1.涉及书法汉字修复领域。
技术背景
2.书法,是中国及深受中国文化影响过的周边国家和地区特有的一种文字美的艺术表现形式。作为中国文化传承的载体,书法文字兼具重要的史学与艺术价值。然而,随着时间的流逝,记录书法的碑文石刻受到各类侵蚀作用,斑斑驳驳的文字上大多包含或大或小的侵蚀和噪点。因而,书法文字侵蚀修复的问题应运而生,其意义主要在于:书法大家的墨宝遭受到笔画乃至偏旁部首的完整性,破坏书法作品的本身的价值。修复书法文字侵蚀,即在保留作家原书写风格的基础上还原被侵蚀的字体,恢复其自身的历史与美学价值。
3.如今的书法文字侵蚀修复主要分为两类,其一是传统的人工手动修复,其二则是利用计算机较为传统的图像修复方法修复。下面对两者进行详述。
4.第一,人工手动修复。这类修复方法是指通过专业的文物修复专家之手,凭借其多年积累的经验和先验知识,对书法文字进行猜测补全。经修复专家修复的作品一般效果不错,内容合情合理,笔画连贯且毫无僵硬之态。但其弊端也很突出,人工修复费时费力。相关文物修复专家人数较少,且对每一件文物的修复方案都要进行细细推敲,不可能实现大批量的修复。大量拓片囤积不得修复,其中的价值也逐渐石沉大海。
5.第二,计算机传统图像修复方法修复。这类修复方法主要通过一些插值的方法,使得残断的笔画联结起来。这类方法虽然速度快,但效果却不尽人意。主要体现在以下两点:1)修复效果僵硬。这类传统方法主要去除了汉字上的噪点,不去考虑字的字形和风格,仅仅在笔画中断处进行简单填充。2)对于侵蚀较大区域,这类方法无从下手。因为传统方法无法习得汉字中常见的笔画,对汉字的结构特征一无所知。所以在有大区域需要填补时,无法正确修复。
6.1.1相关的现有技术
[0007]“基于条件对抗网络的缺损古籍汉字修复方法”,专利公开号:cn110335212a。
[0008]
cn110335212a利用了条件对抗网络技术,构建了由判别器和生成器构成的神经网络模型,从而达到了汉字修复图像,它的简要步骤图如下,后文会进行详尽阐述:
[0009]
首先,该发明基于手写汉字图像数据集,通过建立n个文件夹,分别对应n个不同的手写汉字图像,每个文件夹内分别放入m个汉字图像,最终得到n*m张图片,预处理后作为输入;然后将得到的手写汉字图像数据进行训练,通过梯度反向传播算法迭代更新辨别器神经网络权重和生成器神经网络权重;最后将待处理的缺损手写汉字图像数据样本带入更新的辨别器和生成器中进行迭代,得到修复后的手写汉字图像。
[0010]
cn110335212a技术的第一个主要缺点在于它使用的数据集是手写汉字数据集,缺少足够的字体风格特征。对于书法汉字修复来说,修复具有独特风格的书法汉字字体是一大难点,使用笔画粗细单一,风格迥异的手写汉字数据集,直接将这一维度的特征向量予以忽略,修复的汉字风格很难与原文保持一致,即使较好地恢复了字型,填补上的笔画也颇为
僵硬。
[0011]
第二个缺点在于这一技术缺少对字形结构的控制。由于受损部分有很大的随机性,修复的笔画时而不符合原字的字型结构。当侵蚀区域较大时,正确地恢复字型也成了极大的挑战。
[0012]
现存表现较好的其余方法需要提供对侵蚀区域的标注。而拓片上零零散散、大小不一的侵蚀区域目前没有很好的自动标注方法,也就直接导致了该方法地修复效果不佳。在本发明提出的方案中,能有效解决这一局限。
技术实现要素:
[0013]
针对修复的汉字风格很难与原文保持一致的缺陷,以及缺少对字形结构的控制的缺陷,如何从噪点中提取字型结构并转换为特征向量,从而通过损失函数控制字型结构,成为可以改进的创新点。
[0014]
技术方案
[0015]
一种基于风格迁移的书法汉字修复方法,特征是,概述如下:
[0016]
首先,为确保风格一致,本发明提出风格编码器,输入辅助风格字体,用于提取出拓片上完好汉字的书写风格特征。
[0017]
接着,为确保修复字型正确,本发明不仅输入待修复汉字,还提供该字的宋体完整版本作为原字型参考。将上述书写风格特征、待修复汉字、参考原字型整合,三者一并输入到用于修复汉字的生成器g中,得到修复结果,用于分别提供给判别器d和结构提取器。
[0018]
然后,判别器d的目标是鉴别生成器g的修复结果与参与连接的原型字体和输入编码器之中的风格字体,将前者判为假,后者判为真。同时,原字型也会通过结构提取器生成带有结构特征的特征向量。通过下述的综合损失函数反向传播不断优化判别器d与生成器g。
[0019]
为了考量修复结果是否理想,设计的损失函数包括以下六个部分:
[0020]
1)对抗损失,用于考量修复汉字整体而言是否接近真实完整汉字;
[0021]
所述对抗损失函数:定义待修复的汉字图像为c
c
,完整图像为c
t
,同一个字的宋体原型图像为c
p
,与c
c
具有相同风格的其他完整汉字图像为c
s
,c
c
和c
p
在通道维度上连接得到的图像向量为c
v
,使用风格编码器抽取的c
p
的风格编码为s
p
,c
s
的风格编码为s
s
,c
t
的风格编码为s
t
,则生成式对抗网络gan的损失函数可表示如下:
[0022][0023]
其中d
s
(c)是判别器,判别具有风格s的图像c是否是生成器生成的,g(c,s)表示这是生成器依据风格编码s对图像c进行修复后生成的结果;
[0024]
2)l1损失,用于考量修复结果在像素级别上与标准结果的差距;
[0025]
目标平均绝对误差损失函数:
[0026]
其中c
v
,c
t
,s
s
,g(c
v
,s
s
)的含义同上所述。
[0027]
3)编码损失,用于考量风格编码器编码效果;
[0028]
风格编码损失函数:
[0029]
其中c
v
,s
s
,s
t
的含义同上所述,g(c
c
,s
t
)表示生成器参考目标图像c
t
的风格编码s
t
对缺损图像c
c
,进行修复的结果,g(c
c
,s
s
)表示生成器参考风格字体c
s
的风格编码s
s
对缺损图像c
c
,进行修复的结果。
[0030]
4)风格重构损失,同样用于考量修复汉字的风格与原作品书写风格的一致程度;
[0031]
风格编码重构损失函数:定义e(c)表示使用风格编码器提取文字图像c的风格编码,风格编码重构损失函数(4)可表示如下:
[0032][0033]
其中c
v
,c
s
,s
s
的含义同上所述,g(c
v
,s
s
)表示生成器依据风格字体c
s
的风格编码s
s
对图像向量c
v
进行修复的结果,e(g(c
v
,s
s
))表示使用风格编码器提取修复结果的风格编码。
[0034]
5)循环一致损失,用于考量字型是否保持完好;
[0035]
所述循环一致性损失函数:定义g(c
v
,s
s
)表示生成器依据风格编码s
s
对图像c
v
进行修复的结果,表示g(c
v
,s
s
)在通道维度上与c
p
连接得到的图像向量,循环一致性损失函数可表示如下:
[0036]
其中c
v
,c
p
,s
s
,s
p
的含义同上所述,表示生成器依据原型字体的风格编码s
p
对图像向量进行反向复原的结果。
[0037]
6)字型结构损失,用于考量修复字型与真实字型的偏离程度;
[0038]
文字结构一致性损失函数:定义s(c)表示使用预训练结构提取器抽取文字图像c的文字结构并以嵌入向量的形式输出,文字结构一致性损失函数(3)可表示如下:
[0039][0040]
其中c
v
,c
p
,s
s
的含义同上所述。g(c
v
,s
s
)表示生成器依据风格字体c
s
的风格编码s
s
对图像向量c
v
进行修复的结果,表示使用结构提取器从修复结果中提取结构嵌入向量,s(c
p
)表示从原型字体c
p
提取结构嵌入向量。
[0041]
采用综合损失函数以协调以上六个损失函数。模型的综合损失函数可表示如下:
[0042][0043]
最后得到的修复结果就是参考原型字体的结构和风格字体的风格进行修复的效果。
附图说明
[0044]
图1是本方案提出的对抗式生成网络整体结构图
[0045]
图2本方案提出的对抗式生成网络判别器与生成器相互制约的关系
[0046]
图3本方案提出的对抗式生成网络循环一致性损失函数的约束对象
[0047]
图4本方案提出的对抗式生成网络结构提取器的结构
[0048]
图5本方案提出的对抗式生成网络风格编码重构损失函数的表现形式
[0049]
图6本方案提出的对抗式生成网络风格编码器的结构
[0050]
图7是本方案提出的对抗式生成网络与目标修复字符的比对过程
[0051]
图8是现有技术cn110335212a专利文献中的流程图。
具体实施方式
[0052]
以下结合附图对本发明技术方案做进一步介绍。
[0053]
一种基于风格迁移的书法文字侵蚀修复方法,特征是,使用生成式对抗网络来完成汉字的模型修复。
[0054]
第一部分,具体的网络结构设计。
[0055]
如下图1所示。
[0056]
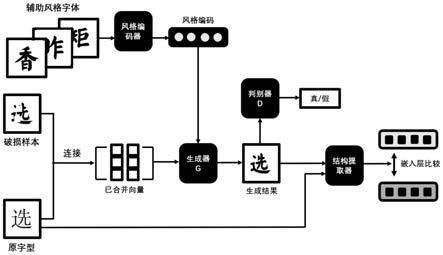
如图1所示的网络结构示意图,这是一个基于生成式对抗网络gan改良的模型,由一个生成器g,一个判别器d,一个风格编码器和一个结构提取器组成,完成一个端到端的书法文字侵蚀修复:输入端为一个带有随机侵蚀噪点的破损样本与一个改字对应的宋体字,以及一系列与破损样本同一风格的其他字型。生成器通过对原字型结构的提取以及对同风格其余汉字的风格提取,不断生成足以迷惑判别器的修复样本,同时,判别器也在训练中不断提高鉴别能力,从而达成对抗生成的动态平衡。
[0057]
以下图1进行具体分析:假设,作为参考的原型字体为宋体,需要修复的汉字图像为某一种字体a。首先,需要从字体a中选取若干完整的汉字,将它们定义为风格字体,使用一个风格编码器从风格字体中提取出一个风格编码。这个风格编码表示字体a的风格特征分布。随后,从将待修复的字体图像和同一个字的宋体完整图像在通道维度上进行连接,得到一个待修复的图像向量。将连接后的图像向量和用编码器抽取的风格编码一起输入到生成器g中,完成对汉字图像的修复,生成修复后的图像。将修复后的图像输入到判别器d中。判别器d的任务是将生成器g生成的修复结果判别为假,而将参与连接的原型字体和输入编码器之中的风格字体判别为真。最后得到的修复结果就是参考原型字体的结构和风格字体的风格进行修复的效果。
[0058]
第二部分,本方案提出的汉字修复模型需要使用损失函数来约束和修正网络的训练过程。本方案中涉及的损失函数有以下六个。
[0059]
1)对抗损失函数。
[0060]
定义待修复的汉字图像为c
c
,完整图像为c
t
,同一个字的宋体原型图像为c
p
,与c
c
具有相同风格的其他完整汉字图像为c
s
,c
c
和c
p
在通道维度上连接得到的图像向量为c
v
,使用风格编码器抽取的c
p
的风格编码为s
p
,c
s
的风格编码为s
s
,c
t
的风格编码为s
t
,则生成式对抗网络gan的损失函数可表示如下:
[0061][0062]
其中d
s
(c)是判别器,判别具有风格s的图像c是否是生成器生成的,g(c,s)表示这是生成器依据风格编码s对图像c进行修复后生成的结果。
[0063]
对抗损失函数(1)同时优化生成器和判别器的损失函数。生成器的目的是要生成的修复结果让判别器无法识别出来,哪一个是原来输入的,哪一个是生成出来的。而判别器的目标是尽可能识别出哪一张图片是生成器生成的,哪一张是原有的。这是一个相互对抗的过程,如图2所示。
[0064]
2)循环一致性损失函数。
[0065]
定义g(c
v
,s
s
)表示生成器依据风格编码s
s
对图像c
v
进行修复的结果,表示g(c
v
,s
s
)在通道维度上与c
p
连接得到的图像向量,循环一致性损失函数可表示如下:
[0066][0067]
其中c
v
,c
p
,s
s
,s
p
的含义同上所述,表示生成器依据原型字体的风格编码s
p
对图像向量进行反向复原的结果。
[0068]
循环一致性损失函数(2)的目标是优化生成器。如图3所示,过程中将受损的汉字图像向量和一个风格编码输入生成器中生成修复结果图像x。随后再将生成的修复结果x与原型字体连接后和原型字体的风格编码一起输入生成器中还原出一个宋体的图像y。计算还原出的宋体图像y和原型字体的逐像素误差,通过减少一致性损失来优化生成器。减少一致性损失可以避免生成器丢失文字图像的内容信息。
[0069]
3)文字结构一致性损失函数。
[0070]
定义s(c)表示使用预训练结构提取器抽取文字图像c的文字结构并以嵌入向量的形式输出,文字结构一致性损失函数(3)可表示如下:
[0071][0072]
其中c
v
,c
p
,s
s
的含义同上所述。g(c
v
,s
s
)表示生成器依据风格字体c
s
的风格编码s
s
对图像向量c
v
进行修复的结果,表示使用结构提取器从修复结果中提取结构嵌入向量,s(c
p
)表示从原型字体c
p
提取结构嵌入向量。
[0073]
文字结构一致性损失函数(3)的目标是优化生成器。如图4所示,结构提取器由多个残差块组成。将原型字体图像c
p
和生成器生成的修复结果图像分别输入残差神经网络中,计算输出的嵌入向量的均方误差损失,通过训练使损失函数趋近于零。则最后达到的效果为在嵌入层上,c
p
和具有一致的文字结构。这个损失函数(3)可以约束生成器在修复过程中不改变字体的原有结构,避免修复结果出现严重形变。
[0074]
4)风格编码重构损失函数。
[0075]
定义e(c)表示使用风格编码器提取文字图像c的风格编码,风格编码重构损失函数(4)可表示如下:
[0076][0077]
其中c
v
,c
s
,s
s
的含义同上所述,g(c
v
,s
s
)表示生成器依据风格字体c
s
的风格编码s
s
对图像向量c
v
进行修复的结果,e(g(c
v
,s
s
))表示使用风格编码器提取修复结果的风格编码。
[0078]
这个损失函数(4)同时用于优化生成器和风格编码器,将生成器生成的修复结果图像重新输入到风格编码器中,提取出修复结果的风格编码e(g(c
v
,s
s
)。计算风格字体的风格编码s
s
与修复结果的风格编码e(g(c
v
,s
s
)的平均绝对误差损失,目标是使该损失趋近于零。这个过程中既优化了风格编码器提取风格编码的准确性,也提高了生成器对风格编码的利用率,如图5。
[0079]
5)风格编码损失函数。
[0080][0081]
其中c
v
,s
s
,s
t
的含义同上所述,g(c
c
,s
t
)表示生成器参考目标图像c
t
的风格编码s
t
对缺损图像c
c
,进行修复的结果,g(c
c
,s
s
)表示生成器参考风格字体c
s
的风格编码c
s
对缺损图像c
c
,进行修复的结果。
[0082]
风格编码损失函数(5)用于优化风格编码器。对于同一张受损的文字图像c
c
,分别用该文字完整图像的风格编码s
t
和同一风格的其他文字图像的风格编码s
s
来引导生成器进行修复,分别得到修复结果g(c
c
,s
t
)和g(c
c
,s
s
),计算g(c
c
,s
t
)和g(c
c
,s
s
)平均绝对误差损失,并训练优化使该损失趋近于零。这个过程中保证了风格编码器对同一风格的字体总能提取出相同的风格编码。图6所示。
[0083]
6)目标平均绝对误差损失函数(6)。
[0084][0085]
其中c
v
,c
t
,s
s
,g(c
v
,s
s
)的含义同上所述。
[0086]
目标平均绝对误差损失函数(6)用于优化生成器。对于一个文字c,获得它的完整图像c
t
、受损后的图像c
c
和以宋体书写的原型图像c
p
,将c
c
和c
p
在通道维度上连接后得到图像向量c
v
,用生成器修复c
v
得到g(c
v
,s
s
)。g(c
v
,s
s
)与c
t
越相似,即说明修复效果越理想。g(c
v
,s
s
)与c
t
的相似程度通过计算这两张图像的逐像素平均绝对误差损失函数判断,在优化过程中使该损失趋近于零。该损失函数(6)保证了生成器的修复结果与目标结果在视觉上具有相似性。如图7所示。
[0087]
综上,模型的综合损失函数可表示如下:
[0088][0089]
根据实验结果,文字结构一致性损失函数(2)和目标平均绝对误差损失函数(6)对本发明方案提出的模型影响最明显,定义文字结构一致性损失函数(2)的权重为λ
str
,取值为10,定义目标平均绝对误差损失函数(6)的权重为λ
l1
,取值为10;风格编码损失函数(5)有较明显的作用,定义其权重为λ
enc
,取值为2;其他损失函数在共同作用下能产生一定影响,定义对抗损失函数(1)的权重为λ
adv
,循环一致性损失函数(2)的权重为λ
cyc
,风格编码重构损失函数(4)的权重为λ
sty
,取值均为1。
[0090]
本技术方案优势
[0091]
本方案最终可以在文字字体修复领域中,达到以下两种效果:
[0092]
1、可以在不提供图像受损部分掩模提示的前提下完成文字图像修复任务。由上述技术方案的介绍可知,由于本发明方案创新性地引入了原型字体和待修复字体两通道输入样本的方式,结合控制字型结构特征的结构提取器,采用本发明的文字字体修复方法不需要如传统现有方法需要依赖输入破损区域的具体信息。
[0093]
2、可以在文字图像修复的过程中兼顾字体的结构特征和风格特征,确保修复结果具有较好的可读性和视觉美观性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

