本发明涉及一种跨语料库情感识别方法,尤其适用于语音情感识别领域使用的一种基于图卷积神经网络的跨语料库情感识别方法。
背景技术:
语音情感识别技术已经成为人机和谐交互的目标,随着科学技术的发展,对语音情感识别技术提出了更高的要求。在诸多领域都有了广泛的应用,在教学领域,具有情感识别能力的计算机远程教学系统,识别学生情绪,提高教学质量;在临床医学领域,拥有语音情感识别能力的计算机帮助孤僻症患者反复练习情感交流,逐渐康复。
传统的语音情感识别技术都是基于单个语料库,在两种不同的情感语料库中识别效果很差。往往在实践中,训练和测试的语料库是不相同的。因此跨语料库情感识别面临着很大的挑战。如何在多个不相同的语料库之间进行准确的情感识别,是目前需要解决的一个重要问题。
技术实现要素:
发明目的:针对上述技术问题,本发明提出了一种基于图卷积神经网络的跨语料库情感识别的方法,对不同语料库都具有良好的适用性,且识别结果更准确。
技术方案:为实现上述技术目的,本发明所述的一种基于图卷积神经网络的跨语料库情感识别方法,其特征在于步骤如下:
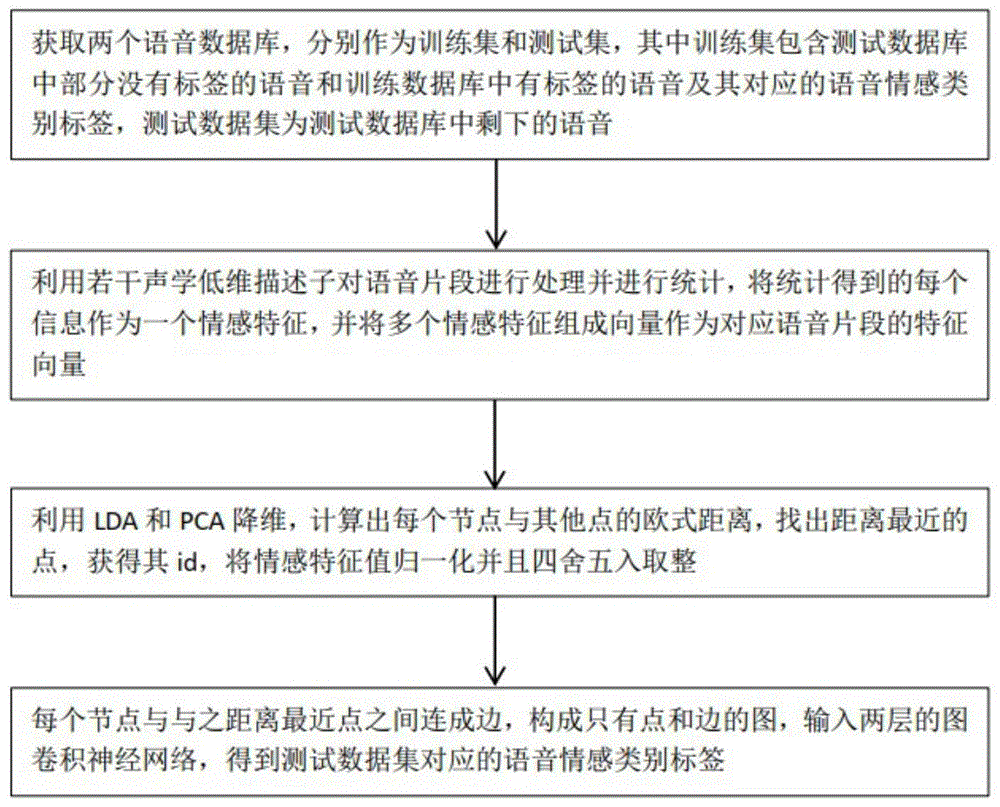
s1获取两个音频数据库,两个音频数据库中的每条音频都具有一个情感标签,一个音频数据库作为训练数据集,另一个作为测试数据集,其中测试数据集分成多份,取一份作为测试样本,删除该份测试样本中语音的情感标签形成无标签的测试样本,;
s2利用若干声学低维描述子对两个音频数据库中的音频进行特征提取,得到多个情感特征组,并将多个情感特征组成向量作为对应语音的特征向量;
s3建立图卷积神经网络模型gcn,将每条音频定义为gcn的节点,其中包括无标签的的音频,将gcn中每个节点与与之距离最近节点之间构成边,最终将节点和边连接构成一张新的图,这张新的图把有标签数据、无标签数据和测试数据连接了起来,将新图输入两层的图卷积神经网络,;
s4将已知情感标签的训练数据集中的样本和无标签的测试样本一起放入s3中获得的卷积神经网络模型继续训练,测试测试数据集中未删除情感标签的样本,采用softmax分类器进行分类,得到未删除情感标签的测试样本的标签分类;
s5无标签的测试样本悬链后得到语音情感标签概率,softmax输出最大概率的情感标签,结合预测出语音的情感分类,输出情感分类即为从语音中识别出来的情感。
步骤s2具体包括:
s2.1对于berlin库和enterface库中的音频,计算其34个声学低维描述子值和对应增量参数;所述34个声学低维描述子分别为:响度、梅尔频率倒谱系数0-14、梅尔频带对数功率0-7、8个线谱对频率、平滑的基频轮廓线和最终基频候选的发声概率;4个基于音高的低级描述子和对应增量参数、最后附加音高的数量和总输入的持续时间;所述4个基于音高的低级描述子分别为:基频频率、2个抖动和闪烁;描述子来源于interdpeech2010emotionchallenge提供的功能集;
s2.2对于每个音频,利用opensmile软件分别对其34个声学低维描述子进行21种统计函数处理,所述21种统计函数分别为为求最大值和最小值的绝对位置、平均值、斜率、偏移量、误差、标准偏差、偏度、峰度、3个第一四分位数、3个四分位数间距、最大值、最小值和两个时间百分比;对其4个基于音高的低级描述子进行19种统计函数处理,所述的19种统计函数不包括上述21个函数中的最小值和范围;
s2.3将s2.2中计算得到的每个值作为一个情感特征,并将35*2*21 4*2*19 2=1582个情感特征组成向量作为对应音频的特征向量,并将每个特征值归一化到0-1之间,四舍五入取整。
步骤s3具体包括:
s3.1由于两个音频数据库空间分布不同,所以运用lda(线性判别分析),将有标签的样本按照标签信息投影到一起,形成4维数据,运用pca(主成分分析),将没有标签的样本降维投影到低维子空间,形成50维数据;
s3.2在投影后的平面上计算每个节点与其他节点之间的欧式距离,得到每个节点与与之距离最近点的id,点与点之间距离的关系构成图的边,lda(线性判别分析)的投影构成一张图,pca(主成分分析)的投影构成一张图,在两个图中选择5个不同情感的点一一连接,将两张图构成一张完整的图;
s3.3将节点和边构成的图输入到两层的图卷积神经网络中,图卷积将未知标签的特征通过邻接矩阵传到已知标签的特征节点上,利用已知标签节点的分类器进行分类测试;
进一步的,图卷积神经网络模型中的传播方式为:
式中,
s3.4在投影构成的图上的卷积为频域卷积,利用图的傅里叶变换实现卷积;利用图的拉普拉斯矩阵计算出频域上的拉普拉斯算子,再类比频域上欧式空间的卷积,从而得到图卷积的公式,利用拉普拉斯矩阵l(l=d-a)替代拉普拉斯算子和特征向量x,形成图的傅里叶变换,具体为:
l=uλut
u=(u1,u2,…,un)
u是归一化图拉普拉斯矩阵l的特征向量矩阵,根据以上卷积和傅里叶变换相结合,在投影构成的图的频域卷积可以写成:
在整个投影构成的图的n个节点上做卷积,那么得到的图的卷积为:
将欧式空间上的卷积和图上的卷积进行对比,两者非常相似,f是特征函数,g是卷积核:
(f*g)=f-1[f[f]⊙f[g]]
(f*gg)=u(utf⊙utg)=u(utg⊙utf)
我们将utg看成是用于频域卷积神经网络的卷积核,写成gθ,那么图上卷积的最终公式为:
(f*gg)θ=ugθutf
最后,一般的频域卷积网络要计算拉普拉斯矩阵所有的特征值和特征向量,计算量很大,所以提出用切比雪夫多项式来加快特征矩阵的求解;
假设切比雪夫多项式的第k项是tk,频域卷积核为:
其中:tk(x)=2xtk-1(x)-tk-2(x),t0(x)=1和t1(x)=x,
其中
步骤s3.3具体包括:
使用一个对称邻接矩阵a,两层gcn,在投影构成的图进行半监督节点分类:
首先将
其中,w(0)是输入层到隐藏层的权重,w(1)是隐藏层到输出层的权重,采用两种不同的激活函数relu和softmax,在半监督分类中,评估所有标签样本的交叉熵误差:
式中,yl是有标签的样本集.。.
有益效果:本方法的跨语料库情感识别的方法用一个有标签的数据库训练去测试另一个没有标签的数据库,使用部分测试数据库中的数据和训练数据集一起训练去测试测试数据库中剩下的数据,实现在两个数据库中跨库学习,因此本方法对于不同环境有拥有良好的适用性,识别结果更准确,也能更好地比较不同语言之间的情感的相似性和差异性。
附图说明
图1是本发明提供的基于图卷积神经网络的跨语料库情感识别方法的流程示意图。
图2是本发明提供的图卷积神经网络的模型示意图。
具体实施方式
下面结合附图对本发明的实施例做进一步说明:
如图1所示,本法民的一种基于图卷积神经网络的跨语料库情感识别的方法,包括以下步骤:
(1)获取两个音频数据库,分别作为训练数据集和测试数据集,将测试数据集平均划分成10份,选取其中的9份作为无标签样本和训练数据集一起训练,剩下的1份作为测试样本。在本实施例中,我们使用情感语音识别中常见的两类语音情感数据库:berlin和enterface。berlin库有7种情感:中性、害怕、生气、高兴、悲伤、厌恶和无聊,一共有535句语句。enterface库有6种情感:害怕、生气、高兴、悲伤、厌恶和惊喜,一共有1166个视频。我们选取berlin库和enterface库具有的5种相同情绪:害怕、生气、高兴和悲伤,一共1395条语句,进行训练和测试。
(2)利用若干声学低维描述子对berlin库和enterface库中的音频进行特征提取,得到1582维特征,并将多个情感特征组成向量作为对应语音的特征向量。
该步骤具体包括:
(2-1)对于berlin库和enterface库中的音频,计算其34个声学低维描述子值和对应增量参数;所述34个声学低维描述子分别为:响度、梅尔频率倒谱系数0-14、梅尔频带对数功率0-7、8个线谱对频率、平滑的基频轮廓线和最终基频候选的发声概率;4个基于音高的低级描述子和对应增量参数、最后附加音高的数量和总输入的持续时间;所述4个基于音高的低级描述子分别为:基频频率、2个抖动和闪烁;描述子来源于interdpeech2010emotionchallenge提供的功能集;
(2-2)对于每个音频,利用opensmile软件分别对其34个声学低维描述子进行21种统计函数处理,所述21种统计函数分别为为求最大值和最小值的绝对位置、平均值、斜率、偏移量、误差、标准偏差、偏度、峰度、3个第一四分位数、3个四分位数间距、最大值、最小值和两个时间百分比;对其4个基于音高的低级描述子进行19种统计函数处理,所述的19种统计函数不包括上述21个函数中的最小值和范围;
(2-3)将统计得到的每个信息(2-2中计算得到的每个值)作为一个情感特征,并将35*2*21 4*2*19 2=1582个情感特征组成向量作为对应音频的特征向量,并将每个特征值归一化到0-1之间,四舍五入取整。
(3)建立图卷积神经网络模型,将每条音频看成节点,每个节点与与之距离最近节点之间构成边,将节点和边构成的图输入到两层的图卷积神经网络中,图卷积将未知标签的特征传到已知标签的特征节点上,利用已知标签节点的分类器进行分类测试。
(3-1)其中,要求出每个节点与与之距离最近点的id,需要用到lda(线性判别分析)和pca(主成分分析),进行半监督判别分析,lda计算过程:
数据集d={(x1,y1),(x2,y2),…,(xm,ym)},其中xi为n维向量,yi∈{c1,c2,…,ck},定义nj(j=1,2,…,k)为第j类样本的个数,xj(j=1,2,…,k)为第j类样本的集合,μj(j=1,2,…,k)为第j类样本的均值,∑j(j=1,2,…,k)为第j类样本的协方差矩阵。
(3-1-1)利用下式计算类内散度sw:
(3-1-2)利用下式计算类间散度sb:
(3-1-3)计算矩阵
其中w为n*d的矩阵,目标函数j(w)的优化过程可以转化为:
最大值是矩阵
(3-1-4)对样本集中的每一样本特征xi,转化为新的样本zi=wtxi
(3-1-5)得到输出样本集d'={(z1,y1),(z2,y2),…,(zm,ym)}
(3-2)pca的计算过程:
首先输入数据集x={x1,x2,x3,…,xn}
(3-2-1)去平均值,即每一个特征值减去各自的平均;
(3-2-2)计算协方差矩阵
(3-2-3)用特征值分解方法求协方差矩阵
(3-2-3)对特征值从大到小排序,选择其中最大的k个,然后将其对应的k个特征向量分别作为行向量组成特征矩阵p;
(3-2-4)将数据转换到k个特征向量构建的新空间中,即y=px;
其中,图卷积神经网络模型中的传播方式为:
式中,
(3-3)在图步骤(3)中构成的新图上的卷积我们考虑到的是频域卷积,利用图的傅里叶变换实现卷积。简单来讲,就是用图的拉普拉斯矩阵计算出频域上的拉普拉斯算子,再类比频域上欧式空间的卷积,就得到图卷积的公式。使用拉普拉斯矩阵l(l=d-a)替代拉普拉斯算子和特征向量x,形成图的傅里叶变换。图是无向图,l是对称矩阵,分解为:
l=uλxut
u=(u1,u2,…,un)
u是归一化图拉普拉斯矩阵l的特征向量矩阵,根据以上卷积和傅里叶变换相结合,在步骤(3)中构成的图上的频域卷积可以写成:
在整个新图的n个节点上做卷积,那么得到的图的卷积为:
将欧式空间上的卷积和图上的卷积进行对比,两者非常相似,f是特征函数,g是卷积核:
(f*g)=f-1[f[f]⊙f[g]]
(f*gg)=u(utf⊙utg)=u(utg⊙utf)
我们将utg看成是用于频域卷积神经网络的卷积核,写成gθ,那么新图上卷积的最终公式为:
(f*gg)θ=ugθutf
最后,一般的频域卷积网络要计算拉普拉斯矩阵所有的特征值和特征向量,计算量很大,所以提出用切比雪夫多项式来加快特征矩阵的求解。假设切比雪夫多项式的第k项是tk,频域卷积核就变成:
其中:tk(x)=2xtk-1(x)-tk-2(x),t0(x)=1和t1(x)=x,
其中
其中,两层的卷积神经网络,使用一个对称邻接矩阵a,两层gcn(图卷积神经网络),在新图上进行半监督节点分类。首先将
其中,w(0)是输入层到隐藏层的权重,w(1)是隐藏层到输出层的权重。第一层采用激活函数relu,第二层采用激活函数softmax。在半监督分类中,我们评估所有标签样本的交叉熵误差:
式中,yl是有标签的样本集.
本实施例还提供了一种基于图卷积神经网络的跨语料库情感识别装置,包括处理器及存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述方法。
为验证本发明的有效性,在语音情感数据库berlin和enterface数据库上我们分别进行了实验。在实验中,我们将两个数据库分别作为源域和目标域,其中源域是作为训练集提供训练数据和部分标签,目标域是作为测试集,提供测试数据和标签。在我们的实验中,要通过两种方案进行分析。源语料库可以包含目标语料库没有标签的样本信息。如方案1:用enterface库训练去测试berlin库,在enterface库训练的过程中加上berlin库一部分没有标签的样本。方案2:用berlin库训练去测试enterface库,在berlin库训练过程中加上enterface库一部分没有标签的样本。我们对训练过程中含有无标签样本的个数对实验影响进行了多次试验,评价标准为accuracy。
实验预期,基于本发明提出的基于图卷积神经网络的跨语料库情感识别方法,取得了比较好的跨数据库情感识别率。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

