本发明属于时序数据处理技术领域,尤其涉及一种基于时序逻辑的大数据压缩方法及复盘播放方法。
背景技术:
传统的时序逻辑数据复盘是对所记录的时序过程的快照或线性录制,是一帧一帧的场景叠加,只能来回观看,无法根据自身兴趣选择观看的场景和角度,也无法利用记录内容开展科学全面的评估分析,大量的信息被舍弃和浪费,如文献1“宋祥斌,马鑫基于大数据的演练复盘及应用[j]《电子技术与软件工程》2019:170-171”所述。
现有时序数据复盘播放系统多采用直接读取时序数据进行展示的方式,如基于兵棋推演的海上攻防信息系统的复盘回放就是先将回放数据直接加载到客户端缓存中,通过读取客户端缓存中的数据进行复盘播放,如文献2“方雄利基于兵棋推演的海上攻防信息系统分析与研究[d]武汉工程大学2018”所述。该播放流程过于简单,在低密度、数据量较小的情况下能够正常运行,然而面对高密度的大量数据时不仅对硬件设备性能要求较高,而且播放流畅度也相形见绌。
时序大数据具有高密度、多对象和数据量大等特点,导致数据按时间查询、数据传输、对象渲染等方面的效率大大降低,给数据的复盘播放造成了较大的困难,因此一个适合播放流程的时序数据压缩方法必不可少。时序大数据由于采集时间间隔非常短,一般为0.1s,因此在整个数据集的时间跨度可以达到若干小时以上时,数据量会非常大。现有时序数据压缩方法有的处理数据结构相对简单,主要服务于节省数据库存储空间,如文献3“丁良,李在学,蔡富东,吕昌峰,陈雷,甘法刚一种时序数据的压缩方法、装置以及设备[p]:中国,cn201911421733.1”所述,无法满足多对象数据结构需求,有的数据编码方式相对复杂,如文献4“王建民,黄向东,乔嘉林,王晨,龙明盛一种自适应编码长度的时序数据存储的方法和装置[p]:中国,cn201711319331.1”所述,解码无法适应数据复盘播放时的快速、高效需求。
技术实现要素:
本发明要解决的技术问题是怎样快速、高效的提取时序大数据从而流畅的进行复盘播放,提供了一种基于时序逻辑的大数据压缩方法及复盘播放方法。
为解决该问题,本发明所采用的技术方案是:
一种基于时序逻辑的大数据压缩方法,所述大数据存储在关系型数据库中,所述大数据中的每个类为一张数据表,每张数据表中的字段包括有数据id、时刻、实体id以及类的各属性,包括以下步骤:
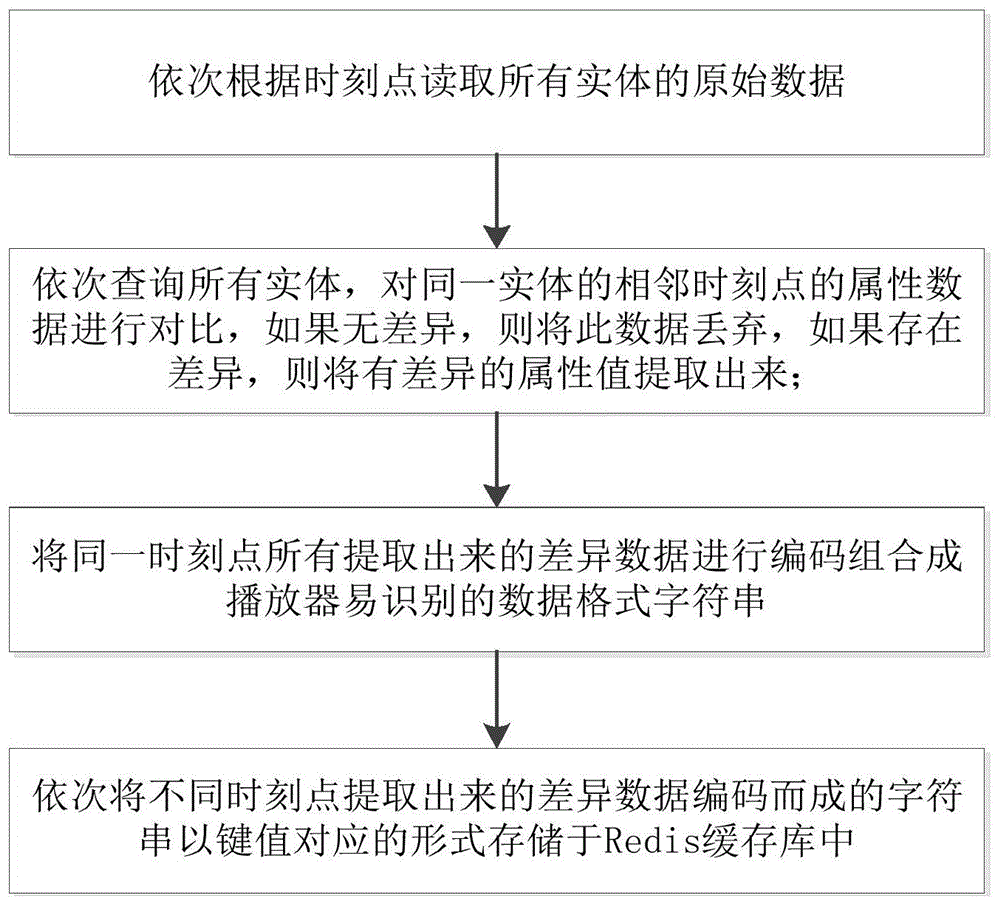
步骤1:依次根据时刻点读取所有实体的原始数据;
步骤2:依次查询所有实体,对同一实体的相邻时刻点的属性数据进行对比,如果无差异,则将此数据丢弃,如果存在差异,则将有差异的属性、属性值以及该实体的“实体id”提取出来;
步骤3:将同一时刻点所有提取出来的差异数据进行编码组合成播放器易识别的数据格式字符串,其中实体与实体之间采用自定义的符号间隔开来;
步骤4:依次将不同时刻点提取出来的差异数据编码而成的字符串以key-value的形式存储于redis缓存库中,其中key为该时间节点的时刻点,value为组合而成的播放器易识别数据。
进一步地,步骤1.3中所述自定义的符号为“&&”。
本发明还提供了一种计算机可读介质,存储有基于时序逻辑的大数据压缩方法的计算机程序,所述计算机程序可被处理器执行以实现前面所述的基于时序逻辑的大数据压缩方法的步骤。
本发明还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有基于时序逻辑的大数据压缩方法计算机程序,所述处理器执行所述计算机程序时实现前面所述基于时序逻辑的大数据压缩方法的步骤。
本发明还提供了一种基于时序逻辑的大数据复盘播放方法,所述大数据存储在关系型数据库中,包括以下步骤:
步骤1:数据准备阶段,从所述关系型数据库中提取原始时序数据,根据基于时序逻辑的大数据压缩方法对所述原始时序数据进行压缩,并将压缩后的数据存储于redis缓存库中;
步骤2:复盘播放时,客户端获取压缩缓存库中的压缩数据并存入客户端的缓存中;
步骤3:根据复盘播放器的播放条所处时刻,所述播放条所处时刻是指播放初始时刻或者拖拽后的时刻,从原始时序数据表中提取出播放条所处时刻点的原始数据进行渲染;
步骤4:根据当前时刻值从客户端缓存中获取压缩数据,提取出有变化的数据进行局部渲染。
进一步地,所述redis缓存库中的数据存储于内存中。
本发明还提供了一种计算机可读介质,存储有基于时序逻辑的大数据复盘播放方法的计算机程序,其特征在于,所述计算机程序可被处理器执行以实现前面所述的基于时序逻辑的大数据复盘播放方法的步骤。
本发明还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有基于时序逻辑的大数据复盘播放方法的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现前面所述基于时序逻辑的大数据复盘播放方法的步骤。
与现有技术相比,本发明所取得的有益效果是:
本发明基于时序逻辑的大数据压缩方法,针对于数据库中的数据在采集时时间间隔较小,同一实体相邻时间点之间存在着大量的重复数据,通过对比去掉同一实体中相邻时间点之间无变化的属性,实现了大数据的压缩。
本发明基于时序大数据的复盘播放方法,在原始时序数据使用压缩方法将视频大数据压缩后存储于内存中,读取速度将更快,复盘播放时,首先从mysql关系数据库的原始数据表中读取该初始时刻的原始数据,并进行渲染,同时客户端获取redis缓存库中的压缩数据,存入客户端的缓存中,当用户点击播放按钮开始复盘播放时,复盘播放器根据时间驱动器的时间值从客户端(本地)缓存中获取有变化的数据进行局部渲染。当用户拖动播放条调整播放进度时,同理复盘播放器首先会从mysql原始数据表中去读取拖动后初始时刻的原始数据重新进行整体渲染,然后根据时刻点从客户端缓存中获取有变化的数据进行局部渲染。该播放流程在复盘播放的初始时刻或者拖拉进度条的时候就已经将大部分的实体对象进行了构建,在播放的时候只需对属性值有变化的实体对象的该属性展现方式进行改变即可,节省了客户端的资源,并且提升了渲染速度。
附图说明
图1为时序数据压缩流程图;
图2为数据库部分数据表设计图;
图3为时序数据复盘播放流程图;
图4为redis缓存案例示意图。
具体实施方式
图1为本发明基于时序逻辑的大数据压缩方法的流程示意图,所述大数据存储在关系型数据库中,所述大数据中的每个类为一张数据表,每张数据表中的字段包括有数据id、时刻、实体id以及类的各属性,包括以下步骤:
步骤1:依次根据时刻点读取所有实体的原始数据;
步骤2:依次查询所有实体,对同一实体的相邻时刻点的属性数据进行对比,如果无差异,则将此数据丢弃,如果存在差异,则将有差异的属性、属性值以及该实体的“实体id”提取出来;
步骤3:将同一时刻点所有提取出来的差异数据进行编码组合成播放器易识别的数据格式字符串,其中实体与实体之间采用自定义的符号间隔开来;
步骤4:依次将不同时刻点提取出来的差异数据编码而成的字符串以key-value的形式存储于redis缓存库中,其中key为该时间节点的时刻点,value为组合而成的播放器易识别数据。
原始时序数据存储在关系型数据库中,本实施例中,原始时序数据存储在mysql关系型数据库中,数据库设计成一个类一张数据表,本实施例中,数据库中的数据表包括ctrack、carmorvehicle、cpersion等,每张数据表中的字段包括数据id、时刻、实体名字、实体id、位置以及该类属性等,具体设计如图2所示。“数据id”为每条数据的唯一标识,“时刻(simtime)”字段存储每条数据对应的时间节点,时间节点以时序数据集合的开始时间为计时起点,单位为秒(s),本实施例中同一实体的相邻数据间隔0.1s。“实体id”为区分同一个类中不同实体的标识,该表还包括位置、速度、状态等一些其它的类属性。从相邻数据间隔0.1s可以看出,数据采集采集时间间隔为0.1s,一般整个数据集的时间跨度可以达到若干小时以上,因此数据量会非常大,但是正由于数据采集时间间隔较小,所以同一实体相邻时间节点之间的数据重复率较大,每一个类表中属性数量较多,而大多数实体的大多数属性值变化频率较低,同一实体相邻时间点之间存在着大量的重复数据,根据以上时序数据的特点,该数据压缩方法采用同一实体相邻时间节点相对比,提取出有变化的属性和值进行编码的方式。通过轮询时间节点获取当前时间节点的所有实体原始数据和前一时间节点的所有实体原始数据,再通过轮询所有实体,对同一实体的当前属性数据和前一时间节点的属性数据进行对比,如果无差异,则可将此数据丢弃,如果存在差异,则将有差异的属性以及该实体的“实体id”提取出来。将该时间节点所有提取出来的差异数据进行编码组合成播放器易识别格式的字符串,其中实体与实体之间采用“&&”符号间隔开来,以key-value的形式存储于redis缓存库中,其中key为该时间节点的时刻值,value为组合而成的播放器易识别数据,实现数据的压缩。redis缓存样式如图4所示。
本发明还提供了一种计算机可读介质,存储有基于时序逻辑的大数据压缩方法的计算机程序,所述计算机程序可被处理器执行以实现前面所述的基于时序逻辑的大数据压缩方法的步骤。
本发明还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有基于时序逻辑的大数据压缩方法计算机程序,所述处理器执行所述计算机程序时实现前面所述基于时序逻辑的大数据压缩方法的步骤。
本实施例中给出了如表1所示拟压缩的部分原始数据,该数据的起始时间starttime为492.3s,结束时间endtime为757.8s,时间间隔为0.1s,固时间轮询次数为(endtime-starttime)*10,第i次轮询的时间节点currenttime为starttime i*0.1。通过currenttime从cpersion类原始数据表中获取当前时间节点的实体数据列表csoilderunitlistpersion_new以及前一时间节点的实体数据列表cpersion_old。通过轮询cpersion_new列表,查找出cpersion_old列表中与cpersion_new列表中“实体id”相同的数据进行比对,如果当前时间节点的该实体各属性值与前一时间节点该实体各属性值无差异,则将该实体数据丢弃,如果属性值存在差异,则将该实体的“实体id”和当前时间节点存在差异的属性(属性名和属性值)提取出来,按如下格式组合"muobjectid:110010328,msguarddirectionz:0.0,mecurrentweapontype:6619236,&&"。该时间节点的其它实体提取出来的“实体id”和差异属性均按格式组合后进行字符串拼接,拼接后字符串如下:
"muobjectid:110010328,msguarddirectionz:0.0,mecurrentweapontype:6619236,&&muobjectid:120010200,msguarddirectionx:-0.258199,msguarddirectiony:-0.966118,msvelocityvectorx:-0.258199,msvelocityvectory:-0.966118,&&muobjectid:120010202,msguarddirectionx:0.979355,msguarddirectiony:0.202028,msvelocityvectorx:0.979355,msvelocityvectory:0.202028,&&muobjectid:120010208,msguarddirectionx:-0.949687,msguarddirectiony:0.313298,msvelocityvectorx:-0.949687,msvelocityvectory:0.313298,&&"同一时间节点的不同实体之间使用"&&"符号进行间隔,便于复盘播放器解析时将该字符串分割成json数组格式。将之上拼接字符串作为value值存入redis缓存中,该value对应的key为当前时间节点currenttime的时刻值。当时间节点轮询结束后,所有的key-value压缩数据都已存入redis缓存中,数据压缩完成。
表1数据表中部分原始数据
本发明在压缩数据方法的基础上,提出了一种基于时序逻辑的大数据复盘播放方法,如图3所示,包括以下步骤:
步骤1:数据准备阶段,从所述关系型数据库中提取原始时序数据,根据前面描述的压缩方法对所述原始时序数据进行压缩,并将压缩后的数据存储于redis缓存库中;
本实施例将在数据准备阶段中将原始数据进行压缩,并将压缩后的数据存储于redis缓存库中,使用redis缓存即节省了复盘播放时服务器端的高sql语句消耗,而且由于redis数据存储于内存中,读取速度将更快,并且value的格式将全面适应播放器的解析播放功能,因此能够较大提升时序大数据的播放流畅度。
步骤2:复盘播放时,客户端获取压缩缓存库中的压缩数据并存入客户端的缓存中;
步骤3:根据复盘播放器的播放条所处时刻,从原始时序数据表中提取出播放条所处时刻点的原始数据进行渲染,所述播放条所处时刻是指播放初始时刻或者拖拽后的时刻;
步骤4:根据当前时刻值从客户端缓存中获取压缩数据进行解析,提取出有变化的数据进行局部渲染。
复盘播放的主要功能在客户端实现,复盘播放器首先从mysql原始数据表中读取播放条所处时刻点的原始数据,并进行渲染,客户端获取redis缓存中的压缩数据,存入客户端的缓存中以备播放使用,客户点击播放按钮开始复盘播放时,根据播放条所处时刻点从客户端本地缓存中读取压缩数据进行解析,获取有变化的数据进行局部渲染。
因此本发明的播放方法,可以根据用户拖动播放条调整播放进度,该播放流程在复盘播放的初始时刻或者拖拉进度条的时候就已经将大部分的实体对象进行了构建,在播放的时候只需对属性值有变化的实体对象的该属性展现方式进行改变即可,节省了客户端的资源,并且提升了渲染速度。
使用所述复盘播放方法能将复盘播放预加载时间缩短2到5倍,将客户端性能消耗降低4到8倍。复盘播放流程中使用redis缓存技术,提升了预加载时获取服务器播放数据的速度。该数据压缩技术能将原始数据的大小最少降低一个数量级,数据量的缩小不仅提升了预加载时间,而且大量减少了客户端的渲染工作量,降低了客户端的性能消耗。
本发明还提供了一种计算机可读介质,存储有基于时序逻辑的大数据复盘播放方法的计算机程序,其特征在于,所述计算机程序可被处理器执行以实现前面所述的基于时序逻辑的大数据复盘播放方法的步骤。
本发明还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有基于时序逻辑的大数据复盘播放方法的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现前面所述基于时序逻辑的大数据复盘播放方法的步骤。
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。