本发明属于语音合成领域,尤其涉及一种音色克隆方法、系统、装置及计算机可读存储介质。
背景技术:
传统的语音合成方法需要在专业录音设备和环境中采集大量的语音合成数据,才可以得到具有语音合成的能力,数据整体制作时间周期长,数据采集成本高。目前还存在一种录制少量语音合成数据,通过音色克隆的方法进行语音合成的方式,但该方式对目标说话人的音色还原效果差,且对不同的目标说话人均需要训练专门的声纹模型,整个计算和部署流程繁琐,需要大量的成本投入。
技术实现要素:
本发明主要解决了传统的语音方法需要大量采集语音数据或是合成的语音与目标说话人音色差别过大,过程繁琐的问题,提供了一种利用多说话人数据集训练得到多说话人语音合成模型,再利用目标说话人数据集对多说话人语音合成模型进行微调训练得到具备目标说话人音色的目标人语音合成模型,只需采集少量目标人语音数据,目标人语音合成快速,所需成本投入较低的一种音色克隆方法、系统、装置及计算机可读存储介质。
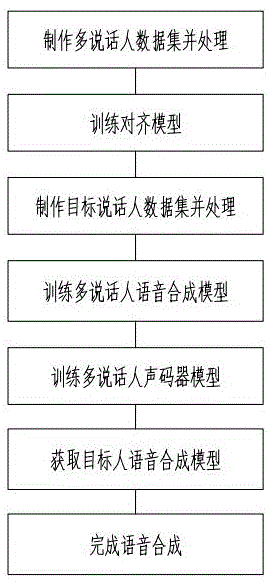
本发明解决其技术问题所采用的技术方案是,一种音色克隆方法,包括以下步骤:
s1:制作多说话人数据集并处理;
s2:利用多说话人数据集训练对齐模型;
s3:制作目标说话人数据集并处理;
s4:利用多说话人数据集训练多说话人声码器模型;
s5:利用多说话人数据集训练多说话人语音合成模型;
s6:利用目标说话人数据集和多说话人语音合成模型获取具有目标说话人音色的目标人语音合成模型;
s7:将待合成文本输入至目标人语音合成模型进行语音合成任务。
利用多说话人数据集进行多说话人语音合成模型的训练,使得多说话人语音合成模型中包含多中音色,在获得目标说话人数据集后,生成的目标人语音合成模型能够更好的学习说话人的风格和音色。
作为上述方案的一种优选方案,所述s1包括以下步骤:
s11:制作录音文本;
s12:选择多个录音人在标准录音环境下根据录音文本进行录音;
s13:基于录音和录音文本进行发音一致性校对,人工标注发音序列,添加韵律标签;
s14:提取各个录音对应的梅尔频谱特征、音高特征、能量特征,并对发音序列进行编码。
录音文本从公开文本中筛选得到,包含全部音节及大部分双音节和三音节词汇,覆盖90%以上的汉语常见韵律段,确保训练出来的多说话人语音合成模型能够覆盖绝大多数的音节和韵律;通过提取音高特征和能量特征提高语音合成效果。
作为上述方案的一种优选方案,所述步骤s3包括以下步骤:
s31:录取目标说话人朗读指定文本的音频以及文本对应的人工标注发音序列与韵律标签;
s32:提取音频的梅尔频谱特征、音高特征和能量特征。
s33:使用对齐模型获取发音序列的时长信息。
通过提取音高特征和能量特征提高语音合成效果。
作为上述方案的一种优选方案,所述多说话人语音合成模型包括音素序列与韵律序列混合编码网络、说话人信息编码网络、skipencoder跳跃编码网络、duration时长预测网络、lengthregulator对齐网络、能量编码网络、能量预测网络、音高编码网络、音高预测网络和decoder解码网络。
作为上述方案的一种优选方案,所述多说话人声码器模型为multibandmelgan声码器。
作为上述方案的一种优选方案,所述步骤s4中,对多说话人语音合成模型进行训练时,利用音素序列与韵律序列混合编码网络获取韵律信息,在skipencoder跳跃编码网络中添加韵律信息获得第一阶段编码信息,第一阶段编码信息作为音高预测网络和能量预测网络的输入,预测当前的音高特征和能量特征,预测得到的音高特征和能量特征由音高编码网络和能量编码网络进行编码,获得第二阶段编码信息,将第一阶段编码信息和第二阶段编码信息进行相加后送入decoder解码网络进行解码。
在编码时添加韵律信息,让skipencoder跳跃编码网络学习到韵律标签对于发音行为的影响,实现通过指定韵律标签的方式来指定韵律节奏;在解码时添加音高和能量的预测和编码,提高语音合成的效果。
作为上述方案的一种优选方案,所述步骤s6中,对多说话人语音合成模型进行finetune微调训练,训练时固定多说话人语音合成模型中的音素序列与韵律序列混合编码网络、skipencoder跳跃编码网络、duration时长预测网络、lengthregulator对齐网络、能量编码网络和音高编码网络,令说话人信息编码网络、能量预测网络、音高预测网络和decoder解码网络参与训练。
通过finetune微调训练对人信息编码网络、能量预测网络、音高预测网络和decoder解码网络等直接影响音色变化的网络进行训练,使得通过学习目标说话人数据集,使得目标说话人编码信息与其音色对应,最终得到具有目标说话人音色信息的神经网络结构。
对应的,本发明还提供一种音色克隆系统,包括:
多说话人数据采集与存储模块,用于制作多说话人数据集并进行存储
目标说话人数据采集模块,用于采集目标说话人音频信息生成目标说话人数据集;
第一训练模块,用于基于多说话人数据集训练对齐模型;
第二训练模块,用于基于多说话人数据集训练多说话人声码器模型;
第三训练模块,用于基于多说话人数据集训练多说话人语音合成模型;
目标人语音合成模型生成模块,用于基于目标说话人数据集和多说话人语音合成模型生成目标人语音合成模型;
合成模块,用于根据待合成文本和目标人语音合成模型生成目标人语音。
对应的,本发明还提供一种音色克隆装置,包括:处理器以及存储计算机可执行指令的存储器,所述计算机可执行指令在被执行时所述处理器执行上述优选方案任一项所述的方法。
对应的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储一个或多个程序,当所述一个或多个程序被处理器执行时,实现上述优选方案任一项所述的方法。
本发明的有益效果是:使用多说话人数据集进行语音合成模型的训练,包含多种音色,通过finetune微调训练,目标说话人的风格和音色能够被更好的学习;在编码阶段添加韵律信息,让skipencoder跳跃编码器学习到韵律标签对于发音行为的影响,从而在使用阶段可以通过指定韵律标签的方式来指定韵律节奏;使用时长预测模型来进行发音序列与频谱序列的对齐,加快语音生成的推理速度;在解码阶段添加音高和能量的预测和编码,目标人语音合成模型添加了音高和能量的预测与编码,将其作为一个单独的预测模块,有效的提高语音合成的效果。
附图说明
图1为实施例中音色克隆方法的一种流程示意图。
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步的说明。
实施例:
本实施例一种音色克隆方法,如图1所示:包括以下步骤:
s1:制作多说话人数据集并处理,具体包括以下步骤:
s11:制作录音文本,录音文本从网络公开文本中筛选得到,要求文本包含《新华字典》中的全部音节,覆盖汉语中90%以上的双音节与三音节词汇,覆盖90%以上的汉语常见韵律段;
s12:选择多个录音人朗读录音文本并录音;在录音时需在专业录音环境下进行,录取的音频应为48khz;
s13:基于录音和录音文本进行发音序列一致性校对,由人工进行发音序列与音频的一致性;
s14:提取各个录音对应的梅尔频谱特征、音高特征、能量特征,并对发音序列进行编码。进行梅尔频谱特征提取时,令
其中,
将计算得到的线性谱通过梅尔滤波器
进行能量特征提取时,将梅尔频谱
进行音高特征提取时,使用公开算法
将
s2:利用多说话人数据集,使用开源工具montreal-forced-aligner训练对齐模型,使用对齐模型,提取多说话人数据集中发音序列对应的发音时长信息。
s3:制作目标说话人数据集并处理,具体包括以下步骤:
s31:录取目标说话人朗读指定文本的音频;录制时,目标说话人在安静环境下,阅读10句指定文本,使用手机录制16khz采样率音频;
s32:手工标注文本的发音序列和韵律标签,利用开源工具montreal-forced-aligner加载训练好的对齐模型,对发音序列的发音时长进行提取,得到与音频对应的对齐信息;提取音频的梅尔频谱特征,音高特征,能量特征。
s4:利用多说话人数据集训练多说话人语音合成模型,多说话人语音合成模型包括音素序列与韵律序列混合编码网络、说话人信息编码网络、skipencoder跳跃编码网络、duration时长预测网络、lengthregulator对齐网络、能量编码网络、能量预测网络、音高编码网络、音高预测网络和decoder解码网络。对多说话人语音合成模型进行训练时,利用音素序列与韵律序列混合编码网络获取韵律信息,在skipencoder跳跃编码网络中添加韵律信息获得第一阶段编码信息,第一阶段编码信息作为音高预测网络和能量预测网络的输入,预测当前的音高特征和能量特征,预测得到的音高特征和能量特征由音高编码网络和能量编码网络进行编码,获得第二阶段编码信息,将第一阶段编码信息和第二阶段编码信息进行相加后送入decoder解码网络进行解码。
s5:利用多说话人数据集训练多说话人声码器模型,多说话人声码器模型为multibandmelgan声码器;
s6:利用目标说话人数据集和多说话人语音合成模型获取具有目标说话人音色的目标人语音合成模型;该步骤采用finetune微调训练,训练时固定多说话人语音合成模型中的音素序列与韵律序列混合编码网络、skipencoder跳跃编码网络、duration时长预测网络、lengthregulator对齐网络、能量编码网络和音高编码网络,令说话人信息编码网络、能量预测网络、音高预测网络和decoder解码网络参与训练。其中,音素序列与韵律序列混合编码网络、skipencoder跳跃编码网络、能量编码网络和音高编码网络为信息编码网络,不参与finetune微调训练,使用多说话人数据集训练得到的参数信息,可保持整体发音效果的稳定性,不会因为目标说话人的小数据样本,导致整体的效果出现较大的波动,过度拟合。duration时长预测网络直接影响说话人的风格,由于小样本的说话人风格存在较大波动,网络难以学习,所以这部分不参与finetune微调过程,在推理合成阶段,可借助其他在多说话人数据集中的风格特征,或使用默认风格特征。lengthregulator对齐网络不涉及带梯度的参数,不参与训练过程。说话人信息编码网络、能量预测网络、音高预测网络和decoder解码网络直接影响音色的效果变化,这些网络通过学习目标说话人数据集,使得目标说话人编码信息与其音色对于,最终得到具有目标说话人音色信息的神经网络结构
s7:将待合成文本输入至目标人语音合成模型完成语音合成。
对应的本实施例还提供一种音色克隆系统,包括:
多说话人数据采集与存储模块,用于制作多说话人数据集并进行存储
目标说话人数据采集模块,用于采集目标说话人音频信息生成目标说话人数据集;
第一训练模块,用于基于多说话人数据集训练对齐模型;
第二训练模块,用于基于多说话人数据集训练多说话人声码器模型;
第三训练模块,用于基于多说话人数据集训练多说话人语音合成模型;
目标人语音合成模型生成模块,用于基于目标说话人数据集和多说话人语音合成模型生成目标人语音合成模型;
合成模块,用于根据待合成文本和目标人语音合成模型生成目标人语音。
本实施例还提供一种音色克隆装置,包括但不限于处理器以及存储计算机可执行指令的存储器,计算机可执行指令在被执行时所述处理器执行本实施例中音色克隆方法。
本实施例还提供一种,所述计算机可读存储介质存储一个或多个程序,当所述一个或多个程序被处理器执行时,实现权利要求1-7任一项所述的方法。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

