1.本发明涉及公交车到站时间预测领域,具体涉及一种面向有缺失数据的公交车到站时间预测方法,用于对出发时间不确定、gps设备有问题等有数据缺失情况的公交线路提供准确的到站时间预测。
背景技术:
2.公交车网络对快速发展的城市交通至关重要,由于经济,环保等特点,目前公交车仍是城市出行的主要方案。阻碍乘客选择公交的主要因素是其漫长的等待时间和旅程时间的不确定性,因此准确预测公交车的到站时间对于解决这个问题非常重要。它还可以帮助减少交通拥堵,并被用于其他的综合智能交通应用,如行程规划。
3.现有的公交车到达或旅行时间预测方法,依赖大量的历史旅行记录和公共交通路线的广泛覆盖。因此,现有方法无法或难以准确预测有数据缺失的公交车到站时间,其原因主要包括:1) 数据稀疏性:对于预测郊区(记录稀少)和正在考虑和设计(没有记录)的交通路线的旅行时间预测,主要问题是它们有大量的缺失数据,无法从历史记录中学习到准确的运行模式,从而无法预测到站时间;2)独立的旅行模式:从空间角度看,为扩大服务覆盖面积,城市公交网络中的公交线路不会有过多重复和重叠,导致公交线路之间难以互相学习运行模式。即使部分站点共享同一道路的部分,由于需求不同,乘客数量的不同,停车的顺序和位置不同,交通网络中的路线具有相对不同和独立的旅行模式;3)复杂的交通状况:公共交通线路的旅行模式比私人车辆更复杂,因为它们也有独特的交通信息。除了受到道路长度、方向和交互数字的影响外,公共交通线路还受到出发时间安排、数量和停靠地点的影响。
4.因此,对于具有历史数据缺失的公交车到站时间预测方法的提出是必要且重要的。
技术实现要素:
5.为了解决对有数据缺失问题的公交车到达时间预测的问题,本发明提供一种面向有缺失数据的公交车到站时间预测方法,该方法可以准确有效地学习和预测公共交通网络中每条路径的旅行时间,不仅能提高当前旅行记录少的公交线路的到达时间预测准确率,还可以对没有历史记录的处于设计阶段的公交线路提供预计旅行时间。
6.本发明的技术方案如下:本发明提供了一种面向有缺失数据的公交车到站时间预测方法,其包括如下步骤:1)将历史公交车运行轨迹gps信息、公共交通站点位置信息与城市兴趣点数据(数据信息包含建筑经纬度和建筑城市功能分类信息)进行数据整合;通过基于密度的聚类方
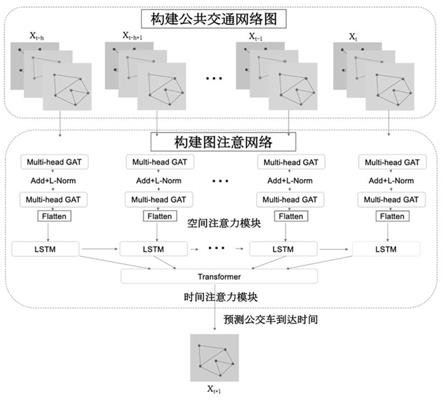
法从整合后的数据中提取公交网络中重要的地理位置,利用得到的地理位置来表示每条公交路线的地理结构,进行公共交通网络图的节点抽取和边抽取,构建公共交通网络图;2)根据构建的公共交通网络图,建立多头时空图注意力网络预测模型从空间和时间的角度学习公交路线之间的相关性;其中,所述的多头时空图注意力网络预测模型包括顺次连接的空间注意力模块和时间注意力模块;所述空间注意力模块为多头具有掩码的图注意力网络的注意力模块,其应用图注意网络来学习不同节点之间的空间依赖关系,并利用带有掩码的多头图注意块学习不同情况下公交线路之间的全局和局部空间依赖关系;所述时间注意力模块包括一个lstm层和一个transformer层,分别用于进行局部时间依赖学习和全局时间依赖学习;3)利用多头时空图注意力网络预测模型,对具有缺失数据的公交车到站时间进行预测。
7.进一步的,所述的通过基于密度的聚类方法从整合后的数据中提取公交网络中重要的地理位置,具体为:根据整合后的数据中速度为0的gps点的数量来设置基于密度的聚类方法的参数,通过基于密度的聚类方法得到公交网络中重要的地理位置,并根据每个地理位置包含的gps点的数量来确定地理位置的权重。
8.进一步的,所述的利用得到的重要的地理位置来表示每条路线的地理结构,具体为:用权重来表现交叉口和站点的位置,以代表每条公交路线的地理结构。
9.进一步的,所述的节点抽取具体为:在每条公交路线的每两个相邻站点之间选择一个地理位置,将两个站点信息和其之间的被选择的地理位置信息集合作为节点s的信息,以代表两个相邻站点之间的路段。
10.进一步的,所述的每两个相邻站点之间选择一个地理位置构成节点信息,具体为:选择公交路线中,与两个相邻站点位置距离最远,且人流量最大的交叉口,将该交叉口信息与两个相邻站点的地理位置信息一起构成节点信息。
11.进一步的,所述的边抽取具体为:建立边图来代表路段之间的关系,其中,边上编码的权重是空间相关性强度或相似性;构建三个分别表示地理结构相似度关系、公交路线之间的距离关系、城市功能区域划分关系的邻接矩阵a,得到三种表示不同关系的公共交通网络图。
12.优选的,所述邻接矩阵a的构建方法,具体为:建立地理结构相似关系边图,根据提取的节点包含的三个重要地理位置信息,提取出节点的位置信息、节点长度信息,利用dtw算法做相似度比较,建立节点之间的地理结构相似邻接矩阵a
g
;然后,根据每个节点中三个地理位置附近的城市兴趣点数据中包含的建筑类别信息,提取每个节点的城市功能类别,根据城市功能的相似度,建立节点之间的城市功能区域划分关系邻接矩阵a
f
;最后,根据公交路线之间的距离关系,设计了第三种地理距离邻接矩阵a
d
;邻接矩阵中边的权重经过归一化处理,范围在0到1之间。
13.进一步的,所述的步骤3)具体为:对具有缺乏数据的公交线路,利用多头时空图注意力网络预测模型并根据公交车运行模式的相似度,学习前h个时间段内具有完整历史数据的公交车运行模式;继而预测具有缺乏数据的公交线路的公交车到站时间。
14.与现有技术相比,本发明根据每条公共交通线路的地理结构与线路之间的空间
‑
时间依赖关系,利用基于密度聚类方法来定位路线中的重要旅行地点(如车站、交叉口);根据挖掘的重要旅行地点,构建一个具有交通重要性的有权重的公共交通网络图。基于构建的交通网络图,提供了一个多注意图神经网络,从空间和时间的角度学习公交路线之间的相关性。在空间注意力模块中,建立了多头具有掩码的图注意力网络的注意力模块(multi
‑
head gat),可以学习全局和局部路线在城市功能,路线距离,公交结构相似度三种视图上的重要性,并有效地结合多种影响因素来组合学习的旅行模式。在时间注意力模块中,提出用长短期记忆(lstm)和transformer层来学习较远和最近时间的公交运行模式。结合空间和时间注意力模块,准确推断和学习具有稀疏和无历史数据的公交路线的旅行(到达)时间。本发明不仅能提高当前旅行记录少的公交线路的到达时间的预测准确率,还可以对没有历史记录的处于设计阶段的线路提供预计的站与站之间的旅行时间。
附图说明
15.图1为面向有缺失数据的公交车到站时间预测方法的流程图;图2为本发明实施例中基于密度的聚类方法的伪代码示意图;图3为本发明实施例中选择站点之间的地理位置方法的伪代码示意图;图4为本发明方法与对比实验方法的实验结果图。
具体实施方式
16.下面结合具体实施方式对本发明做进一步阐述和说明。
17.本发明方法的流程图如图1所示,其由两个主要部分组成,分别是公共交通网络图构建和基于多头注意力图网络模型的构建。首先,将历史公交车运行轨迹gps信息、公共交通站点位置信息与城市兴趣点数据(poi)数据整合,然后本发明提出了一种基于密度的聚类方法来自动发现重要地理位置(包括站点和交叉口),并利用挖掘的地理位置来表示每条路线的地理结构;根据地理结构相似度(如公交站点之间的距离,十字路口数量)、公交路线之间的距离,和城市功能区域划分,构建三种公共交通网络图。根据构建的公共交通网络图,本发明建立多头时空图注意力网络预测模型,包括空间和时间注意力模块来预测到站时间。在空间注意力模块中,本发明设计一个带有掩码的多头图注意块,以学习不同情况下公交线路之间的全局和局部空间依赖关系。多头机制对拥有完整历史旅行记录的相邻公交线路段的旅行时间进行了集合学习。通过设计的掩码机制,对不同邻居公交线路段组成的加权相邻矩阵进行屏蔽,注意力区块可以集中在选定的邻居上,并减少计算时间。例如,当目标路线的不稳定历史记录很少时,其自身的输入历史旅行时间就有必要被忽略。在时间注意力模块中,为了准确模拟不同条件下以往历史数据的时间影响(如交通拥堵和天气条件下的正常和异常情况),本发明通过一个lstm层和一个transformer层构建了一个时间注意力模块,以获得全局(远距离)和局部(最近)的时间模式,用于旅行时间预测。通过时空注意力,可以学习前h个时间段内具有完整历史数据的公交车运行模式(x
t
‑
h
,
…
,x
t
);根据运行模式的相似度,对具有缺乏历史数据的公交车进行到站时间x
t 1
预测。
18.以下对本发明的公共交通网络图构建和多注意力图网络的预测模型的构建进行展开说明。
19.一、公共交通网络图的构建
由于公共交通的结构通常由一连串相连的路段或站点表示,现有的基于网格的地图分割对旅行时间的预测不起作用。于是,通过考虑公共交通的空间和时间特征,本发明从一个新的图形视图中构建了一个交通网络g,并提出了一种基于密度的聚类方法(dbscan)来自动发现重要的地理位置(站点和交叉口),并利用得到的地理位置来表示每条路线的地理结构(geo
‑
structure)。然后,基于发现的公交路线的地理结构,本发明构建了公共交通网络g,其中g中的节点s代表每两个相邻站点之间的旅行段。
20.(1)基于dbscan的公共交通地理结构挖掘首先,本发明利用基于密度的聚类算法(dbscan)来提取公共交通的地理结构,包括叉路口和站点的准确位置和密度。过程不直接使用标记的车站信息,而是从dbscan算法中提取位置,原因有二:首先,由于提出的旅行段是基于站点的,存在两条路线有相同的站点,但有不同的路径的情况。因此,只用车站的位置来提取路线的地理结构是不准确的。其次,每个车站和路口的等待时间通常受到乘客数量和交通信号灯的影响,这可能导致不同路线的旅行时间有很大的差异。所以,本发明通过基于密度的聚类方法(dbscan),寻找密集区域(geo
‑
structure discovery),不需要设定集群数量或固定形状,具体步骤如图2所示(algorithm 1)图2中,gps点p包含经度和纬度信息(long, lat),c是经过算法聚类后得出的公交网络中的重要点,包含经度,纬度,gps数量和站点信息(long,lat,num,st)。基于密度的聚类算法需要两个参数:扫描半径eps和最小点数minpts,参数根据数据库中速度值在0左右的gps点的数量来设置,以找到沿途的所有重要地理位置,包括车站和交叉口。然后,根据每个挖掘出的地理位置范围内gps数量来确定站点和交叉口的权重。
21.(2)公共交通网络图的节点抽取和边抽取2.1)节点抽取在提取了公交网络的重要地理位置后,本发明提出了一种节点信息表示方法,方法设计首先在每条公交路线的每两个相邻站点之间选择一个重要地理位置,由两个站点信息和之间的重要地理位置信息的集合作为节点s的信息,以代表从一个站点到下一个站点的旅行段。选择站点之间的地理位置方法如图3(algorithm 2)所示。图3中,步骤3遍历所有从dbscan中得到的聚类c的集合,步骤4
‑
6中,在相邻的两个拥有站点的c中,找到与站点位置距离最远,且人流量最大的c
i 1
作为s中的信息之一,步骤7集合两个站点和c
i 1
作为s的信息。
22.2.2)邻接矩阵(边)建立本发明根据节点的信息建立边图来代表路段(节点)之间的关系。由于许多影响因素会影响公交系统的出行模式,本发明构建了三个邻接矩阵a来表示不同的关系。首先建立地理结构相似关系边图,根据提取的节点包含的三个重要地理位置信息,提取出路段(节点)的位置信息,路段长度信息,利用dtw算法做相似度比较,建立节点之间的地理结构相似邻接矩阵a
g
;然后,根据每个节点中三个位置附近的城市兴趣点数据中包含的建筑类别信息(设置为节点经纬度半径范围100米距离内的建筑城市功能类别信息集合),提取每个路段(节点)的城市功能类别,根据城市功能的相似度,建立节点之间的城市功能区域划分关系邻接矩阵a
f
;最后,由于在一定空间地理范围内,道路上的交通情况可能比较相似。根据这一考量,本发明根据公交路线之间的距离关系,设计了第三种地理距离邻接矩阵a
d
。邻接矩阵中边的权重本发明设计经过归一化处理,范围在0到1之间。
23.二、多头时空图注意力网络预测模型构建在构建公交网络图后,本发明提出了多头时空图注意力网络预测模型,用于利用有限的数据预测整个城市的公交车旅行时间。这个模型可以有效地学习和预测全市范围内各条公交线路的行驶时间,特别是对于郊区的线路和没有任何历史公交行驶记录的路径。它可以帮助更新现有的公共交通系统,调整发展中地区线路的过时时间表,并帮助选择新的线路和设计新的线路,提供正常和非正常交通条件下每条线路的旅行时间。这个模型包含两个模块,即空间注意力模块和时间注意力模块。
24.2.1)空间注意力模块在空间注意力模块中,本发明应用图注意网络(gat)来学习不同旅行段之间的空间依赖关系。与图卷积网络(gcn)相比,gat的动态图处理能力和归纳学习能力更适合在数据有限的情况下进行城市范围内的旅行时间预测。图关注层是gat的基础部分,它可以学习每节点之间的相关性,并更新每对节点的隐藏特征。节点特征在时间间隔t中表示为h
ti
。在第一层,h
ti
是s
i
段的输入旅行时间记录和嵌入的时间信息。s
i
和s
j
的注意系数e
tij
可以表示为:其中w是l层的可学习参数,a(.)是计算相关性的函数。本发明利用leakyrelu主动函数来训练前馈神经网络。对于每一层,通过softmax函数将输出归一化为[0,1]:为了获得更丰富的旅行模式组合,用于有缺失数据的公交车线路准确学习具有完整历史数据的公交线路运行模式,本发明将空间注意扩展为有掩码的多头注意机制,其由具有可学习的k个独立注意力头被串联起来以达到最终的空间注意力结果:其中σ为softmax函数。在每个注意力头中,本发明对邻接矩阵加入掩码注意力机制,用于关注具有完整历史运行数据的公交线路,并学习运行模式。掩码m在l层的表示为:其中γ为节点i和节点j的注意力a的阈值,对l层加了掩码后的x输出表示为:其中x为公交运行时间的输入数据,x’为加入注意力机制后的输出,x
l’为在掩码机制加入后第l层的输出,am为邻接矩阵于掩码矩阵的hadamard乘积。
[0025]
2.2)时间注意力模块在学习空间依赖性后,本发明连接一个时间注意力模块。由于每个公交车行程的旅行时间受实时交通状况的影响很大。例如,当交通状况正常时,目标路线同一时间段的以
往远距离历史记录在当前时间段的行驶时间可能高度相似。然而,当交通拥堵发生时,旅行模式可能是不稳定的,但仍然可能与最近的时间段有类似的模式。因此,对于不同的交通状况,全局(远时间)和局部(最近)的时间旅行模式都需要考虑。
[0026]
2.2.1局部时间依赖学习递归神经网络(rnn)是一种人工神经网络,特别适合捕捉序列学习中的时间依赖性。然而,以前的研究表明,由于梯度消失和爆炸的问题,rnn通常很难训练长序列。为了克服这些缺点,lstm(long short
‑
term memory)通过引入一个输入门和一个遗忘门来自动确定最佳时间滞后。因此,本发明建立了一个基于lstm的模型来关注局部时间信息,其中h
t
‑1是lstm单元的输入向量,w
ix
, w
ih
和b
i
是递归层的可学习参数矩阵和偏置向量,σ标准sigmoid函数。lstm的输入门i
t
可以表示为:。
[0027]
2.2.2 全局时间依赖学习为了从全局角度发现时间上的公交旅行模式信息,本发明在时间注意力模块中引入了transformer层。对于单头注意力层,对于公共交通网络图中的每个节点通常有三种类型的向量q,查询k、键和值v。隐藏子空间学习过程可以表述为:w
q
, w
k
, w
v
为科学系参数,全局时间注意力的输出attention是根据缩放的点积注意力计算的,,其中d
k
为缩放因子,表示为:。
[0028]
2.3)公交到达时间预测层当得到高维时空特征后,本发明使用线性层进行预测。通过最小化期望输出的预测值x’t 1
和真实值之间的均方误差l来训练预测x
t 1
,使用均方误差(mse)损失来训练多头时空图注意力网络预测模型,可以表述为:其中是模型中的可学习参数。
[0029]
在本发明方法的实验验证环节,本发明使用了公交车轨迹和poi信息,这些数据都是从某城市的交通部门获得的。公交车轨迹包括位置、时间戳、速度和公交车id信息。平均采样频率为每点30秒,每天的数量为278条单独线路产生的约30万个点。poi数据集由建筑位置和类别(社会功能)组成。使用交叉验证法,选择三条线路作为目标线路,以评估本本发明方法的性能和稳健性。本发明选择的三条测试公交线路位于城市的不同区域,其中包括发达的中心区域、偏远地区以及连接中心和郊区的路径。然后对结果进行平均。在三条测试公交线路的每条轨迹中随机删除40%、60%和80%的gps记录点,以测试不同程度的记录稀少的线路的预测精度。本发明还删除了它们的所有历史记录,将其视为三条正在设计中的路线(没有任何历史旅行时间记录),以测试新路线的旅行时间估计性能(站点位置和路径是设计好的),这有助于评估所提出的模型,此处将本发明方法取名为magtte。
[0030]
对比实验方法:
历史平均模型(ha)。通过计算每个时间段(15分钟)内公交线路的历史平均行驶时间来预测行驶时间。
[0031]
空间
‑
时间人工神经网络(st
‑
ann)。
[0032]
卡尔曼滤波(kf)。
[0033]
支持向量回归(svr)。
[0034]
e
‑
knn:这是一个基于加权增强的k
‑
nn方法提出的模型,它使用与当前交通状况最相似的k条记录来识别交通状况并预测出行时间。在这里,将出行模式的相似度设定为90/%以上,目标路段为k个邻居。
[0035]
rnntte:该模型基于lstm神经网络,包含一个具有128个隐藏单元的全连接lstm层。
[0036]
deeptte :这是一个模型结合了geo
‑
conv层和lstm层来预测旅行时间。
[0037]
实验结果如图4所示,结果表明,在设计过程中,本发明方法在旅行时间预测问题领域的表现优于现有的其他先进的方法,无论是稀疏的记录还是路线。它证明了所提出的magtte能够有效地预测整个城市的公共交通出行时间,mape错误率最小,并用于更新和发展公共交通路径。
[0038]
上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明的保护范围应以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。