技术特征:
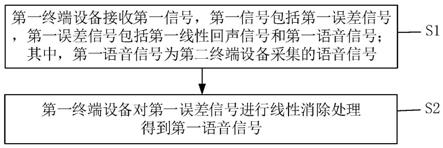
1.一种噪声提取方法,其特征在于,所述方法包括:获取目标语音数据对应的目标文本信息;将所述目标文本信息输入到预先训练的噪声识别模型中,获得所述目标文本信息映射到各个预设噪声标签的预测概率;其中,所述预设噪声标签用于表示预测噪声文本的索引位置,所述预测噪声文本为所述目标文本信息中的词组,所述词组为所述目标文本信息中一个字或连续的多个字的组合;将所述预测概率最大的预设噪声标签对应的所述预测噪声文本确定为所述目标噪声文本。2.根据权利要求1所述的方法,其特征在于,所述各个预设噪声标签是由预设文本长度确定的,所述各个预设噪声标签的生成方式包括:确定形成预设文本长度的各个位的位置标号;将所述任一位的位置标号或者任一连续多个位的位置标号作为预设噪声标签。3.根据权利要求2所述的方法,其特征在于,所述获取目标语音数据对应的目标文本信息包括:获取目标语音数据对应的语音数据文本;若所述语音数据文本的长度等于所述预设文本长度,则将所述语音数据文本依次填入所述形成预设文本长度的各个位,得到所述目标文本信息;若所述语音数据文本的长度大于所述预设文本长度,则获取所述语音数据文本中,从第一个字开始且长度等于所述预设文本长度的文本信息,并依次填入形成所述形成预设文本长度的各个位,得到所述目标文本信息;若所述语音数据文本的长度小于所述预设文本长度,则在所述语音数据文本的最后一个字之后添加至少一个指定字符,并依次填入所述形成预设文本长度的各个位,得到所述目标文本信息;其中,所述语音数据文本的长度与所述至少一个指定字符的长度之和为所述预设文本长度。4.根据权利要求1
‑
3任一项所述的方法,其特征在于,所述将所述目标文本信息输入到预先训练的噪声识别模型中,获得所述目标文本信息映射到各个预设噪声标签的预测概率包括:将所述目标文本信息输入至噪声识别模型中的特征提取网络,获取所述目标文本信息的目标特征;将所述目标特征输入至所述噪声识别模型中的分类网络,获得所述目标文本信息的特征映射到各个预设噪声标签的预测概率。5.根据权利要求4所述的方法,其特征在于,所述特征提取网络包括:输入层、字嵌入层、卷积层、激活层、池化层和融合层;所述输入层,用于生成与所述目标文本信息对应的目标数组;其中,所述目标数组中的各元素为:所述目标文本信息中每个字的索引值;所述字嵌入层,用于生成所述目标数组对应的编码矩阵;其中,所述编码矩阵中的各元素为:所述目标数组中的每个索引值所表征的字的字向量;所述卷积层,用于利用多种卷积核,分别对所述编码矩阵进行特征提取,得到所述目标文本信息的多个初始特征矩阵;
所述激活层,用于利用预设激活函数,分别对各个初始特征矩阵进行激活,得到所述目标文本信息的多个激活特征矩阵;所述池化层,用于按照预设的下采样方式,分别对各个激活特征矩阵进行预设维度的压缩,得到所述目标文本信息的多个压缩维度后的下采样特征矩阵;所述融合层,用于对所述多个下采样特征矩阵进行融合,得到所述目标文本信息的目标特征矩阵,作为所述目标文本信息的目标特征。6.根据权利要求5所述的方法,其特征在于,所述分类网络包括:全连接层和归一化层;所述全连接层,用于利用所述目标特征矩阵计算初始概率矩阵;其中,所述初始概率矩阵中的各元素用于表征各个预设噪声标签对应的所述目标文本信息中的词组为目标噪声文本的初始概率值;所述归一化层,用于对所述初始概率矩阵中的各元素进行归一化,得到所述目标文本信息的目标概率矩阵;其中,所述目标概率矩阵中的各元素为:所述目标文本信息映射到各个预设噪声标签的预测概率。7.根据权利要求4所述的方法,其特征在于,所述噪声识别模型的训练方式,包括:获取预设的添加有噪声标注的样本文本信息;其中,所述噪声标注为噪声文本在所述样本文本信息中的索引位置;针对每一样本文本信息,将该样本文本信息输入到待训练的初始模型中,获得该样本文本信息映射到各个预设噪声标签的概率;若概率最大的预设噪声标签与该样本文本信息的噪声标注匹配,则进行下一条样本文本信息训练;若概率最大的预设噪声标签与该样本文本信息的噪声标注不匹配,则调整所述初始模型的参数,返回所述将该样本文本信息输入到待训练的初始模型中,获得该样本文本信息映射到各个预设噪声标签的概率的步骤,直至所述初始模型收敛。8.根据权利要求1
‑
4任一项所述的方法,其特征在于,所述方法还包括:删除所述目标文本信息中的目标噪声文本,得到待处理文本信息;按照预设处理方式,对所述待处理文本信息进行自然语言处理,得到关于所述待处理文本信息的处理结果。9.一种指令识别方法,其特征在于,所述方法包括:利用权利要求1
‑
8任一项所述的噪声提取方法,确定目标指令对应的指令文本信息中的目标噪声文本信息;删除所述指令文本信息中的所述目标噪声文本信息,得到待识别文本信息;将所述待识别文本信息输入到预先训练的意图识别模型中,获得所述待识别文本信息所表征的目标用户意图;将所述待识别文本信息输入到预先训练的命名实体识别模型中,获得所述待识别文本信息的目标命名实体识别结果;基于所述目标用户意图和所述目标命名实体识别结果,执行所述目标指令。10.一种电子设备,其特征在于,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;存储器,用于存放计算机程序;
处理器,用于执行存储器上所存放的程序时,实现权利要求1
‑
9任一所述的方法步骤。
技术总结
本发明实施例提供了一种噪声提取及指令识别方法和电子设备,涉及人工智能技术领域。该方法包括:获取目标语音数据对应的目标文本信息;将所述目标文本信息输入到预先训练的噪声识别模型中,获得所述目标文本信息映射到各个预设噪声标签的预测概率;其中,所述预设噪声标签用于表示预测噪声文本的索引位置,所述预测噪声文本为所述目标文本信息中的词组,所述词组为所述目标文本信息中一个字或连续的多个字的组合;将所述预测概率最大的预设噪声标签对应的所述预测噪声文本确定为所述目标噪声文本。与现有技术相比,应用本发明实施例提供的方案,可以实现在不借助停用词表的情况下,提取待进行自然语言处理的文本中的噪声。提取待进行自然语言处理的文本中的噪声。提取待进行自然语言处理的文本中的噪声。
技术研发人员:米良 黄海荣 李林峰
受保护的技术使用者:湖北亿咖通科技有限公司
技术研发日:2021.07.22
技术公布日:2021/10/28
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。