本发明涉及非易失存储器
技术领域:
,特别涉及误码率平衡方法及装置。
背景技术:
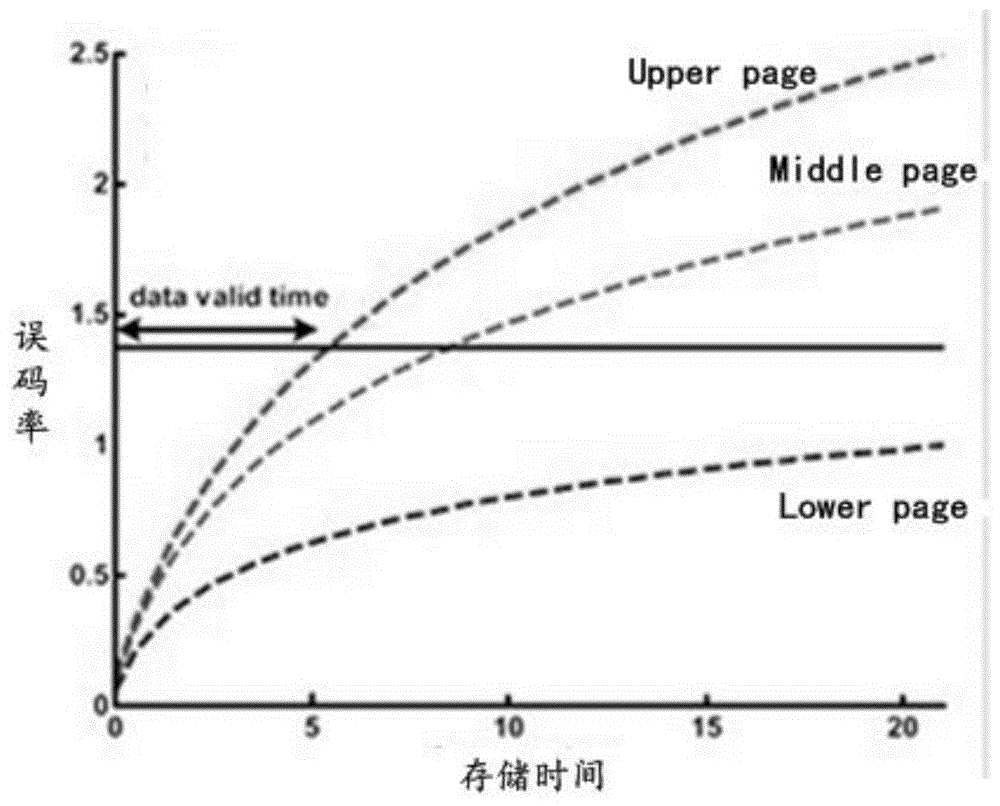
:nand闪存是用于ssd和存储卡的一种非易失性存储体系结构。典型的nand包括多个块(block),每个block又由多个物理页(page)组成,每个page对应着一个字线(wordline,wl),由多个存储单元(最小存储粒度)构成。物理页是读写的单元,也就是向nand闪存中写入或读出数据必须以页为操作单位进行。其中,tlcnand闪存是nand的一种,tlcnand的一个存储单元可存储3比特,这3比特分别属于不同的逻辑页:快页(upperpage)、中页(middlepage)、慢页(lowerpage)。也即,一物理页对应三个虚拟页。这3比特的格雷码有多个分布态(e至p7)如下表1所示。ep1p2p3p4p5p6p7lowerpage10000111middlepage11001100upperpage11100001表1在将数据写入物理页之前,会对原始数据进行编码存储。当upperpage、middlepage、lowerpage中任一页数据的误码率上升到纠错能力上限时,就需要将upperpage、middlepage、lowerpage中的数据读出进行纠错,纠错后再重新编码写入。upperpage、middlepage、lowerpage存在误码率不平衡的问题,请参见图1,在upperpage达到纠错上限时,当upperpage误码率上升到纠错能力上限时,就需要进行读出纠错再写入的操作,而此时middlepage和lowerpage的误码率还较低,纠错能力被浪费。技术实现要素:有鉴于此,本发明实施例提供误码率平衡方法及装置,以实现对不同逻辑页的误码率的平衡。为实现上述目的,本发明实施例提供如下技术方案:一种误码率平衡方法,包括:获取待存储的原始数据;采用预设编码算法对所述原始数据进行编码,得到第一码字组;其中,所述第一码字组包括:j个第一码字,所述j个第一码字与j个逻辑页一一对应;所述j个第一码字中对应同一存储单元的数据为一个比特单元;每一比特单元包括j比特的数据;j为正整数;根据比特单元的分布态,确定第一比特单元组;所述第一比特单元组包括:与同一沟道上g个连续的存储单元相对应的g个比特单元,并且,所述g个比特单元的分布态组合为第一分布态组合集中的分布态组合;g为自然数;对所述第一比特单元组执行平衡各逻辑页的误码率的修改操作,得到第二码字组;在执行所述修改操作后,所述第一比特单元组被修改为第二比特单元组;所述第二比特单元组中的g个比特单元的分布态组合为第二分布态组合集中的分布态组合;向非易失存储器写入所述第二码字组。一种误码率平衡装置,包括:获取单元,用于获取待存储的原始数据;编码单元,用于:采用预设编码算法对所述原始数据进行编码,得到第一码字组;其中,所述第一码字组包括:j个第一码字,所述j个第一码字与j个逻辑页一一对应;所述j个第一码字中对应同一存储单元的数据为一个比特单元;每一比特单元包括j比特的数据;j为正整数;根据比特单元的分布态,确定第一比特单元组;所述第一比特单元组包括:与同一沟道上g个连续的存储单元相对应的g个比特单元,并且,所述g个比特单元的分布态组合为第一分布态组合集中的分布态组合;g为自然数;对目标存储单元组在第一码字中所对应的比特单元,执行平衡各逻辑页的误码率的修改操作,得到第二码字组;在执行所述修改操作后,所述第一比特单元组被修改为第二比特单元组;所述第二比特单元组中的g个比特单元的分布态组合为第二分布态组合集中的分布态组合;向非易失存储器写入所述第二码字组。可见,在本发明实施例中,在编码得到第一码字组后,对第一码字组中的第一比特单元组执行了平衡各逻辑页的误码率的修改操作,得到第二码字组并保存。在执行修改操作后,第一比特单元组被修改为第二比特单元组,而第二比特单元组中的g个比特单元的分布态组合为第二分布态组合集中的分布态组合。第一比特单元组中g个比特单元的分布态组合则为第一分布态组合集中的分布态组合。第二分布态组合集中的分布态组合与第一分布态组合集中的分布态组合相比,可在一定程度上平衡upperpage、middlepage、lowerpage的误码率,进而推迟了读出纠错再写入的操作的发生时间。此外,需要说明的是,本发明在第一码字组的基础上引入了修改错误得到第二码字组,但引入的修改错误在纠错能力范围内是可以纠正的。在需要从非易失存储器中读取数据时,会使用与编码算法相应的译码算法对存储的码字进行解码和纠错处理,这样就能纠正本发明实施例在编码时引入的修改错误。附图说明图1为误码率不平衡示意图;图2a为本发明实施例提供的横向扩散效应示意图;图2b为本发明实施例提供的存储单元间相互影响示意图;图2c为本发明实施例提供的固态驱动器结构示意图;图3、4为本发明实施例提供的误码率平衡方法的示例性流程;图5为本发明实施例提供的修改前后逻辑页的误码率示意图;图6为本发明实施例提供的误码率平衡装置的结构示意图。具体实施方式nand闪存分为slc(单层次存储单元)nand闪存、mlc(双层存储单元)nand闪存以及tlc(triple-levelcell,三层存储单元)nand闪存等。tlcnand的一个存储单元可存储3比特,这3比特分别属于不同的逻辑页:快页(upperpage)、中页(middlepage)、慢页(lowerpage)。也即,一物理页对应三个虚拟页。tlcnand闪存通过增加存储单元在垂直方向(位线方向)上的堆叠(3d堆叠)数量(wordline的堆叠数)以实现高密度化、大容量化。请参见图2a,tlcnand闪存采用“共享电荷存储层(sharesilicon)”结构,该结构在简化了工艺制程的同时带来了横向扩散(lateralspreading)效应:若对一个块进行数据写入,那么对于同一个沟道上相邻字线(wordline)所对应的存储单元,如果存储的电荷差距大,会导致明显的横向扩散效应,进而导致对应存储单元的误码率的明显上升。以p6态为例,图2b示出了在同一沟道上相邻字线分别是e到p7态下误码率的情况。可以看到如果相邻wl存储的信息是e,则p6的误码率明显比相邻wl存储的信息是p7的情况高很多。请参见图2b,根据统计当wl(n)(字线n)存储的是p6态时,若wl(n 1)存储的信息是e态,则p6的误码率相比于相邻是p7态的误码率来说要高得多。同时,因为编程顺序(从wl(0)开始编程),wl(n 1)对wl(n)的影响比wl(n-1)要大。由于高态(例如p7态)的阈值分布在存储过程中会因横向扩散效应和纵向脱陷导致更严重的展宽和更快的漂移速度,这造成高态分布态之间的交叠更加严重。若以上表1中的格雷码编码方式进行数据写入,p7和p6态交叠产生的错误是由upperpage承担,p6和p5态交叠产生的错误是由middlepage承担。这些高态产生的错误往往较其他态交叠产生的错误要多,从而导致tlc中三个逻辑页的错误增长速度不同,进而导致逻辑页间误码率的不平衡。为解决上述问题,本发明提供误码率平衡方法及装置,以实现对不同逻辑页的误码率的平衡。请参见图2c,上述装置具体可为固态驱动器(solidstatedisk或solidstatedrive,简称ssd)中的ecc(errorcheckingandcorrecting,错误检查和纠正)模块,或为ssd中的控制器(包括ecc模块和读写控制器)。来自pc(个人电脑)的待写入nand的数据,会经ecc模块处理后,由读写控制器写入nand。而在需要读取数据时,可由读写控制器从nand中读取数据,交由ecc模块进行译码后,再提供给pc。图3示出了上述误码率平衡方法的一种示例性流程,其可包括:s0:获取待存储的原始数据。在待存储的原始数据较多时,可将其划分为固定长度的多个数据块。每一数据块包括j*k比特数据,对每一数据块中的原始数据执行下述操作。上述j为正整数。以slc为例,j=1,以mlc为例,j=2,以tlc为例,j=3。s1:采用预设编码算法对上述原始数据进行编码,得到第一码字组。在编码时,是按照逻辑页分别编码,因此得到的第一码字组包括j个第一码字。预设编码算法可为bch(bose-chaudhuri-hocquenghem)编码算法、ldpc(low-densityparity-check,ldpc)编码算法等。在一个示例中,可使用bch(9872,8192,120)编码算法进行编码。需要说明的是,bch码通常表示为bch(n,k,t),其中η为码字长度;k为码字中数据信息的长度;t为该bch码所允许的纠正错误的个数;n-k为冗余位的长度,n-k的值越大,冗余位的开销越多,则bch码的纠错能力越强。则bch(9872,8192,120)表示码字长度为9872,码字中数据信息长度为8192,所允许的纠正错误个数等于120个。前述提及的数据块的长度k,与编码算法支持的数据信息的长度相等,若采用bch(9872,8192,120),k取值为8192。j个第一码字中对应同一存储单元的数据为一个比特单元,一个比特单元包括j比特的数据,一个比特单元中的j比特分别属于j页逻辑页,这j比特数据的格雷码对应一个分布态。对于tlcnand闪存,j=3,也即,一个比特单元包括3个比特,这正好是一个tlcnand存储单元可存储的容量。与前述提及的相同,一个比特单元中的3比特分别属于不同的逻辑页:upperpage、middlepage和lowerpage。这3比特的格雷码分布态(e至p7)如下表1所示。ep1p2p3p4p5p6p7lowerpage10000111middlepage11001100upperpage11100001表1第一码字可以dp1表示。s2:根据比特单元的分布态,确定第一比特单元组。第一比特单元组包括:与同一沟道上g个连续的存储单元相对应的g个比特单元(g为自然数),并且,这g个比特单元所对应的分布态组合为第一分布态组合集中的分布态组合。本文后续将以g=3为例进行介绍。同一沟通上的g个连续的存储单元可视为一个存储单元组,则第一比特单元组对应一个目标存储单元组。以图2a为例,在同一沟道上字线wl(n 3)、wl(n 2)、wl(n 1)所对应的存储单元可构成一个存储单元组,该存储单元组对应的比特单元组可称为单元组n 2;在同一沟道上字线wl(n 2)、wl(n 1)、wl(n)所对应的存储单元可构成一个存储单元组,该存储单元组对应的比特单元组可称为单元组n 1;同理,在同一沟道上字线wl(n 1)、wl(n)、wl(n-1)所对应的存储单元亦可构成一个存储单元组,该存储单元组对应的比特单元组可称为单元组n。假定,单元组n所对应的分布态组合与第一类分布态组合相匹配,那么,单元组n即为第一比特单元组。本文后续会详细介绍第一分布态组合集。s3:对第一比特单元组执行平衡各逻辑页的误码率的修改操作,得到第二码字组。在执行上述修改操作后,第一比特单元组被修改为第二比特单元组。第二比特单元组中的g个比特单元的分布态组合为第二分布态组合集中的分布态组合。这样,第一码字组被修改为第二码字组。第二码字组与第一码字组相类似,包括j个第二码字,第二码字可用dalgpalg表示。上述平衡各逻辑页的误码率的修改操作,具体用于降低横向扩散效应和纵向脱陷效应。具体的,平衡各逻辑页的误码率的修改操作可包括:对第一比特单元中与目标逻辑页对应的数据进行修改,得到第二目标比特单元。其中,第一目标比特单元为对应第一预设分布态的比特单元,第二目标比特单元对应的分布态为第二预设分布态。也即,本实施例中,通过对数据进行修改,改变了目标存储单元组所对应的分布态组合。本文后续会详细介绍第二分布态组合集。s4:向非易失存储器写入第二码字组。可按照现有的写入方式写入第二码字组。步骤s4可由前述的读写控制器执行。在编码得到第一码字组后,对第一码字组中的第一比特单元组执行了平衡各逻辑页的误码率的修改操作,得到第二码字组并保存。在执行修改操作后,第一比特单元组被修改为第二比特单元组,而第二比特单元组中的g个比特单元的分布态组合为第二分布态组合集中的分布态组合。第一比特单元组中g个比特单元的分布态组合则为第一分布态组合集中的分布态组合。第二分布态组合集中的分布态组合与第一分布态组合集中的分布态组合相比,可在一定程度上平衡upperpage、middlepage、lowerpage的误码率,进而推迟了读出纠错再写入的操作的发生时间。此外,需要说明的是,本实施例是在第一码字组的基础上引入了修改错误得到第二码字组,但引入的修改错误在译码算法的纠错能力内是可以纠正的。实际上,现有技术在需要从nand中读取数据时,会使用与编码算法相应的译码算法对存储的码字进行译码,在译码过程中,会使用与编码算法相应的译码算法对存储的码字进行解码和纠错处理,这样就能纠正本发明实施例在编码时引入的修改错误。下面以g=3为例,重点介绍如何确定第一分布态组合集和第二分布态组合集。本申请是基于数据修改评估模型来确定第一分布态组合集和第二分布态组合集的,其建立步骤如下:步骤1:定义某沟道上三个相邻的wl所对应的三个存储单元为一个存储单元组。步骤2:计算第一码字组中各分布态组合所对应的存储单元组的误码率:以某一分布态组合abd为例,其对应的各存储单元组中的三个存储单元均分别以wl(n 1)、wl(n)、wl(n-1)表示,wl(n)分别与wl(n 1)和wl(n-1)相邻。abd也可分别称为第一至第三分布态。在一个示例中,可采用如下计算公式计算abd在预定时刻t的误码率errorrate(abd,t):errorrate(abd,t)=errornum(abd,t)/totalnum(abd)。预定时刻t为预估的数据保持时间,本领域技术人员可根据实际情况灵活设计时刻t,在此不作赘述。errornum(abd,t)表示t时刻分布态组合为abd但发生错误的存储单元组的数量,totalnum(abd)表示分布态组合为abd的存储单元组的总数量。假定要将abd修改为acd。其中,abd可视为初始分布态组合,acd可视为目标分布态组合,以tlc为例,a、c、d中的每一个分布态为e至p7态中的任一个,但abd与acd是不同的,也即b与c是不同的。c也可称为第四分布态。同理,acd在预定时刻t的误码率errorrate(acd,t)=errornum(acd,t)/totalnum(acd)。其他分布态在预定时刻的误码率计算方式与之相类似,在此不作赘述。步骤3:计算修改前后wl(n)的误码率变化:wl(n)的误码率变化=errorrate(abd,t)-errorrate(acd,t)也即,wl(n)的误码率变化为初始分布态组合和目标分布态组合间的差值(可称为第一误码率差值)。步骤4:计算修改前后wl(n-1)的误码率变化:计算修改前后wl(n-1)的误码率变化时,是将wl(n-1)作为中间存储单元的。在修改前,以wl(n-1)作为中间存储单元的存储单元组的分布态可表示为:xab,分布态x表示任一分布态。xab可视为一个分布态组合集(可称为第三分布态组合集),以tlc模式为例,以0对应e态,1对应p1态,以此类推,则xab可包括:0ab、1ab、2ab、3ab、4ab、5ab、6ab、7ab。在修改后,以wl(n-1)作为中间存储单元的存储单元组的分布态可表示为:xac。同理,xac可视为一个分布态组合集(可称为第四分布态组合集),以tlc模式为例,则xac可包括:0ac、1ac、2ac、3ac、4ac、5ac、6ac、7ac。设修改前wl(n-1)的误码率表示为errorrateaver(ab,t)或eraver1,则errorrateaver(ab,t)=average(∑x∈[0,7]errorrate(xab,t));也即,将0ab、1ab、2ab、3ab、4ab、5ab、6ab、7ab在预定时刻t的误码率相加再取平均值作为errorrateaver(ab,t)。设修改后wl(n-1)的误码率表示为errorrateaver(ac,t)或eraver2,则errorrateaver(ac,t)=average(∑x∈[0,7]errorrate(xac,t))。也即,将0ac、1ac、2ac、3ac、4ac、5ac、6ac、7ac在预定时刻t的误码率相加再取平均值作为errorrateaver(ac,t)。wl(n-1)的误码率变化=errorrateaver(xab)-errorrateaver(xac)。wl(n-1)的误码率变化可称为第二误码率差值。步骤5:计算修改前后wl(n 1)的误码率变化:计算修改前后wl(n 1)的误码率变化时,也是将wl(n 1)作为中间存储单元的。在修改前,以wl(n 1)作为中间存储单元的存储单元组的分布态可表示为bdy,分布态y表示e至p7分布态。bdy可视为一个分布态组合集(可称为第五分布态组合集),以tlc模式为例,以0对应e态,1对应p1态,以此类推,则bdy可包括:bd0、bd1、……bd7。在修改后,以wl(n-1)作为中间存储单元的存储单元组的分布态可表示为:bcy。同理,bcy可视为一个分布态组合集(可称为第六分布态组合集),以tlc模式为例,则cdy可包括:cd0、cd1、……cd7。以errorrateaver(bdy)或eraver3表示修改前在时刻twl(n 1)的误码率,以errorrateaver(cdy)或eraver4表示修改后在时刻twl(n 1)的误码率,则:wl(n 1)的误码率变化=errorrateaver(bdy)-errorrateaver(cdy)wl(n 1)的误码率变化可称为第三误码率差值。步骤6:计算更改增益(将abd改成acd):更改增益=wl(n)的误码率变化 wl(n-1)的误码率变化 wl(n 1)的误码率变化。某第一码字组计算出的数据修改评估模型如下表2所示,表2中的每一行为一个数据修改评估结果,包括初始分布态组合、目标分布态组合、误码率增益等:表2以表2中第一行为例,初始分布态组合为:070(也即,e态、p7态、e态),误码率为0.45,目标分布态组合为000(也即,e态、e态、e态),也即,将wl(k)的分布态由p7态修改为e态,通过表1可知,是将middlepage上的数据由“0”修改为“1”。表2中第一行中,目标分布态组合的误码率等于0;wl(n)的误码率增益为正0.447,表示wl(n)的误码率降低了0.447;wl(n-1)的误码率增益为负0.002,表示wl(n-1)的误码率增大了0.002;wl(n 1)的误码率增益为负0.001,表示wl(n 1)的误码率增大了0.001;总增益为0.444。基于上述表2,可将满足预设条件的数据修改评估结果作为目标数据修改评估结果,将目标数据修改评估结果中的初始分布态组合放入所述第一分布态组合集,将目标数据修改评估结果中的目标分布态组合放入所述第二分布态组合集中。在一个示例中,预设条件可包括:增益高,并且,修改的逻辑页为lowerpage。例如,第一分布态组合集可包括如下任意一种或多种:第一组合:e态、p7态、e态,对应表2中的070;第二组合:e态、p7态、p1态,对应表2中的071;第三组合:p1态、p7态、e态,对应表2中的170;第四组合:p2态、p7态、e态,对应表2中的270。第二分布态组合集可包括如下组合中的至少一种:第五组合:e态、p2态、e态,对应表2中的020;第六组合:e态、p2态、p1态,对应表2中的021;第七组合:p1态、p2态、e态,对应表2中的120;第八组合:p2态、e态、e态,对应表2中的200。基于上述分析,请参见图4,误码率平衡方法的示例性得可包括如下步骤:s40:获取待存储的原始数据;s40与前述的步骤s0相同,在此不作赘述。s41:采用bch(9872,8192,120)编码算法对上述原始数据进行编码,得到第一码字组。bch(9872,8192,120)编码算法请参见前述记载,在此不作赘述。s42:将分布态组合为第一组合至第四组合的比特单元组确定为第一比特单元组。具体的,可将与同一沟道上3个连续的存储单元相对应,且分布态组合为070、071、170、270的比特单元组确定为第一比特单元组。s43:对第一比特单元组执行平衡各逻辑页的误码率的修改操作,得到第二码字组。其中,s43可进一步包括如下步骤:s4301:将第一组合(070)中p7态所对应的lowerpage页的数据由1修改为0,以将p7态修改为p2态,从而将第一组合修改为第五组合(020);s4302:将第二组合(071)中p7态所对应的lowerpage页的数据由1修改为0,以将p7态修改为p2态,从而将第二组合修改为第六组合(021);s4303:将第三组合(170)中p7态所对应的lowerpage页的数据由1修改为0,以将p7态修改为p2态,从而将第三组合修改为第七组合(120);s4304:将第四组合(270)中p7态所对应的middlepage页的数据由0修改为1,以将p7态修改为e态,从而将第四组合修改为第八组合(200)。s4301至s4304的操作可总结如下:070--->020[1;1;1;1;0;1;1;1;1]--->[1;1;1;0;0;1;1;1;1]071--->021[1;1;1;1;0;1;0;1;1]--->[1;1;1;0;0;1;0;1;1170--->120[0;1;1;1;0;1;1;1;1]--->[0;1;1;0;0;1;1;1;1]270--->200[0;0;1;1;0;1;1;1;1]--->[0;0;1;1;1;1;1;1;1]可见,在本实施例中,目标逻辑页为:middlepage或lowerpage,第一预设分布态为p7态,第二预设分布态为p2态或e态。s44:向非易失存储器写入第二码字组。步骤s44与前述步骤的s4相同,在此不赘述。下面简单介绍如何进行译码。由于随着时间的推移第二码字会出现其他错误,因此,可将译码时获取的各第二码字以d′algpa′lg表示。使用bch(9872,8192,120)对d′algpa′lg进行解码处理和纠错处理,可得到原始数据。在本实施例中,通过修改单元组,在lowerpage或middlepage上引入修改以降低middlepage和upperpage的误码率。图5示出了使用本实施例的技术方案修改数据后,修改前后逻辑页的误码率示意图,图5中的‘ini’表示“修改前”,‘alg’表示“修改后”。可见,与修改前相比,lowerpage的误码率增大了,同时,lowerpage和middlepage的误码率减小了,三个逻辑页的误码率得到平衡,三个逻辑页的误码率几乎在同时超过纠错能力。datavalidtime表示数据保持(有效)时间,与修改前相比,datavalidtime推迟了。修改前后的实验数据对比还可参见下表3:表3bch(9872,8192,120)允许的纠正错误的个数是120个。那么,采用传统的ecc方案,以125摄氏度下为例,在写入5.5小时后,upperpage的错误达到120个时,middlepage和lowerpage的错误分别为100个和56个。而采用本实施例所提供的方案后,同样在125摄氏度下,在写入5.5小时后,upperpage的错误达到106个,middlepage和lowerpage的错误分别为108个和113个。在6.8小时后,upperpage的错误才达到120个,middlepage和lowerpage的错误分别为118个。这表明,本实施例所提供的技术方案,在tlc模式下三个逻辑页的误码率几乎在同时超过纠错能力,使纠错能力被完全使用,有效时间得到了延长,在减少横向电荷扩散效应对nandflash数据保持能力的影响的同时调整了tlc误码率不平衡现象,大大提高nandflash的数据保持能力。上述介绍了g=3时技术方案,实际上g可取1、2、4、5等。对于g=1的情况,则未考虑横向电荷扩散效应,只是减少了纵向脱陷效应。对于g=1的情况,将不再考虑分布态组合,只考虑将高态修改为低态。以tlc模式为例,示例性的可将p7态修改为p2态。下面介绍误码率平衡装置(ecc模块或ssd中的控制器),请参见图6,其示例性的包括:获取单元1,用于获取待存储的原始数据;编码单元2,用于:采用预设编码算法对原始数据进行编码,得到第一码字组;其中,所述第一码字组包括:j个第一码字,所述j个第一码字与j个逻辑页一一对应;所述j个第一码字中对应同一存储单元的数据为一个比特单元;每一比特单元包括j比特的数据;j为正整数;根据比特单元的分布态,确定第一比特单元组;所述第一比特单元组包括:与同一沟道上g个连续的存储单元相对应的g个比特单元,并且,所述g个比特单元的分布态组合为第一分布态组合集中的分布态组合;g为自然数;对目标存储单元组在第一码字中所对应的比特单元,执行平衡各逻辑页的误码率的修改操作,得到第二码字组;在执行所述修改操作后,所述第一比特单元组被修改为第二比特单元组;所述第二比特单元组中的g个比特单元的分布态组合为第二分布态组合集中的分布态组合;向非易失存储器写入所述第二码字组。具体细节请参见本文前述记载,在此不作赘述。在本发明其他实施例中,还包括:评估单元3,用于在执行平衡各逻辑页的误码率的修改操作之前,建立数据修改评估模型;所述第一分布态组合集和第二分布态组合集是根据数据修改评估模型确定的。如何建立模型,以及如何确定第一分布态组合集和第二分布态组合集的具体细节请参见本文前述记载,在此不作赘述。在本发明其他实施例中,执行平衡各逻辑页的误码率的修改操作的方面,上述所有实施例中的编码模块2可具体用于:对第一目标比特单元中与目标逻辑页对应的数据进行修改,得到第二目标比特单元;其中,第二目标比特单元对应的分布态为第二预设分布态。分布态为第一预设分布态的比特单元为第一目标比特单元。修改后目标存储单元组所对应的g个比特单元的分布态组合与第二分布态组合集相匹配。具体细节请参见本文前述记载,在此不作赘述。本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,之处参见方法部分说明即可。专业人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及模型步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。结合本文中所公开的实施例描述的方法或模型的步骤可以直接用硬件、处理器执行的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、wd-rom、或
技术领域:
内所公知的任意其它形式的存储介质中。对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。