1.本发明涉及语种识别技术领域,特别涉及一种基于空洞卷积神经网络的端到端语种识别分类方法。
背景技术:
2.语种识别(language identification,lid)是指自动判定给定的语音片段,从该语音片段的语音信号中提取各语种的差异信息,判断语言种类的过程。语种识别技术在多语种语音处理方面有重要的应用,例如,口语语言翻译系统、多语种语音识别系统、语音文本处理等。
3.目前,传统的语种识别技术包括两种方法:第一种方法,基于音素层特征的语种识别技术;其中,基于音素层特征的语种识别技术是将音素层特征作为识别依据。常用的方法有音素识别后接n元文法模型(phoneme recognizer followed by language model,prlm)和并行音素识别器后接语言模型(parallel phone recognition followed by language modeling,pprlm)等。第二种方法,基于声学层特征的语种识别技术依赖于声学层特征,主流的语种识别系统有混合高斯模型-全局背景模型(gaussian mixture model-universal back-ground model,gmm-ubm)、高斯超向量-支持向量机(gmm super vector-support vector machines,gsv-svm)和基于全差异空间的(total variability,tv)i-vector系统等。本发明采用传统的tv ivector系统提取原始i-vector。
4.近几年,深度神经网络(deep neural networks,dnn)模型在语种识别技术上得到快速发展,具体从以下两个方面体现:一方面从前端语种特征提取层面,利用dnn模型强大的语种特征的抽取能力,提取了深度瓶颈特征(deep bottleneck feature,dbf)。另一方面从模型域出发,提出基于dnn的tv建模策略。
5.近几年,也有学者提出了基于深度学习的端对端语种识别系统,摒弃了传统的语种识别系统框架。2014年google的研究人员将特征提取、特征变换和分类器融于一个神经网络模型中,搭建了一个帧级别的语种识别端到端系统。随后有研究人员在此基础上发掘了不同神经网络的优势,包括延时神经网络(time-delay neural network,tdnn),长短时记忆递归神经网络(long short term memory-recurrent neural network,lstm-rnn),但这些端到端语种识别系统的输入为帧级声学特征,输出为帧级判决,需要后处理将帧级特征转成句级特征进行语种判决。2016年geng等人利用注意力机制模型(attention-based model),结合lstm-rnn搭建了端到端语种识别系统,输入帧级声学特征,利用lstm提取语音的段级表达,在短时语音上取得了不错的语种识别性能。2018年,david等人提出基于深度神经网络的x-vector系统,验证了借助统计池化层得到的输入语音段级表达在各个语音时长测试条件下都优于传统i-vector系统。同年cai等人采用深度卷积神经网络提取更加具有语种鉴别性的帧级特征并提出基于可学习的字典编码层,也得到了很好的段级表达。从这些研究工作中可以发现,相比较传统的基于i-vector方法的语种识别技术,基于深度学习的端到端方法更具性能优势,已经成为语种识别任务中的主流方法。普通的卷积神经网
络及其下采样在局部上下文建模和语种相关性方面具有很强的能力,但在这一过程中压缩了特征,丧失了语音的时间结构。然而时间信息与语种识别高度相关。
技术实现要素:
6.本发明的目的在于,为解决现有的基于卷积神经网络的语种识别方法存在上述缺陷,提出了一种基于空洞卷积神经网络的端到端语种识别网络,经过多层空洞卷积,保证网络计算量不变的情况下,增加语音信号的感受野,充分挖掘上下文信息,提取具有更具有鉴别性的语种特征,进一步提升语种识别系统的性能。
7.为了达到上述目的,本发明实施例记载了一种基于空洞卷积神经网络的端到端语种识别分类方法,通过下列步骤实现对目标语音的识别:
8.提取训练语音的帧级别声学底层特征;待训练语种识别网络接收,并对训练语音的帧级别声学底层特征进行至少一层空洞卷积后,输出训练语音后验概率;将训练语音后验概率与真实类别标签的最小均方误差作为待训练语种识别网络的损失函数,通过减小优化函数的值进行梯度回传并更新待训练语种识别网络的参数,得到训练后语种识别网络;提取测试语音的帧级别声学底层特征;训练后语种识别网络接收测试语音的帧级别声学底层特征,输出测试语音后验概率;根据测试语音后验概率判定测试语音中的至少一个语种类别。
9.一个实例中,训练语音的帧级别声学底层特征,和测试语音的帧级别声学底层特征,为23维梅尔倒谱系数。
10.一个实例中,语种识别网络为残差网络,残差网络中包括至少一空洞卷积层。
11.其中,残差网络第l组中第i层空洞卷积层的输出为:
[0012][0013]
为与相关联的滤波器,p为中的特征映射域,a为网络层的输入,b为滤波器域,k为空洞率。
[0014]
本发明实施例的优点在于:使用空洞卷积神经网络,在输出特征图的分辨率不变的情况下,不降低单个神经元的感受野,弱化语音中的时间信息丢失问题。空洞卷积继承了残差网络的特性,保持了输入信号的时间结构,并且随着网络的扩展,网络可以保证大的视野,提供了很强的局部上下文建模能力。
附图说明
[0015]
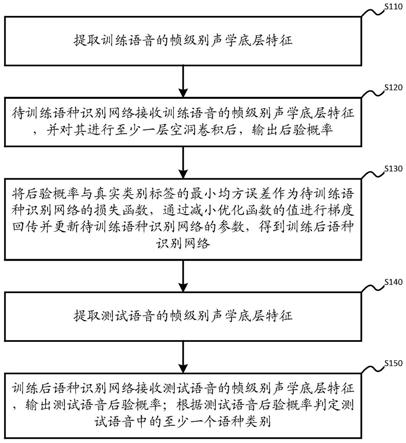
图1为本发明实施例的一种基于空洞卷积神经网络的端到端语种识别分类方法流程图框图;
[0016]
图2(a)为标准卷积的示意图;
[0017]
图2(b)为空洞卷积的示意图。
具体实施方式
[0018]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例
中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0019]
图1为本发明实施例的一种基于空洞卷积神经网络的端到端语种识别分类方法流程图框图,如图1所示,包括下列步骤:
[0020]
步骤s101:提取训练语音的帧级别声学底层特征。
[0021]
一个实施例中,帧级别声学底层特征为23维梅尔倒谱系数。
[0022]
步骤s102:待训练语种识别网络接收训练语音的帧级别声学底层特征,并对其进行至少一层空洞卷积后,输出后验概率。
[0023]
采用基于空洞卷积的语种识别网络作为样本的训练对象,可以通过空洞卷积,增加语音信号的感受野。以此充分挖掘上下文信息,提取具有鉴别性的帧级别语种特征。随后,网络中的平均池化层将帧级别语种特征的集合进行统计,并计算集合的均值,得到段级特征传递给后续的全连接层,最终由输出层输出后验概率。
[0024]
一个实施例中,采用经典的34层残差网络(residual network)resnet34作为基线构建语种识别网络,其中,resnet34中的卷积层均为标准卷积。我们将resnet34中的部分或全部标准卷积替换为空洞卷积。基于空洞卷积不需要引入新的参数即可进行卷积的特点,如图2所示,图2(a)为标准卷积的示意图,图2(b)为空洞卷积的示意图,使构建的语种识别网络,可以从更广泛的语境中整合不同的语言信息,从而增加语音信号的感受野。
[0025]
具体地,resnet34中的每个残差结构包含5组卷积层,使用表示l组中的第i层,l=1,
…
,5。在不降低感知场的情况下提高深层网络的时间分辨率,以此保持语音中的时间结构,使用空洞卷积取代标准卷积。
[0026]
在标准卷积中,的输出是:
[0027][0028]
其中,为与相关联的滤波器,p为中的特征映射域,a为网络层的输入,b为滤波器域。
[0029]
在空洞卷积中,的输出是:
[0030][0031]
其中,k为空洞率。
[0032]
步骤s103:将后验概率与真实类别标签的最小均方误差作为待训练语种识别网络的损失函数,通过减小优化函数的值进行梯度回传并更新待训练语种识别网络的参数,得到训练后语种识别网络。
[0033]
步骤s104:提取测试语音的帧级别声学底层特征。其中,帧级别声学底层特征为23维梅尔倒谱系数。
[0034]
步骤s105:训练后语种识别网络接收测试语音的帧级别声学底层特征,输出后验概率,即分数向量;根据后验概率得到至少一个语种类别的概率,根据这一概率判定其所对
应语种的语种类别。
[0035]
一个实施例中,采用平均检测代价c
avg
(average cost)对测试语音的识别结果进行评价,得到语种类别的概率。
[0036]
c
avg
的定义为:
[0037][0038]
其中,n
l
为目标语种数目,l
t
为目标语种,l
n
为非目标语种,l
o
为集外语种,p
miss
(l
t
)表示目标语种为l
t
时的漏检率,p
fa
(l
t
,l
n
)是目标语种为l
t
时的虚警率,c
miss
和c
fa
分别是漏检和虚警的惩罚因子,p
target
为目标语种的先验概率,p
non-target
=(1-p
target-p
out-of-set
)/(n
l-1)为非目标语种的先验概率,p
out-of-set
为集外语种的先验概率。
[0039]
如考虑闭集测试计算c
avg
,则p
out-of-set
=0,此时定义c
miss
=c
fa
=1,p
target
=0.5。
[0040]
实施例一
[0041]
采用resnet34卷积神经网络作为基线,其中,resnet34中的每个残差结构包含5组卷积层,且均为标准卷积。将其中每个残差结构的第4和第5组标准卷积(和)替换为空洞卷积,构建基于空洞卷积神经网络的语种识别网络。使用训练语音的帧级别声学底层特征对该语种识别网络进行训练,得到训练完成的基于空洞卷积的resnet34。
[0042]
为便于比较,设置对比例一。
[0043]
对比例一
[0044]
采用resnet34卷积神经网络作为语种识别网络,其中,resnet34中的每个残差结构包含5组卷积层,且均为标准卷积。使用与实施例一中相同的训练语音的帧级别声学底层特征对该语种识别网络进行训练,得到训练完成的基于标准卷积的resnet34。
[0045]
将3段时长不等的测试语音,分别作为实施例一和对比例一中的输入,进行语音识别。其中,第一测试语音时长为3秒,第二测试语音时长为10秒,第三测试语音时长为30秒。采用平均检测代价c
avg
分别对实施例一和对比例一中的3段测试语音的识别结果进行评价,如表1所示:
[0046] 第一测试语音(3s)第二测试语音(10s)第三测试语音(30s)实施例一18.26%5.98%2.04%对比例一20.44%6.35%2.22%
[0047]
表1不同测试语音的平均检测代价
[0048]
通过表1可知,本技术实施例一中采用基于空洞卷积的resnet34对不同时长的测试语音进行识别的结果,采用平均检测代价c
avg
进行评价的结果均小于对比例一中传统的采用基于标准卷积的resnet34的识别结果。对于平均检测代价c
avg
的评价,两者的数值越小,表示识别结果的准确率越高。由此可知,实施例一相比于对比例一在多种不同时长的测试语音的识别方面,均体现出更好的识别性能。
[0049]
本发明实施例使用空洞卷积神经网络,在输出特征图的分辨率不变的情况下,不降低单个神经元的感受野,弱化语音中的时间信息丢失问题。空洞卷积继承了残差网络的
特性,保持了输入信号的时间结构,并且随着网络的扩展,网络可以保证大的视野,提供了很强的局部上下文建模能力。
[0050]
以上的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。