1.本发明涉及一种跳波束资源的分配方法,属于通信技术领域。
背景技术:
2.卫星通信具有覆盖区域广、通信容量大、传输质量好、组网迅速且不受地理气候环境影响等特点。尽管陆地移动通信系统及网络规模发展迅速,但在面积广阔而人口稀少的地区和自然环境恶劣的地域,仍然要凭借卫星通信特有的技术特点提供通信服务,同陆地移动通信网相互协作,构成天地互联网络实现全球无缝覆盖。而卫星通信系统是典型的资源受限系统,星上有效载荷以及频谱资源有限是限制发展的关键因素,因此如何在有限的资源下进行合理高效的星上资源分配是卫星通信系统中的关键问题。为了满足宽带高速业务以及卫星物联网的需求,多波束系统被提出,在多波束系统中,将整个卫星地理覆盖区域划分为类似于地面蜂窝系统的若干小区,卫星利用多个窄波束以小区为单位进行覆盖。
3.在近些年被提出的“跳波束”技术在波束工作模式中应用时分复用的思想,将系统的时间资源分成很多段时隙,每个时隙只有一部分波束按需工作,在下一时隙依据流量动态请求来调度波束,使系统波束“跳”到其他小区,即波束按时隙调度。在多波束卫星通信系统中,波束间存在的同频干扰是限制通信速率以及系统容量的重要因素之一,跳波束技术利用其可以在空间维度隔离的优势,通过调整空间位置分布可以解决同频干扰的问题,因此可以利用跳波束技术进行星上资源的分配。
4.为解决低轨多波束卫星系统中服务场景不断变化,以及多元化、复杂化的发展趋势,需要引入智能化在线资源管理技术。在多波束系统中,系统的信道容量、星上缓存分布、星上资源、和当前资源分分配方式对下一状态资源分配策略的影响,需要综合考虑上述需求,进行相关性建模。而深度强化学习算法在序贯决策问题中有良好的应有基础,将深度强化学习用于低轨卫星系统资源管理也具有如下的优势:卫星高速移动带来的地面场景变化可为深度强化学习提供大量可训练数据;卫星服务场景中的资源调度可以归类为复杂系统中的决策问题,通过马尔科夫决策模型来解决agent与环境交互过程中产生决策的问题;深度强化学习可以训练不能直接优化的目标,对于不同服务场景,智能体无需重新构建模型,可以在变化的环境中不断学习和优化。正是由于这些原因,将深度强化学习中的深度q网络算法应用到具有跳波束功能的卫星系统资源分配问题中具有不言而喻的好处与优势。
技术实现要素:
5.本发明为了解决现有的跳波束卫星通信系统在资源分配时存在针对服务场景不断变化时缺乏连续性导致不同业务量的时延性能较差的问题,基于强化学习进行了跳波束资源分配方法的研究。
6.基于深度强化学习的跳波束资源分配方法,包括以下步骤:
7.基于跳波束卫星通信系统模型,将地面业务请求分为实时数据业务和非实时数据
业务两类,并分别建立如下优化函数:
[0008][0009][0010][0011][0012][0013]
其中,p1对应于实时业务,是此种情况下t
j
时刻小区c
n
的卫星缓冲区中数据包数量,是此种情况下t
j
时刻小区c
n
的时隙长度;p2对应于非实时数据业务,是此种情况下t
j
时刻小区c
n
的卫星缓冲区中数据包数量,是此种情况下t
j
时刻小区c
n
的到达率,是t
j
时刻卫星跳波束于小区c
n
的覆盖情况;t=[t,t t
th
]是星上缓存器中可以存储数据包的时长范围,缓冲区内时延超过t
th
的数据包将被丢弃,p
b
是卫星波束最大功率,是波束发射功率,p
tot
是卫星总功率;
[0014]
将卫星缓存器中数据最大有效时间长度为t
th
划分为等长的m段,对应m个跳波束时隙,在t时刻前m个时隙到达小区n的数据包时延l为该时隙所在区间;在t时刻前m个时隙到达小区n的实时数据包个数在t时刻前m个时隙到达小区n的非实时数据包个数
[0015]
将数据包时延、实时数据包个数、非实时数据包构成的地面小区业务量请求作为环境状态s,将卫星波束作为智能体agent,将照亮小区作为动作,将卫星跳波束技术中的资源分配的最优化问题视为马尔科夫决策过程,基于深度q网络进行跳波束资源分配。
[0016]
进一步地,所述跳波束卫星通信系统模型如下:
[0017]
跳波束卫星通信系统的跳波束卫星通信场景:卫星提供k个波束共覆盖n个小区c={c
n
|n=1,2,
…
,n},c
n
即图1中的cell,卫星具有跳波束功能;各小区业务量请求以数据包的形式表示,每个数据包大小均为mbit,服从到达率为的泊松分布,其中是t
j
时刻小区c
n
的到达率;星上存在缓冲区,缓冲区中的数据包为其中表示t
j
时刻小区c
n
缓冲的数据包数量;
[0018]
对跳波束卫星通信系统每个时隙的波束调度过程进行建模:t
j
时刻卫星缓冲区中
数据包数量其中是前一时刻缓冲区暂存数据包数量,是t
j
‑1时刻卫星跳波束覆盖情况,是t
j
‑1时刻新的数据包对应的服从到达率。
[0019]
进一步地,所述的环境状态s中的t
j
时刻状态矩阵其中和分别为t
j
时刻的wt和dt,dt=[d
1,t
,d
2,t
];
[0020][0021][0022][0023]
进一步地,深度q网进行跳波束资源分配是的动作集合为其中a
n
=1表示小区n有波束照亮,a
n
=0表示小区n无波束照亮。
[0024]
进一步地,深度q网络中的q网络是采用卷积神经网络和深度神经网络结合的方式构建的,首先利用卷积神经网络对状态矩阵进行特征提取,再通过深度神经网络实现从状态空间到动作空间的非线性映射。
[0025]
进一步地,深度q网络的奖励设置方式如下:
[0026]
对agent动作的有两种不同的奖励:以最小化实时数据包平均时延为目标,定义奖励为负的数据包时延总和,即其中代表矩阵的哈达玛乘积;以最大化非实时数据包吞吐量为目标,定义奖励为每个时隙的系统数据包吞吐量,即r
2t
=x
t
*c
t
。
[0027]
进一步地,深度q网络中进行动作选择的过程中引入贪婪算法ε
‑
greedy进行动作选择,即以概率ε通过随机的方式选择动作,以概率1
‑
ε通过输出最大q值方式选择动作。
[0028]
基于深度强化学习的跳波束资源分配系统,所述系统用于所述的基于深度强化学习的跳波束资源分配方法。
[0029]
本实施方式为一种存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现所述的基于深度强化学习的跳波束资源分配方法。
[0030]
本实施方式为一种设备,所述设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现所述的基于深度强化学习的跳波束资源分配方法。
[0031]
有益效果:
[0032]
本发明提出的基于深度q网络的跳波束资源分配分配方法,可以针对服务场景不断变化的情况进行处理,而且不同业务量都具有良好的时延性能。虽然深度q网络算法在训练过程中单次运算复杂度较高,但训练得到q网络结构后,算法中参数和计算方式无需根据环境变化而重新构建模型,运算次数减少,整体计算复杂度适中。对于低轨卫星网络服务场景不断变化,以及包含多种业务类型的混合系统,该算法性能较好,对于解决动态资源管理问题具有明显优势。
附图说明
[0033]
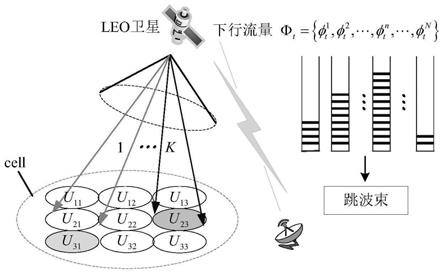
图1为跳波束卫星通信场景示意图;
[0034]
图2为马尔科夫决策过程的状态提取过程示意图;
[0035]
图3为q网络结构示意图;
[0036]
图4为基于深度q网络的跳波束资源分配方法整体结构示意图;
[0037]
图5为数据包平均时延随地面业务量请求变化示意图;
[0038]
图6为系统吞吐率随地面业务量请求变化示意图。
具体实施方式
[0039]
具体实施方式一:
[0040]
本实施方式为基于深度强化学习的跳波束资源分配方法,包括以下步骤:
[0041]
1.构建跳波束卫星通信系统模型,作为对跳波束资源分配算法的分析基础:
[0042]
跳波束卫星通信场景示意图如图1所示,卫星提供k个波束共覆盖n个小区c={c
n
|n=1,2,
…
,n},c
n
即图1中的cell,卫星具有跳波束功能。假设各小区业务量请求以数据包的形式表示,每个数据包大小均为mbit,服从到达率为的泊松分布,其中是t
j
时刻小区c
n
的到达率;星上存在缓冲区,缓冲区中的数据包为其中表示t
j
时刻小区c
n
缓冲的数据包数量;数据包最大有效时延为t
th
,当数据包在缓冲区停留时间超过t
th
时,数据包将被丢弃。
[0043]
跳波束卫星通信系统每个时隙的波束调度过程可建模为如下过程:
[0044]
t
j
时刻卫星缓冲区中数据包数量表示为:其中是前一时刻缓冲区暂存数据包数量,是t
j
‑1时刻卫星跳波束覆盖情况,是t
j
‑1时刻新的数据包对应的服从到达率。
[0045]
2.在构建跳波束卫星通信系统模型基础上,对多种地面业务优化目标进行分析:
[0046]
对多种地面业务优化目标进行建模分析,将地面业务请求分为实时数据业务和非实时数据业务两类。实时业务对时效性要求高,由于跳波束系统中断性服务的特点,对于实时业务数据包的时延性能具有较高的要求。而对于非实时数据业务,则希望能够最大化系统吞吐性能。因此,以这两种优化目标建立如下优化函数:
[0047][0048][0049][0050][0051]
[0052]
其中,p1对应于实时业务,是此种情况下t
j
时刻小区c
n
的卫星缓冲区中数据包数量,是此种情况下t
j
时刻小区c
n
的时隙长度;p2对应于非实时数据业务,是此种情况下t
j
时刻小区c
n
的卫星缓冲区中数据包数量,是此种情况下t
j
时刻小区c
n
的到达率,是t
j
时刻卫星跳波束于小区c
n
的覆盖情况;t=[t,t t
th
]是星上缓存器中可以存储数据包的时长范围,缓冲区内时延超过t
th
的数据包将被丢弃,p
b
是卫星波束最大功率,是波束发射功率,p
tot
是卫星总功率。
[0053]
三条约束条件分别表示每时隙最多有k个小区有波束照亮、所有点波束发射功率总和不能超过卫星总功率、任意波束发射功率不能超过波束最大功率。
[0054]
3.使用马尔科夫决策过程模型对跳波束卫星通信系统资源分配的最优化问题进行分析:
[0055]
马尔科夫决策过程包括状态、动作、策略、奖励和回报五个要素,其模型要素的提取主要包括状态提取、动作选择与奖励设置三个方面。
[0056]
地面小区的业务量请求用数据包数量描述,将马尔科夫决策过程模型中的状态定义为地面小区的数据包个数;状态重构过程如图2所示,图中标记“x”表示地面实时数据包请求,对应数据矩阵d
1,t
;标记“o”表示地面非实时数据包请求,对应数据矩阵d
2,t
;假设卫星缓存器中数据最大有效时间长度为t
th
,将t
th
划分为等长的m段,对应m个跳波束时隙,每一段内全部数据包时延相等,单个时隙时延为
[0057]
在t时刻前m个时隙到达小区n的数据包时延表示为:l
n
为该时隙所在区间;在t时刻前m个时隙到达小区n的实时数据包个数表示为:在t时刻前m个时隙到达小区n的非实时数据包个数表示为:
[0058]
因此,在马尔科夫决策过程中,t
j
时刻状态矩阵为其中和分别为t
j
时刻的wt和dt,dt=[d
1,t
,d
2,t
];
[0059][0060][0061][0062]
在动作选择方面,由于每个时隙需要选择k个波束进行服务,动作空间随小区数量和波束数量增大而急剧增大,例如从37个小区中选择10个波束照射小区时,动作空间大小为无法使用q网络遍历整个动作空间。因此为了算法可实现将动作空间转换
为状态空间,在q网络输出中选择前k个具有最大q值的动作作为波束调度方案来执行,动作集合a可表示为:其中a
n
=1表示小区n有波束照亮,a
n
=0表示小区n无波束照亮。
[0063]
在奖励设置方面,对agent动作的有两种不同的奖励:以最小化实时数据包平均时延为目标,定义奖励为负的数据包时延总和,在这种定义原则下,当前状态实时数据包时延总和越大,获得奖励越小,即其中代表矩阵的哈达玛乘积;以最大化非实时数据包吞吐量为目标,定义奖励为每个时隙的系统数据包吞吐量,在这种定义原则下,系统吞吐量越大,获得奖励值越大,即r
2t
=x
t
*c
t
。
[0064]
4.设计深度q网络算法用于解决跳波束卫星通信系统资源分配问题
[0065]
利用价值学习方法中的深度q网络算法来实现跳波束资源分配问题,其主要包括q网络结构、动作选择策略以及q网络训练三个方面。
[0066]
(1)q网络
[0067]
在深度q网络算法中,q网络代表动作价值函数,q网络经过训练得出的q*函数可以给所有动作打分,来指导agent做动作。本发明中的状态提取出的数据包矩阵与像素值矩阵类似,本发明采用卷积神经网络和深度神经网络结合的方式来构建q网络,首先利用卷积神经网络(两个卷积层 flatten层)对状态矩阵进行特征提取,再通过深度神经网络(三个全连接层)实现从状态空间到动作空间的非线性映射。
[0068]
q值的获取方式如图3所示,输入为状态提取后的数据包矩阵[d
1,t
,d
2,t
],先经过两个卷积层,进行特征提取;而后经过flatten层,最后在通过三个全连接层神经网络,最后输出层为动作的q值。
[0069]
(2)动作选择策略
[0070]
在深度q网络算法中,agent选取q网络输出中的最大q值执行动作。但在实际问题中,agent经历的状态有限,无法遍历整个状态空间,所以对于未经历过的状态,无法给出最佳的动作策略;还有值得注意的是,该方法可能使agent的探索陷入局部最小值的情况,直接影响到算法的收敛效果。
[0071]
为解决这个问题,在动作选择策略中引入贪婪算法(ε
‑
greedy)。设置贪婪因子ε,在选择动作策略时,以概率ε通过随机的方式选择动作,以概率1
‑
ε通过输出最大q值方式选择动作。这样不仅可以让agent获得更多探索的机会,还可以在训练过程中有效跳出陷入局部最小值的情况。而随着训练次数增多,q网络的训练效果逐渐变好,探索的必要性减弱,算法在整个训练期间,贪婪因子ε的值,从初始值ε
i
到最终值ε
r
线性减小。
[0072]
(3)q网络训练
[0073]
在q网络通过神经网络模型逼近动作价值函数时,在训练过程中由于输入状态序列存在相关性,且损失函数中训练标签随q网络更新不稳定,导致训练结果长期难以收敛,甚至发散。针对上述问题,在训练过程中引入经验池以及q
‑
target目标网络的方法来解决。
[0074]
经验池作为深度q网络的记忆库,用来学习之前的经历。由于q
‑
learning是一种离线学习方法,他能够学习当前经历着的,以及过去经历的,甚至学习别人的经历,因此在学习过程中随机加入之前的经验会让神经网络训练效率更高。除此之外,经验池可以解决相
关性及非静态分布问题。在算法初始化阶段清空经验池d,进入训练过程后,将每次训练与环境交互得到的转移样本四元组(s
t
,a
t
,r
t 1
,s
t 1
)存储到d中,当堆积容量达到n
start
时,开始训练。在训练过程中,随机抽取一些(minibatch)四元组来训练,打乱其中的相关性。当经验池中存储四元组超过最大容量n
ep
时,依次清空最早存储的数据。
[0075]
q
‑
target目标网络的作用也是一种打乱相关性的机制,在深度q网络算法中,建立两个神经网络结构完全相同但参数不同的q网络,预测q估计的主网络mainnet使用的是最新的参数,而预测q现实的神经网络targetnet参数是很久之前未更新的,q(s,a;θ
i
)表示当前主网络输出,用来评估当前的状态动作函数;q(s,a;θ
i
‑
)表示目标网络输出,用来计算标签值,以及训练q网络时损失函数的计算,其中标签值y
i
为:
[0076][0077]
损失函数为:
[0078]
l(θ)=e[(y
t
‑
q(s
t
,a
t
;θ))2]
[0079]
其中,θ与θ
‑
分别为主网络q与目标网络q
‑
的参数,目标网络参数θ
‑
每g步从主网络更新。这样,在一段时间内保持目标q
‑
网络参数不变,一定程度上降低了当前q值与目标q
‑
值的相关性,可以提高算法稳定性。
[0080]
5.在步骤3、步骤4的基础上,对基于深度q网络的跳波束资源分配算法进行分析:
[0081]
基于深度q网络的跳波束资源分配算法的整体结构示意图如图4所示,其主要包含深度q网络训练网络构建和跳波束动态资源分配两部分;
[0082]
将地面小区业务量请求建模为环境状态s,将卫星波束建模为智能体agent,将卫星跳波束技术中的资源分配的最优化问题建模为马尔科夫决策过程:agent观察当前环境得到某一状态s
t
后,作出动作a
t
,即给出跳波束服务小区;执行该动作后,环境更新为状态s
t 1
,并给出对动作a
t
价值的反馈评价,即奖励r
t
。本发明利用价值学习方法即深度q网络算法,通过神经网络构建q网络作为动作价值函数,来反映当前动作的好坏程度,即q值;q
*
函数可以给所有动作打分,指导agent做动作,来获得最佳回报;利用经验池和adam优化器来训练q网络,得到最终的q
*
函数得到最佳回报
[0083]
基于深度q网络的跳波束资源分配的具体流程如下表所示:
[0084]
[0085][0086]
参数定义:卫星波段中心频率f
c
,跳波束时隙长度t
s
,小区总数n,波束总数k,数据包数据量大小m,数据包有效时间阈值t
th
,时延分段数f,训练次数n
epochs
,学习率α,初始探索概率ε
i
,最终探索概率ε
f
,经验池最大容量n
ep
,开始训练时经验池数据量n
start
,训练批量数据大小n
batch
,折扣因子γ,网络更新频率g,测试频率t,测试步数step。
[0087]
具体实施方式二:
[0088]
本实施方式为基于深度强化学习的跳波束资源分配系统,所述系统用于所述的基于深度强化学习的跳波束资源分配方法。
[0089]
具体实施方式三:
[0090]
本实施方式为一种存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现所述的基于深度强化学习的跳波束资源分配方法。
[0091]
具体实施方式四:
[0092]
本实施方式为一种设备,所述设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现所述的基于深度强化学习的跳波束资源分配方法。
[0093]
实施例
[0094]
按照具体实施方式进行仿真,仿真过程中仿真参数设定如下:卫星波段中心频率为20ghz,星上总速率为5gbps,点波束速率为500mbps,跳波束时隙长度为10ms,小区总数为37,波束总数为10,数据包数据量大小为100kbit,数据包有效时间阈值为0.4s,时延分段数为40,训练次数为20000次,学习率为10
‑5,初始探索概率为0.8,最终探索概率为0.01,经验池最大容量为20000,开始训练时经验池数据量为100,训练批量数据大小为32,折扣因子为0.9,网络更新频率和测试频率均为50,测试步数为500步。
[0095]
仿真环境为:python3.8.3。
[0096]
仿真结果如图5、图6所示。
[0097]
由图5可以看出,本发明提出的基于深度q网络的波束分配方案与固定分配方法相比,当业务量请求低时固定分配时延低,但随着业务量增加,固定分配时延性能急剧恶化,不具有普适性;本发明的时延性依然良好。
[0098]
与多目标优化算法和随机分配算法相比,本发明整体上具有更好的系统时延性能,数据包平均时延分别能减小62.5%和70%;与ga算法相比,本发明在业务量请求低时有
优势,数据包平均时延能减小33%,但随着业务量增加,两种分配方式时延性能接近。
[0099]
由图6可以看出,深度q网络分配算法与其他算法相比,当业务请求较低时,深度q网络算法资源利用率更高,业务量请求高时,吞吐率随业务请求增加都能够接近1,星上能力最大化利用,而随机分配与固定分配方法归一化系统吞吐量最大只可以达到60%左右,资源利用效率较低。由此可见,本发明提出的深度q网络分配算法在训练过程中单次运算复杂度较高,但训练得到q网络结构后,算法中参数和计算方式无需根据环境变化而重新构建模型,运算次数减少,整体计算复杂度适中。对于低轨卫星网络服务场景不断变化,以及包含多种业务类型的混合系统,该算法性能较好,对于解决动态资源管理问题具有明显优势。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。