本发明属于语音识别技术领域,具体涉及一种语音分离方法。
背景技术:
语音分离的目的是将多个音源的混合语音分离成其对应成分。近些年针对语音分离问题提出了如深度聚类,置换不变训练,深度吸引子网络等多种方法。然而在这些方法中,被广泛应用的声学特征是短时傅里叶变换的幅度谱(short–timefouriertransform,stft)。这就会导致在从分离后的幅度谱恢复成时域信号的过程中,所用到的是含有噪声的相位谱,从而得到次优的性能。
为了克服这一缺陷,由网络学习的从时域到时频域变换的可学习特征成为了新的趋势。其中代表性的就是一维卷积滤波器(1d-conv)。由于该变换是与分离网络联合训练的,并且不需要额外的人工操作,因此该变换相比于stft来说使语音分离的性能得到了提升。在这些时域方法中,conv-tasnet(convolutionaltimedomainaudioseparationnetwork,conv-tasnet)在帧长设置为仅2毫秒的低时延情况下得到了杰出的分离性能,从而受到了广泛的关注。
近期有一些工作旨在研究conv-tasnet的声学特征。例如,ditter和gerkmann用人工设计特征,即多相位gammatone滤波器组(mpgtf)来代替conv-tasnet中编码器部分的可学习特征,并在尺度无关信噪比(scale-invariantsource-to-noise,si-snr)上带来了提升。pariente等人将参数化滤波器扩展为了复值的解析滤波器,同时他们也提出了类似的一维卷积滤波器的解析版本。解析的一维卷积滤波器相比于原始的conv-tasnet也有性能上的提升。但是这种方法在语音分离时并未达到最佳性能,还有进一步提升的空间。
技术实现要素:
为了克服现有技术的不足,本发明提供了一种基于参数化多相位gammatone滤波器组的语音分离方法,首先在gammatone滤波器的基础上构建参数化多相位gammatone滤波器组,然后用参数化多相位gammatone滤波器组替换conv-tasnet网络的编码器,解码器不变或采用参数化多相位gammatone滤波器组的逆变换,形成新conv-tasnet网络,对新conv-tasnet网络进行训练,得到最终的语音分离网络。本发明方法在解码器为可学习特征的情况下,获得了具有竞争力的性能;在解码器为编码器的逆变换的情况下,该特征优于stft,mpgtf等人工设计特征。
本发明解决其技术问题所采用的技术方案包括如下步骤:
步骤1:对gammatone滤波器进行改进,得到参数化多相位gammatone滤波器组;
步骤1-1:gammatone滤波器的冲激响应函数γ(t)为:
γ(t)=αtn-1exp(-2πbt)cos(2πfct φ)(1)
其中,n是滤波器阶数,b是带宽参数,fc是滤波器的中心频率,t>0是时间,α是幅度,φ是相移;
滤波器中心频率fc和带宽参数b由矩形带通滤波器的等效矩形带宽erb(.)决定:
fc=c2(erb-c1)(3)
其中,c1和c2是不同的滤波器参数;
步骤1-2:使用m个gammatone滤波器构成参数化多相位gammatone滤波器组,带宽参数b和第j个滤波器
其中,erbscale表示将1/erb(fc)进行频率积分得到的erb尺度,
将
步骤2:使用参数化多相位gammatone滤波器组替换conv-tasnet网络的编码器,构成新conv-tasnet网络;
步骤3:采用adam优化器,设置初始学习率,对新conv-tasnet网络进行训练,训练完成后采用新conv-tasnet网络实现语音分离。
优选地,所述步骤2中构成新conv-tasnet网络时,新conv-tasnet网络的解码器保持新conv-tasnet网络的解码器不变。
优选地,所述步骤2中构成新conv-tasnet网络时,新conv-tasnet网络的解码器为参数化多相位gammatone滤波器组的逆变换。
优选地,所述
优选地,所述
优选地,所述c1=24.7,c2=9.265。
优选地,所述初始学习率为0.001。
本发明的有益效果如下:
本发明针对目前现有人工特征的参数无法与网络进行联合训练的缺点提出了改进版本的参数化多相位gammatone滤波器组特征,其中参数化多相位gammatone滤波器组的中心频率与带宽参数将与网络进行联合训练。实验结果表明,在解码器为可学习特征的情况下,该特征获得了具有竞争力的性能;在解码器为编码器的逆变换的情况下,该特征优于stft、mpgtf等人工设计特征。
附图说明
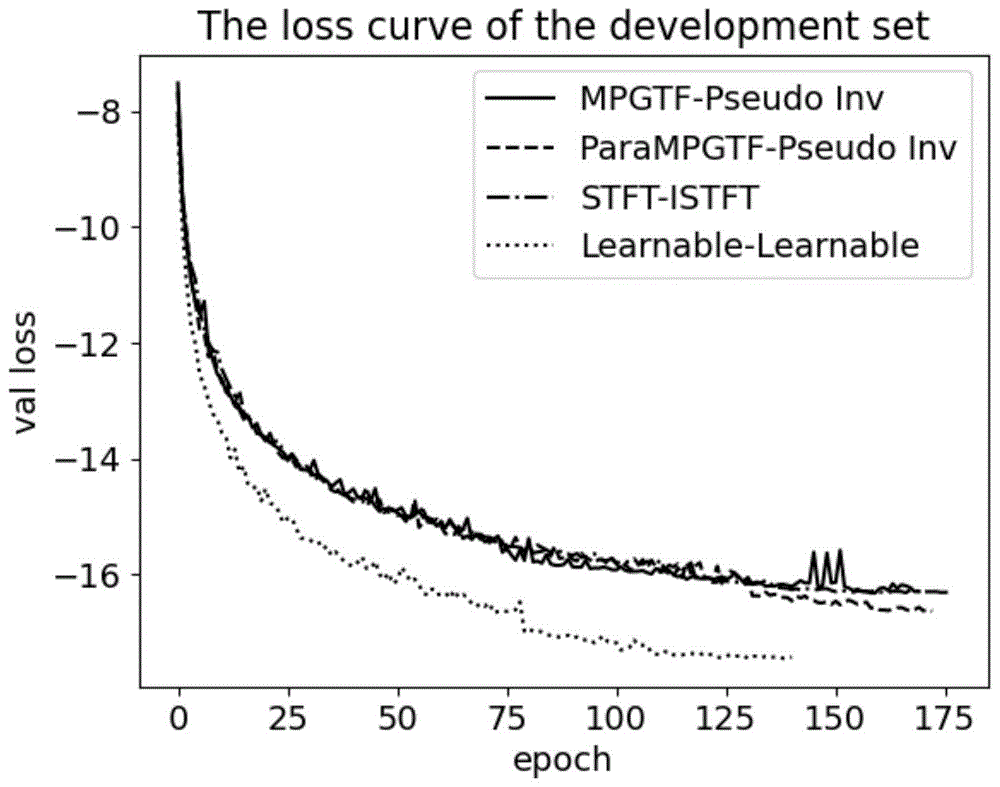
图1为本发明实施例不同编码器-解码器的收敛曲线。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
conv-tasnet是目前最流行的时域语音分离网络,针对conv-tasnet的编码器和解码器进行了一些改进。用人工设计特征或者参数化特征代替conv-tasnet中的可学习特征。然而目前缺少对可学习特征、人工设计特征以及参数化特征的比较。
本发明将人工设计特征的多相位gammatone滤波器组与参数化特征进行了结合,提出了参数化多相位gammatone滤波器组。
本发明的基础分离框架是conv-tasnet。它是由三个主要部分构成:编码器,分离网络和解码器。其中编码器可以看作是n个长度为l的滤波器的集合。编码器的输出是由输入混合语音和滤波器卷积所产生的:
其中,n是滤波器的索引,i是帧数的索引,d是帧移,
解码器的作用是重构第c个说话人的时域语音信号
其中
一种基于参数化多相位gammatone滤波器组的语音分离方法,包括以下步骤:
步骤1:gammatone滤波器组模拟了人类听觉系统的掩蔽效应,在语音分离任务中是一种良好的特征。对gammatone滤波器进行改进,得到参数化多相位gammatone滤波器组parampgtf;
步骤1-1:gammatone滤波器的冲激响应函数γ(t)为:
γ(t)=αtn-1exp(-2πbt)cos(2πfct φ)(1)
其中,n是滤波器阶数,b是带宽参数,fc是滤波器的中心频率,t>0是时间,α是幅度,φ是相移;
gammatone滤波器组通过以下三个方面的改进成为多相位gammatone滤波器组。第一:滤波器的长度被设置成了2毫秒,其目的是为了使系统低时延;第二:对每个滤波器
滤波器中心频率fc和带宽参数b由矩形带通滤波器的等效矩形带宽erb(.)决定:
fc=c2(erb-c1)(3)
其中,c1和c2是不同的滤波器参数;通常情况下,根据经验公式,c1和c2分别被设置为24.7和9.265。然而这种经验设置可能不够准确,从而可能会导致次优的性能。
步骤1-2:使用m个gammatone滤波器构成参数化多相位gammatone滤波器组,滤波器组的参数c1和c2将与网络联合训练;带宽参数b和第j个滤波器
其中,erbscale表示将1/erb(fc)进行频率积分得到的erb尺度,
其中fhz表示频率变量;
将
步骤2:使用参数化多相位gammatone滤波器组替换conv-tasnet网络的编码器,解码器保持conv-tasnet网络的解码器不变或者为参数化多相位gammatone滤波器组的逆变换,构成新conv-tasnet网络;
步骤3:采用adam优化器,设置初始学习率,对新conv-tasnet网络进行训练,训练完成后采用新conv-tasnet网络实现语音分离。
具体实施例:
(1)实验设置:
conv-tasnet网络在4秒长的片段上进行了200个周期的训练。优化器采用adam优化器,初始学习率为0.001。如果在验证集上连续5个周期性能没有提升则学习率减半。同时,当验证集上的性能在过去的10个周期内都没有提升时,网络训练将会被停止。网络的超参数设置遵循conv-tasnet中的网络超参数,其中滤波器数目n为512。时序卷积网络(temporalconvolutionalnetworks,tcn)的掩模函数分别被设置为sigmoid函数和修正线性单元(rectifiedlinearunit,relu)。对于parampgtf,将阶数n设置为2,幅度α设置为1。将c1和c2的初始值设置为其经验值,即c1=24.7,c2=9.265。采用si-snr作为评价指标。所报告的结果均是3000句测试混合语音的平均结果。
(2)数据准备:
使用wsj0-2mix数据集对双说话人语音分离性能进行比较。它包含了30个小时的训练数据,10小时的验证数据以及5小时的测试数据。wsj0-2mix中的混合语音是通过在wallstreetjournal(wsj0)训练集si_tr_s中随机选择不同的说话者和句子产生的,并将它们以-5分贝到5分贝范围中的随机信噪比混合。测试集中的句子来自于wsj0数据集中si_dt_05和si_et_05中16个训练中未用到的说话人。wsj0-2mix中的所有语音均被重采样至8000赫兹。
(3)实验结果:
首先比较了解码器为可学习特征,编码器为stft、mpgtf、parampgtf和可学习特征时的情况,表1列出了比较结果。从表1中可以看出,这四种特征并没有产生很大的性能差异。如果仔细比较,发现stft特征在测试集和验证集都达到最高的性能。mpgtf和parampgtf性能比较接近,parampgtf在验证集上略好于mpgtf,而在测试集上略差于mpgtf。
表1不同特征作为编码器的比较
分别将编码器设置为stft,mpgtf,parampgtf,并将解码器设置为其对应的逆变换。表2列出了stft,mpgtf,parampgtf以及它们逆变换分别作为编码器和解码器的实验结果。从表中可以看出,这三种比较方法的性能大体上是相似的。但在测试集和验证集上,所提出的parampgtf都达到了最好的性能,这也表明了参数化训练的策略有进传统人工设计特征的潜力。
表2编码器和解码器为不同特征及其逆变换时的比较
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

