1.本发明涉及金融投资技术领域,尤其涉及一种股票推荐方法及装置、 计算机设备、存储介质。
背景技术:
2.股票是一种常见的投资方式,通过投入本金,在市场估值向上波动时, 用户可以获得收益,通过股票获取尽可能多的收益是每个股民的梦想。
3.但是股票市场千变万化,预测股票的未来趋势目前都没有一种稳健、 应用价值高的方案。无论是股评家还是人工的分析都很难做到精准的预 测,股市的未知性和风险性依旧是很难攻克的一个方向。
4.因此,亟需一种股票推荐方法及装置、计算机设备、存储介质。
技术实现要素:
5.(一)要解决的技术问题
6.鉴于上述技术中存在的问题,本发明至少从一定程度上进行解决。为 此,本发明的一个目的在于提出了一种股票推荐方法,能够在预测基于股 票收益率的排序应用中,表现出很高的应用价值和稳健性。
7.本发明的第二个目的在于提出了一种股票推荐装置。
8.本发明的第三个目的在于提出了一种计算机设备。
9.本发明的第四个目的在于提出了一种计算机可读存储介质。
10.(二)技术方案
11.为达到上述目的,本发明一方面提供一种股票推荐方法,包括以下步 骤:
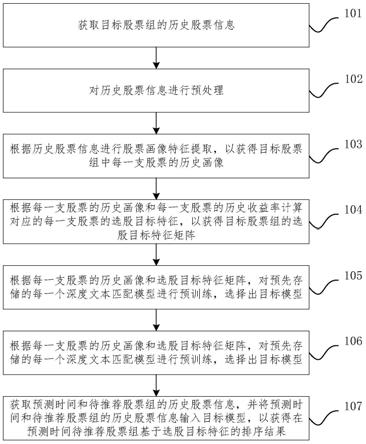
12.获取目标股票组的历史股票信息;
13.根据历史股票信息进行股票画像特征提取,以获得目标股票组中每 一支股票的历史画像;
14.根据每一支股票的历史画像和每一支股票的历史收益率计算对应的 每一支股票的选股目标特征,以获得目标股票组的选股目标特征矩阵;
15.根据每一支股票的历史画像和选股目标特征矩阵,对预先存储的每 一个深度文本匹配模型进行预训练,以选择出目标模型;
16.根据每一支股票的历史画像和选股目标特征矩阵训练目标模型;
17.获取预测时间和待推荐股票组的历史股票信息,并将预测时间和待 推荐股票组的历史股票信息输入目标模型,以获得在预测时间待推荐股 票组基于选股目标特征的排序结果。
18.本发明实施例提供的股票推荐方法,首先获取目标股票组的历史股 票信息,并根据历史股票信息进行股票画像特征提取来获得目标股票组 中每一支股票的历史画像,然后根据每一支股票的历史画像和每一支股 票的历史收益率计算对应的每一支股票的选股
目标特征以获得目标股票 组的选股目标特征矩阵,接着根据每一支股票的历史画像和选股目标矩 阵对预先存储的每一个深度文本匹配模型进行预训练来选择出目标模型, 最后根据每一支股票的历史画像和选股目标特征矩阵训练目标模型,这 样在将预测时间和待推荐股票组的历史股票信息输入到目标模型,能够 获得在预测时间待推荐股票组基于选股目标特征的排序结果。可见,本发 明将量化投资中的选股问题转化为了机器学习中目标股票组与选股目标 的匹配问题,并根据股票历史画像和股票历史收益率构建选股目标,将选 股目标作为机器学习问答问题中的问题表示,为实现问题定义到问题解 决创造了条件,也为训练高质量的目标模型提供了支撑,以及根据每一支 股票的历史画像和选股目标矩阵对预先存储的每一个深度文本匹配模型 进行预训练,来选择出适合当前选股问答的目标模型,以降低训练数据非 独立同分布特性的不利影响,从而本发明将预测时间和待推荐股票组的 历史股票信息输入训练好的目标模型,能够准确预测出基于股票收益率 的排序结果,大大提高了算法的准确度,表现出很高的应用价值和稳健性。
19.可选地,历史股票信息包括证券市场交易数据和金融社交媒体数据, 其中,根据历史股票信息进行股票画像特征提取,包括:以资产定价视角, 从证券市场交易数据中提取传统量化因子,并从金融社交媒体数据中提 取新型社交媒体量化因子。
20.可选地,根据每一支股票的历史画像和每一支股票的历史收益率计 算对应的每一支股票的选股目标特征,包括:
21.获取每一支股票的历史画像特征矩阵以及每一支股票的历史收益率集合其中,采 用的时间窗口为周度,周度包括日历周内所有交易日,历史画像特征矩阵 是由股票画像特征向量在时间序列上向后回溯w个窗口得到,w∈n ,t
i
为某一周度时间点,j为目标组股票内的第j支股票,j<n,n为目标组股 票内的股票数量,为股票的周度画像特征向量;
22.降序排列r
(j)
,并从中选取排名前k个收益率对应的股票画像特 征向量,以获得每一支股票的选股目标特征矩阵的选股目标特征矩阵其中,为k
×
m维矩阵;k为收益率最优时间窗口, k=a,1<a≤w。
23.可选地,获得目标股票组的选股目标特征矩阵,包括:
24.采用t-sne模型对每一支股票的选股目标特征矩阵进行第一次降 维处理,以获得目标股票组的选股中间矩阵
25.采用pca模型对选股中间矩阵进行第二次降维处理,以获得目 标股票组的选股目标特征矩阵
26.其中,第一次降维参数d
f
=b,b∈n ;第二次降维参数d
s
= if(m,c),m<c<(b
×
n)。
27.可选地,根据每一支股票的历史画像和选股目标特征矩阵,对预先存 储的每一个深度文本匹配模型进行预训练,以选择出目标模型,包括:
28.根据每一支股票的历史画像和选股目标特征矩阵,使预先存储的每 一个深度文本匹配模型以其所有超参数组合进行预训练;
29.在预训练过程中,根据模型表现对每一个超参数组合进行评估,以获 得每一个模型的超参数组合评估值集合;
30.根据每一个模型的超参数组合评估值集合计算每一个模型的第一标 准差,以获得所有模型的第一标准差集合;
31.根据第一标准差集合计算第二标准差,并根据第二标准差选择出目 标模型。
32.可选地,根据第二标准差选择出目标模型,包括:
33.对第二标准差进行判断;
34.若第二标准差小于预设的第一阈值,则将第一标准差集合中的最小 标准差对应的模型作为目标模型;
35.若第二标准差大于等于预设的第一阈值且小于等于预设的第二阈值, 则将第一标准差集合中的最大标准差对应的模型作为目标模型;
36.若第二标准差大于预设的第二阈值,将第一标准差集合中的中间标 准差对应的模型作为目标模型。
37.可选地,根据每一支股票的历史画像和选股目标特征矩阵训练目标 模型,包括:
38.从目标模型的超参数组合评估值集合中选出评估值最大的超参数组 合作为目标模型的最优超参数组合;
39.根据最优超参数组合训练目标模型。
40.为达到上述目的,本发明另一方面提供的一种股票推荐装置,包括:
41.获取模块,用于获取目标股票组的历史股票信息;
42.股票画像模块,用于根据历史股票信息进行股票画像特征提取,以获 得目标股票组中每一支股票的历史画像;
43.选股特征提取模块,用于根据每一支股票的历史画像和每一支股票 的历史收益率计算对应的每一支股票的选股目标特征,以获得目标组股 票的选股目标特征矩阵;
44.模型选择模块,用于根据每一支股票的历史画像和选股目标特征矩 阵,对预先存储的每一个深度文本匹配模型进行预训练,以选择出目标模 型;
45.模型训练模块,用于根据每一支股票的历史画像和选股目标特征矩 阵训练目标模型;
46.获取模块还用于,获取预测时间和待推荐股票组的历史股票信息,并 将预测时间和待推荐股票组的历史股票信息输入目标模型,以获得在预 测时间待推荐股票组基于选股目标特征的排序结果。
47.本发明实施例提供的股票推荐装置,通过获取模块获取目标股票组 的历史股票信息,并通过股票画像模块根据历史股票信息进行股票画像 特征提取来获得目标股票组中每一支股票的历史画像,然后通过选股特 征提取模块根据每一支股票的历史画像和每一支股票的历史收益率计算 对应的每一支股票的选股目标特征以获得目标股票组的选股
目标特征矩 阵,接着通过模型选择模块根据每一支股票的历史画像和选股目标矩阵 对预先存储的每一个深度文本匹配模型进行预训练来选择出目标模型, 最后通过模型训练模块根据每一支股票的历史画像和选股目标特征矩阵 训练目标模型,这样在将预测时间和待推荐股票组的历史股票信息输入 到目标模型,能够获得在预测时间待推荐股票组基于选股目标特征的排 序结果。可见,本发明将量化投资中的选股问题转化为了机器学习中目标 股票组与选股目标的匹配问题,并根据股票历史画像和股票历史收益率 构建选股目标,将选股目标作为机器学习问答问题中的问题表示,为实现 问题定义到问题解决创造了条件,也为训练高质量的目标模型提供了支 撑,以及根据每一支股票的历史画像和选股目标矩阵对预先存储的每一 个深度文本匹配模型进行预训练,来选择出适合当前选股问答的目标模 型,以降低训练数据非独立同分布特性的不利影响,从而本发明将预测时 间和待推荐股票组的历史股票信息输入训练好的目标模型,能够准确预 测出基于股票收益率的排序结果,大大提高了算法的准确度,表现出很高 的应用价值和稳健性。
48.此外,本发明实施例还提供一种计算机设备,包括存储器、处理器及 存储在存储器上并可在处理器上运行的股票推荐程序,处理器执行股票 推荐程序时,实现如上所述的股票推荐方法。
49.本发明实施例的计算机设备,通过处理器运行存储器存储的股票推 荐程序,能够将预测时间和待推荐股票组的历史股票信息输入训练好的 目标模型,准确预测出基于股票收益率的排序结果,大大提高了算法的准 确度,表现出很高的应用价值和稳健性,由于本发明将量化投资中的选股 问题转化为了机器学习中目标股票组与选股目标的匹配问题,并根据股 票历史画像和股票历史收益率构建选股目标,将选股目标作为机器学习 问答问题中的问题表示,为实现问题定义到问题解决创造了条件,也为训 练高质量的目标模型提供了支撑,以及根据每一支股票的历史画像和选 股目标矩阵对预先存储的每一个深度文本匹配模型进行预训练,来选择 出适合当前选股问答的目标模型,以降低训练数据非独立同分布特性的 不利影响。
50.此外,本发明实施例还提供一种计算机可读存储介质,其上存储有股 票推荐程序,该股票推荐程序被处理器执行时实现如上所述的股票推荐 方法。
51.本发明实施例提供的计算机可读存储介质,其上存储的股票推荐程 序被处理器执行时,能够将预测时间和待推荐股票组的历史股票信息输 入训练好的目标模型,准确预测出基于股票收益率的排序结果,大大提高 了算法的准确度,表现出很高的应用价值和稳健性,由于本发明将量化投 资中的选股问题转化为了机器学习中目标股票组与选股目标的匹配问题, 并根据股票历史画像和股票历史收益率构建选股目标,将选股目标作为 机器学习问答问题中的问题表示,为实现问题定义到问题解决创造了条 件,也为训练高质量的目标模型提供了支撑,以及根据每一支股票的历史 画像和选股目标矩阵对预先存储的每一个深度文本匹配模型进行预训练, 来选择出适合当前选股问答的目标模型,以降低训练数据非独立同分布 特性的不利影响。
52.(三)有益效果
53.本发明的有益效果是:
54.本发明提供的股票推荐方法和装置,将量化投资中的选股问题转化 为了机器学习中目标股票组与选股目标的匹配问题,并根据股票历史画 像和股票历史收益率构建选
股目标,将选股目标作为机器学习问答问题 中的问题表示,为实现问题定义到问题解决创造了条件,也为训练高质量 的目标模型提供了支撑,以及根据每一支股票的历史画像和选股目标矩 阵对预先存储的每一个深度文本匹配模型进行预训练,来选择出适合当 前选股问答的目标模型,以降低训练数据非独立同分布特性的不利影响, 从而本发明将预测时间和待推荐股票组的历史股票信息输入训练好的目 标模型,能够准确预测出基于股票收益率的排序结果,大大提高了算法的 准确度,表现出很高的应用价值和稳健性。
附图说明
55.本发明借助于以下附图进行描述:
56.图1为根据本发明一个实施例的股票推荐方法的流程图;
57.图2为根据本发明一个实施例的mv-lstm模型的设计框架图;
58.图3为根据本发明一个实施例的股票推荐装置的方框示意图。
59.【附图标记说明】
60.1:获取模块;
61.2:股票画像模块;
62.3:选股特征提取模块;
63.4:模型选择模块;
64.5:模型训练模块。
具体实施方式
65.为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施 方式,对本发明作详细描述。
66.本发明实施例提出的股票推荐方法和装置,将量化投资中的选股问 题转化为了机器学习中目标股票组与选股目标的匹配问题,并提供一种 选股目标算法和一种深度文本匹配模型选择算法,能够在预测基于股票 收益率的排序应用中,大大提高算法的准确度,表现出很高的应用价值和 稳健性。
67.为了更好的理解上述技术方案,下面将参照附图更详细地描述本发 明的示例性实施例。虽然附图中显示了本发明的示例性实施例,然而应当 理解,可以以各种形式实现本发明而不应被这里阐述的实施例所限制。相 反,提供这些实施例是为了能够更清楚、透彻地理解本发明,并且能够将 本发明的范围完整的传达给本领域的技术人员。
68.下面就参照附图来描述根据本发明实施例提出的股票推荐方法和股 票推荐装置。
69.图1为本发明一个实施例的股票推荐方法的流程示意图。
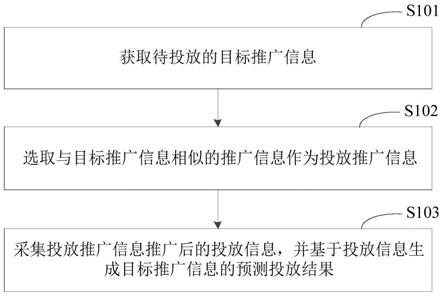
70.如图1所示,该股票推荐方法包括以下步骤:
71.步骤101、获取目标股票组的历史股票信息。
72.其中,历史股票信息包括证券市场交易数据和金融社交媒体数据。
73.具体地,作为一个示例,可从中国沪深股市筛选出一组股票作为目标 股票组。其中目标股票组的历史股票信息的数据源可包括wind金融终 端(wind financial terminal,wft)、通联数据(datayes)和东方财富网 (east money information)。wind金融
终端是中国最资深的金融信息服务 提供商之一,它提供准确、及时、完整的沪深股票数据,包括基础信息、 行情、权益、公司治理、交易数据、重大事件、财务数据和指数数据等; 通联数据是中国最专业的金融大数据提供商之一,它提供种类全面且质 量可靠的量化因子库;东方财富网是中国访问量最大、影响力最大的财经 证券门户网站之一,它旗下的股吧(股票主题社区),为用户提供实时行情 评论和个股交流论坛。当然目标股票组的历史股票信息的数据源还可以 包括如百度或者谷歌搜索趋势或者指数数据。
74.步骤102、对历史股票信息进行预处理。
75.其中,预处理的步骤包括数据清洗、去噪和整合等。
76.步骤103、根据历史股票信息进行股票画像特征提取,以获得目标股 票组中每一支股票的历史画像。
77.具体地,作为一个实施例,根据历史股票信息进行股票画像特征提取, 包括:以资产定价视角,从证券市场交易数据中提取传统量化因子,并从 金融社交媒体数据中提取新型社交媒体量化因子(如表1所示)。从资产 定价视角系统、全面地量化了影响股票收益的因素,从而综合的刻画这一 风险资产的金融属性,并为后续问题地解决提供数据基础。
78.表1股票画像
79.[0080][0081]
步骤104、根据每一支股票的历史画像和每一支股票的历史收益率计 算对应的每一支股票的选股目标特征,以获得目标股票组的选股目标特 征矩阵。
[0082]
具体地,作为一个实施例,根据每一支股票的历史画像和每一支股票 的历史收益率计算对应的每一支股票的选股目标特征,包括:
[0083]
获取每一支股票的历史画像特征矩阵以及每一支股票的历史收益率集合其中,采 用的时间窗口为周度,周度包括日历周内所有交易日,历史画像特征矩阵 是由股票画像特征向量在时间序列上向后回溯w个窗口得到,w∈n ,t
i
为某一周度时间点,j为目标组股票内的第j支股票,j<n,n为目标组股 票内的股票数量,为股票的周度画像特征向量;降序排列r
(j)
, 并从中选取排名前k个收益率对应的股票画像特征向量,以获得每一 支股票的选股目标特征矩阵其中,为 k
×
m维矩阵;k为收益率最优时间窗口,k=a,1<a≤w。
[0084]
进一步地,作为一个实施例,获得目标股票组的选股目标特征矩阵, 包括:采用t-sne模型对每一支股票的选股目标特征矩阵进行第一次 降维处理,以获得目标股票组的选股中间矩阵采用pca模型对选 股中间矩阵进行第二次降维处理,以获得目标股票组的选股目标特征 矩阵其中,第一次降维参数d
f
=b,b∈n ;第二次降维参数d
s
= if(m,c),m<c<(b
×
n)。对每一支股票的选股目标特征矩阵进行降维处 理,可以大大降低运算量,提高了处理速度。
[0085]
步骤105、根据每一支股票的历史画像和选股目标特征矩阵,对预先 存储的每一个深度文本匹配模型进行预训练,以选择出目标模型。
[0086]
具体地,作为一个实施例,步骤105包括:根据每一支股票的历史画 像和选股目标特征矩阵,使预先存储的每一个深度文本匹配模型以其所 有超参数组合进行预训练;在预训练过程中,根据模型表现对每一个超参 数组合进行评估,以获得每一个模型i的超参数组合评估值集合k
(i)
= {score1,score2,
…
,scorek},k为超参数组合的数目;根据每一个模型的超 参数组合评估值集合a
(i)
计算每一个模型的第一标准差以获得所有 模型
的第一标准差集合根据第一标准差集合计 算第二标准差σ
b
,并根据第二标准差σ
b
选择出目标模型。其中,在模型训 练过程中,选股目标特征矩阵看作是机器学习问答问题中的问题表示,每 一支股票的历史画像看作是机器学习问答问题中的答案表示。
[0087]
进一步地,作为一个实施例,根据第二标准差σ
b
选择出目标模型,包 括:对二标准差σ
b
进行判断;若第二标准差σ
b
小于预设的第一阈值a,则 将第一标准差集合b中的最小标准差min(b)对应的模型作为目标模型;若 第二标准差σ
b
大于等于预设的第一阈值a且小于等于预设的第二阈值b, 则将第一标准差集合b中的最大标准差max(b)对应的模型作为目标模型; 若第二标准差σ
b
大于预设的第二阈值b,将第一标准差集合b中的中间标 准差median(b)对应的模型作为目标模型。
[0088]
进一步地,作为一个实施例,预设的第一阈值a=0.01,预设的第二 阈值b=0.035。
[0089]
本发明提供的目标模型选择算法,可以根据不同深度文本匹配模型 的特点,选择出适合当前选股问答的目标模型,以降低训练数据非独立同 分布特性的不利影响,从而将预测时间和待推荐股票组的历史股票信息 输入这种训练好的目标模型,能够准确预测出基于股票收益率的排序结 果,大大提高了算法的准确度,表现出很高的应用价值和稳健性。
[0090]
具体地,作为一个示例,预先存储的深度文本匹配模型可包括 drmm-tks模型、conv-knrm模型和mv-lstm模型。对于上述从中 国沪深股市筛选出的目标股票组,mv-lstm更擅长捕捉时间序列数据中 的信号,在模型预训练中表现最好。
[0091]
对于mv-lstm模型,详细描述如下:
[0092]
如图2所示,mv-lstm模型首先采用双向长短记忆算法 (bidirectional lstms,bi-lstms),生成多位置句子表示。bi-lstms可 以捕获序列向后与向前方向的信息,每个位置上的输出是来自这两个方 向上的两个向量和的连接。若定义一个句子t= {t
(1)
,t
(2)
,
…
,t
(k)
,
…
,t
(w)
}作为算法输入,t
(k)
表示在位置t上的词向量表示。 经过公式(1-1)、(1-2)、(1-3)、(1-4)、(1-5)计算后,位置t输出一个词向 量表示h
(t)
。
[0093][0094]
式中,i、f、o分别代表输入层门、忘记门和输出层门;c是存储信 息的记忆单元。
[0095]
那么,第t个位置上的句子表示由和连接生成其 中,(
·
)
t
表示下一步运算将用到的置换操作。然后,在位置句表示的基础 上,对来自不同位置的交互句子对进行建模,mv-lstm采用三种相似度 函数,分别是余弦相似性、双线性相似性和张量层相似性,对与的 交互进行建模,其中与分别代表句子s
x
与s
y
在第i
与j处的位置句 子表示。最后,k-max池化层按公式(1-6)从相似矩阵或者相似张量中抽取 前k个最强局部信息,并经过全连接隐含层生成更高水平的向量表示r, 多层感知器再按公式(1-7)、(1-8)计算出匹配得分。
[0096][0097][0098]
s=w
s
r b
s
,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1-8)
[0099]
mv-lstm的损失函数计算公式是:
[0100][0101]
式中,分别表示正样本和负样本。
[0102]
步骤106、根据每一支股票的历史画像和选股目标特征矩阵训练目标 模型。
[0103]
具体地,作为一个实施例,步骤106包括:从目标模型的超参数组合 评估值集合a
(i)
中选出评估值最大的超参数组合作为目标模型的最优超 参数组合;根据最优超参数组合训练目标模型。
[0104]
步骤107、获取预测时间和待推荐股票组的历史股票信息,并将预测 时间和待推荐股票组的历史股票信息输入目标模型,以获得在预测时间 待推荐股票组基于选股目标特征的排序结果。
[0105]
具体地,作为一个示例,对于上述从中国沪深股市筛选出的目标股票 组,本发明训练了mv-lstm模型,在预测待推荐股票组在某一调仓日 的股票收益率排序过程中,训练好的mv-lstm模型在ndcg@10和err 两种评价指标下,都取得了非常不错的表现。
[0106]
综上所述,本发明提供的股票推荐方法将量化投资中的选股问题转 化为了机器学习中目标股票组与选股目标的匹配问题,并结合提供的选 股目标算法和深度文本匹配模型选择算法,从而能够在预测基于股票收 益率的排序应用中,大大提高算法的准确度,表现出很高的应用价值和稳 健性。
[0107]
根据本发明实施例提供的股票推荐方法,首先获取目标股票组的历 史股票信息,并根据历史股票信息进行股票画像特征提取来获得目标股 票组中每一支股票的历史画像,然后根据每一支股票的历史画像和每一 支股票的历史收益率计算对应的每一支股票的选股目标特征以获得目标 股票组的选股目标特征矩阵,接着根据每一支股票的历史画像和选股目 标矩阵对预先存储的每一个深度文本匹配模型进行预训练来选择出目标 模型,最后根据每一支股票的历史画像和选股目标特征矩阵训练目标模 型,这样在将预测时间和待推荐股票组的历史股票信息输入到目标模型, 能够获得在预测时间待推荐股票组基于选股目标特征的排序结果。可见, 本发明将量化投资中的选股问题转化为了机器学习中目标股票组与选股 目标的匹配问题,并根据股票历史画像和股票历史收益率构建选股目标, 将选股目标作为机器学习问答问题中的问题表示,为实现问题定义到问 题解决创造了条件,也为训练高质量的目标模型提供了支撑,以及根据每 一支股票的历史画像和选股目标矩阵对预先存储的每一个深度文本匹配 模型进行预训练,来选择出适合当前选股问答的目标模型,以降低训练数 据非独立同分布特性的不利影响,从而本发明将预测时间和待推荐股票 组的历史股票信息输入训练好的目标模型,能够准确预测出基于股票收 益
率的排序结果,大大提高了算法的准确度,表现出很高的应用价值和稳 健性。
[0108]
图3为本发明一个实施例的股票推荐装置的方框示意图。
[0109]
如图3所示,该股票推荐装置包括:获取模块1、股票画像模块2、 选股特征提取模块3、模型选择模块4和模型训练模块5。
[0110]
其中,获取模块1,用于获取目标股票组的历史股票信息;股票画像 模块2,用于根据历史股票信息进行股票画像特征提取,以获得目标股票 组中每一支股票的历史画像;选股特征提取模块3,用于根据每一支股票 的历史画像和每一支股票的历史收益率计算对应的每一支股票的选股目 标特征,以获得目标组股票的选股目标特征矩阵;模型选择模块4,用于 根据每一支股票的历史画像和选股目标特征矩阵,对预先存储的每一个 深度文本匹配模型进行预训练,以选择出目标模型;模型训练模块5,用 于根据每一支股票的历史画像和选股目标特征矩阵训练目标模型;获取 模块1还用于,获取预测时间和待推荐股票组的历史股票信息,并将预测 时间和待推荐股票组的历史股票信息输入目标模型,以获得在预测时间 待推荐股票组基于选股目标特征的排序结果。
[0111]
作为一个实施例,股票画像模块2具体用于以资产定价视角,从证券 市场交易数据中提取传统量化因子,并从金融社交媒体数据中提取新型 社交媒体量化因子,以获得目标股票组中每一支股票的历史画像。
[0112]
作为一个实施例,选股特征提取模块3具体用于降序排列每一支股 票的历史收益率集合r
(j)
,并从每一支股票的历史画像特征矩阵 中选取排名前j个收益率对应的股票画像特征向量,以获得每一支股 票的选股目标特征矩阵然后采用t-sne模 型对每一支股票的选股目标特征矩阵进行第一次降维处理,以获得目 标股票组的选股中间矩阵采用pca模型对选股中间矩阵进行 第二次降维处理,以获得目标股票组的选股目标特征矩阵
[0113]
作为一个实施例,模型选择模块4具体用于根据每一支股票的历史 画像和选股目标特征矩阵,使预先存储的每一个深度文本匹配模型以其 所有超参数组合进行预训练;在预训练过程中,根据模型表现对每一个超 参数组合进行评估,以获得每一个模型i的超参数组合评估值集合a
(i)
= {score1,score2,
…
,scorek},k为超参数组合的数目;根据每一个模型的超 参数组合评估值集合a
(i)
计算每一个模型的第一标准差以获得所有 模型的第一标准差集合根据第一标准差集合计 算第二标准差σ
b
,并根据第二标准差σ
b
选择出目标模型。
[0114]
作为一个实施例,通过模型选择模块4根据第二标准差σ
b
选择出目 标模型,包括:对二标准差σ
b
进行判断;若第二标准差σ
b
小于预设的第一 阈值a,则将第一标准差集合b中的最小标准差min(b)对应的模型作为目 标模型;若第二标准差σ
b
大于等于预设的第一阈值a且小于等于预设的第 二阈值b,则将第一标准差集合b中的最大标准差max(b)对应的模型作为 目标模型;若第二标准差σ
b
大于预设的第二阈值b,将第一标准差集合b 中的中间
标准差median(b)对应的模型作为目标模型。
[0115]
作为一个实施例,模型训练模块5具体用于从目标模型的超参数组 合评估值集合a
(i)
中选出评估值最大的超参数组合作为目标模型的最优 超参数组合;根据最优超参数组合训练目标模型。
[0116]
综上所述,本发明提供的股票推荐装置将量化投资中的选股问题转 化为了机器学习中目标股票组与选股目标的匹配问题,并结合提供的选 股目标算法和深度文本匹配模型选择算法,从而能够在预测基于股票收 益率的排序应用中,大大提高算法的准确度,表现出很高的应用价值和稳 健性。
[0117]
根据本发明实施例提供的股票推荐装置,通过获取模块获取目标股 票组的历史股票信息,并通过股票画像模块根据历史股票信息进行股票 画像特征提取来获得目标股票组中每一支股票的历史画像,然后通过选 股特征提取模块根据每一支股票的历史画像和每一支股票的历史收益率 计算对应的每一支股票的选股目标特征以获得目标股票组的选股目标特 征矩阵,接着通过模型选择模块根据每一支股票的历史画像和选股目标 矩阵对预先存储的每一个深度文本匹配模型进行预训练来选择出目标模 型,最后通过模型训练模块根据每一支股票的历史画像和选股目标特征 矩阵训练目标模型,这样在将预测时间和待推荐股票组的历史股票信息 输入到目标模型,能够获得在预测时间待推荐股票组基于选股目标特征 的排序结果。可见,本发明将量化投资中的选股问题转化为了机器学习中 目标股票组与选股目标的匹配问题,并根据股票历史画像和股票历史收 益率构建选股目标,将选股目标作为机器学习问答问题中的问题表示,为 实现问题定义到问题解决创造了条件,也为训练高质量的目标模型提供 了支撑,以及根据每一支股票的历史画像和选股目标矩阵对预先存储的 每一个深度文本匹配模型进行预训练,来选择出适合当前选股问答的目 标模型,以降低训练数据非独立同分布特性的不利影响,从而本发明将预 测时间和待推荐股票组的历史股票信息输入训练好的目标模型,能够准 确预测出基于股票收益率的排序结果,大大提高了算法的准确度,表现出 很高的应用价值和稳健性。
[0118]
此外,本发明实施例还提供一种计算机设备,包括存储器、处理器及 存储在存储器上并可在处理器上运行的股票推荐程序,处理器执行股票 推荐程序时,实现如上所述的股票推荐方法。
[0119]
根据本发明实施例提供的计算机设备,通过处理器运行存储器存储 的股票推荐程序,能够将预测时间和待推荐股票组的历史股票信息输入 训练好的目标模型,准确预测出基于股票收益率的排序结果,大大提高了 算法的准确度,表现出很高的应用价值和稳健性,由于本发明将量化投资 中的选股问题转化为了机器学习中目标股票组与选股目标的匹配问题, 并根据股票历史画像和股票历史收益率构建选股目标,将选股目标作为 机器学习问答问题中的问题表示,为实现问题定义到问题解决创造了条 件,也为训练高质量的目标模型提供了支撑,以及根据每一支股票的历史 画像和选股目标矩阵对预先存储的每一个深度文本匹配模型进行预训练, 来选择出适合当前选股问答的目标模型,以降低训练数据非独立同分布 特性的不利影响。
[0120]
此外,本发明实施例还提供一种计算机可读存储介质,其上存储有股 票推荐程序,该股票推荐程序被处理器执行时实现如上所述的股票推荐 方法。
[0121]
根据本发明实施例提供的计算机可读存储介质,其上存储的股票推 荐程序被处
理器执行时,能够将预测时间和待推荐股票组的历史股票信 息输入训练好的目标模型,准确预测出基于股票收益率的排序结果,大大 提高了算法的准确度,表现出很高的应用价值和稳健性,由于本发明将量 化投资中的选股问题转化为了机器学习中目标股票组与选股目标的匹配 问题,并根据股票历史画像和股票历史收益率构建选股目标,将选股目标 作为机器学习问答问题中的问题表示,为实现问题定义到问题解决创造 了条件,也为训练高质量的目标模型提供了支撑,以及根据每一支股票的 历史画像和选股目标矩阵对预先存储的每一个深度文本匹配模型进行预 训练,来选择出适合当前选股问答的目标模型,以降低训练数据非独立同 分布特性的不利影响。
[0122]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统或 计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例, 或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多 个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限 于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形 式。
[0123]
本发明是参照根据本发明实施例的方法、设备(系统)和计算机程序 产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现 流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框 图中的流程和/或方框的结合。
[0124]
应当注意的是,在权利要求中,不应将位于括号之间的任何附图标记 理解成对权利要求的限制。词语“包含”不排除存在未列在权利要求中的 部件或步骤。位于部件之前的词语“一”或“一个”不排除存在多个这样 的部件。本发明可以借助于包括有若干不同部件的硬件以及借助于适当 编程的计算机来实现。在列举了若干装置的权利要求中,这些装置中的若 干个可以是通过同一个硬件来具体体现。词语第一、第二、第三等的使用, 仅是为了表述方便,而不表示任何顺序。可将这些词语理解为部件名称的 一部分。
[0125]
此外,需要说明的是,在本说明书的描述中,术语“一个实施例”、
ꢀ“
一些实施例”、“实施例”、“示例”、“具体示例”或“一些示例
”ꢀ
等的描述,是指结合该实施例或示例描述的具体特征、结构、材料或者特 点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语 的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特 征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方 式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明 书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和 组合。
[0126]
尽管已描述了本发明的优选实施例,但本领域的技术人员在得知了 基本创造性概念后,则可对这些实施例作出另外的变更和修改。所以,权 利要求应该解释为包括优选实施例以及落入本发明范围的所有变更和修 改。
[0127]
显然,本领域的技术人员可以对本发明进行各种修改和变型而不脱 离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明 权利要求及其等同技术的范围之内,则本发明也应该包含这些修改和变 型在内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。