本发明属于地理信息数据和交通数据挖掘应用领域,主要是利用土地利用信息数据模拟道路交通流量的方法。
背景技术:
对路网交通流量进行全面动态流量模拟,不仅可以识别路网交通运行状况,也可以为后续交通管控和排放治理提供数据支撑。
传统方法是通过交通监测设备,如磁感线圈和视频摄像头等,获取路段的交通流量和路段速度。然而由于上述设备能够采集的交通数据在路网的覆盖范围有限因而无法刻画全路网交通流特征。近年来,车车通信(vehicle-to-vehicle,v2v)和车路协同(vehicle-to-infrastructure,v2i)技术(如射频识别技术,radio-frequencyidentification,rfid)不断发展,虽然这些智能交通通信技术能够极大的提升获取的交通流数据的多样性以及准确性,然而其高于传统设备的安装费用使其目前仅能在一些发达城市的核心区域逐步推广应用还难以覆盖到区域乃至全国范围。
为了获取包含城际间道路的全路网的交通流量信息,以往研究往往采用参数分配或者交通模型的方法。参数分配方法中,车队活动水平通常是最为常用的分配参数。国内研究中主要是通过将将不同车型的年均行驶里程(vehiclekilometertravel,vkt)分配到路段层面,再结合以市/县为单位的分车型机动车保有量计算了全国路网层面的车辆活动水平,然而这样的分配方法往往无法反映研究范围下最小划分行政单位内部交通流量的空间差异。美国的研究将美国年均行驶里程数据库(annualaveragedailytraffic,aadt)基于道路类型进行拆分,这种拆分方法相较于国内的年均vkt更能反应道路车流的时空分配特征,但是仍然存在部分问题:首先aadt数据的收集往往仅收集部分道路的样本流量数据(samplepanel)从而代替整个片区的完整流量(fullextent);其次由于aadt数据的上报也是以州为单位,因而也不可避免地使用一些经验分配。上述两种分配方式的结果都不可避免地造成了其与实际道路交通流量空间分布特征的差异。此外由于交通分配参数都是以年为单位统计的,因而在时间分辨率上仅仅能够反映年际之间的空间分布差异,难以反映更为细致的时间分布特征从而无法用于对短期交通管控措施(如京津冀区域重污染时期的交通管控措施)的精准评估。传统的交通需求模型包括交通平衡模型、交通流密度模型。交通需求模型主要基于od出行矩阵等对方法对路网交通流进行仿真模拟,但是由于这些模型往往要求模拟路网复杂性不高且连通性完整,同时需要对模拟区域的出行特征进行调研或假设,加之模拟过程耗费时间较多,因而应用范围主要集中在某段道路的以及城市的部分核心区域骨干路网的交通流特征模拟,难以在较大的城市乃至区域路网上应用。
此外,上述模型方法采用的交通流数据库在应用上还面临这着计算量巨大、难以实时处理的问题,难以适应未来对多源数据融合、实时传输及处理的需求。针对传统区域路网交通模拟方法存在的计算效率低、时空精度低等问题,本专利研究构建了基于土地利用的机器学习模型实现区域骨干路网交通流特征和污染排放的动态分析,兼具科学性和对大数据实时化处理的适应性,且建模方法迁移能力强,是目前一种理想的模拟交通流时空分布特征的方法。
技术实现要素:
本发明的目的是提供一种基于土地利用信息的路网交通流模拟方法,通过本方法可以基于部分路段采集流量对全路网交通流进行模拟,从而刻画区域路网交通变化时空分布特征,并可以对路网交通运行状况进行评估。
本发明技术方案一种基于土地利用信息的路网交通流量动态模拟方法,实现该方法的主要步骤为:
步骤1,收集区域内路网部分路段交通流信息,这里称具有交通流量的部分路段为路段集a,没有交通流量的路段成为路段集b,主要包括:分车型的道路流量及路段速度。
步骤2,收集路网所有路段(包括路段集a和b)土地利用信息,土地利用信息需要包括人口密度、道路密度以及距离交通枢纽(机场、货运中心)的距离等可能会影响交通流变化的变量。将这些土地利用信息根据自身特征整理为不同的预测变量。
步骤3,利用随机森林模型在路段集a上建立道路土地利用信息和路段交通流量之间的关系。
随机森林是一种集成多棵决策树训练及预测结果的分类器,其主要原理是通过训练一批决策树从而利用所有决策树预测结果的平均值(回归问题)或多数结果(分类问题)作为随机森林的预测结果。随机森林的构建方法如下:
(1)从m个预测变量中选取m个预测变量作为一棵决策树的预测变量。通常而言,对于分类问题,m为m的平方根;对于回归问题,m为m的三分之一;
(2)从n个观测值中通过有放回随机采样(bootstrap)的方法构建的等同于样本个数的观测值作为一棵决策树的训练集,该训练集中的预测值数目约为n的三分之二,剩下的三分之一被称为袋外观测值(outofbagobservation,oobobervation)作为后续随机森林的测试集从而评估其误差;
(3)每棵树完整分类不进行剪枝,通过确定最后一个节点分裂后的观测值数量,即最小叶片数,来结束分类。
由于在上述构建方法中对于观测值选取和预测变量的选取都是随机的,因此避免在训练过程中产生的过拟合问题,同时由于每次拟合都是部分的预测变量和观测值,因此随机森林对缺失值不敏感,有着较好的抗噪能力。本研究中构建的随机森林包含300棵决策树,最小叶片数为5。
步骤4,将收集的路段集a上的路段流量数据随机平均划分成十个测试集,每次采用其中九组数据作为训练集进行建模,剩下的一组数据作为测试集,遍历十组数据后,每组数据都会成为一次测试集,采用十折交叉验证(ten-foldcrossvalidation)来验证基于土地利用信息的流量模拟模型的准确性。
步骤5,基于上述模型识别在交通流模拟过程中最重要的预测变量。利用随机森林模型对区域交通流进行逐小时模拟从而获取区域交通流的时间变化特征,并计算通过随机置换预测变量观测值导致袋外误差率变化来说明各预测变量在模拟各交通流特征的重要性。其主要计算原理如下式所示:
其中,vriij为预测变量xi在第j棵树上的变量相对重要性(variablerelativeimportance);oobj为第j棵树上袋外观测值数目;yk为第k个袋外观测值的真实结果;yk1j为预测变量xi置换观测值前第j棵树对第k个袋外观测值的预测结果;yk2j为预测变量xi置换观测值后第j棵树对第k个袋外观测值的预测结果;i(x)为指示函数,相等为1,不相等为0。特别地,若xi没有在第j棵树的建模过程中出现,则vriij为0。由此,预测变量xi在整个随机森林中vrii的计算方法如下:
其中,n为随机森林树木总量。vrii越大,预测变量xi在随机森林预测重型要性越高。
步骤6,利用步骤3建立的土地利用信息到道路流量的映射关系和步骤2收集的没有交通流信息路段土地利用信息,模拟整个区域其他路段交通流量信息。
为了基于部分道路监测流量获取全路网的交通流量信息,目前的研究主要采用参数分配或者交通模型的方法。
参数分配方法通常是利用车队活动水平或燃油消耗量分配到路段层面,再结合以市/县为单位的分车型机动车保有量计算了全国路网层面的车辆活动水平,然而这样的分配方法往往无法反映研究范围下最小划分行政单位内部交通流量的空间差异。美国的相关研究将美国年均行驶里程数据库(annualaveragedailytraffic,aadt)基于道路类型进行拆分,这种拆分方法相较于国内活动水平或燃油消耗的拆分方法更能反应道路车流的时空分配特征,但是仍然存在部分问题:首先aadt数据的收集往往仅收集部分道路的样本流量数据(samplepanel)从而代替整个片区的完整流量(fullextent);其次由于aadt数据的上报也是以州为单位,因而也不可避免地使用一些经验分配。国内外的基于参数的分配方式的结果都不可避免地造成了其与实际道路交通流量空间分布特征的差异。此外由于交通分配参数都是以年为单位统计的,因而在时间分辨率上仅仅能够反映年际之间的空间分布差异,难以反映更为细致的时间分布特征从而无法用于对短期交通管控措施(如京津冀区域重污染时期的交通管控措施)的精准评估。
交通需求模型方法是指利用包括交通平衡模型、交通流密度模型在内的交通模型对流量进行模拟。交通需求模型主要基于od(orientation-destination)出行矩阵等对方法对路网交通流进行仿真模拟,但是由于这些模型往往要求模拟路网复杂性不高且连通性完整,同时需要对模拟区域的出行特征进行调研或假设,加之模拟过程耗费时间较多,因而应用范围主要集中在某段道路的以及城市的部分核心区域骨干路网的交通流特征模拟,难以在较大的城市乃至区域路网上应用。
本发明使用的基于土地利用信息的交通流量模拟方法,利用土地利用信息的高分辨率动态模拟路网交通流特征,从而克服了传统参数分配方法导致的时空分辨率不足、结果误差大的问题;另一方面,通过引入随机森林模型进行模拟,从而不再需要进行复杂交通需求调研,有效提升了模拟的效率,由于土地利用信息的高覆盖率也讲模拟边界从城市内部拓展到城市区域乃至全国层面。
附图说明
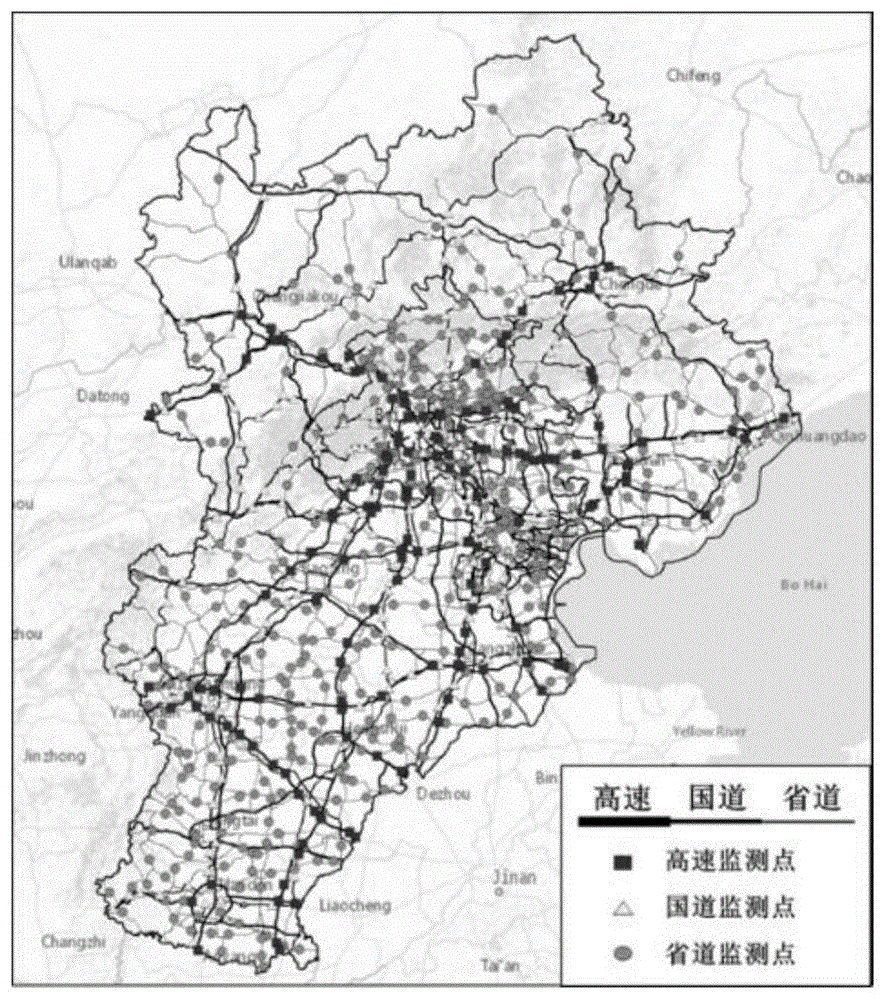
附图1京津冀监测站点位置示意图。
附图2京津冀站点小时交通流箱式分布图。
附图3不同情景下京津冀区域机动车逐小时分车型活动水平变化。
具体实施方式
为了使本技术领域的人员更好地理解本发明,下面将结合本发明实施例中的附图,以京津冀地区路网交通流模拟为例说明对本发明实施例中的技术方案进行清楚、完整地描述。
步骤1,收集区域路网有监测站点的数据信息,以京津冀为例,站点位置信息如附图1所示,采集的交通信息主要包括站点监测获得的分车型(包括中小型客车、大型客车、轻型货车、中型货车和重型货车)路段流量以及路段速度(典型车型流量和速度变化如附图2所示)。
步骤2,收集道路周围用地信息,选取的预测变量包括了人口密度、道路密度以及距离交通枢纽(机场、货运中心)的距离等可能会影响交通流变化的变量。表1列出了本研究选取的用于训练基于土地利用模型的预测变量。
从变量格式上来分,可以分为点变量和缓冲区变量,点变量是指从路段中点提取出的地理信息;缓冲区变量是指以路段中点为中心画出不同半径的缓冲区,通过计算缓冲区内单位面积的地理信息来表征该半径缓冲区下的地理信息。从变量内容上来分,主要可以分为土地利用类型相关和道路信息相关,土地利用类型相关变量主要包括了土地利用类型、兴趣点(pointofinterest,poi)、距离变量以及人口密度等共计139个预测变量。土地利用类型参考了清华大学宫鹏课题组的研究成果,其利用随机森林模型,将收集到的2015年的分辨率为30m的全球用地类型数据与哨兵2号(sentinel2)采集到的分辨率为10m的全球影像相匹配,从而生成了2017年分辨率为10m的全球用地类型数据库。基于该数据库信息,根据本研究划分的不同缓冲区提取计算各缓冲区内单位面积的用地类型面积。poi信息来自高德地图,高德开放平台提供多种应用程序编程接口(applicationprogramminginterface,api),其中包括搜索服务api,可以实现poi信息的查询功能,研究基于该api的查询结果将poi分为十种并提取计算其在各缓冲区内单位面积的poi数目。距离变量是通过计算路段中点到各相应poi的欧式距离得到的。人口数据来自世界人口数据库(worldpop)[139],其利用随机森林的方法估计了单位像素点(peopleperpixel,ppp)和单位公顷(peopleperhectare,pph)的人口,从而构建了分辨率为100m的人口数据集,基于联合国(unitednation,un)公布的人口数据对估计的人口数据集进行了以国家单位的总量约束。道路信息相关变量主要包括了道路种类、道路周围其他道路密度、道路设计信息(道路车道数和设计时速)以及路段位置信息(经纬度及所在的行政区划)等共计11个预测变量。道路信息相关变量主要来自于北京四维图新科技股份有限公司开发的中国电子导航地图(chinadigitalroad-networkmap,cdrm),本研究中区域骨干路网包含京津冀区域内18824km高速、8989km国道和22847km省道。
表1预测变量种类
注:#为缓冲区变量,本研究中每个变量缓冲区半径设置为50m,100m,200m,300m,500m,1000m,2000m和5000m。
步骤3,利用通过参数比选,构建本研究采用的随机森林包含300棵决策树,最小叶片数为5。
步骤4,采用十折交叉法验证模型准确性。选取皮尔逊相关系数(pearsonr),均方根误差(rootmeansquarederror,rmse)和平均绝对误差(meanabsolutepredictionerror,mape)作为评估测试集中模拟值和观测值之间的差异的统计指标,其计算公式分别为:
最后模拟结果如表2所示
表2交叉验证结果
步骤5,进一步利用随机森林模型对区域交通流进行逐小时模拟从而获取区域交通流的时间变化特征,并计算通过随机置换预测变量观测值导致袋外误差率变化来说明各预测变量在模拟各交通流特征的重要性。其主要计算原理如下式所示:
其中,vriij为预测变量xi在第j棵树上的变量相对重要性(variablerelativeimportance);oobj为第j棵树上袋外观测值数目;yk为第k个袋外观测值的真实结果;yk1j为预测变量xi置换观测值前第j棵树对第k个袋外观测值的预测结果;yk2j为预测变量xi置换观测值后第j棵树对第k个袋外观测值的预测结果;i(x)为指示函数,相等为1,不相等为0。特别地,若xi没有在第j棵树的建模过程中出现,则vriij为0。由此,预测变量xi在整个随机森林中vrii的计算方法如下:
其中,n为随机森林树木总量。vrii越大,预测变量xi在随机森林预测重型要性越高。
基于随机森林逐小时模拟结果,对每个小时的变量重要性进行排序,将典型工作日全天24小时的变量排名平均值作为该预测变量的重要性指数。表3列出了典型工作日模型中各个模拟变量下最重要的十个预测变量及其24小时变量排名的平均值,整体而言,相比于用地类型相关的预测变量(如用地类型、poi等),与道路信息相关的预测变量(如道路种类、道路密度、车道数等)在模拟交通流特征时重要性更为凸显。特别地,在重型货车流量模拟的过程中,最重要的十个预测变量全部都是和道路地理信息相关的预测变量。对于客车车队(中小型客车和大型客车)和轻型货车车队(轻型货车和中型货车)而言,仍然有部分较为重要的预测变量是与用地类型相关的,如人口和poi等。较为重要的与用地类型相关的变量缓冲区半径都较大(一般为2000m和5000m),这主要是因为城际的交通流监测点通常位于高速公路而远离市区,缓冲区较小的范围内人口和poi信息较为缺乏,从而导致其对预测结果的影响不显著。
表3预测交通流特征过程中最重要的十个预测变量
步骤6,根据交通流数据采集的时间段,对于京津冀区域路网研究主要设置如下三种模拟情景:
(1)典型工作日情景,该情景下的逐小时交通流特征为收集到的1月、4月、7月和11月各一周中的工作日逐小时交通流特征的平均;
(2)典型节假日情景,该情景下的逐小时交通流特征为收集到的1月、4月、7月和11月各一周中的节假日逐小时交通流特征的平均;
(3)重污染情景,为2017年11月4日至2017年11月7日京津冀区域遭受的重污染时间段,该时间段内京津冀区域大气污染传输通道,即“2 26”个城市于4日启动了重污染橙色预警,与交通领域相关的主要应急措施包括:国i和国ii排放标准轻型汽油车、建筑垃圾、渣土、砂石等货运车辆禁止上路行驶;列入橙色预警期间工业企业停产限产名单企业实施停产限产措施等。
建立了2017年京津冀区域骨干路网高分辨率交通流数据库,解析了京津冀骨干路网交通流时空分布特征。工作日情景下区域骨干路网机动车活动水平总量为8.41亿车公里(vehkm),与节假日情景下总量为9.31亿车公里的车辆活动水平相比下降了10%。从车队构成来看,小型客车活动水平削减占总削减约70%,除小型客车外,重型货车和轻型货车工作日活动水平的削减分别贡献了总活动水平削减的16%和10%。重污染时期区域路网整体车辆活动水平相比于典型工作日削减了23%,控制措施在北京的效果最为明显,北京整体交通流活动水平相比于典型工作日削减了29%,中型货车和重型货车的削减尤为明显,削减比例分别为42%和52%;相比之下,河北交通流活动水平的削减主要来源于小型客车,相比典型工作日削减比例为27%,中型货车和重型货车仅分别削减了5%和14%。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。