存在目标数据集时机器学习算法的自动优化
1.相关申请的交叉引用
2.本技术要求在2019年2月5日提交的题为“automatic optimization of machine learning algorithms in the presence of target datasets”的美国临时申请第62/801,534号的优先权,其全部内容通过引用并入本文。
3.背景
4.机器学习技术允许我们训练模型来学习特定任务。为了训练这种模型,需要具有对应的地面实况(ground truth)的训练数据集。在给定域中训练机器学习算法的常用方法是使用来自给定训练数据集中的所有样本训练全局模型,其中,地面实况通常是手动创建或标注的。当任务与图像相关时,由这些模型在新的、看不见的目标图像上获取的输出在与训练集相似的图像一起使用时效果最好,并且在应用于可以与训练集的图像很大程度上不相似的不同和相异的图像时表现出明显的性能下降。一个优点是在训练集中具有更多的图像,使得具有更多相似图像的概率增加。然而,尽管图像采集系统不断地生成越来越多的图像,但是人工标注或识别图像内容标签或提取包含在海量图像中的图像数据是困难的,甚至是不可能的。自动标记或提取图像数据的现有技术尝试已经表现出具有高预测误差的差的性能。因此,需要开发新颖有效的工具来自动训练机器学习算法,以对图像执行不同类型的任务。
5.附图简述
6.参考附图阐述详细描述。在附图中,附图标记最左边的数字标识附图标记第一次出现的附图。在不同附图中使用相同的附图标记标识相似或相同的项。
7.图1是根据本公开的实施例的基于不同土地利用类别(land use classes)生成图像的语义分割(semantic segmentation)的示例方法的流程图。
8.图2是根据本公开的实施例的基于具有与目标数据集相似的标记训练数据集的目标数据集生成训练集的示例性方法的流程图。
9.图3展示了根据本公开的实施例的使用包括与目标数据集相似的标记训练数据集的生成的训练集的示例性方法。
10.图4示出了根据本公开的实施例的基于具有预测为具有高置信度的目标图像块的目标数据集生成训练集的示例性方法的另一流程图。
11.图5展示了根据本公开的实施例的基于包括与目标数据集相似的标记训练数据集和预测为具有高置信度的目标图像块的目标数据集来生成和使用生成的训练集的示例性方法。
12.图6展示了根据本公开的实施例的具有光学/捕获系统和控制模块的基于卫星的成像系统,该控制模块生成训练集并且训练机器学习算法以自动识别和分类图像中包含的土地类型。
13.图7展示了根据本公开的实施例的具有相机和控制模块的uav系统,该控制模块被配置为生成训练集并且训练机器学习算法,以从航空图像自动地提取数据。
14.图中的元件是为了简单和清楚而展示出的并且没有按比例绘制。此外,某些动作
和/或步骤可以以特定顺序描述或描绘,而本领域技术人员将理解实际上并不需要这种关于顺序的特定性。
15.详细描述
16.概述
17.根据本公开的实施例包括用于使用具有自动生成的训练数据集的机器学习技术来传递知识的方法、系统和计算机程序产品。实施例还包括从用于机器学习的目标数据集自动生成训练数据集以在图像上执行任务。主要益处中的一个是可以将在一个域中学到的知识传递到提取数据或标记图像成本高或根本不可行的另一个域中。同样,另一个益处是将在一个域中学到的知识传递到子域中,从而提高性能。根据本公开的方法和系统还提供基于目标集的训练集,该目标集以更有效的方式扩充数据并且改进训练集的内容。
18.现有技术的机器学习技术通常被训练为生成由标记训练数据集(第一训练数据集)定义的整个域的输出。然而,当面对属于不同于原始训练数据集(第一训练数据集)的新的域或子域的目标数据集时,使用全局训练数据集学习的模型可能表现欠佳/不佳,即使由于学习算法优化了整个标记训练数据集域中的函数这一事实,原始的标记训练数据集具有与目标样本相似的样本。为了克服该缺点,本文描述的实施例提供了训练数学模型以优化整个数据集域中的唯一函数的方法(计算机实现的方法),并且通过自动生成的训练数据集(第二训练数据集)围绕目标域进一步重新训练数学模型,以便函数局部调整到目标数据集。在某些情况下,数学模型已经在整个数据集域中进行了训练,本文提供的方法通过自动生成的训练数据集(第二训练数据集)围绕目标域重新训练数学模型,以便函数局部调整到目标数据集。
19.训练数据集包含属于不同类别的图像。在一些实施例中,训练数据集包含在与目标数据集中要预测的那些图像相同的类别中的图像,因此可以在那些类别中训练模型。在某些情况下,训练数据集的图像包括具有与相同类别表示成比例的图像,而在其他情况下,训练数据集包括具有相同类别表示但比例不同的图像。如果必要的话,当训练数据集具有由少数实例表示的类别而其他类别具有大量代表性实例时,可以应用多种方法来校正训练数据集的不平衡。
20.根据本公开的实施例还包括训练数学预测模型,诸如但不限于回归、分类、分割和/或聚类模型。根据图像内容的性质,模型所预测的输出可以包括连续值或离散值。在某些情况下,该模型用于自动地预测离散图像内容标签,例如,当模型自动地为图像中包含的不同元素或特征分配语义标签时。在其他情况下,该模型用于自动地预测连续值,例如通过基于图像中包含的元素或特征确定数量。
21.本公开提供了一种在机器学习算法中自动地传递知识(在机器学习算法中自动地生成训练数据集)的方法(计算机实现的方法),该方法包括:用第一训练数据集的图像训练数学模型,以减少在所有训练数据集的域中测量的全局误差,从而获取全局域数学模型;获取至少一个目标数据集,其中,该至少一个目标数据集包括至少一个图像;基于至少一个图像生成第二训练数据集;并且用所述第二训练数据集重新训练全局域数学模型;其中,训练数学模型包括执行机器学习算法。因此,本公开提供了一种在机器学习算法中自动地传递知识的计算机实现的方法,包括训练数学模型以减少在由预选训练数据集定义的所有源域中测量的一些全局误差。在整个训练集域中对数学模型进行训练之后,获取全局数学模型
或全局域数学模型(在本公开中这两个表达式被认为是等效的)。当全局数学模型用于预测具有作为新域或不同域或源域的子域的目标域的目标数据集的输出值时,可能会发生目标数据集属于其中训练的全局数学模型的误差高的目标域。为此,在获取至少一个目标数据集之后,该方法进一步包括生成第二训练数据集,以在目标数据集的邻域中重新训练全局域数学模型,使其可以在局部实现更高的性能。通常,训练或重新训练数学模型的步骤包括执行机器学习算法或调整执行机器学习算法的数学模型的参数,例如支持向量机、随机森林以及神经网络,诸如卷积神经网络、全卷积神经网络、非卷积神经网络等。
22.在一些实施例中,第二训练数据集包括但不限于来自第一训练数据集的与来自至少一个目标数据集的至少一个图像相似的图像。在其他实施例中,第二训练数据集包括来自至少一个目标数据集的由全局数学模型预测为具有高置信度的部分或完整图像。在其他实施例中,第二训练数据集包括一组图像,该组图像包括与目标数据集相似的图像,以及来自至少一个目标数据集的由全局数学模型预测为具有高置信度的部分或完整图像。附加地或可替代地,在其他实施例中,第二训练数据集进一步包括目标数据集的由全局数学模型分类为具有低置信度和/或与原始训练集(即:第一训练数据集)不相似的手动标注/标记的完整图像或部分图像。
23.一种生成具有来自第一训练数据集的与来自(至少一个)目标数据集的图像相似的图像的第二训练数据集的方法包括测量图像之间的相似性,例如测量像素级或图像级描述符之间的相似性。在一些实施例中,使用完全或部分从预训练机器学习模型导出的图像特征描述符向量来选择相似图像。例如,从预训练模型导出的图像特征描述符可以是最后一层之前的层中的任一个的数字响应。神经网络被解剖,并且在输出层之前的隐藏层中的任一个处产生的值可以被认为是描述符。附加地或可替代地,在一些实施例中,通过测量来自第一训练数据集的图像和来自至少一个目标数据集的至少一个图像的像素级或图像级描述符之间的相似性来选择相似图像。在一些实施例中,该方法进一步包括为来自目标数据集的每个图像的每个像素或像素集,并且还为来自训练数据集的每个图像的每个像素或像素集生成图像特征描述符向量,然后计算图像特征描述符向量之间的距离,并且仅从第一训练数据集的图像中选择与目标数据集的图像的像素/像素集距离接近的那些像素/像素集。距离接近可以被解释为具有低于某个距离阈值的距离值。因此,来自第一训练数据集的图像的与目标数据集的图像的像素/像素集距离接近的那些像素/像素集被认为是相似的。在一些实施例中,图像特征描述符向量是组合选自包括但不限于以下各项的组的不同图像特征描述符向量的结果:例如,梯度方向直方图(hog)、红
‑
绿
‑
蓝(rgb)颜色直方图、纹理直方图、对小波滤波器的响应、人工神经网络以及从预训练模型提取的深度神经网络特征。例如,卷积神经网络可以用作特征提取器,和/或图像特征描述符可以从预训练模型导出,其中,可以选择从输出层之前的隐藏层中的任一个产生的任何值作为特征描述符。
24.在一些实施例中,根据需要哪些图像变换不变性,即根据要使用哪些图像变换不变性来选择图像特征描述符向量、通过将图像特征描述符向量连结或应用产生新特征描述符的任何类型的函数将图像特征描述符向量组合成单个向量的方式、以及测量图像特征描述符向量之间的距离(例如欧几里得距离、余弦相似性、切比雪夫距离等)的函数。图像变换不变性包括但不限于平移、旋转、缩放、剪切、图像模糊以及图像亮度和对比度变化的任意组合。
25.在其他实施例中,在生成图像特征描述符向量并且计算它们之间的距离之后,该方法进一步包括:从目标数据集的图像中选择与训练数据集的图像的像素/像素集距离远的那些像素/像素集,手动标注标签或分配值,并且将标记或手动标注的目标图像添加到第二训练集,以包括覆盖原始数据集(第一训练数据集)未定义的区域的最小数量的要标注的图像。距离远可以被解释为具有等于或大于某个阈值的距离值。因此,与训练数据集的图像的像素/像素集距离远的目标数据集的图像的像素/像素集被认为是不相似的图像。
26.一种从目标数据集的图像生成具有一个或更多个图像块/部分图像或完整图像的第二训练数据集的方法是:使用全局数学模型测试来自目标数据集的图像,该全局数学模型已在整个训练集域中首次训练;以及从目标数据集中选择那些输出值由全局数学模型预测为具有高置信度的完整图像或部分图像。
27.例如,在一些实施例中,可以使用半监督机器学习方法获取一个或更多个目标图像的块(部分)。在一些情况下,一个或更多个目标图像的块是使用它们的逐像素置信水平来选择的,其中,每个类别的阈值是预选的,并且来自所有像素的数学模型的预测超过所述预选阈值。半监督机器学习方法可以是例如用于语义分割的网络,该网络只知道图像中存在的标签,而实际不知道关于每个像素值的信息。目标图像的部分基于使用源/原始数据集(第一训练数据集)训练的全局数学模型所具有的置信度/概率。一部分可以是图像的以高概率(即概率高于预定阈值)对其内的所有像素进行分类的一部分。根据所述部分,我们可以不仅有一个类别,而且有多个类别。例如,目标图像可以是描绘森林和城市的图像,中间有一条河流将它们隔开。数学模型可以对河流和森林的分类置信度高,但对城镇的分类置信度低,甚至可能对城市的某些区域进行错误分类。在这种情况下要使用的部分是图像的仅包含河流和森林的部分。
28.在其他实施例中,选择其输出值由全局数学模型预测为具有低置信度的完整目标图像或目标图像的部分,以手动标注标签或分配值,并且将其添加到第二训练集中。
29.在一些实施例中,至少一个目标数据集由全部或部分搭载在飞行器上的成像装置捕获,其中,飞行器可选自包括但不限于卫星、航天器、航空器、飞机、无人驾驶飞行器(uav)和无人机的组。
30.实施例包括一种系统,该系统包括成像装置、全局域数学模型以及控制模块。成像装置被配置为捕获至少一个目标图像。全局域数学模型可以用第一训练数据集进行训练,以减少在第一训练数据集的所有域中测量的全局误差。控制模块被配置为获取至少一个目标数据集,其中,该至少一个目标数据集包括至少一个目标图像;基于该至少一个目标图像生成第二训练数据集;并且使用第二训练数据集重新训练全局域数学模型;其中,训练数学模型包括执行机器学习算法。在一些实施例中,控制模块被配置为用第一训练数据集训练数学模型,以减少在第一训练数据集的所有域中测量的全局误差,从而获取全局域数学模型;获取至少一个目标数据集,其中,该至少一个目标数据集包括至少一个目标图像;基于该至少一个目标图像生成第二训练数据集;并且使用第二训练数据集重新训练全局域数学模型;其中,训练数学模型包括执行机器学习算法。
31.因此,成像装置被配置为捕获包括目标图像的易失性或固定图像。目标图像具有在捕获时尚未识别的图像内容特征。控制模块被配置为用第一训练数据集训练机器学习系统或数学模型,以减少在训练数据集的所有域中测量的全局误差,从而获取训练的机器学
习系统。在一些实施例中,第一训练数据集包括包含多个图像的图像集合,其中,这些图像具有已被正确分配语义描述或标签的特征。控制模块进一步被配置为基于至少一个目标图像生成第二训练数据集,并且用第二训练数据集重新训练机器学习系统。
32.在一些实施例中,控制模块进一步被配置为通过以下各项生成第二训练数据集:通过从第一训练数据集中选择与目标图像相似的图像、通过选择由机器学习系统(或数学模型,或全局域数学模型)预测为具有高置信度(即:置信水平等于或高于预定阈值)的目标图像的部分或完整目标图像,和/或通过选择两者,即来自第一训练数据集的与目标图像相似的图像和由机器学习系统预测为具有高置信度的目标图像的部分或完整目标图像。第二训练数据集可以进一步或可替代地包括由机器学习系统分类为具有低置信度(即:置信水平低于预定阈值)的手动标注的完整目标图像或目标图像的部分和/或与原始训练集不相似的手动标注的完整目标图像或目标图像的部分。
33.为了从第一训练数据集中选择与目标图像相似的图像,控制模块进一步被配置为生成目标图像和来自第一训练数据集的图像的每个像素或像素集的图像特征描述符向量并且计算图像特征描述符向量的距离,并且仅从第一训练数据集的图像中选择与目标图像的像素/像素集距离接近的那些像素/像素集。在一些实施例中,图像特征描述符向量可以全部或部分地包括从机器学习模型导出的特征。在其他示例中,图像特征描述符向量可以全部或部分地包括从固有图像特征(诸如但不限于直方图、频率分析和颜色组成)导出的特征。
34.本文描述了各种示例以帮助说明,但是这些示例并不意味着限制性的理解。
35.识别航空或卫星图像的方法示例
36.从航空或卫星图像中收集信息以获取具有对应地面实况的目标数据集的过程通常是慢的并且成本很高。为了获取允许在合理的时间量内区分和识别地球表面上的元素的信息,甚至禁止对全球(地球)的所有区域进行重复的测量。由于生成必要的地面实况需要巨大的经济努力,一个显示本文所述方法的优点的示例是使用机器学习技术和专门生成的训练数据集训练数学模型,以学习航空或卫星图像的分割,并且传递从在给定区域或地区中捕获的图像中学到的知识,以生成对全球任何地方以及一年中任何时间的预测。
37.所描述的方法还允许专门研究可以是地理的、季节性的或类似的特定域,以自动地分割新看到的地球的区域或地区的图像,而不限于地球的确定部分或季节,因为没有足够的具有地面真实性的图像。在一个示例中,该方法包括机器学习技术以训练数学模型来学习从飞行器捕获的航空或卫星图像的分割。飞行器可以是例如航空器、航天器、无人机、飞机、可以是低地球轨道卫星的卫星、无人驾驶飞行器(uav)或飞越地球的类似交通工具。
38.在这种情况下,目标图像(目标数据集)包括从飞行器捕获的一个或更多个航空或卫星图像,并且源图像(对应于第一训练数据集)包括包含具有对应的地面实况的多个航空或卫星图像的图像集合。第一训练数据集必须可靠且值得信赖,并且可以是机器生成的、人为生成的或这些的组合。通常,模型使用来自其中地面实况可用的区域的源图像进行训练,这些图像类似于并且保留目标图像的采样分布。目标和源图像的其他示例也可用于本公开,诸如医学图像、工业图像、安全相机图像或其他类型的图像,因为本文描述的方法包括处理从部分或完全在地球上或者部分或完全搭载在飞行器上的成像装置捕获的固定或易失性图像。
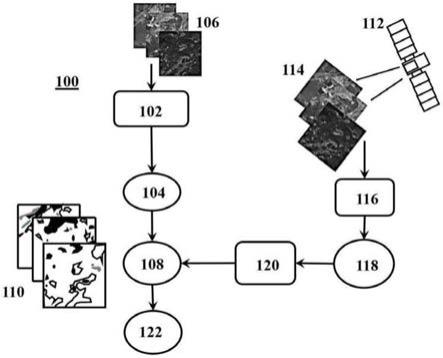
39.图1示出了根据示例性实施例的生成分割诸如基于土地利用类别(来自土地利用分类系统)的卫星图像的语义分割的示例方法100的示意图。该方法包括使用来自给定原始训练集106(第一训练集)的所有样本训练102数学模型104,以获取基于土地利用类别学习卫星图像110的语义分割的全局域数学模型108。优选地,原始训练集106包括标记的卫星图像。在该示例中,模型被训练以自动地预测离散值,即图像内容标签。可以分配给目标和训练图像的图像内容(类别)标签包括但不限于水体(河流、湖泊、水坝)、森林、裸地、荒地、建筑物、道路、作物类型和作物生长、土壤组成、矿山、石油和天然气基础设施和/或这些的不同子类或状态,诸如不同的土壤类型、不同的作物或不同的建筑类型或功能。一旦数学模型104被训练102以学习卫星图像110的语义分割,方法100进一步包括从感兴趣的区域或地区捕获112一个或更多个没有图像内容标签的卫星图像114。基于一个或更多个卫星图像114,方法100进一步包括生成116训练集118(第二训练集),并且使用生成的训练集118重新训练120全局域数学模型108以获取预测的数学模型122。在一些示例中,数学模型可以被训练为预测数据集的连续数量输出(回归),而不是被训练为预测离散类别标签输出(分类)。例如,当模型用于确定作物的不同生长状态时,这是有用的。
40.图2、图4和图5示出了示例性方法的示意图,该方法生成训练集以重新训练数学模型从而优化机器学习算法以便调整模型的输出,使得模型可以使用来自先前标记的卫星图像的知识,并且即使来自原始训练集的图像来自地球的不同地区或在不同季节或一天中的不同时间拍摄,仍可以通过语义分割以高准确度预测新捕获的卫星图像的元素。
41.图2示出了通过选择与卫星捕获的卫星图像214(目标数据集)最接近的那些标记的卫星图像206(第一训练集)来生成训练集218的方法200。在一些情况下,仅选择一个标记的卫星图像206,然而在其他情况下,选择两个或更多个与卫星图像214相似的标记的卫星图像206,其中,卫星图像214也可以仅包括一个卫星图像。方法200通过测量图像之间的相似性、比较特征向量220并且选择低于距离或距离阈值即高于相似性水平的那些图像生成训练集218(第二训练集)。基于机器学习的方法222,诸如人工神经网络、深度学习技术或其他类似方法,可以用作特征提取器,该特征提取器从标记的卫星图像206和卫星图像214的集合中生成每个图像的特征向量。在其他示例中,一般图像描述符向量生成器224可以用作特征提取器,该特征提取器从标记的卫星图像206和卫星图像214的集合中生成每个图像的特征向量。在其他示例中,基于机器学习的方法222和一般图像描述符向量生成器224的组合可以用作特征提取器。两个图像之间的相似性是通过组合两个特征向量之间的距离和与由平均图像颜色、颜色直方图、方向梯度和斜率的直方图组成的一般图像描述符向量的距离来计算的。并且位于卫星图像214的域的给定邻域内的相似图像被包括在训练集218中。通过查看每个卫星图像214的特征向量与标记的卫星图像206中的每个的对应向量之间的距离并且选择距离低于特定距离阈值的那些标记的卫星图像来计算上述邻域。因此,该邻域将由与待分类的卫星图像214最接近的一定数量的标记的卫星图像218定义。
42.图3展示了由低轨道卫星捕获的三个卫星图像314(目标图像)及其五个最接近的包括通过图2的方法200生成的训练集318(第二训练数据集)的标记的卫星图像。一旦识别出预选数量(k)的最接近的标记的卫星图像,它们就被用于重新训练326模型308,该模型已经用来自原始训练集306(第一训练数据集)的所有标记的卫星图像进行了全局训练302。以这种方式,该过程产生局部调整到新域的函数328。
43.图4示出了生成训练集418(第二训练数据集)以重新训练426全局数学模型408从而获取预测的数学模型428的另一示例性方法的示意图。用于生成训练集418的方法400包括设置阈值430,然后计算一个或更多个卫星图像414的全局数学模型408的预测432,并且选择434在图像的所选部分的所有像素中,其预测432的分数高于给定阈值,即具有高置信度,或者换句话说,置信水平高于(或等于,取决于如何进行确定)给定阈值的一个或更多个卫星图像414的块436。由全局数学模型408预测为具有高置信度的一个或更多个卫星图像414的块436包括训练集418。在一些情况下,方法400使用半监督方法选择已经由数学模型408以高置信度标记的块或部分图像。如何设置阈值的一个示例涉及首先计算对标记的卫星图像的全局数学模型的预测,其中,全局数学模型最初是用所有标记的卫星图像进行训练的。基于全局数学模型对标记的卫星图像的预测,确定每个类别的值,其中,所有像素中的预测都具有预选分数,这意味着它们具有预选的准确度水平。
44.图5示出了用于生成训练集518(第二训练数据集)的方法500,其包括计算538每个未标记的捕获图像514(目标数据集)的与原始训练集506(第一训练数据集)最接近的实例,并且从已经被预测为具有高置信度(高于阈值的置信水平)的未标记的捕获图像514中选择534图像和/或区域或块536。在一些情况下,置信水平可以使用概率来表达,并且阈值可以是例如80%、90%或99%,或任何其他值。这组完整和部分图像包括用于重新训练526全局数学模型508以获取专门用于在目标数据集的邻域内更好地执行的预测数学模型528的训练集518。可以例如使用测量图像之间相似性的非监督机器学习方法来选择最接近目标图像的训练图像,而来自目标图像的图像和/或区域或块可以使用先前训练的全局模型来预测。
45.通常,该方法提供了迭代局部函数逼近技术,该技术组合了围绕目标域调整全局函数的该全局函数的重新定义以及使用目标数据集的可靠预测部分作为新的训练数据进行的数据扩充。该方法显著提高了分类器性能以自动监测土地利用。以这种方式,该过程产生局部调整到新域的函数。
46.此外,可以训练模型以自动地预测图像中的连续值,包括但不限于水体(河流、湖泊、水坝)的水平、作物生长阶段、垃圾场中的废物量以及类似任务。通常,该方法还可以用于使用机器学习算法的回归分析。
47.处理航空或卫星图像的系统示例
48.如上所述的系统的一个示例包括基于航空或卫星的系统,该系统包括成像装置和控制模块。基于航空或卫星的系统可以全部或部分地搭载在飞行器上,诸如但不限于航空器、航天器、无人机、飞机或可以是低地球轨道卫星的卫星。在一些实施例中,系统的部件中的一些或全部可以是陆基的(ground
‑
based)或搭载在单独的飞行器上,其中,这种陆基的或单独的飞行器与系统的一部分通信。例如,成像装置的光学系统(例如,透镜和传感器阵列等)可以搭载在卫星上,而其他部件,诸如任何合适的计算装置或成像装置的系统可以是基于地面的。
49.图6中示出基于卫星的系统。系统600可以用于实施图1至图5中描述的方法,并且该系统包括卫星642,该卫星具有搭载在卫星642上的光学/捕获系统644和可以全部或部分地搭载在卫星642上或陆基的控制模块646。光学/捕获系统644从地球表面获得至少一个卫星图像614(目标图像),并且控制模块646使用没有图像内容标签的卫星图像614和具有图
像内容标签的多个卫星图像606(第一训练数据集),以生成训练集(第二训练数据集)并且训练机器学习算法以自动地识别和分类图像中包含的土地覆盖类型,并且将一个或更多个图像内容标签分配给卫星图像614。
50.在一些情况下,该系统可以包括一个或更多个飞行器,使得该系统引导至少一个配备有成像装置的飞行器在所选择的位置处捕获具有未知图像内容标签的航空或卫星图像。
51.控制模块646进一步被配置为使用例如人工神经网络,包括深度学习技术、非监督机器学习方法、半监督机器学习方法或卷积神经网络,生成与目标域更相关的那些训练数据集,诸如但不限于训练集118、218、318、418、518。控制模块646进一步被配置为使用基于目标数据集生成的训练集重新训练机器学习算法,以获取新的预测模型。在一些情况下,那些与目标域更相关的训练数据集包括但不限于与来自目标域的未标记的目标数据集接近的源图像,以及由数学模型以高置信度标记的来自目标域的未标记的目标数据集的一个或更多个目标图像的块。在一些情况下,接近未标记的目标数据集的源图像是通过使用非监督机器学习方法选择的,而一个或更多个目标图像的块是通过使用其他机器学习方法选择的。
52.基于生成的训练集获取的新预测模型能够为飞行器从感兴趣的区域或地区捕获的图像分配一个或更多个图像内容标签,并且以高准确度预测新捕获的卫星图像的元素,即使来自原始训练集的图像来自地球的不同地区或者在不同季节或一天中的不用时间拍摄。
53.在一些情况下,生成的训练集可以包括:a)一个或更多个源图像,它们具有与目标图像的图像特征描述符向量相似但没有图像内容标签的识别的图像特征描述符向量,b)一个或更多个完整的目标图像和/或目标图像的没有图像内容标签的已由数学模型以预定的置信水平分配了标签的一个或更多个部分,或c)包括a)和b)的两个图像集。可以相对于识别、分类或标记过程的准确度水平(准确度水平是否为预定值或更高)来定义预定置信水平。在某些情况下,生成的训练集进一步包括完整的目标图像或目标图像的被手动分配了标签的部分,因为它们的输出值是由全局数学模型预测为具有低置信度的,或者因为目标图像的图像特征描述符向量距离原始训练集的图像特征描述符向量超过一定的距离阈值。在某些情况下,诸如在回归或概率回归预测建模中,数学模型分配连续值(例如连续标签)而不是离散值(标签),并且生成的训练集可以包括:a)一个或更多个具有与目标图像的连续值相似的预测连续值的源图像,b)一个或更多个完整的目标图像和/或目标图像的已被数学模型以预定的置信水平分配了连续值(即连续标签)的一个或更多个部分,或c)包括a)和b)的两个图像集。例如,全局域数学模型可已经用包含提供图像内小麦生长程度的图像的第一训练数据集进行了训练。卫星可以拍摄麦田的卫星图像,而无需确定小麦生长的程度(目标数据集)。生成的训练集可以包括:a)来自第一训练数据集的一个或更多个图像,这些图像的小麦生长的程度类似于卫星图像的小麦生长的程度,b)一个或更多个完整的卫星图像和/或卫星图像的具有由全局域数学模型预测为具有高于90%的置信水平的小麦生长程度的一个或更多个部分,或c)包括a)和b)的两个图像集。生成的训练集也可以包括完整的目标图像或目标图像的被手动分配了连续值的一部分,因为它们的输出值是由全局数学模型预测为具有低置信度的。
54.图7展示了包括无人机742或uav的系统700,该无人机或uav具有搭载在无人机742上的相机744和控制模块746,该控制模块可以部分搭载在无人机742上并且部分陆基。相机744从地球表面获得至少一个航空图像714,并且控制模块746使用航空图像714和多个具有图像内容标签的航空图像706生成训练集,并且如关于前面的附图所述训练机器学习算法,以自动地从航空图像714中提取数据并且确定已由航空图像714捕获的大坝两侧的水位。控制模块746使用经过训练的机器学习算法进行回归分析并且提供给定时间大坝处的水位。
55.结论
56.尽管本公开使用特定于结构特征和/或方法动作的语言,但本发明不限于所描述的特定特征或动作。相反,具体特征和动作被公开为实施本发明的说明性形式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。