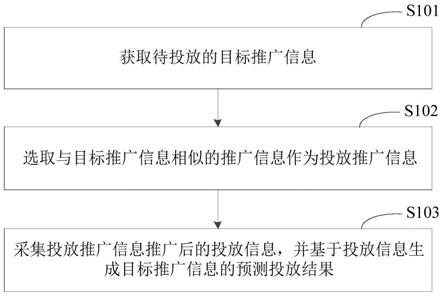
1.本发明涉及云计算领域,特别涉及一种物理服务器的上云方法、云迁移系统和计算机可读存储介质,计算机可读存储介质被处理器执行时能实现物理服务器的上云方法。
背景技术:
2.云计算的出现,带来了全新的it基础架构建设、使用和交付模式。云服务器供应商通过服务器虚拟化技术得到虚拟机并将其作为业务服务器提供给用户使用,可以实现更细粒度的资源利用。相比传统物理机,虚拟机的部署更为方便快捷,而且可以在不同物理机之间迁移,提高了资源调度的灵活性。
3.而随着云计算步入成熟期,企业数据中心逐渐云化,客户遇到的首要问题就是业务上云。每一个业务系统,自开始进行上云操作就需要停止对外服务,特别是导出数据时,为了保证上云之后的数据一致性,需要停止服务至上云完成之后才能继续提供服务,从操作系统部署、数据导出、数据导入、业务部署、结果验证,环节众多,而且最终结果也难以预测,有可能迁移完成之后由于兼容性等问题导致迁移失败。
技术实现要素:
4.本发明所要解决的技术问题是提供一种物理服务器的上云方法,存储有被执行时实现上述方法的计算机程序的计算机可读存储介质,包括该存储介质的云迁移系统,该方法能够实现资源池异构。
5.提供一种物理服务器的上云方法,包括如下步骤:云迁移步骤,将源端的磁盘空间中的数据迁移到目标端;业务切换步骤,在完成所述云迁移步骤后,进行源端和目标端的业务切换;其特征是,包括与所述云迁移步骤一起执行的增量迁移步骤,自启动所述云迁移步骤的时间点开始,将源端产生的增量数据分多次迁移到目标端。
6.优选地,所述业务切换步骤是在源端数据全部迁移完成之后执行的。
7.优选地,包括空盘识别步骤:通过磁盘空间使用识别技术将闲置的磁盘空间标记空数据,在所述云迁移步骤中跳过被标记为空的数据所占据的磁盘空间。
8.优选地,所述增量数据是通过安装在源端的代理agent对磁盘空间变化量进行记录得到的。
9.优选地,所述增量迁移步骤是周期性执行的。
10.优选地,所述业务切换步骤在所述增量迁移步骤完成后才执行。
11.优选地,所述业务切换步骤在预设的业务闲时执行,所述增量迁移步骤一直执行直到所述业务闲时。
12.优选地,对于源端上由相同主机服务的多个业务,将其数据迁移至目标端的不同虚拟机。
13.还提供一种计算机可读存储介质,其存储有计算机程序,所述计算机程序被处理
器执行时能够实现上述物理服务器的上云方法。
14.还提供一种云迁移系统,包括作为物理服务器的源端、作为目标端的具有多个虚拟机的云管平台以及处理器,处理器内预先存储有上述计算机可读存储介质,该计算机可读存储介质上的计算机程序可被处理器执行。
15.有益效果:该自动化的物理服务器的上云方法,用户可以在不关闭业务的同时进行迁移操作,保证用户的业务受到最小的影响。系统业务在线时定点通过全量迁移来复制整个磁盘,通过网络传输全量数据,然后通过增量的方式,将全盘迁移过程中产生的数据再次复制到目标vm中,确保数据的一致性。
附图说明
16.图1是云迁移系统架构示意图。
17.图2是精简迁移方式的过程示意图。
18.图3是增加迁移方式的过程示意图。
19.图4是多业务主机上云后的多虚拟机配置方式的示意图。
具体实施方式
20.以下结合具体实施方式对本发明创造作进一步详细说明。
21.如图1所示,云迁移系统包括作为源端的物理服务器和目标端虚拟机vm,以及对虚拟机进行管理的云管平台。该云迁移系统执行如下物理服务器的上云方法:云迁移步骤,将源端的磁盘空间中的数据迁移到目标端;与云迁移步骤一起执行的增量迁移步骤,自启动云迁移步骤的时间点开始,将源端产生的增量数据分多次迁移到目标端;业务切换步骤,在完成云迁移步骤后,进行源端和目标端的业务切换。
22.具体地,源端安装迁移代理agent,该迁移代理agent通过v2vserver与目标端虚拟机vm里面的pe系统建立联系,然后通过p2p技术,将源端的数据直迁到目标端。云迁移系统要求目标端的磁盘大小大于等于源端磁盘,然后通过整机迁移的技术,将源端数据通过p2p网络传输的方式直接迁入目标磁盘。整机迁移可以实现系统 数据 业务一次性迁移到目标端vm,是业务上云最高效、最方便的迁移模式。
23.见图2,云迁移系统通过智能的磁盘空间使用识别技术,只拷贝磁盘上的有效数据,空闲的空间不做传输操作,极大的提高了数据迁移速度,如上图所示,磁盘的空白区域是不做迁移的,只保留下指针记录,在目标端再进行空间恢复。
24.如图3所示,云迁移系统通过在源端安装agent的方式,记录磁盘变化量,整机迁移后仅需迁移增量数据,可以极大的降低业务的中断时间,减少停机窗口。
25.为了确保数据的一致性,在数据迁移完成之后,需要协调数分钟的停机窗口进行源端和目标端的业务切换。增量数据的同步周期默认为5分钟同步一次,用户可以在白天启动迁移任务,然后晚上再进行业务切换,期间的增量数据可以每五分钟同步一次,无需等到晚上再启动迁移任务。
26.云迁移系统采用在线迁移的方式,用户可以在不关闭业务的同时进行迁移操作,保证用户的业务受到最小的影响。系统业务在线时通过全量迁移来复制整个磁盘,通过网
络传输全量数据,然后通过增量的方式,将全盘迁移过程中产生的数据再次复制到目标vm中,确保数据的一致性。
27.该云迁移系统对源端和目标端的配置如下。
28.(1)源端和目标端的磁盘个数保持一致,目标端的磁盘存储量大于等于源端的磁盘存储量。
29.(2)目标端的cpu大小和内存大小根据源端业务的cpu、内存使用率调整,如目标端的内存(cpu)大小=源端内存(cpu)大小*使用率*预设倍数(如1.2倍);如此则源端内存(cpu)使用率越低,迁移后匹配的目标端的内存(cpu)大小越小,使用率低于83.33%时目标端的内存(cpu)大小小于源端。
30.(3)把源端混合在一台主机上的多个业务,经上云后分设在不同主机上,见图4,原来邮件服务器和oa服务器跑在同一台物理机上,上云后则分开在两台vm上面运行。
31.其中,限制云迁移服务所占用的存储性能。为了确保在迁移过程中业务系统能够正常运行,云迁移系统读取源端数据时默认占用源端主机存储性能的30%,大于这个数值可以会导致源端业务影响缓慢或前端页面超时无响应,在业务空闲阶段也可以调整到最大值,这样数据迁移就会快非常多,可以节省大量的迁移时间。
32.其中,限制云迁移服务所占用的网络带宽。为了确保在迁移过程中不影响到同一网络下的业务的运行,默认占用网络带宽为300mbit/s,可以根据当前环境的网络空闲度适当上调该值,
‑
1是代表不限制网络带宽,如果已经协调了停机窗口,可以调整为
‑
1缩减数据迁移的时间。
33.其中,默认使用pe的ip,也就是目标端数据传输的ip作为业务上云之后的业务ip,如果要保留源端的ip地址,则通过切换步骤将ip设置调整为“使用源机配置”。
34.其中,该云迁移系统的源端支持:windowsserver2008/2008r2/2012/2012r2/2016/2019;windows7/8/10;redhat/centos/oraclelinux6.x及之后的版本;suse10sp1~sp4/11sp1~sp4/12sp1~sp4/15以及ubuntu14~20。
35.如上仅为本发明创造的实施方式,不以此限定专利保护范围。本领域技术人员在本发明创造的基础上作出非实质性的变化或替换,仍落入专利保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。