1.本发明针对消失模铸造生产的柔性作业车间调度问题,具体涉及一种基于知识驱动的柔性离散制造生产调度优化方法。
背景技术:
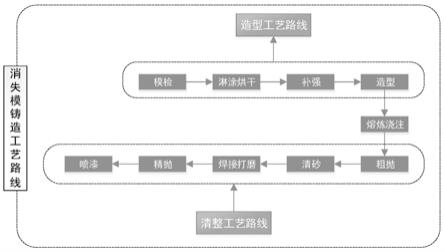
2.消失模铸造(epc)技术是一种新型铸造技术,由于铸造工艺本身的特点,消失模铸造车间调度问题存在许多局限性,如具有批处理机的柔性作业车间和时间执行窗口(time execution window,tew)等,极大增加了调度问题的难度和复杂性,它的工艺路线如图1所示,特点如下:
3.1、在作业车间操作环境下为每个作业确定加工路线。
4.2、批处理机可以同时加工多个作业,单处理机一次只能加工一个作业。
5.3、特殊工序的加工时间受到限制。
6.4、一种加工资源只能加工某种特定的工序。
7.许多关于铸造行业的调度研究集中于批量加工调度和流水车间调度,很少涉及到铸造工艺中遇到的批量柔性作业车间调度问题。原因如下:
8.1、fcjsp的一些实际调度因素增加了数学建模的难度。
9.2、批处理机增加了另一维度的复杂性。
10.3、现有研究很难在不修正的情况下解决fcjsp问题。
技术实现要素:
11.本发明的上述技术问题主要是通过下述技术方案得以解决的:
12.基于知识驱动的柔性离散制造生产调度优化方法,其特征在于:基于以下目标函数和约束条件:
13.目标成本函数为:
14.根据tew机制,需要划分开始熔炼的工序的时间周期;如式(1)所示,cid是ji的先前熔炼工序的完成时间,“ceil”表示取整;例如,如果cid=20,计算出的d
i
=2,j
i
是在第2天进行批处理的候选任务;
[0015][0016]
要确定以最短完工时间(即作业的最大完成时间)为目标的调度结果(即作业的最大完成时间);问题的数学公式描述如下:
[0017][0018]
其约束条件为:
[0019]
不等式(3)表示启动时间o
ij
与完成时间o
ij
之间的约束关系;不等式(4)保证开始
时间o
i(j 1)
必须不小于完成时间o
ij
;不等式(3)和(4)保证了作业i的工序顺序约束;
[0020]
s
ij
x
ijk
×
p
ijk
≤c
ij
i∈{1,2
…
,n};j∈{1,2
…
,ni};k∈mij
ꢀꢀ
(3)
[0021]
c
ij
≤s
i(j 1)
i∈{1,2
…
,n};j∈{1,2
…
,ni
‑
1}
ꢀꢀ
(4)
[0022]
式(5)表示该工序在同一时间只能被同一资源加工;此外,这意味着每道工序只能从候选资源集中选择一个资源;
[0023][0024]
式(6)保证每个任务对于每个批工序只能分配到一个批计划中;
[0025][0026]
约束(7)表示每种资源只能加工一道特定的工序;m
il
表示工序o
il
的候选资源集;
[0027][0028]
不等式(8)和式(9)表明,特殊工序必须在特定的时间段内进行加工,这代表了tew机制;其中,由式(1)计算出的d
i
表示作业i的时间段,j=s表示作业o
ij
,其中a为特定时间段内需要处理的特定工序;
[0029]
v
ijk
×
s
ij
≥(d
i
×
24) 15i∈{1,2
…
,n};j=s;k∈mij
ꢀꢀ
(8)
[0030]
v
ijk
×
s
ij
p
ijk
≤(d
i
×
24) 23i∈{1,2
…
,n};j=s;k∈mij
ꢀꢀ
(9)
[0031]
不等式(10)指定批处理中作业的总权重不能超过资源总量;
[0032][0033]
具体包括:
[0034]
步骤1、初始化参数后,采用了三种种群初始化策略进行粒子初始化,包括最短加工时间(spt)策略、剩余作业时间最长(mwr)策略、随机初始化策略;
[0035]
步骤2、编码与解码,采用将连续粒子位置映射到作业离散调度的编码方法;在fcjsp(柔性铸造车间调度问题)中,每个粒子由两部分序列组成:o序列和r序列。o序列定义为工序的序列,r序列定义为每道工序的资源选择;
[0036]
步骤3、pso用于全局搜索,采用连续和离散更新策略,以提高串行混合模式下的全局搜索能力;连续部分引入时变压缩因子以保证收敛稳定性;离散部分采用了保持序交叉(pox),并设计了一种基于过程的资源交叉(prx)方法来提高搜索效率;
[0037]
步骤4、基于知识驱动的局部禁忌搜索,具体包括:
[0038]
步骤4.1定义禁忌搜索:选择历史极值gbest,作为ts的高质量解决方案的初始解;
[0039]
步骤4.2基于知识驱动的局部搜索,将邻域结构i的经验可能性初始化为p
nsi
(0)=1/tn;tn是邻域结构的总数;在每一代中,利用邻域结构生成解构造的基于知识的经验更新可能性,如下所示:
[0040][0041]
其中ns
i
是邻域结构i的经验,即使用邻域结构i对当前解决方案进行改进的次数。
[0042]
在上述的基于知识驱动的柔性离散制造生产调度优化方法,对模型的环境定义如下:
[0043]
(1)将机器设备、加工组、工人统称为加工资源;
[0044]
(2)在0时刻,所有作业被发布,所有机器都可用;0时刻是第一天的8点;
[0045]
(3)加工一旦开始就不能中断;
[0046]
(4)同一作业的工序有先后顺序,但不同作业之间的工序没有优先级之分;
[0047]
(5)将相邻两道工序之间的搬运时间和启动时间合并到加工时间中。
[0048]
在上述的基于知识驱动的柔性离散制造生产调度优化方法,所述参数和决策变量包括:m为加工资源总数;n为作业总数;i为作业索引,i=1,2
…
,n;j为工序索引,j=1,2
…
,n
i
,如果j=s,即为熔炼工序;k为资源索引,k=1,2
…
,m;为j
i
第i个作业;n
i
为作业i的总工序数;b
j
为第j道工序的总批次号;d
i
为作业i的熔炼日期;o
ij
为作业i的第j道工序;m
ij
为作业i的第j道工序的可选资源集;b
jb
为第j道工序第b批次作业集;t
jb
为第j道工序中第b个批次的加工时间;w
jb
为第j道工序中第b个批次的总权重;s
ij
为作业i中第j道工序的开始时间;c
ij
为作业i第j道工序的完成时间;c
im
为作业i的完成时间;c
k
为资源k的加工能力;p
ijk
为资源k中o
ij
工序的加工时间;且
[0049][0050][0051][0052]
在上述的基于知识驱动的柔性离散制造生产调度优化方法,所述三种种群初始化策略具体方式如下:最短加工时间(spt)策略、剩余作业时间最长(mwr)策略、随机初始化策略;最短加工时间(spt)策略是选择加工时间最短的工序,以缩短完工时间;剩余作业时间最长(mwr)策略将一个作业中剩余的总加工时间按优先级排序,用于优化资源分配;随机初始化策略随机生成工序和资源的顺序,丰富种群多样性;这三种初始化策略的比例为0.3:0.3:0.4。
[0053]
在上述的基于知识驱动的柔性离散制造生产调度优化方法,所述编码解码采用块集成解码(bid)规则;bid规则是将编码集分为柔性块和批处理块,每个块通过相应的解码方法进行解码。
[0054]
在上述的基于知识驱动的柔性离散制造生产调度优化方法,所述采用连续和更新策略具体方式为:
[0055]
连续部分引入时变压缩因子以保证收敛稳定性;离散部分采用了保持序交叉(pox),并设计了一种基于过程的资源交叉(prx)方法来提高搜索效率。
[0056]
在上述的基于知识驱动的柔性离散制造生产调度优化方法,所述基于知识驱动的局部搜索禁忌搜索具体方式为:
[0057]
选择历史极值gbest,作为ts的高质量解决方案的初始解,新的禁忌对象进入队列的头部,而其他对象移动到队列的末尾;如果没有移动空间,第一个进入队列的对象将被释放;式(11)和(12)表示禁忌表的长度,禁忌表的长度随迭代周期动态变化;这里,k是一个与参数相关联的动态禁忌表,t
max
是最大迭代次数;
[0058][0059]
δ=t
max
/5
ꢀꢀꢀꢀ
(12)
[0060]
k
max
是ts算法在当前迭代中执行的步长;k是当前的步长;k随当前迭代t动态变化,如式13所示;这保证了算法在后期关注局部搜索性能;
[0061][0062]
因此,本发明具有如下优点:提出一种知识驱动的柔性离散制造生产调度优化方法来解决消失模铸造环境下的批量柔性作业车间调度问题,并将其用于消失模铸造。实验结果表明,该模型更适合铸造生产,解决了批量生产和调度问题,增强了hpso的局部搜索能力,该算法比已有算法具有更高的效率性和鲁棒性。
附图说明
[0063]
图1是工艺路线图。
[0064]
图2是算法流程图。
[0065]
图3是fcjsp调度甘特图。
[0066]
图4是分段编码结构图。
[0067]
图5是块集成解码规则的结构图。
[0068]
图6是基于批加工工序的工序划分图。
[0069]
图7是每个块的编码集示意图。
[0070]
图8是批加工块的解码结构图。
[0071]
图9是甘特图实例图。
[0072]
图10是升序排序策略示意图。
[0073]
图11是pox交叉和prx交叉的过程示意图。
[0074]
图12是禁忌表更新过程示意图。
[0075]
图13是关键路径的搜索方法示意图。
具体实施方式
[0076]
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
[0077]
为使得本发明的发明目的、特征、优点能够更加的明显和易懂,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,下面所描述的实施例仅仅是本发明一部分实施例,而非全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0078]
采用混合粒子群优化算法对模型进行求解,提出块集成解码规则以及采用离散型和连续性两种搜索策略对粒子群优化算法进行全局搜索,在此基础上,基于知识驱动对领域禁忌搜索算法进行局部搜索。
[0079]
为了更加直观描述问题,现假设一个带有三个作业的实例,其中每个作业包含可以在六种资源上加工的四道工序,如图3所示。实例中,o13、o23和o33在m4上分批加工,加工时间受tew限制。此外,每个资源只能加工一道特定的工序。
[0080]
进一步地,对模型的环境做出合理假设包括:
[0081]
(1)将机器设备、加工组、工人统称为加工资源。
[0082]
(2)在0时刻,所有作业被发布,所有机器都可用。0时刻是第一天的8点。
[0083]
(3)加工一旦开始就不能中断。
[0084]
(4)同一作业的工序有先后顺序,但不同作业之间的工序没有优先级之分。
[0085]
(5)将相邻两道工序之间的搬运时间和启动时间合并到加工时间中。
[0086]
参数和决策变量包括:
[0087][0088][0089]
目标函数:
[0090]
根据tew机制,需要划分开始熔炼的工序的时间周期。如式(1)所示,cid是ji的先前熔炼工序的完成时间,“ceil”表示取整。例如,如果cid=20,计算出的di=2,ji是在第2天进行批处理的候选任务。
[0091][0092]
要确定以最短完工时间(即作业的最大完成时间)为目标的调度结果(即作业的最
大完成时间)。问题的数学公式描述如下:
[0093][0094]
约束条件
[0095]
不等式(3)表示启动时间o
ij
与完成时间o
ij
之间的约束关系。不等式(4)保证开始时间o
i(j 1)
必须不小于完成时间o
ij
。不等式(3)和(4)保证了作业i的工序顺序约束。
[0096]
s
ij
x
ijk
×
p
ijk
≤c
ij
i∈{1,2
…
,n};j∈{1,2
…
,ni};k∈mij
ꢀꢀ
(3)
[0097]
c
ij
≤s
i(j 1)
i∈{1,2
…
,n};j∈{1,2
…
,ni
‑
1}
ꢀꢀ
(4)
[0098]
式(5)表示该工序在同一时间只能被同一资源加工。此外,这意味着每道工序只能从候选资源集中选择一个资源。
[0099][0100]
式(6)保证每个任务对于每个批工序只能分配到一个批计划中。
[0101][0102]
约束(7)表示每种资源只能加工一道特定的工序。m
il
表示工序o
il
的候选资源集。
[0103][0104]
不等式(8)和式(9)表明,特殊工序必须在特定的时间段内进行加工,这代表了tew机制。其中,由式(1)计算出的d
i
表示作业i的时间段,j=s表示作业o
ij
,其中a为特定时间段内需要处理的特定工序。
[0105]
v
ijk
×
s
ij
≥(d
i
×
24) 15i∈{1,2
…
,n};j=s;k∈mij(8)v
ijk
×
s
ij
p
ijk
≤(d
i
×
24) 23i∈{1,2
…
,n};j=s;k∈mij
ꢀꢀ
(9)
[0106]
不等式(10)指定批处理中作业的总权重不能超过资源总量。
[0107][0108]
进一步地,将描述采用hpso算法求解fcjsp的具体过程:
[0109]
hpso算法结合粒子群算法和禁忌搜索(ts)算法,求解fcjsp(flexible casting job shop scheduling problem)模型的流程图如图2所示。
[0110]
(1)初始化
[0111]
初始解的质量对收敛速度有很大的影响。因此,我们采用了三种种群初始化策略。最短加工时间(spt)策略是选择加工时间最短的工序,以缩短完工时间。剩余作业时间最长(mwr)策略将一个作业中剩余的总加工时间按优先级排序,用于优化资源分配。随机初始化策略随机生成工序和资源的顺序,丰富种群多样性。这三种初始化策略的比例为0.3:0.3:0.4。
[0112]
(2)编码与解码
[0113]
传统的粒子群算法对作业的工序进行连续更新,不适合离散型fcjsp。因此,采用将连续粒子位置映射到作业离散调度的编码方法。在fcjsp中,每个粒子由两部分序列(o序列和r序列)组成。o序列定义为工序的序列,r序列定义为每道工序的资源选择。如图3所示,o序列3
‑2‑1‑2‑3‑
1可以转换成一个有序工序列:o
31
‑
o
21
‑
o
11
‑
o
22
‑
o
32
‑
o
12
,r序列中的元素2可
以表示为第2个资源m3。
[0114]
然而,分段编码可以有效地整合和解决单一加工机器上的工序顺序和资源选择问题,却不能解决批生产和批调度问题。为此,提出了块集成解码(bid)规则。bid规则的核心思想是将编码集分为柔性块和批处理块,每个块通过相应的解码方法进行解码。bid规则的结构如图4所示,具体描述如下。
[0115]
从图5中可以看出,行表示作业i的索引,列表示作业i的工序,b1表示作业1的第三道工序和作业2的第二道工序是同批工序。因此,分块矩阵作业1的总工序数为,f1,f2,b1,f3,b2,f4,f5,其中b1,b2为批加工工序,同理,作业2的总工序数也为7。该分块矩阵依据图6所示的工序划分方法,可分为三个柔性分块和两个批处理分块和柔性分块表示o
11
,o
12
,和o
21
工序属于该分块。
[0116]
下面将详细介绍柔性块和批处理块的解码方法。同时,给出一个实例来说明该解码方法,该实例的相关数据如表2所示。tbd表明批工序的加工时间是不确定的。一个可行解的o序列和r序列分别为[1,1,2,1,1,2,1,2,2,2]和[1,1,2,1,2,1,1,2,1,2],分块矩阵bm为该分块矩阵依据图6所示的工序划分方法可以分为:
[0117]
即三个柔性分块和和两个批处理分块和每个分块的编码集如图6所示。
[0118]
表2两个作业和五台机器的实例
[0119][0120]
柔性块1的o序列和r序列分别为[1,1,2,
‑
,
‑
,2]和[1,1,2,
‑
,
‑
,1]。o序列中的元素表示工序o
11
‑
o
12
‑
o
21
‑
,
‑
,
‑
o
22
,r序列可以转换为所选资源m1‑
m3‑
m2‑
,
‑
,
‑
m3。另外,对应的加
工时间为[4
‑6‑
6,
‑
,
‑
7],开始和结束的加工时间为完成时间矩阵ct为[6,13],即该区块作业1和作业2的完工时间分别为6和13。对于o11工序,可以描述为在m1上加工o11工序,加工时间从0开始,到6结束。以类似的方式描述其他工序。
[0121]
对于批处理块,解决批生产和批调度问题的解码方法如图7所示。具体步骤如下:
[0122]
step1:完工时间矩阵ct由前一个区块的调度方案生成。列i表示作业i完工时间,如果ct为初始块,则为0矩阵。如果该块满足tew约束,则继续步骤2,否则继续步骤4。
[0123]
step2:根据ct矩阵分配每日候选任务集。如果ct中的作业i对应的完工时间在昨天23:00到今天23:00之间,作业i就是今天的候选任务。
[0124]
step3:使用任务发布策略构建满足tew约束的批计划。当候选任务集的总权值超过资源加工能力时,随机发布候选任务到第二天,直到满足加工能力约束。已发布的任务将不会在下一个候选任务集中再次被释放,然后继续到步骤5。
[0125]
step4:采用基于时间排序的任务互补策略构建批量计划。ct矩阵按升序排序。满足容量约束的批量生成是基于升序的。该批次中的最后一个任务是最后一个补充作业。
[0126]
step5:满足tew约束的批次开始时间为工序加工当日的23:00;否则,开始时间是该批中最终任务完工时间与资源空闲时间之间的较大时间。随后更新ct矩阵并记录批计划。
[0127]
step6:如果该批编码集中的剩余任务有库存,则转到step2或step4。否则解码停止。
[0128]
对于批量块2,由柔性块1生成完工时间矩阵ct=[6,13]。假设两个作业的总权值不超过所选资源的容量,加工时间为7h,假设加工时间与总权值有关。在step4中,根据任务补充策略对作业进行批处理,结果是作业1和作业2是在m4中加工的同一批。批处理的开始时间为13小时,这是单个完工时间的最大值。因此,解码的结果可以描述为m4同时批处理作业1和作业2,加工时间分别为13h和20h。
[0129]
对于批量块3,由批量块2生成完工时间矩阵ct=[20,20]。对批次2使用相同的假设集。虽然最早的加工开始时间是20时,但在tew约束下,开始时间被限制在23时。因此,结果是m5在批处理中同时加工作业1和作业2,加工时间分别在23h和30h开始和结束。
[0130]
最后,可根据上述方法对柔性块4进行解码。通过解码方法得到的甘特图如图9所示。完工时间为36小时。
[0131]
(3)pso用于全局搜索
[0132]
粒子群算法容易陷入局部最优解,难以平衡全局和局部的关系,导致早熟收敛。采用禁忌搜索(禁忌search,ts)算法来提高局部搜索能力,以弥补算法后期难以收敛的缺陷。本文采用连续和离散更新策略,以提高串行混合模式下的全局搜索能力。连续部分引入时变压缩因子以保证收敛稳定性。离散部分采用了保持序交叉(pox),并设计了一种基于过程的资源交叉(prx)方法来提高搜索效率。
[0133]
普通粒子群算法随机生成初始粒子,并通过粒子间的信息交换不断更新粒子的速度和位置。种群大小设为n,种群中的每个粒子为x
i
(x1,x2,
…
,x
n
),单个粒子中各阶段的位置为x
i,,j
(x
i,1
,x
i,2
,
…
),速度为v
i,j
(v
i,1
,v
i,2
,
…
)。单个粒子之间的信息交换和学习过程可以用以下公式来描述:
[0134]
v
i,j 1
=ω
×
v
i,j
c1×
rand()
×
(pbest
i
‑
x
i,j
) c2×
rand()
×
(gbest
‑
x
i,j
)
ꢀꢀ
(12)
[0135]
x
i,j 1
=x
i,j
v
i,j 1
ꢀꢀ
(13)
[0136]
其中w为惯性权重,用于控制先前速度的大小并考虑其当前位置。pbest
i
是x
i
所获得的最优解,gbest是到目前为止种群所获得的最优解。c1和c2分别是个个人学习因素和社会学习因素。
[0137]
压缩因子可以有效控制系统行为的收敛稳定性,提高粒子探索未知领域的能力。动态更新策略可以平衡c1和c2之间的矛盾。每个粒子都可以按照改进后的公式迭代更新:
[0138]
v
i,j 1
=λv
i,j
c1r1(pbest
i,j
‑
x
i,j
) c2r2(gbest
j
‑
x
i,j
)
ꢀꢀ
(14)
[0139][0140][0141][0142][0143]
t是当前迭代次数。t
max
是最大迭代次数。c
1n
和c
1m
分别为个人学习因子的初始最大值和最小值。c
2n
和c
2m
分别为社会学习因子的初始最大值和最小值。
[0144]
fcjsp是离散问题。上述改进的方法会破坏粒子的合理性,产生不可行解;因此,该方法应作相应的修正。分别采用升序排序策略和舍入策略对o序列和r序列进行修改。
[0145]
升序排序策略用于通过以下步骤修改o序列,如图10所示。
[0146]
step1:对更新后的粒子x
i 1
的o序列进行升序排序;
[0147]
step2:记录排序后的o序列序号;
[0148]
step3:按序号从旧粒子中得到新的粒子
[0149]
用于修改r序列的舍入策略描述如下:
[0150]
step1:将o序列的一个元素转换为o
ij
,并取o
ij
的可选资源集;
[0151]
step2:取一个r序列对象的元素,该元素对应于o序列对象的元素;
[0152]
step3:判断:如果r序列的更新元素小于0,取第一个资源的索引。如果在0和最大值之间,则舍入元素,否则考虑最大值。
[0153]
经过连续更新策略后,修正后的粒子对粒子搜索方向有一定偏差。因此,为了进一步优化粒子的搜索方向,本文通过借鉴gbest和pbest的成功经验,采用了基于工序的pox交叉和基于机器的prx交叉,如图11所示。这两道工序的加工过程如下:
[0154]
pox交叉
[0155]
步骤1:将作业集随机划分为两个作业集,作业集1和作业集集2。
[0156]
步骤2:将父代1的作业集1复制到子代c中,保持它的位置和顺序。
[0157]
步骤3:复制父代2的作业集2到子代c中,插入父代2的顺序。
[0158]
步骤4:复制父代1和父代2中r序列对应的元素到子代c中
[0159]
prx交叉
[0160]
步骤1:随机生成可变加工集;
[0161]
步骤2:将父代1的o序列复制到子代c中。
[0162]
步骤3:将父代1中与其不可变加工集对应的r序列的元素复制到子代c中
[0163]
步骤4:将父代2中r序列的剩余元素按父代1的顺序插入子代c中。
[0164]
在离散空间中更新粒子,如式(19)所示。用粒子x
i,j
与个体极值pbest
i
和历史极值gbest交叉来更新位置。
[0165][0166]
式(20)表示当前粒子应使用自身经验进行更新。(x
i,j
,pbest
i
)表示x
i,j
与pbest
i
在pox和prx中的交叉。rand()是0到1.之间的随机数。利用自身经验显示动态交叉概率。
[0167][0168]
式(21)表示当前粒子应该使用整个种群的经验进行更新。
[0169][0170]
(4)基于知识驱动的局部搜索禁忌搜索
[0171]
4.1禁忌搜索的设计
[0172]
ts算法是基于邻域搜索的一种算法。初始解的质量和设计的邻域对算法的性能有很大影响。因此,选择历史极值gbest,作为ts的高质量解决方案的初始解。在图12中,新的禁忌对象进入队列的头部,而其他对象移动到队列的末尾。如果没有移动空间,第一个进入队列的对象将被释放。式(22)和(23)表示禁忌表的长度,禁忌表的长度随迭代周期动态变化。这里,k是一个与参数相关联的动态禁忌表,tmax是最大迭代次数。
[0173][0174]
δ=t
max
/5
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(23)
[0175]
k
max
是ts算法在当前迭代中执行的步长。k是当前的步长。k随当前迭代t动态变化,如式24所示。这保证了算法在后期关注局部搜索性能。
[0176][0177]
轻视规则是一种激励措施,以获得更有效的优化性能的卓越候选解。本研究的轻视规则采用适应度值优化策略,以实现即时可及性。当搜索动作可以提供比当前更好的邻域解决方案时,无论禁忌表是什么,这个动作都将被接受。
[0178]
4.2基于知识驱动的局部搜索
[0179]
由于粒子群算法是随机搜索,其搜索效率不能得到保证。同时,在搜索过程中获得
的特定知识有助于解决优化问题。因此,提出了一种知识驱动的搜索策略,以有效地挖掘好的解决方案。通过生成邻域结构解,构造基于知识驱动策略的搜索策略,以调整各邻域结构的经验概率。
[0180]
将邻域结构i的经验可能性初始化为p
nsi
(0)=1/tn。tn是邻域结构的总数。在每一代中,利用邻域结构生成解构造的基于知识的经验更新可能性,如下所示:
[0181][0182]
其中ns
i
是邻域结构i的经验,即使用邻域结构i对当前解决方案进行改进的次数。
[0183]
邻域结构的设计反映了当前解周围信息的利用程度,影响最终解的质量和效率。多种局部搜索策略可以增强算法的局部搜索能力,克服算法陷入局部最优解的缺点。因此,设计了四种领域结构。ns1和ns2可以解释为随机跳出局部最优解的突变算子。ns3基于批处理工序,创建一个权重较小的作业先进行批处理,减少了等待时间,从而提高了完工时间。基于关键路径的ns4是提高完工时间的有效方法,描述如下:
[0184]
ns1:插入工序。从o序列中选择两个不同的位置a和b,然后将索引b的元素插入到索引a的元素前面。
[0185]
ns2:资源突变。随机选择r序列中的一个元素,然后用从候选资源集中随机选择的另一个资源索引替换它。
[0186]
ns3:基于批处理工序的工序交换。在构建批计划时,为了避免批量过多和等待时间增加,随机选择批工序,并与到达时间较晚、权重较大的工序进行交换。
[0187]
ns4:基于关键路径的工序交换。关键路径是随机选择的。头(尾)和随机工序在一个关键块中进行交换。图13中箭头线表示的关键路径。从最终完成工序o
34
开始的关键路径,关键路径由箭头线表示。另外,关键工序o
14
的前一道工序是批处理工序o
13
,由o
13
,o
23
和o
33
组成的批处理计划被视为关键工序o
13
,成为关键块。对于采用tew机制的批量加工,选择等待时间最短的工序o
12
作为关键工序。同时确定o
21
和o
31
,前一个在资源m3上的工序o21成为关键工序。
[0188]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。