本发明属于语音处理技术领域,涉及语音合成技术,具体涉及一种少语料的语音模型训练及合成方法。
背景技术:
在人工智能技术领域,语音增强、语音合成一直都是专家学者及语音交互产品市场关注的话题。近年来,深度学习技术推动了人工智能领域的快速发展,语音合成也有了突破性进展,某些特定场景下的合成语音真实度甚至可比拟真人发声,语音合成技术广泛应用于新闻播报,有声小说,配音等领域。
采用深度学习技术进行合成相较于传统的语音合成方法,不需要过多的语言学和信号学的知识,也不需要人工进行语言学标注,端到端的处理技术可以直接输入文本,通过深度模型计算得到对应的音频信息,合成效果也优于传统语音合成算法。
但是深度学习合成方法也有其缺点,如对合成不好的文本进行针对性优化较难,而且需要大量的优质的原始语料,对语料的依赖性很大,质量较差和数量不够的训练集很难拟合端到端模型的大量参数。实际应用中,客户对音色的要求往往很多,包括年龄段(男、女、老、幼),音色类型(温柔、可爱、严肃等),语种(中文,英文,日语等),想要收集如此多的语料工作量大。而不同语种的混合合成往往需要发音人会多种语言,更难以实现。
技术实现要素:
为克服现有方案技术存在的缺陷,本发明公开了一种少语料的语音模型训练及合成方法。
本发明公开了一种少语料的语音模型训练及合成方法,包括模型训练及语音合成;
所述模型训练包括如下步骤:
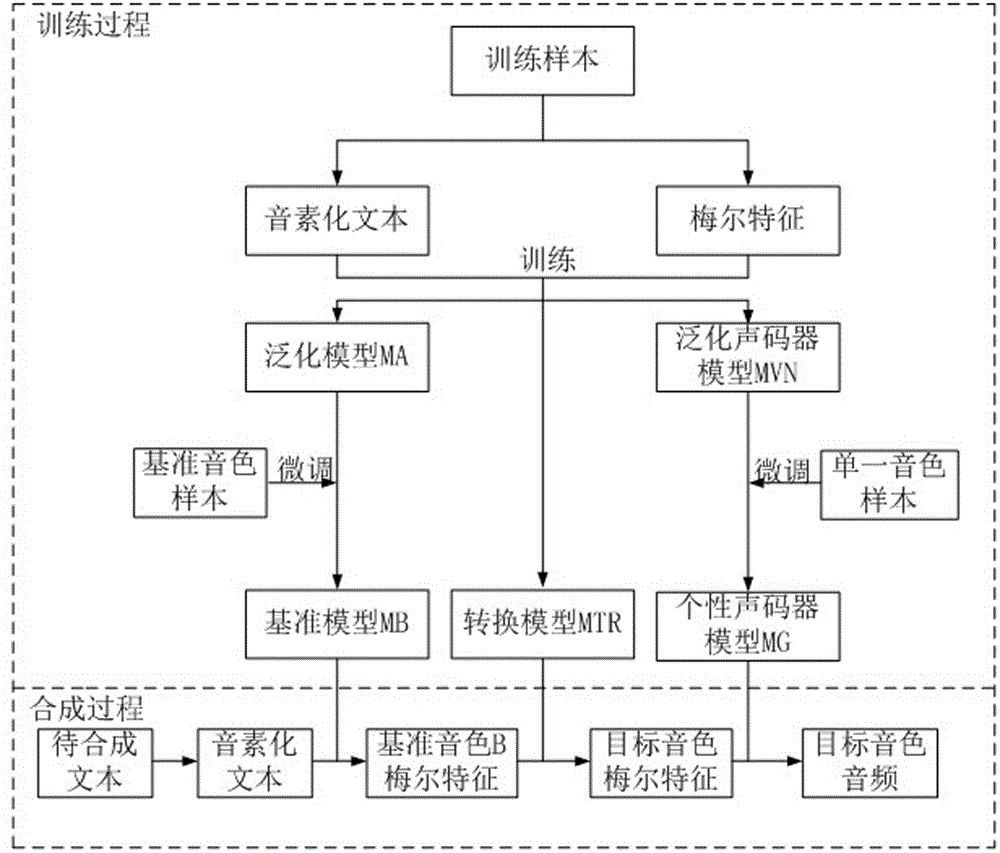
s1.收集训练样本集,所述训练样本集包括多个音色的样本,每一样本包括文本及对应的音频文件,其中至少1个音色的样本数据符合基准音色标准,所述基准音色标准为预设的标准;
s2.对各个样本的文本进行音素化处理,得到音素化文本;对各个样本的音频文件采用相同方法提取梅尔特征;在符合基准音色标准的样本中选择一个作为基准音色样本;
s3.对语音模型进行训练,得到泛化模型;训练方法为:所有样本的音素化文本作为输入,对应音频的梅尔特征作为输出,训练语音模型;
s4.将基准音色样本在泛化模型基础上做微调训练,得到基准模型;
s5.将训练样本集的所有样本按音色分类,训练音色转化的转换模型,每一类音色对应一个转换模型;
s6.使用训练样本集的所有样本训练泛化声码器模型,然后使用每个音色对应的样本分别在此泛化声码器模型上进行微调训练,得到每个音色对应的个性声码器模型。
优选的:所述步骤s3中的语音模型为tacotron、fastspeech模型中任意一种。
优选的:所述步骤s5中训练使用的转换模型为stargan-vc模型。
优选的:所述基准音色标准为样本的音频数据时间长度大于10小时。
优选的,所述样本的音频文件时间长度大于10分钟。
优选的,训练样本集中各个样本的文本完全不同。
优选的,所述语音合成包括如下步骤:
s7.将待合成文本进行预处理得到音素化文本,并输入基准模型mb,得到待合成文本基准音色的梅尔特征;
s8.将步骤s7得到的梅尔特征送入目标音色对应的转换模型mtr转化,得到目标音色的梅尔特征;
s9.将步骤s7中目标音色的梅尔特征送入对应音色的个性声码器模型mg,从而合成出指定音色的声音。
本发明相对传统的语音合成方法,通过基准音色生成基准模型,仅需要基准音色较大数据量,即可实现对其他音色的少语料训练并得到合成音频所需模型,模型训练时间缩短,通过转换模型和个性声码器模型训练,提升了后续语音合成效果。
附图说明
图1是本发明所述少语料的语音模型训练及合成方法的一个具体实施方式示意图。
具体实施方式
下面对本发明的具体实施方式作进一步的详细说明。
本发明所述少语料的语音模型训练及合成方法,包括如下步骤:
s1.收集训练样本集,所述训练样本集包括多个音色的样本,每一样本包括文本及对应的音频文件,其中至少1个音色的样本数据符合基准音色标准,所述基准音色标准为预设的标准;
s2.对各个样本的文本进行音素化处理,得到音素化文本;对各个样本的音频文件采用相同方法提取梅尔特征;在符合基准音色标准的样本中选择一个作为基准音色样本;
s3.对语音模型进行训练,得到泛化模型ma;训练方法为:所有样本的音素化文本作为输入,对应音频的梅尔特征作为输出,训练语音模型;
s4.将基准音色样本在泛化模型ma基础上做微调训练,得到基准模型mb;
s5.将训练样本集的所有样本按音色分类,训练音色转化的转换模型mtr,每一类音色对应一个转换模型mtr;
s6.使用训练样本集的所有样本训练泛化声码器模型mvn,然后使用每个音色对应的样本分别在此泛化声码器模型mvn上进行微调训练,得到每个音色对应的个性声码器模型mg。
一个具体的包括模型训练和语音合成的实施方式为:
1)准备多个种类目标音色的语料数据作为训练样本集,用于泛化模型训练,其中有一个音色b作为基准音色用于泛化模型微调,该基准音色的语料数据样本数据量大且质量高,例如一般大于10小时。如需训练多语种模型,则需提供各个语种的语料数据。
如背景技术所述,在语音合成技术中,音色指不同的发音类型,严格意义上说,即使年龄、性别、语种都相同,每个人的音色也不相同。传统语音合成方案每个音色数据都需要大量的训练数据才能合成准确的发音,本发明所提出的方案只需要提供一个音色的大量数据,有效节约训练成本。
每一训练样本集的语料数据包括文本和与文本对应的音频。
2)对训练样本集各个样本的文本进行文本归一化处理,对文本中的数字、单位、特殊字符等进行音素归一化处理,例如汉字转换为对应的拼音,其他语种转换为其对应的音素如英语转化为音标。归一化文本后得到音素化文本。
各语种的音素提取需要确保音素的唯一性,如果音素相同,则需要采用其他方式对相同音素进行标注实现区分,例如中文,英语,日语中均存在相同音素t,则需要添加标签进行区分,例如中文,英语,日语中的音素t分别修改为音素t1、音素t2和音素t3。音素提取后得到各个训练样本集的音素化文本。对音频进行处理,采样率归一化,并根据设置的采样率,匹配最佳参数后提取梅尔特征。
本发明所有模型训练中用到的梅尔特征的提取方式必须一致。
语音的时域信号(波形振幅)相比于频域信号如梅尔频谱特征(mel-spectrogram)更不稳定,可理解为听起来一样的语音在时域上波形可以差别很大,但是频域内会保持一致。所以语音处理领域通常将时域信号转为频域信号进行处理。梅尔频谱特征的典型提取步骤为分帧、预加重、加窗、短时傅里叶变换(stft)、得到梅尔刻度,着重提取人耳敏感特征,适合语音合成采用。
本发明中模型训练,可使用现有的公开的模型结构如tacotron、fastspeech等作为训练用模型。具体可按如下步骤进行:
3)将训练样本集所有样本的音素化文本作为输入,对应音频的梅尔特征作为输出,训练深度学习模型,模型名称标记为泛化模型ma。
所有样本作为输入可以提高该模型的泛化性,所训练出来的模型参数能够覆盖所有音色文本到梅尔特征的转换信息。
4)将基准音色b样本在泛化模型ma基础上做微调训练,得到音色b的声学模型,标记为基准模型mb。
在泛化模型ma上进行微调训练,由于泛化模型ma包含不同音色的数据特征,所以得到的模型参数更加稳定丰富,尤其对基准音色b的训练集里没有出现过的文本,微调训练相比于直接用基准音色b数据训练可以更好的提取未出现文本的梅尔特征;相比于直接采用基准音色b的数据进行训练,拟合效果更优。
5)将所有样本按音色分类,训练音色转化的转换模型mtr,转换模型mtr可实现基准音色b到其他音色的梅尔特征的转换,每一类音色对应一个转换模型mtr。
音色转换模型实现梅尔特征间的转换,与训练样本集的文本具体内容无关,且能够基于较少数据量实现转换。现有公开模型如stargan-vc模型已验证音色转换模型在较少如几分钟的数据量上也能完成转换并达到较好的转换效果,可参考论文《stargan-vc:non-parallelmany-to-manyvoiceconversionwithstagan》(2018ieeespokenlanguagetechnologyworkshop(slt),作者hirokazukameoka,takuhirokaneko,koutanaka,nobukatsuhojo)。
6)使用所有语料数据训练泛化声码器模型mvn,然后每个音色分别在此泛化声码器模型mvn上进行微调训练,得到每个音色对应的个性声码器模型mg。
由于小语料训练声码器模型难以拟合,本发明在所有语料数据上训练出声码器模型后,每个音色再微调训练,保证了音色数据在少量语料数据下也能合成出正确的音频信息,每个音色都微调训练又强化了每个音色的个性化特征。
通过上述步骤,利用训练样本集的音素化文本、梅尔特征、音频进行模型训练,得到了泛化模型ma、基准模型mb、转换模型mtr、泛化声码器模型mvn和个性声码器模型mg。利用这些模型可以进行合成目标音色音频,具体地:
7)将待合成文本进行预处理后,作为基准模型mb的输入,得到b音色的梅尔特征。
8)将步骤7)得到的梅尔特征送入目标音色y对应的转换模型mtr转化,得到目标音色的梅尔特征。
9)将步骤8)中目标音色的梅尔特征送入对应音色的个性声码器模型mg,从而合成出指定音色的声音。
传统的端到端语音合成算法通常在泛化模型上直接微调finetune声学模型,然后送入声码器,在少训练样本集集的情况下,微调finetune效果不理想,声码器部分也不能准确区分不同音色间的个性化差异。本发明专利提出的一种少语料语音合成训练方法,声学基础模型和声码器基础模型均在所有训练语料上进行训练得到,所以在此基础模型上微调finetune的模型既能保证大模型的泛化性,又能准确拟合音色数据不足情况下模型的参数。少语料音色数据的梅尔特征不采用直接用声学模型推理得到的方式,而是采用音色转换模型来提取,由于大语料音色数据b的梅尔特征预测已经非常准确,所以再将b的梅尔特征送入音色转换模型,得到目标音色的梅尔特征,这样既解决了目标音色语料不足对不同文本的合成问题,音色转换模型也大大降低了对训练语料数量的需求。本发明方案在音色数据不足的情况下,提高了其语音合成效果。
所述的微调训练(finetune)指:首先用大量数据训练基础模型,然后采用少量数据在基础模型上继续叠加训练。由于深度学习模型通常具有大量的参数,如果作为训练样本集的数据量少,容易导致模型不收敛或过度拟合(即训练集上效果很好,测试集上效果差)等,泛化能力差。而采用微调finetune的方式训练,由于大量样本训练好的基础模型已经能够表述目标模型的大部分特征,所以只需要在基础模型上继续叠加训练就能拟合小样本数据又不缺失小样本数据不包含的大量特征。
微调采用单一样本以其归一化后的音素化文本作为输入,梅尔特征作为输出进行重复训练,微调中,具体训练方式可变,如可调整训练参数batch-size,学习率(learning_rate)等,也可固定模型某些层的参数,只更新指定层参数修改训练集。
所述的梅尔特征即梅尔频谱特征mel-spectrongram,具体的提取方法为对语音时域信号即原始波形数据进行如下处理:分帧、预加重、加窗、短时傅里叶变换(stft);即可得到梅尔特征。
一个具体实施方式为:
①准备训练语料,准备5个音色的训练语料数据作为训练样本集,包含4个中文语种和1个英文语种的音频及对应文本,5个音色中有一个中文语种的音色b音频数据量最好在10小时以上;剩余音色每个的数据量大于10分钟,各个训练样本集的文本不一致,以保证文本数据的多样性。
音色指不同的发音类型,也与性别年龄等有关,可以用性别、年龄、发音风格、语言等因素定义,例如可以设置(青年、女性、严肃、中文)为基准音色b,其余四个音色分别为(青年、女性、温柔、中文)、(青年、女性、可爱、中文)、(儿童、女性、可爱、英文)、(老年、女性、严肃、中文)。
②文本归一化处理,对文本中的数字、单位、特殊字符等进行归一化处理;对中文语种的汉字转换为对应的音素即汉语拼音,英语语种转换为其对应的音素即音标,并保证中英文不同语种间的音素表示符号不要重复,进行上述处理后得到音素化文本。
对所有样本的音频进行处理,统一采样率,并根据设置的采样率,匹配最佳参数提取梅尔特征,梅尔特征的具体提取在本领域为现有技术,在此不再赘述。
③模型训练:
a1)训练声学模型,对所有样本的音素化文本进行唯一编码,作为模型输入;对应训练样本集的音频梅尔特征作为模型输出,训练模型;该模型可实现由文本生成对应的梅尔特征。得到泛化模型ma。
b1)将具有大样本的基准音色b数据在泛化模型ma的基础上做微调训练,得到基准模型mb。
c1)将所有数据按音色分类,训练音色转化的转换模型mtr,此转换模型mtr可实现基准音色b到其他音色的梅尔特征的转换,每一类音色对应一个转换模型mtr。
d1)采用所有样本训练声码器模型,模型输入为梅尔特征,该梅尔特征与上述步骤a1)中所用的梅尔特征保持一致;原始音频文件作为模型输出。该模型实现的功能为梅尔特征到音频文件的转换,训练好的模型为泛化声码器模型mvn。
然后每个音色分别在泛化反解码模型mvn上进行微调finetune训练,得到每个音色对应的个性声码器模型mg。
至此,通过利用训练样本集的音素化文本、梅尔特征、音频进行模型训练,得到了泛化模型ma、基准模型mb、转换模型mtr、泛化声码器模型mvn和个性声码器模型。
④合成目标音色音频,目标为将一个待合成文本合成为具有目标音色y的音频文件。
a2)将待合成文本进行预处理,具体处理方式与之前训练过程中对样本的文本处理方式相同,得到该文本对应的音素化文本,将该音素化文本作为基准模型mb的输入,从而得到待合成文本的基准音色b的梅尔特征。
b2)将步骤a2)得到的基准音色b的梅尔特征送入目标音色y对应的转换模型mtr转化,得到目标音色y的梅尔特征。
以往的合成方式中直接由声学模型得到梅尔特征,由于目标音色训练数据量少,所以对不同文本拟合效果相对更差,且不能合成该音色其他语种的文本,如目标音色训练集只有中文数据,则不能合成英语文本;而本发明中,由于基准音色b是基准音色对应的大训练集得到,所以基准音色b的梅尔特征预测更加准确,转换模型mtr只是对梅尔特征进行变换,与文本无关,因此目标音色的梅尔特征比直接采用其声学模型得到的梅尔特征对不同的文本适应性更好。而且对于不同语种,即使目标音色的训练集里没有该语种的语料,也能通过基准音色b得到的该语料的梅尔特征得到对应语种的梅尔特征,实现目标音色不同语种的合成。
c2)将步骤b2)得到的目标音色y的梅尔特征送入该目标音色y对应的个性声码器模型,从而合成出该音色的声音。声码器的输入只与梅尔特征有关,所以输入不同音色,不同语料的梅尔特征时,则生成对应的合成音频。
本发明中的技术效果采用语音合成领域最常用的mos打分的方式体现,即由不同的人分别对原始音频和合成的音频进行mos打分(总分5分),最后求平均值。对清晰度、自然度、可理解性等方面进行综合打分。
准备基准音色b中文语料约10个小时,其余八个普通音色1-8,每个音色的语料约20分钟,英语音色e一个,英语语料约10个小时。
采用本发明训练方法进行训练后,完成后得到多个个性声码器模型作为模型1,模型2为利用相同语料,采用传统方法进行训练后得到的声码器模型。
多个听众对由个性声码器模型对输入的中文或英文文本合成的音频进行听音打分,取平均值作为最终分数。采用国际通用的mos(meanopinionscore)测试。mos是一种主观测试方法,将用户接听和感知语音质量的行为进行调研和量化,由不同的调查用户分别对原始标准语音和合成或衰减后声音进行主观感受对比,评出mos分值。具体打分标准如下表:
以下给出采用mos评分由50人听音打分后的分值,模型1-音色b表示利用本发明训练得到的个性声码器模型,选择对应音色b的个性声码器模型合成相应音色b的音频文件;模型2-音色b表示利用传统方法得到的模型2合成音色b的音频文件;其余以此类推。
统计后具体数值如下表:
由上表可见,本发明得到的个性化声码器模型合成出的音频文件,在相同语种的得分均高于传统模型2的得分,无论是基准音色还是普通音色,模型1对应的各项打分在中英文文本上均高于模型2,与原始音频的分数差距也较小。
而由于模型2采用传统方法训练,中文声码器模型无法合成英文文本,反之亦然,因此打分为零,具体表现为合成的跨语种音频完全为噪音。而本发明采用的个性声码器模型对英文文本均能合成,其中英文音色e对应的个性声码器模型对英文文本合成分数最高,基准音色b由于训练数据量大,对应的声码器模型对英文文本合成分数也较好,即使是数据量小的普通音色1也能合成出英文文本对应的音频,且得分较为接近3.0的中等评分标准。
前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

