一种基于ddpg算法获得最优资源分配以提升定位精度的方法
技术领域
1.本发明涉及无线定位技术领域,尤其是涉及一种基于ddpg算法获得最优资源分配以提升定位精度的方法。
背景技术:
2.随着无线通信技术的快速发展,基于位置信息的服务和应用被广泛研究。通过使用gnss,人们在户外可以达到米级的精度。但是由于卫星信号很有可能受到障碍物阻挡,这就使得gnss可能在室内、城市街道或茂密的森林环境中失效。而在这样的对gnss有挑战的环境中,无线网络定位是一个很有前途的替代方案。
3.常见的无线定位网络使用的定位方法主要可以分为基于测距和不基于测距的定位方法,其中不基于测距的定位方法主要是指纹定位法,该方法需要先建立一个指纹数据库,而基于测距的定位方法主要包括到达时间(toa),到达时间差(tdoa)等方法,基于测距的方法无需建立指纹库且定位精度较高。
4.传统的无线定位网络主要采用的是非协同定位,它只允许位置已知的锚节点和位置未知的代理节点之间进行通信,而使用toa进行定位时一般需要代理节点至少和三种不同的锚节点进行测距来获得自身位置,要想获得较高的定位精度就要求锚节点部署的密度能足够大,这就不可避免的提高了成本。此外,当锚节点和代理节点之间的通信距离较大时,容易出现中断通信的问题,不能保证通信的连续性,从而降低定位精度。
技术实现要素:
5.有鉴于此,本发明的目的在于提供一种基于ddpg算法获得最优资源分配以提升定位精度的方法,主要采用的是基于测距的定位方法中的toa定位,同时加入协同定位,以获得更高的定位精度。
6.为实现上述目的,本发明采用以下内容:
7.一种基于ddpg算法获得最优资源分配以提升定位精度的方法,主要利用ddpg算法来分配带宽和功率,所述方法包括以下步骤:
8.步骤一、获取测距信息,估计代理节点位置:
9.假设无线定位网络中具有n
a
个代理节点和n
b
个锚节点,则整个网络可以使用的总带宽和总功率分别为b
total
,p
total
,无线定位网络中的各个节点根据带宽和功率的分配方案测量自身和其他节点之间的距离,利用toa定位方法来确定代理节点的具体位置;
10.步骤二、获取ddpg网络状态空间:
11.所述ddpg算法的状态空间是指各个节点之间的距离以及信道参数,通过步骤一中的测距操作获得各个节点之间的距离信息,通过信道估计获得信道参数;
12.步骤三、开始网络训练:
13.采用强化学习中的ddpg算法以获得最优的资源分配方案,采用均方误差下界speb
actor网络、critic网络、target critic网络,其中actor网络和target actor网络的结构相同,critic网络和target critic网络的结构相同。
24.在其中一个实施例中,所述actor网络和target actor网络均包含有五个隐藏层,每一隐藏层都使用线性整流函数relu作为激活函数;actor网络的输入为所述步骤2中的状态空间,大小为(n
a
n
b
)*2n
a
,从第二个隐藏层起,网络被分为结构相同的上下两半部分,上半部分被训练用于带宽的分配,下半部分被训练用于功率的分配,对它们的输出分别进行softmax操作,最终输出得到归一化的带宽分配和功率分配,大小为n
a
n
b
。
25.在其中一个实施例中,所述target actor网络用于隔一段时间将actor网络的网络参数按照一定百分比加权到target actor网络中,以实现target actor网络的更新。
26.在其中一个实施例中,所述critic网络和target critic网络均包含有三个隐藏层,每一隐藏层都使用线性整流函数relu作为激活函数;critic网络的输入为某一时刻的状态s
t
和动作a
t
,输出为对应的q值q(s
t
,a
t
)。
27.在其中一个实施例中,所述target critic网络用于隔一段时间将critic网络的网络参数按照一定百分比加权到target critic网络中,以实现target critic网络的更新。
附图说明
28.下面结合附图对本发明的具体实施方式作进一步详细的说明。
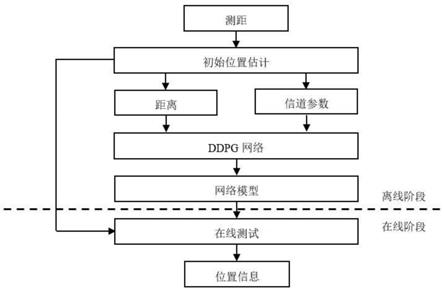
29.图1是本发明一种基于ddpg算法获得最优资源分配以提升定位精度的方法的系统流程图;
30.图2是本发明所用ddpg算法流程示意图;
31.图3是本发明ddpg算法中actor网络的网络结构示意图;
32.图4是本发明ddpg算法中critic网络的网络结构示意图;
33.图5是一个实施例中非协同定位的实验场景仿真图;
34.图6是另一个实施例中协同定位的实验场景仿真图;
35.图7是非协同定位的离线阶段进行网络训练的收益图;
36.图8是非协同定位场景下穷尽算法与ddpg算法的性能对比图;
37.图9是协同定位的离线阶段进行网络训练的收益图;
38.图10是协同定位场景下ddpg算法的性能图。
具体实施方式
39.为了更清楚地说明本发明,下面结合优选实施例对本发明做进一步的说明。本领域技术人员应当理解,下面所具体描述的内容是说明性的而非限制性的,不应以此限制本发明的保护范围。
40.现有技术一(cn108810840b)涉及到一种协作定位中基于efim和距离协作的节点选择方法,包括下列步骤:1)在场景中放置代理和锚节点,计算它们与待定位目标节点的距离;2)得到费希尔信息矩阵fim再对高维的fim进行分解和量化得到二维的等效费希尔信息矩阵efim;3)当目标节点和锚节点协作时,根据锚节点的efim计算节点的位置误差界限的平方speb;当目标节点和邻近代理节点协作时,根据代理节点的efim计算speb,根据新的节
点选择标准从邻近节点中选择节点,构建辅助节点的集合,对目标节点定位。
41.现有技术一存在的问题是其只考虑了应该选取哪些传感器进行定位的问题,可是忽略了各个选定的传感器对定位精度的贡献不一样,若对这些传感器进行合理资源分配可以更进一步的提升定位精度,但是其并没有考虑到传感器的带宽和功率等资源的分配。
42.现有技术二(cn106714301b)涉及到一种载波资源优化问题的混合整数线性规划求解方法(mixed integer linear programming,milp),在用yalmip工具求解混合整数规划mip模型时,先将混合整数规划问题转化为混合整数线性规划,因此需要将目标函数进行线性近似处理。用全局speb作为目标函数,在节点的发射功率、信号带宽、载波频率的下界和上界限制、整个系统中可用总功率限制、整个无线网络中总带宽限制以及节点间的信号载波频率与带宽不相互干扰条件下,优化得出的分配资源,包括发射功率、载波频率、信号带宽,然后目标节点通过与锚节点以及协作的目标节点进行单向toa测距来获取自己的位置信息。
43.现有技术二存在的问题是在线测试速度长,其每次进行资源分配时都需要使用现有的凸优化工具进行迭代搜索,直到带宽、载波频率和功率的变化小于特定阈值时才会停止搜索,需要花费的时间比较长,并且当代理节点增加后所要花费的搜索时间会更长。
44.现有技术三(t.zhang,a.f.molisch,y.shen,q.zhang and m.z.win,"joint power and bandwidth allocation in cooperative wireless localization networks,"2014ieee international conference on communications(icc),2014,pp.2611
‑
2616,doi:10.1109/icc.2014.6883717)涉及到一种对功率和带宽联合分配的方法来提高室内定位精度,其根据室内的所有节点之间的信道状况和距离角度关系来分配功率和带宽,但是该分配问题是非凸的,故提出了利用泰勒展开和迭代搜索来近似求解该资源分配问题,获得最优的资源分配方案来提高定位精度。
45.现有技术三存在的问题是:1、定位精度差:由于其是利用泰勒展开和迭代搜索的方式来近似求解非凸的功率和带宽分配问题,因此定位精度是无法达到最优的;2、在线分配速度长:与现有技术二同样的问题,其也是利用现有的凸优化工具对近似后的分配方案进行迭代搜索,直到带宽和功率的变化小于特定阈值时才会停止搜索,每次需要花费的时间比较长,在实时定位中效果不佳,同样当代理节点个数增加时所要花费的时间也会相应的增加。
46.根据对上述现有技术的分析,本发明主要解决的技术问题是如何在保证定位精度的同时减少在线定位阶段进行资源分配时所要消耗的时间。
47.针对上述技术问题,本发明提出了一种基于ddpg算法获得最优资源分配以提升定位精度的方法,目的是在尽可能短的时间内获得最优的分配方案以提高定位精度。参见图1所示的系统流程图,本发明主要包括两个部分:第一部分主要执行的操作是测距,而第二部分又由两个相关的操作组成
‑‑
位置推理和资源分配。位置推理是根据第一部分代理节点测得的距离信息,利用相关推理算法计算出代理节点的位置,在位置推理操作中获得的位置信息为节点之间的资源分配提供了先验知识。因为无线网络中可以使用的资源是有限的,所以必须以最有效的方式进行资源分配以提高测距的准确性,进而提高代理节点位置估计的精度。
48.ddpg算法的状态空间选取的是节点之间的距离以及信道参数,这些状态空间可以
从位置推理操作中获得,而ddpg算法的动作空间则选取的是各个节点分配到的带宽和功率,这里的节点指的是无线定位网络中位置已知的锚节点以及需要定位的代理节点。在经过合理的收益设置后,训练神经网络模型。在线测试阶段,只需要将代理节点此刻获得的状态信息输入到模型中,便可获得最优的带宽和功率分配方案。上述过程主要包括以下几个步骤:
49.步骤一、获取测距信息,估计代理节点位置:
50.假设无线定位网络中具有n
a
个代理节点和n
b
个锚节点,则整个网络可以使用的总带宽和总功率分别为b
total
,p
total
,无线定位网络中的各个节点根据带宽和功率的分配方案测量自身和其他节点之间的距离,利用toa定位方法来确定代理节点的具体位置;
51.其中,初始的分配方案是均匀分配,即每个节点分配到的资源是相同的,节点i分配到的带宽资源节点i分配到的功率资源其中i∈{1,2,
…
,n
a
n
b
}。
52.步骤二、获取ddpg网络状态空间:
53.所述ddpg算法的状态空间是指各个节点之间的距离以及信道参数,通过步骤一中的测距操作获得各个节点之间的距离信息,通过信道估计获得信道参数。
54.步骤三、开始网络训练:
55.采用强化学习中的ddpg算法以获得最优的资源分配方案,强化学习本质上的目的是让智能体学会在一个环境中应该采取何种动作以获得最大的收益,采用均方误差下界speb来衡量带宽和功率分配方案的优异度,speb本质上也是克拉美罗下界crlb,单个代理节点的speb可表示为
56.其中,j
e
(p
i
)是代理节点p
i
的等价费舍尔信息矩阵efim,是p
i
的估计值,协同定位网络的全局efim可表示为
[0057][0058]
代理节点i从所有的n
b
个锚节点处获得的测距信息为个锚节点处获得的测距信息为从代理节点k处获得的测距信息为理节点k处获得的测距信息为其中其中表示从节点i到节点k的角度值,λ
ik
是指测距信息密度,表示为其中ξ
ik
是指代理节点i和节点k之间测距信道参数,d
ik
代表的是代理节点i和节点k之间距离,p
k
和b
k
分别表示节点k分配到的功率和带宽资
源,当协同定位网络的全局efim中的c
ik
=0便可得到非协同定位网络的efim,再对非协同定位网络的efim求逆取迹便可得到整个网络的speb,
[0059]
整个无线定位网络的speb值可以表达为
[0060]
由此看出,全局的speb是一个关于功率和带宽的函数,因此重点在于优化无线定位网络的带宽和功率资源的分配方案。
[0061]
非协同定位网络可以看作是协同定位网络的特殊情况,令协同定位网络的efim中的c
ik
=0可得到非协同定位网络的efim,再对非协同定位网络的efim求逆取迹可得到整个无线定位网络的speb值。
[0062]
选取代理节点与其他各个节点之间的距离以及信道参数作为ddpg算法的状态空间,带宽和功率的分配方案作为ddpg算法的动作空间,定义一个强化学习的收益设置,强化学习的收益设置对最后的结果起着至关重要的影响,将收益设置表达为学习的收益设置对最后的结果起着至关重要的影响,将收益设置表达为
[0063]
其中,speb
now
指的是当时刻下的资源分配方案所对应的speb值,speb
uniform
指的是均匀分配方案所对应的speb值,p
max
指的是功率分配方案中最大的功率值。
[0064]
所用ddpg算法主要由四个网络组成,分别为actor网络、target actor网络、critic网络、target critic网络,具体参见表1所示的网络配置和参数的概述以及图2所示的ddpg算法流程示意图。
[0065][0066]
表1
[0067]
其中actor网络和target actor网络的结构相同,如图3所示,它们均包含有五个隐藏层,每一隐藏层都使用线性整流函数relu作为激活函数;actor网络的输入为所述步骤二中的状态空间,大小为(n
a
n
b
)*2n
a
,从第二个隐藏层起,网络被分为结构相同的上下两半部分,上半部分被训练用于带宽的分配,下半部分被训练用于功率的分配,对它们的输出分别进行softmax操作,最终输出得到归一化的带宽分配和功率分配,大小为n
a
n
b
。
[0068]
而target actor网络用于隔一段时间将actor网络的网络参数按照一定百分比加权到target actor网络中,以实现target actor网络的更新。
[0069]
其中,critic网络和target critic网络的结构相同,如图4所示,它们均包含有三个隐藏层,每一隐藏层都使用线性整流函数relu作为激活函数;critic网络的输入为某一时刻的状态s
t
和动作a
t
,输出为对应的q值q(s
t
,a
t
)。
[0070]
而target critic网络用于隔一段时间将critic网络的网络参数按照一定百分比加权到target critic网络中,以实现target critic网络的更新。
[0071]
步骤四、在线阶段位置的预测:
[0072]
在线测试阶段,代理节点通过均匀分配的方案获得代理节点和其他节点之间的距离信息,再通过toa定位方法估算出代理节点的位置信息,根据代理节点的位置信息可以获得步骤二中所述的状态空间,将获得的状态空间输入到步骤三里训练后的网络中,便可得到最优的资源分配方案,利用输出的资源分配方案再进行测距进而获得最终的位置估计。
[0073]
通过下列仿真实验可证明本发明的可实现性:
[0074]
基于python仿真软件,将实验的场景设计为一个9*9的正方形区域,在这个区域内有4个锚节点,它们分别位于[0,0]、[0,9]、[9,9]、[9,0],而代理节点随机的分布在该正方形区域内,如图5、图6所示,它们分别为非协同定位和协同定位的实验场景,在协同定位的场景中代理节点之间是可以进行测距操作的,而在非协同定位的场景中是不可以的。
[0075]
在该实验场景中可以用来分配的总带宽b
total
以及总功率p
total
经过归一化之后都被设为1,再者由于硬件的限制,单个节点能够分配到的功率也是有上限的,因此要求单个节点能分配到的功率经过归一化之后应该小于0.4,路径损失系数α被设置为2。
[0076]
本发明认为代理节点和其他各个节点之间的距离、角度以及信道参数都是已知的,它们可以通过初始的测距以及信道估计获得,故在仿真实验时仅考虑自由空间路径损失的影响,因此将信道参数ξ设为100。
[0077]
其中:在非协同定位的离线阶段,按照步骤三进行网络训练,如图7所示,以场景中只存在两个代理节点为例,可以看到收益在稳定的上升。
[0078]
在非协同定位的在线测试阶段,在进行分配之前,需要获得代理节点和锚节点之间的距离、角度以及信道参数信息。在利用python仿真时,由于角度以及信道参数都和距离相关,因此只需要将代理节点和锚节点之间距离信息组成一个长度为1*4的向量作为模型的输入,而模型的输出则是一个长度为4*2的向量,代表着四个锚节点的带宽以及功率的分配方案。此外,甚至还考虑了场景中存在多个代理节点的情况,用于对比。
[0079]
本发明所用ddpg算法在非协同场景下得到的结果如图8所示,随机生成多个场景输入到网络中可以得到对应场景的分配方案,再将网络输出的分配方案的speb值和均匀分配方案的speb值做对比,得到对应的提升倍数,最后再选取所有场景提升倍数的中位数来表征所用的算法的性能,我们还提出了穷尽算法用于比较。从图8中可以看出的是该算法能够达到穷尽算法的50%左右的性能。
[0080]
其中:在协同定位的离线阶段,按照步骤三进行网络训练,如图9所示,以场景中只存在两个代理节点为例,可以看到收益在稳定的上升。
[0081]
在协同定位的在线测试阶段,与非协同定位不同的是,代理节点之间也能够进行测距操作。当代理节点和锚节点之间的信道状况较差时,为了进一步的降低总的speb值,应该考虑将部分的资源分配给代理节点。因此,模型的输入向量除了代理节点和锚节点之间距离的信息,还需要加上代理节点之间距离的信息,输入向量的长度变为了(4 2)*2,同样的模型的输出也要加上对代理节点的分配情况,因此输出的向量长度变为了(4 2)*2。此外,甚至还考虑了存在更多代理节点的情况,用于对比。
[0082]
本发明所用ddpg算法在协同场景下得到的结果如图10所示,随机生成多个场景输入到网络中可以得到对应场景的分配方案,再将网络输出的分配方案的speb值和均匀分配方案的speb值做对比,得到对应的提升倍数,最后再选取所有场景提升倍数的中位数来表
征所用的算法的性能。在协同场景下的穷尽算法所需的时间太长,在协同场景下是难以实现的,因此也就不用穷尽算法来和ddpg算法进行性能上的比较了。
[0083]
通过对比图8与图10,可以看出协同定位的方法的性能要比非协同定位的方法的性能要更好。
[0084]
综上,本发明能够达到如下的有益效果:
[0085]
1、数据采集简单:本发明在进行网络训练时,只需要按照资源均匀分配的方案采集代理节点和其他节点的距离以及信道参数信息,再将采集的信息按照设定的收益设置放入网络中训练即可,数据采集非常的方便;
[0086]
2、在线测试速度快:不同于利用凸优化算法来获得最优分配的技术,在线测试阶段,本发明只需要将代理节点的状态信息输入训练好的神经网络,即可立即获得分配方案,进而获得更加精准的位置信息。计算复杂度低,计算速度快,代理节点可以获得实时的定位服务;
[0087]
此外,与本发明提出的ddpg算法相比,现有的协同定位的穷尽搜索方法所要消耗的时间太长,可参见表2穷尽算法和ddpg算法求解速度对比;
[0088]
表2:穷尽算法和ddpg算法求解速度对比(单位:秒)
[0089][0090]
3、成本低,适用范围广:本发明主要是基于ddpg实现的,它只需要提前训练出用于某个特定室内场景的模型,便可以直接依据代理节点的初始位置使用该模型得到最优的资源分配方案,进而提升代理节点的位置准确度;由此可见本发明实现的成本是非常低的,而且适用于大多数的室内场景。
[0091]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定,对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。