一种基于全局
‑
局部加窗的声音特征快速提取方法
技术领域
1.本发明涉及一种声音特征提取技术,更具体的说,涉及一种基于全局
‑
局部加窗的声音特征快速提取方法。
背景技术:
2.语音是人类之间沟通交流的最直接也是最快捷方便的一种手段,而实现人类与计算机之间畅通无阻的语音交流,一直是人类追求的一个梦想。伴随着移动智能设备的普及,各家移动设备的厂家也开始在自家的设备上集成了语音识别系统,像apple siri、microsoft cortana、google now等语音助手的出现,使得人们在使用移动设备的同时,也能够进行语音交流,极大的方便了人们的生活。但是此类助手也存在一些尴尬的瞬间,例如在一些工作场合或者聚会的场合,某人的一句“hey siri”就可能唤醒多台苹果设备,使用者难免尴尬困惑。
3.语音识别的核心是通过预先训练说话人的声音样本,提取出相对应的声音特征放入到系统中,应用的时候将待验证的语音进行特征提取并与系统中预先存入的声音特征进行匹配,以确定说话人的身份。
4.当前大多数声纹提取技术都是基于mfcc、fbank等方式方法来进行声音特征提取,但是它们基本都是将时域的信息转换为频域进行提取,要经过多次傅里叶变换,这无疑增加了时间花费,并且加窗过程很少有考虑到全局特征。
技术实现要素:
5.本发明的目的旨在解决现有声音特征提取速度慢,未能考虑全局对局部影响的问题。本发明的目的通过下述的技术方案实现:
6.一种基于全局
‑
局部加窗的声音特征快速提取方法,其特征在于包括以下步骤:
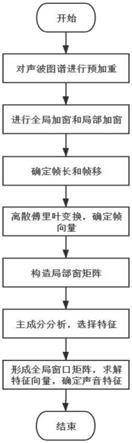
7.(1)采集声音样本,形成声波图谱,预处理并对其进行预加重;
8.(2)对预加重处理后的声波进行全局加窗和局部加窗;
9.(3)根据全局加窗结果确定帧长和帧移。
10.(1)(4)进行局部加窗,并对其进行离散傅里叶变换,以单个正弦函数作为基向量,构造帧向量;
11.(5)构造局部窗矩阵。
12.(6)进行主成分分析,挑选具有代表性的特征;
13.(7)形成全局窗口矩阵,进行特征值求解,利用所求得特征值确定该声源的声音特征。
14.1、步骤(1)具体的实现方法如下,采用一阶偏导与拉普拉斯算子的组合对局部平滑曲线进行加重。
15.16.其中,k1和k2是两个系数,f是x的波普函数,w是对采样点处的加重权重。然后将其通过一个高通滤波器:
17.h(z)=1
‑
lnw
×
z
‑118.在语音和图像信号,尤其是本方法中处理的目标函数声波图谱,在低频段处的能量大,而在高频段处能量小,也就是低频段信噪比大,高频信噪比低,我们采用本方法中的增大高频段信噪比的方法,从而减低在频率高处噪音对声音特征提取的影响。
19.本步骤中所述的预处理过程包括但不限于:数据筛选、降噪、信号转化等常规语音信号处理过程。
20.2、步骤(2)具体的实现方法如下,对采用步骤(1)所述方法预处理之后的声波进行全局层次加窗。将定义域为l的声波图谱分为w个局部窗口,应满足如下条件:
[0021][0022]
其中,l、l1、l2、的计量单位应该为毫秒ms,并且l1、l2是一个经验参数,取值一般可以采取与现行办法相同的值。k3、k4都是一个非负整数参数。
[0023]
3、步骤(3)具体的实现方法如下,在基于步骤(2)的基础上,在每一个窗口内,进行确定帧的长度和帧移。帧的长度l3应该满足l
11
<l3=<l
22
。帧移长度l4的应该满足如下:
[0024][0025]
4、步骤(4)具体的实现方法如下,在基于步骤(3)确定帧长和帧移之后。进行局部加窗,并采用离散傅里叶变换对每一帧声波图谱进行分解,分解得到:
[0026][0027]
确定合适的前n项,分别以正弦和余弦为基,构造出两个向量。构造方法如下:
[0028]
s
n
(x)=s1(x) s2(x)
[0029][0030][0031][0032][0033]
在上面的流程中,我们将s
n
分解为只含正弦基的s1和只含余弦基的s2,在根据其各个基的系数产生两个向量v1和v2。再通过这两个向量的非线性结合,构造该帧的帧向量如下:
[0034]
[0035]
5、步骤(5)具体的实现方法如下,在基于步骤(4)的途径构造帧向量之后,构建每个局部窗的特征矩阵,由于每个帧都有1个n 1维向量来表征。考虑到语音是一个时序表征,前面的语音对后面有影响,所以,在同一个子窗口内,每帧都有相关的信息会传给后一个帧。在形成局部窗口的特征矩阵时,将相邻两个帧的特征向量做差,再以合适的方式添加到下一个帧的特征向量中,形成局部窗口特征矩阵的下一行。具体计算如下:
[0036][0037]
r2=v2 ln|v2‑
v1|
[0038][0039]
r
n
=v
n
ln|v
n
‑
v
n
‑1|
[0040][0041]
r1、r2、r
n
均是局部窗口矩阵m的行向量,n表示该局部窗口拥有的帧数量。
[0042]
6、步骤(6)具体的实现方法如下,基于步骤(5)的方法构建的局部窗口矩阵,对其采用主成分分析,将局部窗口矩阵降维到维。所述的主成分分析过程包括但不限于:相关数据的处理、pca算法的应用、其他可用于主成分分析的算法。
[0043]
7、步骤(7)具体的实现方法如下,在步骤(6)描述,得到每个局部窗口矩阵维。对所得的w个局部窗口矩阵进行拼接,形成整个全局窗口的矩阵。进行特征值求解,得到每个特征值对应的特征向量。挑选最大的特征值对应的对应向量作为声音特征,若对应不止一个特征向量,则选择二范式最大的那个。
[0044]
所述的特征值求解过程包括但不限于:特征值求解、计算特征向量、数据处理等常规特征值求解过程。
[0045]
2、在能够表征声音特征的向量后,可以采用计算相似度的方法进行特征普配,确定声音是否来自同一人。
[0046]
所述计算相似度方法包括但不限于:余弦相似度、欧几里得距离、曼哈顿距离、皮尔森相关系数。
附图说明
[0047]
图1为实施例的基于全局
‑
局部加窗的声音特征快速提取方法流程示意图;
[0048]
图2为实施例的基于全局
‑
局部加窗的声音特征快速提取方法的声音特征匹配具体实施流程图。
具体实施方式
[0049]
为了使本发明的目的、技术方案及优点更加清楚,以下结合附图及实施例,对本发
明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不限定本发明。
[0050]
实施例
[0051]
如图1所示,描述的是一种基于全局
‑
局部加窗的声音特征快速提取方法的主要流程和组成部分;图2描述了实施例中声音特征匹配具体实施流程图。
[0052]
一种基于全局
‑
局部加窗的声音特征快速提取方法,总体的方法方案包括如下步骤:
[0053]
(1)采集声音样本,形成声波图谱,预处理并对其进行预加重。
[0054]
(2)对预加重处理后的声波进行全局加窗和局部加窗。
[0055]
(3)根据全局加窗结果确定帧长和帧移。
[0056]
(4)进行局部加窗进行离散的傅里叶变换。以单个正弦函数作为基向量,构造帧向量。
[0057]
(5)构造局部窗矩阵。
[0058]
(6)进行主成分分析,挑选具有代表性的特征。
[0059]
(7)形成全局窗口矩阵,进行特征值求解。利用所求得特征值确定该声源的声音特征
[0060]
1、实列中,采用一阶偏导与拉普拉斯算子的组合对局部平滑曲线进行加重。
[0061][0062]
其中,k1和k2是两个系数,f是x的波普函数,w是对采样点处的加重权重。然后将其通过一个高通滤波器:
[0063]
h(z)=1
‑
lnw
×
z
‑1[0064]
在语音和图像信号,尤其是本方法中处理的目标函数声波图谱,在低频段处的能量大,而在高频段处能量小,也就是低频段信噪比大,高频信噪比低,我们采用本方法中的增大高频段信噪比的方法,从而减低在频率高处噪音对声音特征提取的影响。
[0065]
本步骤中所述的预处理过程包括但不限于:数据筛选、降噪、信号转化等常规语音信号处理过程。
[0066]
3、实例中,对采用步骤(1)所述方法预处理之后的声波进行全局层次加窗。将定义域为l的声波图谱分为w个局部窗口,应满足如下条件:
[0067][0068]
其中,l、l1、l2、的计量单位应该为毫秒ms,并且l1、l2是一个经验参数,取值一般可以采取与现行办法相同的值。k3、k4都是一个非负整数参数。
[0069]
3、实例中,在基于步骤(2)的基础上,在每一个窗口内,进行确定帧的长度和帧移。帧的长度l3应该满足l
11
<l3=<l
22
。帧移长度l4的应该满足如下:
[0070][0071]
4、实例中,在基于步骤(3)确定帧长和帧移之后。进行局部加窗,并采用离散傅里
叶变换对每一帧声波图谱进行分解,分解得到:
[0072][0073]
确定合适的前n项,分别以正弦和余弦为基,构造出两个向量。构造方法如下:
[0074]
s
n
(x)=s1(x) s2(x)
[0075][0076][0077][0078][0079]
在上面的流程中,我们将s
n
分解为只含正弦基的s1和只含余弦基的s2,在根据其各个基的系数产生两个向量v1和v2。再通过这两个向量的非线性结合,构造该帧的帧向量如下:
[0080][0081]
6、实例中,在基于步骤(4)的途径构造帧向量之后,构建每个局部窗的特征矩阵,由于每个帧都有1个n 1维向量来表征。考虑到语音是一个时序表征,前面的语音对后面有影响,所以,在同一个子窗口内,每帧都有相关的信息会传给后一个帧。在形成局部窗口的特征矩阵时,将相邻两个帧的特征向量做差,再以合适的方式添加到下一个帧的特征向量中,形成局部窗口特征矩阵的下一行。具体计算如下:
[0082][0083]
r2=v2 ln|v2‑
v1|
[0084][0085]
r
n
=v
n
ln|v
n
‑
v
n
‑1|
[0086][0087]
r1、r2、r
n
均是局部窗口矩阵m的行向量,n表示该局部窗口拥有的帧数量。
[0088]
6、实例中,基于步骤(5)的方法构建的局部窗口矩阵,对其采用主成分分析,将局部窗口矩阵降维到维。所述的主成分分析过程包括但不限于:相关数据的处理、pca算法的应用、其他可用于主成分分析的算法。
[0089]
7、步骤(7)具体的实现方法如下,在步骤(6)描述,得到每个局部窗口矩阵维。对所得的w个局部窗口举证进行拼接,形成整个全局窗口的矩阵。进行特征值求解,得到每个特征值对应的特征向量。挑选最大的特征值对应的对应向量作为声音特征,若对应不止一个特征向量,则选择二范式最大的那个。
[0090]
所述的特征值求解过程包括但不限于:特征值求解、计算特征向量、数据处理等常规特征值求解过程。
[0091]
7、实例中,在获得能够表征声音特征的向量后,可以采用计算余弦相似度的方法进行特征普配,确定声音是否来自同一人。具体流程如图2所示。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

