本发明涉及一种语音转换方法及系统,尤其是基于特征解耦的多因素可控的语音转换方法及系统。
背景技术:
语音转换技术指的是在不改变语义信息的基础上,转化源说话人的发言使其听起来像是目标说话人说出的一样。语音转换在许多领域应用广泛,包括生成各种表达性的语音转换器,唱歌的新语音效果和跨语言的配音等。同时,语音转换对语音分析、语音合成、说话人识别等其它领域有重要的促进作用。
目前已有的语音转换系统仅从语音信号中解耦出说话人的音色信息和以文本信息为主的剩余信息,转换因素单一,不能转换韵律、音调等,难以满足对于语音交互的表现力多样性的需求。
现有技术中,有一种基于非平行语料的语音转换,由于其训练数据获取难度低、应用场景多而受到了更多的关注,如何利用非平行语料进行训练并实现语音转换的可大致分为构造平行语料和特征解耦两个思路,其中构造平行语料的方法转换后的音频仍然保留源说话人的韵律特征,与目标说话人的相似度不高;基于特征解耦的方法广泛采用的是由编码器和解码器组成的自编码器架构,将语音信号中的文本内容与说话人信息分离开,在训练时使用重建损失约束也即让解码器的输出与编码器的输入越接近越好,在转换时将说话人信息替换为目标说话人的表征,并且会采用对抗训练的说话人分类器来使得文本表征尽可能少地含有说话人信息以提高解耦程度。
但这些方法存在如下缺点:
1)韵律转换效果差。传统方法的韵律信息混杂在说话人信息或是文本信息中,转换后的音频的韵律信息在源说话人与目标说话人二者的韵律信息间滑动,合成音频的自然度低。
2)提取的语音特征不鲁棒。特征提取器本身设计的不完备性以及粗糙的解耦手段导致提取出的特征间的解耦程度有限。
3)可控性低。传统方法多只能实现音色的转换,无法实现其他副语言因子(节奏、音调)可控的语音生成。
4)对齐特性差。目前对于声学特征序列与文本信息序列、节奏序列、基频序列的对齐仅采用简单的填充机制,将短序列均以0值填充到最长序列的长度,导致合成音频的后半段存在发音混乱等现象。
技术实现要素:
本发明的目的是为了解决现有技术中的问题,提出一种基于特征解耦的多因素可控的语音转换方法及系统,提高转换效果,提升鲁棒性、可控性和对齐特性。
为解决上述技术问题,本发明提出一种基于特征解耦的多因素可控的语音转换方法,包括如下步骤:s1、从音频信号中提取出不同的语音表征,其中包括韵律信息;s2、采用mask-and-predict解码方法利用对抗训练进一步解耦提取出的语音表征;s3、从解耦程度高的语音表征中预测声学特征,并利用声码器进行音频合成。
在一些实施例中,还包括如下特征:
步骤s1中所述不同的语音表征包括如下语音因子:音色表征、文本表征、节奏表征、基频表征,对不同的语音因子,分配相应的编码器。
对不同的编码器施以不同的信息瓶颈限制各编码器的编码能力。
所述限制包括:限制一、4个编码器的输入不相同,有的是音频,有的只是基频曲线;限制二、对4个编码器的输出在维度上进行限制;限制三、在音高和文本的提取上,加入了随机重采样这一操作来破坏节奏信息。
采取了以下方法中的至少一者提高语音表征学习的效果,以提升步骤s1中的提取效果:方法一、通过多标签二维向量限制节奏编码只能为离散化表征,当采取离散编码时,建模空间有限,节奏编码器会优先编码可以恢复出完整音频的节奏信息;方法二、采用词预测网络从文本表征中预测一个二值的、与词典等大的指示向量,向量的每一维度值为0或1指示该段音频中是否包含对应的词,通过这种显式的损失函数引导,文本编码器会倾向于编码出更有效的文本信息;方法三、采用预训练好的说话人编码器从特定音频中提取对应说话人的表征,从而实现不要求说话人在训练时见过,可实现向集外目标说话人的转换。
步骤s2中,通过降低各语音特征间的互信息以增大提取出的各语音特征间的解耦程度。
采取mask-and-predict解码方法来提供显式的正交性保证,训练过程中,随机选取某一个语音因子,将其对应的表征向量置为0,然后用剩余的语音表征来预测被抹掉的这一个;而在反向传播过程中,梯度通过梯度反转层进行反转,从而使得预测得越不准确。
步骤s3中,在训练时,各语音表征是从同一段音频中提取的,解码器的输出越接近输入越好,将编码器的输入替换成目标因素的来源音频,即可实现多因素可控的语音转换。
步骤s3中,采用注意力机制进行动态对齐以解决不同来源的语音表征序列的对齐问题;并施加单调性限制降低转换后音频的错字、漏字问题。
本发明还提出一种基于特征解耦的多因素可控的语音转换方法及系统,包括处理器和存储器,所述存储器中存储有计算机程序,所述计算机程序可被处理器执行以实现如上所述的方法。
与现有技术相比,本发明的有益效果有:本发明将韵律信息从音频信号中提取出来,而不是混杂在文本、说话人信息内,实现对韵律更精准的控制,降低韵律转换的不确定性。除可转换音色说话人音色外,还可以实现向任意来源的节奏、基频进行转换,因而可控性更高。
附图说明
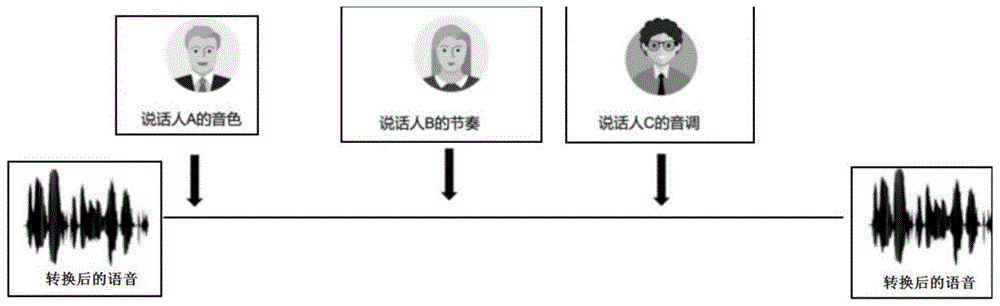
图1为本发明实施例多因素可控的语音转换系统概略示意图。
图2为本发明实施例基于特征解耦的多因素可控的语音转换系统框架示意图。
图3为本发明实施例编码器分别对不同的信息进行编码得到对应的表征的示意图。
图4为本发明实施例mask-and-predict提高解耦程度示意图。
图5为本发明实施例多因素可控的语音转换示意图。
具体实施方式
语音信号包含了丰富的信息,包括语言信息、说话人特征、情感、韵律、节奏等等。本发明人认识到,由于包含韵律、情感、音调、节奏等信息的副语言信息的高度耦合性导致语音生成时的可控性低,解耦程度高的语音因子是实现多因素可控语音转换、提高转换语音的质量和相似度的前提,同时也可提升下游任务的性能。其中转换语音的质量评价指标包含主、客观指标,客观是有mcd(melcepstraldistortion),主观包括需要听者来对合成音频的质量、与目标说话人音色的相似度、与目标说话人的风格相似度等进行打分。
本发明下述实施例主要涉及到音色、音调和节奏三方面的转换,如图1所示,是本发明实施例的多因素可控的语音转换系统概略示意图,其主要框架参考图如图2所示,该语音转换框架主要由三部分组成,第一部分是从音频信号中提取出不同的语音表征;第二部分是采用mask-and-predict(一种解码方法)的思想利用对抗训练进一步解耦提取出的语音表征;第三部分是从解耦程度高的语音表征中预测声学特征,并利用声码器进行音频合成。
相比之前的方法,本发明实施例有以下几点优势:
1)提高韵律转换的效果。将韵律信息从音频信号中提取出来,而不是混杂在文本、说话人信息内,实现对韵律更精准的控制,降低韵律转换的不确定性。
2)提取的特征更为鲁棒。通过mask-and-predict操作,对从特征提取器提取出的互信息高的表征进行了更为显式的正交化处理,提高特征提取的鲁棒性。
3)可控性更高。除可转换音色说话人音色外,还可以实现向任意来源的节奏、基频进行转换。
4)更好的对齐特性。通过引入attention机制(attention机制为大家广泛应应用于不同长度序列之间的对齐,即为下文提到的“梅尔谱序列与文本序列、节奏序列、基频序列的分别对齐”),实现梅尔谱序列(即decoder的输出,也即预测出声学特征,梅尔普会输入到声码器来进行音频的合成)与文本序列、节奏序列、基频序列的分别对齐,减少合成音频中出现的错误,提高合成音频的质量。
具体方法描述如下:
1、语音表征学习
为了提取出多种不同的语音因子(例如音色表征、文本表征、节奏表征、基频表征等),需要给不同的编码器(编码器与上述语音因子相对应,对上述因子分别编码)施以不同的信息瓶颈限制各编码器的编码能力,这些限制包括:首先4个编码器的输入不相同,有的是音频,有的只是基频曲线;其次4个编码器的输出在维度上进行了限制,限制在比较小的数值;最后,在音高和文本的提取上,加入了随机重采样这一操作来破坏节奏信息,如图3所示。图3是4个编码器分别对不同的信息进行编码,得到对应的表征的示意图。这主要是基于这一假设:即当编码能力有限时,各编码器会优先编码在其他地方无法编码的信息。
本发明采取了以下几种方法提高语音表征学习的效果:
一是通过多标签二维向量限制节奏编码只能为离散化表征,因为节奏编码器的输入是完整的音频信息,如果不加任何限制,节奏编码器会将音频中的所有信息进行编码以获取最好的音频重建效果,当采取离散编码时,建模空间有限,节奏编码器会优先编码可以恢复出完整音频的节奏信息。
二是采用词预测网络从文本表征中预测一个二值的、与词典等大的指示向量,向量的每一维度值为0或1指示该段音频中是否包含对应的词,通过这种显式的损失函数引导,文本编码器会倾向于编码出更有效的文本信息。
三是采用预训练好的说话人编码器从特定音频中提取对应说话人的表征,这就不要求说话人在训练时见过,可实现向集外目标说话人的转换。
通过以上方法,各编码器可学习到不同语音因子的表征。
2、语音表征解耦的对抗学习
由于第一步中仅是将各语音表征因子提取出来(如音色表征、文本表征、节奏表征、基频表征),并未施加任何正交性限制,故这些表征因子间的耦合程度很高,导致转换的音频质量下降,因为不同信息如文本和音色会掺杂在一起,当替换其中某一种时,会造成合成时信息的混乱,进一步降低合成的音频的质量。因此通过降低各语音特征间的互信息以增大提取出的各语音特征间的解耦程度,本发明主要采取mask-and-predict的思想来提供显式的正交性保证。但与bert等模型中使用的mask-and-predict操作不同,我们不是使用相邻帧的特征来预测某一帧的特征,而是在同一帧的不同特征之间进行mask和predict;且在mask-and-predict操作之后,我们增加了梯度反转层将梯度回传到自编码器结构中。如图4所示。训练过程中,会随机选取某一个语音因素(或称语音因子,包括音色表征、文本表征、节奏表征、基频表征中的任意一种),将其对应的表征向量置为0,然后用剩余的语音表征来预测被mask掉(置为0即表示对应的信息被抹掉,需要从其他特征中预测)的这一个,这个预测网络会预测得越准确越好,而在反向传播过程中,梯度会通过梯度反转层进行反转,从而使得预测得越不准确。预测的准确度越低就说明剩余表征无法预测出被mask掉的那个表征,即被mask掉的表征与剩余表征间的互信息越少,解耦程度就越高。
3、基于解耦语音表征的语音转换
在训练时,各语音表征是从同一段音频中提取的,解码器的输出越接近输入越好,将编码器的输入(如图2或图5所示)替换成目标因素(即想要转换的某一因素,如音色、基频、节奏等)的来源音频,即可实现多因素可控的语音转换,如图5所示。
为了解决不同来源的语音表征序列的对齐问题,本发明采用注意力机制进行动态对齐,并施加单调性限制降低转换后音频的错字、漏字问题。由于在训练过程中使用的是重建损失进行约束,各序列是同一来源,也就不存在不同长度序列的对齐问题,而在测试时由于不同说话人、不同音频的差异,节奏序列、基频序列、文本序列等序列长度不等,简单的填补机制无法保证合成高质量的音频,而注意力机制在各序列间进行自动的对齐,单调性限制了注意力的对齐特性,减少合成的漏字、错字问题,提高了合成音频的质量。
本发明上述实施例技术方案带来的有益效果可以归纳为:
1、实现了一个可控性更高的语音转换框架(如图5),可转换任意来源的声音的音色、节奏、基频等。
2、提取到的特征鲁棒性强,降低了对特征提取器提取精度的依赖。现有技术中的特征提取器对于维度等非常敏感,也即这个维度大一点或者小一点都会造成提取的特征不纯、相互之间耦合程度高,而这里我们的mask-and-predict模块能够进一步提高这些特征的解耦程度,即使在提取器比较粗糙的情况下仍可得到耦和程度低的表征。
3、提高了韵律转换的效果,实现对韵律更精准的控制,降低韵律转换的不确定性。与现有的方法相比较,现有的方法不能实现韵律的控制或者是比较粗糙的控制,而这里我们将节奏、基频特征分离开来,就可以实现单独的转换,实现更精细的控制。
4、能够更好地对齐不同来源的语音因素序列,提高转换后音频的质量。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

