1.本发明涉及的是一种神经网络应用领域的技术,具体是一种针对车险用户基于机器学习的换车预测方法。
背景技术:
2.通过对现有技术的查新,目前业界对于精准营销领域已有一些成果。用户画像技术是精准营销领域最常用的技术手段,利用现代计算机技术收集、分析用户信息,通过机器学习、深度学习等技术对用户特征进行分类、筛选,建立用户画像,实现用户潜在价值挖掘、用户价值细分和用户管理等功能。在用户画像的基础上,通过个性化营销策略,实现企业商业目标以及利润增长。
技术实现要素:
3.本发明针对现有技术存在的上述不足,提出一种面向车险用户的智能化换车预测系统及方法。
4.本发明是通过以下技术方案实现的:
5.本发明涉及一种面向车险用户的智能化换车预测方法,根据历史用户车险保单数据中前后年份保单中投保车辆是否一致来标注用户是否换车以及所更换的车型,筛选用户相关特征集以训练机器学习以及深度学习模型,完成用户是否换车以及是否更换指定车型的精准预测。
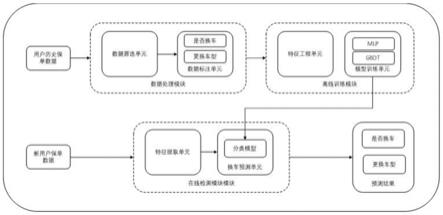
6.本发明涉及一种实现上述方法的面向车险用户的基于机器学习的换车预测系统,包括:数据处理模块、离线训练模块以及在线预测模块,其中:数据处理模块根据用户车险保单信息,进行数据筛选和数据标注处理并输出用户是否换车及更换车型结果,离线训练模块根据用户车险保单及标注信息,进行机器学习模型训练并输出预测模型,在线预测模块根据新的用户保单信息及预测模型,进行用户是否换车以及更换指定车型预测,输出用户是否换车以及是否更换指定车型。
7.所述的数据处理模块包括:数据筛选单元和数据标注单元,其中:数据筛选单元从用户车险保单数据中筛选有效样本,根据保单的投保日期、被投保人证件号码字段进行数据清洗,获得同一用户不同年份的保单数据,提取保单数据中投保用户信息、投保车辆信息以及保险信息等相关特征;数据标注单元从筛选出来的同一用户不同年份的保单数据中,根据保单中的投保车辆vin码是否一致,判断用户不同年份投保的车辆是否一致,从而标注用户是否换车以及所更换的车型。
8.所述的离线训练模块包括:特征工程单元、模型训练单元,其中:特征工程单元将数据处理模块中提取到的相关特征进行清洗、整理、归一化,通过字符数据数值化的方法将单个用户的保单信息变成一组特征值,并使用xgboost筛选较为重要的特征;模型训练单元将数据划分为训练数据集和测试数据集,使用训练集训练机器学习模型,使用测试集测试模型效果,并将效果最优的模型保存后提供给在线预测模块进行预测。
9.所述的在线预测模块包括:特征提取单元、换车预测单元,其中:特征提取单元根据用户导入想要预测的保单信息作为在线预测的最初特征输入,根据离线训练模块中的特征工程单元所使用的方法,提取、筛选相关字段并进行标准化处理;换车预测单元将处理后的特征输入到所对应的训练好的模型,模型输出换车预测结果。技术效果
10.本发明整体解决了通过用户车险保单预测用户是否换车及更换车型的问题;与现有技术相比,本发明基于车险保单数据完成换车及更换车型预测;使用用户的车险保单数据即可完成用户的换车及更换车型的预测,不需要大量用户个人信息,更加实用;训练的模型可以对所有的车险用户是否换车进行预测,同时本发明的方法可以扩展到多种车型的换车预测,灵活性强。
附图说明
11.图1为本发明系统结构图。
具体实施方式
12.如图1所示,为本实施例涉及的一种面向车险用户的智能化换车预测,包括:数据处理模块、离线训练模块以及在线预测模块,其中:数据处理模块根据用户车险保单信息,进行数据筛选和数据标注处理并输出用户是否换车及更换车型结果,离线训练模块根据用户车险保单及标注信息,进行机器学习模型训练并输出预测模型,在线预测模块根据新的用户保单信息及预测模型,进行用户是否换车以及更换指定车型预测,输出用户是否换车以及是否更换指定车型。
13.所述的数据处理模块包括:数据筛选单元和数据标注单元,其中:数据筛选单元进行数据收集和数据筛选,数据标注单元根据被投保人证件号码、字段,在筛选出来的数据中查找下一年的同一用户的保单数据并进行数据标注。
14.所述的数据收集是指:收集保险公司提供的用户保单数据,规范化各字段数据格式,提取保单数据中的用户信息、车辆信息以及保险信息等50个相关字段作为特征,建立用户保单数据库。
15.所述的数据筛选是指:根据保单的投保日期、被投保人证件号码、字段,在用户保单数据库中查找出同一用户在不同年份都有投保车辆的数据,根据保单的vin码、字段,删去不同vin码、数量大于1的保单数据,保留不同年份投保车辆数目都为1的数据,即在用户保单数据库中筛选出同一用户在不同年份都投保1辆车的数据记录。
16.所述的数据标注具体为:当本年度投保车辆的vin码、和下一年度投保车辆的vin码、字段值不同,则标注为换车,同时使用下一年保单数据中的投保车型标注用户所更换的车型;当本年度投保车辆的vin码、和下一年度投保车辆的vin码、字段值相同,则标注为未换车。
17.所述的离线训练模块包括:特征工程单元、模型训练单元,其中:特征工程单元对数据处理模块得到的数据进行异常值处理、数据标准化和特征筛选,模型训练单元根据筛选出的特征进行mlp模型和gbdt模型的建模训练。
18.所述的异常值处理是指:对数据处理模块得到的特征中的缺省值或者异常值进行
异常值处理,处理特征包括:地区、三责险保额、签单保费、交通违法系数、预期赔付率、车系、协商实际价值、车龄、车型分类、车型细分类、车型风险等级、车辆类型、排量、平台返回出险次数、平台返回ncd系数、车辆案件总数、车辆赔付金额、被保人性别、投保人是否寿险客户、是否为寿险长险有效保单客户、投保人购买寿险总保单数、年龄、车型、新车购置价、燃料类型等50个字段。由于未换车数据量较大,对于未换车用户的数据若存在缺省值,异常数据直接去除,对于换车用户的数据若存在异常,通过均值填充、热卡填充、人工填补等方式进行处理。
19.所述的人工填补适合缺失值可以由其余数据推测出的部分,如性别可由省份证号推测。
20.所述的热卡填充是指:对于一个包含空值的对象,热卡填充法在完整数据中找到一个与它最相似的对象,然后用这个相似对象的值来进行填充。
21.所述的数据标准化是指:将上述特征值符合正态分布的数值类型的特征,通过标准化后,转换成标准正态分布,如车龄、新车购置价、协商实际价值等直接转化为标准正态分布。将上述其余数值类型的特征,通过无量纲化方法中的区间缩放法进行标准化处理,处理公式为,其中x为该特征的原值,min为该特征所有值中的最小值,max为该特征所有值中的最大值,x
′
为原值标准化后的值。将上述特征值属于字符串类型的特征,通过onehot编码的方法将字符数据转化为到数值上。
22.所述的特征筛选是指:使用xgboost对上述标准化后的50个特征进行特征筛选,筛选对于分类模型来说重要度较高的特征。xgboost的主要参数设置为:输入数据的长度为50,booster为树类型(gbtree),激活函数为multi:softmax,树的最大深度为6层,gamma值为0.1。训练轮次100轮。采用十折交叉验证法,从数据集中选出5000个换车数据,5000个未换车数据,输入到xgboost模型中进行学习,输出50个特征的特征重要性结果,并统计十折实验中特征重要性靠前的特征集。根据统计结果,从50个特征中筛选出重要程度高的特征,共28个,包括:地区、三责险保额、签单保费、交通违法系数、预期赔付率、最终赔付率、车系、协商实际价值、车龄、车型分类、车型细分类、车型风险等级、车辆类型、排量、平台返回出险次数、平台返回ncd系数、车辆案件总数、车辆赔付金额、被保人性别、投保人是否寿险客户、是否为寿险长险有效保单客户、投保人购买寿险总保单数、年龄、车型、险种、新车购置价、燃料类型、投保人已缴总保费等。
23.所述的mlp模型是指:选定多层感知机mlp作为分类模型,mlp的网络结构及参数包括:一个输入层,三个隐藏层,以及一个输出层。三层隐藏层的节点分别为128、256以及64,隐藏层采用激活函数leakyrelu,并且设置对应的dropout为0.2。输出层的激活函数为sigmod。
24.将特征工程单元得到的数据逐一分开训练得到不同的模型,按照种类可以分为用户是否会换车模型,换车后是否会换成宝马、路虎、雷克萨斯、大众、梅赛德斯
‑
奔驰等多个目标车型的二分类模型。对于是否换车模型,当用户换车,则标签为1,未换车,则标签为0。对于换成目标车型模型,换成目标车型的数据标记为1,换成其它车型的数据标记为0。将所有数据按照4:1划分,其中75%数据进行训练,25%的数据作为测试集。
25.所述的leakyrelu的公式为sigmod的公式为
26.mlp的模型效果如下表所示。
27.所述的gbdt模型是指:选取sklearn库中的gradientboostingclassifier模型,实验中设置树的大小为500,树的最大深度为4,学习率设置为0.1,树分裂一个内部节点需要的最少样本数为100。损失函数为对数损失函数l(y,p(y|x))=
‑
logp(y|x)。
28.将特征工程单元得到的数据逐一分开训练得到不同的模型,此处所训练的模型数据与上述mlp模型数据相同,将所有数据划4:1,其中75%数据进行训练,25%的数据作为测试集。
29.gbdt模型效果如下表所示。
30.准确率(accuracy),表示所有预测结果正确的样本占所有样本比例。
31.精确率(precision),表示预测结果为有效的样本中真实有效的样本比例。
32.召回率(recall),表示预测结果为有效的样本占所有真实有效样本的比例。
33.将上述训练好的效果最优的模型保存到本地,用于在线检测模块。
34.所述的在线检测模块具体包括:特征提取单元、换车预测单元,其中:特征提取单元使用离线训练模块中的特征工程单元的方法提取预测所需要的用户的多维度特征信息,换车预测单元将得到的用户多维度特征批量输入到保存好的模型中,得到用户是否换车以及是否更换目标车型的预测值。
35.所述的多维度特征信息包括:地区、三责险保额、签单保费、交通违法系数、预期赔付率、最终赔付率、车系、协商实际价值、车龄、车型分类、车型细分类、车型风险等级、车辆类型、排量、平台返回出险次数、平台返回ncd系数、车辆案件总数、车辆赔付金额、被保人性别、投保人是否寿险客户、是否为寿险长险有效保单客户、投保人购买寿险总保单数、年龄、车型、险种、新车购置价、燃料类型、投保人已缴总保费等。
36.经过具体实际实验,在linux操作系统下,配置python编程语言,使用shell命令启动上述模型,模型在测试集上对于是否换车的准确率达到70.2%,对于更换车型的准确率最高达到74.8%。实验结果表明本实施例基于保单数据进行换车及更换车型预测具有一定的效果和实用性。
37.上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。