本发明涉及语音播报领域,特别涉及一种语音播报系统。
背景技术:
随着经济和科技的不断发展,社会各个领域竞争愈发激烈,许多企业纷纷加大研发力度、建立相关实验室来提高自身的竞争力。细胞室也属于实验室的一个重要分支,在细胞室不仅有需要珍贵的工作设备,还存放着大量的实验细胞样本。对细胞室内部的报警信息进行语音播报使得工作人员第一时间知道是非常必要的,目前,细胞室内部的语音播报设备在播报报警信息时,预先必须录制音频文件,形式单一,如果某一个报警文字发生改变,需要重新录制,不能够智能化的调节音量、音色,使得工作人员在嘈杂的环境中无法听清。
技术实现要素:
本发明旨在至少一定程度上解决上述技术中的技术问题之一。为此,本发明的目的在于提出了一种语音播报系统,通过获取报警信息声学参数,根据声学参数生成语音文件进行播报,解决了报警信息如果某一个报警文字发生改变,需要重新录制的问题。
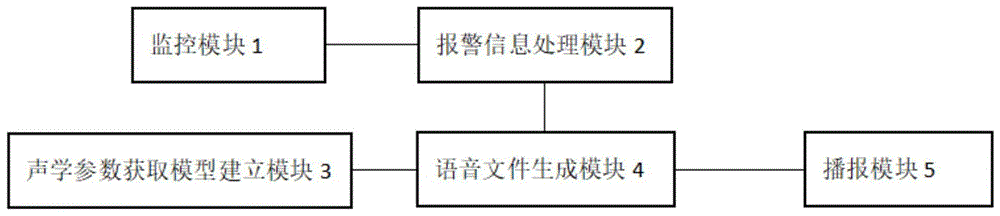
一种语音播报系统,包括:
监控模块,用于对所述细胞室进行监控,在确定细胞室内发生异常时生成报警信息;
报警信息处理模块,与所述监控模块连接,用于:
接收所述监控模块发送的报警信息,根据所述报警信息确定报警类型;所述报警类型包括开关报警类型以及模拟量报警类型;在确定所述报警信息为模拟量报警类型时,根据预设转换规则,将所述报警信息转换为文本信息;
声学参数获取模型建立模块,用于建立声学参数获取模型;
语音文件生成模块,分别与所述报警信息处理模块、声学参数获取模型建立模块连接,用于:
接收所述报警信息处理模块发送的文本信息;
将所述文本信息输入声学参数获取模型中,输出声学参数,将所述声学参数进行语音合成,得到第一语音文件;
播报模块,与所述语音文件生成模块连接,用于接收所述语音文件生成模块发送的第一语音文件并进行语音播报。
进一步地,所述声学参数获取模型建立模块,包括:
标注模块,用于获取样本声音数据,对所述样本声音数据进行声音标注前端处理,得到样本文本信息;
特征获取模块,与所述标注模块连接,用于接收所述标注模块发送的样本文本信息,对所述样本文本信息进行特征提取,提取所述样本文本信息的基频的声学特征和频谱的声学特征;
模型生成模块,与所述特征获取模块连接,用于接收所述特征获取模块发送的所述样本文本信息的基频的声学特征和频谱的声学特征,对所述样本文本信息的基频的声学特征和频谱的声学特征基于马尔可夫模型的参数聚类和训练,生成声学参数获取模型。
进一步地,所述在确定所述报警信息为模拟量报警类型时,根据预设转换规则,将所述报警信息转换为文本信息,包括:
获取所述模拟量报警类型包括的模拟量类型及模拟量数值,根据所述模拟量类型查询预设模拟量类型-标准数值表,得到所述模拟量类型相对应的标准数值,计算所述标准数值与所述模拟量数值的差值,根据所述差值生成文本信息。
进一步地,所述的语音播报系统,还包括:
语音信号采集模块,用于采集所述细胞室内部工作人员发出的语音信号;
声纹特征提取模块,与所述语音信号采集模块连接,用于接收所述语音信号采集模块发送的语音信号,将所述语音信号输入预先训练好的声纹特征提取模型中,输出声纹特征;所述声纹特征提取模型为通过样本语音信号与所述样本语音信号对应的声纹特征通过训练得到的神经网络模型;
第一控制模块,分别与所述语音信号采集模块、声纹特征提取模块连接,用于:
接收声纹特征提取模块发送的声纹特征,将所述声纹特征分别与若干个预设声纹特征数据进行匹配,计算得到若干个匹配度,筛选出最大匹配度,判断所述最大匹配度是否大于预设匹配度;
在确定所述最大匹配度大于预设匹配度时,接收所述语音信号采集模块发送的语音信号,提取所述语音信号中的内容信息,根据所述内容信息生成第一文本,获取预设文本数据库中与所述第一文本关联度最大的第二文本,根据预设词向量数据库得到所述第二文本的文本向量;
对所述第一文本进行分词处理,得到若干个分词,根据预设词向量数据库分别得到每个分词的词向量;
根据所述文本向量分别确定每个词向量的向量权重,根据每个词向量的向量权重对所述第一文本的分词的顺序进行调整,得到目标文本;
提取所述目标文本的特征信息,获取与所述特征信息相对应的决策树;所述决策树包括非叶子节点集合与叶子节点集合;
将所述目标文本输入决策树中的非叶子节点集合包括的第一个非叶子节点中,输出语义识别结果,获取所述语义识别结果的可信度,判断所述可信度是否大于预设可信度,在确定所述可信度大于预设可信度时,将所述语义识别结果作为目标语义识别结果;
根据所述目标语义识别结果在所述对话数据库中查找对话内容,并将所述对话内容转换为第二语音文件,控制所述播报模块对所述第二语音文件进行语音播报,同时,判断所述目标语义识别结果是否为控制指令,在确定所述目标语义识别结果为控制指令时,控制所述细胞室内部的设备执行。
进一步地,所述的语音播报系统,还包括:
声音信号采集模块,用于在所述播报模块播报第一语音文件前,采集所述细胞室内部的声音信号;
第二控制模块,分别与所述播报模块、声音信号采集模块连接,用于:
接收所述声音信号采集模块发送的声音信号,根据所述声音信号得到声音时域信号;
对所述声音信号进行快速傅里叶变换,得到声音频域信号;在快速傅里叶变换时,对所述声音信号变换区间的长度为预设长度;
计算所述声音频域信号在所述变换区间内的平方和;
根据所述变换区间的长度及所述平方和计算得到所述声音时域信号的能量和,根据所述能量和计算得到所述声音时域信号的声压级,判断所述声压级是否小于预设声压级,在确定所述声压级小于预设声压级时,控制所述播报模块根据预设音量播报所述第一语音文件;
反之,查询预设声压级-第一目标音量表,得到与所述声压级相对应的第一目标音量,对所述第一目标音量进行特征提取,提取所述第一目标音量对应的第一电频响曲线,并提取所述第一电频响曲线的低频部分与高频部分;
查询预设声压级-伴音功率余量表,得到与所述声压级相对应的伴音功率余量;
根据所述伴音功率余量对所述第一电频响曲线的低频部分与高频部分进行补偿处理,得到第二电频响曲线,根据所述第二电频响曲线生成第二目标音量;
控制所述播报模块根据第二目标音量对所述第一语音文件进行语音播报。
进一步地,所述第二控制模块还用于:
获取所述声音信号的频谱参数,获取所述频谱参数中的低频段参数,获取所述低频段参数在所述频谱参数中的比例,根据所述比例得到所述声音信号的第一音色;
获取所述播报模块的预设音色,计算所述第一音色与所述预设音色的匹配度,判断所述匹配度是否小于预设匹配度,在确定所述匹配度小于预设匹配度时,控制所述播报模块根据所述预设音色播报所述第一语音文件;
反之,从预设音色数据库提取出第二音色,并根据所述第二音色播报所述第一语音文件。
进一步地,所述声音信号采集模块包括声音传感器。
进一步地,所述声纹特征提取模块还用于:
在将所述语音信号输入预先训练好的声纹特征提取模型前,计算所述语音信号的信噪比,并判断所述信噪比是否大于预设信噪比,在确定所述信噪比大于预设信噪比时,将所述语音信号输入预先训练好的声纹特征提取模型中;
反之,对所述语音信号进行滤波处理,并将滤波处理后的语音信号输入预先训练好的声纹特征提取模型中。
进一步地,所述在将所述语音信号输入预先训练好的声纹特征提取模型前,计算所述语音信号的信噪比,包括:
计算所述语音信号的幅度a,如公式(1)所示:
其中,e1为所述语音信号中的有效信号的功率系数;e2为所述语音信号中的噪声的功率系数;t为所述声纹特征提取模块接收所述语音信号的接收时长;n为对所述语音信号进行信号分割后的信号节点的个数;ψi为第i个信号节点的能量;
根据所述语音信号的幅度a,计算所述语音信号的信噪比ζ,如公式(2)所示:
其中,ε为n个信号节点中的噪声的方差;γ1为所述语音信号中有效信号的强度;γ2为所述语音信号中噪声的强度;k为所述语音信号在传输过程中的损耗系数;f1为所述语音信号中有效信号的振动频率;f2为所述语音信号中噪声的振动频率;e为自然常数。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为根据本发明第一实施例的一种语音播报系统的框图;
图2为根据本发明第二实施例的一种语音播报系统的框图;
图3为根据本发明第二实施例的一种语音播报系统的框图。
附图标记
监控模块1、报警信息处理模块2、声学参数获取模型建立模块3、语音文件生成模块4、播报模块5、语音信号采集模块6、声纹特征提取模块7、第一控制模块8、声音信号采集模块9、第二控制模块10。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
下面参考图1至图3来描述本发明实施例提出的一种语音播报系统。
如图1所示,一种语音播报系统,包括:
一种语音播报系统,应用于细胞室,包括:
监控模块1,用于对所述细胞室进行监控,在确定细胞室内发生异常时生成报警信息;
报警信息处理模块2,与所述监控模块1连接,用于:
接收所述监控模块1发送的报警信息,根据所述报警信息确定报警类型;所述报警类型包括开关报警类型以及模拟量报警类型;在确定所述报警信息为模拟量报警类型时,根据预设转换规则,将所述报警信息转换为文本信息;
声学参数获取模型建立模块3,用于建立声学参数获取模型;
语音文件生成模块4,分别与所述报警信息处理模块2、声学参数获取模型建立模块3连接,用于:
接收所述报警信息处理模块2发送的文本信息;
将所述文本信息输入声学参数获取模型中,输出声学参数,将所述声学参数进行语音合成,得到第一语音文件;
播报模块5,与所述语音文件生成模块4连接,用于接收所述语音文件生成模块4发送的第一语音文件并进行语音播报。
上述方案的工作原理:监控模块1用于对所述细胞室进行监控,在确定细胞室内发生异常时生成报警信息;报警信息处理模块2用于接收所述监控模块1发送的报警信息,根据所述报警信息确定报警类型;所述报警类型包括开关报警类型以及模拟量报警类型;开关报警为细胞室内部各设备的开启/关闭状态的报警;模拟量报警类型为实验室内部温度、湿度、压力等变量发生异常时的报警;在确定所述报警信息为模拟量报警类型时,根据预设转换规则,将所述报警信息转换为文本信息;声学参数获取模型建立模块3用于建立声学参数获取模型;语音文件生成模块4用于接收所述报警信息处理模块2发送的文本信息;将所述文本信息输入声学参数获取模型中,输出声学参数,声学参数为文本信息的声学特征和频谱的声学特征;将所述声学参数进行语音合成,得到第一语音文件;播报模块5用于接收所述语音文件生成模块4发送的第一语音文件并进行语音播报。
上述方案的有益效果:监控模块1用于对所述细胞室进行监控,在确定细胞室内发生异常时生成报警信息;报警信息处理模块2用于接收所述监控模块1发送的报警信息,根据所述报警信息确定报警类型;所述报警类型包括开关报警类型以及模拟量报警类型;开关报警为细胞室内部各设备的开启/关闭状态的报警;模拟量报警类型为实验室内部温度、湿度、压力等变量发生异常时的报警;在确定所述报警信息为模拟量报警类型时,根据预设转换规则,将所述报警信息转换为文本信息;声学参数获取模型建立模块3用于建立声学参数获取模型;语音文件生成模块4用于接收所述报警信息处理模块2发送的文本信息;将所述文本信息输入声学参数获取模型中,输出声学参数,声学参数为文本信息的声学特征和频谱的声学特征;将所述声学参数进行语音合成,得到第一语音文件;播报模块5用于接收所述语音文件生成模块4发送的第一语音文件并进行语音播报。
根据发明的一些实施例,所述声学参数获取模型建立模块3,包括:
标注模块,用于获取样本声音数据,对所述样本声音数据进行声音标注前端处理,得到样本文本信息;
特征获取模块,与所述标注模块连接,用于接收所述标注模块发送的样本文本信息,对所述样本文本信息进行特征提取,提取所述样本文本信息的基频的声学特征和频谱的声学特征;
模型生成模块,与所述特征获取模块连接,用于接收所述特征获取模块发送的所述样本文本信息的基频的声学特征和频谱的声学特征,对所述样本文本信息的基频的声学特征和频谱的声学特征基于马尔可夫模型的参数聚类和训练,生成声学参数获取模型。
上述方案的工作原理:标注模块用于获取样本声音数据,对所述样本声音数据进行声音标注前端处理,得到样本文本信息;特征获取模块用于接收所述标注模块发送的样本文本信息,对所述样本文本信息进行特征提取,提取所述样本文本信息的基频的声学特征和频谱的声学特征;模型生成模块用于接收所述特征获取模块发送的所述样本文本信息的基频的声学特征和频谱的声学特征,对所述样本文本信息的基频的声学特征和频谱的声学特征基于马尔可夫模型的参数聚类和训练,生成声学参数获取模型。
上述方案的有益效果:对所述样本声音数据进行声音标注前端处理,得到样本文本信息;特征获取模块用于接收所述标注模块发送的样本文本信息,对所述样本文本信息进行特征提取,提取所述样本文本信息的基频的声学特征和频谱的声学特征;提取所述样本文本信息的基频的声学特征和频谱的声学特征是建立声学参数获取模型的必要前提;模型生成模块用于接收所述特征获取模块发送的所述样本文本信息的基频的声学特征和频谱的声学特征,对所述样本文本信息的基频的声学特征和频谱的声学特征基于马尔可夫模型的参数聚类和训练,生成声学参数获取模型,根据马尔可夫模型的参数聚类和训练,生成的声学参数获取模型更加的精确,提高本系统的实用性。
根据本发明的一些实施例,所述在确定所述报警信息为模拟量报警类型时,根据预设转换规则,将所述报警信息转换为文本信息,包括:
获取所述模拟量报警类型包括的模拟量类型及模拟量数值,根据所述模拟量类型查询预设模拟量类型-标准数值表,得到所述模拟量类型相对应的标准数值,计算所述标准数值与所述模拟量数值的差值,根据所述差值生成文本信息。
上述方案的工作原理:获取所述模拟量报警类型包括的模拟量类型及模拟量数值,根据所述模拟量类型查询预设模拟量类型-标准数值表,得到所述模拟量类型相对应的标准数值,计算所述标准数值与所述模拟量数值的差值,根据所述差值生成文本信息。
上述方案的有益效果:示例的,模拟量类型为温度,模拟量数值为18℃,通过查询预设温度-标准数值表,得到温度标准数值为23℃,通过计算温度标准数值与模拟量数值的差值,得到5℃,即23℃-18℃=5℃,根据所述差值生成的文本信息为:温度降低5摄氏度;实现了模拟量报警,增加了报警的多样性及全面性。
如图2所示,根据本发明的一些实施例,所述的语音播报系统,还包括:
语音信号采集模块6,用于采集所述细胞室内部工作人员发出的语音信号;
声纹特征提取模块7,与所述语音信号采集模块6连接,用于接收所述语音信号采集模块6发送的语音信号,将所述语音信号输入预先训练好的声纹特征提取模型中,输出声纹特征;所述声纹特征提取模型为通过样本语音信号与所述样本语音信号对应的声纹特征通过训练得到的神经网络模型;
第一控制模块8,分别与所述语音信号采集模块6、声纹特征提取模块7连接,用于:
接收声纹特征提取模块7发送的声纹特征,将所述声纹特征分别与若干个预设声纹特征数据进行匹配,计算得到若干个匹配度,筛选出最大匹配度,判断所述最大匹配度是否大于预设匹配度;
在确定所述最大匹配度大于预设匹配度时,接收所述语音信号采集模块6发送的语音信号,提取所述语音信号中的内容信息,根据所述内容信息生成第一文本,获取预设文本数据库中与所述第一文本关联度最大的第二文本,根据预设词向量数据库得到所述第二文本的文本向量;
对所述第一文本进行分词处理,得到若干个分词,根据预设词向量数据库分别得到每个分词的词向量;
根据所述文本向量分别确定每个词向量的向量权重,根据每个词向量的向量权重对所述第一文本的分词的顺序进行调整,得到目标文本;
提取所述目标文本的特征信息,获取与所述特征信息相对应的决策树;所述决策树包括非叶子节点集合与叶子节点集合;
将所述目标文本输入决策树中的非叶子节点集合包括的第一个非叶子节点中,输出语义识别结果,获取所述语义识别结果的可信度,判断所述可信度是否大于预设可信度,在确定所述可信度大于预设可信度时,将所述语义识别结果作为目标语义识别结果;
根据所述目标语义识别结果在所述对话数据库中查找对话内容,并将所述对话内容转换为第二语音文件,控制所述播报模块5对所述第二语音文件进行语音播报,同时,判断所述目标语义识别结果是否为控制指令,在确定所述目标语义识别结果为控制指令时,控制所述细胞室内部的设备执行。
上述方案的工作原理:语音信号采集模块6用于采集所述细胞室内部工作人员发出的语音信号;声纹特征提取模块7用于接收所述语音信号采集模块6发送的语音信号,将所述语音信号输入预先训练好的声纹特征提取模型中,输出声纹特征;所述声纹特征提取模型为通过样本语音信号与所述样本语音信号对应的声纹特征通过训练得到的神经网络模型;第一控制模块8用于接收声纹特征提取模块7发送的声纹特征,将所述声纹特征分别与若干个预设声纹特征数据进行匹配,计算得到若干个匹配度,筛选出最大匹配度,判断所述最大匹配度是否大于预设匹配度;在确定所述最大匹配度大于预设匹配度时,接收所述语音信号采集模块6发送的语音信号,提取所述语音信号中的内容信息,根据所述内容信息生成第一文本,获取预设文本数据库中与所述第一文本关联度最大的第二文本,根据预设词向量数据库得到所述第二文本的文本向量;对所述第一文本进行分词处理,得到若干个分词,根据预设词向量数据库分别得到每个分词的词向量;根据所述文本向量分别确定每个词向量的向量权重,根据每个词向量的向量权重对所述第一文本的分词的顺序进行调整,得到目标文本;提取所述目标文本的特征信息,获取与所述特征信息相对应的决策树;所述决策树包括非叶子节点集合与叶子节点集合;将所述目标文本输入决策树中的非叶子节点集合包括的第一个非叶子节点中,输出语义识别结果,获取所述语义识别结果的可信度,判断所述可信度是否大于预设可信度,在确定所述可信度大于预设可信度时,将所述语义识别结果作为目标语义识别结果;反之,将所述目标文本输入非叶子节点集合包括的第二个非叶子节点中,直至所述语义识别结果的可信度大于预设可信度,并将可信度大于预设可信度的语义识别结果作为目标语义识别结果;根据所述目标语义识别结果在所述对话数据库中查找对话内容,并将所述对话内容转换为第二语音文件,控制所述播报模块5对所述第二语音文件进行语音播报,同时,判断所述目标语义识别结果是否为控制指令,在确定所述目标语义识别结果为控制指令时,控制所述细胞室内部的设备执行,示例的,照明灯、打开紫外线灯、关闭门等。
上述方案的有益效果:本方案提供了一种与用户语音交互的方法;语音信号采集模块6用于采集所述细胞室内部工作人员发出的语音信号;获取语音信号是实现与用户语音交互的必然前提;声纹特征提取模块7用于接收所述语音信号采集模块6发送的语音信号,将所述语音信号输入预先训练好的声纹特征提取模型中,输出声纹特征,声纹特征是能够表征用户身份信息的重要特征;第一控制模块8用于接收声纹特征提取模块7发送的声纹特征,将所述声纹特征分别与若干个预设声纹特征数据进行匹配,计算得到若干个匹配度,筛选出最大匹配度,判断所述最大匹配度是否大于预设匹配度;在确定所述最大匹配度大于预设匹配度时,表示工作人员身份合法;接收所述语音信号采集模块6发送的语音信号,提取所述语音信号中的内容信息,根据所述内容信息生成第一文本,获取预设文本数据库中与所述第一文本关联度最大的第二文本,根据预设词向量数据库得到所述第二文本的文本向量;对所述第一文本进行分词处理,得到若干个分词,根据预设词向量数据库分别得到每个分词的词向量;根据所述文本向量分别确定每个词向量的向量权重,根据每个词向量的向量权重对所述第一文本的分词的顺序进行调整,得到目标文本;对所述第一文本的分词的顺序进行调整,使得得到的目标文本更加的精确,提高最后语义识别的准确性;提取所述目标文本的特征信息,获取与所述特征信息相对应的决策树;所述决策树包括非叶子节点集合与叶子节点集合;将所述目标文本输入决策树中的非叶子节点集合包括的第一个非叶子节点中,输出语义识别结果,获取所述语义识别结果的可信度,判断所述可信度是否大于预设可信度,在确定所述可信度大于预设可信度时,将所述语义识别结果作为目标语义识别结果,其中,非叶子节点包括若干个子非叶子节点,每个子非叶子节点对应不同的语义识别系统,提高最后语义识别结果的准确性;根据所述目标语义识别结果在所述对话数据库中查找对话内容,并将所述对话内容转换为第二语音文件,控制所述播报模块5对所述第二语音文件进行语音播报,同时,判断所述目标语义识别结果是否为控制指令,在确定所述目标语义识别结果为控制指令时,控制所述细胞室内部的设备执行,示例的,照明灯、打开紫外线灯、关闭门等。
如图3所示,根据本发明的一些实施例,所述的语音播报系统,还包括:
声音信号采集模块9,用于在所述播报模块5播报第一语音文件前,采集所述细胞室内部的声音信号;
第二控制模块10,分别与所述播报模块5、声音信号采集模块9连接,用于:
接收所述声音信号采集模块9发送的声音信号,根据所述声音信号得到声音时域信号;
对所述声音信号进行快速傅里叶变换,得到声音频域信号;在快速傅里叶变换时,对所述声音信号变换区间的长度为预设长度;
计算所述声音频域信号在所述变换区间内的平方和;
根据所述变换区间的长度及所述平方和计算得到所述声音时域信号的能量和,根据所述能量和计算得到所述声音时域信号的声压级,判断所述声压级是否小于预设声压级,在确定所述声压级小于预设声压级时,控制所述播报模块5根据预设音量播报所述第一语音文件;
反之,查询预设声压级-第一目标音量表,得到与所述声压级相对应的第一目标音量,对所述第一目标音量进行特征提取,提取所述第一目标音量对应的第一电频响曲线,并提取所述第一电频响曲线的低频部分与高频部分;
查询预设声压级-伴音功率余量表,得到与所述声压级相对应的伴音功率余量;
根据所述伴音功率余量对所述第一电频响曲线的低频部分与高频部分进行补偿处理,得到第二电频响曲线,根据所述第二电频响曲线生成第二目标音量;
控制所述播报模块5根据第二目标音量对所述第一语音文件进行语音播报。
上述方案的工作原理:声音信号采集模块9用于在所述播报模块5播报第一语音文件前,采集所述细胞室内部的声音信号;第二控制模块10用于接收所述声音信号采集模块9发送的声音信号,根据所述声音信号得到声音时域信号;对所述声音信号进行快速傅里叶变换,得到声音频域信号;在快速傅里叶变换时,对所述声音信号变换区间的长度为预设长度;计算所述声音频域信号在所述变换区间内的平方和;根据所述变换区间的长度及所述平方和计算得到所述声音时域信号的能量和,根据所述能量和计算得到所述声音时域信号的声压级,判断所述声压级是否小于预设声压级,在确定所述声压级小于预设声压级时,控制所述播报模块5根据预设音量播报所述第一语音文件;反之,查询预设声压级-第一目标音量表,得到与所述声压级相对应的第一目标音量,对所述第一目标音量进行特征提取,提取所述第一目标音量对应的第一电频响曲线,并提取所述第一电频响曲线的低频部分与高频部分;查询预设声压级-伴音功率余量表,得到与所述声压级相对应的伴音功率余量;根据所述伴音功率余量对所述第一电频响曲线的低频部分与高频部分进行补偿处理,得到第二电频响曲线,根据所述第二电频响曲线生成第二目标音量;控制所述播报模块5根据第二目标音量对所述第一语音文件进行语音播报。
上述方案的有益效果:若播报模块5在播报第一语音文件前,细胞室内部的环境声音过于的嘈杂,那么就会使得工作人员无法听清报警信息,因此,播报模块5在播报第一语音文件前获取细胞室内部环境的声压级,并根据环境的声压级来调整播报模块5的播报音量是非常必要的;声音信号采集模块9用于在所述播报模块5播报第一语音文件前,采集所述细胞室内部的声音信号,获取声音信号是检测环境声压级的必要前提;第二控制模块10用于接收所述声音信号采集模块9发送的声音信号,根据所述声音信号得到声音时域信号;对所述声音信号进行快速傅里叶变换,得到声音频域信号;在快速傅里叶变换时,对所述声音信号变换区间的长度为预设长度;根据声音频域信号及声音时域信号,使得获取到的声压级更加的精确;计算所述声音频域信号在所述变换区间内的平方和;根据所述变换区间的长度及所述平方和计算得到所述声音时域信号的能量和,根据所述能量和计算得到所述声音时域信号的声压级,判断所述声压级是否小于预设声压级,在确定所述声压级小于预设声压级时,表示细胞室内部的环境声音不是太大,控制所述播报模块5根据预设音量播报所述第一语音文件;反之,查询预设声压级-第一目标音量表,得到与所述声压级相对应的第一目标音量,对所述第一目标音量进行特征提取,提取所述第一目标音量对应的第一电频响曲线,并提取所述第一电频响曲线的低频部分与高频部分;查询预设声压级-伴音功率余量表,得到与所述声压级相对应的伴音功率余量;根据所述伴音功率余量对所述第一电频响曲线的低频部分与高频部分进行补偿处理,得到第二电频响曲线,根据所述第二电频响曲线生成第二目标音量;控制所述播报模块5根据第二目标音量对所述第一语音文件进行语音播报,使得工作人员能够清楚的听清播报模块5播报的第一语音文件,以提高用户的体验感。
如图3所示,根据本发明的一些实施例,所述第二控制模块10还用于:
获取所述声音信号的频谱参数,获取所述频谱参数中的低频段参数,获取所述低频段参数在所述频谱参数中的比例,根据所述比例得到所述声音信号的第一音色;
获取所述播报模块5的预设音色,计算所述第一音色与所述预设音色的匹配度,判断所述匹配度是否小于预设匹配度,在确定所述匹配度小于预设匹配度时,控制所述播报模块5根据所述预设音色播报所述第一语音文件;
反之,从预设音色数据库提取出第二音色,并根据所述第二音色播报所述第一语音文件。
上述方案的工作原理:获取所述声音信号的频谱参数,获取所述频谱参数中的低频段参数,获取所述低频段参数在所述频谱参数中的比例,根据所述比例得到所述声音信号的第一音色;获取所述播报模块5的预设音色,计算所述第一音色与所述预设音色的匹配度,判断所述匹配度是否小于预设匹配度,在确定所述匹配度小于预设匹配度时,控制所述播报模块5根据所述预设音色播报所述第一语音文件;反之,从预设音色数据库提取出第二音色,并根据所述第二音色播报所述第一语音文件。
上述方案的有益效果:若播报模块5的预设音色与细胞室内部环境的第一音色匹配度大于预设匹配度,会使得播报模块5播报的第一语音文件辨识度降低,进而使得用户无法清楚的听到,因此,在播报模块5播报第一语音文件前,对所诉播报模块5的音色调整是非常必要的,在所述第一音色与所述预设音色的匹配度小于预设匹配度时,控制所述播报模块5根据所述预设音色播报所述第一语音文件;反之,从预设音色数据库提取出第二音色,并根据所述第二音色播报所述第一语音文件,增加播报声音的特征性及辨识度,提高用户的体验感。
根据本发明的一些实施例,所述声音信号采集模块9包括声音传感器。
根据本发明的一些实施例,所述声纹特征提取模块7还用于:
在将所述语音信号输入预先训练好的声纹特征提取模型前,计算所述语音信号的信噪比,并判断所述信噪比是否大于预设信噪比,在确定所述信噪比大于预设信噪比时,将所述语音信号输入预先训练好的声纹特征提取模型中;
反之,对所述语音信号进行滤波处理,并将滤波处理后的语音信号输入预先训练好的声纹特征提取模型中。
上述方案的工作原理:在将所述语音信号输入预先训练好的声纹特征提取模型前,计算所述语音信号的信噪比,并判断所述信噪比是否大于预设信噪比,在确定所述信噪比大于预设信噪比时,将所述语音信号输入预先训练好的声纹特征提取模型中;反之,对所述语音信号进行滤波处理,并将滤波处理后的语音信号输入预先训练好的声纹特征提取模型中。
上述方案的有益效果:在与工作人员进行语音交互时,精准的确定工作人员的身份是非常必要的,若语音信号中的噪声太多,不仅会影响后续识别的准确性,还会造成对工作人员的身份识别的不精确性,因此在将所述语音信号输入预先训练好的声纹特征提取模型前,计算所述语音信号的信噪比是非常必要的,在确定所诉后信噪比小于等于预设信噪比时,对所述语音信号进行滤波处理,并将滤波处理后的语音信号输入预先训练好的声纹特征提取模型中,提高最后对工作人员身份识别的精确性及后续对语音信号识别的准确性。
根据本发明的一些实施例,所述在将所述语音信号输入预先训练好的声纹特征提取模型前,计算所述语音信号的信噪比,包括:
计算所述语音信号的幅度a,如公式(1)所示:
其中,e1为所述语音信号中的有效信号的功率系数;e2为所述语音信号中的噪声的功率系数;t为所述声纹特征提取模块7接收所述语音信号的接收时长;n为对所述语音信号进行信号分割后的信号节点的个数;ψi为第i个信号节点的能量;
根据所述语音信号的幅度a,计算所述语音信号的信噪比ζ,如公式(2)所示:
其中,ε为n个信号节点中的噪声的方差;γ1为所述语音信号中有效信号的强度;γ2为所述语音信号中噪声的强度;k为所述语音信号在传输过程中的损耗系数;f1为所述语音信号中有效信号的振动频率;f2为所述语音信号中噪声的振动频率;e为自然常数。
上述方案的工作原理及有益效果:在计算所述语音信号的信噪比时,考虑所述语音信号中有效信号的强度、所述语音信号中有效信号的振动频率、所述语音信号中噪声的振动频率、所述声纹特征提取模块7接收所述语音信号的接收时长、所述语音信号中的有效信号的功率系数、所述语音信号中的噪声的功率系数等因素,使得计算出来的信噪比更加的精确,提供判断所述信噪比于预设信噪比大小的准确性,对语音信号进行信号分割,得到n信号点,更加的体现了语音信号的特征,根据n个信号点进行计算,得到的计算结果更准确。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

