元所属的列。
[0032]
在一些实施方式中,关于是否接受针对特定聚类的特定改变的确定可以基于任何合适的概率函数。在这些或其他实施方式中,概率函数可以基于可能由特定改变而引起的系统能量的变化。在一些实施方式中,可以使用lfm 110来确定系统能量的变化。
[0033]
lfm 110可以指示系统106中的变量之间的相互作用,相互作用相对于一个或更多个变量的状态变化受他们的相应权重影响。例如,可以按照式(2)如下表示lfm 110的针对系统106中的变量的值:
[0034][0035]
在式中(2),h
i
(x)是局部字段矩阵h中的第i个变量的局部字段值,其中,局部字段矩阵h中的第i个变量与对应的状态矩阵x中的第i个变量相对应;x
j
是状态向量x中的第j个变量并且可以为0或1;w
ij
是x中的第i个变量与第j个变量之间的连接权重;并且b
i
是与第i个变量相关联的偏置。
[0036]
如上面所指示的,在一些实施方式中,系统能量相对于所提议的改变的变化可以基于lfm 110。例如,对于非交叉聚类的cbm(例如,对于的cbm的行聚类),可以按照式(3)如下确定系统能量的变化:
[0037]
δe
rc
(x
rc
,k)=h
k,j
‑
h
k,i
ꢀꢀꢀ
(3)
[0038]
在式(3)中,k表示状态矩阵x的由对应的状态向量x
rc
索引的给定行,并且h
k,j
和h
k,i
与所提议的改变中涉及的神经元相对应。在式(3)中,h
k,j
是与在进行所提议的激活x
k,j
并且去激活x
k,i
的交换之前处于去激活状态的神经元x
k,j
相对应的局部字段矩阵值,并且h
k,i
是与在进行所提议的激活x
k,j
并且去激活x
k,i
的交换之前处于激活状态的神经元x
k,i
相对应的局部字段矩阵值。
[0039]
作为另一示例,对于交叉聚类的cbm(例如,对于行/列交叉聚类的cbm),可以按照式(4)如下确定系统能量的变化:
[0040]
δe
xc
(x
xc
,k,k
′
)=
‑
(h
k,l
h
k
′
,l
′
) (h
k,l
′
h
k
′
,l
)
‑
(w
k,l:k
′
,l
′
w
k,l
′
:k
′
,l
)
ꢀꢀꢀ
(4)
[0041]
在式(4)中,k和k
′
表示状态矩阵x的由对应的状态向量x
xc
索引的行;l和l
′
分别表示状态向量x
xc
中第k行和第k
′
行中激活的神经元的索引;h
k,l
、h
k
′
,l
′
、h
k,l
′
和h
k
′
,l
对应于与以上描述的提议改变中所涉及的神经元;并且w
k,l:k
′
,l
′
和w
k,l
′
:k
′
,l
对应于可以与关于所提议的
改变而讨论的神经元相对应的权重。如下面进一步详细描述的,在一些实施方式中,能量引擎102可以被配置成:基于第一矩阵112和第二矩阵114,例如通过使用下面详细描述的式(13)和式(14)中的一个或更多个来确定式(4)中w
k,l:k
′
,l
′
和w
k,l
′
:k
′
,l
的值。
[0042]
如上面所指示的,可以接受的关于是否可以接受针对一个或更多个变量的提议的改变的概率,可以基于响应于该提议改变而可能发生的系统能量的变化。例如,对于基于上式(3)确定能量的变化的非交叉聚类的cbm(例如,对于行聚类的cbm),可以按照式(5)如下确定系统中所提议的改变的接受概率:
[0043][0044]
在式(5)中,δe
rc
(x
rc
,k)可以是根据式(3)确定的能量变化,并且t可以是可以用于影响是否进行改变的比例因子。例如,t可以是执行模拟或数字退火处理例如副本交换(也称为“并行回火”)时用作比例因子的“温度”。
[0045]
作为另一示例,对于基于上式(4)确定能量变化的交叉聚类的cbm(例如,对于cbm的行/列聚类),可以按照式(6)如下确定系统中所提议的改变的接受概率:
[0046][0047]
在式(6)中,δe
rc
(x
xc
,k,k
′
)可以是根据式(4)确定的能量变化,并且t可以是比例因子,例如,上面关于式(5)描述的比例因子。
[0048]
能量引擎102可以输出系统更新104。系统更新104可以包括对系统106的更新,该更新可以响应于接受一个或更多个提议改变而发生。
[0049]
在一些实施方式中,能量引擎102可以被包括在退火系统(例如,数字退火系统或量子退火系统)中或其一部分中。在这些或其他实施方式中,能量引擎102可以被配置成针对系统106执行副本交换马尔可夫链蒙特卡洛(markov chain monte carlo)(mcmc)处理。例如,能量引擎102可以被配置成执行副本交换以查找可以使系统106的能量最小化的状态向量xmin。作为另一示例,能量引擎102可以被配置成执行副本交换以查找可以使系统106的能量最大化的状态向量xmax。副本交换可以包括同时运行系统106的m个副本但使用不同的比例因子,这些比例因子会在运行系统106的这些副本期间影响系统是否发生改变。因此,在一些实施方式中,能量引擎102可以在不同温度水平下针对系统106的多个副本执行上述更新操作。
[0050]
lfm引擎108可以被配置成基于系统106的更新来更新lfm 110,系统106的更新可以反映在系统更新104中。另外地或可替选地,lfm引擎108可以被配置成:在对求解对应的优化问题进行初始化时,首先基于系统106生成lfm 110。
[0051]
如上式(2)所指示的,lfm 110的值可以基于状态矩阵x的值以及系统106的变量之间的连接权重。系统106的连接权重可以对应于第一矩阵112和第二矩阵114。
[0052]
第一矩阵112和第二矩阵114可以每个均是可以表示对应的优化问题的、可以在系统106的变量之间创建权重的方面的矩阵。例如,对于二次分配问题(qap),第一矩阵112可以是对应的流量(flow)矩阵,并且第二矩阵可以是对应的距离(distance)矩阵。第一矩阵112和第二矩阵114可以对应于可以以与qap的流量矩阵和距离矩阵类似的方式使用的任何其他适用问题的任何其他合适的矩阵。
[0053]
lfm引擎108可以被配置成使用第一矩阵112和第二矩阵114确定可以用于更新lfm 110的权重的值。在一些实施方式中,lfm引擎108可以在每次出现新的系统更新104时持续且动态地进行该确定。lfm引擎108可以被配置成使用第一矩阵112和第二矩阵114持续地以该动态方式而不是访问所存储的包括已经存储在其中的所有权重的权重矩阵来获取权重。
[0054]
在一些实施方式中,可以使用第一矩阵112的转置和第二矩阵114的转置来获得权重。例如,在第一矩阵112和/或第二矩阵114为非对称的情况下,可以如下面进一步详细描述的使用第一矩阵112的转置和第二矩阵114的转置来确定权重。在这些或其他实施方式中,在第一矩阵112和第二矩阵114为对称的情况下,可以不使用或不需要这样的矩阵的转置。
[0055]
使用第一矩阵112和第二矩阵114代替权重矩阵可以改善环境100的存储特征和/或性能特征。例如,权重矩阵的元素数目通常比第一矩阵112和第二矩阵114中的元素数目大几个数量级。例如,权重矩阵可以具有n4个元素,并且第一矩阵112和第二矩阵114可以各自分别具有n2个元素使得经过组合他们可以具有2n2个元素。这样,代替存储权重矩阵,使用第一矩阵112和第二矩阵114确定权重可以引起显著的存储器节省。例如,第一矩阵112和第二矩阵114可以存储在计算机可读存储介质116(“crm116”)上,并且可以比用于跟踪权重值的权重矩阵占用少得多的存储空间(例如,少99%)。
[0056]
即使在可以使用和存储第一矩阵112的转置和第二矩阵114的转置的情况下,存储器节省仍然可以是相当可观的。例如,取决于n的大小,在这样的场景中存储的元素的总数可以是4n2,这仍然可以明显小于n4。
[0057]
在一些实施方式中,存储器节省可以使得lfm引擎108和crm 116能够处于同一芯片上,这可以通过减少相对于第一矩阵112和第二矩阵114存储在crm 116上的数据的获取次数来提高处理速度。因此,在一些实施方式中,lfm引擎108和其上存储有第一矩阵112和第二矩阵114的crm 116可以在同一芯片上。另外地或可替选地,lfm引擎108和其上存储有第一矩阵112和第二矩阵114的crm 116可以在不同的芯片上。
[0058]
此外,在lfm引擎108被实现为软件指令的情况下,lfm引擎108也可以与第一矩阵112和第二矩阵114存储在相同的crm 116上。另外地或可替选地,在lfm引擎108被实现为软件指令的情况下,lfm引擎108可以与第一矩阵112和第二矩阵114存储在不同的crm 116上。
[0059]
在一些实施方式中,lfm 110也可以与第一矩阵112和第二矩阵114存储在相同的crm 116上。在这些或其他实施方式中,与权重矩阵相比,经组合的lfm 110、第一矩阵112和第二矩阵114可以仍然占用更小量存储空间。
[0060]
另外地或可替选地,lfm 110可以与第一矩阵112和第二矩阵114存储在不同的crm 116上。在这些或其他实施方式中,针对一个或更多个crm的任何合适的配置,lfm 110、第一矩阵112、第二矩阵114、lfm引擎108和能量引擎102可以存储在一起或者单独存储。
[0061]
如以上所指示的,lfm引擎108可以被配置成使用第一矩阵112和第二矩阵114来更新lfm 110以确定与在系统更新104中更新的变量相对应的权重。在这些或其他实施方式中,所确定的权重可以用于更新lfm 110。
[0062]
例如,第一矩阵112和第二矩阵114可以分别是对称的流量矩阵“f”和距离矩阵“d”。此外,系统106可以包括行/列交叉聚类的玻尔兹曼机,并且系统更新104可以包括针对系统106的特定行“r”和特定列“c”的改变。在这样的情况下,可以通过确定矩阵“f”和“d”的
分别对应于系统106的特定行“r”和特定列“c”的行“f
r,*”和行“dc
,*”的张量积根据式(7)如下确定子权重矩阵“w
r,c”:
[0063][0064]
基于式(2)和(7),lfm引擎108可以根据下式(8)改变lfm 110的与系统更新104相对应的部分(“h
i,*”):
[0065]
h[i,:] =f[k
′
,i]*d[l,:] f[k,i]*d[l
′
,:]
‑
f[k,i]*d[l,:]
‑
f[k
′
,i]*d[l
′
,:]
ꢀꢀꢀ
(8)
[0066]
在式(8)中,根据“f[k
′
,i]*d[l,:] f[k,i]*d[l
′
,:]
‑
f[k,i]*d[l,:]
‑
f[k
′
,i]*d[l
′
,:]”确定的值可以与h
i,*
相加以更新lfm 110。此外,k和k’分别表示状态矩阵x的与状态变化相对应的行,并且l和l
′
分别表示被改变的变量在行k和行k
′
内的索引。
[0067]
在一些实施方式中,lfm引擎108可以被配置成处理lfm 110时依次执行对应的四个变量的相应的乘积运算和更新。例如,图1b示出了示例算法150,示例算法150可以用于在神经元(在算法150中称为“位”)x
k,l
和x
k',l'
已经被去激活并且神经元x
k’,l
和x
k,l'
已经被激活的情况下顺序地更新lfm 110,作为行/列交叉聚类的玻尔兹曼机的系统更新104的一部分。算法150被配置成以顺序方式更新lfm 110的与x
k,l
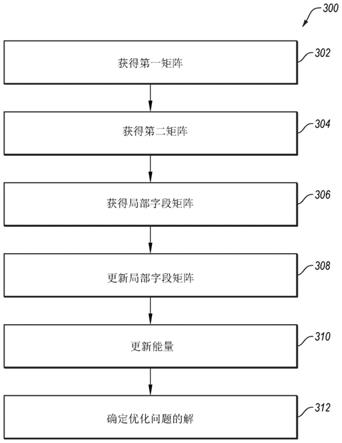
、x
k',l'
、x
k',l和
x
k,l'
相对应的元素。算法150可以使用软件和/或硬件的任何合适的实现方式实现。
[0068]
例如,图1b还示出了被配置成实现算法150的lfm引擎108的示例硬件实现方式152。在实现方式152中,所有元素可以被存储在同一芯片上。在一些实施方式中,实现方式152可以是图2的计算系统202的示例实现方式或者可以包括图2的计算系统202中的一个或更多个元素。另外地或可替选地,在一些实施方式中,实现方式152可以使用图形处理单元(gpu)和/或现场可编程门阵列(fpga)执行一个或更多个处理功能。
[0069]
此外,lfm 110可以由“h”表示,并且第一矩阵112和第二矩阵114可以分别由“f”和“d”表示。另外,在所示示例中,“h”、“f”和“d”可以存储在实现方式152中的片上存储器154上。“f”矩阵可以是“dim x dim”矩阵,并且实现方式152中的dim至1多路复用器156可以被配置成在执行算法150的运算时选择“f”的相关部分。此外,实现方式152可以包括算术元件158,算术元件158被配置成针对“f”和“d”中与算法150的当前执行的运算相关联的各个元素中的每个元素执行相关的乘法和加法运算。
[0070]
例如,算术元件158可以顺序地执行算法150的行“1”和行“2”的运算“h[i,:] =f[k
′
,i]*d[l,:]”;然后算术元件158可以执行算法150的行“3”和行“4”的运算“h[i,:] =f[k,i]*d[l
′
,:]”;然后算术元件158可以执行算法150的行“5”和行“6”的运算“h[i,:]
‑
=f[k
′
,i]*d[l
′
,:]”;并且然后,算术元件158可以执行算法150的行“7”和行“8”的运算“h[i,:]
‑
=f[k,i]*d[l,:]”。
[0071]
另外地或可替选地,lfm引擎108可以被配置成针对要处理的四个变量同时执行式(8)中的两个或更多个更新运算。例如,图1c示出了另一示例算法160,示例算法160可以用于在神经元x
k,l
和x
k',l'
已经被去激活并且神经元x
k',l
和x
k,l'
已经被激活的情况下更新lfm 110,作为行/列交叉聚类的玻尔兹曼机的系统更新104的一部分。算法160被配置成:基于
x
k,l
和x
k',l'
的去激活,在大致相同的时间更新lfm 110中与x
k,l
和x
k',l'
相对应的元素。算法160还被配置成:基于x
k',l
和x
k,l'
的激活,在大致相同的时间更新与x
k',l
和x
k,l'
相对应的元素。这样,算法160可以是算法150的大约两倍的速度。算法160可以使用软件和/或硬件的任何合适的实现方式实现。
[0072]
例如,图1c还示出了被配置成实现算法160的lfm引擎108的示例硬件实现方式162。在实现方式162中,所有元素可以被存储在同一芯片上。在一些实施方式中,实现方式162可以是图2的计算系统202的示例实现方式或者可以包括图2的计算系统202中的一个或更多个元素。另外地或可替选地,在一些实施方式中,实现方式162可以使用图形处理单元(gpu)和/或现场可编程门阵列(fpga)执行一个或更多个处理功能。
[0073]
此外,lfm 110可以由“h”表示,并且第一矩阵112和第二矩阵114可以分别由“f”和“d”表示。另外,在所示示例中,“h”、“f”和“d”可以存储在实现方式162中的片上存储器164上。“f”矩阵可以是“dimx dim”矩阵,并且实现方式162中的dim至1多路复用器166可以被配置成在执行算法160的运算时选择“f”的相关部分。
[0074]
此外,实现方式162可以包括算术元件168a,算术元件168a被配置成针对“f”和“d”的对应元素执行算法160的行“1”和行“2”的乘法和加法运算。另外地或可替选地,实现方式162可以包括算术元件168b,算术元件168b被配置成针对“f”和“d”的对应元素执行算法160的行“3”和行“4”的相关乘法和加法运算。在这些或其他实施方式中,实现方式162可以包括移位寄存器165,移位寄存器165被配置成使得“f”中适当的值在适当的时间被发送至算术元件168b。
[0075]
作为另一示例,图1d示出了另一示例算法170,示例算法170可以用于在神经元x
k,l
和x
k',l'
已经被去激活并且神经元x
k',l
和x
k,l'
已经被激活的情况下更新lfm 110,作为行/列交叉聚类的玻尔兹曼机的系统更新104的一部分。算法170被配置成在大致相同的时间更新lfm 110中与x
k,l
、x
k',l'
、x
k’,l
和x
k,l'
相对应的元素。这样,算法170可以是算法160的大约两倍的速度,并且可以是算法150的大约四倍的速度。算法170可以使用软件和/或硬件的任何合适的实现方式实现。
[0076]
例如,图1d还示出了被配置成实现算法170的lfm引擎108的示例硬件实现方式172。在实现方式172中,所有元素可以被存储在同一芯片上。在一些实施方式中,实现方式172可以是图2的计算系统202的示例实现方式或者可以包括图2的计算系统202中的一个或更多个元素。另外地或可替选地,在一些实施方式中,实现方式172可以使用图形处理单元(gpu)和/或现场可编程门阵列(fpga)执行一个或更多个处理功能。
[0077]
此外,lfm 110可以由“h”表示,并且第一矩阵112和第二矩阵114可以分别由“f”和“d”表示。另外,在所示示例中,“h”、“f”和“d”可以存储在实现方式172中的片上存储器174上。“f”矩阵可以是“dim x dim”矩阵,并且实现方式172中的dim至1多路复用器176可以被配置成在执行算法170的运算时选择“f”的相关部分。
[0078]
此外,实现方式172可以包括算术元件178a、算术元件178b、算术元件178c和算术元件178d。算术元件178a可以被配置成针对“f”和“d”的对应元素执行算法170的行“2”的乘法和加法运算“h[i,:] =f[k
′
,i]*d[l,:]”。算术元件178b可以被配置成针对“f”和“d”的对应元素执行算法170的行“3”的乘法和加法运算“h[i,:]
‑
=f[k,i]*d[l,:]”。算术元件178c可以被配置成针对“f”和“d”的对应元素执行算法170的行“2”的乘法和加法运算“h
[i,:] =f[k,i]*d[l
′
,:]”。算术元件178d可以被配置成针对“f”和“d”的对应元素执行算法170的行“3”的乘法和加法运算“h[i,:]
‑
=f[k
′
,i]*d[l
′
,:]”。
[0079]
在这些或其他实施方式中,实现方式172可以包括移位寄存器175a,移位寄存器175a被配置成使得“f”的适当值在适当的时间被发送至算术元件178b和178d。在这些或其他实施方式中,实现方式172可以包括移位寄存器175b,移位寄存器175b被配置成使得“d”的适当值在适当的时间被发送至算术元件178a和178b。
[0080]
作为另一示例,在一些实施方式中,可以简化式(8)使得lfm引擎108可以根据下式(9)同时更新lfm 110中要处理的四个元素:
[0081]
h[i,:] =(f[k
′
,i]
‑
f[k,i])*(d[l,:]
‑
d[l
′
,:])
ꢀꢀꢀ
(9)
[0082]
图1e示出了另一示例算法180,示例算法180可以用于基于式(9),在x
k,l
和x
k',l'
已经被去激活并且神经元x
k',l
和x
k,l'
已经被激活的情况下更新lfm 110,作为行/列交叉聚类的玻尔兹曼机的系统更新104的一部分。算法180被配置成在大致相同的时间更新lfm 110中与x
k,l
、x
k',l'
、x
k',l
和x
k,l'
相对应的元素。这样,算法180可以是算法160的大约两倍的速度,并且可以是算法150的大约四倍的速度。算法180可以使用软件和/或硬件的任何合适的实现方式实现。
[0083]
例如,图1e还示出了被配置成实现算法180的lfm引擎108的示例硬件实现方式182。在实现方式182中,所有元素可以被存储在同一芯片上。在一些实施方式中,实现方式182可以是图2的计算系统202的示例实现方式或者可以包括图2的计算系统202中的一个或更多个元素。另外地或可替选地,在一些实施方式中,实现方式182可以使用图形处理单元(gpu)和/或现场可编程门阵列(fpga)执行一个或更多个处理功能。
[0084]
此外,lfm 110可以由“h”表示,并且第一矩阵112和第二矩阵114可以分别由“f”和“d”表示。另外,在所示示例中,“h”、“f”和“d”可以存储在实现方式182中的片上存储器184上。此外,在实现方式182中,“f”和“d”可以被存储两次以帮助提高执行算法180的速度。“f”矩和“d”矩阵可以每个均是“dim x dim”矩阵。实现方式182中的dim至1多路复用器186a和186b可以被配置成在执行算法180的运算时选择“f”和“d”的相关部分。
[0085]
此外,实现方式182可以包括算术元件188a、算术元件188b和算术元件188c。算术元件188a可以被配置成针对“f”的对应元素执行算法180的行“3”的加法运算“f[k
′
,i]
‑
f[k,i]”以获得“f
diff”。算术元件188b可以被配置成针对“d”的对应元素执行算法180的行“1”的加法运算“d[l,:]
‑
d[l
′
,:]”以获得“d
diff
[:]”。算术元件188c可以被配置成针对由算术元件188a和算术元件188b提供的结果执行算法180的行“4”的乘法和加法运算“h[i,:] =f
diff
*d
diff
[:]”。
[0086]
图1f还示出了被配置成实现算法180的lfm引擎108的示例硬件实现方式192。在实现方式192中,所有元素可以被存储在同一芯片上。在一些实施方式中,实现方式192可以是图2的计算系统202的示例实现方式或者可以包括图2的计算系统202中的一个或更多个元素。另外地或可替选地,在一些实施方式中,实现方式192可以使用图形处理单元(gpu)和/或现场可编程门阵列(fpga)执行一个或更多个处理功能。
[0087]
此外,lfm 110可以由“h”表示,并且第一矩阵112和第二矩阵114可以分别由“f”和“d”表示。另外,在所示示例中,“h”、“f”和“d”可以存储在实现方式192中的片上存储器194上。“f”矩阵可以是“dim x dim”矩阵。实现方式192中的dim至1多路复用器196可以被配置
成在执行算法180的运算时选择“f”的相关部分。
[0088]
此外,实现方式192可以包括算术元件198a、算术元件198b和算术元件198c。算术元件198a可以被配置成针对“f”的对应元素执行算法180的行“3”的加法运算“f[k
′
,i]
‑
f[k,i]”。算术元件198b可以被配置成针对“d”的相应元素执行算法180的行“1”的加法运算“d[l,:]
‑
d[l
′
,:]”。算术元件198c可以被配置成针对由算术元件198a和算术元件198b提供的结果执行算法180的行“4”的乘法和加法运算“h[i,:] =f
diff
*d
diff
[:]”。
[0089]
在这些或其他实施方式中,实现方式192可以包括移位寄存器195a,移位寄存器195a被配置成使得“f”的适当值在适当的时间被发送至算术元件198a。在这些或其他实施方式中,实现方式192可以包括移位寄存器195b,移位寄存器195b被配置成使得“d”的适当值在适当的时间被发送至算术元件198b。
[0090]
返回至图1a,在一些实施方式中,第一矩阵112和/或第二矩阵114可以是非对称的。在这些或其他实施方式中,可以针对非对称矩阵执行一个或更多个预处理操作以使其对称。另外地或可替选地,在一些这样的情况下(例如,没有执行预处理或不能使非对称矩阵对称的情况),可以基于转置的第一矩阵112和/或转置的第二矩阵114来确定权重以更新lfm 110。
[0091]
例如,第一矩阵112和第二矩阵114可以分别是对称的流量矩阵“f”和距离矩阵“d”。在这样的情况下,可以通过如以上所描述的确定矩阵“f”和“d”的行“f
r,*”和“d
c,*”的张量积同时还考虑矩阵“f”和“d”各自的转置矩阵“f
t”和“d
t”的“(f
t
)
r,*”和“(d
t
)
c,*”的张量积来分别根据式(10a)或(10b)如下确定子权重矩阵“w
r,c”:
[0092][0093][0094]
基于式(2)和式(10a),可以在这样的非对称情况下,根据下式(11a)改变lfm 110中与系统更新104相对应的部分(“h
i,*”):
[0095]
h[i,:] =f[k
′
,i]*d[l,:] f[k,i]*d[l
′
,:]
‑
f[k,i]*d[l:]
‑
f[k
′
,i]*d[l
′
,:] f[i,k
′
]*(d[:,l])
t
f[i,k]*(d[:,l
′
])
t
—f[i,k]*(d[:,l])t—f[i,k
′
]*(d[:,l
′
])
t
ꢀꢀꢀ
(11a)
[0096]
另外地或可替选地,基于式(2)和(10b),可以在这样的非对称情况下,根据下式(11b)改变lfm 110中与系统更新104相对应的部分(“h”),这可以改善缓存区:
[0097]
h[i,:] =f[k
′
,i]*d[l,:] f[k,i]*d[l
′
,:]
‑
f[k,i]*d[l,:]
‑
f[k
′
,i]*d[l
′
,:] f
t
[k
′
,i]*d
t
[l,:] f
t
[k,i]*d
t
[l
′
,:]
‑
f
t
[k,i]*d
t
[l,:]
‑
f
t
[k
′
,i]*d
t
[l
′
,:]
ꢀꢀꢀ
(11b)
[0098]
在一些实施方式中,可以对以上关于图1b至图1f描述的算法和/或硬件实现方式进行一个或更多个变型,以使得针对非对称矩阵执行的附加操作可以进行。例如,转置的“f”矩阵和转置的“d”矩阵也可以存储在片上存储器中。此外,可以使用一个或更多个算术元件、多路复用器和/或寄存器,以使得执行的附加操作可以进行。另外地或可替选地,可以顺序地执行式(11a)和(11b)中的一个或更多个运算。在这些或其他实施方式中,可以将式(11a)和(11b)中的两个或更多个运算一起执行。另外地或可替选地,可以在大致相同的时
间执行式(11a)和(11b)中的全部运算。
[0099]
例如,在一些实施方式中,可以简化式(11a),使得lfm引擎108可以根据下式(12a)同时更新lfm 110中要处理的四个元素:
[0100]
h[i,:] =(f[k
′
,i]
‑
f[k,i])*(d[l,:]
‑
d[l
′
,:]) (f[i,k
′
]
‑
f[i,k])*(d[:l]
‑
d[:,l
′
])
t
ꢀꢀꢀ
(12a)
[0101]
另外地或可替选地,可以根据下式(12b)来简化式(11b):
[0102]
h[i,:] =(f[k
′
,i]
‑
f[k,i])*(d[l,:]
‑
d[l
′
,:]) (ft[k
′
,i]
‑
ft[k,i])*(dt[l,:]
‑
d
t
[l
′
,:])
ꢀꢀꢀ
(12b)
[0103]
如在一些实施方式中所描述的,能量引擎102可以使用更新的lfm110来生成新的系统更新104。例如,能量引擎102可以基于上面的式(3)或式(4)使用lfm 110的更新值来更新系统106的能量值。在这些或其他实施方式中,能量引擎102可以被配置成基于第一矩阵112和第二矩阵114确定式(4)中(w
k,l:k
′
,l
′
w
k,l
′
:k
′
,l
)的值。
[0104]
例如,在第一矩阵112和第二矩阵114是对称的“f”矩阵和“d”矩阵的情况下,能量引擎102可以根据式(13)如下确定式(4)中(w
k,l:k
′
,l
′
w
k,l
′
:k
′
,l
)的值:
[0105]
(w
k,l:k
′
,l
′
w
k,l
′
:k
′
,l
)=
‑
2f
k,k’d
l,l’ꢀꢀꢀ
(13)
[0106]
作为另一示例,在第一矩阵112和第二矩阵114是非对称的“f”矩阵和“d”矩阵的情况下,能量引擎102可以根据式(14)如下确定式(4)中(w
k,l:k
′
,l
′
w
k,l
′
:k
′
,l
)的值:
[0107]
(w
k,l:k
′
,l
′
w
k,l
′
:k
′
,l
)=
‑
(f
k,k’ f
k’,k
)(d
l,l’ d
l’,l
)
ꢀꢀꢀ
(14)
[0108]
然后,能量引擎102可以利用上面的式(5)或式(6),使用更新的能量值来确定是否接受对系统106的提议改变。然后,lfm引擎108还可以基于如上所述的新的系统更新104再次更新lfm 110。在一些实施方式中,可以迭代地执行这样的操作直至获得与系统106相关联的优化问题的解。例如,可以执行这些操作直至系统106的状态与最大或最小伊辛能量相关联。
[0109]
在不脱离本公开内容的范围的情况下可以对图1a至图1f进行修改、添加或省略。例如,关于图1b至图1f描述的算法和实现方式仅是示例而不是限制性的。另外,尽管被图示和描述为彼此分开,但是在一些实施方式中,能量引擎102和lfm引擎108可以组合。另外地或可替选地,被描述为由能量引擎102和/或lfm引擎108执行的操作可以通过可能与本文所描述的实现方式并不完全相同的任何适用的实现方式执行。另外地,环境100可以包括比本公开内容中示出和描述的元素多或少的元素。此外,特定装置或系统中元件的特定配置、关联或包含可以根据特定实现方式而变化。
[0110]
图2示出了根据本公开内容的至少一个实施方式的被配置成执行本文所描述的一个或更多个操作的示例计算系统202的框图。例如,在一些实施方式中,计算系统202可以被配置成实施或指导与图1a中的能量引擎102和/或lfm 108相关联的一个或更多个操作。在一些实施方式中,计算系统202可以被包括在退火系统中或形成退火系统的一部分。计算系统202可以包括处理器250、存储器252和数据存储装置254。处理器250、存储器252和数据存储装置254可以通信地耦接。
[0111]
通常,处理器250可以包括任何适当的专用或通用计算机、计算实体、或包括各种计算机硬件或软件模块的处理装置,并且可以被配置成执行存储在任何适用的计算机可读存储介质上的指令。例如,处理器250可以包括微处理器、微控制器、数字信号处理器(dsp)、
专用集成电路(asic)、现场可编程门阵列(fpga)、图形处理单元(gpu)或者被配置成解译和/或执行程序指令和/或处理数据的任何其他数字电路系统或模拟电路系统。尽管在图2中被示出为单个处理器,但是处理器250可以包括被配置成单独地或共同地执行或指导执行在本公开内容中描述的任何数量的操作的任何数量的处理器。另外地,处理器中的一个或更多个处理器可以存在于一个或更多个不同的电子装置(例如,不同的服务器)上。
[0112]
在一些实施方式中,处理器250可以被配置成:解译和/或执行存储在存储器252、数据存储装置254、或者存储器252和数据存储装置254中的程序指令,并且/或者对存储在存储器252、数据存储装置254、或者存储器252和数据存储装置254中的数据进行处理。在一些实施方式中,处理器250可以从数据存储装置254获取程序指令并将程序指令加载到存储器252中。在程序指令被加载到存储器252中之后,处理器250可以执行程序指令。例如,在一些实施方式中,图1a中的能量引擎102和/或lfm引擎108可以是作为可以被加载到存储器252中并由处理器250执行的程序指令的软件模块。
[0113]
存储器252和数据存储装置254可以包括载有或具有存储在其上的计算机可执行指令或数据结构的计算机可读存储介质。这样的计算机可读存储介质可以包括可由通用或专用计算机(例如,处理器250)访问的任何可用的非暂态介质。作为示例而非限制,这样的计算机可读存储介质可以包括有形的或非暂态计算机可读存储介质,包括:随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、致密盘只读存储器(cd
‑
rom)或其他光盘存储装置、磁盘存储装置或其他磁存储装置、闪速存储器装置(例如,固态存储器装置)、或可以用于以计算机可执行指令或数据结构的形式承载或存储特定程序代码并且可以由通用或专用计算机访问的任何其他非暂态存储介质。在这些和其他实施方式中,如本公开内容中所说明的术语“非暂态”应当被解释为仅排除被发现落在in re nuijten,500f.3d 1346(fed.cir.2007)的联邦巡回法院判决(federal circuit decision)中的可取得专利的主题的范围之外的这些类型的暂态介质。
[0114]
以上的组合也可以被包括在计算机可读存储介质的范围内。例如,计算机可执行指令可以包括被配置成使处理器250执行特定操作或一组操作的指令和数据。
[0115]
可以在不脱离本公开内容的范围的情况下对计算系统202进行修改、添加或省略。例如,在一些实施方式中,计算系统202可以包括可能未明确示出或描述的任何数量的其他组件。另外地或可替选地,计算系统202可以包括较少的元件或者被不同地配置。例如,存储器252和/或数据存储装置254可以被省略或者可以是相同的计算机可读存储介质的一部分。另外,在本公开内容中对硬件或由硬件执行的操作的引用可以指计算系统202的一个或更多个元件的任何适用的操作、配置或组合。
[0116]
图3示出了根据本公开内容中描述的至少一个实施方式的求解优化问题的示例方法300的流程图。方法300可以由任何合适的系统、设备或装置执行。例如,图1a中的能量引擎102和/或lfm引擎108或者图2中的计算系统202可以执行与方法300相关联的一个或更多个操作。尽管用离散的块示出,但是根据特定的实现方式,与方法300的一个或更多个块相关联的步骤和操作可以被划分为附加的块、被组合成更少的块或者被去除。
[0117]
在块302处,可以获得与和系统相关联的优化问题相关联的第一矩阵。获得第一矩阵可以包括访问存储在计算机可读介质中的第一矩阵。另外地或可替选地,获得第一矩阵可以包括将第一矩阵存储在计算机可读介质中。
[0118]
图1a中的第一矩阵112可以是第一矩阵的示例。在一些实施方式中,优化问题可以是二次分配问题,并且第一矩阵可以是二次分配问题的距离矩阵。在一些实施方式中,第一矩阵可以是对称的。另外地或可替选地,第一矩阵可以是非对称的。在第一矩阵为非对称的一些情况下,可以对第一矩阵执行一个或更多个适用的操作以使其对称。
[0119]
在一些实施方式中,可以将第一矩阵存储在包括被配置成执行方法300的操作的处理器的芯片的本地存储器中。另外地或可替选地,可以将第一矩阵存储在与被配置成执行方法300的操作的处理器不在同一芯片上的存储器或数据存储装置中。
[0120]
在一些实施方式中,可以获得作为第一矩阵的转置的经转置的第一矩阵。例如,可以在第一矩阵为非对称的情况下获得经转置的第一矩阵。在一些情况下,经转置的第一矩阵可能已经被创建并且可以通过被访问或存储来获得。另外地或可替选地,可以通过针对第一矩阵执行适用的转置操作来生成经转置的第一矩阵。
[0121]
在一些实施方式中,可以将经转置的第一矩阵存储在包括被配置成执行方法300的操作的处理器的芯片的本地存储器中。另外地或可替选地,可以将经转置的第一矩阵存储在与被配置成执行方法300的操作的处理器不在同一芯片上的存储器或数据存储装置中。
[0122]
在块304处,可以获得与优化问题相关联的第二矩阵。获得第二矩阵可以包括访问存储在计算机可读介质中的第二矩阵。附加地或可替选地,获得第二矩阵可以包括将第二矩阵存储在计算机可读介质中。
[0123]
图1a中的第二矩阵114可以是第二矩阵的示例。在一些实施方式中,优化问题可以是二次分配问题,并且第二矩阵可以是二次分配问题的流量矩阵。在一些实施方式中,第二矩阵可以是对称的。另外地或可替选地,第二矩阵可以是非对称的。在第二矩阵为非对称的一些情况下,可以对第二矩阵阵执行一个或更多个适用的操作以使其对称。
[0124]
在一些实施方式中,可以将第二矩阵存储在包括被配置成执行方法300的操作的处理器的芯片的本地存储器中。另外地或可替选地,可以将第二矩阵存储在与被配置成执行方法300的操作的处理器不在同一芯片上的存储器或数据存储装置中。
[0125]
在一些实施方式中,可以获得作为第二矩阵的转置的经转置的第二矩阵。例如,可以在第二矩阵为非对称的情况下获得经转置的第二矩阵。在一些情况下,经转置的第二矩阵可能已经被创建并且可以通过被访问或存储来获得。另外地或可替选地,可以通过针对第二矩阵执行适用的转置操作来生成经转置的第二矩阵。
[0126]
在一些实施方式中,可以将经转置的第二矩阵存储在包括被配置成执行方法300的操作的处理器的芯片的本地存储器中。另外地或可替选地,可以将经转置的第二矩阵存储在与被配置成执行方法300的操作的处理器不在同一芯片上的存储器或数据存储装置中。
[0127]
第一矩阵和第二矩阵可以与赋予系统中的各个变量的对应权重有关,其中,所述对应权重同各个变量与系统中的一个或更多个其他变量之间的关系有关。系统可以包括可以用于求解优化问题和/或可以对应于优化问题的任何适用系统。图1a中的系统106是系统的示例。
[0128]
在块306处,可以获得与优化问题相关联的局部字段矩阵。局部字段矩阵可以是指示系统的变量之间的受他们的相应权重影响的相互作用的矩阵,其中,相互作用与求解优
化问题期间变量的状态变化有关。图1a中的lfm 110是可以获得的局部字段矩阵的示例。
[0129]
获得局部字段矩阵可以包括访问存储在计算机可读介质中的局部字段矩阵。另外地或可替选地,获得局部字段矩阵可以包括将局部字段矩阵存储在计算机可读介质中。在一些实施方式中,获得局部字段矩阵可以包括基于系统的状态变量矩阵并且基于第一矩阵和第二矩阵来生成局部字段矩阵。附加地或可替选地,可以基于第一转置矩阵和/或第二转置矩阵来生成局部字段矩阵。例如,可以基于以上关于图1a描述的式(2)以及式(7)至式(11)中的一个或更多个来生成局部字段矩阵。
[0130]
在块308处,可以对局部字段矩阵进行更新。在一些实施方式中,可以在求解优化问题期间响应于系统中一个或更多个变量的状态变化来更新局部字段矩阵。如上所述,可以基于针对系统确定的能量值来接受状态变化。
[0131]
局部字段矩阵的更新可以包括针对第一矩阵的第一部分和第二矩阵的第二部分执行一个或更多个算术运算,第一矩阵的第一部分和第二矩阵的第二部分与局部字段矩阵的对应于要更新的一个或更多个变量的第三部分相对应。在这些或其他实施方式中,更新可以包括针对经转置的第一矩阵和/或经转置的第二矩阵执行一个或更多个算术运算(例如,在第一矩阵和/或第二矩阵为非对称的情况下)。
[0132]
例如,在一些实施方式中,可以如以上关于图1a至图1f所描述的,通过针对第一矩阵的第一部分与第二矩阵的第二部分之间的差执行一个或更多个张量积运算来更新局部字段矩阵。附加地或可替选地,所述算术运算还包括如以上关于图1a至图1f所描述的针对经转置的第一矩阵和经转置的第二矩阵的一个或更多个张量积运算。
[0133]
如以上所指示的,可以通过基于第一矩阵和第二矩阵(并且在某些情况下,基于经转置的第一矩阵和经转置的第二矩阵)动态确定权重来执行更新,使得可以省略对全局权重矩阵的存储。如以上所指示的,省略对全局权重矩阵的存储可以减少可用于求解优化问题的存储器资源的数量。此外,还如以上所描述的,通过启用对求解优化问题中使用的信息的片上存储,减少存储器资源的数量还可以减少求解优化问题的时间量。
[0134]
在块310处,可以基于更新的局部字段矩阵来更新系统的能量值。例如,可以基于上面的式(3)或式(4)利用局部字段矩阵的更新值来更新系统的能量值。
[0135]
在块312处,可以基于能量值确定优化问题的解。例如,可以以迭代的方式更新系统并且因此可以使局部字段矩阵被更新任意次,直至系统的状态与具有最大或最小伊辛能量的能量值相关联。这样的情况下的系统状态可以被用作优化问题的解。
[0136]
在不脱离本公开内容的范围的情况下,可以对方法300进行修改、添加或省略。例如,可以以不同的顺序实现方法300的操作。另外地或可替选地,可以同时执行两个或更多个操作。此外,概述的操作和动作仅作为示例提供,并且在不脱离所公开的实施方式的实质的情况下,某些操作和动作可以是可选的、可以被组合成较少的操作和动作或者可以被扩展成其他操作和动作。
[0137]
如本文所使用的,术语“模块”或“组件”可以指被配置成执行模块或组件的操作的特定硬件实现以及/或者可以存储在计算系统的通用硬件(例如,计算机可读介质、处理装置等)上和/或由计算系统的通用硬件执行的软件对象或软件例程。在一些实施方式中,本文描述的不同组件、模块、引擎和服务可以被实现为在计算系统上执行的对象或进程(例如,作为单独的线程)。虽然本文描述的一些系统和方法通常被描述为以(存储在通用硬件
上和/或由通用硬件执行的)软件实现,但是特定的硬件实现或软件实现和特定的硬件实现的组合也是可能的并且是可预期的。在本说明书中,“计算实体”可以是如本文先前定义的任何计算系统,或者在计算系统上运行的任何模块或模块的组合。
[0138]
在本公开内容中并且特别是在所附权利要求书(例如,所附权利要求书的正文)中使用的术语通常旨在作为“开放式”术语(例如,术语“包括”应当理解为“包括但不限于”,术语“具有”应当理解为“至少具有”,术语“包含”应当理解为“包含但不限于”等)。
[0139]
另外地,如果意在表达特定数目的引入的权利要求叙述,则这样的意图将在权利要求书中明确记载,并且在没有这样的叙述的情况下,不存在这样的意图。例如,为帮助理解,所附权利要求书可以包含介绍性短语“至少一个”和“一个或更多个”的使用以引入权利要求叙述。然而,即使当同一权利要求包括引导性短语“一个或更多个”或“至少一个”以及不定冠词如“一”或“一个”时(例如,“一”和/或“一个”应当被解释为意指“至少一个”或“一个或更多个”),对这样的短语的使用也不应被解释为暗含由不定冠词“一”或“一个”引入的权利要求叙述将包含这样引入的权利要求叙述的任何特定权利要求限制为仅包含一个这样叙述的实施方式;这同样适用于对用于引入权利要求叙述的定冠词的使用。
[0140]
此外,即使明确地记载了特定数量的引入的权利要求叙述,本领域技术人员也将认识到,这样的叙述应当被解释为至少意指所记载的数量(例如,没有其他修饰语的“两个叙述”的无修饰叙述意指至少两个叙述,或者两个或更多个叙述)。此外,在使用类似于“a、b和c中的至少之一等”或“a、b和c中的一个或更多个等”的惯用语的情况下,通常这样的构造旨在包括仅a、仅b、仅c、a和b一起、a和c一起、b和c一起或a、b和c一起等。另外,术语“和/或”的使用旨在以这种方式来解释。
[0141]
此外,呈现两个或更多个替选术语的任何分隔词或短语,不论在说明书、权利要求书还是附图中,都应当被理解为考虑包括所述术语中的一个、所述术语中的任何一个或者所有术语的可能性。例如,即使在其他地方使用术语“和/或”,短语“a或b”也应当被理解为包括“a”或“b”或“a和b”的可能性。
[0142]
本公开内容中叙述的所有示例和条件语言旨在用于教导目的以帮助读者理解本公开内容和发明人为了促进本领域而贡献的构思,并且应当被解释为不限于这样的具体叙述的示例和条件。尽管详细地描述了本公开内容的实施方式,但是在不脱离本公开内容的主旨和范围的情况下可以对这些实施方式进行各种改变、替换和更改。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
