本发明涉及深度学习与人工智能技术领域,尤其涉及一种语音识别任务中的保持注意力机制单调性方法。
背景技术:
语音识别任务,是深度学习领域最重要,也是最常见的问题之一,目标是将语音识别为文本。用深度学习解决这类问题的一般方式为,构造一个端到端的神经网络模型,目前语音领域的主流方法为encoder-decoder框架结合注意力机制。虽然这类方法在多个数据集中均取得了良好的效果,然而基于注意力机制的自回归解码方式,由于更依赖上下文而非音频,因此容易产生解码过长或重复解码的问题,这一问题严重影响模型性能,是这类方法被诟病的重要原因之一。
这类错误在模型中体现为由query、key相乘得到的注意力机制的权重的交叉对齐或者重复对齐,因此保证注意力机制权重的单调对齐关系对于解决解码过长或重复解码至关重要。对于注意力机制单调对齐关系的研究,尤其是在以transformer等可并行模型框架为基础模型的研究中,主要针对在线学习任务,这些方法是为了解决在线学习任务的训练过程与测试过程相匹配而设计的,但是按照这一思路做常规离线学习任务发现其性能不佳。
技术实现要素:
本发明的目的是提供一种语音识别任务中的保持注意力机制单调性方法,通过正则化手段约束注意力机制权重的分布,使模型在训练和测试过程中都能保持良好的语音和文本的对齐关系,从而避免解码过长或重复解码的问题,提升模型稳定性。
本发明的目的是通过以下技术方案实现的:
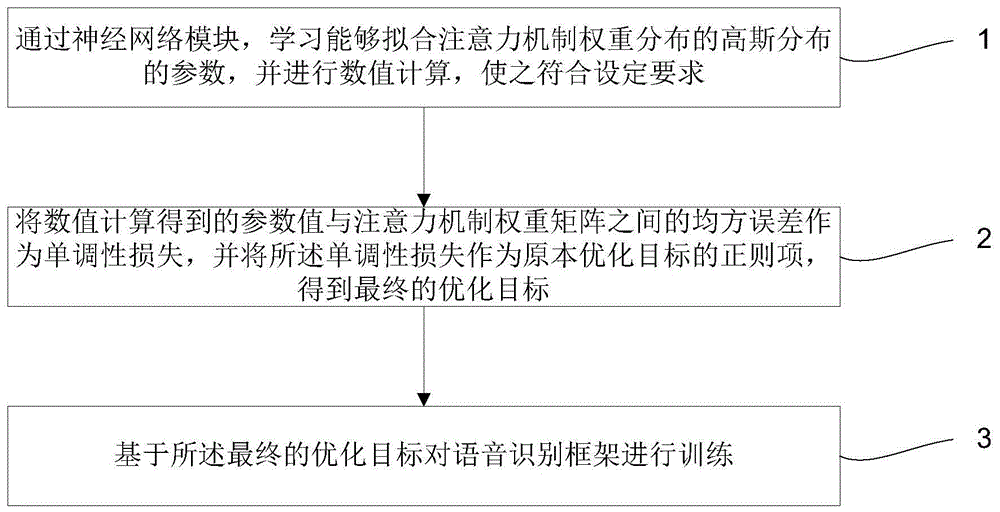
一种语音识别任务中的保持注意力机制单调性方法,包括:
通过神经网络模块,学习能够拟合注意力机制权重分布的高斯分布的参数,并进行数值计算,使之符合设定要求;
将数值计算得到的参数值与注意力机制权重矩阵之间的均方误差作为单调性损失,并将所述单调性损失作为原本优化目标的正则项,得到最终的优化目标;
基于所述最终的优化目标对语音识别框架进行训练。
由上述本发明提供的技术方案可以看出,使得模型在训练和测试过程中都能保持良好的语音和文本的对齐关系,从而避免解码过长或重复解码的问题,提升模型稳定性,减少预测错误,尤其是插入错误。此外,该方法简单易实施,参数量小,只少量增加计算量。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
图1为本发明实施例提供的一种语音识别任务中的保持注意力机制单调性方法的流程图;
图2为本发明实施例提供的产生单调性损失的核心模型结构示意图;
图3为本发明实施例提供的单调性策略实验数据;
图4为本发明实施例提供的样例展示图。
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。
本发明实施例提供一种语音识别任务中的保持注意力机制单调性方法,如图1所示,其主要包括如下步骤:
步骤1、通过神经网络模块,学习能够拟合注意力机制权重分布的高斯分布的参数,并进行数值计算,使之符合设定要求。
本发明实施例中,所述语音识别框架为语音识别领域一种主流的encoder-decoder attention的网络框架(包含注意力机制的编解码框架),如图2所示,通过神经网络模块,来学习能够拟合注意力机制权重分布的高斯分布的参数,连接编码器和解码器的注意力机制的三个输入query(q)、key(k)、value(v)分别来自解码器、编码器、编码器,经信息的提取与融合得到与query同大小的输出。将解码器、编码器的序列长度分别记为i、j,特征维度均为d。
本发明实施例中,神经网络模块可以选择线性层来实现,如图2右侧部分所示,神经网络模块的输入为query,记为
本发明实施例中,需要对参数均值μ和方差σ的初步数值进行一定的数值计算,计算使之符合要求且在合理范围内。如图2所示,在进行数值计算时,对均值μ的初步数值进行截断使之非负,再做放缩使得求和等于语音序列长度,计算结果记为δ;对方差σ进行截断使之在设定范围内(例如,控制在[0.5,5]区间内),计算结果记为σ;计算过程表示为:
δ,σ=cal(μ)(qwμ),cal(σ)(qwσ)
其中,wμ、wσ各自表示神经网络模块中对于均值μ、方差σ的映射权重,q为注意力机制中的query;令qwμ,qwσ=x,则cal(μ)(x)、cal(σ)(x)的计算公式为:
cal(σ)(x)=clamp(x,σmin,σmax)
上式中,xi为qwμ的第i行,inf表示无穷大,clamp(.)为区间限定函数,将括号中的三个数值对应的表示为(x,xmin,xmax),如果输入为矩阵则为每一个元素进行计算,表示为:
步骤2、将数值计算得到的参数值与注意力机制权重矩阵之间的均方误差作为单调性损失,并将所述单调性损失作为原本优化目标的正则项,得到最终的优化目标。
本发明实施例中,首先,由向量δ与σ对应的计算每个位置高斯分布参数的均值μi与σi,从而计算每个位置上的数值
μi,σi=μi-1 δi,σi
其中,i,j为位置索引,
前文中xi的角标i与μi/σi的角标i含义相同。
本发明实施例中,将单调性损失作为原本优化目标lossce的正则项参与共同训练。首先,对于对解码器部分的n个layer和每个layer的h个head的单调性损失取平均,表示为:
然后,将lossmono作为原本优化目标lossce的正则项,得到最终的优化目标loss:
loss=lossce λ*lossmono
其中,n=1,…,n,h=1,…,h;,
本领域技术人员可以理解,解码器部分的n个layer、h个head均为模型结构中的专有名字,可以翻译为:解码器的n个层和每个层的h个“头”。具体来说,解码器有n个广义上的神经网络层;head与注意力机制相关,输入从特征维度上会分裂成h个head。
本发明实施例上述方案,通过正则化手段约束注意力机制权重的分布,具体来说,上述方案通过高斯分布来产生一个分布
步骤3、基于所述最终的优化目标对语音识别框架进行训练。
本发明实施例中,在基础模型框架(即包含注意力机制的编解码框架)下加入了单调性策略,按照常规方式选定训练参数与策略,并将预先收集语音数据集作为训练数据,基于所述最终的优化目标对语音识别框架进行训练。
对于训练后的语音识别框架,使用新的语音数据样本进行测试,获得语音识别结果。
为了说明本发明实施例上述方案的效果,下面结合具体示例进行说明。
如图3所示,本示例中采用600小时左右的中文语音识别数据集进行训练,并分别在同源测试集和非同源测试集上进行测试,其中同源测试集表示与训练数据来源相同的数据集,非同源测试集表示与训练数据来源不同的数据集,测试集均为中文。此外,为了重点考察本发明所提出的方法对由于对齐问题导致的插入错误的降低情况,在基线中插入错误明显的非同源测试集样本被单独提取出来形成“插入错误”测试集。实验对比基线方法(baseline)和两种正则化系数10、100下的保持单调性的方法(mono10、mono100)。分别展示以词为单位的“替换”错误(sub)、“删除”错误(del)、“插入”错误(ins)和准确率(acc),指标间的关系为acc=1-(sub del ins)。实验结果显示,引入单调性方法后同源测试集上准确率有少量提升,非同源测试集上有较为明显提升,在“插入错误”测试集中对插入错误有明显降低,说明本发明中的方法在对齐问题不明显的情况下能保持原有性能,对明显的插入错误能一定程度降低,增强模型的稳定性和泛化性。
如图4所示,对于明显的由于对齐问题导致的循环解码的情况,本发明中的方法有明显的改善,且在正则化系数较小的情况下已有明显的减缓,当正则化系数较大时,几乎没有错误对齐的问题;其中,mono_10、mono_100分别表示正则化系数λ为10、100
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例可以通过软件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,上述实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是cd-rom,u盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

