1.本发明属于图像数据处理领域,具体涉及一种基于摄影测量数据的尾矿库语义分割方法。
背景技术:
2.尾矿库是用以堆存金属或非金属矿山进行矿石选别后排出的尾矿或其他工业废渣的场所,是矿山企业必不可少的基础设施及环境保护工程。尾矿库具有的高势能使得矿山作业现场存在人造泥石流的潜在危险。一旦失事,极易造成溃坝并引发重特大安全事故。
3.尾矿库地物信息(例如初期坝、堆积坝、水面、干滩等)的语义分割是对尾矿库现状进行分析的重要基础,尾矿库地物信息的语义分割是测量干滩长度等指标的重要支撑。传统的尾矿库现状分析方法通常依靠人工,通过人工现场排查或者人工使用测量工具获取尾矿库的几何信息;但是,人工作业模式效率低、数据完整性不强。
技术实现要素:
4.本发明的目的在于提供一种基于摄影测量数据的尾矿库语义分割方法,该方法能够快速地对尾矿库进行语义分割。
5.本发明提供的这种基于摄影测量数据的尾矿库语义分割方法,包括如下步骤:
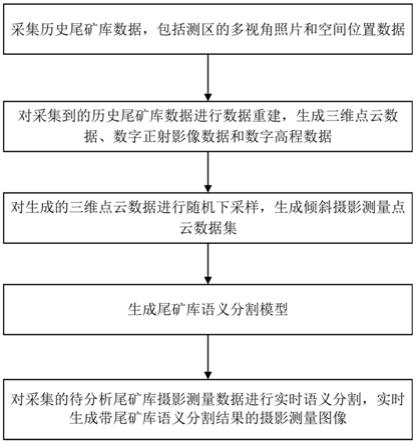
6.s1.采集历史尾矿库数据,包括测区的多视角照片和空间位置数据;
7.s2.对采集到的历史尾矿库数据进行数据重建,生成三维点云数据、数字正射影像数据和数字高程数据;
8.s3.对生成的三维点云数据进行随机下采样,生成倾斜摄影测量点云数据集;
9.s4.生成尾矿库语义分割模型;
10.s5.对采集的待分析尾矿库摄影测量数据进行实时语义分割,实时生成带尾矿库语义分割结果的摄影测量图像。
11.所述的步骤s1,历史尾矿库数据包括尾矿库初期坝数据、堆积坝数据、水面数据和干滩数据;具体为采用航测多旋翼无人机进行数据采集,航测多旋翼无人机包括智能避障模块、高精度三轴云台和集成rtk模块;rtk模块能够为无人机提供实时厘米级定位数据,同时设计无人机的飞行航线和相机工作模式参数。
12.所述的步骤s2,具体为采用影像处理软件,生成三维点云数据、数字正射影像数据和数字高程数据。
13.所述的步骤s3,具体为生成倾斜摄影测量点云数据集data={x
i
},其中,倾斜摄影测量点云数据集中的第i个采样点表示为x
i
={x
i
,y
i
,z
i
,r
i
,g
i
,b
i
};其中,x
i
表示点的经度,y
i
表示点的纬度,z
i
表示点的高度,r
i
表示rgb红色,g
i
表示rgb绿色,b
i
表示rgb蓝色;i=1,2,
…
,n,n为采样点个数。
14.所述的步骤s4中,尾矿库语义分割模型的生成方法具体采用有监督深度学习方法得到,同时采用的模型引入注意力机制的动态图卷积神经网络,有监督深度学习方法包括
如下步骤:
15.a1.选取一个尾矿库语义分割场景,获取步骤s1
‑
s3得到的下采样之后的倾斜摄影测量点云数据集、数字正射影像数据和数字高程数据;
16.a2.在数字正射影像数据上通过经验将初期坝、堆积坝、水面和干滩进行手工分割,为每个像素标识类别;
17.a3.根据三维点和数字正射影像像素点的关系,为步骤a1得到的倾斜摄影测量点云数据集中的每个点x
i
找到在数字正射影像数据的对应像素点,将对应像素点的类别标签y
i
作为x
i
的标签,最后将x
i
和y
i
合并,生成初始训练数据集;
18.a4.选择若干个尾矿库语义分割场景,重复步骤a1
‑
a3,获得多场景的训练数据集;
19.a5.构建基于深度学习的尾矿库语义分割模型;尾矿库语义分割模型包括动态图卷积神经网络模块和通道注意力模块;其中,动态图卷积神经网络模块用于对点云中邻域样本点的关系进行建模;通道注意力模块用于对若干个通道间的特征聚合关系进行建模;
20.a6.选择神经网络训练平台,设置目标优化函数和优化方法,设置尾矿库语义分割模型中的迭代次数、学习率、训练误差和批训练数目训练参数,采用步骤a4中的多场景的训练数据集进行测试。
21.所述的步骤a5,具体构建基于深度学习的尾矿库语义分割模型的方法如下:基于深度学习的尾矿库语义分割模型,包括1个输入层、2个边卷积层、3个多层感知器和1个输出层,在边卷积层和多层感知器层之间引入通道注意力模块;其中,边卷积层用于提取和融合每个点的独立特征和该点的局域特征;多层感知器用来对边卷积获得的特征信息进行特征融合和特征降维,最后接输出层输出四类别的one
‑
hot编码。
22.所述的边卷积层具体为网络的每一层构造具有顶点和边的局部有向图结构,设为二元组g
l
=(v
l
,e
l
);其中,v
l
为第l层点云顶点;e
l
为第l层点云边;对任意中心顶点通过基于点向欧几里得距离的knn算法获取最近邻域点集{x
i1
,x
i2
,
…
,x
ik
},并建立中心顶点x
i
与领域x
j
之间边特征的联系;顶点的特征融合了上一层网络的顶点特征和当前层网络动态更新的邻域特征,并随着网络深度不断迭代更新;
23.在计算领域动态特征时,边卷积层定义边缘特征为:
[0024][0025]
其中,h
θ
表示使用可学习参数θ构成的非线性函数;x
i
为中心顶点;x
j
为领域;边卷积模块通过通道注意力模块提取动态特征。
[0026]
所述的通道注意力模块,具体为将边卷积层提取的局部空间信息压缩成一个通道描述器,对多个通道间的特征聚合关系进行建模,计算每个通道特征聚合时的权重,最后加权聚合每个通道表示来获得局部通道结构信息;通道注意力模块主要包括全局信息嵌入和权重自适应调整两个步骤:
[0027]
b1.全局信息嵌入将每个通道的全局空间信息压缩为一个通道描述符,作为该通道重要性的一个统计量;对于特征矩阵其中,k为特征的维数,c为特征通道的数目,分别从第c个通道的k维空间计算各个通道的通道统计量z
c
:
[0028][0029]
其中,k为特征维度的序号;表示第c个通道第k个维度的特征;
[0030]
b2.权重自适应调整具体为,通道特征聚合时的权重,自适应步骤基于全局信息嵌入得到的统计量来建立通道的依赖关系;通过门控机制和激活函数,并设计两层全连接层来计算第c个通道的依赖关系s
c
:
[0031]
s
c
=σ(w2g(w1z
c
))
[0032]
其中,c∈{1,2,...,c};g(
·
)选用relu函数作为激活函数;σ(
·
)选用sigmoid函数作为激活函数;w1为升维全连接参数;w2为降维全连接层参数。
[0033]
所述的步骤s4,具体为根据尾矿库语义分割模型,输出长度为n=3的独热编码w;语义分割模型有4个输出节点,每个节点有0和1两种状态;对于倾斜摄影测量点云数据集中的第i个采样点x
i
={x
i
,y
i
,z
i
,r
i
,g
i
,b
i
};其中,x
i
表示点的经度,y
i
表示点的纬度,z
i
表示点的高度,r
i
表示rgb红色,g
i
表示rgb绿色,b
i
表示rgb蓝色;i=1,2,
…
,n,n为采样点个数;4个输出节点中有且仅有一个输出节点的输出状态为1,剩余3个输出节点的输出状态为0。
[0034]
所述的步骤s5,语义分割结果包括关于初期坝、堆积坝、水面和干滩的语义分割结果。
[0035]
本发明提供的这种基于摄影测量数据的尾矿库语义分割方法,结合倾斜摄影测量生产的点云数据和dom数据,基于深度学习模型对尾矿库进行语义分割,能够准确高效地对尾矿库土地类型进行分割,方法简单,成本低,数据完整性高。
附图说明
[0036]
图1为本发明系统的结构示意图。
[0037]
图2为本发明实施例的基于深度学习的尾矿库语义分割模型示意图。
[0038]
图3为本发明实施例中第一个边卷积模块示意图。
具体实施方式
[0039]
如图1为本发明方法的流程示意图:本发明提供的这种基于摄影测量数据的尾矿库语义分割方法,包括如下步骤:
[0040]
s1.采集历史尾矿库数据,包括测区的多视角照片和空间位置数据;
[0041]
s2.对采集到的历史尾矿库数据进行数据重建,生成三维点云数据、数字正射影像数据(dom)和数字高程数据(dsm);
[0042]
s3.对生成的三维点云数据进行随机下采样,生成倾斜摄影测量点云数据集;
[0043]
s4.生成尾矿库语义分割模型;
[0044]
s5.对采集的待分析尾矿库摄影测量数据进行实时语义分割,实时生成带尾矿库语义分割结果的摄影测量图像。
[0045]
所述的步骤s1,历史尾矿库数据包括尾矿库初期坝数据、堆积坝数据、水面数据和干滩数据;在实施例中具体为根据尾矿库观测需求,采用航测多旋翼无人机采集数据,航测多旋翼无人机包括智能避障模块、高精度三轴云台和集成rtk模块;rtk模块能够为无人机提供实时厘米级定位数据,同时设计无人机的飞行航线和相机工作模式参数。
[0046]
所述的步骤s2,具体为采用影像处理软件,生成三维点云数据、数字正射影像数据(dom)和数字高程数据(dsm)。
[0047]
所述的步骤s3,具体为生成倾斜摄影测量点云数据集data={x
i
},其中,倾斜摄影测量点云数据集中的第i个采样点表示为x
i
={x
i
,y
i
,z
i
,r
i
,g
i
,b
i
};其中,x
i
表示点的经度,y
i
表示点的纬度,z
i
表示点的高度,r
i
表示rgb红色,g
i
表示rgb绿色,b
i
表示rgb蓝色;i=1,2,
…
,n,n为采样点个数。
[0048]
所述的步骤s4中,尾矿库语义分割模型的生成方法具体采用有监督深度学习方法得到,同时采用的模型引入注意力机制的动态图卷积神经网络(dgcnn),有监督深度学习方法包括如下步骤:
[0049]
a1.选取一个尾矿库语义分割场景,获取步骤s1
‑
s3得到的下采样之后的倾斜摄影测量点云数据集、数字正射影像数据和数字高程数据;
[0050]
a2.在数字正射影像数据上通过经验将初期坝、堆积坝、水面和干滩进行手工分割,为每个像素标识类别;
[0051]
a3.根据三维点和数字正射影像像素点的关系,为步骤a1得到的倾斜摄影测量点云数据集中的每个点x
i
找到在数字正射影像数据的对应像素点,将对应像素点的类别标签y
i
作为x
i
的标签,最后将x
i
和y
i
合并,生成初始训练数据集;
[0052]
a4.选择多个尾矿库语义分割场景,重复步骤a1
‑
a3,获得多场景的训练数据集;
[0053]
a5.构建基于深度学习的尾矿库语义分割模型;尾矿库语义分割模型包括动态图卷积神经网络模块和通道注意力模块;其中,动态图卷积神经网络模块用于对点云中领域样本点的关系进行建模;通道注意力模块用于对若干个通道间的特征聚合关系进行建模;
[0054]
a6.在本实施例中选择pyotrch为神经网络训练平台,设置目标优化函数和优化方法;目标优化函数包括交叉熵函数;优化方法包括adam方法,设置尾矿库语义分割模型中的迭代次数、学习率、训练误差和批训练数目等训练参数,采用步骤a4中的多场景的训练数据集进行测试。
[0055]
所述的步骤s4,具体为根据尾矿库语义分割模型,输出长度为n=3的独热编码w(在本实施例中,0001表示初期坝,0010表示堆积坝,0100表示水面,1000表示干滩);语义分割模型有4个输出节点,每个节点有0和1两种状态;对于倾斜摄影测量点云数据集中的第i个采样点x
i
={x
i
,y
i
,z
i
,r
i
,g
i
,b
i
};其中,x
i
表示点的经度,y
i
表示点的纬度,z
i
表示点的高度,r
i
表示rgb红色,g
i
表示rgb绿色,b
i
表示rgb蓝色;i=1,2,
…
,n,n为采样点个数;4个输出节点中有且仅有一个输出节点的输出状态为1,剩余3个输出节点的输出状态为0。
[0056]
所述的步骤s5,尾矿库语义分割结果包括关于初期坝、堆积坝、水面和干滩的语义分割结果。
[0057]
在本实施例中,如图2为本发明实施例的基于深度学习的尾矿库语义分割模型示意图:
[0058]
输入:倾斜摄影测量生成点云第i个采样点x
i
={x
i
,y
i
,z
i
,r
i
,g
i
,b
i
};其中,x
i
表示点的经度,y
i
表示点的纬度,z
i
表示点的高度,r
i
表示rgb红色,g
i
表示rgb绿色,b
i
表示rgb蓝色;i=1,2,
…
,n,n为采样点个数。
[0059]
输出:初期坝、堆积坝、水面和干滩四个类别的one
‑
hot编码0001,0010,0100,1000。
[0060]
基于深度学习的尾矿库语义分割模型,包括1个输入层、2个边卷积层(edgeconv)、3个多层感知器和1个输出层,2个边卷积层采用相同的结构,在边卷积层和多层感知器层之间引入通道注意力模块(channel attension pooling);其中,边卷积层提取、融合每个点的独立特征和该点的局域特征;多层感知器用来对边卷积获得的特征信息进行特征融合和特征降维,最后接softmax层(本实施例中输出层采用softmax层)输出四类别的one
‑
hot编码;多层感知器网络模块mlp{a,b},表示该感知器第一隐含层有a个节点,输出层有b个节点。
[0061]
边卷积层(edgeconv)具体为网络的每一层构造具有顶点和边的局部有向图结构,形式上描述为二元组g
l
=(v
l
,e
l
);其中,v
l
为第l层点云顶点;e
l
为第l层点云边;图2的结构表述为点云中每个点及其邻域点之间的相似关系。在邻域样本的选择上,对任意中心顶点通过基于点向欧几里得距离的knn算法获取最近邻域点集{x
i1
,x
i2
,
…
,x
ik
},并建立中心顶点x
i
与领域x
j
之间边特征的联系。顶点的特征融合了上一层网络的顶点特征和当前层网络动态更新的邻域特征,并随着网络深度不断迭代更新。
[0062]
在计算领域动态特征时,边卷积层定义边缘特征为:
[0063][0064]
其中,h
θ
表示使用可学习参数θ构成的非线性函数,一般使用多层感知器网络来实现;h
θ
(x
i
,x
j
‑
x
i
)在求解边特征时考虑到了x
i
,以及x
i
与领域x
j
的差x
j
‑
x
i
,同时兼顾了全局形状信息和局部邻域信息,具有较强的点云特征提取与特征融合能力。
[0065]
如图3为本发明实施例中第一个边卷积(edgeconv mlp{64,64})模块示意图。由于在网络学习过程中,每次迭代各层网络节点的数值都在发生变化,导致每层构造的图结构也会发生变化,使得边卷积(edgeconv)模块具有动态提取特征的能力。
[0066]
边卷积模块通过通道注意力模块提取动态特征;通道注意力模块:将边卷积层提取的局部空间信息压缩成一个通道描述器,对多个通道间的特征聚合关系进行建模,计算每个通道特征聚合时的权重,最后加权聚合每个通道表示来获得局部通道结构信息。通道注意力模块主要包括全局信息嵌入和权重自适应调整两个步骤:
[0067]
b1.全局信息嵌入实现的是将每个通道的全局空间信息压缩为一个通道描述符,实际上相当于使用平均池化来对每个通道的特征图降维到一维,作为该通道重要性的一个统计量。
[0068]
对于特征矩阵其中,k为特征的维数,c为特征通道的数目,分别从第c个通道的k维空间计算各个通道的通道统计量z
c
:
[0069][0070]
其中,k为特征维度的序号;表示第c个通道第k个维度的特征;
[0071]
b2.通道特征聚合时的权重,自适应步骤主要基于全局信息嵌入得到的统计量来建立通道的依赖关系。具体而言,通过简单的门控机制、激活函数,并设计两层全连接层来计算第c个通道的依赖关系s
c
:
[0072]
s
c
=σ(w2g(w1z
c
))
[0073]
其中,c∈{1,2,...,c};g(
·
)选用relu函数作为激活函数;σ(
·
)选用sigmoid函数作为激活函数;w1为升维全连接参数;w2为降维全连接层参数。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
