1.本技术涉及图像处理领域,尤其涉及一种图像处理方法、装置和电子设备。
背景技术:
2.随着电子设备的广泛使用,使用电子设备进行拍照已经成为人们生活中的一种日常行为方式。以电子设备为手机为例,现有技术中,为了提高拍照质量,业界提出了在手机上设置双摄像头,利用两个摄像头获取的图像信息之间的差异,进行图像信息的互补,由此来提升拍摄的图像质量。
3.但是实际上,目前配置有双摄像头的手机在拍摄图像时,只是将两个摄像头获取的图像进行简单的融合,而这种方式无法在各种场景下均拍摄出质量较高的图像。
4.示例性的,手机配置了两个摄像头,一个是主摄像头,另一个是广角摄像头或者是长焦摄像头。其中,广角摄像头的视场角相对于主摄像头的视场角较大,适合近景拍摄,长焦摄像头的视场角相对于主摄像头的视场角较小,适合远景拍摄。此时,若将主摄像头拍摄的图像和广角摄像头或者和长焦摄像头拍摄的图像进行简单融合,由于两个摄像头的视场角不匹配,将会导致融合得到的图像立体感较差,质量也较差。
5.例如,采用这种双摄像头的手机得到的两种图像中有视场角重合的部分,也有视场角不重合的部分。如果直接将两张图像进行融合,那么最终拍摄得到的图像中视场角重合的部分清晰度高,不重合的部分清晰度低,使得拍摄得到的图像会出现中心部分和四周部分的清晰度不一致的问题,即图像上会出现融合边界,影响成像效果。
6.因此,亟待一种新的图像处理方法,来有效提高获取的图像的清晰度。
技术实现要素:
7.本技术提供一种图像处理方法、装置和电子设备,通过将小视场角图像中的纹理信息添加到大视场角图像中,从而可以增强细节,实现提高大视场角图像的清晰度的目的。
8.为达到上述目的,本技术采用如下技术方案:
9.第一方面,提供一种图像处理方法,该方法包括:
10.获取多帧原始图像,多帧原始图像为对相同的待拍摄场景拍摄的图像,多帧原始图像包括:小视场角图像和大视场角图像,大视场角图像对应的视场角包括小视场角图像对应的视场角;对小视场角图像和大视场角图像均进行分割,分别得到小视场角图像对应的至少一个第一图像块和大视场角图像对应的至少一个第二图像块,至少一个第一图像块与至少一个第二图像块具有映射关系;对至少一个第一图像块中的纹理信息进行提取,并将提取的纹理信息添加至目标图像块,得到目标图像,目标图像块为:与至少一个第一图像块具有映射关系的第二图像块。
11.本技术实施例提供一种图像处理方法,通过获取多帧原始图像,对多帧原始图像中的小视场角图像进行分割,得到对应的至少一个第一图像块,同时,对多帧原始图像中的大视场角图像进行分割,得到对应的至少一个第二图像块。由于大视场角图像对应的视场
角包括小视场角图像对应的视场角,所以,分割后的至少一个第一图像块与至少一个第二图像块具有映射关系,基于此,再从一个或多个第一图像块中提取纹理信息并添加至与被提取纹理信息的第一图像块具有映射关系的第二图像块中。由于小视场角图像相对于大视场角图像清晰度较高,细节更丰富,因此,将从第一图像块提取的纹理信息添加给第二图像块时,可以增强第二图像块的细节,进而可以起到提高大视场角图像的清晰度和质量的作用。
12.在第一方面一种可能的实现方式中,对小视场角图像和大视场角图像均进行分割,得到小视场角图像对应的至少一个第一图像块和大视场角图像对应的至少一个第二图像块,包括:利用深度学习网络模型,对小视场角图像和所述大视场角图像均进行语义分割,分别得到小视场角图像对应的至少一个第一图像块和大视场角图像对应的至少一个第二图像块;每个第一图像块和每个第二图像块均具有对应的类别,至少一个第一图像块为多个第一图像块时,多个第一图像块对应不同的类别,至少一个第二图像块为多个第二图像块时,多个第二图像块对应不同的类别;其中,映射关系为:m个第一图像块与n个第二图像块的类别相同,m和n分别为大于或者等于1的整数,类别用于表示第一图像块和第二图像块的内容属性。
13.在第一方面一种可能的实现方式中,对小视场角图像和大视场角图像均进行分割,得到小视场角图像对应的至少一个第一图像块和大视场角图像对应的至少一个第二图像块,包括:根据颜色或色调,对小视场角图像和大视场角图像均进行分割,分别得到小视场角图像对应的至少一个第一图像块和大视场角图像对应的至少一个第二图像块;每个第一图像块和每个第二图像块均具有对应的颜色或色调,至少一个第一图像块为多个第一图像块时,多个第一图像块对应不同的颜色或色调,至少一个第二图像块为多个第二图像块时,多个第二图像块对应不同的颜色或色调;其中,映射关系为:p个第一图像块和q个第二图像块的颜色或色调相同,p和q分别为大于或者等于1的整数。
14.在第一方面一种可能的实现方式中,在对第一图像块中的纹理信息进行提取,并将提取的纹理信息添加至目标图像块之前,该方法还包括:将小视场角图像贴到大视场角图像中的第一区域;其中,第一区域为大视场角图像中与小视场角图像对应的区域,第二区域为大视场角图像中除了第一区域之外的区域,目标图像块为:与至少一个第一图像块具有映射关系且位于第二区域的第二图像块,以及,与至少一个第一图像块具有映射关系的第二图像块中的子图像块,子图像块位于第二区域。在该实现方式中,小视场角图像相对于大视场角图像的清晰度较高,将小视场角图像贴到大视场角图像中的第一区域时,整体提高了大视场角图像中第一区域的清晰度,因此,后续只需要将第一图像块提取的纹理信息添加位于第二区域的第二图像块以及第二图像块中位于第二区域的子图像块中,从而可以减少计算量,提高处理效率。
15.在第一方面一种可能的实现方式中,在将小视场角图像贴到大视场角图像的第一区域之前,该方法还包括:利用分水岭算法,确定至少一个第二图像块对应的连通域;在将小视场角图像贴到大视场角图像的第一区域之后,该方法还包括:确定至少一个第一图像块与目标图像块对应的连通域是否连通;若连通,则确定至少一个第一图像块的图像熵;根据至少一个第一图像块的图像熵,确定将从至少一个第一图像块中提取出的纹理信息添加至目标图像块的添加方式;以确定出的添加方式将提取的纹理信息添加至目标图像块。在
该实现方式中,可以通过确定第一图像块与目标图像块对应的连通域是否连通,来提高后续添加纹理信息的准确度,将第一图像块中的纹理信息仅添加给相连通的连通域中的目标图像块中。
16.在第一方面一种可能的实现方式中,当利用深度学习网络模型,对小视场角图像和大视场角图像均进行语义分割时,该方法还包括:确定至少一个第一图像块和目标图像块之间的相似度或峰值信噪比;当相似度或峰值信噪比满足各自对应的预设阈值时,则确定至少一个第一图像块的图像熵;根据至少一个第一图像块的图像熵,确定将从至少一个第一图像块提取的纹理信息添加至目标图像块的添加方式;以确定出的添加方式将提取的纹理信息添加至目标图像块。在该实现方式中,根据相似度或峰值信噪比,可以筛选出关联性更强的第一图像块和目标图像块,在此基础上,通过确定图像熵即可知道第一图像块的细节信息较多还是较少,由此,可以根据不同的图像熵确定出不同的对目标图像块添加纹理信息的添加方式。
17.在第一方面一种可能的实现方式中,该方法还包括:若非连通,则确定至少一个第一图像块和目标图像块之间的相似度或峰值信噪比;当相似度或峰值信噪比满足各自对应的预设阈值时,则确定至少一个第一图像块的图像熵;根据至少一个第一图像块的图像熵,确定将从至少一个第一图像块提取的纹理信息添加至目标图像块的添加方式;以确定出的添加方式将提取的纹理信息添加至目标图像块。在该实现方式中,虽然第一图像块与目标图像块对应的连通域非连通,但是,第一图像块也有可能与目标图像块是同一种对象,因此,可以进一步判断相似度来确定是否要进行纹理信息的添加。
18.在第一方面一种可能的实现方式中,根据至少一个第一图像块的图像熵,确定将从至少一个第一图像块提取的纹理信息添加至目标图像块的添加方式,包括:当至少一个第一图像块的图像熵小于图像熵阈值时,将从至少一个第一图像块提取的纹理信息添加至目标图像块的添加方式为显式添加方式;当至少一个第一图像块的图像熵大于或等于图像熵阈值时,将从至少一个第一图像块提取的纹理信息添加至目标图像块的添加方式为隐式添加方式;其中,添加方式包括显式添加方式和隐式添加方式,显式添加方式用于表示在添加纹理信息时对纹理信息不改变,隐式添加方式用于表示在添加纹理信息时对纹理信息进行适应性变形。在该实现方式中,当第一图像块的图像熵小于图像熵阈值时,表明第一图像块中的细节信息较少,此时,可以以显示添加的方式,直接将纹理信息复制并粘贴至目标图像块,计算量少,效率高;而当第一图像块的图像熵大于或者等于图像熵阈值时,表明第一图像块中的细节信息较多,此时,需以隐式添加的方式,将从第一图像块提取的纹理信息进行适应性变形后再添加给目标图像块,使得原来的目标图像块中的内容和纹理信息融合的更加自然服帖,增加图像的细节,提高视觉效果。
19.在第一方面一种可能的实现方式中,深度学习网络模型为fcn、segnet、deeplab中的任意一种。
20.第二方面,提供了一种图像处理装置,该装置包括用于执行以上第一方面或第一方面的任意可能的实现方式中各个步骤的单元。
21.第三方面,提供了一种图像处理装置,包括:接收接口和处理器;接收接口用于从电子设备处获取多帧原始图像;多帧原始图像为对相同的待拍摄场景拍摄的图像,多帧原始图像包括:小视场角图像和大视场角图像,大视场角图像对应的视场角包括小视场角图
像对应的视场角;处理器,用于调用存储器中存储的计算机程序,以执行如第一方面或第一方面的任意可能的实现方式中提供的图像处理方法中进行处理的步骤。
22.第四方面,提供了一种电子设备,包括摄像头模组、处理器和存储器;摄像头模组,用于获取多帧原始图像;多帧原始图像为对相同的待拍摄场景拍摄的图像,多帧原始图像包括:小视场角图像和大视场角图像,大视场角图像对应的视场角包括小视场角图像对应的视场角;存储器,用于存储可在处理器上运行的计算机程序;处理器,用于执行如第一方面或第一方面的任意可能的实现方式中提供的图像处理方法中进行处理的步骤。
23.在第四方面一种可能的实现方式中,摄像头模组包括第一摄像头和第二摄像头,第一摄像头用于对待拍摄场景以第一视场角进行拍照,第二摄像头用于对待拍摄场景以第二视场角进行拍照;第一视场角小于第二视场角;第一摄像头,用于在处理器获取拍照指令后,获取小视场角图像,小视场角图像对应的视场角为第一视场角;第二摄像头,用于在处理器获取拍照指令后,获取大视场角图像,大视场角图像对应的视场角为第二视场角。
24.第五方面,提供了一种芯片,包括:处理器,用于从存储器中调用并运行计算机程序,使得安装有芯片的设备执行执行如第一方面或第一方面的任意可能的实现方式中提供的图像处理方法。
25.第六方面,提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序包括程序指令,程序指令当被处理器执行时,使处理器执行如第一方面或第一方面的任意可能的实现方式中提供的图像处理方法。
26.第七方面,提供了一种计算机程序产品,计算机程序产品包括存储了计算机程序的计算机可读存储介质,计算机程序使得计算机执行如第一方面或第一方面的任意可能的实现方式中提供的图像处理方法。
27.本技术提供的图像处理方法、装置和电子设备,通过获取多帧原始图像,对多帧原始图像中的小视场角图像进行分割,得到对应的至少一个第一图像块,同时,对多帧原始图像中的大视场角图像进行分割,得到对应的至少一个第二图像块。由于大视场角图像对应的视场角包括小视场角图像对应的视场角,所以,分割后的至少一个第一图像块与至少一个第二图像块具有映射关系,基于此,再从一个或多个第一图像块中提取纹理信息并添加至与被提取纹理信息的第一图像块具有映射关系的第二图像块中。由于小视场角图像相对于大视场角图像清晰度较高,细节更丰富,因此,将从第一图像块提取的纹理信息添加给第二图像块时,可以增强第二图像块的细节,进而可以起到提高大视场角图像的清晰度和质量的作用。
附图说明
28.图1为现有技术提供的一种对双摄像头拍摄的图像进行处理的示意图;
29.图2为本技术实施例提供的一种电子设备的结构示意图;
30.图3为本技术实施例提供的一种图像处理装置的硬件架构图;
31.图4为本技术实施例提供的一种图像处理方法的流程示意图;
32.图5为本技术实施例提供的另一种图像处理方法的流程示意图;
33.图6为本技术实施例提供的一种纹理信息添加方式的示意图;
34.图7为本技术实施例提供的又一种图像处理方法的流程示意图;
35.图8为本技术实施例提供的一种确定第二图像块对应的连通域的示意图;
36.图9为本技术实施例提供的又一种图像处理方法的流程示意图;
37.图10为本技术实施例提供的又一种图像处理方法的流程示意图;
38.图11为本技术实施例提供的又一种图像处理方法的流程示意图;
39.图12为本技术实施例提供的又一种图像处理方法的流程示意图;
40.图13为本技术实施例提供的又一种图像处理方法的流程示意图;
41.图14为本技术实施例提供的又一种图像处理方法的流程示意图;
42.图15为本技术实施例提供的一种图像处理装置的结构示意图;
43.图16为申请实施例提供的一种芯片的结构示意图。
具体实施方式
44.下面将结合附图,对本技术中的技术方案进行描述。
45.在本技术实施例的描述中,除非另有说明,“/”表示或的意思,例如,a/b可以表示a或b;本文中的“和/或”仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,在本技术实施例的描述中,“多个”是指两个或多于两个。
46.以下,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本实施例的描述中,除非另有说明,“多个”的含义是两个或两个以上。
47.首先,对本技术实施例中的部分用语进行解释说明,以便于本领域技术人员理解。
48.1、视场角(field of view,fov),用于指示摄像头所能拍摄到的最大的角度范围。若待拍摄物体处于这个角度范围内,该待拍摄物体便会被摄像头捕捉到。若待拍摄物体处于这个角度范围之外,该待拍摄物体便不会被摄像头捕捉到。
49.通常,摄像头的视场角越大,则拍摄范围就越大,焦距就越短;而摄像头的视场角越小,则拍摄范围就越小,焦距就越长。因此,摄像头因视场角的不同可以被划分主摄像头、广角摄像头和长焦摄像头。其中,广角摄像头的视场角相对于主摄像头的视场角较大,焦距较小,适合近景拍摄;而长焦摄像头的视场角相对于主摄像头的视场角较小,焦距较长,适合远景拍摄。
50.2、连通域,指的是:属于一区域a内任一项简单闭合曲线的内部都属于a,则称a为连通域,或者,连通域也可以表述为:a内任一封闭曲线所围成的区域内只含有a中的点。
51.3、分水岭算法(watershed algorithm),分水岭算法是一种基于拓扑理论的数学形态学的分割方法,也是一种常用的图像分割的方法,其基本思想是把图像看做是测地学上的拓扑地貌,图像中每一点像素的灰度值表示该点的海拔高度,图像中的凹陷地点就是图像中的局部极小值。而汇水盆就是地形中凹陷地点影响的区域,也是图像中包围局部极小值的区域。通过注水,在水面上涨的过程中,这些凹陷的地点被浸没,最终在其周围形成堤坝,这些堤坝用于阻挡其他汇水盆里的水混到自己的盆中。当地形中所有的汇水盆都被堤坝包围后,停止注水,此时,这些堤坝即是分水岭。
52.以上是对本技术实施例所涉及名词的简单介绍,以下不再赘述。
53.随着电子设备的广泛使用,使用电子设备进行拍照已经成为人们生活中的一种日常行为方式。以手机为例,现有技术中,为了提高拍照质量,业界提出了在手机上设置双摄像头,利用两个摄像头获取的图像信息之间的差异,进行图像信息的互补,由此来提升拍摄的图像质量。
54.但是实际上,目前配置有双摄像头的手机在拍摄图像时,只是将两个摄像头获取的图像进行简单的融合,而这种方式无法在各种场景下均拍摄出质量较高的图像。
55.示例性的,手机配置了两个摄像头,一个是主摄像头,另一个是广角摄像头或者是长焦摄像头,或者,两个摄像头分别为广角摄像头和长焦摄像头。其中,广角摄像头的视场角相对于主摄像头的视场角较大,长焦摄像头的视场角相对于主摄像头的视场角较小。然后,将主摄像头拍摄的图像和广角摄像头拍摄的图像,或者;将主摄像头拍摄的图像和长焦摄像头拍摄的图像进行简单融合,或者;将广角摄像头拍摄的图像和长焦摄像头拍摄的图像进行简单融合。
56.图1示出了一种现有技术对双摄像头拍摄的图像进行处理的示意图。
57.如图1所示,在现有技术中,通常会根据视场角大小,将主摄像头拍摄的第一视场角图像填充在广角摄像头拍摄的第二视场角图像中,或者,将长焦摄像头拍摄的第一视场角图像填充在主摄像头或广角摄像头拍摄的第二视场角图像中。但是,在这种方式中,由于两个摄像头的视场角不匹配,将会导致融合得到的图像立体感较差,质量也较差。
58.例如,采用这种双摄像头的手机得到的两种图像中有视场角重合的部分,也有视场角不重合的部分。如果直接将两张图像进行融合,那么最终拍摄得到的图像中视场角重合的部分与不重合的部分可能对位对不上,部分内容产生断裂或畸形。此外,视场角重合的部分可能清晰度高,不重合的部分清晰度低,使得拍摄得到的图像会出现中心部分和四周部分的清晰度不一致的问题,即图像上会出现融合边界,影响成像效果。
59.有鉴于此,本技术实施例提供了一种图像处理方法,针对具有视场角重合部分的小视场角图像和大视场角图像,通过将小视场角图像中的纹理信息添加到大视场角图像中,增强细节,以实现提高大视场角图像的清晰度的目的。
60.本技术实施例提供的图像处理方法可以适用于各种电子设备,对应的,本技术实施例提供的图像处理装置可以为多种形态的电子设备。
61.在本技术的一些实施例中,该电子设备可以为单反相机、卡片机等各种摄像装置、手机、平板电脑、可穿戴设备、车载设备、增强现实(augmented reality,ar)/虚拟现实(virtual reality,vr)设备、笔记本电脑、超级移动个人计算机(ultra
‑
mobile personal computer,umpc)、上网本、个人数字助理(personal digital assistant,pda)等,或者可以为其他能够进行图像处理的设备或装置,对于电子设备的具体类型,本技术实施例不作任何限制。
62.下文以电子设备为手机为例,图2示出了本技术实施例提供的一种电子设备100的结构示意图。
63.电子设备100可以包括处理器110,外部存储器接口120,内部存储器121,通用串行总线(universal serial bus,usb)接口130,充电管理模块140,电源管理模块141,电池142,天线1,天线2,移动通信模块150,无线通信模块160,音频模块170,扬声器170a,受话器170b,麦克风170c,耳机接口170d,传感器模块180,按键190,马达191,指示器192,摄像头
193,显示屏194,以及用户标识模块(subscriber identification module,sim)卡接口195等。其中传感器模块180可以包括压力传感器180a,陀螺仪传感器180b,气压传感器180c,磁传感器180d,加速度传感器180e,距离传感器180f,接近光传感器180g,指纹传感器180h,温度传感器180j,触摸传感器180k,环境光传感器180l,骨传导传感器180m等。
64.处理器110可以包括一个或多个处理单元,例如:处理器110可以包括应用处理器(application processor,ap),调制解调处理器,图形处理器(graphics processing unit,gpu),图像信号处理器(image signal processor,isp),控制器,视频编解码器,数字信号处理器(digital signal processor,dsp),基带处理器,和/或神经网络处理器(neural
‑
network processing unit,npu)等。其中,不同的处理单元可以是独立的器件,也可以集成在一个或多个处理器中。
65.其中,控制器可以是电子设备100的神经中枢和指挥中心。控制器可以根据指令操作码和时序信号,产生操作控制信号,完成取指令和执行指令的控制。
66.处理器110中还可以设置存储器,用于存储指令和数据。在一些实施例中,处理器110中的存储器为高速缓冲存储器。该存储器可以保存处理器110刚用过或循环使用的指令或数据。如果处理器110需要再次使用该指令或数据,可从所述存储器中直接调用。避免了重复存取,减少了处理器110的等待时间,因而提高了系统的效率。
67.处理器110可以运行本技术实施例提供的图像处理方法的软件代码,拍摄得到清晰度较高的图像。
68.在一些实施例中,处理器110可以包括一个或多个接口。接口可以包括集成电路(inter
‑
integrated circuit,i2c)接口,集成电路内置音频(inter
‑
integrated circuit sound,i2s)接口,脉冲编码调制(pulse code modulation,pcm)接口,通用异步收发传输器(universal asynchronous receiver/transmitter,uart)接口,移动产业处理器接口(mobile industry processor interface,mipi),通用输入输出(general
‑
purpose input/output,gpio)接口,用户标识模块(subscriber identity module,sim)接口,和/或通用串行总线(universal serial bus,usb)接口等。
69.mipi接口可以被用于连接处理器110与显示屏194,摄像头193等外围器件。mipi接口包括摄像头串行接口(camera serial interface,csi),显示屏串行接口(display serial interface,dsi)等。在一些实施例中,处理器110和摄像头193通过csi接口通信,实现电子设备100的拍摄功能。处理器110和显示屏194通过dsi接口通信,实现电子设备100的显示功能。
70.gpio接口可以通过软件配置。gpio接口可以被配置为控制信号,也可被配置为数据信号。在一些实施例中,gpio接口可以用于连接处理器110与摄像头193,显示屏194,无线通信模块160,音频模块170,传感器模块180等。gpio接口还可以被配置为i2c接口,i2s接口,uart接口,mipi接口等。
71.usb接口130是符合usb标准规范的接口,具体可以是mini usb接口,micro usb接口,usb type c接口等。usb接口130可以用于连接充电器为电子设备100充电,也可以用于电子设备100与外围设备之间传输数据。也可以用于连接耳机,通过耳机播放音频。该接口还可以用于连接其他电子设备,例如ar设备等。
72.可以理解的是,本技术实施例示意的各模块间的接口连接关系,只是示意性说明,
并不构成对电子设备100的结构限定。在本技术另一些实施例中,电子设备100也可以采用上述实施例中不同的接口连接方式,或多种接口连接方式的组合。
73.充电管理模块140用于从充电器接收充电输入。
74.电源管理模块141用于连接电池142,充电管理模块140与处理器110。电源管理模块141接收电池142和/或充电管理模块140的输入,为处理器110,内部存储器121,显示屏194,摄像头193,和无线通信模块160等供电。
75.电子设备100的无线通信功能可以通过天线1,天线2,移动通信模块150,无线通信模块160,调制解调处理器以及基带处理器等实现。
76.天线1和天线2用于发射和接收电磁波信号。电子设备100中的每个天线可用于覆盖单个或多个通信频带。不同的天线还可以复用,以提高天线的利用率。例如:可以将天线1复用为无线局域网的分集天线。在另外一些实施例中,天线可以和调谐开关结合使用。
77.移动通信模块150可以提供应用在电子设备100上的包括2g/3g/4g/5g等无线通信的解决方案。移动通信模块150可以包括至少一个滤波器,开关,功率放大器,低噪声放大器(low noise amplifier,lna)等。移动通信模块150可以由天线1接收电磁波,并对接收的电磁波进行滤波,放大等处理,传送至调制解调处理器进行解调。移动通信模块150还可以对经调制解调处理器调制后的信号放大,经天线1转为电磁波辐射出去。在一些实施例中,移动通信模块150的至少部分功能模块可以被设置于处理器110中。在一些实施例中,移动通信模块150的至少部分功能模块可以与处理器110的至少部分模块被设置在同一个器件中。
78.无线通信模块160可以提供应用在电子设备100上的包括无线局域网(wireless local area networks,wlan)(如无线保真(wireless fidelity,wi
‑
fi)网络),蓝牙(bluetooth,bt),全球导航卫星系统(global navigation satellite system,gnss),调频(frequency modulation,fm),近距离无线通信技术(near field communication,nfc),红外技术(infrared,ir)等无线通信的解决方案。无线通信模块160可以是集成至少一个通信处理模块的一个或多个器件。无线通信模块160经由天线2接收电磁波,将电磁波信号调频以及滤波处理,将处理后的信号发送到处理器110。无线通信模块160还可以从处理器110接收待发送的信号,对其进行调频,放大,经天线2转为电磁波辐射出去。
79.在一些实施例中,电子设备100的天线1和移动通信模块150耦合,天线2和无线通信模块160耦合,使得电子设备100可以通过无线通信技术与网络以及其他设备通信。所述无线通信技术可以包括全球移动通讯系统(global system for mobile communications,gsm),通用分组无线服务(general packet radio service,gprs),码分多址接入(code division multiple access,cdma),宽带码分多址(wideband code division multiple access,wcdma),时分码分多址(time
‑
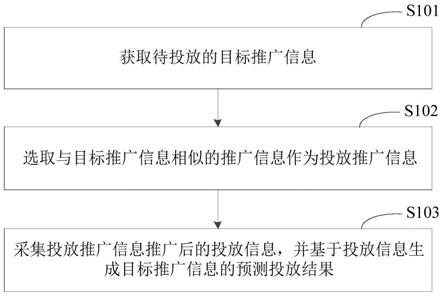
division code division multiple access,td
‑
scdma),长期演进(long term evolution,lte),bt,gnss,wlan,nfc,fm,和/或ir技术等。所述gnss可以包括全球卫星定位系统(global positioning system,gps),全球导航卫星系统(global navigation satellite system,glonass),北斗卫星导航系统(beidou navigation satellite system,bds),准天顶卫星系统(quasi
‑
zenith satellite system,qzss)和/或星基增强系统(satellite based augmentation systems,sbas)。
80.电子设备100通过gpu,显示屏194,以及应用处理器等实现显示功能。gpu为图像处理的微处理器,连接显示屏194和应用处理器。gpu用于执行数学和几何计算,用于图形渲
染。处理器110可包括一个或多个gpu,其执行程序指令以生成或改变显示信息。
81.显示屏194用于显示图像,视频等。显示屏194包括显示面板。显示面板可以采用液晶显示屏(liquid crystal display,lcd),有机发光二极管(organic light
‑
emitting diode,oled),有源矩阵有机发光二极体或主动矩阵有机发光二极体(active
‑
matrix organic light emitting diode的,amoled),柔性发光二极管(flex light
‑
emitting diode,fled),miniled,microled,micro
‑
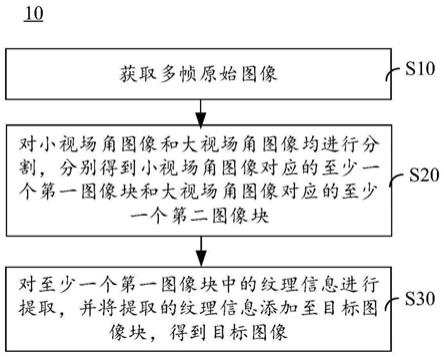
oled,量子点发光二极管(quantum dot light emitting diodes,qled)等。在一些实施例中,电子设备100可以包括1个或n个显示屏194,n为大于1的正整数。
82.摄像头193用于捕获图像。可以通过应用程序指令触发开启,实现拍照功能,如拍摄获取任意场景的图像。摄像头可以包括成像镜头、滤光片、图像传感器等部件。物体发出或反射的光线进入成像镜头,通过滤光片,最终汇聚在图像传感器上。图像传感器主要是用于对拍照视角中的所有物体(也可称为待拍摄场景、目标场景,也可以理解为用户期待拍摄的场景图像)发出或反射的光汇聚成像;滤光片主要是用于将光线中的多余光波(例如除可见光外的光波,如红外)滤去;图像传感器主要是用于对接收到的光信号进行光电转换,转换成电信号,并输入处理器130进行后续处理。其中,摄像头193可以位于电子设备100的前面,也可以位于电子设备100的背面,摄像头的具体个数以及排布方式可以根据需求设置,本技术不做任何限制。
83.示例性的,电子设备100包括前置摄像头和后置摄像头。例如,前置摄像头或者后置摄像头,均可以包括1个或多个摄像头。以电子设备100具有3个后置摄像头为例,这样,电子设备100启动启动3个后置摄像头进行拍摄时,可以使用本技术实施例提供的图像处理方法。或者,摄像头设置于电子设备100的外置配件上,该外置配件可旋转的连接于手机的边框,该外置配件与电子设备100的显示屏194之间所形成的角度为0
‑
360度之间的任意角度。比如,当电子设备100自拍时,外置配件带动摄像头旋转到朝向用户的位置。当然,手机具有多个摄像头时,也可以只有部分摄像头设置在外置配件上,剩余的摄像头设置在电子设备100本体上,本技术实施例对此不进行任何限制。
84.内部存储器121可以用于存储计算机可执行程序代码,所述可执行程序代码包括指令。内部存储器121可以包括存储程序区和存储数据区。其中,存储程序区可存储操作系统,至少一个功能所需的应用程序(比如声音播放功能,图像播放功能等)等。存储数据区可存储电子设备100使用过程中所创建的数据(比如音频数据,电话本等)等。此外,内部存储器121可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件,闪存器件,通用闪存存储器(universal flash storage,ufs)等。处理器110通过运行存储在内部存储器121的指令,和/或存储在设置于处理器中的存储器的指令,执行电子设备100的各种功能应用以及数据处理。
85.内部存储器121还可以存储本技术实施例提供的图像处理方法的软件代码,当处理器110运行所述软件代码时,执行图像处理方法的流程步骤,得到清晰度较高的图像。
86.内部存储器121还可以存储拍摄得到的图像。
87.外部存储器接口120可以用于连接外部存储卡,例如micro sd卡,实现扩展电子设备100的存储能力。外部存储卡通过外部存储器接口120与处理器110通信,实现数据存储功能。例如将音乐等文件保存在外部存储卡中。
88.当然,本技术实施例提供的图像处理方法的软件代码也可以存储在外部存储器中,处理器110可以通过外部存储器接口120运行所述软件代码,执行图像处理方法的流程步骤,得到清晰度较高的图像。电子设备100拍摄得到的图像也可以存储在外部存储器中。
89.应理解,用户可以指定将图像存储在内部存储器121还是外部存储器中。比如,电子设备100当前与外部存储器相连接时,若电子设备100拍摄得到1帧图像时,可以弹出提示信息,以提示用户将图像存储在外部存储器还是内部存储器;当然,还可以有其他指定方式,本技术实施例对此不进行任何限制;或者,电子设备100检测到内部存储器121的内存量小于预设量时,可以自动将图像存储在外部存储器中。
90.电子设备100可以通过音频模块170,扬声器170a,受话器170b,麦克风170c,耳机接口170d,以及应用处理器等实现音频功能。例如音乐播放,录音等。
91.压力传感器180a用于感受压力信号,可以将压力信号转换成电信号。在一些实施例中,压力传感器180a可以设置于显示屏194。
92.陀螺仪传感器180b可以用于确定电子设备100的运动姿态。在一些实施例中,可以通过陀螺仪传感器180b确定电子设备100围绕三个轴(即,x,y和z轴)的角速度。陀螺仪传感器180b可以用于拍摄防抖。
93.气压传感器180c用于测量气压。在一些实施例中,电子设备100通过气压传感器180c测得的气压值计算海拔高度,辅助定位和导航。
94.磁传感器180d包括霍尔传感器。电子设备100可以利用磁传感器180d检测翻盖皮套的开合。在一些实施例中,当电子设备100是翻盖机时,电子设备100可以根据磁传感器180d检测翻盖的开合。进而根据检测到的皮套的开合状态或翻盖的开合状态,设置翻盖自动解锁等特性。
95.加速度传感器180e可检测电子设备100在各个方向上(一般为三轴)加速度的大小。当电子设备100静止时可检测出重力的大小及方向。还可以用于识别电子设备姿态,应用于横竖屏切换,计步器等应用。
96.距离传感器180f,用于测量距离。电子设备100可以通过红外或激光测量距离。在一些实施例中,拍摄场景,电子设备100可以利用距离传感器180f测距以实现快速对焦。
97.接近光传感器180g可以包括例如发光二极管(led)和光检测器,例如光电二极管。发光二极管可以是红外发光二极管。电子设备100通过发光二极管向外发射红外光。电子设备100使用光电二极管检测来自附近物体的红外反射光。当检测到充分的反射光时,可以确定电子设备100附近有物体。当检测到不充分的反射光时,电子设备100可以确定电子设备100附近没有物体。电子设备100可以利用接近光传感器180g检测用户手持电子设备100贴近耳朵通话,以便自动熄灭屏幕达到省电的目的。接近光传感器180g也可用于皮套模式,口袋模式自动解锁与锁屏。
98.环境光传感器180l用于感知环境光亮度。电子设备100可以根据感知的环境光亮度自适应调节显示屏194亮度。环境光传感器180l也可用于拍照时自动调节白平衡。环境光传感器180l还可以与接近光传感器180g配合,检测电子设备100是否在口袋里,以防误触。
99.指纹传感器180h用于采集指纹。电子设备100可以利用采集的指纹特性实现指纹解锁,访问应用锁,指纹拍照,指纹接听来电等。
100.温度传感器180j用于检测温度。在一些实施例中,电子设备100利用温度传感器
180j检测的温度,执行温度处理策略。例如,当温度传感器180j上报的温度超过阈值,电子设备100执行降低位于温度传感器180j附近的处理器的性能,以便降低功耗实施热保护。在另一些实施例中,当温度低于另一阈值时,电子设备100对电池142加热,以避免低温导致电子设备100异常关机。在其他一些实施例中,当温度低于又一阈值时,电子设备100对电池142的输出电压执行升压,以避免低温导致的异常关机。
101.触摸传感器180k,也称“触控器件”。触摸传感器180k可以设置于显示屏194,由触摸传感器180k与显示屏194组成触摸屏,也称“触控屏”。触摸传感器180k用于检测作用于其上或附近的触摸操作。触摸传感器可以将检测到的触摸操作传递给应用处理器,以确定触摸事件类型。可以通过显示屏194提供与触摸操作相关的视觉输出。在另一些实施例中,触摸传感器180k也可以设置于电子设备100的表面,与显示屏194所处的位置不同。
102.骨传导传感器180m可以获取振动信号。在一些实施例中,骨传导传感器180m可以获取人体声部振动骨块的振动信号。骨传导传感器180m也可以接触人体脉搏,接收血压跳动信号。在一些实施例中,骨传导传感器180m也可以设置于耳机中,结合成骨传导耳机。音频模块170可以基于所述骨传导传感器180m获取的声部振动骨块的振动信号,解析出语音信号,实现语音功能。应用处理器可以基于所述骨传导传感器180m获取的血压跳动信号解析心率信息,实现心率检测功能。
103.按键190包括开机键,音量键等。按键190可以是机械按键。也可以是触摸式按键。电子设备100可以接收按键输入,产生与电子设备100的用户设置以及功能控制有关的键信号输入。
104.马达191可以产生振动提示。马达191可以用于来电振动提示,也可以用于触摸振动反馈。例如,作用于不同应用(例如拍照,音频播放等)的触摸操作,可以对应不同的振动反馈效果。
105.指示器192可以是指示灯,可以用于指示充电状态,电量变化,也可以用于指示消息,未接来电,通知等。
106.sim卡接口195用于连接sim卡。sim卡可以通过插入sim卡接口195,或从sim卡接口195拔出,实现和电子设备100的接触和分离。
107.可以理解的是,本技术实施例示意的结构并不构成对电子设备100的具体限定。在本技术另一些实施例中,电子设备100可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。图示的部件可以以硬件,软件或软件和硬件的组合实现。
108.本技术实施例提供的图像处理方法,还可以适用于各种图像处理装置。图3示出了本技术实施例提供的一种图像处理装置200的硬件架构图。如图3所示,该图像处理装置200例如可以为处理器芯片。示例性的,图3所示的硬件架构图可以是图2中的处理器110,本技术实施例提供的图像处理方法可以应用在该处理器芯片上。
109.如图3所示,该图像处理装置200包括:至少一个cpu,存储器、微控制器(microcontroller unit,mcu)、gpu、npu、内存总线、接收接口和发送接口等。除此之外,该图像处理装置200还可以包括ap、解码器以及专用的图形处理器等。
110.该图像处理装置200的上述各个部分通过连接器相耦合,示例性的,连接器包括各类接口、传输线或总线等,这些接口通常是电性通信接口,但是,也可能是机械接口或其他
形式的接口,本技术实施例对此不做任何限制。
111.可选地,cpu可以是一个单核(single
‑
cpu)处理器或多核(multi
‑
cpu)处理器。
112.可选地,cpu可以是多个处理器构成的处理器组,多个处理器之间通过一个或多个总线彼此耦合。该连接接口可以为处理器芯片的数据输入的接口,在一种可选地情况下,该接收接口和发送接口可以是高清晰度多媒体接口(high definition multimedia interface,hdmi)、v
‑
by
‑
one接口、嵌入式显示端口(embedded display port,edp)、移动产业处理器接口(mobile industry processor interface,mipi)display port(dp)等,该存储器可以参考上述对内部存储器121部分的描述。在一种可能实现的方式中,上述各部分集成在同一个芯片上。在另一个可能实现的方式中,cpu、gpu、解码器、接收接口以及发送接口集成在一个芯片上,该芯片内部的各部分通过总线访问外部的存储器。专用图形处理器可以为专用isp。
113.可选地,npu也可以作为独立的处理器芯片。该npu用于实现各种神经网络或者深度学习的相关运算。本技术实施例提供的图像处理方法可以由gpu或npu实现,也可以由专门的图形处理器来实现。
114.应理解,在本技术实施例中涉及的芯片是以集成电路工艺制造在同一个半导体衬底上的系统,也叫半导体芯片,其可以是利用集成电路工艺制作在衬底上形成的集成电路的集合,其外层通常被半导体封装材料封装。所述集成电路可以包括各类功能器件,每一类功能器件包括逻辑门电路、金属氧化物半导体(metal oxide semiconductor,mos)晶体管、二极管等晶体管,也可以包括电容、电阻或电感等其他部件。每个功能器件可以独立工作或者在必要的驱动软件的作用下工作,可以实现通信、运算或存储等各类功能。
115.下面结合说明书附图,对本技术实施例所提供的图像处理方法进行详细介绍。
116.图4为本技术实施例所示的一种图像处理方法的流程示意图。如图4所示,该图像处理方法10包括:s10至s30。
117.s10、获取多帧原始图像。多帧原始图像为对相同的待拍摄场景拍摄的图像。
118.多帧原始图像包括:小视场角图像和大视场角图像。大视场角图像对应的视场角包括小视场角图像对应的视场角。
119.该图像处理方法的执行主体可以是上述图2所示的设置有摄像头模组的电子设备100,还可以是上述图3所示的图像处理装置200。当执行主体是电子设备时,通过摄像头模组中的摄像头获取多帧原始图像,具体通过几个摄像头或者通过哪个摄像头获取,可以根据需要进行设置和更改,本技术实施例对此不进行任何限制。当执行主体是图像处理装置时,可以通过接收接口获取多帧原始图像,而该多帧原始图像为与图像处理装置连接的电子设备的摄像头模组所拍摄得到的。
120.上述原始图像也可称为raw图。上述原始图像可以为直接拍摄得到的原始图像,也可以为对拍摄得到的视频截取的原始图像。
121.在获取的多帧原始图像中,小视场角图像和大视场角图像分别可以包括1帧,也可以包括多帧,但至少获取的多帧原始图像包括1帧小视场角图像和1帧大视场角图像。
122.应理解,小视场角图像和大视场角图像可以是同时拍摄得到的,也可以不是同时拍摄得到的,但至少应为同一时间段内对相同的待拍摄场景拍摄的图像。例如,在2秒内对相同的待拍摄场景进行拍摄,得到多帧小视场角图像和多帧大视场角图像。
123.可选地,多帧原始图像的尺寸可以全部相同。当然,多帧原始图像的尺寸也可以部分相同,部分不同;也可以完全不相同。本技术实施例对此不进行任何限制。
124.可选地,多帧原始图像可以是连续获取的,获取的间隔时间可以相同也可以不同。当然,多帧原始图像也可以不是连续获取的,本技术实施例对此不进行任何限制。
125.应理解,大视场角图像对应的视场角大于小视场角图像对应的视场角,并且,大视场角图像对应的视场角包括小视场角图像对应的视场角,由此,大视场角图像和小视场角图像具有视场角重合部分,该视场角重合部分即为小视场角图像对应的视场角。也就是说,大视场角图像包含小视场角图像中的内容。
126.还应理解,视场角越大,拍摄得到的图像细节信息越少,越不清晰,因此,大视场角图像相对于小视场角图像捕捉的细节信息较少,清晰度较低。
127.s20、对小视场角图像和大视场角图像均进行分割,分别得到小视场角图像对应的至少一个第一图像块和大视场角图像对应的至少一个第二图像块。
128.其中,至少一个第一图像块与至少一个第二图像块具有映射关系,也即,一个或多个第一图像块与一个或多个第二图像块具有映射关系。
129.应理解,对大视场角图像和小视场角图像均进行分割,分别得到的第一图像块和第二图像块个数有可能相同也有可能不同。但由于大视场角图像对应的视场角较大,所以,对大视场角图像分割得到的第二图像块的个数应大于或者等于对小视场角图像分割得到的第一图像块的个数,而且,对大视场角图像分割得到的第二图像块应包含至少一个对小视场角图像分割得到的第一图像块。
130.应理解,第一图像块与第二图像块之间可以有数量上的映射关系,也可以有内容上的映射关系,可以是一一对应的映射关系,也可以是一对多、多对一或多对多的映射关系,具体映射关系由分割方式来决定,而分割方式可以根据需要进行选择和修改,本技术实施例对此不进行任何限制。
131.可选地,作为一种可能实现的方式,上述s20可以包括:
132.利用深度学习网络模型,对小视场角图像和大视场角图像均进行语义分割(semantic segmentation),分别得到小视场角图像对应的至少一个第一图像块和大视场角图像对应的至少一个第二图像块。
133.其中,每个第一图像块和每个第二图像块均具有对应的类别,对小视场角图像进行语义分割后,当只得到一个第一图像块时,该第一图像块对应一个类别;当得到多个第一图像块时,该多个第一图像块对应不同的类别。
134.对大视场角图像进行语义分割后,当只得到一个第二图像块时,该第二图像块对应一个类别;当得到多个第二图像块时,该多个第二图像块对应不同的类别。
135.此处,上述映射关系为:m个第一图像块与n个第二图像块的类别相同,m和n分别为大于或者等于1的整数。
136.应理解,语义在语音识别中指的是语音的意思,但是,在图像领域中,语义指的是图像的内容,对图像意思的理解。基于此,语义分割指的是:从像素的角度分割出图像中的不同对象。
137.应理解,类别即为图像中的不同图像块的内容属性,换句话说,类别即为图像中的不同对象分别对应的品类或门类。类别可以根据需要进行预设和更改,本技术实施例对此
不进行任何限制。例如,类别可以为“猫”、“狗”等动物,“树”、“花朵”等植物,也可以为“桌子”“汽车”等物体。
138.例如,一张图像中有3个人,每人骑了一辆自行车,则对该图像进行语义分割时,可以分割出3个人所对应的图像块,每个图像块的类别对应为“人”类别,而分割出的3辆自行车所对应的图像块,每个图像块的类别对应为“自行车”类别。
139.应理解,该多个第一图像块可以为每个第一图像对应不同的类别,或者,可以为多组第一图像块对应不同的类别,每组第一图像块包含一个或多个第一图像块。该多个第二图像块可以为每个第二图像块对应不同的类别,或者,可以多组第二图像块对应不同的类别,每组第二图像块包含一个或多个第二图像块。
140.应理解,由于大视场角图像和小视场角图像中都可能包含属于同一类别的多个图像块,所以,在小视场角图像中,可能有多个第一图像块对应的类别相同,同理,在大视场角图像中,也可能有多个第二图像块对应的类别相同。又由于大视场角图像对应的视场角图像包括小视场角图像对应的视场角,也即,大视场角图像包含小视场角图像的内容,所以,可能存在:m个第一图像块与n个第二图像块的类别相同,m和n分别为大于或者等于1的整数。
141.例如,该映射关系为:1个第一图像块的类别与多个第二图像块的类别相同,或者;多个第一图像块的类别与1个第二图像块的类别相同,或者;多个第一图像块的类别与多个第二图像块的类别相同。
142.可选地,此处进行语义分割的深度学习网络模型可以为完全卷积网络(fcn)、segnet、deeplab中的任意一种。
143.当然,深度学习网络模型还可以为其他模型,只要能实现语义分割功能即可,具体可以根据需要进行设置,本技术实施例不进行任何限制。
144.可选地,作为另一种可能实现的方式,上述s20还可以包括:
145.根据颜色或色调,对小视场角图像和大视场角图像均进行分割,分别得到小视场角图像对应的至少一个第一图像块和大视场角图像对应的至少一个第二图像块。
146.其中,每个第一图像块和每个第二图像块均具有对应的颜色或色调,对小视场角图像进行分割后,当只得到一个第一图像块时,该第一图像块对应一个颜色或色调;当得到多个第一图像块时,该多个第一图像块对应不同的颜色或色调。
147.对大视场角图像进行分割后,当只得到一个第二图像块时,该第二图像块对应一个颜色或色调;当得到多个第二图像块时,该多个第二图像块对应不同的颜色或色调。
148.此处,上述映射关系为:p个第一图像块和q个第二图像块的颜色或色调相同,p和q分别为大于或者等于1的整数。
149.应理解,该多个第一图像块可以为每个第一图像对应不同的颜色或色调,或者,可以为多组第一图像块对应不同的颜色或色调,每组第一图像块包含一个或多个第一图像块。该多个第二图像块可以为每个第二图像块对应不同的颜色或色调,或者,可以多组第二图像块对应不同的颜色或色调,每组第二图像块包含一个或多个第二图像块。
150.应理解,由于大视场角图像和小视场角图像中都可能包含属于同一颜色或色调的多个图像块,所以,在小视场角图像中,可能有多个第一图像块对应的颜色或色调相同,同理,在大视场角图像中,也可能有多个第二图像块对应的颜色或色调相同。又由于大视场角
图像包含小视场角图像的内容,所以,可能存在:p个第一图像块与q个第二图像块的颜色相同,或者,p个第一图像块与q个第二图像块的色调相同,p和q分别为大于或者等于1的整数。
151.例如,该映射关系为:1个第一图像块的颜色与多个第二图像块的颜色相同,或者;多个第一图像块的颜色与1个第二图像块的颜色相同,或者;多个第一图像块的颜色与多个第二图像块的颜色相同。
152.s30、对至少一个第一图像块中纹理信息进行提取,并将提取的纹理信息添加至目标图像块,得到目标图像。
153.上述s30还可以表述为:对多个第一图像块中至少部分图像块的纹理信息进行提取,并将提取的纹理信息添加至目标图像块,得到目标图像。
154.其中,目标图像块为:与被提取纹理信息的第一图像块具有映射关系的第二图像块。也就是说,针对任意一个被提取纹理信息的第一图像块,目标图像块为:与被提取纹理信息的第一图像块具有映射关系的1个或多个第二图像块。第二图像块具体数量为多少,决定于分割后第二图像块与第一图像块的映射关系。
155.此外,目标图像为添加了纹理信息的大视场角图像。
156.应理解,本技术中的纹理信息指的是物体表面呈现凹凸不平的沟纹,同时也包括在物体的光滑表面上的彩色图案,通常更多地称之为花纹。纹理信息能反应第一图像块中物体的细节。
157.应理解,由于小视场角图像相对于大视场角图像的清晰度较高,所以,由小视场角图像分割的第一图像块也相对于大视场角图像分割的第二图像块的清晰度较高,由此,可以将第一图像块中的纹理信息提取后,添加至与该被提取纹理信息的第一图像块具有映射关系的第二图像块中,以提高这些第二图像块的清晰度。
158.还应理解,在从不同的第一图像块中提取出的纹理信息不同的情况下,将从不同的第一图像块中提取出的纹理信息添加至目标图像块时,可以使得不同的第二图像块增加的细节不同,在提高大视场角图像的细节丰富度的同时可以使得大视场角图像更逼真,立体效果更好。
159.此处,第二图像块除了纹理信息会改变,其他颜色、高动态范围(high dynamic range,hdr)、亮度等信息均保持不变。
160.本技术实施例提供一种图像处理方法,通过获取多帧原始图像,对多帧原始图像中的小视场角图像进行分割,得到对应的至少一个第一图像块,同时,对多帧原始图像中的大视场角图像进行分割,得到对应的至少一个第二图像块。由于大视场角图像对应的视场角包括小视场角图像对应的视场角,所以,分割后的至少一个第一图像块与至少一个第二图像块具有映射关系,基于此,再从1个或多个第一图像块中提取纹理信息并添加至与被提取纹理信息的第一图像块具有映射关系的第二图像块中。由于小视场角图像相对于大视场角图像清晰度较高,细节更丰富,因此,将从第一图像块提取的纹理信息添加给第二图像块时,可以增强第二图像块的细节,进而可以起到提高大视场角图像的清晰度和质量的作用。
161.可选地,如图5所示,在上述s20之后,s30之前,该方法10还可以包括s40。
162.s40、将小视场角图像贴到大视场角图像中的第一区域。
163.其中,第一区域为大视场角图像中与小视场角图像对应的区域。第二区域为大视场角图像中除了第一区域之外的区域。
164.应理解,第一区域即为大视场角图像中,与小视场角图像的视场角重合的区域,第二区域即为与小视场角图像的视场角未重合的区域。例如,大视场角图像的中心区域是与小视场角图像视场角重合的区域,则中心区域即为第一区域,环绕第一区域的区域即为第二区域。
165.此时,在执行s40的情况下,s30中的目标图像块将指示的是:与被提取纹理信息的第一图像块具有映射关系的且位于第二区域的第二图像块,以及,与被提取纹理信息的第一图像块具有映射关系的第二图像块中的子图像块,该子图像块是位于第二区域的。
166.应理解,小视场角图像相对于大视场角图像的清晰度较高,将小视场角图像贴到大视场角图像中的第一区域时,整体提高了大视场角图像中第一区域的清晰度,因此,后续只需要将第一图像块提取的纹理信息添加至位于第二区域的第二图像块以及第二图像块中位于第二区域的子图像块中,从而可以减少计算量,提高处理效率。
167.基于此,在添加纹理信息时,虽然,第二图像块与被提取纹理信息的第一图像块具有映射关系,但是,应该排除位于第一区域的第二图像块,以及第二图像块中与第一区域重叠的子图像块,而仅对位于第二区域的第二图像块,以及,对第二图像块中与第二区域重叠的子图像块进行纹理添加。
168.可选地,当利用深度学习网络模型,对小视场角图像和大视场角图像均进行语义分割时,该方法10还可以包括:s21至s23。
169.s21、确定至少一个第一图像块和目标图像块之间的相似度或峰值信噪比(peak signal to noise ratio,psnr)。
170.其中,可以利用结构相似性(structural similarity,ssim)算法,确定至少一个第一图像块和目标图像块之间的相似度。
171.s22、当相似度或峰值信噪比满足各自对应的预设阈值时,确定至少一个第一图像块的图像熵(image entropy)。
172.应理解,相似度对应的预设阈值、峰值信噪比对应的预设阈值均可以根据需要进行设置和更改,本技术实施例对此不进行任何限制。
173.应理解,图像熵指的是一种图像特征的统计形式,反映了图像中平均信息量的多少。其中,图像的一维熵指的是图像中灰度分布的聚集特征所包含的信息量。例如,设pi表示图像中灰度值为i的像素所占的比例,因此,一维熵可以根据以下公式进行计算:
[0174][0175]
其中,灰度值的取值范围为[0,255]。
[0176]
应理解,根据上述公式计算得到的一维熵即为图像熵。当确定出的第一图像块的图像熵较大时,说明第一图像块的信息量大,细节较多;当确定出的第一图像块的图像熵较小时,说明第一图像块的信息量小,细节较少。由此,可以设定图像熵阈值,第一图像块的图像熵与图像熵阈值来对比,以判断第一图像块的信息量大小。
[0177]
其中,图像熵阈值的大小可以根据需要进行设定和修改,本技术实施例对此不进行任何限制。
[0178]
s23、根据至少一个第一图像块的图像熵,确定将从至少一个第一图像块中提取出的纹理信息添加至目标图像块的添加方式。
[0179]
上述s23还可以表述为:根据被提取纹理信息的第一图像块的图像熵,确定从被提取纹理信息的第一图像块中提取出的纹理信息添加至目标图像块的添加方式。
[0180]
则相应的,上述s30可以表述为:
[0181]
对至少一个第一图像块中的纹理信息进行提取,并以确定出的添加方式将提取的纹理信息添加至目标图像块,得到目标图像。
[0182]
基于此,上述s23进一步可以包括:
[0183]
当至少一个第一图像块的图像熵小于图像熵阈值时,将从至少一个第一图像块提取的纹理信息添加至目标图像块的添加方式为显式添加方式。
[0184]
当至少一个第一图像块的图像熵大于或等于图像熵阈值时,将从至少一个第一图像块提取的纹理信息添加至目标图像块的添加方式为隐式添加方式。
[0185]
当确定出的添加方式为显式添加方式时,上述s30对应为:以显式添加方式,将提取的纹理信息添加至目标图像块。
[0186]
当确定出的添加方式为隐式添加方式时,上述s30对应为:以隐式添加方式,将提取的纹理信息添加至目标图像块。
[0187]
其中,添加方式包括显式添加方式和隐式添加方式。显式添加方式用于指示添加纹理信息时对纹理信息不改变,隐式添加方式用于指示在添加纹理信息时对纹理信息进行适应性变形。
[0188]
换句话说,显式添加方式指的是:将从第一图像块中提取的纹理信息,复制并粘贴至对应的目标图像块中。若第二图像块面积较大,可以多次将第一图像块中提取的纹理信息,按一定顺序复制并粘贴至对应的目标图像块中,填满目标图像块。
[0189]
隐式添加方式指的是:将从第一图像块中提取的纹理信息,复制并粘贴至对应的目标图像块中时,根据目标图像块的形状和内容,进行适应性变形,例如:进行旋转、缩放、拉伸等处理。此时,若第二图像块面积较大,可以多次将第一图像块中提取的纹理信息复制并粘贴至对应的目标图像块中,并且,每次粘贴时进行的处理可以不相同,以使得添加至目标图像块中纹理信息不完全一样。
[0190]
应理解,当第一图像块的图像熵小于图像熵阈值时,表明第一图像块中的细节信息较少,此时,可以以简单的方式,直接将纹理信息复制并粘贴至目标图像块,计算量少,效率高;而当第一图像块的图像熵大于或者等于图像熵阈值时,表明第一图像块中的细节信息较多,此时若进行显式添加,则会使得目标图像块的视觉效果较差,看起来像一模一样的小图像块僵硬的排列在一起,导致内容上时有断裂,造成图像失真等问题,因此,需以隐式添加的方式,将从第一图像块提取的纹理信息进行适应性变形后再添加给目标图像块,使得原来的目标图像块中的内容和纹理信息融合的更加自然服帖,增加图像的细节,提高视觉效果。
[0191]
例如,如图6中的(a)所示,第一图像块的图像熵小于图像熵阈值,因此,将从第一图像块中提取的纹理信息,直接复制并粘贴至目标图像块中,不进行任何改变,也即,以显式添加方式将纹理信息添加至目标图像块。
[0192]
如图6中的(b)所示,第一图像块的图像熵大于图像熵阈值,此时,由于目标图像块中的花瓣a朝左绽放,花瓣b朝右绽放,那么,在添加纹理信息时,可以将第一图像块中提取的纹理信息按照花瓣a的位置和形状进行适应性变形后添加至花瓣a中,将纹理信息按照花
瓣b的位置和形状进行适应性变形后添加至花瓣b中,也即,以隐式添加方式将纹理信息添加至目标图像块。
[0193]
可选地,如图7所示,在上述s40之前,该方法10还可以包括s50。
[0194]
s50、利用分水岭算法,确定至少一个第二图像块对应的连通域。
[0195]
当然,也可以利用其它算法,只要能确定出大视场角图像中的第二图像块所对应的连通域即可,本技术实施例对此不进行任何限制。
[0196]
示例性的,如图8中的(a)所示,大视场角图像可以被分割为多个第二图像块(例如k1~k10),然后,如图8中的(b)所示,利用分水岭算法,可以确定k1对应连通域l1,k2~k3对应连通域l2,k5对应连通域l3,k6对应连通域l4,k7对应连通域l5,k8对应连通域l7,k9对应连通域l7,k10对应连通域l8。
[0197]
在上述基础上,如图9所示,当确定出第二图像块对应的连通域后,该方法10还包括s60和s70。
[0198]
s60、确定至少一个第一图像块与目标图像块对应的连通域是否连通。
[0199]
应理解,当在该方法10中未包括将小视场角图像贴到大视场角图像上这一步骤时,目标图像块为:与被提取纹理信息的第一图像块具有映射关系的第二图像块,目标图像块对应的连通域即为该具有映射关系的第二图像块对应的连通域。
[0200]
当在该方法10中包括将小视场角图像贴到大视场角图像上这一步骤时,目标图像块为:与被提取纹理信息的第一图像块具有映射关系且位于第二区域的第二图像块,以及与被提取纹理信息具有映射关系的第二图像块中的子图像块,子图像块位于第二区域。
[0201]
当目标图像块为:与被提取纹理信息的第一图像块具有映射关系且位于第二区域的第二图像块时,目标图像块对应的连通域即为该第二图像块对应的连通域。
[0202]
当目标图像块为:与被提取纹理信息具有映射关系的第二图像块中的子图像块,子图像块位于第二区域。目标图像块对应的连通域即为该子图像块对应的连通域。
[0203]
例如,可以通过确定第一图像块与目标图像块对应的连通域相临近的边界处的像素值是否相同,来判断第一图像块与目标图像块对应的连通域是否连通。
[0204]
例如,若拍摄小视场角图像和大视场角图像的两个摄像头位置是固定的,则第一图像块与目标图像块的相对位置是固定的,由此,可以通过预先记录坐标,来判断第一图像块与目标图像块对应的连通域是否连通。
[0205]
例如,还可以先利用尺度不变特征变换(scale
‑
invariant feature transform,sift)、surf、orb等任意一种算法,对第一图像块和目标图像块进行关键点检测;再计算单应性(homography)矩阵,即,将关键点在世界坐标系中的位置转换为像素坐标系中的位置。然后,即可通过坐标映射获取第一图像块和目标图像块中的关键点在像素坐标系中的相对位置,由此,可以根据该相对位置来判断第一图像块与目标图像块对应的连通域是否连通。
[0206]
应理解,即使第一图像块与第二图像块对应的类别相同,例如,都是树叶,但是有可能是不同树木的树叶,因此,为了提高准确度,可以进一步判断第一图像块与目标图像块所对应的连通域是否连通,当第一图像块与目标图像块对应的连通域连通时,则为同一种树木的树叶的概率更大。因此,可以通过确定第一图像块与目标图像块对应的连通域是否连通,来提高后续添加纹理信息的准确度,将第一图像块中的纹理信息仅添加给相连通的连通域中的目标图像块中。
[0207]
s70、若连通,则确定至少一个第一图像块的图像熵。
[0208]
然后,继续根据至少一个第一图像块的图像熵,确定将从至少一个第一图像块中提取出的纹理信息添加至目标图像块的添加方式,再以确定出的显式添加方式或隐式添加方式将提取的纹理信息添加至目标图像块。
[0209]
s80、若非连通,则可以利用如上述s21~s23所述的方法,继续确定至少一个第一图像块与目标图像块之间的相似度或峰值信噪比,根据相似度或峰值信噪比是否满足各自对应的预设阈值,再进一步确定是否需要计算第一图像块的图像熵,当需要确定第一图像块的图像熵时,再根据确定的第一图像块的图像熵的大小,继续判断以显式添加方式或隐式添加方式将纹理信息添加至目标图像块。
[0210]
结合以上,本技术还提供如下实施例:
[0211]
实施例1,一种图像处理方法,如图10所示,该方法包括以下s1010至s1030。
[0212]
s1010、获取2帧原始图像,该2帧原始图像为对相同的待拍摄场景拍摄的图像。
[0213]
该2帧原始图像包括:1帧小视场角图像和1帧大视场角图像,大视场角图像对应的视场角包括小视场角图像对应的视场角。
[0214]
应理解,小视场角图像较为清晰,大视场角图像较为模糊。
[0215]
s1020、利用深度学习网络模型,对大视场角图像和小视场角图像均进行语义分割,分别得到小视场角图像对应的4个第一图像块和大视场角图像对应的6个第二图像块。
[0216]
上述s1020可以表述为:对小视场角图像利用深度学习网络模型进行语义分割,得到小视场角图像对应的4个第一图像块,每个第一图像块相应具有一个类别。例如:x1为天空,x2为树干,x3为树叶,x4为草地。
[0217]
对大视场角图像利用深度学习网络模型进行语义分割,得到大视场角图像对应的6个第二图像块,每个第二图像块相应具有一个类别。例如:y1为天空,y2为树干,y3为树叶,y4为草地,y5和y6为云朵。
[0218]
其中,第一图像块和第二图像块具有的映射关系为:x1和y1的类型相同,x2和y2的类别相同,x3和y3的类别相同,x4和y4的类别相同,而y5和y6没有类别相同的第一图像块。
[0219]
此处,深度学习网络模型为fcn、segnet、deeplab中的任意一种。
[0220]
s1030、对每个第一图像块中的纹理信息进行提取,并将提取的纹理信息添加至目标图像块,得到目标图像。
[0221]
目标图像块为:与被提取纹理信息的第一图像块类别相同的1个或多个第二图像块。
[0222]
目标图像为:添加了纹理信息的大视场角图像。
[0223]
上述s1030可以表述为:对x1中的纹理信息进行提取,并将提取的纹理信息添加至y1中;对x2中的纹理信息进行提取,并将提取的纹理信息添加至y2中;对x3中的纹理信息进行提取,并将提取的纹理信息添加至y3中;对x4中的纹理信息进行提取,并将提取的纹理信息添加至y4中。
[0224]
此处,由于y5和y6没有类别相同的第一图像块,所以,对y5和y6不进行添加纹理信息的处理,但是,由于其他第二图像块都进行了纹理信息的添加,所以,大视场角图像整体上还是提高了清晰度和质量。
[0225]
实施例2,一种图像处理方法,如图11所示,该方法包括以下s2010至s2070。
[0226]
s2010、获取2帧原始图像,该2帧原始图像为对相同的待拍摄场景拍摄的图像。
[0227]
该2帧原始图像包括:1帧小视场角图像和1帧大视场角图像,大视场角图像对应的视场角包括小视场角图像对应的视场角。
[0228]
其中,小视场角图像较为清晰,大视场角图像较为模糊。
[0229]
s2020、利用深度学习网络模型,对大视场角图像和小视场角图像均进行语义分割,分别得到小视场角图像对应的4个第一图像块和大视场角图像对应的6个第二图像块。
[0230]
上述s2020可以表述为:对小视场角图像利用深度学习网络模型进行语义分割,得到小视场角图像对应的4个第一图像块,每个第一图像块相应具有一个类别。例如:x1为天空,x2为树干,x3为树叶,x4为草地。
[0231]
对大视场角图像利用深度学习网络模型进行语义分割,得到大视场角图像对应的6个第二图像块,每个第二图像块相应具有一个类别。例如:y1为天空,y2为树干,y3为树叶,y4为草地,y5和y6为云朵。
[0232]
其中,第一图像块和第二图像块具有的映射关系为:x1和y1的类型相同,x2和y2的类别相同,x3和y3的类别相同,x4和y4的类别相同,y5和y6没有类别相同的第一图像块。
[0233]
此处,深度学习网络模型为fcn、segnet、deeplab中的任意一种。
[0234]
s2030、确定每个第一图像块和目标图像块之间的相似度或峰值信噪比。
[0235]
上述s2030可以表述为:确定x1和y1之间的相似度或峰值信噪比;确定x2和y2之间的相似度或峰值信噪比;确定x3和y3之间的相似度或峰值信噪比;确定x4和y4之间的相似度或峰值信噪比。
[0236]
s2040、当相似度或峰值信噪比满足各自对应的预设阈值时,则确定对应的第一图像块的图像熵。
[0237]
上述s2040可以表述为:上述x1和y1之间的相似度满足对应的预设阈值,则确定x1的图像熵;x2和y2之间的相似度不满于预设阈值,则不继续进行处理;x3和y3之间的相似度满足对应的预设阈值,则确定x3对应的图像熵,x4和y4之间的相似度也满足对应的预设阈值,则确定x4对应的图像熵。根据峰值信噪比确定每个第一图像块的图像熵的过程类似,在此不再赘述。
[0238]
当相似度或峰值信噪比不满足各自对应的预设阈值时,说明不相似,则不用确定第一图像块的图像熵,结束流程。
[0239]
s2050、当第一图像块的图像熵小于图像熵阈值时,对该第一图像块中的纹理信息进行提取,并以显式添加方式,将提取的纹理信息添加至目标图像块。
[0240]
s2060、当第一图像块的图像熵大于或者等于图像熵阈值时,对该第一图像块中的纹理信息进行提取,并以隐式添加方式,将提取的纹理信息添加至目标图像块。
[0241]
其中,显式添加方式用于指示在添加纹理信息时对纹理信息不改变;隐式添加方式用于指示在添加所述纹理信息时对纹理信息进行适应性变形。
[0242]
s2070、根据s2050和s2060,得到目标图像。
[0243]
目标图像为:以显式添加方式和/或隐式添加方式添加了纹理信息的大视场角图像。
[0244]
上述2050至s2070可以表述为:上述x1的图像熵小于图像熵阈值,则以显式添加方式,将从x1提取的纹理信息添加至y1;上述x3对应的图像熵大于图像熵阈值,则以隐式添加
方式,将从x3提取的纹理信息添加至y3;上述x4的图像熵等于图像熵阈值,也以隐式添加方式,将从x4提取的纹理信息添加至y4,由此,得到目标图像。
[0245]
实施例3,一种图像处理方法,如图12所示,该方法包括以下s3010至s3070。
[0246]
s3010、获取2帧原始图像,该2帧原始图像为对相同的待拍摄场景拍摄的图像。
[0247]
该2帧原始图像包括:1帧小视场角图像和1帧大视场角图像,大视场角图像对应的视场角包括小视场角图像对应的视场角。
[0248]
其中,小视场角图像较为清晰,大视场角图像较为模糊。
[0249]
s3020、利用深度学习网络模型,对大视场角图像和小视场角图像均进行语义分割,分别得到小视场角图像对应的4个第一图像块和大视场角图像对应的6个第二图像块。
[0250]
上述s3020可以表述为:对小视场角图像利用深度学习网络模型进行语义分割,得到小视场角图像对应的4个第一图像块,每个第一图像块相应具有一个类别。例如:x1为天空,x2为树干,x3为树叶,x4为草地。
[0251]
对大视场角图像利用深度学习网络模型进行语义分割,得到大视场角图像对应的6个第二图像块,每个第二图像块相应具有一个类别。例如:y1为天空,y2为树干,y3为树叶,y4为草地,y5和y6为云朵。
[0252]
其中,第一图像块和第二图像块之间具有的映射关系为:x1和y1的类别相同,x2和y2的类别相同,x3和y3的类别相同,x4和y4的类别相同,y5和y6没有类别相同的第一图像块。
[0253]
此处,深度学习网络模型为fcn、segnet、deeplab中的任意一种。
[0254]
s3030、结合图12,将小视场角图像贴到大视场角图像中的第一区域。
[0255]
其中,第一区域为大视场角图像中与小视场角图像对应的区域,第二区域为大视场角图像中除了第一区域之外的区域。
[0256]
此时,目标图像块为:与第一图像块类别相同且位于第二区域的第二图像块,以及,与第一图像块类别相同的第二图像块中的子图像块,子图像块位于第二区域。
[0257]
s3040、确定每个第一图像块和目标图像块之间的相似度或峰值信噪比。
[0258]
应理解,y1与x1的类别相同,y1中位于第二区域的子图像块为y12;y2与x2的类别相同,但位于第一区域中,不再计算;y3与x3的类别相同,但位于第一区域中,也不再计算;y4和x4的类别相同,y4中位于第二区域的子图像块为y42。
[0259]
由此,上述s3040可以表述为:确定x1和y12之间的相似度或峰值信噪比;确定x4和y42之间的相似度或峰值信噪比。
[0260]
s3050、当相似度或峰值信噪比满足各自对应的预设阈值时,则确定第一图像块的图像熵。
[0261]
上述s3050可以表述为:上述x1和y12之间的相似度满足对应的预设阈值,则确定x1的图像熵;x4和y42之间的相似度满足对应的预设阈值时,则确定x4对应的图像熵。根据峰值信噪比确定每个第一图像块的图像熵的过程类似,在此不再赘述。
[0262]
当相似度或峰值信噪比不满足各自对应的预设阈值时,说明不相似,则不用确定第一图像块的图像熵,结束流程。
[0263]
s3060、当第一图像块的图像熵小于图像熵阈值时,对该第一图像块中的纹理信息进行提取,并以显式添加方式,将提取的纹理信息添加至目标图像块。
[0264]
s3070、当第一图像块的图像熵大于或者等于图像熵阈值时,对该第一图像块中的纹理信息进行提取,并以隐式添加方式,将提取的纹理信息添加至目标图像块。
[0265]
其中,显式添加方式用于指示在添加纹理信息时对纹理信息不改变;隐式添加方式用于指示在添加所述纹理信息时对纹理信息进行适应性变形。
[0266]
s3080、根据s3060和s3070,得到目标图像。
[0267]
目标图像为:以显式添加方式和/或隐式添加方式添加了纹理信息的大视场角图像。
[0268]
上述s3060至s3080可以表述为:上述x1的图像熵小于图像熵阈值,则以显式添加方式,将从x1提取的纹理信息添加至y12;上述x4的图像熵等于图像熵阈值,也以隐式添加方式,将从x4提取的纹理信息添加至y42,由此,得到目标图像。
[0269]
实施例4,一种图像处理方法,如图13所示,该方法包括以下s4010至s4090。
[0270]
s4010、获取2帧原始图像,该2帧原始图像为对相同的待拍摄场景拍摄的图像。
[0271]
该2帧原始图像包括:1帧小视场角图像和1帧大视场角图像,大视场角图像对应的视场角包括小视场角图像对应的视场角。
[0272]
其中,小视场角图像较为清晰,大视场角图像较为模糊。
[0273]
s4020、根据颜色或色调,对大视场角图像和小视场角图像均进行分割,分别得到小视场角图像对应的多个第一图像块和大视场角图像对应的多个第二图像块。
[0274]
上述s4020可以表述为:根据颜色对小视场角图像进行分割,得到小视场角图像对应的多个第一图像块,每个第一图像块相应具有一个颜色。例如:w1为棕色、w2为黑色、w3为黄色、w4为绿色等。
[0275]
根据颜色对大视场角图像进行分割,得到大视场角图像对应的多个第二图像块,每个第二图像块相应具有一个颜色。例如:z1为绿色,z2和z3为棕色等。
[0276]
其中,第一图像块与第二图像块之间具有的映射关系为:w1与z2、z3的颜色相同,w4与z1的颜色相同等。
[0277]
s4030、利用分水岭算法,确定每个第二图像块对应的连通域。
[0278]
结合图13,例如:z1对应连通域r1,z2~z9对应连通域r2(如图13中所示的斜线区域)等。
[0279]
s4040、将小视场角图像贴到大视场角图像中的第一区域。
[0280]
其中,第一区域为大视场角图像中与小视场角图像对应的区域,第二区域为大视场角图像中除了第一区域之外的区域。
[0281]
此时,目标图像块为:与第一图像块颜色相同且位于第二区域的第二图像块,以及,与第一图像块颜色相同的第二图像块中的子图像块,子图像块位于第二区域。
[0282]
s4050、确定每个第一图像块与目标图像块对应的连通域是否连通。
[0283]
例如,与w1具有相同颜色的z2和z3等均位于第二区域,则z2和z3等为目标图像块,z2和z3等对应的连通域为r2。
[0284]
与w1具有相同颜色的z9有一部分位于第一区域(如图13中所示的p1),另一部分位于第二区域(如图13中所示的p2),将小视场角图像贴到大视场角图像之后,w1对应的目标图像块则为z9中位于第二区域的子图像块,由于z9中位于第二区域的子图像块对应的连通域为r2,由此,需判断第一图像块w1和连通域r2是否连通。
[0285]
s4060、若连通,则确定第一图像块的图像熵。若非连通,则结束流程。
[0286]
确定是否连通的步骤与上述s60中的描述相同,在此不再赘述。
[0287]
s4070、当第一图像块的图像熵小于图像熵阈值时,对第一图像块中的纹理信息进行提取,并以显式添加方式,将提取的纹理信息添加至目标图像块。
[0288]
s4080、当第一图像块的图像熵大于或者等于图像熵阈值时,对第一图像块中的纹理信息进行提取,并以隐式添加方式,将提取的纹理信息添加至目标图像块。
[0289]
其中,显式添加方式用于指示在添加纹理信息时对纹理信息不改变;隐式添加方式用于指示在添加所述纹理信息时对纹理信息进行适应性变形。
[0290]
s4090、根据s4070和s4080,得到目标图像。
[0291]
上述s4070至s4090可以表述为:由于第一图像块w1和连通域r2连通,当上述w1的图像熵大于图像熵阈值时,则以隐式添加方式,将从w1提取的纹理信息添加至z2和z3等位于第二区域的图像块,以及z9中位于第二区域的子图像块。
[0292]
实施例5,一种图像处理方法,如图14所示,该方法包括以下s5010至s5100。
[0293]
s5010、获取2帧原始图像,该2帧原始图像为对相同的待拍摄场景拍摄的图像。
[0294]
该2帧原始图像包括:1帧小视场角图像和1帧大视场角图像,大视场角图像对应的视场角包括小视场角图像对应的视场角。
[0295]
其中,小视场角图像较为清晰,大视场角图像较为模糊。
[0296]
s5020、利用深度学习网络模型,对大视场角图像和小视场角图像均进行语义分割,分别得到小视场角图像对应的多个第一图像块和大视场角图像对应的多个第二图像块。
[0297]
上述s5020可以表述为:利用深度学习网络模型对小视场角图像进行语义分割,得到小视场角图像对应的多个第一图像块,每个第一图像块相应具有一个类别。例如:e1为树干、e2为人、e3为树叶等。
[0298]
利用深度学习网络模型对大视场角图像进行语义分割,得到大视场角图像对应的多个第二图像块,每个第二图像块相应具有一个类别。例如:f1~f9均为树干等。
[0299]
其中,e1和f1~f9的类别都相同。
[0300]
此处,深度学习网络模型为fcn、segnet、deeplab中的任意一种。
[0301]
s5030、利用分水岭算法,确定每个第二图像块对应的连通域。
[0302]
结合图14,例如:f1对应连通域v1,f2~f9对应连通域v2(如图14中所示的斜线区域)等。
[0303]
s5040、将小视场角图像贴到大视场角图像中的第一区域。
[0304]
其中,第一区域为大视场角图像中与小视场角图像对应的区域,第二区域为大视场角图像中除了第一区域之外的区域。
[0305]
此时,目标图像块为:与第一图像块类别相同且位于第二区域的第二图像块,以及,与第一图像块类别相同的第二图像块中的子图像块,子图像块位于第二区域。
[0306]
s5050、确定每个第一图像块与目标图像块对应的连通域是否连通。
[0307]
例如,与e1具有相同类别的f2和f3等均位于第二区域,则f2和f3等为目标图像块,f2和f3等对应的连通域为v2。
[0308]
与e1具有相同的类别的f9有一部分位于第一区域(如图14中所示的q1),另一部分
位于第二区域(如图14中所示的q2),将小视场角图像贴到大视场角图像之后,e1对应的目标图像块则为f9中位于第二区域的子图像块,由于f9中位于第二区域的部分对应的连通域为v2,由此,需判断第一图像块e1和连通域v2是否连通。
[0309]
s5060、若连通,则确定第一图像块的图像熵。
[0310]
确定是否连通的步骤与上述s60中的描述相同,在此不再赘述。
[0311]
s5070、当第一图像块的图像熵小于图像熵阈值时,对第一图像块中的纹理信息进行提取,并以显式添加方式,将提取的纹理信息添加至目标图像块。
[0312]
s5080、当第一图像块的图像熵大于或者等于图像熵阈值时,对第一图像块中的纹理信息进行提取,并以隐式添加方式,将提取的纹理信息添加至目标图像块。
[0313]
其中,显式添加方式用于指示在添加纹理信息时对纹理信息不改变;隐式添加方式用于指示在添加所述纹理信息时对纹理信息进行适应性变形。
[0314]
s5090、若非连通,则利用继续确定第一图像块和目标图像块之间的相似度或峰值信噪比,当相似度或峰值信噪比满足对应的预设阈值时,则确定第一图像块的图像熵,再以s5070至s5080的方式进行纹理添加;若相似度或峰值信噪比不满足对应的预设阈值时,则结束流程。
[0315]
s5100、根据s5070至s5090,得到目标图像。
[0316]
目标图像为:以显式添加方式和/或隐式添加方式添加了纹理信息的大视场角图像。
[0317]
上述主要从电子设备或图像处理装置的角度对本技术实施例提供的方案进行了介绍。可以理解的是,电子设备和图像处理装置,为了实现上述功能,其包含了执行每一个功能相应的硬件结构或软件模块,或两者结合。本领域技术人员应该很容易意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,本技术能够以硬件或硬件和计算机软件的结合形式来实现。某个功能究竟以硬件还是计算机软件驱动硬件的方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0318]
本技术实施例可以根据上述方法示例对电子设备和图像处理装置进行功能模块的划分,例如,可以对应每一个功能划分每一个功能模块,也可以将两个或两个以上的功能集成在一个处理模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。需要说明的是,本技术实施例中对模块的划分是示意性的,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。下面以采用对应每一个功能划分每一个功能模块为例进行说明:
[0319]
图15为本技术实施例提供的一种图像处理装置的结构示意图。如图15所示,该图像处理装置200包括获取模块210和处理模块220,处理模块220可以包括第一处理模块和第二处理模块。
[0320]
该图像处理装置可以执行以下方案:
[0321]
获取模块210,用于获取多帧原始图像。多帧原始图像为对相同的待拍摄场景拍摄的图像,多帧原始图像包括:第一视场角图像和第二视场角图像。大视场角图像对应的视场角包括小视场角图像对应的视场角。
[0322]
第一处理模块,用于对小视场角图像和大视场角图像均进行分割,分别得到小视
场角图像对应的至少一个第一图像块和大视场角图像对应的至少一个第二图像块,至少一个第一图像块与至少一个第二图像块具有映射关系。
[0323]
第二处理模块,用于对第一图像块中的纹理信息进行提取,并将提取的纹理信息添加至目标图像块,得到目标图像,目标图像块为:与至少一个第一图像块具有映射关系的第二图像块。
[0324]
可选地,第一处理模块,用于利用深度学习网络模型,对小视场角图像和大视场角图像均进行语义分割,分别得到小视场角图像对应的至少一个第一图像块和大视场角图像对应的至少一个第二图像块。
[0325]
每个第一图像块和每个第二图像块均具有对应的类别,至少一个第一图像块为多个第一图像块时,多个第一图像块对应不同的类别,至少一个第二图像块为多个第二图像块时,多个第二图像块对应不同的类别。
[0326]
其中,该映射关系为:m个第一图像块与n个第二图像块的类别相同,m和n分别为大于或者等于1的整数,类别用于表示第一图像块和第二图像块的内容属性。
[0327]
可选地,第一处理模块,用于根据颜色或色调,对小视场角图像和大视场角图像均进行分割,分别得到小视场角图像对应的至少一个第一图像块和大视场角图像对应的至少一个第二图像块。
[0328]
每个第一图像块和每个第二图像块均具有对应的颜色或色调,至少一个第一图像块为多个第一图像块时,多个第一图像块对应不同的颜色或色调,至少一个第二图像块为多个第二图像块时,多个第二图像块对应不同的颜色或色调。
[0329]
其中,该映射关系为:p个第一图像块和q个第二图像块的颜色或色调相同,p和q分别为大于或者等于1的整数。
[0330]
可选地,第一处理模块,还用于将小视场角图像贴到大视场角图像中的第一区域。
[0331]
其中,第一区域为大视场角图像中与小视场角图像对应的区域,第二区域为大视场角图像中除了第一区域之外的区域,目标图像块为:与至少一个第一图像块具有映射关系且位于第二区域的所述第二图像块,以及,与至少一个第一图像块具有映射关系的第二图像块中的子图像块,子图像块位于第二区域。
[0332]
可选地,第一处理模块,还用于利用分水岭算法,确定第二图像块对应的连通域。此外,还用于确定至少一个第一图像块与目标图像块对应的连通域是否连通。
[0333]
若连通,则第一处理模块,还用于确定至少一个第一图像块的图像熵。
[0334]
第二处理模块,还用于根据至少一个第一图像块的图像熵,确定将从至少一个第一图像块中提取出的纹理信息添加至目标图像块的添加方式;
[0335]
并以确定出的添加方式将提取的纹理信息添加至目标图像块。
[0336]
可选地,第一处理模块,还用于确定至少一个第一图像块和目标图像块之间的相似度或峰值信噪比。
[0337]
当相似度或峰值信噪比满足对应的预设阈值时,则确定至少一个第一图像块的图像熵。
[0338]
第二处理模块,还用于根据至少一个第一图像块的图像熵,确定将从至少一个第一图像块中提取出的纹理信息添加至目标图像块的添加方式;
[0339]
并以确定出的添加方式将提取的纹理信息添加至目标图像块。
[0340]
可选地,第二处理模块,还用于当至少一个第一图像块的图像熵小于图像熵阈值时,对至少一个第一图像块中的纹理信息进行提取,并以显式添加方式,将提取的纹理信息添加至目标图像块。
[0341]
当至少一个第一图像块的图像熵大于或等于图像熵阈值时,对至少一个第一图像块中的纹理信息进行提取,并以隐式添加方式,将提取的纹理信息添加至目标图像块。
[0342]
其中,显式添加方式用于指示在添加纹理信息时对纹理信息不改变;隐式添加方式用于指示在添加纹理信息时对纹理信息进行适应性变形。
[0343]
作为一个示例,结合图3所示的图像处理装置,图15中的获取模块210可以由图3中的接收接口来实现,图15中的处理模块220可以由图3中的中央处理器、图形处理器、微控制器和神经网络处理器中的至少一项来实现,本技术实施例对此不进行任何限制。
[0344]
本技术实施例还提供另一种图像处理装置,包括:接收接口和处理器;
[0345]
接收接口用于从电子设备处获取多帧原始图像;多帧原始图像为对相同的待拍摄场景拍摄的图像,多帧原始图像包括:小视场角图像和大视场角图像,大视场角图像对应的视场角包括小视场角图像对应的视场角。
[0346]
处理器,用于调用存储器中存储的计算机程序,以执行如上述所述的图像处理方法10中进行处理的步骤。
[0347]
本技术实施例还提供另一种电子设备,包括摄像头模组、处理器和存储器。
[0348]
摄像头模组,用于获取多帧原始图像;多帧原始图像为对相同的待拍摄场景拍摄的图像,多帧原始图像包括:小视场角图像和大视场角图像,大视场角图像对应的视场角包括小视场角图像对应的视场角。
[0349]
存储器,用于存储可在处理器上运行的计算机程序。
[0350]
处理器,用于执行如上述所述的图像处理方法10中进行处理的步骤。
[0351]
可选地,摄像头模组包括第一摄像头和第二摄像头,第一摄像头用于对待拍摄场景以第一视场角进行拍照,第二摄像头用于对待拍摄场景以第二视场角进行拍照;第一视场角小于第二视场角。
[0352]
第一摄像头,用于在处理器获取拍照指令后,获取小视场角图像;小视场角图像对应的视场角为第一视场角。
[0353]
第二摄像头,用于在处理器获取所述拍照指令后,获取大视场角图像;大视场角图像对应的视场角为第二视场角。
[0354]
严格来说,是通过彩色摄像头和黑白摄像头中的图像处理器来获取图像。其中,图像传感器例如可以为电荷耦合元件(charge
‑
coupled device,ccd)、互补金属氧化物半导体(complementary metal oxide semiconductor,cmos)等。
[0355]
本技术实施例还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机指令;当所述计算机可读存储介质在图像处理装置上运行时,使得该图像处理装置执行如上所示的方法。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或者数据中心通过有线(例如同轴电缆、光纤、数字用户线(digital subscriber line,dsl))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取
的任何可用介质或者是包含一个或多个可以用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质(例如,软盘、硬盘、磁带),光介质、或者半导体介质(例如固态硬盘(solid state disk,ssd))等。
[0356]
本技术实施例还提供了一种包含计算机指令的计算机程序产品,当其在图像处理装置上运行时,使得图像处理装置可以执行如上所示的方法。
[0357]
图16为本技术实施例提供的一种芯片的结构示意图。图16所示的芯片可以为通用处理器,也可以为专用处理器。该芯片包括处理器401。其中,处理器401用于支持图像处理装置执行如上所示的技术方案。
[0358]
可选的,该芯片还包括收发器402,收发器402用于接受处理器401的控制,用于支持通信装置执行如上所示的技术方案。
[0359]
可选的,图16所示的芯片还可以包括:存储介质403。
[0360]
需要说明的是,图16所示的芯片可以使用下述电路或者器件来实现:一个或多个现场可编程门阵列(field programmable gate array,fpga)、可编程逻辑器件(programmable logic device,pld)、控制器、状态机、门逻辑、分立硬件部件、任何其他适合的电路、或者能够执行本技术通篇所描述的各种功能的电路的任意组合。
[0361]
上述本技术实施例提供的电子设备、图像处理装置、计算机存储介质、计算机程序产品、芯片均用于执行上文所提供的方法,因此,其所能达到的有益效果可参考上文所提供的方法对应的有益效果,在此不再赘述。
[0362]
应理解,上述只是为了帮助本领域技术人员更好地理解本技术实施例,而非要限制本技术实施例的范围。本领域技术人员根据所给出的上述示例,显然可以进行各种等价的修改或变化,例如,上述检测方法的各个实施例中某些步骤可以是不必须的,或者可以新加入某些步骤等。或者上述任意两种或者任意多种实施例的组合。这样的修改、变化或者组合后的方案也落入本技术实施例的范围内。
[0363]
还应理解,上文对本技术实施例的描述着重于强调各个实施例之间的不同之处,未提到的相同或相似之处可以互相参考,为了简洁,这里不再赘述。
[0364]
还应理解,上述各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本技术实施例的实施过程构成任何限定。
[0365]
还应理解,本技术实施例中,“预先设定”、“预先定义”可以通过在设备(例如,包括电子设备)中预先保存相应的代码、表格或其他可用于指示相关信息的方式来实现,本技术对于其具体的实现方式不做限定。
[0366]
还应理解,本技术实施例中的方式、情况、类别以及实施例的划分仅是为了描述的方便,不应构成特别的限定,各种方式、类别、情况以及实施例中的特征在不矛盾的情况下可以相结合。
[0367]
还应理解,在本技术的各个实施例中,如果没有特殊说明以及逻辑冲突,不同的实施例之间的术语和/或描述具有一致性、且可以相互引用,不同的实施例中的技术特征根据其内在的逻辑关系可以组合形成新的实施例。
[0368]
最后应说明的是:以上所述,仅为本技术的具体实施方式,但本技术的保护范围并不局限于此,任何在本技术揭露的技术范围内的变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应以所述权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。