1.本发明涉及图像处理技术领域,特别是涉及一种基于深度学习的图书馆自动盘书方法及系统。
背景技术:
2.由于场景图像中包含着丰富的文本信息,可以在很大程度上帮助人们去捕获和认知场景图像的内容及含义。如果使用计算机自动识别场景图像中包含的文本内容,并应用于盲人辅助导航、无人驾驶导航、安全保卫、危机预防及处理等领域,将给人们的工作生活带来极大便利。
3.自然场景文本定位被认为是文档分析领域中最困难也是最有价值的一个难题。自然图像中的文本越来越受到计算机视觉界的关注,因为它在文档分析、场景理解、机器人导航和图像检索等方面有大量的实际应用。虽然之前的研究在文本检测和文本识别方面都取得了显著的进展,但针对大差异的文本或背景高度复杂的文本仍然存在识别精度低的问题。
技术实现要素:
4.本发明的目的是提供一种基于深度学习的图书馆自动盘书方法及系统,以提高识别精度。
5.为实现上述目的,本发明提供了一种基于深度学习的图书馆自动盘书方法,所述方法包括:
6.步骤s1:获取各书籍对应的原始图像;
7.步骤s2:对各书籍对应的所述原始图像进行预处理,获得样本数据集;
8.步骤s3:利用标签工具对所述样本数据集中书名和书名坐标进行标注,获得标签数据集;
9.步骤s4:采用u
‑
net网络将所述标签数据集输入到east网络模型中进行训练,获得预测模型;
10.步骤s5:对测试集中的书籍进行书名坐标标注,获得多个书名坐标标注图像;
11.步骤s6:采用python算法对多个所述书名坐标标注图像分别进行裁剪;
12.步骤s7:将裁剪后的多个所述书名坐标标注图像输入所述预测模型中进行文字识别,获得测试集中各书籍对应的书名。
13.可选地,所述利用标签工具对所述样本数据集中书名和书名坐标进行标注,获得标签数据集,具体为:
14.利用labelimg标签工具,将有效的样本图像中文本行的坐标按照从左上角开始顺时针的方向存储在txt格式的文本中,获得标签数据集。
15.可选地,所述east网络模型包括:特征提取层、特征融合层和特征输出层;
16.所述特征提取层用于对已标注各书名以及各书名对应书名坐标的图像进行特征
提取,获得不同尺度特征图像;
17.所述特征融合层用于采用u
‑
net网络对不同尺度特征图像进行融合,获得融合图像;
18.所述特征输出层用于根据融合图像输出检测框位置。
19.可选地,所述对各书籍对应的所述原始图像进行预处理,获得样本数据集,具体为:
20.利用剪辑工具对各书籍对应的所述原始图像进行分割处理,获得样本数据集。
21.本发明还提供一种基于深度学习的图书馆自动盘书系统,所述系统包括:
22.获取模块,用于获取各书籍对应的原始图像;
23.预处理模块,用于对各书籍对应的所述原始图像进行预处理,获得样本数据集;
24.第一标注模块,用于利用标签工具对所述样本数据集中书名和书名坐标进行标注,获得标签数据集;
25.训练模块,用于采用u
‑
net网络将所述标签数据集输入到east网络模型中进行训练,获得预测模型;
26.第二标注模块,用于对测试集中的书籍进行书名坐标标注,获得多个书名坐标标注图像;
27.裁剪模块,用于采用python算法对多个所述书名坐标标注图像分别进行裁剪;
28.文字识别模块,用于将裁剪后的多个所述书名坐标标注图像输入所述预测模型中进行文字识别,获得测试集中各书籍对应的书名。
29.可选地,所述第一标注模块,具体为:
30.利用labelimg标签工具,将有效的样本图像中文本行的坐标按照从左上角开始顺时针的方向存储在txt格式的文本中,获得标签数据集。
31.可选地,所述east网络模型包括:特征提取层、特征融合层和特征输出层;
32.所述特征提取层用于对已标注各书名以及各书名对应书名坐标的图像进行特征提取,获得不同尺度特征图像;
33.所述特征融合层用于采用u
‑
net网络对不同尺度特征图像进行融合,获得融合图像;
34.所述特征输出层用于根据融合图像输出检测框位置。
35.可选地,所述预处理模块,具体为:
36.利用剪辑工具对各书籍对应的所述原始图像进行分割处理,获得样本数据集。
37.根据本发明提供的具体实施例,本发明公开了以下技术效果:
38.本发明将u
‑
net网络与east网络模型相结合获得预测模型,其思想为逐步合并特征图,同时保持上采样分支较小,既可以利用不同级别的特征提高识别精度,又可以节省计算成本,实现结构轻量化。
附图说明
39.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图
获得其他的附图。
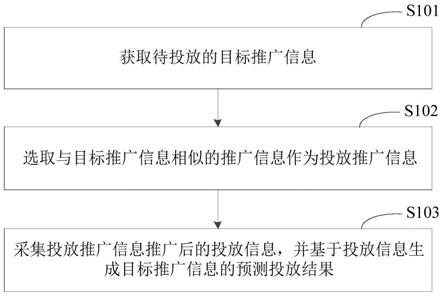
40.图1为本发明基于深度学习的图书馆自动盘书方法流程图;
41.图2为本发明剪辑后有效的样本图像示意图;
42.图3为本发明标签数据集示意图;
43.图4为本发明east网络模型示意图;
44.图5为本发明书名坐标标注图像示意图;
45.图6为本发明裁剪后的书名坐标标注图像示意图;
46.图7为本发明attention原理图;
47.图8为本发明基于深度学习的图书馆自动盘书系统结构图;
48.图9为本发明字符识别的网络结构图。
具体实施方式
49.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
50.本发明的目的是提供一种基于深度学习的图书馆自动盘书方法及系统,以提高识别精度。
51.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
52.实施例1
53.如图1所示,本发明公开一种基于深度学习的图书馆自动盘书方法,其特征在于,所述方法包括:
54.步骤s1:获取各书籍对应的原始图像。
55.步骤s2:对各书籍对应的所述原始图像进行预处理,获得样本数据集。
56.步骤s3:利用标签工具对所述样本数据集中书名和书名坐标进行标注,获得标签数据集。
57.步骤s4:采用u
‑
net网络将所述标签数据集输入到east网络模型中进行训练,获得预测模型。
58.步骤s5:对测试集中的书籍进行书名坐标标注,获得多个书名坐标标注图像。
59.步骤s6:采用python算法对多个所述书名坐标标注图像分别进行裁剪。
60.步骤s7:将裁剪后的多个所述书名坐标标注图像输入所述预测模型中进行文字识别,获得测试集中各书籍对应的书名。
61.下面对各个步骤进行详细论述:
62.步骤s2:对各书籍对应的所述原始图像进行预处理,获得样本数据集,具体为:利用剪辑工具对各书籍对应的所述原始图像进行分割处理,获得样本数据集。所述样本数据集中包括多张有效的样本图像;所述剪辑工具可以为看图王工具包里的剪辑工具,也可以使用ps剪辑工具。本发明使用的是电脑自带剪辑工具。
63.本发明采用nikon d750单反相机来获取各书籍对应的原始图像,采集形式为图像
数据,图像数据的分辨率为6016
×
4016,采集完毕后,由于各书籍对应的原始图像的样本分辨率较高且图书摆放存在不整齐的现象,所以利用剪辑工具对图像数据进行分割处理,将剪辑之后的图像看做有效的样本图像,剪辑后有效的样本图像如图2所示。
64.步骤s3:利用标签工具对所述样本数据集中书名和书名坐标进行标注,获得标签数据集;所述标签数据集包括已标注各书名以及各书名对应书名坐标的图像。本实施例中,标签工具为labelimg标签工具;标注方式是将有效的样本图像中文本行的坐标按照从左上角开始顺时针的方向存储在txt格式的文本中,获得标签数据集,所述标签数据集如图3所示。
65.步骤s4:采用u
‑
net网络将所述标签数据集输入到east网络模型中进行训练,获得预测模型。
66.因为文本区域的大小差别很大,所以定位大文本将需要更深层的特征,而定位小文本则需要浅层特征。因此,网络必须使用不同级别的特征来满足这些要求,但是在大型特征图上合并大量通道会显著增加后期计算开销。为了弥补这一点,本发明采用u
‑
shape的思想逐步合并特征图,同时保持上采样分支较小。共同建立一个网络,既可以利用不同级别的特征,又可以节省很少的计算成本。
67.如图4所示,图4中conv stage为卷积层,concat unpool为连接层。本发明所述east网络模型包括特征提取层(即feature extractor stme(pvanet))、特征融合层(即feature
‑
merging branch)和特征输出层(即output layer)。所述特征提取层用于对已标注各书名以及各书名对应书名坐标的图像进行特征提取,获得不同尺度特征图像。所述特征融合层用于采用u
‑
net网络对不同尺度特征图像进行融合,获得融合图像。所述特征输出层用于根据融合图像h4输出检测框位置(即图4中text boxes)。另外,所述特征输出层还用于根据融合图像h4输出检测框置信度(即图4中score map)、检测框旋转角度(即图4中text rotation angle)和任意四边形检测框位置(即图4中text quadrangle coordinates)。
68.所述特征提取层基于vgg16作为网络结构的骨干,所述特征提取层包括输入层、第一卷积层、第二卷积层、第三卷积层和第四卷积层;所述输入层包括16个7
×
7的卷积核,所述第一卷积层包括16个卷积核,所述第二卷积层包括64个卷积核,所述第三卷积层包括256个卷积核,所述第四卷积层包括384个卷积核。所述第一卷积层输出的第一特征图像f1为输入图像(即已标注各书名以及各书名对应书名坐标的图像)大小的1/32,所述第二卷积层输出的第二特征图像f2为输入图像大小的1/16,所述第三卷积层输出的第三特征图像f3为输入图像大小的1/8,所述第四卷积层输出的第四特征图像f4为输入图像大小的1/4。
69.本发明采用u
‑
net网络将前面抽取的不同尺度特征图像按一定的规则进行合并,具体步骤如下:
70.所述融合特征层包括第一连接层(即图4中concat unpool)、第二连接层、第三连接层和第五卷积层。
71.所述第三连接层用于对第四特征图像f4进行放大1倍,并将放大后的第四特征图像f4与第三特征图像f3依次做1
×
1和3
×
3(即图4中1*1和3*3)的卷积处理,获得第一特征融合图像h1;此实施例中,所述第三连接层中包括128个1
×
1的卷积核和128个3
×
3的卷积核。
72.所述第二连接层用于对第一特征融合图像h1进行放大1倍,并将放大后的第一特
征融合图像h1与第二特征图像f2依次做1
×
1和3
×
3的卷积处理,获得第二特征融合图像h2;所述第二连接层中包括64个1
×
1的卷积核和64个3
×
3的卷积核。
73.所述第一连接层用于对第二特征融合图像h2进行放大1倍,并将放大后的第二特征融合图像h2与第一特征图像f1依次做1
×
1和3
×
3的卷积处理,获得第三特征融合图像h3;所述第一连接层包括32个1
×
1的卷积核和32个3
×
3的卷积核。
74.所述第五卷积层用于对第三特征融合图像h3做3
×
3的卷积处理,获得融合图像h4;所述第五卷积层包括32个3
×
3的卷积核。
75.所述输出层用于对融合图像h4做1
×
1的卷积处理,获得检测框位置;所述输出层包括4个1
×
1的卷积核;所述检测框位置为已进行书名坐标标注的位置。
76.步骤s5:对测试集中的书籍进行书名坐标标注,获得多个书名坐标标注图像,具体如图5所示。图2和图5中,除了书名之外的文字没有特殊意义,本发明仅仅给出一个示例。
77.步骤s6:采用python算法对多个所述书名坐标标注图像进行裁剪,如图6所示。
78.步骤s7:将裁剪后的多个所述书名坐标标注图像输入所述预测模型中进行文字识别,获得测试集中各书籍对应的书名。具体的,本发明采用注意力机制(即attention机制),将裁剪后的多个所述书名坐标标注图像输入所述预测模型中进行文字识别,获得测试集中各书籍对应的书名。本发明基于注意力机制attention进行文字识别,融入了人类视觉对特征点的重视程度不同的特点,使其对特征点识别更加精准。
79.如图7所示,attention机制的具体计算过程,可以将其归纳为两个过程:第一个过程是根据query和key计算权重系数,第二个过程根据权重系数对value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据query和key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理。
80.在第一个阶段,根据query和key,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量cosine相似性或者通过再引入额外的神经网络来求值。
81.方式如下:
82.点积:
83.similarity(query、key
i
)=query*key
i
84.cosin相识性:
[0085][0086]
mlp网络:
[0087]
similarity(query,key
i
)=mlp(query,key
i
)
[0088]
similarity表示q和k的相似性
[0089]
encoder
‑
decoder框架在文本处理领域的应用:将构成source的元素分解成是由一系列的(key,value)组成的数据对,此时给定target中的某个元素query,通过计算query和各个key的相似性或者相关性,得到每个key对应value的权重系数,然后对value进行加权求和,求得最终的注意力权重。所以根本上attention机制是对source中元素的value值进行加权求和,而query和key用来计算对应value的权重系数。source和target可以是语言、语音、图片等。注意力机制实际上可以看成是一个query到一系列key
‑
value对的映射。
从图7可以理解,从每个key地址都会取出内容,取出内容的重要性根据query和key的相似性来决定,之后对value进行加权求和,这样就可以取出最终的value值,即是attention权值。
[0090]
第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似softmax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过softmax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
[0091][0092]
第二阶段的计算结果a
i
即为value
i
对应的权重系数,然后进行加权求和即可得到attention数值。加权求和公式如下:
[0093][0094]
经过上面三个阶段的计算,就可以得到针对query的注意力权值。
[0095]
注意力权值的作用如下:
[0096]
汉字识别网络主要有三部分:卷积神经网络、循环神经网络和注意力模型。在网络的前端,卷积神经网络自动从输入的图片中提取特征,接着注意力模型根据循环神经网络神经元的隐藏状态及上一时刻的输出计算出注意力权重,最后将卷积神经网络输出的特征图与注意力权重结合起来,输入到lstm中进行解码后,得到整个字符集的概率分布,最后直接提取概率最高的编号所对应的字符作为最后的识别结果。字符识别的网络结构如9图所示。
[0097]
实施例2
[0098]
如图8所示,本发明还提供一种基于深度学习的图书馆自动盘书系统,所述系统包括:
[0099]
获取模块801,用于获取各书籍对应的原始图像。
[0100]
预处理模块802,用于对各书籍对应的所述原始图像进行预处理,获得样本数据集。
[0101]
第一标注模块803,用于利用标签工具对所述样本数据集中书名和书名坐标进行标注,获得标签数据集。
[0102]
训练模块804,用于采用u
‑
net网络将所述标签数据集输入到east网络模型中进行训练,获得预测模型。
[0103]
第二标注模块805,用于对测试集中的书籍进行书名坐标标注,获得多个书名坐标标注图像。
[0104]
裁剪模块806,用于采用python算法对多个所述书名坐标标注图像分别进行裁剪。
[0105]
文字识别模块807,用于将裁剪后的多个所述书名坐标标注图像输入所述预测模型中进行文字识别,获得测试集中各书籍对应的书名。
[0106]
作为一种可选的实施方式,本发明所述第一标注模块803,具体为:
[0107]
利用labelimg标签工具,将有效的样本图像中文本行的坐标按照从左上角开始顺时针的方向存储在txt格式的文本中,获得标签数据集。
[0108]
作为一种可选的实施方式,本发明所述east网络模型包括:特征提取层、特征融合层和特征输出层;
[0109]
所述特征提取层用于对已标注各书名以及各书名对应书名坐标的图像进行特征提取,获得不同尺度特征图像。
[0110]
所述特征融合层用于采用u
‑
net网络对不同尺度特征图像进行融合,获得融合图像。
[0111]
所述特征输出层用于根据融合图像输出检测框位置。
[0112]
作为一种可选的实施方式,本发明所述预处理模块802,具体为:
[0113]
利用剪辑工具对各书籍对应的所述原始图像进行分割处理,获得样本数据集。
[0114]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0115]
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。