本发明属于自然语言处理,语音合成技术,深度学习技术领域,具体的说是一种基于深度学习的语音合成方法。
背景技术:
语音合成作为实现人机语音交互系统的核心技术之一,是语音处理技术中一个重要的方向,其应用价值越来越受到重视。作为人机语音交互的出口,语音合成的效果直接影响到人机交互的体验。一个高质量的、稳定的语音合成系统能够让机器更加地拟人化,使人机交互过程更加自然。
近年来,随着人工神经网络的迅速发展,端到端的语音合成模型取得了更好的效果,例如tacotron以及tacotron2等。它们直接从文本产生梅尔频谱图,然后再通过griffin-lim算法或者wavenet的声码器合成音频结果。通过端到端的神经网络,合成的音频质量有了极大的提高,甚至可以与人类录音相媲美。
这些端到端模型多用rnn作为编码器和解码器。然而,rnn作为一种自回归模型,其第i步的输入包含了第i-1步输出的隐藏状态,这种时序结构限制了训练和预测过程中的并行计算能力。此外,这种结还会导致当输入序列过长时来自许多步骤之前的信息在传递过程中逐渐消失进而使生成的上下文信息存在偏差的问题。
技术实现要素:
本发明是为了解决上述现有技术存在的不足之处,提出一种基于深度学习的语音合成方法,以期能充分利用gpu的并行计算能力从而获得更快的训练速度和预测速度,并能从输入序列中获取远距离信息,使其在长文本语音合成中效果跟好,进而在实际使用过程中能更好的满足高效、高质量的需求。
本发明为达到上述发明目的,采用如下技术方案:
本发明一种基于深度学习的语音合成方法的特点是按如下步骤进行:
步骤1、建立文本数据库和音频数据库,所述文本数据库中的每个文本与所述音频数据库中的每个音频用编号相对应,从而得到n条原始数据,记为w={w(1),w(2),…,w(n),…,w(n)},w(n)表示第n条原始数据,且w(n)=<audion,textn>;audion表示第n条音频,textn表示第n个文本,n=1,2,…,n;
步骤2、对第n个文本textn进行标准化处理,得到预处理后的第n个文本textn′;
将所述预处理后的第n个文本textn′中的字符串转化为字符,并用one-hot向量表示每个字符,从而得到向量化后的第n个文本向量,记为
步骤3、利用梅尔频率倒谱系数对第n条音频audion进行语音特征提取,得到第n条语音信息特征mfccn,从而与所述向量化后的第n个文本向量cn共同构成第n条训练数据w′(n)=<mfccn,cn>;
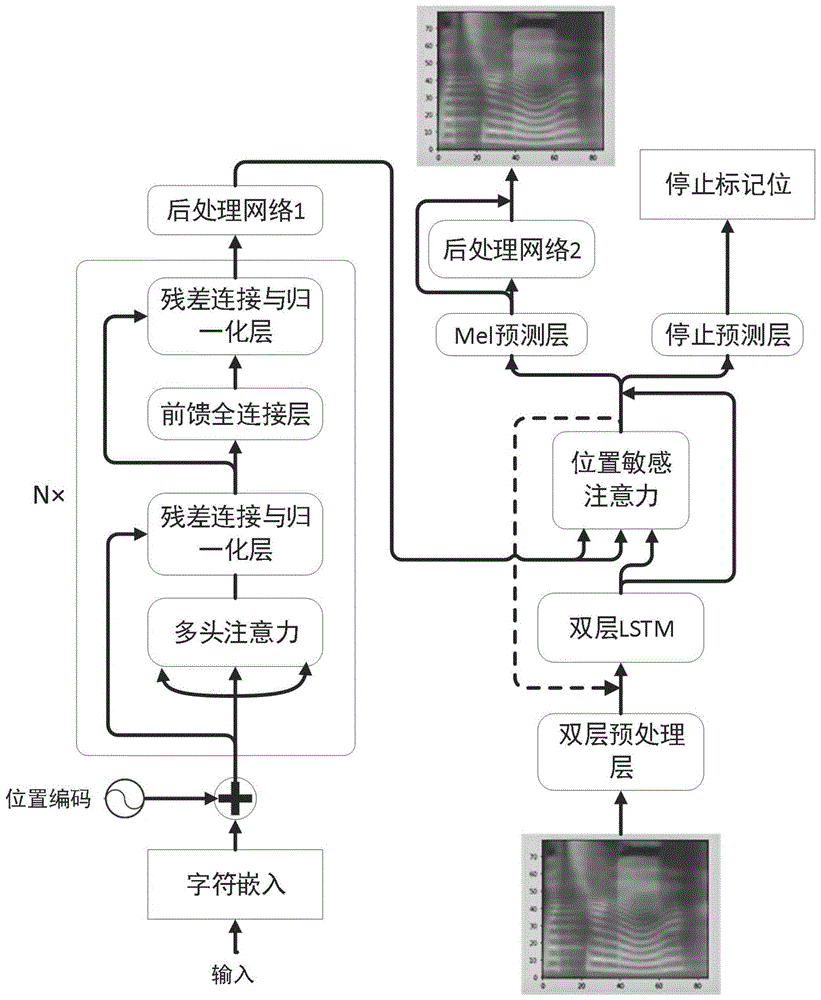
步骤4、构建基于bert模型的编码器神经网络,包括:多头注意力层、两个残差连接与归一化层、双层全连接层、单层全连接层;所述多头注意力层是由h个点积注意力组成;所述双层全连接层、单层全连接层中设置有概率为p的dropout函数以及神经元的激活函数tanh;
步骤4.1、利用式(1)得到第n个文本向量cn在t位置对应的位置信息编码
式(1)中,t表示字符在所述向量化后的第n个文本向量cn中的位置,f(t)i表示第i个字符
步骤4.2、将第n个文本向量cn及其位置信息编码ln在对应位置相加后得到第n个输入向量xn;再将第n个输入向量xn输入所述多头注意力层的每个点积注意力中,从而利用式(2)得出第j个点积注意力的输出αj:
式(2)中,
步骤4.3、将h个点积注意力的输出
式(3)中,wo表示d×dk维的线性变换矩阵,concat(·)表示拼接操作;
步骤4.4、将多头注意力的输出向量on与其第n个输入向量xn经过残差连接与归一化层,从而利用式(4)得到输出向量hn:
hn=layernorm(xn on)(4)
式(4)中,layernorm(·)表示层归一化函数;
步骤4.5、将输出向量hn输入所述双层全连接层中,从而利用式(5)得到相应层的输出in:
in=max(0,hnw1 b1)w2 b2(5)
式(5)中,w1,w2表示维度为d×dff的两个待训练的参数矩阵,dff表示全连接层隐藏节点的个数即该层的输出维度,b1表示第一偏置矩阵,b2表示第二偏置矩阵,max(·)表示取最大值函数;
步骤4.6、将双层全连接层的输出in与输出向量hn经过残差连接与归一化层,从而利用式(4)得到第n个文本向量cn的上下文向量un;
步骤4.7、所述上下文向量un通过一层全连接层处理后得到所述编码器神经网络输出的维度为d×dff的缩放后的上下文向量u′n,并作为编码器的输出向量;
步骤5、构建解码器神经网络,包括:预处理网络、2个单向lstm层、位置敏感注意力层、停止标记位预测层、mel预测层以及后处理网络;所述预处理网络包含2个全连接层,每个全连接层均有dpre个relu隐藏单元;所述后处理网络r层卷积层,每层包含ddec个维度为k×1的卷积核;
步骤5.1、定义t时刻解码器神经网络的输出为
步骤5.2、所述t时刻解码器神经网络的输出
将预处理层的输出向量
步骤5.3、将t时刻单向lstm层的输出向量
步骤5.4、将注意力向量ftn通过维度为(m ddec)×1的停止标记位预测层的处理后再经过sigmod函数激活处理后得到t时刻的停止标记值
当
当
步骤5.5、注意力向量ftn经过所述mel预测层的处理后输出mel向量
步骤5.6、将t 1赋值给t后,返回步骤5.2执行;
步骤6、将所述向量化后的第n个文本向量cn及第n条语音信息特征mfccn输入到由编码器神经网络和解码器神经网络所构成的模型中进行训练,从而获得训练后的梅尔频谱预测模型,用于将文本转换成梅尔频谱帧;
步骤7、使用waveglow模型作为声码器,并使用第n条语音信息特征mfccn以及对应音频进行训练,从而获得训练后的waveglow模型,用于将梅尔频谱帧生成对应的音频;
步骤8、将训练后的梅尔频谱预测模型与waveglow模型组成为语音合成模型,从而对按照步骤2处理后的文本向量进行语音合成,并获得音频结果。
与现有技术相比,本发明的有益效果在于:
1、本发明通过采用预训练模型bert作为编码器,基于在大数据集上经过训练的模型bert通过微调额外的输出层来适配下游任务,使得待训练参数量更少,模型更容易收敛;从而使得模型训练过程大大加快,使用更少的时间就能得到训练好的语音合成模型。
2、本发明通过使用self-attention来代替rnn的方法,self-attention可以并行处理编码器的输入,不需要进行自回归计算从而大大减少计算时间,提升训练效率和预测过程。此外,self-attention机制可以同时从上下文中提取信息来建立长期依赖关系,从而避免了使用传统rnn带来的训练和预测缓慢、长距离信息丢失的问题。
3、本发明通过增加位置信息编码,使输入信号在前向和后向传播时任意位置之间的间隔缩短到1。这在神经网络tts模型中有很大的帮助,比如合成波的韵律,它不仅取决于周围的几个单词,还取决于句子级别的语义。
附图说明
图1为本发明模型架构图。
具体实施方式
本实施例中,一种基于深度学习的端到端语音合成方法,是用于将所输入文本快速合成高质量的音频,如图1所示,步骤如下:
步骤1、建立文本数据库和音频数据库,文本数据库中的每个文本与音频数据库中的每个音频用编号相对应,从而得到n条原始数据,记为w={w(1),w(2),…,w(n),…,w(n)},w(n)表示第n条原始数据,且w(n)=<audion,textn>;audion表示第n条音频,textn表示第n个文本,n=1,2,…,n;本实施例中,利用公开的音频数据集ljspeech-1.1作训练和测试,其中包含13100个单声道演讲者的短音频片段,即n=13100。这些片段来自7本非小说类书籍。该数据包含在家庭环境中使用内置麦克风在macbookpro上记录的大约24小时的语音数据。
步骤2、根据维基百科所有文本数据建立字典,每一个字符或单词对应一个索引,形如<string,index>。对第n个文本textn进行标准化处理:1)去除特殊字符;2)将缩写转换成全写,例如将‘mrs’改写成‘misess’;3)将数字转化成对应的英文文本,比如‘9’改成‘nine’,得到预处理后的第n个文本textn′;
将预处理后的第n个文本textn′中的字符串转化为字符,并用one-hot向量表示每个字符,从而得到向量化后的第n个文本向量,记为
步骤3、利用梅尔频率倒谱系数对第n条音频audion进行语音特征提取,得到第n条语音信息特征mfccn,从而与向量化后的第n个文本向量cn共同构成第n条训练数据w′(n)=<mfccn,cn>;
本实施例中,使用梅尔倒谱系数(mfcc)作为歌曲的第一语音特征。梅尔倒谱系数是在mel标度频率域提取出来的倒谱参数,与频率f的关系可以表示式(1):
步骤3.1、利用式(2)所示的一阶激励响应高通滤波器对音频数据进行预处理,可以平缓语音信号过于起伏的部分,获得平滑的语音信号:
h(s)=1-μs-1(2)
本实施例中,μ表示调整系数,且μ=0.97,s表示原始语音信号;
步骤3.2、对平滑的语音数据取k个采样点为一帧进行分帧处理,获得分帧后的语音信号s(n);分帧处理的参数选择与语音信号的采样频率有关,本文采样频率为22050hz,一般人类语音信号在10ms-20ms为稳定,故去10-20ms为一帧,设置帧长为256个采样点取一帧。分帧后的语音信号为s(n)。为了避免窗边界对信号的遗漏,一般取帧长的一半作为帧移,即每次位移一帧的一半长度后再取下一帧,这样可以避免帧与帧之间的特性变化太大。
步骤3.3、对分帧后的语音信号利用式(3)和式(4)进行加窗处理,通过式(3)的海明窗进行加窗之后,能够减少语音信号吉布斯效应的影响,从而获得加窗后的语音信号s′(n):
s′(n)=s(n) w(n)(3)
式(4)中,a为调整系数,a∈(0,1);本实施例中,a的取值为0.46;
步骤3.4、利用式(5)对加窗后的语音信号s′(n)进行快速傅里叶变换,获得倒谱的语音信号xa(k):
步骤3.5、利用梅尔滤波器组对倒谱的语音信号xa(k)进行滤波,获得加卷的语音信号;
mel滤波器组实质上是满足式(6)的一组三角滤波器:
mel[f(m)]-mel[f(m-1)]=mel[f(m 1)]-mel[f(m-1)](6)
式(6)中,f(m)为三角滤波器的中心频率,各f(m)之间的间隔随着m值的减小而缩小,随着m值得增大而增宽。定义一个具有24个滤波器的滤波器组,因为每一个三角滤波器的覆盖范围都近似于人耳的一个临界带宽,因此可以来模拟人耳的掩蔽效应。24个滤波器形成满足式(7)的滤波器组,通过这个mel滤波器组可以得到经过滤波后的mel频率信号:
步骤3.6、利用离散余弦变换对加卷的语音信号进行解卷,获得静态的梅尔频率倒谱参数smfcc;将步骤3.6中得到的信号h(k)通过式(8)进行离散余弦变换(dft),得到需要的静态mfcc参数smfcc(n):
式(8)中,l为mfcc的系数阶数,本实施例中,l取值为12。
步骤3.7、利用式(9)对静态的梅尔频谱率倒谱参数进行动态差分,获得一阶差分的梅尔频率倒谱参数;
式(9)中,dt表示第t个一阶差分,st表示第t个倒谱系数,p表示倒谱系数的阶数,k表示一阶导数的时间差。本实施例中,k取值为1.
步骤3.8、对一阶差分的梅尔频率倒谱参数进行动态差分计算,获得二阶差分的梅尔频率倒谱参数d2mfcc,即将步骤3.9中得到的一阶差分参数带入式(9)得到二阶差分参数。
步骤3.9、利用式(10)对静态的梅尔频率倒谱参数、一阶差分的梅尔频率倒谱参数和二阶差分的梅尔频率倒谱参数进行结合获得的mfcc既是音频的语音信息特征。
则通过步骤2和本步骤可以得到单条训练数据w(n)′=<mfccn,textn′>
步骤4、构建基于bert模型的编码器神经网络,包括:多头注意力层、两个残差连接与归一化层、双层全连接层、单层全连接层;多头注意力层是由h个点积注意力组成;双层全连接层、单层全连接层中设置有概率为p的dropout函数以及神经元的激活函数tanh。本实施例中p=0.1;
步骤4.1、利用式(11)得到第n个文本向量cn在t位置对应的位置信息编码
式(11)中,t表示字符在向量化后的第n个文本向量cn中的位置,f(t)i表示第i个字符
步骤4.2、将第n个文本向量cn及其位置信息编码ln在对应位置相加后得到第n个输入向量xn;再将第n个输入向量xn输入多头注意力层的每个点积注意力中,从而利用式(12)得出第j个点积注意力的输出αj:
式(12)中,
步骤4.3、将h个点积注意力的输出
式(13)中,wo表示d×dk维的线性变换矩阵,concat(·)表示拼接操作;
步骤4.4、将多头注意力的输出向量on与其第n个输入向量xn经过残差连接与归一化层,从而利用式(14)得到输出向量hn:
hn=layernorm(xn on)(14)
式(14)中,layernorm(·)表示层归一化函数;
步骤4.5、将输出向量hn输入双层全连接层中,从而利用式(15)得到相应层的输出in:
in=max(0,hnw1 b1)w2 b2(15)
式(15)中,w1,w2表示维度为d×dff的两个待训练的参数矩阵,dff表示全连接层隐藏节点的个数即该层的输出维度,b1表示第一偏置矩阵,b2表示第二偏置矩阵,max(·)表示取最大值函数。本实施例中dff=1024;
步骤4.6、将双层全连接层的输出in与输出向量hn经过残差连接与归一化层,从而利用式(4)得到第n个文本向量cn的上下文向量un;
步骤4.7、上下文向量un通过一层全连接层处理后得到编码器神经网络输出的维度为d×dff的缩放后的上下文向量u′n,并作为编码器的输出向量;
步骤5、构建解码器神经网络,包括:预处理网络、2个单向lstm层、位置敏感注意力层、停止标记位预测层、mel预测层以及后处理网络;预处理网络包含2个全连接层,每个全连接层均有dpre个relu隐藏单元;后处理网络r层卷积层,每层包含ddec个维度为k×1的卷积核。本实施例中dpre=256,ddec=512,k=5;
步骤5.1、定义t时刻解码器神经网络的输出为
步骤5.2、t时刻解码器神经网络的输出
将预处理层的输出向量
步骤5.3、将t时刻单向lstm层的输出向量
步骤5.4、将注意力向量ftn通过维度为(d ddec)×1的停止标记位预测层的处理后再经过sigmod函数激活处理后得到t时刻的停止标记值
当
当
步骤5.5、注意力向量ftn经过mel预测层的处理后输出mel向量
步骤5.6、将t 1赋值给t后,返回步骤5.2执行;
步骤6、将向量化后的第n个文本向量cn及第n条语音信息特征mfccn输入到由编码器神经网络和解码器神经网络所构成的模型中进行训练,从而获得训练后的梅尔频谱预测模型,用于将文本转换成梅尔频谱帧;
步骤6.1、本实施例使用adam优化器,其中β1=0.9,β2=0.999,ε=10-8,并且将学习率固定为10-3,且还应用权重为10-6的l2正则化。
步骤6.2、在实施例中定义本发明的神经网络的当前迭代次数为μ,并初始化μ=1;最大迭代次数为μmax=1000;定义batchsize大小为64;定义神经网络的期望输出为t,定义人工设定的熵损失值为h,对深度学习网络中各层的参数进行随机初始化;
步骤6.3、加载数据进行训练,训练过程中每个时间步对比预测值与实际值,计算均方损失函数如(16),并使用adam优化器更新参数。
mseloss(xi,yi)=(xi-yi)2(16)
式(16)中,xi,yi分别为时刻i的预测值与实际值。
步骤7、使用waveglow模型作为声码器,并使用第n条语音信息特征mfccn以及对应音频进行训练,从而获得训练后的waveglow模型,用于将梅尔频谱帧生成对应的音频;本实施例使用带有librosamel过滤器默认设置的80个bin的梅尔频谱图,即每个bin通过过滤器长度进行归一化,并且刻度与htk相同。梅尔频谱图的参数是fft大小1024,跳数256和窗口大小1024。
步骤8、将训练后的梅尔频谱预测模型与waveglow模型组成为语音合成模型,从而对按照步骤2处理后的文本向量进行语音合成,并获得音频结果。
基于bert的端到端语音合成模型,能充分利用gpu的并行计算能力从而获得更快的训练速度和预测速度。并且,它能从输入序列中获取远距离信息,使其在长文本语音合成中效果很好。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

