本发明涉及存内计算技术领域,特别是涉及一种基于4管存储的存储单元、存储阵列及存内计算装置。
背景技术:
深度卷积神经网络(dcnns)继续证明推理精度的提高,深度学习正在向边缘计算转移。这一发展推动了低资源机器学习算法及其加速硬件的工作。dcnns中最常见的运算是乘法和累加(mac),它控制着功率和延迟。mac操作具有很高的规则性和并行性,因此非常适合硬件加速。然而,内存访问量严重限制了传统数字加速器的能源效率。因此,内存计算(imc)对dcnn加速越来越有吸引力。
现在的存算阵列基本都基于六管或者更多管的存储单元,mac操作分为基于电阻分压器、放电率等的电流域计算和基于电荷共享、电容分压器等的电荷域计算两种。相比而言电荷域计算由于没有静态电流,所以功耗更低。而六管结构面积更大,功耗也更大。
技术实现要素:
基于此,本发明的目的是提供一种基于4管存储的存储单元、存储阵列及存内计算装置,提高了计算精度。
为实现上述目的,本发明提供了如下方案:
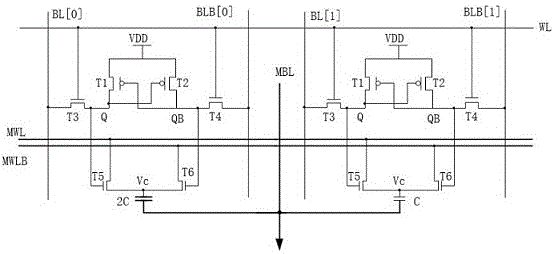
一种基于4管存储的存储单元,所述存储单元包括:第一存储子单元、第二存储子单元、位线bl、位线blb、字线wl、字线mwl、字线mwlb、位线mbl、第一电容和第二电容;
所述第一存储子单元和所述第二存储子单元均包括管t1、管t2、管t3、管t4、管t5和管t6;所述第一存储子单元与所述第二存储子单元的结构相同;
所述管t1的源极和所述管t2的源极均连接vdd电源;所述管t1的栅极分别与所述管t2管的漏极、所述管t4的第一极和所述管t6的栅极连接,所述管t2的栅极分别与所述管t1管的漏极、所述管t3的第一极和所述管t5的栅极连接,所述管t5的第一极与所述字线mwl连接,所述管t6的第一极与所述字线mwlb连接;所述管t4的栅极与所述字线wl连接,所述管t3的栅极与所述字线wl连接,所述管t3的第二极与所述位线bl连接,所述管t4的第二极与所述位线blb连接,所述管t5的第二极和所述管t6的第二极均与电容连接端连接;
所述第一存储子单元的电容连接端与所述第一电容的第一端连接,所述第二存储子单元的电容连接端与所述第二电容的第一端连接,所述第一电容的第二端和所述第二电容的第二端均与所述位线mbl连接;所述第一电容的容量和所述第二电容的容量不同。
可选地,所述第一电容的容量是所述第二电容的容量的两倍。
本发明还公开了一种存储阵列,所述存储阵列包括矩阵式排列的多个所述的基于4管存储的存储单元;
各行所述基于4管存储的存储单元中,各所述管t5的第一极均与所述字线mwl连接,各所述管t6的第一极均与所述字线mwlb连接,各所述管t3的栅极均与所述字线wl连接,各所述管t4的栅极均与所述字线wl连接;
各列所述基于4管存储的存储单元中,各所述管t3的第二极均与所述位线bl连接,各所述管t4的第二极均与所述位线blb连接,各所述第一电容的第二端均与所述位线mbl连接。
可选地,所述存储阵列为128行存储单元,64列存储单元。
本发明还公开了一种存内计算装置,所述存内计算装置包括所述的存储阵列,用于接收输入激活信号,累加位线mbl上的电压;
所述存内计算装置还包括:
激活驱动模块,分别与字线mwl和字线mwlb连接,用于输入激活信号;
列译码模块,分别与位线bl和位线blb连接;
行译码模块,与字线wl连接。
可选地,所述存内计算装置还包括,输出模块,与所述位线mbl连接。
可选地,所述输出模块包括模数转换器,用于将所述模拟电压转换为数字信号后输出,所述模数转换器与所述位线mbl一一对应设置。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明公开了一种基于4管存储的存储单元、存储阵列及存内计算装置,通过4管存储单元,减小了存储单元的面积,通过第一电容的容量和第二电容的容量不同,实现2位的存储权重,提高了计算精度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种基于4管存储的存储单元结构示意图;
图2为本发明一种存内计算装置结构示意图;
图3为本发明乘累加操作数表。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种基于4管存储的存储单元、存储阵列及存内计算装置,提高了计算精度。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1为本发明一种基于4管存储的存储单元结构示意图,如图1所示,一种基于4管存储的存储单元,所述存储单元包括:第一存储子单元、第二存储子单元、位线bl、位线blb、字线wl、字线mwl、字线mwlb、位线mbl、第一电容和第二电容。
所述第一存储子单元和所述第二存储子单元均包括管t1、管t2、管t3、管t4、管t5和管t6;所述第一存储子单元与所述第二存储子单元的结构相同;
所述管t1的源极和所述管t2的源极均连接vdd电源;所述管t1的栅极分别与所述管t2的漏极、所述管t4的第一极和所述管t6的栅极连接,所述管t2的栅极分别与所述管t1的漏极、所述管t3的第一极和所述管t5的栅极连接,所述管t5的第一极与所述字线mwl连接,所述管t6的第一极与所述字线mwlb连接;所述管t4的栅极与所述字线wl连接,所述管t3的栅极与所述字线wl连接,所述管t3的第二极与所述位线bl连接,所述管t4的第二极与所述位线blb连接,所述管t5的第二极和所述管t6的第二极均与电容连接端vc连接。所述管t3的第一极为权重存储点q,所述管t4的第一极为权重存储点qb。
所述第一存储子单元的电容连接端与所述第一电容的第一端连接,所述第二存储子单元的电容连接端与所述第二电容的第一端连接,所述第一电容的第二端和所述第二电容的第二端均与所述位线mbl连接;所述第一电容的容量和所述第二电容的容量不同。
可选地,所述第一电容的容量是所述第二电容的容量的两倍。
本发明还公开了一种存储阵列,如图2所示,所述存储阵列包括矩阵式排列的多个所述的基于4管存储的存储单元;
各行所述基于4管存储的存储单元中,各所述管t5的第一极均与所述字线mwl连接,各所述管t6的第一极均与所述字线mwlb连接,各所述管t3的栅极均与所述字线wl连接,各所述管t4的栅极均与所述字线wl连接;
各列所述基于4管存储的存储单元中,各所述管t3的第二极均与所述位线bl连接,各所述管t4的第二极均与所述位线blb连接,各所述第一电容的第二端均与所述位线mbl连接。
可选地,所述存储阵列为128行存储单元,64列存储单元。
如图2所示,本发明一种存内计算装置,所述存内计算装置包括所述的存储阵列,用于接收输入激活信号,累加位线mbl上的电压;
所述存内计算装置还包括:
激活驱动模块,分别与字线mwl和字线mwlb连接,用于输入激活信号;
列译码模块,分别与位线bl和位线blb连接;
行译码模块,与字线wl连接。
可选地,所述存内计算装置还包括,输出模块,与所述位线mbl连接。
可选地,所述输出模块包括模数转换器,所述模数转换器与所述位线mbl一一对应设置。
本发明具体实施中,图2的存内计算装置为sram(staticrandom-accessmemory静态随机存取存储器)imc宏的体系结构,包括存储阵列①、存储单元的读写操作(r/w)中的行译码模块(r/waddressdecoder)③、存储单元的读写操作(r/w)中的列译码模块(r/wblcontrol)②、存算结构的输入激活驱动模块(mwldecoder/driver)④和包含模数转换器(adc)的输出模块⑤。其中行译码模块对存储阵列字线wl(i)进行选取,列译码模块对位线bl(i)及位线blb(i)进行作用,位线bl(i)和位线blb(i)信号相反,输入激活信号作用于mbl(i),mbl(i)再传输到adc输出。
存储阵列中每行的二进制乘累加(bmac)操作的位线输出mbl是一列乘累加计算的和,mbl端是模拟信号,为了数字化这些值,阵列每列包含一个adc。模数转换器adc对乘累加位线mbl(i)信号进行模数转换。
行译码模块③译码后输出wl[i]信号对阵列①的设定行进行选中,列译码模块②输出bl[i]和blb[i]对阵列的设定列进行选中,列译码模块②和行译码模块③实现的是位单元中权值的读写;输入激活驱动模块④对输入激活信号译码后输出128组mwl信号,mwl信号包括mwl[i]和mwlb[i],mwl信号连接到存储阵列①的每一行;存储阵列①中每列的输出信号mbl[i]连接到输出模块⑤,输出模块⑤中的相应列的adc完成最后的结果输出。
存内计算装置是针对神经网络提出的结构,其工作原理是在存储单元中将输入激活信号和存储权值进行乘累加操作。本发明涉及的存内计算装置使用电荷共享来执行二进制乘累加(bmac)。
如图1所示,存储阵列中的位单元(bitcell)包括左(存储权重为高位)右(存储权重为低位)两部分,每部分由4管(管t1、管t2、管t3、管t4)的基本存储结构外加电容和两个导通晶体管(管t5、管t6)组成,第一部分电容2c的大小是第二部分电容c的两倍。
在位单元中第一电容和第二电容由mac字线(mwl/mwlb)通过管t5、管t6选通之后充放电,而管t5和管t6这两个晶体管由存储的权重(q、qb)选择导通。左边高位部分第一电容(2c)的电容是右边低位部分第二电容(c)的电容的两倍,所产生的电压乘累加结果也是两倍,两部分的电荷被放在同一位线mbl上按列共享,由此就实现了1位输入与2位权重的计算。bmac分两步:第一步预充电,mwl(i)、mwlb(i)、mbl(i)同时充电至vrst(中间电平),第一电容和第二电容两边均没有电压电势;第二步充电关闭,输入驱动将输入激活信号传输到mwl(i)/mwlb(i),输入激活信号与权重同或的结果与mbl在电容两端形成电压差从而在位线mbl上产生电荷积累;第三步mbl通过adc进行模数转换后输出结果。
图3为乘累加操作数表,图3中以mwl和mwlb的电平高低组合来表示输入(input)的数值,输入为1时mwl端电压为vdr(0.8v),mwlb为0v,输入为0时mwl端电压为0v,mwlb为vdr(0.8v),输入为0时,mwl与mwlb都为vrst(0.4v);位单元两部分所存权重中,q为1(vdd)时第一部分cell(2c)权重值为2,第二部分cell(c)权重值为1,q为0(0)时第一部分cell(2c)权重值为-2,第二部分cell(c)权重值为-1;mbl(value)为第一部分cell(2c)权重值乘以输入与第二部分cell(c)权重值乘以输入的和。
本发明中,存内计算装置中的基本存储模块采用4管单元,优化了阵列结构减小了阵列面积;2位的存储权重,提高了计算精度;内存计算装置的计算过程通过电容耦合电荷域完成,没有静态电流,降低了功耗且电容耦合机制拥有更好的稳定性。因此,整个装置相较现有技术有更小的面积,更高的精度,更好的稳定性。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。