本发明涉及一种智能辅助技术,尤其涉及一种辅助歌唱系统、辅助歌唱方法及其非瞬时计算机可读取记录媒体。
背景技术:
现有的歌唱装置能够于播放伴唱带时供使用者自行调整伴奏音乐的音调高低,但当使用者唱歌偏离音准时(即走音),歌唱装置并无法提供任何帮助。又如使用者唱歌时会发生忘词或忘记歌词旋律,歌唱装置仅能将原唱歌声播放出来帮助使用者(即俗称之导唱模式),这仅能帮助使用者私下练习,无助于使用者唱歌演出。
技术实现要素:
有鉴于此,本发明实施例提出一种辅助歌唱系统、辅助歌唱方法及其非瞬时计算机可读取记录媒体。
在一实施例中,辅助歌唱系统包括收音装置、处理装置及播放装置,辅助歌唱方法是关于接唱程序。收音装置接收演唱歌声。处理装置检测演唱歌声是否出现在应演唱期间,若否,则执行接唱程序。接唱程序配合包括编码器及译码器的声学模型执行。声学模型经由原唱者训练数据训练之后获得原唱者声学模型,声学模型经由使用者训练数据训练之后获得使用者声学模型。接唱程序包括:转换原唱者声音片段为原唱者声学特征;输入原唱者声学特征至原唱者声学模型中的编码器中;以使用者声学模型中的译码器接收原唱者声学模型中的编码器的输出;从使用者声学模型中的译码器的输出获得使用者声学特征;及由声码器将使用者声学特征转换为合成歌声。续而,播放装置输出合成歌声。
在一实施例中,辅助歌唱系统包括收音装置、处理装置及播放装置,辅助歌唱系统是关于音准调整程序。收音装置接收演唱歌声。处理装置判断演唱歌声的演唱音准相比于原唱歌声的原唱音准是否一致,若不一致,则对演唱歌声执行音准调整程序。音准调整程序配合包括另一编码器及另一译码器的音准模型执行。音准模型经由原唱者训练数据训练之后获得原唱者音准模型,音准模型经由使用者训练数据训练之后获得使用者音准模型。音准调整程序包括:将演唱歌声转换为使用者声音频谱;将原唱歌声转换为原唱者声音频谱;输入使用者声音频谱至使用者音准模型中的编码器中,以获得使用者声学特征;输入原唱者声音频谱至原唱者音准模型中的编码器中,以获得原唱者基频;将使用者声学特征及原唱者基频输入至使用者音准模型中的译码器;从使用者音准模型中的译码器的输出获得经调整的使用者声音频谱;及将经调整的使用者声音频谱转换为经调整音准的演唱歌声。续而,播放装置输出经调整音准的演唱歌声。
综上所述,根据本发明的实施例,通过检测在应演唱期间使用者是否歌唱来决定是否执行接唱程序,使得使用者在忘词或因故停止歌唱的时候,可以自动以使用者的声音接续歌唱。通过接唱程序,所产生的接唱歌声可保持如同原唱的音准,并且由于采用自编码器架构的模型,接唱歌声可以如同使用者的音色一般。此外,通过检测使用者的歌唱音准,可以在使用者音准偏离的时候,执行音准调整程序。通过音准调整程序,可以自动调整音高,并且由于采用自编码器架构的模型,可以保持原本使用者的音色。
附图说明
图1为本发明一实施例的辅助歌唱系统的架构示意图。
图2为本发明一实施例的处理装置的架构示意图。
图3为本发明一实施例的供执行辅助歌唱方法的计算机程序产品的方块示意图。
图4为本发明一实施例的辅助歌唱方法流程图。
图5为本发明一实施例的声学模型的架构示意图。
图6为本发明一实施例的接唱程序流程图。
图7为本发明一实施例的接唱模块的架构示意图。
图8为本发明一实施例的音准模型的架构示意图。
图9为本发明一实施例的音准调整程序流程图。
图10为本发明一实施例的音准调整模块的架构示意图。
其中,附图标记:
辅助歌唱系统100
收音装置110
处理装置120
播放装置130
处理器121
中央处理单元1213
神经网络处理器1215
内存122
挥发性内存1224
非挥发性内存1226
非瞬时计算机可读取记录媒体123
周边接口124
总线125
计算机程序产品300
人声歌唱检测模块310
接唱模块320
特征分析单元321
声码器322
音准调整模块330
转换单元331
声码器332
音乐分离模块340
混音模块350
步骤s401、s402、s403、s404、s405
声学模型500
混合声学模型500’
编码器510
卷积层511
门控线性单元512
残差块513
译码器520
反卷积层521
门控线性单元522
步骤s601、s602、s603、s604、s605
音准模型800
编码器810
使用者音准模型编码器810a
原唱者音准模型编码器810b
卷积层811
译码器820
使用者音准模型译码器820a
卷积层821
门控循环单元822
后网络830
反卷积层831
步骤s901、s902、s903、s904、s905、s906、
s907
具体实施方式
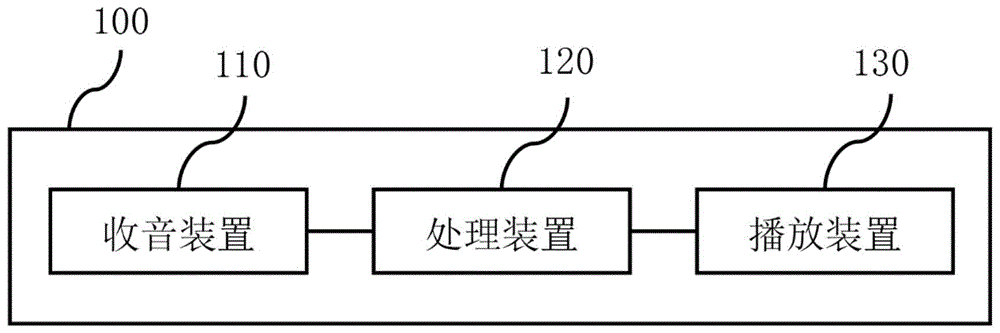
参照图1,为本发明一实施例的辅助歌唱系统100的架构示意图。辅助歌唱系统100包括依序连接的收音装置110、处理装置120及播放装置130。收音装置110与处理装置120之间可以通过有线通信方式(如导线、符合某种通信协议(如通用串行总线(usb))的传输线)或无线通信方式(如蓝牙、无线网络)连接。播放装置130与处理装置120之间可以通过有线通信方式(如导线、传输线)或无线通信方式(如蓝牙、无线网络)连接。
收音装置110用以撷取使用者的演唱歌声,其包括单一麦克风或多个麦克风(如麦克风数组)。麦克风可以采用如动圈式麦克风、电容式麦克风、微机电麦克风等类型。
处理装置120选择性地对收音装置110收取的演唱歌声执行辅助歌唱处理,即辅助歌唱方法(于后详述)。处理装置120为一个或多个具有运算能力的计算机系统,例如个人计算机、笔记本电脑、智能型手机、平板电脑、服务器群集等。参照图2,为本发明一实施例的处理装置120的架构示意图。处理装置120具有处理器121、内存122、非瞬时计算机可读取记录媒体123、供连接收音装置110和播放装置130的周边接口124及供上述元件彼此通信的总线125。总线125包括但不限于系统总线、内存总线、周边总线等一种或多种的组合。处理器121包括但不限于中央处理单元(cpu)1213和神经网络处理器(npu)1215。内存122包括但不限于挥发性内存1224(如随机存取内存(ram))和非挥发性内存1226(如只读存储器(rom))。非瞬时计算机可读取记录媒体123可例如为硬盘、固态硬盘等,供储存包括多个指令的计算机程序产品300(如图3所示),致使计算机系统的处理器121执行该些指令时,使得计算机系统执行所述辅助歌唱方法。
复参照图1,播放装置130用以播放经处理装置120执行或未执行辅助歌唱处理的演唱歌声,其包括单一喇叭或多个喇叭。喇叭可以采用如动圈式喇叭、动铁式喇叭等类型。
在一些实施例中,收音装置110、处理装置120及播放装置130中的任两者可以是以单一个体形式实现。例如,收音装置110和播放装置130为耳机麦克风的单一装置。又如,收音装置110和处理装置120为智能型手机的单一装置实现,而连接一外接形式的播放装置130。或者,播放装置130和处理装置120为个人计算机的单一装置实现,而连接一外接形式的收音装置110。又或者,收音装置110、处理装置120及播放装置130为笔记本电脑的单一装置实现。
在一些实施例中,收音装置110、处理装置120及播放装置130可以是分别独立的个体。例如,处理装置120为一个人计算机,分别连接外接形式的收音装置110及播放装置130。
在一些实施例中,处理装置120包括两个以上的计算机系统,例如:一个人计算机及一服务器。服务器提供前述的辅助歌唱处理。个人计算机内建或外接收音装置110及播放装置130,以将演唱歌声经由网络传送给服务器处理,并经由网络接收服务器回传的经处理的演唱歌声。
合并参照图3及图4,图3为本发明一实施例的供执行辅助歌唱方法的计算机程序产品300的方块示意图,图4为本发明一实施例的辅助歌唱方法流程图。计算机程序产品300包括人声歌唱检测模块310、接唱模块320、音准调整模块330、音乐分离模块340及混音模块350。
首先,音乐分离模块340对使用者欲演唱的歌曲档案进行音乐分离,也就是从歌曲中分别取出伴奏音乐及原唱者的歌声(后称“原唱歌声”)。音乐分离模块340可由强固主成分分析(robustprincipalcomponentanalysis,rpca)、重复特征撷取技术(repeatingpatternextractiontechnique,repet)、卷积神经网络(convolutionalneuralnetworks,cnn)或深度循环神经网络(deeprecurrentneuralnetworks,drnn)等算法实现。其中在使用rpca或repet时,是先假设音乐中伴奏部份会不断的重复出现(因为乐器声音较人声固定),这两个算法是用来找出重复出现的内容,因此即可将这重复出现的部分(即音乐伴奏)抽离出来,进而可得知人声的部分,而能将音乐与人声分离开来。而cnn与drnn则是通过有深度学习过的神经网络模型来分离音乐与人声,即给定输入为一有音乐伴奏的人声至该神经网络模型,接着此神经网络模型通过经过深度学习而得到的参数能自动输出为纯音乐伴奏与纯人声,其中,此神经网络模型能通过训练让神经网络习得如何将人声从歌曲中分离出来更为精确。
在步骤s401中,人声歌唱检测模块310对收音装置110接收到的声音进行检测,以检测演唱歌声是否出现在应演唱期间。所述应演唱期间可根据原唱歌声出现的时间区间来获得。人声歌唱检测模块310可由分类与回归树(classificationandregressiontree,cart)、语音活动检测(voiceactivitydetection,vad)、vadnet等算法实现。若在应演唱期间没有检测到演唱歌声,则进入步骤s402;若在应演唱期间检测到演唱歌声,则进入步骤s403。
在步骤s402中,接唱模块320执行接唱程序(于后详述),接唱程序能自行产生应演唱的歌声(后称“合成歌声”),借此能于使用者忘词的情形提供帮助。
在步骤s403中,音准调整模块330判断演唱歌声的音准(后称“演唱音准”)相比于原唱歌声的音准(后称“原唱音准”)是否一致。若不一致,则进入步骤s404;若一致,则进入步骤s405。
其中,音准调整模块330对于音准是否一致的判断,可基于标准化交叉相关(normalizedcrosscorrelation)算法或和弦音高检测(polyphonicpitchdetection)算法等实现,这些方法通过找出音信中重复出现的波形,计算这些波形出现的时间间隔,便可得到每个波形所需的时间,也就是周期,进而可以经由周期计算出音信的音准(或音频)。借此分别找出歌手与使用者的音准进行判别(如相减的方式),即可判断音准是否一致,如果一致,即表示使用者与歌手的音准是相等,若判断不一致,则表示使用者的音准不等于歌手的音准。本发明并非以此为限制,另于一些实施例中,也可使用开源软件如“world”或“straight”等取出人声音准以进行比对,换句话说,此些开源软件任一者可将人声音准转换成声音参数后,以供后续进行比对。
在步骤s404中,音准调整模块330执行音准调整程序(于后详述),借此将演唱音准调整至原唱音准,以改善走音的现象。
在步骤s405中,混音模块350对于无需调整的演唱歌声、经过步骤s402产生的合成歌声和经过步骤s404调整音准的演唱歌声,将其与音乐分离模块340分离出的伴奏音乐相混合,以经由播放装置130输出。
在说明接唱程序之前,先说明接唱程序所使用到的声学模型。参照图5,为本发明一实施例的声学模型500的架构示意图。声学模型500是一种监督学习方式的神经网络模型,包括编码器510及译码器520,也就是为自编码器(autoencoder)架构。编码器510可对所输入的声学特征转换为特征向量;译码器520则将特征向量转换为声学特征。在经过输入特定人员的大量训练数据(例如带有文字的声音)至声学模型500之后,可收敛出权重参数,此些权重参数搭配此声学模型500,即为训练好的关于此特定人员的声学模型500。其中训练数据即为该人员的大量声音音信。例如,提供大量有关使用者的声音档案作为训练数据(即原唱者训练数据),可训练出使用者声学模型500;提供大量有关歌手(即前述原唱者)的声音档案作为训练数据(即使用者训练数据),可训练出原唱者声学模型500。换言之,利用关于不同人的训练数据,可训练出具有不同权重参数的声学模型500。另外,在一些实施例中,声学模型500也可让特定人员实时以说大量词句或唱大量的歌曲的方式输入而建构完成。
在一些实施例中,如图5所示,编码器510包括一卷积(convolution)层511、一门控线性单元(gatedlinearunit,glu)512及六层残差块(residualblock)513;译码器520包括一反卷积(deconvolution)层521及一门控线性单元522。然而,本发明实施例的编码器510和译码器520并非以上述组成为限。
参照图6,为本发明一实施例的接唱程序流程图。在步骤s601中,将原唱者声音片段转换为声学特征(后称“原唱者声学特征”)。在此,原唱者声学特征可为梅尔倒频谱系数(melfrequencycepstralcoefficents,mfccs),但本发明实施例非以此为限,也可以是例如频谱包络(spectralenvelope)、基频(fundamentalfrequency)、非周期信号(aperiodicity)。在此,可先对原唱者声音片段进行预处理,例如将原唱歌声与伴奏音乐分离,以使用单纯的原唱歌声进行声学特征转换。
在步骤s602中,将原唱者声学特征输入至原唱者声学模型500中的编码器510中,由于原唱者声学模型500具有对应于原唱者的权重参数,因此编码器510可借此输出相应于原唱者声学特征的特征向量。在步骤s603中,以使用者声学模型500中的译码器520接收原唱者声学模型500中的编码器510输出的特征向量。在步骤s604中,由于使用者声学模型500具有对应于使用者的权重参数,因此从使用者声学模型500中的译码器520输出可以获得使用者声学特征(后称“第一使用者声学特征”)。在步骤s605中,由声码器(如图7所示)将第一使用者声学特征转换为合成歌声。借此,产生的接唱歌声可保持如同原唱的音准,且该歌声如同使用者的音色一般。
参照图7,为本发明一实施例的接唱模块320的架构示意图。在一些实施例中,接唱模块320包括特征分析单元321,以从原唱者声音片段获得梅尔倒频谱系数(mfccs)、基本频率(fundamentalfrequency)、频谱包络(spectralenvelope)及非周期信号(aperiodicity)中任一者声纹信息。特征分析单元321包括多种算法,以估算出上述声纹信息。通过例如dio、yin或swipe算法获得基本频率。这些方法通过找出音信中重复出现的波形,计算这些波形出现的时间间隔,便可得到每个波形所需的时间,也就是周期,进而可以计算出音信的音准(基本频率)。通过例如platinum算法(platforminferencebyremovingunderlyingmaterial)获得非周期信号。因为非周期信号通常是音频中极高频的部份。所谓的极高频的部份就是变化非常快的部份,platinum算法就是找出音频中的音频变化的极大值,即为非周期信号。梅尔倒频谱系数的取得方式是,对原唱者声音片段分帧、加窗(windowing),并对每一帧做傅立叶变换(ft),再将每一帧的结果堆叠,可获得声谱图。再通过梅尔标度滤波器(mel-scalefilterbanks)将声谱图转换为梅尔频谱。并且,将梅尔频谱进行对数处理(log)与反傅立叶变换(inverseft)后,便可取得梅尔倒频谱系数。
在一些实施例中,特征分析单元321通过例如cheaptrick算法获得频谱包络。
如图7所示,将梅尔倒频谱系数输入至混合声学模型500’(包括原唱者声学模型500中的编码器510及使用者声学模型500中的译码器520),通过前述步骤s602~s604,可获得第一使用者声学特征(在此为梅尔倒频谱系数)。声码器322除了依据梅尔倒频谱系数产生合成歌声之外,还结合了基本频率、非周期信号(如人声中的气音)、频谱包络(spectralenvelope),使得合成歌声更加自然。其中声码器322将梅尔倒频谱系数,或使用者其他声学特征如基频、频谱包络、非周期信号等作为输入,依序输出每个时间点上音信波形的数值(也就是,x轴为时间轴,y轴为每个时间点上的音信数值)。频谱包络关乎于音色。基本频率关乎于音高。声码器322及至少一部分的特征分析单元321可利用开源软件“world”或“straight”来实现,但本发明实施例非以此为限。
在说明音准调整程序之前,先说明音准调整程序所使用到的音准模型。参照图8,为本发明一实施例的音准模型800的架构示意图。音准模型800是一种监督学习方式的神经网络模型,包括编码器810、译码器820及后网络(postnet)830,也就是为自编码器架构。编码器810可对所输入的声学特征转换为特征向量。译码器820则将特征向量转换为声学特征。后网络830对声学特征进行优化处理,例如减少输出音信的杂音、爆音与不连续性等问题,借此能提高输出音频的质量。在经过输入特定人员的大量训练数据至音准模型800之后,可收敛出权重参数,此些权重参数搭配此音准模型800,即为训练好的关于此特定人员的音准模型800。其中训练数据为该人员大量的音信。例如,提供大量有关使用者的声音档案作为训练数据(即使用者训练数据),可训练出使用者音准模型800;提供大量有关歌手(即原唱者)的声音档案作为训练数据(即原唱者训练数据),可训练出原唱者音准模型800。换言之,利用关于不同人的训练数据,可训练出具有不同权重参数的音准模型800。在此,对于同一人而言,用于训练音准模型800的训练数据可与用于训练声学模型500的训练数据不同。
在一些实施例中,如图8所示,编码器810包括三个卷积层811。译码器820包括一卷积层821及一门控循环单元(gatedrecurrentunit,gru)822。后网络830包括一反卷积层831。然而,本发明实施例的编码器810、译码器820和后网络830并非以上述组成为限。
合并参照图9及图10,图9为本发明一实施例的音准调整程序流程图,图10为本发明一实施例的音准调整模块330的架构示意图。在步骤s901中,利用转换单元331将使用者的演唱歌声转换为声音频谱(后称“使用者声音频谱”)。转换单元331可由傅立叶变换算法或其他时域转频域的算法实现。在步骤s902中,同样利用转换单元331将原唱歌声转换为声音频谱(后称“原唱者声音频谱”)。在此,图9虽绘示两个转换单元331,然而可以是仅由一转换单元331来执行前述步骤s901与步骤s902。
在步骤s903中,将使用者声音频谱输入至使用者音准模型800中的编码器810(于后称“使用者音准模型编码器810a”)中,由于使用者音准模型800具有对应于使用者的权重参数,因此可获得使用者声学特征(于后称“第二使用者声学特征”)。在此,第二使用者声学特征可以例如是基频、频谱包络、非周期音、广义梅尔倒频谱系数(melgeneralizedcepstrum)等中的一个或多个的组合。
在步骤s904中,将原唱者声音频谱输入至原唱者音准模型800中的编码器810(于后称“原唱者音准模型编码器810b”)中,由于原唱者音准模型800具有对应于原唱者的权重参数,因此可获得原唱者基本频率(于后称“原唱者基频”)。
在一些实施例中,步骤s901与步骤s902的先后次序可以互换,步骤s903与步骤s904的先后次序可以互换。步骤s901至步骤s904的次序可以调整,只要在步骤s903执行之前已完成步骤s901,在步骤s904执行之前已完成步骤s902即可。
在步骤s905中,将经由步骤s903获得的第二使用者声学特征和经由步骤s904获得的原唱者基频,输入至使用者音准模型800的译码器820(于后称“使用者音准模型译码器820a”)中,以保留使用者的音色与原唱的音高(即正确的音高)。
在步骤s906中,由于使用者音准模型800具有对应于使用者的权重参数,因此从使用者音准模型译码器820a的输出,可获得经调整的使用者声音频谱。
在步骤s907中,经由声码器332将经调整的使用者声音频谱转换为经调整音准的演唱歌声。其中声码器332将梅尔倒频谱系数,或使用者其他声学特征如基频、频谱包络、非周期信号等作为输入,依序输出每个时间点上音信波形的数值。声码器332可利用开源软件“world”或“straight”来实现,但本发明实施例非以此为限。如此一来,可以让使用者演唱的歌声调整至正确的音准,并且保持原本使用者的音色。
在一些实施例中,音准调整模块330可以是采用音调同步叠加(pitchsynchronousoverlapadd,psola)算法来实现。此算法找出音频中重复出现的波形,通过叠加或删减波形来达成降低或升高频率的目的,借以调整音信的音准。
在一些实施例中,处理装置120依据分离出的原唱歌声辨识原唱者的身份,从而根据原唱者的身份,加载对应原唱者的原唱者音准模型800。
在一些实施例中,处理装置120依据分离出的原唱歌声辨识原唱者的身份,从而根据原唱者的身份,加载对应原唱者的原唱者声学模型500。
在一些实施例中,处理装置120从所播放歌曲档案的元数据中,或者通过使用者输入等方式,获得原唱者的身份,据以加载对应原唱者的原唱者声学模型500和原唱者音准模型800。
在一些实施例中,计算机程序产品300不包括音乐分离模块340及混音模块350,处理装置120是播放无原唱歌声的伴奏音乐。在此情形下,音准调整模块330所需要的原唱歌声可从储存在非瞬时计算机可读取记录媒体123中的歌曲档案或另行处理的歌声档案中取得,应演唱期间可通过时间标记的方式得知。
综上所述,根据本发明的实施例,通过检测在应演唱期间使用者是否歌唱来决定是否执行接唱程序,使得使用者在忘词或因故停止歌唱的时候,可以自动以使用者的声音接续歌唱。通过接唱程序,所产生的接唱歌声可保持如同原唱的音准,并且由于采用自编码器架构的模型,接唱歌声可以如同使用者的音色一般。此外,通过检测使用者的歌唱音准,可以在使用者音准偏离的时候,执行音准调整程序。通过音准调整程序,可以自动调整音高,并且由于采用自编码器架构的模型,可以保持原本使用者的音色。
虽然本发明已以实施例揭露如上,然其并非用以限定本发明,任何所属技术领域中具有公知常识者,在不脱离本发明的精神和范围内,当可作些许的更动与润饰,故本发明的保护范围当视所附的权利要求书所界定的范围为准。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

