1.本发明属于飞行器导航、制导与控制技术领域,具体涉及一种基于深度强化学习的飞行器智能抗扰动控制方法。
背景技术:
2.飞行器(flight vehicle)是指在大气层内或大气层外空间(太空)飞行的器械,可以分为航空器、航天器、火箭和导弹等几种类别,近年来广泛应用于军用和民用领域。为了准确地完成日益复杂化、多样化、精准化的飞行任务,如何设计具有优异控制表现的姿态控制系统,一直是学者们亟待解决的问题。
3.对于飞行器姿态系统中存在的强非线性、强耦合性、参数不确定性、参数时变性和存在外界干扰等问题,非线性抗扰动控制方法(例如自抗扰控制(adrc)和基于干扰观测器的控制方法(dobc))受到了研究人员的青睐。
4.然而,这类传统的控制方法对于复杂环境和不确定性等问题难以避免地存在适应性较低和鲁棒性较差的缺点。
技术实现要素:
5.本发明为了弥补传统抗扰动控制方法适应性较低和鲁棒性较差的缺点,进一步提高在强非线性、强耦合性、参数不确定性、参数时变性和存在外界干扰等问题存在时的控制性能,提出了一种基于深度强化学习的飞行器智能抗扰动控制方法。
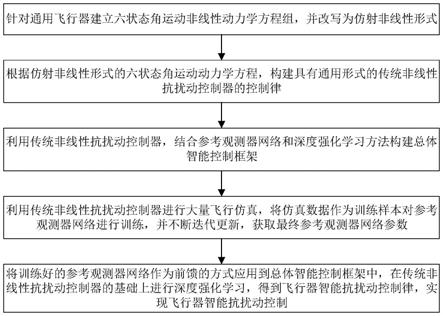
6.所述的基于深度强化学习的飞行器智能抗扰动控制方法,具体包括如下步骤:
7.步骤一、针对通用飞行器建立六状态角运动非线性动力学方程组,并改写为仿射非线性形式;
8.仿射非线性形式的六状态角运动动力学方程组为:
[0009][0010]
式中,ω表示飞行器的姿态角,ω表示飞行器的角速度;f
s
表示姿态角环的系数矩阵,f
f
表示角速率环的系数矩阵;g
s
表示姿态角环的控制矩阵,g
f
表示角速率环的控制矩阵;δ表示控制舵面;表示姿态角环的复合干扰,表示角速率环的复合干扰。
[0011]
步骤二、根据仿射非线性形式的六状态角运动动力学方程,构建具有通用形式的传统非线性抗扰动控制器的控制律;
[0012]
传统非线性抗扰动控制律为:
[0013][0014]
式中,ω
*
为角速率环的期望指令,δ
c
为控制舵面的期望指令,表示姿态角环期
望指令的微分,表示角速率环期望指令的微分;k
ω
表示矩阵形式的姿态角环控制增益系数,k
ω
表示矩阵形式的角速率环控制增益参数;e
ω
表示姿态角环的跟踪误差;e
ω
表示角速率环跟踪误差;表示对姿态角环的复合干扰的估计值,表示对角速率环的复合干扰的估计值;
[0015]
步骤三、利用传统非线性抗扰动控制器,结合参考观测器网络和深度强化学习方法构建总体智能控制框架;
[0016]
所述的总体智能控制框架由:参考观测器网络和使用深度强化学习方法智能调整控制增益参数的传统非线性抗扰动控制器构成。
[0017]
步骤四、利用传统非线性抗扰动控制器进行大量飞行仿真,将仿真数据作为训练样本对参考观测器网络进行训练,并不断迭代更新,获取最终参考观测器网络参数;
[0018]
训练样本的生成过程为:通过在飞行包线内随机给定期望输出,在可行域内随机施加内扰和外扰,使用传统非线性抗扰动控制器控制飞行器模型跟踪期望输出,并采集该过程中的飞行器模型输出和控制输入数据作为训练样本。
[0019]
所述参考观测器网络的结构具体为:
[0020]
x1,x2,...,x
n
为输入序列,y1,y2,...,y
n
为输出序列,bilstm由正向和反向的多层lstm组成,将正向和反向的多层lstm输出h
fn
,h
bn
进行拼接,最终经由全连接层fc得到输出序列;
[0021]
对参考观测器网络进行训练具体为:
[0022]
步骤401,将飞行器模型输出样本数据作为参考观测器网络的输入序列,经由正向和反向的多层lstm输出h
fn
,h
bn
进行拼接,再经过全连接层fc得到参考观测器网络输出,即飞行器的控制输入数据。
[0023]
步骤402,计算参考观测器网络的输出与样本中飞行器模型的控制输入之间的均方误差,作为参考观测器网络的损失函数;
[0024]
步骤403,采用adam优化器根据损失函数计算梯度来更新参考观测器网络参数。
[0025]
步骤404,参数更新后的参考观测器网络进行下一次训练迭代,直至得到一个能够产生精确前馈控制输入的参考观测器网络。
[0026]
步骤五、将训练好的参考观测器网络作为前馈的方式应用到总体智能控制框架中,在传统非线性抗扰动控制器的基础上进行深度强化学习,得到飞行器智能抗扰动控制律,实现飞行器智能抗扰动控制。
[0027]
所述的深度强化学习采用的是td3算法,td3算法包括6个神经网络,具体为:1个动作现实网络、1个动作目标网络、2个评价现实网络和2个评价目标网络;其中动作现实网络和动作目标网络构成动作网络,2个评价现实网络和2个评价目标网络构成2套评价网络;
[0028]
深度强化学习的具体流程如下:
[0029]
步骤501,动作现实网络根据从飞行器仿真环境得到的状态选择一个动作输出,并与噪声叠加,最终得到动作ω
t
下达给飞行器仿真环境执行,返回奖励r
t
和新的状态x
t 1
。
[0030]
ω
t
=a(x
t
|λ
a
) π
t
ꢀꢀꢀ
(4)
[0031]
其中,ω
t
为最终飞行器仿真环境执行的动作,即与噪声叠加后的控制输入;a代表动作现实网络,λ
a
为动作现实网络的参数,x
t
为当前飞行器的飞行状态,π
t
为随机噪声。
[0032]
步骤502,将状态转换过程中的状态x
t
、动作ω
t
、奖励r
t
和新的状态x
t 1
存入经验存储中。
[0033]
步骤503,动作网络和评价网络分别从经验存储中采样n个状态转换过程数据,并利用动作目标网络和2个评价目标网络计算转换过程数据的期望q值,选择其中的最小值作为最终的期望q值;
[0034]
评价网络采样时利用n
‑
step采样机制,即一次采样n个连续的状态转换过程。
[0035]
期望q值q
j*
的计算公式为:
[0036][0037]
其中,n为n
‑
step采样的步数;c
′
j
表示第j个评价目标网络,j=1,2;a
′
表示动作目标网络;为第j个评价目标网络的参数,λ
a
′
为动作目标网络的参数;γ是奖励衰减系数。x
t n
表示第t n时刻的状态。
[0038]
步骤504,分别计算最终的期望q值与两个评价现实网络输出的q值之差,得到两个代价函数l
j
,对评价现实网络的参数进行更新。
[0039]
代价函数l
j
为:
[0040][0041]
其中,c
j
表示第j个评价现实网络,x
i
表示第i个样本的状态,ω
i
表示第i个样本的动作。
[0042]
使用adam优化器对评价现实网络的参数进行更新。
[0043]
步骤505,通过评价现实网络c1计算动作现实网络性能指标的梯度,对动作现实网络a的参数λ
a
进行更新;
[0044]
性能指标的梯度计算公式为:
[0045][0046]
其中,j表示性能指标,j对动作现实网络a的梯度为评价现实网络c1对控制输入u的梯度为动作现实网络a对其参数λ
a
的梯度为
[0047]
在td3中,对动作网络参数的更新使用adam优化器,并采用延迟更新的策略。
[0048]
步骤506,用评价现实网络更新的参数和动作现实网络更新的参数λ
a
渐变更新目标网络的参数;
[0049]
渐变更新目标网络的计算公式为:
[0050][0051]
其中,τ是现实网络的渐变更新系数。
[0052]
步骤507,重复迭代步骤501
‑
506,不断更新评价现实网络和目标网络的参数,得到训练好的动作现实网络;
[0053]
步骤508、利用训练好的动作现实网络实时智能调整控制增益参数,以优化反馈误差项,同时结合参考观测器网络产生的前馈控制输入,得到飞行器智能抗扰动控制律。
[0054]
飞行器智能抗扰动控制律具体表达式如下:
[0055][0056]
其中,e=[e
ω
,e
ω
],n1(x,e)为深度强化学习实时输出的姿态角环控制增益参数,n2(x,e)为深度强化学习实时输出的角速率环控制增益参数;x为飞行器状态向量,ω
ref
,δ
ref
为参考观测器网络输出。
[0057]
本发明的优点在于:
[0058]
(1)一种基于深度强化学习的飞行器智能抗扰动控制方法,引入基于深度学习的参考观测器网络和基于深度强化学习的智能反馈误差项,提升了传统非线性抗扰动控制方法的控制性能以及适应性和鲁棒性;
[0059]
(2)一种基于深度强化学习的飞行器智能抗扰动控制方法,不受具体控制方法限制,可以以各类抗扰动控制方法为基础,提升控制性能,具有易实现和拓展性;
[0060]
(3)一种基于深度强化学习的飞行器智能抗扰动控制方法,适用于多类和多种气动外形的飞行器,具有普适性。
附图说明
[0061]
图1是本发明一种基于深度强化学习的飞行器智能抗扰动控制方法的整体流程图;
[0062]
图2是本发明一种基于深度强化学习的飞行器智能抗扰动控制框架的架构示意图;
[0063]
图3是本发明中参考观测器网络的结构示意图;
[0064]
图4是本发明中参考观测器网络的样本生成方法流程示意图;
[0065]
图5是本发明中参考观测器网络的训练方法示意图;
[0066]
图6是本发明中深度强化学习方法的网络结构示意图;
[0067]
图7是本发明中参考观测器网络输出与传统非线性抗扰动控制方法的控制量对比图;其中,图7(a)为对副翼的输出对比和预测偏差,图7(b)为对方向舵的输出对比和预测偏差,图7(c)为对升降舵的输出对比和预测偏差;
[0068]
图8是本发明中智能抗扰动控制方法与传统非线性抗扰动控制方法的跟踪效果对比图;其中,图8(a)为攻角α的跟踪效果对比以及跟踪误差,图8(b)为侧滑角β的跟踪效果对比以及跟踪误差,图8(c)为倾侧角γ
s
的跟踪效果对比以及跟踪误差;
[0069]
图9是本发明中深度强化学习方法智能控制器参数曲线图;其中,图9(a)为姿态角环的控制增益参数曲线,图9(b)为角速率环的控制增益参数曲线。
具体实施方式
[0070]
为了便于本领域普通技术人员理解和实施本发明,下面结合附图和实施例对本发明作进一步的详细描述。
[0071]
本发明所提出的基于深度强化学习的飞行器智能抗扰动控制方法,是在传统非线性抗扰动控制方法的基础上,结合新一代人工智能的最新研究成果,通过基于深度学习的参考观测器网络产生前馈输入与基于深度强化学习智能调整增益参数的反馈输入相结合的二元智能控制结构。
[0072]
本发明以传统的抗扰动控制框架为基础,通过深度强化学习方法对反馈误差项进行调整优化,以进一步提高控制器在强非线性、强耦合性、参数不确定性、参数时变性和存在外界干扰等问题作用下的跟踪控制性能,对实现飞行器姿态角的抗扰动高精度跟踪控制具有重要的意义。
[0073]
一种基于深度强化学习的飞行器智能抗扰动控制方法,如图1所示,具体步骤如下:
[0074]
步骤一、针对通用飞行器建立六状态角运动非线性动力学方程组,并基于时标分离原理和奇异摄动理论,将其改写为利于控制器设计的姿态角和角速率分环的仿射非线性形式;
[0075]
具体步骤如下:
[0076]
步骤101,在假设飞行器是一理想刚体,且忽略地球曲率和旋转的条件下,通用飞行器六状态角运动非线性动力学方程组可写为如下形式:
[0077]
[0078][0079]
α表示攻角,β表示侧滑角,γ
s
表示倾侧角;w
x
表示滚转角速率,w
y
表示侧滑角速率,w
z
表示俯仰角速率;分别表示α,β,γ
s
和w
x
,w
y
,w
z
的微分,所列写的方程组就是飞行器六状态角运动非线性动力学微分方程组。
[0080]
m表示飞行器质量;g表示飞行器所在位置的重力加速度;θ表示飞行器的弹道倾角;s表示飞行器的参考面积;δ
x
表示副翼偏角,δ
y
表示方向舵偏角,δ
z
表示升降舵偏角;l表示飞行器所受升力,z表示飞行器所受侧力;v表示飞行器速度;i
x
,i
y
,i
z
表示x、y、z三轴转动惯量;表示飞行器所受动压;ρ表示大气密度;l表示平均气动弦长;b表示翼展;表示由侧滑角引起的滚转力矩系数、表示由滚转角速率引起的滚转力矩系数、表示由偏航角速率引起的滚转力矩系数、表示由副翼引起的滚转力矩系数、表示由方向舵引起的滚转力矩系数、表示由侧滑角引起的偏航力矩系数、表示由滚转角速率引起的偏航力矩系数、表示由偏航角速率引起的偏航力矩系数、表示由副翼引起的偏航力矩系数、表示由方向舵引起的偏航力矩系数、c
mz,α
表示由攻角引起的俯仰力矩系数、表示由俯仰角速率引起的俯仰力矩系数、表示由升降舵引起的俯仰力矩系数。
[0081]
步骤102,基于时标分离原理和奇异摄动理论,充分考虑模型参数不确定性和存在外界干扰,将六状态角运动非线性动力学方程组改写为利于控制器设计的仿射非线性形式;
[0082]
时标分离原理指的是按照被控变量对控制输入量响应快慢的特点,将它们分成不同的组,然后进行分组控制,以简化控制系统设计任务。
[0083]
奇异摄动理论是用来近似求解微分方程的重要数学方法之一,利用系统状态变量在时间尺度上的差别,把单个高阶系统解的计算降阶为两个或多个低阶系统的求解。
[0084]
仿射非线性形式的六状态角运动动力学方程组为:
[0085][0086]
式中,表示表示表示表示和表示ω和ω的微分;飞行器的姿态角ω=[α,β,γ
s
]
t
,飞行器的角速度ω=[w
x
,w
y
,w
z
]
t
,控制舵面δ=[δ
x
,δ
y
,δ
z
]
t
;
[0087]
表示姿态角环的复合干扰,表示角速率环的复合干扰;f
s
表示姿态环的系数矩阵,f
f
表示角速率环的系数矩阵;g
s
表示姿态环的控制矩阵,g
f
表示角速率环的控制矩阵,形式如下:
[0088][0089][0090][0091][0092]
[0093][0094]
其中,δf
s
,δg
s
δf
f
,δg
f
表示模型参数不确定性,d
s
,d
f
表示未知外界扰动。
[0095]
步骤二、在自抗扰控制和基于干扰观测器控制方法的基础上,根据仿射非线性形式的飞行器六状态角运动非线性动力学方程,构建传统非线性抗扰动控制器的控制律;
[0096]
传统非线性抗扰动控制律为:
[0097][0098]
式中,ω
*
为角速率环的期望指令,δ
c
表示控制舵面的期望指令;e
ω
=ω
*
‑
ω表示姿态角环跟踪误差,ω
*
表示姿态角环期望指令;e
ω
=ω
*
‑
ω表示角速率环跟踪误差;表示对姿态角环的复合干扰的估计值,表示对角速率环的复合干扰的估计值;k
ω
=diag{k1,k1,k1}表示控制器姿态角环增益参数矩阵,k1表示姿态环的控制增益参数;k
ω
=diag{k2,k2,k2}表示控制器角速率环控制增益参数的矩阵,k2表示角速率环的控制增益参数;g
s
‑1、g
f
‑1分别表示矩阵g
s
、g
f
的逆矩阵;g
st
表示矩阵g
s
的转置矩阵;分别表示姿态角环和角速率环期望指令的微分信号;
[0099]
基于自抗扰adrc理论,由下述形式的线性扩张观测器(leso)获得复合干扰的估计值为:
[0100][0101]
式中,姿态角环复合干扰的估计值角速率环复合干扰的估计值角速率环复合干扰的估计值表示姿态角的估计值,表示角速率的估计值;表示姿态角的估计误差,表示角速率的估计误差。l
1i
=diag{l
1i
,l
1i
,l
1i
}为姿态角环的观测增益矩阵,l
2i
=diag{l
2i
,l
2i
,l
2i
}为角速率环的观测增益矩阵,i=1,2。分别表示姿态角和角速率的估计值的微分;分别表示姿态角环和角速率环复合干扰的微分。
[0102]
步骤三、在传统非线性抗扰动控制器的基础上,结合参考观测器网络和深度强化学习方法,构成总体智能控制框架。
[0103]
总体智能控制框架,如图2所示,包括参考观测器网络,和使用深度强化学习方法智能调整控制增益参数的传统非线性抗扰动控制器。其中参考观测器网络用于产生前馈控制输入,传统非线性抗扰动控制器用于产生反馈控制输入。
[0104]
首先,将对飞行器的期望飞行轨迹指令输入参考观测器网络,参考观测器网络给出前馈控制输入;根据当前飞行器状态以及跟踪参考指令的误差,通过深度强化学习算法实时智能调整控制增益参数,优化反馈误差项,结合传统非线性抗扰动控制器,给出反馈控制输入;
[0105]
然后,将经过前馈控制和反馈控制调整后的控制指令输出给飞行器,使飞行器在有外界扰动的情况下能够按照期望轨迹飞行。
[0106]
步骤四、利用传统非线性抗扰动控制器进行大量飞行仿真,并将仿真数据作为训练样本进行参考观测器网络训练,并不断迭代更新,获取最终参考观测器网络参数。
[0107]
具体如下:
[0108]
参考观测器网络的结构如图3所示,x1,x2,...,x
n
表示输入序列,y1,y2,...,y
n
为输出序列,bilstm(bi
‑
directional long shortterm memory,双向长短时记忆网络)由正向和反向的多层lstm组成,将正向和反向的多层lstm输出h
f
,h
b
进行拼接,最终经由全连接层fc得到输出序列;
[0109]
样本生成的方式如图4所示,具体如下:以传统非线性抗扰动控制器为基础,在飞行包线内随机给定期望输出,在可行域内随机施加内扰和外扰,使用传统非线性抗扰动控制器控制飞行器模型跟踪期望输出,并采集该过程中的飞行器模型输出和控制输入数据作为训练样本。
[0110]
对参考观测器网络进行训练,如图5所示,具体为:
[0111]
步骤401,将飞行器模型输出样本数据作为参考观测器网络的输入序列,经由正向和反向的多层lstm输出h
fn
,h
bn
进行拼接,再经过全连接层fc得到参考观测器网络输出,即飞行器的控制输入数据。
[0112]
为了防止过拟合,训练时在参考观测器网络各个lstm层之间加入dropout层来减轻各个节点之间的依赖关系。
[0113]
步骤402,计算参考观测器网络的输出与飞行器模型的控制输入样本数据之间的均方误差,作为参考观测器网络的损失函数;
[0114]
步骤403,采用adam优化器根据损失函数计算梯度来更新参考观测器网络参数。
[0115]
步骤404,参数更新后的参考观测器网络进行下一次训练迭代,直至得到一个能够产生精确前馈控制输入的参考观测器网络,并利用未经训练的样本对参考观测器网络的性能进行测试,完成训练。
[0116]
步骤五、将训练好的参考观测器网络作为前馈的方式应用到总体智能控制框架中,并在传统非线性抗扰动控制器的基础上进行深度强化学习,得到飞行器智能抗扰动控制律,实现飞行器智能抗扰动控制。
[0117]
深度强化学习采用双延迟深度确定性策略梯度(twin delayed deep deterministic policy gradient,td3)算法,并将n
‑
step采样算法与其进行结合,以提高收敛速度。td3算法的网络结构如图6所示,一共使用了6个神经网络,分别为动作现实网络、动作目标网络、2个评价现实网络和2个评价目标网络。
[0118]
td3算法的流程如下:
[0119]
步骤501,动作现实网络根据从飞行器仿真环境得到的状态选择一个动作输出,并与噪声叠加,增加探索性,最终得到的动作ω
t
下达给飞行器仿真环境执行,返回奖励r
t
和新的状态x
t 1
。
[0120]
ω
t
=a(x
t
|λ
a
) π
t
ꢀꢀꢀ
(6)
[0121]
其中,ω
t
为最终飞行器仿真环境执行的动作,即与噪声叠加后的控制输入,a代表动作现实网络,λ
a
为动作现实网络的参数,x
t
为当前飞行器飞行状态,π
t
为随机噪声。
[0122]
在动作中加入噪声是td3采用的动作目标网络光滑正则化策略。
[0123]
步骤502,将状态转换过程中的状态x
t
、动作ω
t
、奖励r
t
和新的状态x
t 1
存入经验存储中。
[0124]
步骤503,动作网络和评价网络分别从经验存储中采样n个状态转换过程数据,作为动作网络和评价网络训练的一个小批量数据。
[0125]
评价网络采样时采用n
‑
step采样机制,即一次采样n个连续的状态转换过程,提高评价网络的收敛性。
[0126]
步骤504,对采样的小批量数据利用动作目标网络和2个评价目标网络计算期望q值,这样可以切断相关性,提高收敛性,从所有的期望q值中取最小值作为最终的期望q值。
[0127]
期望q值的计算公式为:
[0128][0129]
其中,q
*
表示期望q值,n为n
‑
step采样的步数,c
′
j
表示第j个评价目标网络,j=1,2;a
′
表示动作目标网络,为第j个评价目标网络的参数,λ
a
′
为动作目标网络的参数,γ是奖励衰减系数。r
t
表示t时刻的奖励,γ
n
表示奖励衰减系数的n次方,x
t n
表示第t n时刻的状态。
[0130]
步骤505,分别计算最终的期望q值与两个评价现实网络输出的q值之差,得到两个代价函数l
j
,对评价现实网络的参数进行更新。
[0131]
代价函数l
j
由下式计算:
[0132][0133]
其中,c
j
表示第j个评价现实网络,x
i
表示第i个样本的状态,ω
i
表示第i个样本的动作。
[0134]
评价现实网络的梯度可由代价函数计算。
[0135]
利用代价函数和adam优化器对评价现实网络的参数进行更新。
[0136]
步骤506,通过评价现实网络c1计算动作现实网络性能指标的梯度,对动作现实网络a的参数λ
a
进行更新;
[0137]
性能指标的梯度计算公式为:
[0138][0139]
其中,j表示性能指标。j对动作现实网络a的梯度由评价现实网络c1对控制输入u的梯度点乘动作现实网络a对其参数λ
a
的梯度得到。
[0140]
动作现实网络的目标是使评价网络的输出q值增大,得到可以获得更多奖励的策略,所以,动作现实网络的梯度通过评价现实网络的梯度计算。
[0141]
通过性能指标的梯度计算公式,并使用adam优化器对动作现实网络的参数λ
a
进行更新。在td3中,对动作网络采用延迟更新的策略,即每隔几个循环才更新一次,提高更新的
准确性。
[0142]
步骤507,用现实网络的参数渐变更新目标网络的参数。
[0143]
渐变更新目标网络的计算公式为:
[0144][0145]
其中,τ是渐变更新系数。
[0146]
步骤508,重复迭代步骤501
‑
506,不断更新现实网络和目标网络的参数,可以得到训练好的动作现实网络,将其与传统抗扰动控制器结合,实现实时智能调整控制增益参数的目的。
[0147]
上述训练好的动作现实网络与传统抗扰动控制方法结合产生更优的反馈误差项。
[0148]
步骤509、利用训练好的动作现实网络实时智能调整控制增益参数,以优化反馈误差项,同时结合参考观测器网络产生的前馈控制输入,得到飞行器智能抗扰动控制律。
[0149]
飞行器智能抗扰动控制律的形式如下:
[0150][0151]
其中,e=[e
ω
,e
ω
],n1(x,e)为深度强化学习实时输出的姿态角环控制增益参数,n2(x,e)为深度强化学习实时输出的角速率环控制增益参数,即[n1(x,e),n2(x,e)]=a([x,e]|λ
a
);x为飞行器状态向量,e
ω
,e
ω
为跟踪误差向量,ω
ref
,δ
ref
为参考观测器网络输出;
[0152]
仍由leso进行估计,但由于参考观测器网络的加入,式(5)所示leso构造形式修正为如下所示形式:
[0153][0154]
实施例
[0155]
为检验本发明一种基于深度强化学习的飞行器智能抗扰动控制方法的有效性与较传统非线性抗扰动控制方法的优越性,以某型轴对称飞行器为实施例,进行仿真验证。
[0156]
在该实施例中,控制器参数选取:k1=5,k2=20,l
11
=40,l
12
=400,l
21
=60,l
22
=900。
[0157]
依据本发明的具体实施步骤,本发明所提参考观测器网络输出与原传统非线性抗扰动控制方法的控制量对比如图7所示,参考观测器网络预测的输出和采用传统抗扰动控制方法的实际控制输出几乎一致,其中,如图7(a)和图7(b)所示,对副翼和方向舵的预测精度最高,预测误差在
±
0.02
°
以内;如图7(c)所示,对于升降舵而言,除去初始时刻的较大偏差,预测误差区间也处于
±
0.15
°
以内,验证了本发明中参考观测器网络预测控制输入的有效性。
[0158]
本发明智能抗扰动控制方法与传统非线性抗扰动控制方法的跟踪效果对比如图8所示,通过对姿态角三通道的跟踪效果对比,由图8(a)、图8(b)以及图8(c)可以看出,本发明提出的智能控制方法体现出更佳的控制效果。
[0159]
本发明提出的深度强化学习方法智能控制器参数曲线图如图9所示,图9(a)所示为深度强化学习方法实时调整姿态角环增益参数,图9(b)所示为深度强化学习方法实时调整角速率环增益参数,由两个曲线图可以看出,本发明应用智能控制器能取得更佳的控制效果。
[0160]
综合上述对实施例的仿真验证,证明了本发明一种基于学习的飞行器智能抗扰动控制方法的有效性。
[0161]
本发明说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。