1.本公开涉及电子设备及其控制方法。更具体地,本公开涉及执行语音识别的电子设备及其控制方法。
2.本公开还涉及使用机器学习算法模拟人脑的识别功能和决策功能的人工智能(ai)系统及其应用。
背景技术:
3.近年来,实现人类级别的智能的人工智能系统已经用在各种领域中。人工智能系统是与现有的基于规则的智能系统不同的、在其中机器执行学习和做出决策的功能且自身变得智能的系统。随着人工智能系统越来越多地使用,改进识别率且更精确地了解理解用户的口味,以使得现有的基于规则的智能系统已经逐渐由基于深度学习的人工智能系统替代。
4.人工智能技术由机器学习(例如,深度学习)和使用机器学习的元技术组成。
5.机器学习是通过其本身分类/学习输入数据的特征的算法技术,且元技术是使用比如深度学习等的机器学习算法模拟人脑的功能,比如识别、决策等的技术,且由比如语言理解、视觉理解、推断/预测、知识表达、运动控制等的技术领域的组成。
6.人工智能技术应用到的各种领域如下。语言理解是识别和应用/处理人类语言的技术,且包括自然语言处理、机器翻译、对话系统、问与答、语音识别/合成等。视觉理解是类似人的视觉的识别和处理东西的技术,且包括对象识别、对象跟踪、图像搜索、人类识别、场景理解、空间理解、图像改进等。推断/预测是估计用于逻辑推断和预测的信息的技术,且包括基于知识/概率的推断、优化预测、基于偏好的计划、推荐等。知识表达是其中以知识数据的形式表达人类经验信息的技术,且包括知识结构(数据生成/分类)、知识管理(数据利用)等。运动控制是控制车辆的自我驾驶和机器人的运动的技术,且包括移动控制(导航、碰撞和驾驶)、操纵控制(行为控制)等。
7.近年来,已经开发了识别用户语音并根据识别出的用户语音操作的电子设备,比如ai扬声器。但是,电子设备在比如客厅、厨房和卧室的所有空间中放置就成本而言可能是有问题的。
8.由于这种问题,已经开发了使用处理用户语音的一个主(边缘)设备和接收用户语音并将用户语音提供给主设备的多个从(点)设备的方法。多个从设备可以位于比如客厅、厨房和卧室的空间中。
9.但是,在该情况下,用户语音可能通过几个从设备输入,这可能导致重复处理同一需求的问题。此外,可能由于重复而浪费网络传输和计算资源。
10.以上信息被呈现为背景信息仅为了帮助理解本公开。关于是否任意以上所述可用作本公开的现有技术,没有做出确定,并且没有做出断言。
技术实现要素:
11.技术问题
12.本公开的方面是至少解决上述问题和/或缺点和至少提供如下,所述的优点。此外,不需要本公开克服上面描述的缺点,且本公开的实施例可以不克服上面描述的任何问题。
13.因此,本公开的一方面是提供一种设置多个传感器装置的优先级的电子设备及其控制方法。
14.另外的方面和/或优点将部分地在下面的描述中提出,且部分地将从描述显而易见,或者可以通过本实施例的实践习得。
15.技术方案
16.根据本发明的一方面,提供了一种电子设备。所述电子设备包括通信接口和至少一个处理器,该至少一个处理器被配置为:通过通信接口分别从第一传感器装置和位置远离第一传感器装置的第二传感器装置接收第一音频信号和第二音频信号;获取第一音频信号和第二音频信号之间的相似性;在其中相似性等于或者高于阈值的情况下,基于位置与第一传感器装置相邻的电子设备的操作状态从第一音频信号获取第一预测的音频分量,和基于位置与第二传感器装置相邻的电子设备的操作状态从第二音频信号获取第二预测的音频分量;基于第一预测的音频分量和第二预测的音频分量将第一传感器装置或者第二传感器装置之一识别为有效传感器装置;和对于从有效传感器装置接收到的附加音频信号执行语音识别。
17.所述电子设备可以进一步包括存储器,在其中存储基于电子设备和至少一个其他电子设备中的每一个的操作状态的模式特定音频模型,其中,至少一个处理器进一步被配置为:基于音频模型识别与位置与第一传感器装置相邻的电子设备的操作状态和位置与第二传感器装置相邻的电子设备的操作状态对应的模式,和基于识别的状态分别从第一音频信号和第二音频信号获取第一预测音频分量和第二预测的音频分量,且当多个传感器装置中的每一个学习基于相邻电子设备的操作状态获取的音频时,可以通过人工智能算法获取所述音频模型。
18.所述至少一个处理器可以进一步被配置为基于识别的状态分别从第一音频信号中包括的噪声分量和第二音频信号中包括的噪声分量获取第一预测的音频分量和第二预测的音频分量;基于第一预测的音频分量的幅值和第二预测的音频分量的幅值获取第一音频信号的第一质量特性和第二音频信号的第二质量特性;和基于将第一质量特性和第二质量特性将第一传感器装置或者第二传感器装置之一识别为有效传感器装置。
19.所述至少一个处理器可以进一步被配置为改变位置与第一传感器装置相邻的电子设备的操作状态和位置与第二传感器装置相邻的电子设备的操作状态,以允许位置与第一传感器装置相邻的电子设备和位置与第二传感器装置相邻的电子设备根据预定事件以预定模式操作。
20.所述至少一个处理器可以进一步被配置为基于语音识别结果控制电子设备或者至少一个其他电子设备中的至少一个,和控制有效传感器装置以提供通知控制结果的通知消息。
21.所述至少一个处理器可以进一步被配置为在其中在从接收到第一音频信号起的
阈值时间内接收到第二音频信号的情况下获取相似性。
22.所述至少一个处理器可以进一步被配置为在从接收到第一音频信号起的阈值时间之后接收到第二音频信号的情况下,或者在其中相似性低于阈值的情况下,分别将第一传感器装置和第二传感器装置识别为第一有效传感器装置和第二有效传感器装置;并对于从第一有效传感器装置和第二有效传感器装置中的每一个接收到的附加音频信号执行语音识别。
23.所述至少一个处理器可以进一步被配置为获取第一音频信号和第二音频信号之间的时域相似性,获取第一音频信号和第二音频信号之间的频域相似性,和基于时域相似性或者频域相似性中的至少一个获取相似性。
24.所述至少一个处理器可以进一步被配置为基于第一传感器装置或者第二传感器装置之一被识别为有效传感器装置,在从识别出有效传感器装置起的阈值时间内忽略从第一传感器装置或者第二传感器装置中的另一个接收到的附加音频信号。
25.根据本公开的另一实施例,提供了一种电子设备的控制方法。所述电子设备的控制方法包括:通过通信接口分别从第一传感器装置和位置远离第一传感器装置的第二传感器装置接收第一音频信号和第二音频信号;获取第一音频信号和第二音频信号之间的相似性;在相似性等于或者高于阈值的情况下,基于位置与第一传感器装置相邻的电子设备的操作状态从第一音频信号获取第一预测的音频分量,和基于位置与第二传感器装置相邻的电子设备的操作状态,从第二音频信号获取第二预测的音频分量;基于第一预测的音频分量和第二预测的音频分量将第一传感器装置或者第二传感器装置之一识别为有效传感器装置;和对于从有效传感器装置接收到的附加音频信号执行语音识别。
26.第一预测的音频分量和第二预测的音频分量的获取可以包括:基于该电子设备和至少一个电子设备中的每一个的操作状态,基于模式特定音频模型识别和位置与第一传感器装置相邻的电子设备的操作状态和位置与第二传感器装置相邻的电子设备的操作状态对应的模式;和基于识别的模式分别从第一音频信号和第二音频信号获取第一预测的音频分量和第二预测的音频分量,且当多个传感器装置中的每一个学习基于相邻电子设备的操作状态获取的音频时,可以通过人工智能算法获取音频模型。
27.基于识别的模式的第一预测的音频分量和第二预测的音频分量的获取可以包括:基于识别的模式分别从第一音频信号中包括的噪声分量和第二音频信号中包括的噪声分量获取第一预测的音频分量和第二预测的音频分量;和分别基于第一预测的音频分量的幅值和第二预测的音频分量的幅值获取第一音频信号的第一质量特性和第二音频信号的第二质量特性,和在识别为有效传感器装置时,第一传感器装置或者第二传感器装置之一可以基于第一质量特性和第二质量特性被识别为有效传感器装置。
28.所述控制方法可以进一步包括改变位置与第一传感器装置相邻的电子设备的操作状态和位置与第二传感器装置相邻的电子设备的操作状态,以允许位置与第一传感器装置相邻的电子设备和位置与第二传感器装置相邻的电子设备根据预定事件以预定模式操作。
29.所述控制方法可以进一步包括基于语音识别结果控制电子设备或者至少一个其他电子设备中的至少一个,和控制有效传感器装置以提供通知控制结果的通知消息。
30.在相似性的获取时,可以在其中在从接收到第一音频信号起的阈值时间内接收到
第二音频信号的情况下获取相似性。
31.所述控制方法可以进一步包括在从接收到第一音频信号起的阈值时间之后接收到第二音频信号的情况下,或者在其中相似性低于阈值的情况下,分别将第一传感器装置和第二传感器装置识别为第一有效传感器装置和第二有效传感器装置;并对于从第一有效传感器装置和第二有效传感器装置中的每一个接收到的附加音频信号执行语音识别。
32.相似性的获取可以包括获取第一音频信号和第二音频信号之间的时域相似性,获取第一音频信号和第二音频信号之间的频域相似性,和基于时域相似性或者频域相似性中的至少一个获取相似性。
33.所述控制方法可以进一步包括基于第一传感器装置或者第二传感器装置之一被识别为有效传感器装置,在从识别有效传感器装置起的阈值时间内忽略从第一传感器装置或者第二传感器装置中的另一个接收到的附加音频信号。
34.根据本公开的另一实施例,提供了一种电子设备。该设备包括麦克风、通信接口和至少一个处理器,该至少一个处理器被配置为:通过麦克风接收第一音频信号;通过通信接口从传感器装置接收第二音频信号;获取第一音频信号和第二音频信号之间的相似性;在相似性等于或者高于阈值的情况下,基于该电子设备和位置与传感器装置相邻的电子设备中的每一个的操作状态,分别从第一音频信号和第二音频信号获取第一预测的音频分量和第二预测的音频分量;基于第一预测的音频分量和第二预测的音频分量将该电子设备或者传感器装置之一识别为有效装置;和对于从有效装置接收到的附加音频信号执行语音识别。
35.有益技术效果
36.根据如上所述的本公开的各种实施例,电子设备可以优先多个传感器装置之一以防止比如处理的重复和资源的浪费的问题。
37.对于本领域技术人员,本公开的其它方面、优点和显著特征将从以下详细说明变得清楚,以下的详细说明结合附图公开了本公开的各种实施例。
附图说明
38.从结合附图的以下详细说明,本公开的某些实施例的上述及其他方面、特征和优点将更为明显,在附图中:
39.图1是图示根据本公开的实施例的电子系统的图;
40.图2a是图示根据本公开的实施例的电子设备的配置的示例的框图;
41.图2b是图示根据本公开的实施例的电子设备的特定配置的示例的框图;
42.图2c是图示根据本公开的实施例的存储器中存储的模块的示例的框图;
43.图2d是图示根据本公开的实施例的语音识别模块的示例的框图;
44.图2e是图示根据本公开的实施例的传感器装置的配置的示例的框图;
45.图2f是图示根据本公开的实施例的服务器的配置的示例的框图;
46.图3是用于描述根据本公开的实施例的语音识别方法的图;
47.图4是用于描述根据本公开的实施例的语音识别方法的图;
48.图5是用于描述根据本公开的实施例的语音识别方法的图;
49.图6是用于描述根据本公开的实施例的语音识别方法的图;
50.图7a是用于描述根据本公开的实施例的电子系统的操作的序列图;
51.图7b是用于描述根据本公开的另一实施例的电子系统的操作的序列图;
52.图8是用于描述根据本公开的实施例的对话系统的框图;
53.图9a、图9b和图9c是用于描述根据本公开的实施例的扩展示例的图;
54.图10a和图10b是用于描述根据本公开的各种实施例的装置的优先级设置的图;
55.图11是用于描述根据本公开的实施例的使用服务器的方法的图;和
56.图12是用于描述根据本公开的实施例的电子设备的控制方法的流程图。
57.在全部附图中,相同的附图标记将理解为表示相同的部分、组成和结构。
具体实施方式
58.发明实施方式
59.提供参考附图的以下描述以帮助对通如权利要求和它们的等效物所定义的本公开的各种实施例的全面理解。它包括各种特定细节以帮助理解但是这些被认为仅是示例性的。因此,本领域普通技术人员将认识到在不脱离本公开的范围和精神的情况下可以做出在这里描述的各种实施例的各种改变和修改。另外,为了清楚和简明,可以省略对公知功能和结构的描述。
60.以下说明书和权利要求中使用的术语和词不限于字面的含义,而是仅由本发明人使用以使得能够清楚和一致地理解本公开。因此,对本领域技术人员来说清楚的是,出于说明的目的而不是出于限制通过所附权利要求和它们的等效物所定义的本公开的目的提供以下对本公开的各种实施例的描述。
61.将要理解单数形式“一”、“一个”和“该”包括复数指代,除非上下文清楚地指示。因此,例如,对“一个组件表面“的指代包括对一个或多个这种表面的指代。
62.当前广泛使用的一般术语考虑本公开中的功能被选为本公开的实施例中使用的术语,但是可以取决于本领域技术人员的意图或者司法判例、新技术的出现等而改变。另外,在特定情况下,可能存在由申请人任意选择的术语。在该情况下,这种术语的含义将在本公开的相应说明书部分中具体提到。因此,本公开的实施例中使用的术语应该基于遍及本公开的术语和内容的含义,而不是术语的简单名称而定义。
63.在说明书中,表达“具有”、“可以具有”、“包括”、“可以包括”等指示相应的特征(例如,数值、功能、操作或者比如部分的组件)的存在且不排除附加特征的存在。
[0064]“a或/和b中的至少一个”的表达应该被理解为指示“a或者b”或者“a和b”。
[0065]
说明书中使用的表达“第一”、“第二”等可以指示各种组件而与组件的序列和/或重要性无关,将仅为了区分一个组件与其他组件而使用,且不限制相应的组件。
[0066]
当提到任何组件(例如,第一组件)(操作地或者通信地)与另一组件(例如,第二组件),耦合/耦合到或者连接到该另一组件时,将理解任何组件直接耦合到另一组件或者可以通过其他组件(例如,第三组件)耦合到另一组件。
[0067]
单数形式意在包括复数形式,除非上下文清楚地指示例外。将进一步理解在说明书中使用的术语“包括”或者“由...形成”指定说明书中提到的特征、数字、操作、组件、部分或者其组合的存在,但是不排除一个或多个其他特征、数字、操作、组件、部分或者其组合的存在或者附加。
[0068]
在本公开中,“模块”或者“...器”可以执行至少一个功能或操作,且由硬件或者软件实现或者由硬件和软件的组合实现。另外,多个“模块”或者多个“...器”可以集成在至少一个模块中且由除了需要由特定硬件实现的"模块"或者"...器"之外的至少一个处理器(未示出)实现。
[0069]
在本公开中,术语“用户”可以是使用电子设备的人或者使用电子设备的设备(例如,人工智能(ai)电子设备)。
[0070]
在下文中,将参考附图具体描述本公开的实施例。
[0071]
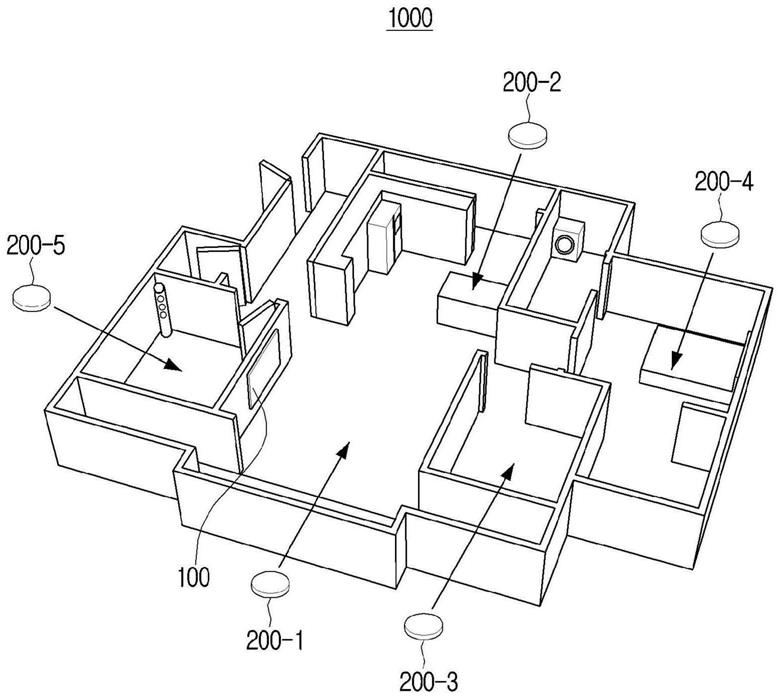
图1是图示根据本公开的实施例的电子系统的图。
[0072]
参考图1,电子系统1000包括电子设备100和多个传感器装置200
‑
1、200
‑
2、200
‑
3、200
‑
4和200
‑
5。这里,电子设备100可以被称为边缘设备、边缘计算设备或者集线器设备,且传感器装置(例如,200
‑
1到200
‑
5中的任意)可以被称为点装置。
[0073]
根据说明书中的各种实施例的电子装置的实例例如可包括以下的至少一个:扬声器、智能电话、平板个人计算机(pc)、移动电话、图像电话、电子书阅读器、桌面pc、膝上型pc、上网本计算机、工作站、服务器、个人数字助理(pda)、便携式多媒体播放器(pmp)、mp3播放器、医疗装置、相机或者可穿戴装置。可穿戴装置可以包括配件类型的可穿戴装置(例如,手表、手环、手链、脚链、项链、眼镜、隐形眼镜或者头戴装置(hmd)),织物或者衣服整体类型的可穿戴装置(例如,电子衣服),身体附着类型的可穿戴装置(例如,皮肤垫或者纹身)或者活体可植入电路中的至少一个。根据实施例,电子设备100例如可包括以下的至少一个:电视(tv)、数字多用途盘(dvd)播放器、音频播放器、冰箱、空调、真空吸尘器、烤箱、微波炉、洗衣机、空气净化器、机顶盒、家庭自动化控制面板、安全控制面板、媒体盒(例如,三星homesync
tm
、苹果tv
tm
或者谷歌tv
tm
)、游戏主机(例如,xbox
tm
或者playstation
tm
)、电子词典、电子钥匙、摄录一体机或者数字相框。
[0074]
根据其他实施例,电子设备100可以包括各种医疗装置(例如,各种便携式医学测量装置(比如血糖仪、心率计、血压计和体温计)、磁谐振血管造影(mra)核磁共振成像(mri)、计算断层分析(ct)、拍照装置和超声装置)、导航装置、全球导航卫星系统(gnss)、事件数据记录器(edr)、飞行数据记录器(fdr)、汽车文娱新闻装置、船舶电子设备(例如,船舶导航装置或者陀螺仪)、航空电子设备、安全装置、汽车头部单元、工业或者家庭机器人、无人机、金融机构的自动付款机(atm)、商店的销售点(pos)或者物联网(iot)装置(例如,灯泡、各种传感器、喷洒灭火系统、火警、恒温器、街灯、烤面包炉、训练设备、热水箱、加热器和锅炉)。
[0075]
虽然为了说明的方便,图1图示电子设备100是tv的情况,电子设备100可以是不同于tv的装置。例如,冰箱、洗衣机或者扬声器之一可以操作为电子设备100。
[0076]
替代地,多个家用电器可以操作为电子设备100。例如,tv可以操作为第一电子设备,冰箱可以操作为第二电子设备,且第一电子设备和第二电子设备可以彼此合作地操作或者单独地操作。将在以下提供其说明。
[0077]
电子设备100可以从多个传感器装置200
‑
1到200
‑
5中的至少一个接收音频信号。例如,电子设备100可以接收与说法“将冰箱的温度降低”对应的音频信号,且在该情况下,电子设备100可以将用于降低冰箱的温度的控制指令发送到冰箱。这里,多个传感器装置200
‑
1到200
‑
5可以是每个均接收环境音频且每个均发送音频信号到电子设备100的装置。
[0078]
电子设备100可以从多个传感器装置200
‑
1到200
‑
5当中的第一传感器装置200
‑
1接收第一音频信号和从第二传感器装置200
‑
2接收第二音频信号,且可以获取第一音频信号和第二音频信号之间的相似性(即,确定相似性)。这里,接收到第一音频信号的时间点可以实质上与接收到第二音频信号的时间点相同。
[0079]
例如,在用户在客厅讲话“hi bixby”的情况下,电子设备100可以从位于客厅中的第一传感器装置200
‑
1接收与"hi bixby"对应的第一音频信号。另外,用户的讲话也可以输入到位于厨房中的第二传感器装置200
‑
2,且电子设备100可以从位于厨房的第二传感器装置200
‑
2接收与“hi bixby”对应的第二音频信号。第二传感器装置200
‑
2位置比第一传感器装置200
‑
1远离电子设备100,且因此电子设备100接收第二音频信号的时间点可能比电子设备100接收第一音频信号的时间点晚。
[0080]
在相似性等于或者高于阈值的情况下,电子设备100可以基于第一音频信号和第二音频信号将第一传感器装置200
‑
1或者第二传感器装置200
‑
2之一识别为有效传感器装置,并对于从有效传感器装置接收到的附加音频信号执行语音识别。
[0081]
作为示例,在确定第一音频信号和第二音频信号来自相同讲话的情况下,电子设备100可以仅将第一传感器装置200
‑
1或者第二传感器装置200
‑
2之一识别为有效传感器装置。此时,电子设备100可以将通知该传感器装置是有效传感器装置的信号发送到识别为有效传感器装置的传感器装置,且该传感器装置可以基于接收到的信号提供警报。例如,一旦接收到通知传感器装置是有效传感器装置的信号,则传感器装置可以通过发光二极管(led)通知、声音通知等通知用户传感器装置处于语音识别激活状态。
[0082]
电子设备100可以基于第一音频信号和第二音频信号中的每一个的质量特性仅将第一传感器装置200
‑
1或者第二传感器装置200
‑
2之一识别为有效传感器装置。这里,音频信号的质量特性可以包括音频信号的强度、功率或者信噪比(snr)特性中的至少一个。
[0083]
即使从未被识别为有效传感器装置的传感器装置接收到附加音频信号,电子设备100也可以不执行语音识别。
[0084]
电子系统1000可以进一步包括至少一个其他电子设备(未示出)。这里,其他电子设备是由电子设备100控制的设备,且可以执行与电子设备100的通信。另外,在有些情况下,其他电子设备也可以执行电子设备100的某些操作。在下文中,为了说明的方便将描述电子系统1000仅包括第一传感器装置200
‑
1和第二传感器装置200
‑
2的情况。
[0085]
多个传感器装置200
‑
1到200
‑
5中的每一个可以设置在距其他电子设备的预定距离内。但是,本公开不限于此,且传感器装置也可以设置在在预定距离内不存在该电子设备或者其他电子设备的位置处。
[0086]
多个传感器装置200
‑
1到200
‑
5中的每一个可以接收用户语音或者其他声音。另外,多个传感器装置200
‑
1到200
‑
5中的每一个可以将输入用户语音等转换为音频信号,并将音频信号发送到电子设备100。
[0087]
替代地,一旦接收到包括触发词或者唤醒词的用户语音,则多个传感器装置200
‑
1到200
‑
5中的每一个可以被唤醒,且可以将与在唤醒之后接收到的用户语音对应的音频信号发送到电子设备100。例如,一旦接收到触发词则多个传感器装置200
‑
1到200
‑
5中的每一个可以被唤醒,且可以将与唤醒之后接收到的用户语音对应的音频信号发送到电子设备100。作为示例,多个传感器装置200
‑
1到200
‑
5中的每一个可以以待机模式操作,以显著地
减小功耗和防止不必要的音频信号被发送到电子设备100。
[0088]
但是,本公开不限于此,且例如,一旦检测到用户,则多个传感器装置200
‑
1到200
‑
5中的每一个可以被唤醒,且可以将与检测到用户之后的用户语音输入对应的音频信号发送到电子设备100。例如,多个传感器装置200
‑
1到200
‑
5中的每一个可以包括一旦检测到用户的运动则唤醒的运动传感器,且可以将与唤醒之后的用户语音输入对应的音频信号发送到电子设备100。替代地,多个传感器装置200
‑
1到200
‑
5中的每一个可以包括一旦检测到用户的触摸则唤醒的照度传感器,且可以将与唤醒之后的用户语音输入对应的音频信号发送到电子设备100。替代地,多个传感器装置200
‑
1到200
‑
5中的每一个可以包括红外传感器、热传感器、声音传感器等以检测用户,且可以将与检测到用户之后的用户语音输入对应的音频信号发送到电子设备100。
[0089]
多个传感器装置200
‑
1到200
‑
5中的每一个可以通过语音动作检测(vad)或者结束点检测(epd)中的至少一个检测用户语音。vad和epd是通常在语音识别领域中使用以通过基于语音的音量、频域中的能量分布等使用统计模型、深度学习模型等检测用户语音的技术。
[0090]
除与输入用户语音对应的音频信号之外,多个传感器装置200
‑
1到200
‑
5中的每一个可以将指示通过vad获取的用户语音的语音动作的时间信息,或者指示通过epd获取的用户语音的结束点的时间信息中的至少一个发送到电子设备100。例如,传感器装置200
‑
1可以将与用户语音对应的音频信号,和指示用户语音的结束点的时间信息(am 9:00:00和am 9:00:03)发送到电子设备100。
[0091]
一旦从第一传感器装置200
‑
1和第二传感器装置200
‑
2接收到指示第一用户语音和第二用户语音中的每一个的语音动作的时间信息或者指示用户语音的结束点的时间信息中的至少一个,则电子设备100可以基于接收到的信息获取与第一用户语音对应的第一音频信号和与第二用户语音对应的第二音频信号之间的相似性。
[0092]
例如,电子设备100可以接收与第一用户语音对应的第一音频信号,和指示来自第一传感器装置200
‑
1的第一用户语音的结束点的时间信息(am 9:00:00和am 9:00:03),并接收与第二用户语音对应的第二音频信号,和指示来自第二传感器装置200
‑
2的第二用户语音的结束点的时间信息(am 9:00:01和am 9:00:04)。另外,因为第一用户语音的结束点之间的时间差和第二用户语音的结束点之间的时间差彼此相同,电子设备100可以确定第一音频信号和第二音频信号来自相同用户语音。
[0093]
但是,本公开不限于此,且多个传感器装置200
‑
1到200
‑
5中的每一个可以仅将与输入用户语音对应的音频信号发送到电子设备100。在该情况下,电子设备100可以通过vad获取指示用户语音的语音动作的时间信息,且通过epd获取指示用户语音的结束点的时间信息。
[0094]
图2a是图示根据本公开的实施例的电子设备的配置的示例的框图。
[0095]
参考图2a,电子设备100包括通信接口110和处理器120。
[0096]
通信接口110是用于执行与各种设备的通信的组件。例如,通信接口110可以由比如蓝牙(bt)、蓝牙低能量(ble)、无线高保真(wi
‑
fi)和zigbee的各种通信接口实现。但是,本公开不限于此,且通信接口110可以由可以执行无线通信的任意通信接口实现。
[0097]
另外,通信接口110可以包括可以执行与各种设备的有线通信的输入和输出接口。
例如,通信接口110可以包括比如高清晰度多媒体接口(hdmi)、移动高清晰度链路(mhl)、通用串行总线(usb)、rgb、d
‑
超小型(d
‑
sub)和数字视觉接口(dvi)的输入和输出接口,且可以执行与各种设备的通信。
[0098]
但是,本公开不限于此,且输入和输出接口可以由可以执行数据发送和接收的任何标准实现。
[0099]
电子设备100可以连接到多个传感器装置200
‑
1到200
‑
5以接收音频信号。电子设备100可以将与音频信号对应的控制指令发送到另一电子设备。另外,电子设备100可以将通知控制结果的通知消息发送到有效传感器装置。
[0100]
除如上所述的接口之外,通信接口110可以包括可以执行与各种设备的有线或者无线通信的任何通信标准接口。
[0101]
处理器120总的控制电子设备100的操作。
[0102]
处理器120可以由处理数字信号的数字信号处理器(dsp)、微处理器或者时间控制器(tcon)实现。但是,本公开不限于此,且处理器120可以包括中央处理单元(cpu)、微控制器单元(mcu)、微处理单元(mpu)、控制器、应用处理器(ap)、图形处理单元(gpu)、通信处理器(cp)或者arm处理器中的一个或多个,或者可以由这些术语定义。另外,处理器120可以由其中嵌入处理算法的片上系统(soc)或者大规模集成电路(lsi)实现,或者可以以现场可编程门阵列(fpga)形式实现。处理器120可以通过执行存储器中存储的计算机可执行指令来执行各种功能。
[0103]
处理器120可以通过通信接口110分别从第一传感器装置200
‑
1和位置远离第一传感器装置200
‑
1的第二传感器装置200
‑
2接收第一音频信号和第二音频信号;获取第一音频信号和第二音频信号之间的相似性;在相似性等于或者高于阈值的情况下,基于位置与第一传感器装置200
‑
1相邻的电子设备的操作状态从第一音频信号获取第一预测的音频分量,和基于位置与第二传感器装置200
‑
2相邻的电子设备的操作状态,从第二音频信号获取第二预测的音频分量;基于第一预测的音频分量和第二预测的音频分量,将第一传感器装置200
‑
1或者第二传感器装置200
‑
2之一识别为有效传感器装置;和对于从有效传感器装置接收到的附加音频信号执行语音识别。
[0104]
这里,电子设备100可以进一步包括存储器(未示出),其中存储基于该电子设备100和至少一个其他电子设备中的每一个的操作状态的模式特定音频模型。例如,音频模型可以是基于多个模式分类的数据。作为多个模式的示例,第一模式可以指示其中位置与第一传感器装置200
‑
1相邻的tv和位置与第二传感器装置200
‑
2相邻的真空吸尘器开启的状态,第二模式可以指示其中仅tv或者真空吸尘器之一开启的状态,且第三模式可以指示其中tv和真空吸尘器两者都关闭的状态。音频模型可以包括关于到处于第一模式的第一传感器装置200
‑
1和第二传感器装置200
‑
2中的每一个的音频输入的信息,关于到处于第二模式的第一传感器装置200
‑
1和第二传感器装置200
‑
2中的每一个的音频输入的信息,和关于到处于第三模式的第一传感器装置200
‑
1和第二传感器装置200
‑
2中的每一个的音频输入的信息。
[0105]
但是,音频模型的以上描述仅是示例,且音频模型可以是其他类型的数据。例如,除tv和真空吸尘器的操作状态之外,音频模型可以进一步包括冰箱、洗衣机等的操作状态。除开启状态和关闭状态之外,每个设备的操作状态可以包括进一步细分的操作状态。例如,
tv的操作状态可以进一步包括比如待机状态、帧状态和发光状态的操作状态,真空吸尘器的操作状态可以进一步包括比如低噪声状态和功率输出状态的操作状态,冰箱的操作状态可以进一步包括比如冷冻存储状态、冷藏存储状态和泡菜致冷状态的操作状态,且洗衣机的操作状态可以进一步包括比如毯子洗涤状态和精洗状态的操作状态。进一步,音频模型可以包括关于到一个传感器装置或者三个或更多传感器装置的音频输入的信息。
[0106]
当多个传感器装置中的每一个通过人工智能算法学习基于相邻电子设备的操作状态获取的音频时,可以获取音频模型。但是,本公开不限于此,且也可以当多个传感器装置中的每一个基于规则学习基于相邻电子设备的操作状态获取的音频时获取音频模型。音频模型也可以由电子设备100以外的单独的电子设备获取。但是,本公开不限于此,且电子设备100可以通过人工智能算法获取音频模型。
[0107]
处理器120可以基于音频模型识别与位置与第一传感器装置200
‑
1相邻的电子设备的操作状态和位置与第二传感器装置200
‑
2相邻的电子设备的操作状态对应的模式,并基于识别的状态从第一音频信号和第二音频信号获取第一预测的音频分量和第二预测的音频分量。
[0108]
这里,处理器120可以实时地识别电子设备100的操作状态。进一步,处理器120可以预先存储另一电子设备的操作状态。例如,其他电子设备可以在预定时间间隔将其操作状态发送到电子设备100。替代地,其他电子设备可以每次改变操作状态都将其改变的操作状态发送到电子设备100。
[0109]
但是,本公开不限于此,且一旦接收到音频信号,处理器120可以将请求其他电子设备的操作状态的信号发送到其他电子设备,并从其他电子设备接收操作状态。
[0110]
处理器120可以基于识别的状态分别从第一音频信号中包括的噪声分量和第二音频信号中包括的噪声分量获取第一预测的音频分量和第二预测的音频分量;分别基于第一预测的音频分量的幅值和第二预测的音频分量的幅值获取第一音频信号的第一质量特性和第二音频信号的第二质量特性;和基于将第一质量特性和第二质量特性将第一传感器装置200
‑
1或者第二传感器装置之一识别为有效传感器装置。将在以下参考附图提供其详细说明。
[0111]
处理器120可以改变位置与第一传感器装置200
‑
1相邻的电子设备的操作状态和位置与第二传感器装置相邻的电子设备的操作状态,以允许位置与第一传感器装置200
‑
1相邻的电子设备和位置与第二传感器装置相邻的电子设备以根据预定事件的预定模式操作。例如,处理器120可以改变电子设备100和另一电子设备的操作状态以允许一旦接收到第一音频信号和第二音频信号,则位置与第一传感器装置200
‑
1相邻的tv和位置与第二传感器装置200
‑
2相邻的真空吸尘器以预定模式操作。
[0112]
替代地,一旦第一传感器装置200
‑
1和第二传感器装置200
‑
2中的每一个根据触发信号唤醒,则指示第一传感器装置200
‑
1和第二传感器装置200
‑
2中的每一个唤醒的信号可以被发送到电子设备100。电子设备100也可以改变位置与第一传感器装置200
‑
1相邻的电子设备的操作状态和位置与第二传感器装置相邻的电子设备的操作状态,以允许位置与第一传感器装置200
‑
1相邻的电子设备和位置与第二传感器装置相邻的电子设备根据接收到的信号以预定模式操作。
[0113]
这里,预定模式可以是其中从位置与第一传感器装置200
‑
1相邻的电子设备和位
置与第二传感器装置200
‑
2相邻的电子设备中的每一个生成的音频的音量被最小化的操作状态。例如,在其中tv开启的状态下,处理器120可以根据预定事件对tv静音。替代地,在其中操作真空吸尘器的状态下,处理器120可以根据预定事件临时停止真空吸尘器。
[0114]
通过上述操作,处理器120可以在从有效传感器装置接收到附加音频信号之前,改变位置与第一传感器装置200
‑
1相邻的电子设备的操作状态和位置与第二传感器装置200
‑
2相邻的电子设备的操作状态。作为示例,在用户说出与触发信号对应的语音之后说出与控制指令对应的语音时,由位置与第一传感器装置200
‑
1相邻的电子设备和位置与第二传感器装置200
‑
2相邻的电子设备引起的噪声可以显著地减小。例如,在其中tv开启的状态下用户说出“hi bixby,给我显示今天的电影列表”的情况下,处理器120可以将“hi bixby”识别为触发信号,并在“给我显示今天的电影列表”之前将tv静音。与“给我显示今天的电影列表”对应的音频信号可以具有相对低于静音之前的噪声。通过这种操作,可以改进语音识别性能。
[0115]
处理器120可以基于语音识别结果控制电子设备100或者至少一个其他电子设备之一,并控制有效传感器装置以提供通知控制结果的通知消息。
[0116]
例如,处理器120可根据语音识别结果改变tv的频道,并将通知tv的频道改变的通知消息发送到有效传感器装置。有效传感器装置可以包括扬声器,并通过扬声器输出通知tv的频道被改变的通知消息。替代地,有效传感器装置可包括显示器,并通过显示器显示通知tv的频道被改变的通知消息。
[0117]
处理器120可以获取第一音频信号和第二音频信号之间的时域相似性,获取第一音频信号和第二音频信号之间的频域相似性,和基于时域相似性或者频域相似性中的至少一个获取相似性。
[0118]
例如,处理器120可以通过第一音频信号和第二音频信号的互相关获取时域相似性,并通过使用时域相似性确定第一音频信号和第二音频信号之间的相似性。替代地,处理器120可以通过频谱相干性获取频域相似性并通过使用频域相似性确定第一音频信号和第二音频信号之间的相似性。替代地,处理器120可以通过计算时域相似性和频域相似性的加权和来确定第一音频信号和第二音频信号之间的相似性。
[0119]
处理器120可以在从接收到第一音频信号起的阈值时间内接收到第二音频信号的情况下获取相似性。作为示例,处理器120可以在从接收到第一音频信号起的阈值时间之后接收到第二音频信号的情况下不获取相似性。例如,处理器120可以在从接收到第一音频信号起的0.01秒内接收到第二音频信号的情况下获取相似性,且可以基于获取的相似性最终识别有效传感器装置。
[0120]
替代地,处理器120可以基于第一音频信号的讲话时间点和第二音频信号的讲话时间点获取相似性。例如,处理器120可以接收指示用户语音的语音动作的时间信息,或者指示来自第一传感器装置200
‑
1和第二传感器装置200
‑
2中的每一个的用户语音的结束点的时间信息中的至少一个。另外,处理器120可以基于接收到的信息比较用户语音开始点,并在用户语音开始点之间的差等于或者短于阈值时间的情况下获取第一音频信号和第二音频信号之间的相似性。
[0121]
作为示例,处理器120可基于第一音频信号和第二音频信号的时间中的接收点,和第一音频信号和第二音频信号之间的相似性识别有效传感器装置。因此,处理器120可以解
决在多个用户说出语音的情况下可能出现的问题。
[0122]
例如,在第一用户在第一传感器装置200
‑
1的附近说出第一用户语音,第二用户在第二传感器装置200
‑
2的附近说出第二用户语音,且第一用户的讲话时间点和第二用户的讲话时间点之间的差超过阈值时间的情况下,处理器120可以执行与第一用户语音和第二用户语音中的每一个对应的控制操作而不执行获取相似性的操作和识别有效传感器装置的操作。
[0123]
替代地,在第一用户在第一传感器装置200
‑
1附近说出第一用户语音,第二用户在第二传感器装置200
‑
2附近说出第二用户语音,且第一用户的讲话时间点和第二用户的讲话时间点之间的差等于或者短于阈值时间的情况下,处理器120可以获取相似性。但是,在该情况下,相似性可能低于阈值。因此,处理器120可确定分别从第一传感器装置200
‑
1和第二传感器装置200
‑
2接收到的第一音频信号和第二音频信号是彼此不同的信号,且可对于第一音频信号和第二音频信号中的每一个执行语音识别。即使在第一用户语音输入到第二传感器装置200
‑
2且第二用户语音输入到第一传感器装置200
‑
1的情况下,在第一传感器装置200
‑
1附近第一用户语音的音量高于第二用户语音的音量,且在第二传感器装置200
‑
2附近第二用户语音的音量高于第一用户语音的音量。另外,第一用户语音的音调和第二用户语音的音调彼此不同,且因此由第一传感器装置200
‑
1接收到的音频信号和由第二传感器装置200
‑
2接收到的音频信号彼此不同以使得处理器120获取低于阈值的相似性。
[0124]
一旦第一传感器装置200
‑
1或者第二传感器装置200
‑
2之一被识别为有效传感器装置,则处理器120可以在从识别出有效传感器装置起的阈值时间内忽略从第一传感器装置200
‑
1或者第二传感器装置200
‑
2中的另一个接收到的附加音频信号。
[0125]
例如,在第一传感器装置200
‑
1被识别为有效传感器装置的情况下,处理器120可以仅对于从第一传感器装置200
‑
1接收到的附加音频信号执行语音识别,且可以不对于从第二传感器装置200
‑
2接收到的附加音频信号执行语音识别。替代地,在第一传感器装置200
‑
1被识别为有效传感器装置的情况下,处理器120可以将在阈值时间期间停止第二传感器装置200
‑
2的音频接收功能的指令发送到第二传感器装置200
‑
2。在第二传感器装置200
‑
2在阈值时间期间不接收音频的情况下,处理器120可以在阈值时间期间仅接收从第一传感器装置200
‑
1发送的附加音频信号。
[0126]
如上所述,在分别从第一传感器装置200
‑
1和第二传感器装置200
‑
2接收到彼此类似的第一音频信号和第二音频信号的情况下,处理器120可仅将第一传感器装置200
‑
1或者第二传感器装置200
‑
2之一识别为用于执行语音识别的装置。例如,处理器120可通过仅预测彼此类似的第一音频信号和第二音频信号的音频分量来确定有效传感器装置,并对于从有效传感器装置接收到的音频信号执行语音识别。作为示例,不对于全部音频信号执行语音识别,以使得可以显著地减小资源浪费,改进网络效率,和解决比如处理的重复的问题。
[0127]
上面已经描述了在从接收到第一音频信号起的阈值时间内接收到第二音频信号,且相似性等于或者高于阈值的情况下的处理器120的操作。
[0128]
相反地,在从接收到第一音频信号起的阈值时间之后接收到第二音频信号,或者相似性低于阈值的情况下,处理器120可以将第一传感器装置200
‑
1和第二传感器装置200
‑
2分别识别为第一有效传感器装置和第二有效传感器装置,并对于从第一有效传感器装置和第二有效传感器装置中的每一个接收到的附加音频信号执行语音识别。作为示例,在从
接收到第一音频信号起的阈值时间之后接收到第二音频信号的情况下,或者在相似性低于阈值的情况下,处理器120可以将第一音频信号第二音频信号识别为彼此不同的信号,并对于从第一有效传感器装置接收到的附加音频信号和从第二有效传感器装置接收到的附加音频信号中的每一个执行语音识别。此时,处理器120可以顺序地或者同时处理多个附加音频信号。
[0129]
处理器120可以基于第一音频信号和第二音频信号中的每一个的音频音量或者功率确定是否获取第一音频信号和第二音频信号之间的相似性。例如,在第一音频信号的音频音量低于阈值的情况下,处理器120可不获取相似性,并将发送第二音频信号的第二有效传感器装置200
‑
2识别为有效传感器装置。
[0130]
处理器120可以在接收到音频信号之前将语音识别功能保持于待机状态。作为示例,处理器120可以在接收到音频信号之前将用于执行语音识别的模块保持于待机状态。一旦接收到音频信号,处理器120可以解除待机状态。通过这种操作,可以减小功耗。
[0131]
上面已描述了处理器120在接收第一音频信号和第二音频信号之后识别有效传感器装置并对于从有效传感器装置接收到的附加音频信号执行语音识别的情况。例如,第一传感器装置200
‑
1和第二传感器装置200
‑
2可接收讲话“hi bixby”,且处理器120可分别从第一传感器装置200
‑
1和第二传感器装置200
‑
2接收第一音频信号和第二音频信号,并将第一传感器装置200
‑
1识别为有效传感器装置。第一传感器装置200
‑
1和第二传感器装置200
‑
2可讲话“开启tv”,处理器120可从第一传感器装置200
‑
1接收与"开启tv"对应的附加音频信号,并对于该附加音频信号执行语音识别。作为示例,上面已描述了仅对于在触发信号之后接收到的音频信号执行语音识别的情况。
[0132]
但是,本公开不限于此,且用户也可仅以讲“开启tv”控制tv而没有比如“hi bixby”的讲话。例如,第一传感器装置200
‑
1和第二传感器装置200
‑
2可接收讲话“开启tv”,且处理器120可分别从第一传感器装置200
‑
1和第二传感器装置200
‑
2接收第一音频信号和第二音频信号,并将第一传感器装置200
‑
1识别为有效传感器装置。另外,处理器120可对于从第一传感器装置200
‑
1接收到的第一音频信号执行语音识别,和对于另外从第一传感器装置200
‑
1接收到的附加音频信号执行语音识别。在该情况下,第一传感器装置200
‑
1和第二传感器装置200
‑
2可连续地处于其中解除待机模式的状态。
[0133]
虽然上面已描述了电子设备100从多个传感器装置接收多个音频信号的情况,本公开不限于此。例如,电子设备100可以包括麦克风(未示出)、通信接口110和处理器120。另外,处理器120可以通过麦克风接收第一音频信号,通过通信接口110从传感器装置接收第二音频信号,获取第一音频信号和第二音频信号之间的相似性,在相似性等于或者高于阈值的情况下,基于电子设备100和位置与传感器装置相邻的电子设备中的每一个的操作状态分别从第一音频信号和第二音频信号获取第一预测的音频分量和第二预测的音频分量,基于第一预测的音频分量和第二预测的音频分量将电子设备100或者传感器装置之一识别为有效装置,并对于从有效装置接收到的附加音频信号执行语音识别。例如,在电子设备100是空调的情况下,空调可以基于空调的操作状态获取直接通过在空调中提供的麦克风接收的第一音频信号的第一质量特性。空调可以通过比较第一质量特性与从传感器装置接收到的第二音频信号的第二质量特性来识别有效装置。
[0134]
根据本公开的与人工智能有关的功能由处理器120和存储器执行。
[0135]
处理器120可以由一个处理器或者多个处理器组成。这里,一个或者多个处理器可以是比如cpu的通用处理器、ap或者数字信号处理器(dsp)、比如gpu的图形专用处理器或者视觉处理单元(vpu),或者比如神经处理单元(npu)的人工智能专用处理器。
[0136]
一个或者多个处理器执行控制以根据存储器中存储的预定义的操作规则或者人工智能模型处理输入数据。替代地,在一个或者多个处理器是人工智能专用处理器的情况下,人工智能专用处理器可以被设计为具有在特定人工智能模型的处理中专用的硬件结构。通过学习获得预定义的操作规则或者人工智能模型。
[0137]
这里,通过学习获得预定义的操作规则或者人工智能模型指的是基本人工智能模型通过使用学习算法学习多个学习数据以获得设置为实现期望特性(或者目的)的预定义的操作规则或者人工智能模型。这种学习可由其中根据本公开执行人工智能的装置执行,或者通过单独的服务器和/或系统执行。学习算法的示例包括有监督学习、无监督学习、半监督学习和增强学习,但是不限于此。
[0138]
人工智能模型可以由多个神经网络层组成。多个神经网络层中的每一个可以具有多个权重值,且可以通过使用先前层的计算结果和通过使用多个权重值的计算来执行神经网络计算。多个神经网络层的多个权重值可以通过人工智能模型的学习结果优化。例如,可以更新多个权重值以减小或者最小化由人工智能模型在学习过程期间获取的损失值或者成本值。
[0139]
人工神经网络可以包括深度神经网络(dnn)。例如,人工神经网络可以是卷积神经网络(cnn)、深度神经网络(dnn)、递归神经网络(rnn)、受限波耳兹曼机(rbm)、深度置信网络(dbn)、双向递归深度神经网络(brdnn)或者深度q
‑
网络,但是不限于此。
[0140]
图2b是图示根据本公开的实施例的电子设备的特定配置的示例的框图。
[0141]
参考图2b,电子设备100可以包括通信接口110、处理器120、存储器130、显示器140、用户界面150、相机160、扬声器170和麦克风180。将省略如图2b所示的组件当中与如图2a所示的重叠的组件的详细说明。
[0142]
通信接口110是用于以各种类型的通信方式执行与各种类型的外部设备的通信的组件。通信接口110包括wi
‑
fi模块111、蓝牙模块112、红外通信模块113、无线通信模块114等。这里,每个通信模块可以以至少一个硬件芯片的形式实现。
[0143]
处理器120可以使用通信接口110执行与各种外部设备的通信。这里,外部设备可以包括多个传感器装置200
‑
1到200
‑
2,比如tv的显示装置,比如机顶盒的图像处理装置,外部服务器,比如遥控器的控制装置,比如蓝牙扬声器的声音输出装置,照明装置,比如智能清洁器或者智能冰箱的家用电器,比如iot家庭管理器的服务器,等等。
[0144]
wi
‑
fi模块111和蓝牙模块112分别以wi
‑
fi方式和蓝牙方式执行通信。在使用wi
‑
fi模块111或者蓝牙模块112的情况下,首先发送和接收比如服务设置标识符(ssid)和会话密钥的各种连接信息,使用连接信息执行通信连接,且可以发送和接收各种信息。
[0145]
红外通信模块113使用用于短距离无线数据传输的位于可见光和毫米波之间的红外光根据红外数据关联(irda)技术执行通信。
[0146]
无线通信模块114可以包括用于取决于各种无线通信协议执行通信的至少一个通信芯片,该各种无线通信协议除如上所述的通信方式之外,比如zigbee、第三代(3g)、第三代伙伴项目(3gpp)、长期演进(lte)、先进lte(lte
‑
a)、第四代(4g)和第五代(5g)。
[0147]
另外,通信接口110可以包括用于通过使用局域网(lan)模块、以太网模块、双绞电缆、同轴电缆、光纤电缆等执行通信的至少一个有线通信模块。
[0148]
通信接口110可以进一步包括输入和输出接口。输入和输出接口可以是hdmi、mhl、usb、显示端口(dp)、雷电、视频图形阵列(vga)端口、rgb端口、d
‑
sub或者dvi之一。
[0149]
输入和输出接口可以输入和输出音频信号或者视频信号中的至少一个。
[0150]
在实现示例中,输入和输出接口可以包括用于仅输入和输出音频信号的端口和用于仅输入和输出视频信号的端口,或者可以实现为用于输入和输出音频信号和视频信号两者的一个端口。
[0151]
存储器130可以由比如只读存储器(rom)(例如,电可擦可编程只读存储器(eeprom))的内部存储器或者处理器120中包括的随机存取存储器(ram)实现,或者由与处理器120分开的存储器实现。在该情况下,取决于数据存储目的,存储器130可以以嵌入在电子设备100中的存储器的形式或者可附加到和可从电子设备100拆卸的存储器的形式实现。例如,用于驱动电子设备100的数据可以存储在嵌入在电子设备100中的存储器中,且用于电子设备100的扩展功能的数据可以存储在可附加到和可从电子设备100拆卸的存储器中。嵌入在电子设备100中的存储器可以由至少一个易失性存储器(例如,动态ram(dram)、静态ram(sram)或者同步动态ram(sdram))、非易失性存储器(例如,一次性可编程rom(otprom)、可编程rom(prom)、可擦可编程rom(eprom)、eeprom、掩模rom、闪存rom、闪存存储器(例如,nand闪存或者nor闪存)、硬盘驱动器或者固态驱动器(ssd))实现,且可附加到和可从电子设备100拆卸的存储器可以由存储卡(例如,紧凑闪存(cf)、安全数字(sd)、微安全数字(微sd)、迷你安全数字(迷你sd)、极端数字(xd)或者多媒体卡(mmc)),可连接到usb端口的外部存储器(例如,usb存储器)等实现。
[0152]
存储器130存储比如用于驱动电子设备100的操作系统(o/s)软件模块、音频处理模块和语音识别模块的各种数据。
[0153]
处理器120通常使用存储器130中存储的各种程序控制电子设备100的操作。
[0154]
作为示例,处理器120包括ram 121、rom 122、主cpu 123、第一接口124
‑
1到第n接口124
‑
n和总线125。
[0155]
ram 121、rom 122、主cpu 123、第一接口124
‑
1到第n接口124
‑
n等可以通过总线125彼此连接。
[0156]
用于启动系统的指令集等存储在rom 122中。一旦输入开启指令以供应功率到主cpu 123,则主cpu 123根据rom 122中存储的指令将存储器130中存储的o/s复制到ram 121,并执行o/s以启动系统。一旦完成启动,则主cpu 123将存储器130中存储的各种应用程序复制到ram 121,并执行复制到ram 121的应用程序以执行各种操作。
[0157]
主cpu 123访问存储器130以使用存储器130中存储的o/s执行启动。另外,主cpu 123使用存储器130中存储的各种程序、内容数据等执行各种操作。
[0158]
第一接口124
‑
1到第n接口124
‑
n连接到如上所述的各种组件。接口之一可以是通过网络连接到外部设备的网络接口。
[0159]
处理器120可执行图形处理功能(视频处理功能)。例如,处理器120可以通过使用计算器(未示出)和呈现器(未示出)呈现包括各种对象,比如图标、图像和文本的屏幕。这里,计算器(未示出)可以基于接收到的控制指令计算比如将显示各个对象的坐标值、取决
于屏幕布局的各个对象的形式、大小和颜色的属性值。另外,呈现器(未示出)可以基于计算器(未示出)中计算的属性值呈现包括对象的各种布局的屏幕。另外,处理器120可对于视频数据执行各种图像处理,比如解码、缩放、噪声过滤、帧速率转换和分辨率转换。
[0160]
处理器120可以对于音频数据执行处理。作为示例,处理器120可以对于音频数据执行各种处理,比如解码、放大和噪声过滤。
[0161]
显示器140可以由各种类型的显示器,比如液晶显示器(lcd)、有机发光二极管(oled)显示器和等离子显示面板(pdp)实现。可以以比如a
‑
si薄膜晶体管(tft)、低温聚硅(ltps)tft和有机的tft(otft)、背光单元等的形式实现的驱动电路可以包括在显示器140中。显示器140可以由与触摸传感器结合的触摸屏、柔性显示器、三维(3d)显示器等实现。
[0162]
用户接口150可以由比如按钮、触摸垫、鼠标或者键盘的装置实现,或者可以由可以执行上述显示功能和操作输入功能的触摸屏实现。这里,按钮可以是在比如电子设备100的主体外观的前表面部分、侧表面部分或者后表面部分的任何区域中形成的各种类型的按钮,比如机械按钮、触摸垫和滚轮。
[0163]
相机160是用于根据用户的控制捕获图像或者视频的组件。相机160可以在特定时间点捕获图像,或者可以捕获连续图像。
[0164]
扬声器170可以是用于输出各种通知声音、音频消息等,以及由输入和输出接口处理的各种音频数据的组件。
[0165]
麦克风180是用于接收用户的语音或者其他声音并将用户的语音或者其他声音转换为音频数据的组件。
[0166]
麦克风180可以以激活模式接收用户的语音。例如,麦克风180可以在电子设备100的上侧、前表面、侧表面等与电子设备100集成地形成。麦克风180可以包括各种组件,比如用于以模拟形式收集用户语音的麦克风,用于放大收集的用户语音的放大器电路,用于采样放大的用户语音和用于将用户语音转换为数字信号的a/d转换电路,和用于从通过转换获得的数字信号去除噪声分量的滤波器电路。
[0167]
电子设备100可以从包括麦克风的传感器装置接收包括用户语音的音频信号。在该情况下,接收到的音频信号可以是数字语音信号,但是在实现示例中也可以是模拟语音信号。在示例中,电子设备100可以通过比如蓝牙或者wi
‑
fi的无线通信方法接收音频信号。
[0168]
电子设备100可以通过将语言自动识别(asr)技术直接应用于从传感器装置接收到的数字语音信号而执行语音识别。
[0169]
替代地,电子设备100可以将从传感器装置接收到的语言信号发送到用于语音识别的外部服务。
[0170]
在该情况下,用于与传感器装置和外部服务器的通信的通信模块可以实现为一个模块或者单独的模块。例如,可以通过使用蓝牙模块执行与传感器装置的通信,且可以通过使用以太网调制解调器或者wi
‑
fi模块执行与外部服务器的通信。
[0171]
外部服务器可以通过将asr技术应用于数字语音信号执行语音识别,并将语音识别结果发送到电子设备100。
[0172]
图2c是图示根据本公开的实施例的存储器中存储的模块的示例的框图。
[0173]
参考图2c,存储器130可以包括配置为一个或多个模块的软件和/或固件。模块可以对应于计算机
‑
可执行指令的集合。
[0174]
存储器130可包括o/s软件模块131、音频处理模块132、语音识别模块133和任务模块134。模块131到134可由处理器120执行以执行各种功能。
[0175]
o/s软件模块131可以是用于驱动电子设备100的模块。例如,处理器120可以通过使用o/s软件模块131执行比如开启和关闭电子设备100的操作,电子设备100的功率管理,应用的驱动和另一电子设备的控制的功能。
[0176]
音频处理模块132可以是用于执行音频信号的分析,相似性的确定等的模块。例如,处理器120可以通过使用音频处理模块132获取第一音频信号和第二音频信号之间的相似性。
[0177]
语音识别模块133可执行语音识别。语音识别模块133可使用asr技术。
[0178]
语音识别模块133可以将与用户的讲话对应的音频信号转换为文本数据。将参考图2d描述语音识别模块133的示例功能。
[0179]
图2d是图示根据本公开的实施例的语音识别模块的示例的框图。
[0180]
参考图2d,语音识别模块133可以包括特征提取器和解码器。特征提取器可以从音频信号提取特征信息(特征向量)。解码器可以基于声学模型和语言模型获取与特征信息对应的语音识别信息。语音识别信息可以包括对应于基于声学模型获取的特征信息的发音信息、音素信息、字符串信息,和与基于语言模型获取的发音信息对应的文本数据。
[0181]
根据另一实施例,语音识别模块133可以包括声学模型或者语言模块中的任何一个,或者可以包括声学模型和语言模块两者并仅使用它们之一。在该情况下,语音识别模块133可以仅应用声学模型或者语言模块之一以获取语音识别信息。例如,语音识别信息可以包括基于声学模型获取的发音信息、音素信息、字符串信息,或者基于语言模型获取的文本信息。作为示例,语音识别信息可以包括发音信息、音素信息或者字符串信息而不是文本数据,发音信息、音素信息或者字符串信息是中间输出且文本数据是最终输出。在该情况下,语音识别信息被发送到另一装置,且该另一装置可以应用未应用的声学模型或者语言模型以最终获取文本数据。
[0182]
根据另一实施例,语音识别模块133可以不包括声学模型和语言模块两者,或者即使在包括声学模型或者语言模块的至少一个的情况下也可以不使用声学模型或者语言模块。在该情况下,语音识别模块133可以仅执行特征信息抽取操作以输出包括特征信息的语音识别信息。语音识别信息可以发送到另一装置,且该另一装置可应用声学模型和语言模型以最终获取文本数据。
[0183]
根据另一实施例,电子设备100可以不包括语音识别模块本身,或者即使在包括语音识别模块的情况下也可以不使用语音识别模块。在该情况下,电子设备100可以将通过麦克风180获取的音频信号发送到另一装置,且该另一装置可以执行语音识别。
[0184]
因而,语音识别模块133的功能的选择性使用可以减小电子设备100中的计算负荷。
[0185]
另外,在从外部设备接收到作为中间输出的语音识别信息的情况下,语音识别模块133可以对于语音识别信息执行其余语音识别处理。例如,在从外部设备接收到的语音识别信息是被应用声学模型且未被应用语言模型的信息的情况下,语音识别模块133可以将语言模型应用于接收到的语音识别信息以获取最终识别结果。作为另一示例,在从外部设备接收到的语音识别信息仅包括特征信息的情况下,语音识别模块133可以将语言模型和
声学模型应用于接收到的语音识别信息以获取最终识别结果。
[0186]
一旦通过语音识别模块133从音频信号获取文本数据,则文本数据可以传送到任务模块134。
[0187]
任务模块134可分析从语音识别模块133传送的文本数据以分析其含义,并执行与含义对应的任务。任务模块134可以使用自然语言处理(nlp)技术。
[0188]
任务模块134可以基于分析的含义识别要执行的任务。可以执行各种类型的任务,比如播放音乐、设置日程、呼叫和响应于询问。另外,任务可以包括用于控制另一电子设备的任务。
[0189]
根据本公开的实施例,用于执行任务的人工智能代理程序可以存储在电子设备100中。
[0190]
人工智能代理程序是用于提供基于人工智能(ai)的服务(例如,语音识别服务、个人秘书程序、翻译服务或者搜索服务)的专用程序,且可以由现有的通用处理器(例如,cpu)或者单独的ai专用处理器(例如,gpu)执行。处理器120可以包括通用处理器或者ai专用处理器中的至少一个。
[0191]
具体地,人工智能代理程序可以包括能够处理用户指令和与用户指令对应的操作,和能够以自然语言处理用于其的通知消息的对话系统。对话系统可以包括语音识别模块133和任务模块134。将在以下提供其说明。
[0192]
图2e是图示根据本公开的实施例的传感器装置的配置的示例的框图。
[0193]
参考图2e,传感器装置200包括处理器210、存储器220、通信接口230和麦克风240。
[0194]
处理器210是用于控制传感器装置200的一般操作的组件。例如,处理器210可以驱动操作系统或者应用以控制连接到处理器210的多个硬件或者软件组件,并执行各种数据处理和计算。处理器210可以是cpu、gpu或者这两者。处理器210可以由通用处理器、数字信号处理器、专用集成电路(asic)、片上系统(soc)、微计算机(micom)等中的至少一个实现。
[0195]
存储器220可以包括内部存储器或者外部存储器。存储器220由处理器210访问,且存储器220中的数据的读出、记录、校正、删除、更新等可以由处理器210执行。
[0196]
存储器220可以包括配置为一个或多个模块的软件和/或固件。模块可以对应于计算机
‑
可执行指令的集合。
[0197]
存储器220可以包括唤醒模块221和任务模块222。模块221和222可以由处理器210执行以执行各种功能。
[0198]
唤醒模块221可以识别音频信号中的预定触发词或者短语。例如,唤醒模块221可以识别通过麦克风240获取的用户语音中包括的触发词。一旦识别到触发词,则可以解除传感器装置200的待机模式。例如,唤醒模块221可以激活麦克风240和通信接口230的记录功能。
[0199]
传感器装置200可不包括唤醒模块221,且在该情况下,可以通过用户手动操作解除传感器装置200的待机模式。例如,可以当选择传感器装置200中提供的特定按钮时解除待机模式。作为另一示例,传感器装置200可仅执行音频信号的记录和音频信号到外部设备,例如,电子设备100或者服务器300的发送,且外部设备可以识别触发词以解除传感器装置200的待机模式。
[0200]
不必须提供唤醒模块221。例如,传感器装置200可以不包括唤醒模块221,且在该
情况下,传感器装置200可以不进入待机模式。
[0201]
一旦接收到用户语音,则任务模块222可以通过vad或者epd中的至少一个检测用户语音。
[0202]
另外,除与用户语音对应的音频信号之外,任务模块222可以确定是否发送指示用户语音的语音动作的时间信息,或者指示用户语音的结束点的时间信息中的至少一个。例如,在确定通过麦克风240接收到的音频不包括用户语音的情况下,任务模块222可以不发送音频信号到电子设备100。
[0203]
通信接口230可以例如通过无线通信或者有线通信连接到网络以执行与外部设备的通信。例如是蜂窝通信协议的无线通信可以使用lte、lte
‑
a、码分多址(cdma)、宽带cdma(wcdma)、通用移动电信系统(umts)、无线宽带(wibro)和全球移动通信系统(gsm)中的至少一个。另外,无线通信例如可以包括短距离通信。短距离通信例如可以包括wi
‑
fi直连、蓝牙、近场通信(nfc)和zigbee中的至少一个。有线通信例如可以包括usb、hdmi、推荐标准232(rs
‑
232)或者普通老式电话业务(pots)中的至少一个。网络可以包括比如计算机网络(例如,局域网(lan)或者广域网(wan))、因特网和电话网络的通信网络中的至少一个。
[0204]
麦克风240是用于接收声音的组件。麦克风240可以将接收到的声音转换为电信号。麦克风240可以与传感器装置200集成地或者与传感器装置200分开地实现。单独的麦克风240也可以电连接到传感器装置200。麦克风240的数目可以是多个。可以通过使用多个麦克风检测用户的移动方向。
[0205]
处理器210可以通过执行存储器220中存储的计算机可执行指令(模块)来执行各种功能。
[0206]
根据实施例,处理器210可以执行存储器220中存储的计算机可读指令,以通过麦克风240获取包括预定触发词的用户语音并控制通信接口230将与用户语音对应的音频信号发送到电子设备100。
[0207]
虽然未示出,传感器装置200可以包括用户输入接收器。用户输入接收器可以接收各种用户输入,比如触摸输入、运动输入和按钮的操作。例如,用户输入接收器可以包括按钮、触摸板等。另外,传感器装置200可以进一步包括用于显示各种信息的显示器。显示器例如可以包括发光二极管(led)、液晶显示器(lcd)等。另外,传感器装置200可以进一步包括相机。通过使用相机捕获的图像可以用于确定用户的移动方向或者通过麦克风240发送的衰减噪声。另外,传感器装置200可以进一步包括扬声器。可以通过扬声器输出通知控制结果的通知消息。
[0208]
图2f是图示根据本公开的实施例的服务器的配置的示例的框图。
[0209]
参考图2f,服务器300包括处理器310、存储器320和通信接口330。
[0210]
处理器310是用于控制服务器300的一般操作的组件。例如,处理器310可以驱动操作系统或者应用以控制连接到处理器310的多个硬件或者软件组件,并执行各种数据处理和计算。处理器310可以是cpu、gpu或者这两者。处理器310可以由通用处理器、数字信号处理器、asic、soc、micom等中的至少一个实现。
[0211]
存储器320可以包括内部存储器或者外部存储器。存储器320由处理器310访问,且存储器320中的数据的读出、记录、校正、删除、更新等可以由处理器310执行。
[0212]
存储器320可以包括配置为一个或多个模块的软件和/或固件。模块可以对应于计
算机
‑
可执行指令的集合。
[0213]
存储器320可以包括语音识别模块321和任务模块322。模块321和322可以由处理器310执行以执行各种功能。
[0214]
语音识别模块321可以执行与如上所述的语音识别模块133的功能相同的功能。
[0215]
任务模块322可执行基于语音识别结果将特定控制信号发送到电子设备100或者另一电子设备中的至少一个的任务。例如,在最终识别结果是“开启tv”的情况下,任务模块322可执行将开启tv的控制信号发送到tv的任务。
[0216]
通信接口330可以例如通过无线通信或者有线通信连接到网络以执行与外部设备的通信。例如是蜂窝通信协议的无线通信可以使用lte、lte
‑
a、cdma、wcdma、umts、wibro和gsm中的至少一个。另外,无线通信例如可以包括短距离通信。短距离通信例如可以包括wi
‑
fi直连、蓝牙、近场通信(nfc)和zigbee中的至少一个。有线通信例如可以包括usb、hdmi、推荐标准232(rs
‑
232)或者普通老式电话业务(pots)中的至少一个。网络可以包括比如计算机网络(例如,局域网(lan)或者广域网(wan))、因特网和电话网络的通信网络的至少一个。
[0217]
处理器310可以通过执行存储器320中存储的计算机可执行指令(模块)来执行各种功能。
[0218]
根据实施例,处理器310可以执行存储器320中存储的计算机可执行指令,以对于从电子设备100或者传感器装置200接收到的音频信号执行语音识别。另外,处理器310可以控制通信接口330以将与语音识别结果对应的控制指令发送到与语音识别结果对应的设备。
[0219]
另外,处理器310也可以执行识别有效传感器装置的操作,而不是语音识别。例如,处理器310可以分别从电子设备100或者多个传感器装置200
‑
1到200
‑
5中的两个接收第一音频信号和第二音频信号。另外,处理器310可以与电子设备100的处理器120类似地执行比如有效传感器装置的确定的操作,且因此将省略重叠描述。
[0220]
在服务器300识别有效传感器装置的情况下,将音频信号发送到服务器300的设备可以另外提供标识信息给服务器300。例如,服务器300可以执行与第一家庭中的电子设备和多个传感器装置,第二家庭中的电子设备和多个传感器装置,...,和第n家庭中的电子设备和多个传感器装置的通信,且在仅接收音频信号的情况下,服务器可以不识别哪个家庭的传感器装置是有效传感器装置。因此,在服务器300识别有效传感器装置的情况下,除音频信号之外,设备或者传感器装置可以发送标识信息到服务器300。这里,标识信息可以包括账户信息、用户信息或者位置信息中的至少一个。
[0221]
每个家庭中的传感器装置可将音频信号和标识信息直接发送到服务器300。替代地,每个家庭中的传感器装置可将音频信号和标识信息发送到同一家庭中的电子设备,且该电子设备可将音频信号和标识信息发送到服务器300。
[0222]
如上所述,电子设备100可以优先化多个传感器装置200
‑
1到200
‑
5之一以防止比如处理的重复和资源的浪费的问题。
[0223]
在下文中,将参考附图更详细地描述电子设备100和多个传感器装置200
‑
1到200
‑
5的操作。
[0224]
图3、图4、图5和图6是用于描述根据本公开的实施例的语音识别方法的图。
[0225]
参考图3、图4、图5和图6,假定电子系统1000包括比如tv的一个电子设备100,第一
到第四传感器装置200
‑
1到200
‑
4,及其他电子设备,比如空调和冰箱。另外,假定接近于电子设备100设置第一传感器装置200
‑
1,接近于冰箱设置第二传感器装置200
‑
2,且接近于空调设置第三传感器装置200
‑
3。另外,假定其中用户在第一传感器装置200
‑
1的附近说出语音的情况。在该情况下,有效传感器装置需要是位置最接近用户的第一传感器装置200
‑
1。
[0226]
第一传感器装置200
‑
1到第四传感器装置200
‑
4每个可以包括或者可以不包括唤醒模块221。在下文中,将首先描述第一传感器装置200
‑
1到第四传感器装置200
‑
4不包括唤醒模块221的情况。如图3所示,用户的讲话“hi bixby,降低冰箱的温度”可输入到位于用户的附近的第一传感器装置200
‑
1到第三传感器装置200
‑
3。但是,第四传感器装置200
‑
4由于到用户的长距离或者第四传感器装置200
‑
4和用户之间的墙壁或者其他阻碍而可能没有接收到用户的讲话。替代地,在第四传感器装置200
‑
4接收到用户的讲话,但是讲话的音量低于阈值的情况下,第四传感器装置200
‑
4可不发送音频信号到电子设备100。替代地,即使在第四传感器装置200
‑
4接收到用户的讲话但是讲话的音量低于阈值的情况下,第四传感器装置200
‑
4也可发送音频信号到电子设备100。另外,电子设备100也可忽略其音量低于阈值的音频信号。
[0227]
用户的讲话“hi bixby,降低冰箱的温度”输入到的第一传感器装置200
‑
1到第三传感器装置200
‑
3可以分别将与讲话"hi bixby,降低冰箱的温度"对应的第一音频信号到第三音频信号发送到电子设备100。这里,第一音频信号到第三音频信号可以是具有取决于输入时间、用户和传感器装置之间的距离等具有时间差的信号。
[0228]
处理器120可以基于第一音频信号到第三音频信号将第一传感器装置200
‑
1到第三传感器装置200
‑
3之一识别为有效传感器装置。作为示例,处理器120可以比较第一音频信号到第三音频信号当中的讲话时间点最早的信号和讲话时间点最晚的信号,以识别讲话时间点之间的差是否等于或者短于阈值时间。在讲话时间点之间的差超过阈值时间的情况下,处理器120可以识别出第一音频信号到第三音频信号彼此不同。这里,除音频信号之外,第一传感器装置200
‑
1到第三传感器装置200
‑
3每个可以将指示用户语音的语音动作的时间信息或者指示用户语音的结束点的时间信息中的至少一个发送到电子设备100。另外,处理器120可以基于接收到的信息识别音频信号的讲话时间点。
[0229]
但是,本公开不限于此,处理器120也可以使用音频信号的接收时间点。例如,处理器120可以比较第一音频信号到第三音频信号当中首先输入的信号的接收时间点和每一个其余信号的接收时间点,以识别接收时间点之间的差是否等于或者短于阈值时间。在接收时间点之间的差超过阈值时间的情况下,处理器120可以识别出第一音频信号到第三音频信号彼此不同。
[0230]
在讲话时间点或者接收时间点之间的差等于或者短于阈值时间的情况下,处理器120可以识别音频信号之间的相似性。在相似性低于阈值的情况下,处理器120可以识别出第一音频信号到第三音频信号彼此不同。
[0231]
这里,处理器120可以通过执行对于整个输入音频信号的比较来识别音频信号之间的相似性。例如,在分别从第一传感器装置200
‑
1和第二传感器装置200
‑
3接收到与用户的讲话“hi bixby,开启空调”对应的第一音频信号和第二音频信号的情况下,处理器120可以通过执行相对于整个第一音频信号和整个第二音频信号的比较来识别相似性。
[0232]
这里,本公开不限于此,且处理器120也可以通过执行仅对于输入音频信号的一部
分的比较来识别音频信号之间的相似性。例如,在分别从第一传感器装置200
‑
1和第二传感器装置200
‑
2接收到与用户的讲话“hi bixby,开启空调”对应的第一音频信号和第二音频信号的情况下,处理器120可以通过执行仅对于与第一音频信号中的讲话“hi bixby”对应的信号和与第二音频信号中的讲话“hi bixby”对应的信号的比较来识别相似性。也就是,处理器120可以通过仅对于接收到的第一音频信号的一部分和第二音频信号的一部分的比较来识别有效传感器装置。这里,第一音频信号的一部分和第二音频信号的一部分可以通过预定时间来确定。
[0233]
在音频信号之间的相似性等于或者高于阈值的情况下,处理器120可通过转换第一音频信号到第三音频信号的音频分量而将第一传感器装置200
‑
1到第三传感器装置200
‑
3之一识别为有效传感器装置。这里,处理器120可通过使用如根据本公开的实施例的图4中的音频模型转换第一音频信号到第三音频信号包括的音频分量。
[0234]
参考图4,提供音频模型的示例。在图示的音频模型中,模式1可以指示其中开启冰箱且空调以turbo模式操作的状态。这里,输入到分别设置在tv、冰箱和空调附近的第一传感器装置200
‑
1到第三传感器装置200
‑
3的音频音量可以分别是60、20和30。模式2可以指示其中降低tv的音量,开启冰箱且空调以标准模式操作的状态。这里,输入到第一传感器装置200
‑
1到第三传感器装置200
‑
3的音频音量可以分别是30、20和20。模式3可以指示其中开启冰箱并关闭空调的状态。这里,输入到第一传感器装置200
‑
1到第三传感器装置100
‑
3的音频音量可以分别是60、20和10。
[0235]
如上所述,音频模型可以包括基于该电子设备和至少一个其他电子设备的操作状态的多个模式,和多个模式的每一个中输入到传感器装置的音频音量。这里,音频音量可以仅包括噪声分量而不包括用户语音。在图4中,为了说明的方便未图示输入到不设置在该电子设备100或者至少一个其他电子设备附近的第四传感器装置200
‑
4的音频音量,但是音频模型也可以包括输入到第四传感器装置200
‑
4的音频音量。
[0236]
处理器120可以识别第一音频信号到第三音频信号中的每一个中的语音分量和噪声分量。例如,根据本公开的实施例,如图5所示,处理器120可以识别第一音频信号中的为65的语音分量和为60的噪声分量,识别第二音频信号中的为30的语音分量和为20的噪声分量,并识别第三音频信号中的为40的语音分量和为30的噪声分量。
[0237]
处理器120可以基于图4中的音频模型识别音频信号中包括的语音分量和噪声分量。作为示例,处理器120可以学习和存储没有用户讲话的音频信号作为如图4所示的音频模型,并当存在用户语音时基于该音频模型识别音频信号中包括的语音分量和噪声分量。
[0238]
另外,处理器120可以根据位置与发送音频信号的每一个传感器装置相邻的电子设备的操作状态执行降噪以显著地减小有效传感器装置的识别误差。例如,处理器120可以根据位置与发送音频信号的每一个传感器装置相邻的电子设备的操作状态,分别从第一音频信号中包括的噪声分量、第二音频信号中包括的噪声分量和第三音频信号中包括的噪声分量获取第一预测的音频分量、第二预测的音频分量和第三预测的音频分量;分别基于第一预测的音频分量的幅值、第二预测的音频分量的幅值和第三预测的音频分量的幅值获取第一音频信号的第一质量特性、第二音频信号的第二质量特性和第三音频信号的第三质量特性;和基于第一质量特性、第二质量特性和第三质量特性将第一传感器装置200
‑
1、第二传感器装置200
‑
2或者第三传感器装置200
‑
3之一识别为有效传感器装置。
[0239]
更具体地,处理器120可以通过使用第一音频信号到第三音频信号中的每一个的质量特性的snr特性识别有效传感器装置。这里,在没有降噪的情况下获取snr特性的情况下,在如图5所示的示例中在降噪之前具有最优选的snr特性的第二传感器装置200
‑
2可被识别为有效传感器装置。作为示例,第一音频信号的snr特性由于比如tv的电子设备100的噪声而恶化,且在该情况下,处理器120将第二传感器装置200
‑
2识别为有效传感器装置,是错误的。
[0240]
处理器120可以通过使用音频模型执行降噪。在例如在其中开启tv的状态下降低tv的音量的情况下,处理器120可以识别出噪声从60减少到30,如图4所示。另外,处理器120可以维持第一音频信号中的为65的语音分量并将噪声分量从60降低到30,如图5所示。处理器120可以对于其余音频信号也执行这种操作,并通过使用减小的噪声获取snr特性。另外,处理器120可以将具有最优选的snr特性的第一传感器装置200
‑
1识别为有效传感器装置。如上所述,可以通过降噪防止识别误差。
[0241]
处理器120可以仅对于与从识别为有效传感器装置的第一传感器装置200
‑
1接收到的第一音频信号对应的“hi bixby,降低冰箱的温度”执行语音识别。另外,处理器120可以仅对于在从第一传感器装置200
‑
1被识别为有效传感器装置起的阈值时间内从第一传感器装置200
‑
1另外接收到的音频信号执行语音识别。
[0242]
处理器120可以基于语音识别结果控制冰箱以降低冰箱的温度。另外,处理器120可以将通知冰箱控制结果的通知消息发送到第一传感器装置200
‑
1,且第一传感器装置200
‑
1可以将控制结果提供给用户。
[0243]
第一传感器装置200
‑
1到第四传感器装置200
‑
4每个可包括唤醒模块221。参考图6,用户的讲话“hi bixby”可输入到位于用户附近的第一传感器装置200
‑
1到第三传感器装置200
‑
3。但是,第四传感器装置200
‑
4由于到用户的长距离或者第四传感器装置200
‑
4和用户之间的墙壁或者其他阻碍而可能接收不到用户的讲话。
[0244]
用户的讲话“hi bixby”输入到的第一传感器装置200
‑
1到第三传感器装置200
‑
3可以确定输入触发信号,且可以在阈值时间期间解除第一传感器装置200
‑
1到第三传感器装置200
‑
3中的每一个的待机模式。一旦在阈值时间内从用户输入附加讲话,则第一传感器装置200
‑
1到第三传感器装置200
‑
3可以分别将第一附加音频信号到第三附加音频信号发送到电子设备100。这里,作为与附加讲话对应的信号的第一附加音频信号到第三附加音频信号可以是具有取决于输入时间、用户和传感器装置之间的距离等的时间差的信号。
[0245]
参考图6,用户的附加讲话“将空调调到19℃”可以输入到位于用户附近的第一传感器装置200
‑
1到第三传感器装置200
‑
3。第一传感器装置200
‑
1到第三传感器装置200
‑
3可以分别将第一附加音频信号到第三附加音频信号发送到电子设备100。
[0246]
处理器120可以基于第一附加音频信号到第三附加音频信号识别有效传感器装置,且用于其的特定方法与如上所述的不包括唤醒模块221的情况下的相同。
[0247]
在第一传感器装置200
‑
1被识别为有效传感器装置的情况下,处理器120可以仅对于第一附加音频信号执行语音识别。处理器120可以在从识别出有效传感器装置起的阈值时间期间如上所述地操作。作为示例,处理器120可以忽略在第一传感器装置200
‑
1被识别为有效传感器装置之后从另一传感器装置接收到的音频信号。替代地,处理器120可以将在第一传感器装置200
‑
1被识别为有效传感器装置之后的阈值时间期间禁止音频信号的传输
的控制指令发送到另一传感器装置。
[0248]
处理器120可以基于语音识别结果将空调控制在19℃操作。另外,处理器120可以将通知空调控制结果的通知消息发送到第一传感器装置200
‑
1,且第一传感器装置200
‑
1可以将控制结果提供给用户。
[0249]
图7a是用于描述根据本公开的实施例的电子系统的操作的序列图。
[0250]
参考图7a,一旦输入用户语音,则第一传感器装置200
‑
1到第三传感器装置200
‑
3可以分别将第一音频信号到第三音频信号发送到电子设备100。此时,第一传感器装置200
‑
1到第三传感器装置200
‑
3可以进一步分别在操作s710、s710
‑
2和s710
‑
3中将epd时间信息发送到电子设备100。这里,第一传感器装置200
‑
1到第三传感器装置200
‑
3每个可以从输入用户语音获取epd时间信息。替代地,电子设备100可以接收第一音频信号到第三音频信号并获取首先接收到音频信号的时间,和基于接收到的音频信号的epd时间信息。epd时间信息可以包括指示用户语音的结束点的时间信息。这里,指示用户语音的结束点的时间信息可以包括用户语音开始点。
[0251]
但是,本公开不限于此,且第一传感器装置200
‑
1到第三传感器装置200
‑
3可以进一步将vad时间信息发送到电子设备100。vad时间信息可以包括指示用户语音的语音动作的时间信息。替代地,电子设备100可以记录epd时间信息或者vad时间信息中的至少一个。
[0252]
电子设备100可以基于epd时间信息或者vad时间信息中的至少一个识别在阈值时间内是否输入了多个音频信号。作为示例,电子设备100可以基于epd时间信息或者vad时间信息中的至少一个识别用户语音的讲话时间点之间的差,并基于讲话时间点之间的差确定是否识别音频信号之间的相似性。例如,电子设备100可以识别第一音频信号和第二音频信号之间的相似性,但是可以不识别第一音频信号和第三音频信号之间的相似性。
[0253]
电子设备100可以在操作s720中获取相似性并在操作s730中识别有效传感器装置。作为示例,电子设备100可以在操作s720获取相似性并在操作s730基于预测的音频分量的质量选择有效传感器装置。这里,预测的音频分量可以包括具有减小的噪声分量的音频分量。在下文中,将描述第一传感器装置200
‑
1是有效传感器装置的情况。
[0254]
电子设备100可以在操作s740识别接收到的音频信号是否是触发信号。在识别出接收到的音频信号是触发信号的情况下,电子设备100可以对于从有效传感器装置接收到的附加音频信号执行语音识别。替代地,在识别出接收到的音频信号不是触发信号的情况下,即使在从有效传感器装置接收到附加音频信号的情况下,电子设备100也可以不执行语音识别。
[0255]
但是,本公开不限于此,且第一传感器装置200
‑
1、第二传感器装置200
‑
2和第三传感器装置200
‑
3可以直接识别触发词。在该情况下,电子设备100可以不执行识别触发词的操作。
[0256]
一旦识别出触发信号,则电子设备100可以控制电子设备100和至少一个其他电子设备的操作状态。例如,电子设备100可以通过降低tv的音量或者对tv静音,和将空调的turbo模式(功率模式)改变为标准模式而显著地减小附加音频信号的噪声分量。
[0257]
替代地,电子设备100可以控制电子设备100或者至少一个其他电子设备中的至少一个的操作状态。例如,电子设备100可以仅降低tv的音量而同时不控制空调或者真空吸尘器。
[0258]
这里,电子设备100还可以仅控制电子设备100或者至少一个其他电子设备之一的操作状态,其位置与有效传感器装置相邻。替代地,电子设备100可以仅控制电子设备100或者至少一个其他电子设备之一的操作状态,其产生响的噪声。
[0259]
电子设备100可以将电子设备的改变的操作状态恢复为初始操作状态。例如,电子设备100可以停止真空吸尘器的操作并控制真空吸尘器再次操作。
[0260]
电子设备100可以在从电子设备100和至少一个其他电子设备的操作状态改变起经过预定时间之后恢复电子设备100和至少一个其他电子设备的操作状态。例如,电子设备100可以在从停止真空吸尘器的操作起经过两秒之后控制真空吸尘器再次操作。
[0261]
替代地,电子设备100可以在s750
‑
1、s750
‑
2和s750
‑
3的操作中在识别有效传感器装置和接收到附加音频信号之后,恢复电子设备100和至少一个其他电子设备的操作状态,如之后所述的。替代地,电子设备100可以在s760中在操作中激活第一传感器装置200
‑
1的语音识别功能之后,恢复电子设备100和至少一个其他电子设备的操作状态,如之后所述的。替代地,电子设备100可以在s770中在操作中执行对于附加音频信号的语音识别之后,恢复电子设备100和至少一个其他电子设备的操作状态,如之后所述的。替代地,电子设备100可以在s780中在操作中基于语音识别结果生成控制指令之后,恢复电子设备100和至少一个其他电子设备的操作状态,如之后所述的。替代地,电子设备100可以在s790中在操作中将通知控制结果的通知消息发送到有效传感器装置之后,恢复电子设备100和至少一个其他电子设备的操作状态,如之后所述的。
[0262]
第一传感器装置200
‑
1到第三传感器装置200
‑
3可以分别根据用户的附加讲话将第一附加音频信号到第三附加音频信号发送到电子设备100。一旦在接收到触发信号的状态下接收到第一附加音频信号到第三附加音频信号,则电子设备100可以在操作s760中激活第一传感器装置200
‑
1的语音识别功能,并在操作s770中对于第一附加音频信号执行语音识别。同时,处理器120可以不对于第二附加音频信号和第三附加音频信号执行语音识别。
[0263]
电子设备100可以在操作s780中基于语音识别结果生成控制指令,并在操作s790中将通知控制结果的通知消息发送到有效传感器装置。
[0264]
但是,本公开不限于此,且电子设备100还可以将通知控制结果的消息发送到位置与用户相邻的传感器装置或者另一电子设备。例如,在用户在用户说出用户语音的时间点位于有效传感器装置的附近,且用户移动到位于另一传感器装置附近的情况下,电子设备100可以将通知控制结果的通知消息发送到另一传感器装置。
[0265]
这里,电子设备100可以通过使用传感器装置、另一电子设备等获取用户位置信息。例如,传感器装置、另一电子设备等可以通过使用红外传感器、温度传感器等检测在其周围是否存在用户,并将检测信息发送到电子设备100。替代地,传感器装置或者另一电子设备可以包括相机,并将由相机捕获的图像发送到电子设备100,且电子设备100可以通过使用接收到的图像执行用户识别以获取用户位置信息。
[0266]
图7b是用于描述根据本公开的另一实施例的电子系统的操作的序列图。在图7b中的总体操作与在图7a中的相同,且因此将仅描述差异。
[0267]
参考图7b,一旦识别出有效传感器装置,则电子设备100可以在操作s751和s752中将第一控制信号发送到有效传感器装置以外的其余传感器装置。这里,第一控制信号可以
是用于禁止阈值时间期间音频信号的传输的信号。作为示例,一旦从电子设备100接收到第一控制信号,则即使在阈值时间期间输入用户语音,第二传感器装置200
‑
2和第三传感器装置200
‑
3也不将与用户语音对应的音频信号发送到电子设备100。作为示例,电子设备100可以仅从第一传感器装置200
‑
1接收音频信号并执行语音识别和控制操作。
[0268]
替代地,一旦从电子设备100接收到第一控制信号,则第二传感器装置200
‑
2和第三传感器装置200可以再次以待机模式操作。在该情况下,第二传感器装置200
‑
2和第三传感器装置200
‑
3不将音频信号发送到电子设备100,直到接收到触发信号为止。
[0269]
电子设备100可以基于从第一传感器装置200
‑
1接收到的音频信号执行语音识别和控制操作,在操作s790将通知消息发送到第一传感器装置200
‑
1,和分别在操作s791和s792将第二控制信号发送到第二传感器装置200
‑
2和第三传感器装置200
‑
3。第二控制信号可以是用于解除音频信号传输的禁止的信号。作为示例,一旦从电子设备100接收到第二控制信号,则第二传感器装置200
‑
2和第三传感器装置200
‑
3可以解除音频信号传输的禁止,且一旦输入用户语音,则第二传感器装置200
‑
2和第三传感器装置200
‑
3可以发送与用户语音对应的音频信号。
[0270]
图8是用于描述根据本公开的实施例的对话系统的框图。
[0271]
参考图8,对话系统800是用于通过使用自然语言与虚拟人工智能代理执行对话的组件。根据本公开的实施例,对话系统800可以存储在电子设备100的存储器130中。但是,这仅是实例,对话系统800中包括的至少一个也可以包括在至少一个外部服务器中。
[0272]
如图8所示,对话系统800可以包括asr模块810、自然语言理解(nlu)模块820、对话管理器(dm)模块830、自然语言生成器(nlg)模块840和文本到语音(tts)模块850。另外,对话系统80可以进一步包括路径计划者模块或者动作计划者模块。
[0273]
asr模块810可以将从传感器装置接收到的音频信号(例如,用户询问)转换为文本数据。例如,asr模块810可以包括讲话识别模块。讲话识别模块可以包括声学模型和语言模型。声学模型可以包括关于发声的信息且语言模型可以包括关于单元音素信息和单元音素信息的组合的信息。讲话识别模块可以通过使用关于发声的信息和关于单元音素信息的信息将用户讲话转换为文本数据。关于声学模型和语言模型的信息可以存储在自动语言识别数据库(asr db)815中。
[0274]
nlu模块820可以执行语法分析或者语义分析以理解用户的意图。可以以用户语音被划分为语法单元(例如,词、短语或者词素),和已经被识别的语法单元的语法元素的方式执行语法分析。可以通过使用语义匹配、规则匹配、公式匹配等执行语义分析。因此,nlu模块820可以获取表示意图需要的域、意图或者参数(或者时隙)。
[0275]
nlu模块820可以通过使用理解意图需要的划分为领域、意图和参数(或者时隙)的匹配规则来确定用户的意图和参数。例如,一个领域(例如,频道)可以包括多个意图(例如,频道向上、频道向下或者频道改变),且一个意图可以包括多个参数(例如,频道改变间隔)。多个规则例如可以包括一个或多个基本参数。匹配规则可以存储在自然语言理解数据库(nlu db)823中。
[0276]
在nlu模块820中分析讲话“开启空调”的情况下,处理器120可能需要位置信息,因为可能有多个可控制的空调。在该情况下,处理器120可以将请求空调的规格的消息发送到有效传感器装置。替代地,处理器120可以基于有效传感器装置的位置控制多个空调之一。
替代地,处理器120可以基于用户的位置控制多个空调之一。此时,在用户的位置连续地改变的情况下,处理器120可以控制另一空调而不是位置与有效传感器装置相邻的空调。
[0277]
nlu模块820可以通过使用比如词素或者短语的语言特征(例如,语法元素)理解从用户语音提取的词的含义,并通过匹配理解的词的含义与领域和意图来确定用户的意图。例如,nlu模块820可以计算每个领域和意图中包括的词的数目以确定用户的意图,词从用户语音提取。根据实施例,nlu模块820可以通过使用用于理解意图的词确定用户语音的参数。根据实施例,nlu模块820可以通过使用其中存储用于理解用户语音的意图的语言特征的nlu db 823来确定用户的意图。
[0278]
nlu模块820可以通过使用私有知识db 825理解用户语音。私有知识db 825可以基于到电子设备100的用户交互输入、用户的搜寻历史、由电子设备100感应的传感信息或者从传感器装置接收到的用户语音中的至少一个,学习知识信息之间的关系。此时,私有知识db 825可以以实体论(ontology)的形式存储知识信息之间的关系。
[0279]
在添加新知识信息的情况下,私有知识db 825可以从外部服务器接收新知识信息的附加信息,并以实体论的形式存储知识信息和附加信息。在私有知识db 825中以实体论的形式存储知识信息仅是示例。该信息也可以以数据集的形式存储。
[0280]
nlu模块820可以通过使用私有知识db 825确定用户的意图。例如,nlu模块820可以通过使用用户信息(例如,控制装置分布和控制功能分布)确定用户的意图。根据实施例,除nlu模块820之外,asr模块810也可以通过参考私有知识db 825识别用户语音。
[0281]
nlu模块820可基于用户语音的意图和参数生成路径规则。例如,nlu模块820可基于用户语音的意图选择电子设备,并确定所选的电子设备中要执行的操作。nlu模块820可以通过确定与所确定的操作对应的参数生成路径规则。根据实施例,由nlu模块820生成的路径规则可以包括关于电子设备的信息,在该电子设备中要执行的操作,和执行操作需要的参数。
[0282]
nlu模块820可以基于用户语音的意图和参数生成单个路径规则或者多个路径规则。例如,nlu模块820可以从路径计划者模块接收与电子设备100对应的路径规则集合,且通过将用户语音的意图和参数映射到接收到的路径规则集合来确定路径规则。这里,路径规则可以包括关于用于执行功能的操作的信息,或者关于执行操作需要的参数的信息。另外,路径规则可以包括功能操作序列。电子设备可以接收路径规则,根据路径规则选择电子设备,和允许在所选的电子设备中执行路径规则中包括的操作。
[0283]
nlu模块820可以基于用户语音的意图和参数,通过确定电子设备,该电子设备中要执行的操作和执行操作需要的参数,来生成一个路径规则或者多个路径规则。例如,nlu模块820可以通过使用电子设备100的信息,根据用户语音的意图,通过以实体论或者图模型的形式布置电子设备和该电子设备中要执行的操作来生成路径规则。例如,生成的路径规则可以通过路径计划者模块存储在路径规则数据库中。生成的路径规则可以添加到nlu db 823的路径规则集合。
[0284]
nlu模块820可以选择多个生成的路径规则当中的至少一个路径规则。例如,nlu模块820可以选择多个路径规则当中的最优路径规则。作为另一示例,nlu模块820可以在仅基于用户语音指定某些操作的情况下选择多个路径规则。nlu模块820可以根据来自用户的附加输入确定多个路径规则当中的一个路径规则。
[0285]
dm模块830可以确定由nlu模块820理解的用户的意图是否清楚。例如,dm模块830可以基于关于参数的信息是否足够来确定用户的意图是否清楚。dm模块830可以确定由nlu模块820获取的参数是否足以执行任务。根据实施例,在用户的意图不清楚的情况下,dm模块830可以执行反馈以向用户请求需要的信息。例如,dm模块830可以执行反馈以请求关于用于理解用户的意图的参数的信息。
[0286]
根据实施例,dm模块830可以包括内容提供者模块。在可以基于由nlu模块820获取的意图和参数执行操作的情况下,内容提供者模块可以生成执行与用户语音对应的任务的结果。
[0287]
根据另一实施例,dm模块830可以通过使用知识db 835提供关于用户语音的响应。这里,知识db 835可以包括在电子设备100中。但是,这仅是示例,且知识db 835可以包括在外部服务器中。
[0288]
nlg模块840可以改变指定信息以具有文本形式。改变为具有文本形式的信息可以具有自然语言讲话的形式。指定信息例如可以是关于附加输入的信息,通知与用户语音对应的操作的完成的信息,或者通知来自用户的附加输入的信息(例如,对于用户语音的反馈信息)。改变为具有文字形式的信息可以在电子设备100的显示器上显示,或者可以由tts模块850改变为具有语音形式。
[0289]
tts模块850可以将文本形式的信息改变为语音形式的信息。tts模块850可以从nlg模块840接收文本形式的信息,将文本形式的信息改变为语音形式的信息,并输出语音形式的信息。
[0290]
asr模块810可以由在图2d中的语音识别模块133实现,且nlu模块820、dm模块830、nlg模块840和tts模块850可以由在图2d中的任务模块134实现。
[0291]
图9a、图9b和图9c是用于描述根据本公开的实施例的扩展示例的图。
[0292]
参考图9a,电子系统1000可以包括多个电子设备(主边缘、从边缘a和从边缘b),而不是一个电子设备(主边缘)100。这里,多个电子设备全部(主边缘、从边缘a和从边缘b)可以是管理多个传感器装置(点1、点2和点3)的设备。例如,主边缘可以从多个传感器装置(点1、点2和点3)接收音频信号,控制从边缘a以执行有效传感器装置的识别,和控制从边缘b以执行语音识别。作为示例,主边缘可以控制从边缘a和从边缘b执行参考图1、2、3、4、5、6、7和8描述的电子设备100的操作的分布式处理。
[0293]
替代地,参考图9b,电子系统1000可以包括多个电子设备(主边缘和从边缘)。主边缘管理房屋a中的两个传感器装置(点1和点2),从边缘管理房屋b中的一个(点3),且这里,由主边缘管理的传感器装置和由从边缘管理的传感器装置可以彼此不同。进一步,主边缘和从边缘分开地操作,且可以仅管理分配给其的传感器装置。但是,在其中主边缘和从边缘需要彼此合作地操作的情况下,例如,在预定周期期间分析用户的使用模式的情况下,主边缘可以优先级高于从边缘。
[0294]
替代地,在主边缘从多个传感器装置(点1和点2)接收音频信号的情况下,主边缘向从边缘请求由从边缘接收的音频信号,且在存在由从边缘接收的音频信号的情况下,音频信号被发送到主边缘,且主边缘可以执行对于该音频信号的比较。
[0295]
替代地,参考图9c,电子系统1000可以包括彼此对应的多个电子设备(边缘a和边缘b),而不是一个电子设备(主边缘)100。边缘a管理两个传感器装置(点1和点2),边缘b管
理一个传感器装置(点3),且这里,由边缘a和边缘b管理的传感器装置可以彼此不同。进一步,边缘a和边缘b可以彼此执行通信并共享数据。例如,即使在当用户说出用户语音时全部三个传感器装置接收到用户语音的情况下,边缘a和边缘b可以仅将三个传感器装置之一识别为有效传感器装置。进一步,边缘a和边缘b每个可以通过设置优先级被操作为主边缘或者从边缘。作为示例,一旦接收到音频信号,则边缘a和边缘b需要执行广播音频信号和检查音频信号是否由另一边缘接收到的操作,直到设置优先级为止。
[0296]
虽然图9a、图9b和图9c图示以三个类型实现多个边缘和多个点且点与相应的边缘协同操作的情况,本公开不限于此。例如,不建立边缘和点之间的对应,且一旦输入用户语音,则点可以通过广播识别与其相邻的边缘并发送音频信号到相邻边缘。替代地,一旦输入用户语音,则点可以通过广播发送信号到多个边缘,多个边缘可以再一次执行比较,且多个边缘之一可以执行语音识别。
[0297]
图10a和图10b是用于描述根据本公开的各种实施例的装置的优先级设置的图。
[0298]
参考图10a,多个传感器装置(点)可以预测要输入的用户语音的质量,且仅一个传感器装置可以发送音频信号到电子设备(边缘)。这里,多个传感器装置(点)每个可以考虑环境传感器装置的状态变化。
[0299]
例如,在接收到用户语音“开启空调”的情况下,位置与空调相邻的传感器装置可以发送音频信号到电子设备。
[0300]
参考图10b,传感器装置(点)可将与输入用户语音对应的音频信号发送到多个电子设备(边缘)当中的具有最高优先级的主边缘。在对于多个电子设备中的每一个未设置优先级的情况下,电子设备需要共享接收到的音频信号或者指示接收到音频信号的信号。但是,在对于多个电子设备中的每一个设置优先级的情况下,不执行以上描述的非必要操作,这可以导致效率的改进。
[0301]
图11是用于描述根据本公开的实施例的使用服务器的方法的图。
[0302]
参考图11,一旦用户语音输入到传感器装置(点),可以获取epd时间信息或者vad时间信息中的至少一个。传感器装置可将与用户语音对应的音频信号和获取的时间信息发送到电子设备(边缘)。例如,在输入用户语音“开启真空吸尘器”的情况下,在操作s1110中,传感器装置可以将与用户语音"开启真空吸尘器"对应的音频信号和获取的时间信息发送到电子设备(边缘)。
[0303]
替代地,传感器装置可以仅将与输入用户语音对应的音频信号发送到电子设备100。在该情况下,电子设备100可以通过vad获取指示用户语音的语音动作的时间信息,且通过epd获取指示用户语音的结束点的时间信息。例如,在输入用户语音“开启真空吸尘器”的情况下,传感器装置可以将与用户语音"开启真空吸尘器"对应的音频信号发送到电子设备(边缘),且电子设备可以从音频信号获取指示用户语音的语音动作的时间信息或者指示用户语音的结束点的时间信息中的至少一个。
[0304]
一旦输入音频信号,则电子设备可以唤醒和执行语音识别。这里,语音识别可以由单独的语音识别服务器执行。作为示例,电子设备可以在操作s1120
‑
1将音频信号发送到语音识别服务器,和在操作s1120
‑
2从语音识别服务器接收语音识别结果。
[0305]
根据另一实施例,在由电子设备接收的音频信号的质量低的情况下,或者在基于语音模型或者语言模型对于音频信号执行的语音识别的精度低的情况下,可以确定语音识
别处理结果不精确。在该情况下,电子设备可以将音频信号发送到具有更大计算性能的语音识别服务器,且语音识别服务器可以再一次处理该音频信号。在该情况下,传感器装置还可以将音频信号发送到语音识别服务器而不经过电子设备。
[0306]
虽然图11图示其中语音识别服务器和控制服务器分开地实现的情况,这仅是示例,且可以实现各种配置。例如,语音识别服务器和控制服务器可以实现为一个服务器。另外,语音识别服务器和控制服务器两者还可以实现为云服务器。
[0307]
电子设备可以在操作s1130
‑
1在语音识别之后将控制指令发送到由用户请求的另一电子设备(边缘)。例如,在tv是边缘并接收用于控制真空吸尘器的用户语音的情况下,tv可以识别出可以不执行tv和真空吸尘器之间的通信,识别能够执行与真空吸尘器的通信的另一电子设备(空调),并在操作s1130
‑
1中将用于控制真空吸尘器的控制指令发送到其他电子设备。其他电子设备在操作s1140
‑
1可以基于接收到的控制指令控制真空吸尘器。
[0308]
这里,tv可以询问至少一个其他电子设备关于至少一个其他电子设备是否可以控制真空吸尘器,并将用于控制真空吸尘器的控制指令发送到响应于此的另一电子设备。但是,这种信息可以预先存储在tv中。
[0309]
替代地,在tv可以执行与真空吸尘器的通信的情况下,一旦接收到用于控制真空吸尘器的用户语音,则tv可以在操作s1130
‑
2中将用于控制真空吸尘器的控制命令直接发送到真空吸尘器。
[0310]
但是,本公开不限于此。电子设备可以在操作s1130
‑
3中发送控制指令到控制服务器,且控制服务器可以在操作s1140
‑
2中发送控制指令到控制目标设备。替代地,语音识别服务器可以在操作s1150中发送语音识别结果到控制服务器,且控制服务器可以在操作s1160生成与语音识别结果对应的控制指令并将该控制指令发送到另一电子设备。
[0311]
图12是用于描述根据本公开的实施例的电子设备的控制方法的流程图。
[0312]
参考图12,在操作s1210中,分别从第一传感器装置和位置远离第一传感器装置的第二传感器装置接收到第一音频信号和第二音频信号。另外,在操作s1220中获取第一音频信号和第二音频信号之间的相似性。另外,在操作s1230中,在相似性等于或者高于阈值的情况下,基于位置与第一传感器装置相邻的电子设备和位置与第二传感器装置相邻的电子设备中的每一个的操作状态,分别从第一音频信号和第二音频信号获取第一预测的音频分量和第二预测的音频分量。在操作s1240中,基于第一预测的音频分量和第二预测的音频分量将第一传感器装置或者第二传感器装置之一识别为有效传感器装置。在操作s1250中,对于从有效传感器装置接收到的附加音频信号执行语音识别。
[0313]
这里,在操作s1230中的第一预测的音频分量和第二预测的音频分量的获取包括:基于该电子设备和至少一个电子设备中的每一个的操作状态,基于模式特定音频模型,识别与位置与第一传感器装置相邻的电子设备的操作状态和位置与第二传感器装置相邻的电子设备的操作状态对应的模式;和基于识别的模式分别从第一音频信号和第二音频信号获取第一预测的音频分量和第二预测的音频分量,其中当多个传感器装置中的每一个通过人工智能算法学习基于相邻电子设备的操作状态获取的音频时可以获取音频模型。
[0314]
另外,第一预测的音频分量和第二预测的音频分量的获取包括:基于识别的模式分别从第一音频信号中包括的噪声分量和第二音频信号中包括的噪声分量获取第一预测的音频分量和第二预测的音频分量;和分别基于第一预测的音频分量的幅值和第二预测的
音频分量的幅值获取第一音频信号的第一质量特性和第二音频信号的第二质量特性,其中在操作s1240中识别为有效传感器装置时,第一传感器装置或者第二传感器装置之一可以基于第一质量特性和第二质量特性被识别为有效传感器装置。
[0315]
该控制方法可以进一步包括改变位置与第一传感器装置相邻的电子设备的操作状态和位置与第二传感器装置相邻的电子设备的操作状态,以允许位置与第一传感器装置相邻的电子设备和位置与第二传感器装置相邻的电子设备根据预定事件以预定模式操作。
[0316]
例如,电子设备可以通过降低tv的音量或者对tv静音,和将空调的turbo模式改变为标准模式而显著地减小附加音频信号的噪声分量。
[0317]
替代地,电子设备可以控制该电子设备或者至少一个其他电子设备中的至少一个的操作状态。例如,电子设备可以仅降低tv的音量而同时不控制空调或者真空吸尘器。
[0318]
这里,电子设备还可以仅仅控制该电子设备或者至少一个其他电子设备中的位置与有效传感器装置相邻的一个的操作状态。替代地,电子设备可以仅控制该电子设备或者至少一个其他电子设备中的产生响的噪声的一个的操作状态。
[0319]
控制方法还可包括基于语音识别结果控制电子设备或者至少一个其他电子设备中的至少一个,和控制有效传感器装置以提供通知控制结果的通知消息。
[0320]
在操作s1220中相似性的获取中,可以在从接收到第一音频信号起的阈值时间内接收到第二音频信号的情况下获取相似性。
[0321]
相反地,该控制方法可以进一步包括:在从接收到第一音频信号起的阈值时间之后接收到第二音频信号的情况下,或者在相似性低于阈值的情况下,分别将第一传感器装置和第二传感器装置识别为第一有效传感器装置和第二有效传感器装置,并对于从第一有效传感器装置和第二有效传感器装置中的每一个接收到的附加音频信号执行语音识别。
[0322]
另外,在操作s1220中的相似性的获取可以包括获取第一音频信号和第二音频信号之间的时域相似性,获取第一音频信号和第二音频信号之间的频域相似性,和基于时域相似性或者频域相似性中的至少一个获取相似性。
[0323]
该控制方法还可包括一旦第一传感器装置或者第二传感器装置之一被识别为有效传感器装置,则在从识别有效传感器装置起的阈值时间内忽略从第一传感器装置或者第二传感器装置中的另一个接收到的附加音频信号。
[0324]
根据如上所述的本公开的各种实施例,电子设备可以优先多个传感器装置之一以防止比如处理的重复和资源的浪费的问题。
[0325]
虽然上面已经描述了电子设备使用音频信号来识别有效传感器装置的情况,但是本公开不限于此。例如,多个传感器装置中的每一个可包括多个麦克风,且在该情况下,多个传感器装置中的每一个可以识别朝向说出用户语音的用户的位置的方向。多个传感器装置可以将朝向用户位置的方向发送到电子设备,且电子设备可以基于朝向用户位置的方向识别有效传感器装置。
[0326]
在使用至少两个麦克风的情况下,向着用户位置的方向可以基于用户语音来识别,且可以通过两个麦克风获取用户语音的相位差和波长,因为用户语音物理地是声波。另外,在使用用户语音的相位差和波长以及两个麦克风之间的距离的情况下,可以通过使用三角函数公式推导出由两个麦克风形成的线和从两个麦克风朝向用户的线之间的角度。通过这种方法,可以识别向着用户位置的方向。
[0327]
还可以执行多个传感器装置之间的通信。在该情况下,分别由多个传感器装置接收的音频信号可以被比较以确定有效传感器装置,且仅有效传感器装置可以发送音频信号到电子设备。特别地,多个传感器装置中的每一个可以被分类为主点或从点之一。
[0328]
在降噪之前的snr特性和降噪之后的snr特性彼此相同的情况下,处理器可基于每个音频信号的强度等识别有效传感器装置。例如,在用户在客厅说出用户语音的情况下,位于客厅中的第一传感器装置和位于厨房中的第二传感器装置可接收用户语音。这里,在位于客厅和厨房中的家用电器关闭且不生成单独的噪声的情况下,在降噪之后从第一传感器装置和第二传感器装置中的每一个发送的音频信号的snr特性可以实质上与降噪之前的相同。在该情况下,处理器120可基于每个音频信号的强度识别有效传感器装置。
[0329]
处理器还可将除通知控制结果的通知消息之外的另一消息发送到有效传感器装置。例如,在用户说出“开启空调”且存在可由处理器控制的多个空调的情况下,处理器可以将请求空调的规格的消息发送到有效传感器装置。替代地,处理器可以基于有效传感器装置的位置控制多个空调之一。替代地,处理器可以基于用户的位置控制多个空调之一。此时,在用户的位置连续地改变的情况下,可以操作另一空调而不是位置与有效传感器装置相邻的空调。
[0330]
根据如上所述的本公开的各种实施例的方法可以以可以在现有电子设备中安装的应用的形式实现。
[0331]
另外,根据如上所述的本公开的各种实施例的方法可以仅通过相对于现有电子设备执行软件升级或者硬件升级实现。
[0332]
另外,可以通过电子设备中提供的嵌入式服务器,或者电子设备或者显示装置的至少一个的外部服务器执行如上所述的本公开的各种实施例。
[0333]
根据本公开的实施例,如上所述的各种实施例可以由包括机器可读的存储介质(例如,计算机可读存储介质)中存储的指令的软件实现。机器可以是从存储介质调用存储的指令并可以取决于调用的指令操作的设备,且可以包括根据公开的实施例的电子设备(例如,电子设备100)。在指令由处理器执行的情况下,处理器可以直接执行与指令对应的功能,或者其他组件可以在处理器的控制下执行与指令对应的功能。指令可以包括由编译器或者解释器创建或者执行的代码。机器可读的存储介质可以以非瞬时存储介质的形式提供。这里,术语“非瞬时”指的是存储介质是有形的而不包括信号,且不区分数据是半永久地或者临时存储在存储介质上。
[0334]
另外,根据本公开的实施例,根据如上所述的各种实施例的方法可以在计算机程序产品中包括和提供。计算机程序产品可以作为产品在销售者和购买者之间交易。计算机程序产品可以以可以由机器读取的存储介质(例如,光盘只读存储器(cd
‑
rom))的形式分发,或者通过应用商店(例如,playstore
tm
)在线分发。在在线分发的情况下,计算机程序产品的至少部分可以至少临时地存储在存储介质中,比如制造商的服务器的存储器,应用商店的服务器或者中继服务器或者临时创建。
[0335]
另外,根据如上所述的各种实施例的每一个组件(例如,模块或者程序)可以包括单个实体或者多个实体,且可以省略如上所述的某些相应的子组件或者可以在各种实施例中另外包括其他子组件。替代地或者另外地,某些组件(例如,模块或者程序)可以集成到一个实体中,且可以以相同或者类似的方式执行在集成之前由各个相应的组件执行的功能。
由根据各种实施例的模块、程序或者其他组件执行的操作可以以顺序方式、并行方式、迭代方式或者渐进方式执行,至少一些操作可以以不同次序执行或者省略,或者可以添加其他操作。
[0336]
虽然在上文中已经图示和描述了本公开的实施例,但是本公开不限于上述特定实施例,而是可以由本公开所属的本领域技术人员多样地修改而不会脱离如所附权利要求中公开的本公开的主旨。这些修改也应该理解为在本公开的范围和精神之内。
[0337]
虽然已经参考其各种实施例示出和描述了本公开,本领域技术人员将理解在其中可以做出形式和细节上的各种改变而不会脱离本公开如所附权利要求及其等效物所定义的精神和保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。