优先权声明本申请要求于2018年10月16日提交的标题为“precisiontuningfortheprogrammingofanalogneuralmemoryinadeeplearningartificialneuralnetwork”的美国临时专利申请号62/746,470和于2018年12月21日提交的标题为“precisiontuningfortheprogrammingofanalogneuralmemoryinadeeplearningartificialneuralnetwork”的美国专利申请号16/231,231的优先权。本发明公开了用于将正确的电荷量精确快速地沉积在人工神经网络中的矢量-矩阵乘法(vmm)阵列内非易失性存储器单元的浮栅上的精度调谐算法和装置的多个实施方案。
背景技术:
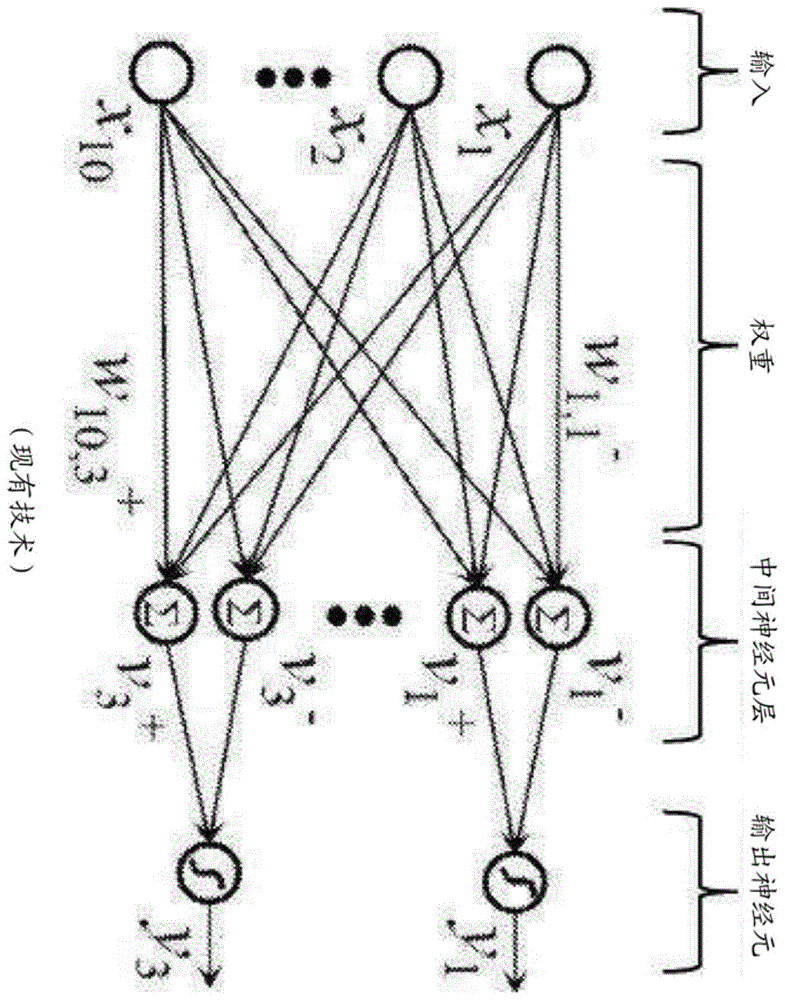
:人工神经网络模拟生物神经网络(动物的中枢神经系统,特别是大脑),并且用于估计或近似可取决于大量输入并且通常未知的函数。人工神经网络通常包括互相交换消息的互连“神经元”层。图1示出了人工神经网络,其中圆圈表示神经元的输入或层。连接部(称为突触)用箭头表示,并且具有可以根据经验进行调整的数值权重。这使得神经网络适应于输入并且能够学习。通常,神经网络包括多个输入的层。通常存在神经元的一个或多个中间层,以及提供神经网络的输出的神经元的输出层。处于每一级别的神经元分别地或共同地根据从突触所接收的数据作出决定。在开发用于高性能信息处理的人工神经网络方面的主要挑战中的一个挑战是缺乏足够的硬件技术。实际上,实际神经网络依赖于大量的突触,从而实现神经元之间的高连通性,即非常高的计算并行性。原则上,此类复杂性可通过数字超级计算机或专用图形处理单元集群来实现。然而,相比于生物网络,这些方法除了高成本之外,能量效率也很普通,生物网络主要由于其执行低精度的模拟计算而消耗更少的能量。cmos模拟电路已被用于人工神经网络,但由于给定大量的神经元和突触,大多数cmos实现的突触都过于庞大。申请人先前在美国专利申请第15/594,439号中公开了一种利用一个或多个非易失性存储器阵列作为突触的人工(模拟)神经网络,该专利申请以引用方式并入本文。非易失性存储器阵列作为模拟神经形态存储器操作。神经网络设备包括被配置成接收第一多个输入并从其生成第一多个输出的第一多个突触,以及被配置成接收第一多个输出的第一多个神经元。第一多个突触包括多个存储器单元,其中存储器单元中的每个存储器单元包括:形成于半导体衬底中的间隔开的源极区和漏极区,其中沟道区在源极区和漏极区之间延伸;设置在沟道区的第一部分上方并且与第一部分绝缘的浮栅;以及设置在沟道区的第二部分上方并且与第二部分绝缘的非浮栅。多个存储器单元中的每个存储器单元被配置成存储与浮栅上的多个电子相对应的权重值。多个存储器单元被配置成将第一多个输入乘以所存储的权重值以生成第一多个输出。必须擦除和编程在模拟神经形态存储器系统中使用的每个非易失性存储器单元,以在浮栅中保持非常特定且精确的电荷量(即电子数量)。例如,每个浮栅必须保持n个不同值中的一个,其中n是可由每个单元指示的不同权重的数量。n的示例包括16、32、64、128和256。vmm系统中的一个挑战是能够以不同n值所需的精度和粒度对所选单元进行编程。例如,如果所选单元可包括64个不同值中的一个值,则在编程操作中需要极端精度。所需要的是适于与模拟神经形态存储器系统中的vmm一起使用的改进的编程系统和方法。技术实现要素:本发明公开了用于将正确的电荷量精确快速地沉积在人工神经网络中的矢量-矩阵乘法(vmm)阵列内非易失性存储器单元的浮栅上的精确调谐算法和装置的多个实施方案。因此,可极精确地对所选单元进行编程,以保持n个不同值中的一个值。附图说明图1为示出人工神经网络的示意图。图2示出现有技术分裂栅闪存存储器单元。图3示出另一现有技术分裂栅闪存存储器单元。图4示出另一现有技术分裂栅闪存存储器单元。图5示出另一现有技术分裂栅闪存存储器单元。图6为示出利用一个或多个非易失性存储器阵列的示例性人工神经网络的不同级的示意图。图7为示出矢量-矩阵乘法系统的框图。图8为示出利用一个或多个矢量-矩阵乘法系统的示例性人工神经网络的框图。图9示出矢量-矩阵乘法系统的另一实施方案。图10示出矢量-矩阵乘法系统的另一实施方案。图11示出矢量-矩阵乘法系统的另一实施方案。图12示出矢量-矩阵乘法系统的另一实施方案。图13示出矢量-矩阵乘法系统的另一实施方案。图14示出了现有技术的长短期存储器系统。图15示出了在长短期存储器系统中使用的示例性单元。图16示出了图15的示例性单元的一个实施方案。图17示出了图15的示例性单元的另一个实施方案。图18示出了现有技术的栅控递归单元系统。图19示出了在栅控递归单元系统中使用的示例性单元。图20示出了图19的示例性单元的一个实施方案。图21示出了图19的示例性单元的另一个实施方案。图22a示出了对非易失性存储器单元进行编程的方法的实施方案。图22b示出了对非易失性存储器单元进行编程的方法的另一实施方案。图23示出了粗略编程方法的一个实施方案。图24示出了在非易失性存储器单元的编程中使用的示例性脉冲。图25示出了在非易失性存储器单元的编程中使用的示例性脉冲。图26示出了用于编程非易失性存储器单元的校准算法,该校准算法基于该单元的斜率特征来调整编程参数。图27示出了在图26的校准算法中使用的电路。图28示出了用于编程非易失性存储器单元的校准算法。图29示出了在图28的校准算法中使用的电路。图30示出了在编程操作期间施加到非易失性存储器单元的控制栅的电压的示例性累进。图31示出了在编程操作期间施加到非易失性存储器单元的控制栅的电压的示例性累进。图32示出了用于在矢量-乘法矩阵系统内的非易失性存储器单元的编程期间施加编程电压的系统。图33示出了电荷求和器电路。图34示出了电流求和器电路。图35示出了数字求和器电路。图36a示出了用于神经元输出的积分型模数转换器的一个实施方案。图36b示出了示出图36a的积分型模数转换器的电压输出随时间变化的曲线图。图36c示出了用于神经元输出的积分型模数转换器的另一实施方案。图36d示出了示出图36c的积分型模数转换器的电压输出随时间变化的曲线图。图36e示出了用于神经元输出的积分型模数转换器的另一实施方案。图36f示出了用于神经元输出的积分型模数转换器的另一实施方案。图37a和37b示出了神经元输出的逐次逼近型模数转换器。图38示出了σ-δ型模数转换器的一个实施方案。具体实施方式本发明的人工神经网络利用cmos技术和非易失性存储器阵列的组合。非易失性存储器单元数字非易失性存储器是众所周知的。例如,美国专利5,029,130(“’130专利”),其以引用方式并入本文,公开了分裂栅非易失性存储器单元的阵列,它是一种闪存存储器单元。此类存储器单元210在图2中示出。每个存储器单元210包括形成于半导体衬底12中的源极区14和漏极区16,其间具有沟道区18。浮栅20形成在沟道区18的第一部分上方并且与其绝缘(并控制其电导率),并且形成在源极区14的一部分上方。字线端子22(其通常被耦接到字线)具有设置在沟道区18的第二部分上方并且与该沟道区的第二部分绝缘(并且控制其电导率)的第一部分,以及向上延伸并且位于浮栅20上方的第二部分。浮栅20和字线端子22通过栅极氧化物与衬底12绝缘。位线24联接到漏极区16。通过将高的正电压置于字线端子22上来对存储器单元210进行擦除(其中电子从浮栅去除),这导致浮栅20上的电子经由fowler-nordheim隧穿从浮栅20到字线端子22隧穿通过中间绝缘体。通过将正的电压置于字线端子22上以及将正的电压置于源极区14上来编程存储器单元210(其中电子被置于浮栅上)。电子电流将从源极区14流向漏极区16。当电子到达字线端子22和浮栅20之间的间隙时,电子将加速并且变热。由于来自浮栅20的静电引力,一些加热的电子将通过栅极氧化物被注入到浮栅20上。通过将正的读取电压置于漏极区16和字线端子22(其接通沟道区18的在字线端子下方的部分)上来读取存储器单元210。如果浮栅20带正电(即,电子被擦除),则沟道区18的在浮栅20下方的部分也被接通,并且电流将流过沟道区18,该沟道区被感测为擦除状态或“1”状态。如果浮栅20带负电(即,通过电子进行了编程),则沟道区的在浮栅20下方的部分被大部分或完全关断,并且电流将不会(或者有很少的电流)流过沟道区18,该沟道区被感测为编程状态或“0”状态。表1示出了可以施加到存储器单元110的端子用于执行读取、擦除和编程操作的典型电压范围:表1:图3的闪存存储器单元210的操作作为其他类型的闪存存储器单元的其他分裂栅存储器单元配置是已知的。例如,图3示出了四栅极存储器单元310,其包括源极区14、漏极区16、在沟道区18的第一部分上方的浮栅20、在沟道区18的第二部分上方的选择栅22(通常联接到字线wl)、在浮栅20上方的控制栅28、以及在源极区14上方的擦除栅30。这种配置在美国专利6,747,310中有所描述,该专利以引用方式并入本文以用于所有目的。这里,除了浮栅20之外,所有的栅极均为非浮栅,这意味着它们电连接到或能够电连接到电压源。编程由来自沟道区18的将自身注入到浮栅20的加热的电子执行。擦除通过从浮栅20隧穿到擦除栅30的电子来执行。表2示出了可以施加到存储器单元310的端子用于执行读取、擦除和编程操作的典型电压范围:表2:图3的闪存存储器单元310的操作wl/sgblcgegsl读取1.0-2v0.6-2v0-2.6v0-2.6v0v擦除-0.5v/0v0v0v/-8v8-12v0v编程1v1μa8-11v4.5-9v4.5-5v图4示出了三栅极存储器单元410,其为另一种类型的闪存存储器单元。存储器单元410与图3的存储器单元310相同,除了存储器单元410没有单独的控制栅。除了没有施加控制栅偏置,擦除操作(由此通过使用擦除栅进行擦除)和读取操作类似于图3的操作。在没有控制栅偏置的情况下,编程操作也被完成,并且结果,在编程操作期间必须在源极线上施加更高的电压,以补偿控制栅偏置的缺乏。表3示出了可以施加到存储器单元410的端子用于执行读取、擦除和编程操作的典型电压范围:表3:图4的闪存存储器单元410的操作wl/sgblegsl读取0.7-2.2v0.6-2v0-2.6v0v擦除-0.5v/0v0v11.5v0v编程1v2-3μa4.5v7-9v图5示出了堆叠栅极存储器单元510,其为另一种类型的闪存存储器单元。存储器单元510类似于图2的存储器单元210,不同的是浮栅20在整个沟道区18上方延伸,并且控制栅22(其在这里将联接到字线)在浮栅20上方延伸,由绝缘层(未示出)分开。擦除、编程和读取操作以与先前针对存储器单元210所述类似的方式操作。表4示出了可以施加到存储器单元510和衬底12的端子用于执行读取、擦除和编程操作的典型电压范围:表4:图5的闪存存储器单元510的操作cgblsl衬底读取2-5v0.6–2v0v0v擦除-8至-10v/0vfltflt8-10v/15-20v编程8-12v3-5v0v0v为了在人工神经网络中利用包括上述类型的非易失性存储器单元之一的存储器阵列,进行了两个修改。第一,对线路进行配置,使得每个存储器单元可被单独编程、擦除和读取,而不会不利地影响阵列中的其他存储器单元的存储器状态,如下文进一步解释。第二,提供存储器单元的连续(模拟)编程。具体地,阵列中的每个存储器单元的存储器状态(即,浮栅上的电荷)可在独立地并且对其他存储器单元的干扰最小的情况下连续地从完全擦除状态变为完全编程状态。在另一个实施方案,阵列中的每个存储器单元的存储器状态(即,浮栅上的电荷)可在独立地并且对其他存储器单元的干扰最小的情况下连续地从完全编程状态变为完全擦除状态,反之亦然。这意味着单元存储装置是模拟的,或者至少可存储许多离散值(诸如16或64个不同的值)中的一个离散值,这允许对存储器阵列中的所有单元进行非常精确且单独的调谐,并且这使得存储器阵列对于存储和对神经网络的突触权重进行微调调整是理想的。采用非易失性存储器单元阵列的神经网络图6概念性地示出了本实施方案的利用非易失性存储器阵列的神经网络的非限制性示例。该示例将非易失性存储器阵列神经网络用于面部识别应用,但任何其他适当的应用也可使用基于非易失性存储器阵列的神经网络来实现。对于该示例,s0为输入层,其为具有5位精度的32×32像素rgb图像(即,三个32×32像素阵列,分别用于每个颜色r、g和b,每个像素为5位精度)。从输入层s0到层c1的突触cb1在一些情况下应用不同的权重集,在其他情况下应用共享权重,并且用3×3像素重叠滤波器(内核)扫描输入图像,将滤波器移位1个像素(或根据模型所指示的多于1个像素)。具体地,将图像的3×3部分中的9个像素的值(即,称为滤波器或内核)提供给突触cb1,其中将这9个输入值乘以适当的权重,并且在对该乘法的输出求和之后,由cb1的第一突触确定并提供单个输出值以用于生成特征映射的其中一层c1的像素。然后将3×3滤波器在输入层s0内向右移位一个像素(即,添加右侧的三个像素的列,并释放左侧的三个像素的列),由此将该新定位的滤波器中的9个像素值提供给突触cb1,其中将它们乘以相同的权重并且由相关联的突触确定第二单个输出值。继续该过程,直到3×3滤波器在输入层s0的整个32×32像素图像上扫描所有三种颜色和所有位(精度值)。然后使用不同组的权重重复该过程以生成c1的不同特征映射,直到计算出层c1的所有特征映射。在层c1处,在本示例中,存在16个特征映射,每个特征映射具有30×30像素。每个像素是从输入和内核的乘积中提取的新特征像素,因此每个特征映射是二维阵列,因此在该示例中,层c1由16层的二维阵列构成(记住本文所引用的层和阵列是逻辑关系,而不必是物理关系,即阵列不必定向于物理二维阵列)。在层c1中的16个特征映射中的每个特征映射均由应用于滤波器扫描的十六个不同组的突触权重中的一组生成。c1特征映射可全部涉及相同图像特征的不同方面,诸如边界识别。例如,第一映射(使用第一权重组生成,针对用于生成该第一映射的所有扫描而共享)可识别圆形边缘,第二映射(使用与第一权重组不同的第二权重组生成)可识别矩形边缘,或某些特征的纵横比,以此类推。在从层c1转到层s1之前,应用激活函数p1(池化),该激活函数将来自每个特征映射中连续的非重叠2×2区域的值进行池化。池化函数的目的是对邻近位置求均值(或者也可使用max函数),以例如减少边缘位置的依赖性,并在进入下一阶段之前减小数据大小。在层s1处,存在16个15×15特征映射(即,十六个每个特征映射15×15像素的不同阵列)。从层s1到层c2的突触cb2利用4×4滤波器扫描s1中的映射,其中滤波器移位1个像素。在层c2处,存在22个12×12特征映射。在从层c2转到层s2之前,应用激活函数p2(池化),该激活函数将来自每个特征映射中连续的非重叠2×2区域的值进行池化。在层s2处,存在22个6×6特征映射。将激活函数(池化)应用于从层s2到层c3的突触cb3,其中层c3中的每个神经元经由cb3的相应突触连接至层s2中的每个映射。在层c3处,存在64个神经元。从层c3到输出层s3的突触cb4完全将c3连接至s3,即层c3中的每个神经元都连接到层s3中的每个神经元。s3处的输出包括10个神经元,其中最高输出神经元确定类。例如,该输出可指示对原始图像的内容的识别或分类。使用非易失性存储器单元的阵列或阵列的一部分来实现每层的突触。图7为可用于该目的的阵列的框图。矢量-矩阵乘法(vmm)阵列32包括非易失性存储器单元,并且用作一层与下一层之间的突触(诸如图6中的cb1、cb2、cb3和cb4)。具体地,vmm阵列32包括非易失性存储器单元阵列33、擦除栅和字线栅解码器34、控制栅解码器35、位线解码器36和源极线解码器37,这些解码器对非易失性存储器单元阵列33的相应输入进行解码。对vmm阵列32的输入可来自擦除栅和字线栅解码器34或来自控制栅解码器35。在该示例中,源极线解码器37还对非易失性存储器单元阵列33的输出进行解码。另选地,位线解码器36可以解码非易失性存储器单元阵列33的输出。非易失性存储器单元阵列33用于两个目的。首先,它存储将由vmm阵列32使用的权重。其次,非易失性存储器单元阵列33有效地将输入与存储在非易失性存储器单元阵列33中的权重相乘并且每个输出线(源极线或位线)将它们相加以产生输出,该输出将作为下一层的输入或最终层的输入。通过执行乘法和加法函数,非易失性存储器单元阵列33消除了对单独的乘法和加法逻辑电路的需要,并且由于其原位存储器计算其也是高功效的。将非易失性存储器单元阵列33的输出提供至差分求和器(诸如求和运算放大器或求和电流镜)38,该差分求和器对非易失性存储器单元阵列33的输出进行求和,以为该卷积创建单个值。差分求和器38被布置用于执行正权重和负权重的求和。然后将差分求和器38的输出值求和后提供至激活函数电路39,该激活函数电路对输出进行修正。激活函数电路39可提供sigmoid、tanh或relu函数。激活函数电路39的经修正的输出值成为作为下一层(例如,图6中的层c1)的特征映射的元素,然后被应用于下一个突触以产生下一个特征映射层或最终层。因此,在该示例中,非易失性存储器单元阵列33构成多个突触(其从现有神经元层或从输入层诸如图像数据库接收它们的输入),并且求和运算放大器38和激活函数电路39构成多个神经元。图7中对vmm阵列32的输入(wlx、egx、cgx以及任选的blx和slx)可为模拟电平、二进制电平或数字位(在这种情况下,提供dac以将数字位转换成适当的输入模拟电平),并且输出可为模拟电平、二进制电平或数字位(在这种情况下,提供输出adc以将输出模拟电平转换成数字位)。图8为示出多层vmm阵列32(此处标记为vmm阵列32a、32b、32c、32d和32e)的使用的框图。如图8所示,通过数模转换器31将输入(表示为inputx)从数字转换为模拟,并将其提供至输入vmm阵列32a。转换的模拟输入可以是电压或电流。第一层的输入d/a转换可通过使用将输入inputx映射到输入vmm阵列32a的矩阵乘法器的适当模拟电平的函数或lut(查找表)来完成。输入转换也可以由模拟至模拟(a/a)转换器完成,以将外部模拟输入转换成到输入vmm阵列32a的映射模拟输入。由输入vmm阵列32a产生的输出被作为到下一个vmm阵列(隐藏级别1)32b的输入提供,该输入继而生成作为下一vmm阵列(隐藏级别2)32c的输入而提供的输出,以此类推。vmm阵列32的各层用作卷积神经网络(cnn)的突触和神经元的不同层。每个vmm阵列32a、32b、32c、32d和32e可以是独立的物理非易失性存储器阵列、或者多个vmm阵列可以利用相同非易失性存储器阵列的不同部分、或者多个vmm阵列可以利用相同物理非易失性存储器阵列的重叠部分。图8所示的示例包含五个层(32a、32b、32c、32d、32e):一个输入层(32a)、两个隐藏层(32b、32c)和两个完全连接的层(32d、32e)。本领域的普通技术人员将会知道,这仅仅是示例性的,并且相反,系统可包括两个以上的隐藏层和两个以上的完全连接的层。矢量-矩阵乘法(vmm)阵列图9示出了神经元vmm阵列900,其特别适用于图3所示的存储器单元310,并且用作输入层与下一层之间的神经元的突触和部件。vmm阵列900包括非易失性存储器单元的存储器阵列901和非易失性参考存储器单元的参考阵列902(在阵列的顶部)。另选地,可将另一个参考阵列置于底部。在vmm阵列900中,控制栅线(诸如控制栅线903)在竖直方向上延伸(因此参考阵列902在行方向上与控制栅线903正交),并且擦除栅线(诸如擦除栅线904)在水平方向上延伸。此处,vmm阵列900的输入设置在控制栅线(cg0、cg1、cg2、cg3)上,并且vmm阵列900的输出出现在源极线(sl0、sl1)上。在一个实施方案中,仅使用偶数行,并且在另一个实施方案中,仅使用奇数行。置于各源极线(分别为sl0、sl1)上的电流执行来自连接到该特定源极线的存储器单元的所有电流的求和函数。如本文针对神经网络所述,vmm阵列900的非易失性存储器单元(即vmm阵列900的闪存存储器)优选地被配置成在亚阈值区域中操作。在弱反转中偏置本文所述的非易失性参考存储器单元和非易失性存储器单元:ids=io*e(vg-vth)/kvt=w*io*e(vg)/kvt,其中w=e(-vth)/kvt对于使用存储器单元(诸如参考存储器单元或外围存储器单元)或晶体管将输入电流转换为输入电压的i到v对数转换器:vg=k*vt*log[ids/wp*io]此处,wp为参考存储器单元或外围存储器单元的w。对于用作矢量矩阵乘法器vmm阵列的存储器阵列,输出电流为:iout=wa*io*e(vg)/kvt,即iout=(wa/wp)*iin=w*iinw=e(vthp-vtha)/kvt此处,wa=存储器阵列中的每个存储器单元的w。字线或控制栅可用作输入电压的存储器单元的输入。另选地,本文所述的vmm阵列的闪存存储器单元可被配置成在线性区域中操作:ids=β*(vgs-vth)*vds;β=u*cox*w/lw=α(vgs-vth)字线或控制栅或位线或源极线可以用作在线性区域中操作的存储器单元的输入。对于i-v线性转换器,在线性区域工作的存储器单元(例如参考存储器单元或外围存储器单元)或晶体管可以用来将输入/输出电流线性转换成输入/输出电压。美国专利申请第15/826,345号描述了图7的vmm阵列32的其他实施方案,该申请以引用方式并入本文。如本文所述,源极线或位线可以用作神经元输出(电流求和输出)。图10示出了神经元vmm阵列1000,其特别适用于图2所示的存储器单元210,并且用作输入层与下一层之间的突触。vmm阵列1000包括非易失性存储器单元的存储器阵列1003、第一非易失性参考存储器单元的参考阵列1001和第二非易失性参考存储器单元的参考阵列1002。沿阵列的列方向布置的参考阵列1001和1002用于将流入端子blr0、blr1、blr2和blr3的电流输入转换为电压输入wl0、wl1、wl2和wl3。实际上,第一非易失性参考存储器单元和第二非易失性参考存储器单元通过多路复用器1014(仅部分示出)二极管式连接,其中电流输入流入其中。参考单元被调谐(例如,编程)为目标参考电平。目标参考电平由参考微阵列矩阵(未示出)提供。存储器阵列1003用于两个目的。首先,它将vmm阵列1000将使用的权重存储在其相应的存储器单元上。第二,存储器阵列1003有效地将输入(即,在端子blr0、blr1、blr2和blr3中提供的电流输入,参考阵列1001和1002将它们转换成输入电压以提供给字线wl0、wl1、wl2和wl3)乘以存储在存储器阵列1003中的权重,然后将所有结果(存储器单元电流)相加以在相应的位线(bl0-bln)上产生输出,该输出将是下一层的输入或最终层的输入。通过执行乘法和加法函数,存储器阵列1003消除了对单独的乘法和加法逻辑电路的需要,并且也是高功效的。这里,电压输入在字线(wl0、wl1、wl2和wl3)上提供,并且输出在读取(推断)操作期间出现在相应位线(bl0-bln)上。置于位线bl0-bln中的每个位线上的电流执行来自连接到该特定位线的所有非易失性存储器单元的电流的求和函数。表5示出了用于vmm阵列1000的工作电压。表中的列指示置于用于所选单元的字线、用于未选单元的字线、用于所选单元的位线、用于未选单元的位线、用于所选单元的源极线和用于未选单元的源极线上的电压。行指示读取、擦除和编程操作。表5:图10的vmm阵列1000的操作wlwl-未选blbl-未选slsl-未选读取1-3.5v-0.5v/0v0.6-2v(ineuron)0.6v-2v/0v0v0v擦除约5-13v0v0v0v0v0v编程1-2v-0.5v/0v0.1-3uavinh约2.5v4-10v0-1v/flt图11示出了神经元vmm阵列1100,其特别适用于图2所示的存储器单元210,并且用作输入层与下一层之间的神经元的突触和部件。vmm阵列1100包括非易失性存储器单元的存储器阵列1103、第一非易失性参考存储器单元的参考阵列1101和第二非易失性参考存储器单元的参考阵列1102。参考阵列1101和1102在vmm阵列1100的行方向上延伸。vmm阵列类似于vmm1000,不同的是在vmm阵列1100中,字线在竖直方向上延伸。这里,输入设置在字线(wla0、wlb0、wla1、wlb2、wla2、wlb2、wla3、wlb3)上,并且输出在读取操作期间出现在源极线(sl0、sl1)上。置于各源极线上的电流执行来自连接到该特定源极线的存储器单元的所有电流的求和函数。表6示出了用于vmm阵列1100的工作电压。表中的列指示置于用于所选单元的字线、用于未选单元的字线、用于所选单元的位线、用于未选单元的位线、用于所选单元的源极线和用于未选单元的源极线上的电压。行指示读取、擦除和编程操作。表6:图11的vmm阵列1100的操作wlwl-未选blbl-未选slsl-未选读取1-3.5v-0.5v/0v0.6-2v0.6v-2v/0v约0.3-1v(ineuron)0v擦除约5-13v0v0v0v0vsl-禁止(约4-8v)编程1-2v-0.5v/0v0.1-3uavinh约2.5v4-10v0-1v/flt图12示出了神经元vmm阵列1200,其特别适用于图3所示的存储器单元310,并且用作输入层与下一层之间的神经元的突触和部件。vmm阵列1200包括非易失性存储器单元的存储器阵列1203、第一非易失性参考存储器单元的参考阵列1201和第二非易失性参考存储器单元的参考阵列1202。参考阵列1201和1202用于将流入端子blr0、blr1、blr2和blr3的电流输入转换为电压输入cg0、cg1、cg2和cg3。实际上,第一非易失性参考存储器单元和第二非易失性参考存储器单元通过多路复用器1212(仅部分示出)二极管式连接,其中电流输入通过blr0、blr1、blr2和blr3流入其中。多路复用器1212各自包括相应的多路复用器1205和级联晶体管1204,以确保在读取操作期间第一非易失性参考存储器单元和第二非易失性参考存储器单元中的每一者的位线(诸如blr0)上的恒定电压。将参考单元调谐至目标参考电平。存储器阵列1203用于两个目的。首先,它存储将由vmm阵列1200使用的权重。第二,存储器阵列1203有效地将输入(提供到端子blr0、blr1、blr2和blr3的电流输入,参考阵列1201和1202将这些电流输入转换成输入电压以提供给控制栅cg0、cg1、cg2和cg3)乘以存储在存储器阵列中的权重,然后将所有结果(单元电流)相加以产生输出,该输出出现在bl0-bln并且将是下一层的输入或最终层的输入。通过执行乘法和加法函数,存储器阵列消除了对单独的乘法和加法逻辑电路的需要,并且也是高功效的。这里,输入提供在控制栅极线(cg0、cg1、cg2和cg3)上,输出在读取操作期间出现在位线(bl0–bln)上。置于各位线上的电流执行来自连接到该特定位线的存储器单元的所有电流的求和函数。vmm阵列1200为存储器阵列1203中的非易失性存储器单元实现单向调谐。也就是说,每个非易失性存储器单元被擦除,然后被部分编程,直到达到浮栅上的所需电荷。这可例如使用下文所述的新型精确编程技术来执行。如果在浮栅上放置过多电荷(使得错误的值存储在单元中),则必须擦除单元,并且部分编程操作的序列必须重新开始。如图所示,共享同一擦除栅(诸如eg0或eg1)的两行需要一起擦除(其被称为页面擦除),并且此后,每个单元被部分编程,直到达到浮栅上的所需电荷。表7示出了用于vmm阵列1200的工作电压。表中的列指示置于用于所选单元的字线、用于未选单元的字线、用于所选单元的位线、用于未选单元的位线、用于所选单元的控制栅、用于与所选单元相同扇区中的未选单元的控制栅、用于与所选单元不同扇区中的未选单元的控制栅、用于所选单元的擦除栅、用于未选单元的擦除栅、用于所选单元的源极线、用于未选单元的源极线上的电压。行指示读取、擦除和编程操作。表7:图12的vmm阵列1200的操作图13示出了神经元vmm阵列1300,其特别适用于图3所示的存储器单元310,并且用作输入层与下一层之间的神经元的突触和部件。vmm阵列1300包括非易失性存储器单元的存储器阵列1303、第一非易失性参考存储器单元的参考阵列1301和第二非易失性参考存储器单元的参考阵列1302。eg线egr0、eg0、eg1和egr1竖直延伸,而cg线cg0、cg1、cg2和cg3以及sl线wl0、wl1、wl2和wl3水平延伸。vmm阵列1300类似于vmm阵列1400,不同的是vmm阵列1300实现双向调谐,其中每个单独的单元可以根据需要被完全擦除、部分编程和部分擦除,以由于使用单独的eg线而在浮栅上达到期望的电荷量。如图所示,参考阵列1301和1302将端子blr0、blr1、blr2和blr3中的输入电流转换成要在行方向上施加到存储器单元的控制栅电压cg0、cg1、cg2和cg3(通过经由复用器1314的二极管连接的参考单元的动作)。电流输出(神经元)在位线bl0-bln中,其中每个位线对来自连接到该特定位线的非易失性存储器单元的所有电流求和。表8示出了用于vmm阵列1300的工作电压。表中的列指示置于用于所选单元的字线、用于未选单元的字线、用于所选单元的位线、用于未选单元的位线、用于所选单元的控制栅、用于与所选单元相同扇区中的未选单元的控制栅、用于与所选单元不同扇区中的未选单元的控制栅、用于所选单元的擦除栅、用于未选单元的擦除栅、用于所选单元的源极线、用于未选单元的源极线上的电压。行指示读取、擦除和编程操作。表8:图13的vmm阵列1300的操作长短期存储器现有技术包括被称为长短期存储器(lstm)的概念。lstm单元通常用于神经网络中。lstm允许神经网络在预定的任意时间间隔内记住信息并在后续操作中使用该信息。常规的lstm单元包括单元、输入栅、输出栅和忘记栅。三个栅调控进出单元的信息流以及信息在lstm中被记住的时间间隔。vmm尤其可用于lstm单元中。图14示出了示例性lstm1400。在该示例中,lstm1400包括单元1401、1402、1403和1404。单元1401接收输入矢量x0并生成输出矢量h0和单元状态矢量c0。单元1402接收输入矢量x1、来自单元1401的输出矢量(隐藏状态)h0和来自单元1401的单元状态c0,并生成输出矢量h1和单元状态矢量c1。单元1403接收输入矢量x2、来自单元1402的输出矢量(隐藏状态)h1和来自单元1402的单元状态c1,并生成输出矢量h2和单元状态矢量c2。单元1404接收输入矢量x3、来自单元1403的输出矢量(隐藏状态)h2和来自单元1403的单元状态c2,并生成输出矢量h3。可使用另外的单元,并且具有四个单元的lstm仅为示例。图15示出了可用于图14中的单元1401、1402、1403和1404的lstm单元1500的示例性具体实施。lstm单元1500接收输入矢量x(t)、来自前一单元的单元状态矢量c(t-1)和来自前一单元的输出矢量h(t-1),并生成单元状态矢量c(t)和输出矢量h(t)。lstm单元1500包括sigmoid函数设备1501、1502和1503,每个sigmoid函数设备应用0和1之间的数字来控制允许输入矢量中的每个分量的多少通过到输出矢量。lstm单元1500还包括用于将双曲线正切函数应用于输入矢量的tanh设备1504和1505、用于将两个矢量相乘在一起的乘法器设备1506、1507和1508、以及用于将两个矢量相加在一起的加法设备1509。输出矢量h(t)可被提供给系统中的下一个lstm单元,或者其可被访问用于其他目的。图16示出了lstm单元1600,其为lstm单元1500的具体实施的示例。为了方便读者,在lstm单元1600中使用与lstm单元1500相同的编号。sigmoid函数设备1501、1502和1503以及tanh设备1504各自包括多个vmm阵列1601和激活电路块区1602。因此,可以看出,vmm阵列在某些神经网络系统中使用的lstm单元中特别有用。lstm单元1600的替代形式(以及lstm单元1500的具体实施的另一个示例)在图17中示出。在图17中,sigmoid函数设备1501、1502和1503以及tanh设备1504以时分复用方式共享相同的物理硬件(vmm阵列1701和激活函数区块1702)。lstm单元1700还包括将两个矢量相乘在一起的乘法器设备1703,将两个矢量相加在一起的加法设备1708,tanh设备1505(其包括激活电路区块1702),当从sigmoid函数区块1702输出值i(t)时存储值i(t)的寄存器1707,当值f(t)*c(t-1)通过多路复用器1710从乘法器设备1703输出时存储值f(t)*c(t-1)的寄存器1704,当值i(t)*u(t)通过多路复用器1710从乘法器设备1703输出时存储值i(t)*u(t)的寄存器1705,当值o(t)*c~(t)通过多路复用器1710从乘法器设备1703输出时存储值o(t)*c~(t)的寄存器1706,和多路复用器1709。lstm单元1600包含多组vmm阵列1601和相应的激活函数区块1602,而lstm单元1700仅包含一组vmm阵列1701和激活函数区块1702,它们用于表示lstm单元1700的实施方案中的多个层。lstm单元1700将需要的空间比lstm1600更小,因为与lstm单元1600相比,lstm单元1700只需要其1/4的空间用于vmm和激活函数区块。还可理解,lstm单元通常将包括多个vmm阵列,每个vmm阵列需要由vmm阵列之外的某些电路区块(诸如求和器和激活电路区块以及高电压生成区块)提供的功能。为每个vmm阵列提供单独的电路区块将需要半导体设备内的大量空间,并且将在一定程度上是低效的。因此,下文所述的实施方案试图最小化vmm阵列本身之外所需的电路。栅控递归单元模拟vmm具体实施可用于栅控递归单元(gru)系统。gru是递归神经网络中的栅控机构。gru类似于lstm,不同的是gru单元一般包含比lstm单元更少的部件。图18示出了示例性gru1800。该示例中的gru1800包括单元1801、1802、1803和1804。单元1801接收输入矢量x0并生成输出矢量h0。单元1802接收输入矢量x1、来自单元1801的输出矢量h0并生成输出矢量h1。单元1803接收输入矢量x2和来自单元1802的输出矢量(隐藏状态)h1,并生成输出矢量h2。单元1804接收输入矢量x3和来自单元1803的输出矢量(隐藏状态)h2,并生成输出矢量h3。可以使用另外的单元,并且具有四个单元的gru仅仅是示例。图19示出了可用于图18的单元1801、1802、1803和1804的gru单元1900的示例性具体实施。gru单元1900接收输入矢量x(t)和来自前一个gru单元的输出矢量h(t-1),并生成输出矢量h(t)。gru单元1900包括sigmoid函数设备1901和1902,每个设备将介于0和1之间的数应用于来自输出矢量h(t-1)和输入矢量x(t)的分量。gru单元1900还包括用于将双曲线正切函数应用于输入矢量的tanh设备1903、用于将两个矢量相乘在一起的多个乘法器设备1904、1905和1906、用于将两个矢量相加在一起的加法设备1907,以及用于从1中减去输入以生成输出的互补设备1908。图20示出了gru单元2000,其为gru单元1900的具体实施的示例。为了方便读者,gru单元2000中使用与gru单元1900相同的编号。如在图20中可见,sigmoid函数设备1901和1902以及tanh设备1903各自包括多个vmm阵列2001和激活函数区块2002。因此,可以看出,vmm阵列在某些神经网络系统中使用的gru单元中特别有用。gru单元2000的替代形式(以及gru单元1900的具体实施的另一个示例)在图21中示出。在图21中,gru单元2100利用vmm阵列2101和激活函数块2102,激活函数块2102在被配置成sigmoid函数时,应用0至1之间的数字来控制允许输入矢量中的每个分量有多少通过到输出矢量。在图21中,sigmoid函数设备1901和1902以及tanh设备1903以时分复用方式共享相同的物理硬件(vmm阵列2101和激活函数区块2102)。gru单元2100还包括将两个矢量相乘在一起的乘法器设备2103,将两个矢量相加在一起的加法设备2105,从1减去输入以生成输出的互补设备2109,复用器2104,当值h(t-1)*r(t)通过多路复用器2104从乘法器设备2103输出时保持值h(t-1)*r(t)的寄存器2106,当值h(t-1)*z(t)通过多路复用器2104从乘法器设备2103输出时保持值h(t-1)*z(t)的寄存器2107,和当值h^(t)*(1-z(t))通过多路复用器2104从乘法器设备2103输出时保持值h^(t)*(1-z(t))的寄存器2108。gru单元2000包含多组vmm阵列2001和激活函数块2002,而gru单元2100仅包含一组vmm阵列2101和激活函数块2102,它们用于表示gru单元2100的实施方案中的多个层。gru单元2100将需要的空间比gru单元2000更小,因为与gru单元2000相比,gru单元2100只需要其1/3的空间用于vmm和激活函数区块。还可以理解的是,gru系统通常将包括多个vmm阵列,每个vmm阵列需要由vmm阵列之外的某些电路区块(诸如求和器和激活电路区块以及高电压生成区块)提供的功能。为每个vmm阵列提供单独的电路区块将需要半导体设备内的大量空间,并且将在一定程度上是低效的。因此,下文所述的实施方案试图最小化vmm阵列本身之外所需的电路。vmm阵列的输入可为模拟电平、二进制电平或数字位(在这种情况下,需要dac来将数字位转换成适当的输入模拟电平),并且输出可为模拟电平、二进制电平或数字位(在这种情况下,需要输出adc来将输出模拟电平转换成数字位)。对于vmm阵列中的每个存储器单元,每个权重w可由单个存储器单元或由差分单元或由两个混合存储器单元(2个单元的平均值)来实现。在差分单元的情况下,需要两个存储器单元来实现权重w作为差分权重(w=w –w-)。在两个混合存储器单元中,需要两个存储器单元来实现权重w作为两个单元的平均值。用于对vmm中的单元进行精确编程的实施方案图22a示出了编程方法2200。首先,该方法开始(步骤2201),这通常响应于接收到编程命令而发生。接下来,批量编程操作将所有单元编程到“0”状态(步骤2202)。然后,软擦除操作将所有单元擦除至中间弱擦除电平,使得每个单元在读取操作期间将消耗大约3μa-5μa的电流(步骤2203)。这与深度擦除级别形成对比,在深度擦除级别中每个单元在读取操作期间将消耗大约20μa-30μa的电流。然后,对所有未选择的单元执行硬编程到非常深的编程状态,以将电子添加到单元的浮栅(步骤2204),以确保那些单元真正“关断”,这意味着那些单元将在读取操作期间消耗可忽略不计的电流量。然后对所选择的单元执行粗略编程方法(步骤2205),之后对所选择的单元执行精密编程方法(步骤2206)以对每个所选择的单元所需的精确值进行编程。图22b示出了与编程方法2200类似的另一种编程方法2210。然而,代替如图22a的步骤2202中那样将所有单元编程到“0”状态的编程操作,在该方法开始(步骤2201)之后,使用擦除操作将所有单元擦除到“1”状态(步骤2212)。然后使用软编程操作(步骤2213)将所有单元编程到中间状态(级别),使得每个单元在读取操作期间将消耗大约3ua-5ua的电流。此后,粗略且精确的编程方法将如图22a所示。图22b的实施方案的变型将完全移除软编程方法(步骤2213)。图23示出了粗略编程方法2205的第一实施方案,其为搜索和执行方法2300。首先,执行查找表搜索以基于旨在存储在所选择的单元中的值来确定该所选择的单元的粗略目标电流值(ict)(步骤2301)。假设所选择的单元可被编程为存储n个可能值(例如,128、64、32等)中的一者。n个值中的每个值将对应于在读取操作期间由所选择的单元消耗的不同期望电流值(id)。在一个实施方案中,查找表可包含m个可能的电流值,以在搜索和执行方法2300期间用作所选择的单元的粗略目标电流值ict,其中m为小于n的整数。例如,如果n为8,则m可以为4,这意味着存在所选择的单元可存储的8个可能值,并且4个粗略目标电流值中的一者将被选择用于搜索和执行方法2300的粗略目标。也就是说,搜索和执行方法2300(其也是粗略编程方法2205的一个实施方案)旨在将所选择的单元快速编程为在一定程度上接近期望值(id)的值(ict),然后精确编程方法2206旨在将所选择的单元更精确地编程为极其接近期望值(id)。对于n=8和m=4的简单示例,单元值、期望电流值和粗略目标电流值的示例在表9和10中示出:表9:n=8时n个期望电流值的示例存储在所选择单元中的值期望电流值(id)000100pa001200pa010300pa011400pa100500pa101600pa110700pa111800pa表10:m=4时的m个目标电流值的示例粗略目标电流值(ict)相关联的单元值200pa ictoffset1000,001400pa ictoffset2010,011600pa ictoffset3100,101800pa ictoffset4110,111偏移值ictoffsetx用于防止在粗调期间超过期望电流值。一旦选择了粗略目标电流值ict,就通过基于所选择单元(例如,存储器单元210、310、410或510)的单元架构类型将电压v0施加到所选择单元的适当端子来对所选择单元进行编程(步骤2302)。如果所选择的单元是图3中类型的存储器单元310,则电压v0将被施加到控制栅端子28,并且根据粗略目标电流值ict,v0可以是5v-7v。v0的值任选地可由存储v0的电压查找表与粗略目标电流值ict确定。接下来,通过施加电压vi=vi-1 vincrement对所选择的单元进行编程,其中i从1开始并在每次重复该步骤时递增,并且vincrement为将导致适合于所需的变化粒度的编程程度的小电压(步骤2303)。因此,执行第一时间步骤2303,i=1,并且v1将为v0 vincrement。然后进行验证操作(步骤2304),其中对所选择的单元执行读取操作,并且测量通过所选择的单元消耗的电流(icell)。如果icell小于或等于ict(此处为第一阈值),则搜索和执行方法2300完成,并且可开始精确编程方法2206。如果icell不小于或等于ict,则重复步骤2303,并且i递增。因此,在粗略编程方法2205结束并且精确编程方法2206开始的时刻,电压vi将是用于对所选择的单元进行编程的最终电压,并且所选择的单元将存储与粗略目标电流值ict相关联的值。精确编程方法2206的目的是将所选择的单元编程到在读取操作期间其消耗电流id(加上或减去可接受的偏差量,诸如50pa或更小)的程度,该电流id是与旨在存储在所选择的单元中的值相关联的期望电流值。图24示出了可在精确编程方法2206期间施加至所选择的存储器单元的控制栅的不同电压累进的示例。在第一种方法下,累进地向控制栅施加递增的电压以进一步编程所选择的存储器单元。起点为vi,其为在粗略编程方法2205期间施加的最终电压。将增量vp1添加至v1,然后使用电压v1 vp1对所选择单元(由从累进2401中的左侧起的第二脉冲所指示)进行编程。vp1为小于vincrement(在粗略编程方法2205期间使用的电压增量)的增量。在施加每个编程电压之后,执行验证步骤(类似于步骤2304),其中确定icell是否小于或等于ipt1(其为第一精确目标电流值并且此处为第二阈值),其中ipt1=id ipt1offset,其中ipt1offset是为防止编程过冲而添加的偏移值。如果不是,则将另一个增量vp1添加到先前施加的编程电压,并重复该过程。在icell小于或等于ipt1时,则编程序列的该部分停止。任选地,如果ipt1等于id或足够精确地近似等于id,则所选择的存储器单元已被成功编程。如果ipt1不够接近id,则可进行较小粒度的进一步编程。这里,现使用累进2402。累进2402的起始点是用于累进2401下的编程的最终电压。将增量vp2(其小于vp1)添加到该电压,并且施加组合电压以对所选择的存储器单元进行编程。在施加每个编程电压之后,执行验证步骤(类似于步骤2304),其中确定icell是否小于或等于ipt2(其为第二精确目标电流值并且此处为第三阈值),其中ipt2=id ipt2offset,其中ipt2offset是为防止编程过冲而添加的偏移值。如果不是,则将另一个增量vp2添加到先前施加的编程电压,并重复该过程。在icell小于或等于ipt2时,则编程序列的该部分停止。这里,假设ipt2等于id或足够接近id,以便编程可停止,因为目标值已以足够的精度实现。本领域的普通技术人员可以理解,可通过使用越来越小的编程增量来施加附加的累进。例如,在图25中,施加三个累进(2501、2502和2503)而不是仅两个累进。在进度2403中示出了第二种方法。此处,并非增加在所选择的存储器单元的编程期间施加的电压,而是在增加周期的持续时间内施加相同的电压。并非在进度2401中添加增量电压诸如vp1并且在进度2403中添加vp2,而是将附加的时间增量tp1添加到编程脉冲,使得每个施加的脉冲比先前施加的脉冲长tp1。在施加每个编程脉冲之后,执行与先前针对累进2401所述相同的验证步骤。任选地,在添加到编程脉冲中的附加时间增量比先前使用的进度具有更短的持续时间的情况下,则可以施加附加累进。尽管仅示出一个时间累进,但本领域的普通技术人员将理解,可施加任何数量的不同时间累进。现在将提供针对粗略编程方法2205的两个附加实施方案的附加细节。图26示出了粗略编程方法2205的第二实施方案,其为自适应校准方法2600。该方法开始(步骤2601)。以默认起始值v0对单元进行编程(步骤2602)。与搜索和执行方法2300中不同,这里v0不是从查找表得出的,而是可以是相对较小的初始值。在第一电流值ir1(例如,100na)和第二电流值ir2(例如,10na)处测量该单元的控制栅电压,并基于这些测量值(例如,360mv/dec)确定亚阈值斜率并存储(步骤2603)。确定新的期望电压vi。第一次执行该步骤时,i=1,并且使用亚阈值公式基于所存储的亚阈值斜率值以及电流目标值和偏移值来确定v1,诸如以下:vi=vi-1 vincrement,vincrement与vg的斜率成比例vg=k*vt*log[ids/wa*io]这里,wa是存储器单元的w,ids是电流目标值加上偏移值。如果所存储的斜率值相对较陡,则可使用相对较小的电流偏移值。如果所存储的斜率值相对平坦,则可使用相对较高的电流偏移值。因此,确定斜率信息将允许选择为所考虑的特定单元定制的电流偏移值。这最终将使编程过程更短。当重复该步骤时,i递增,并且vi=vi-1 vincrement。然后使用vi进行编程。vincrement可由存储vincrement值与目标电流值的查找表确定。然后,进行验证操作,其中对所选择的单元执行读取操作,并且测量通过所选择的单元消耗的电流(icell)(步骤2605)。如果icell小于或等于ict(此处其为粗略目标阈值),其中ict被设定为=id ictoffset,其中ictoffset是为防止编程过冲所添加的偏移值,则自适应校准方法2600完成并且可开始精确编程方法2206。如果icell不小于或等于ict,则重复步骤2604至2605,并且i递增。图27示出了自适应校准方法2600的各方面。在步骤2603期间,电流源2701用于将示例性电流值ir1和ir2施加至所选择的单元(此处为存储器单元2702),然后测量存储器单元2702的控制栅处的电压(cgr1用于ir1,cgr2用于ir2)。斜率将为(cgr2-cgr1)/dec。图28示出了粗略编程方法2205的第二实施方案,其为绝对校准方法2800。该方法开始(步骤2801)。以默认起始值v0对单元进行编程(步骤2802)。在电流值itarget处测量该单元的控制栅电压(vcgrx)并存储(步骤2803)。基于所存储的控制栅电压以及电流目标值和偏移值ioffset itarget来确定新的期望电压v1(步骤2804)。例如,新的期望电压v1可如下计算:v1=v0 (vcgbias-存储的vcgr),其中vcgbias约等于1.5v,其为最大目标电流下的默认读取控制栅电压,并且存储的vcgr为步骤2803测量的读取控制栅电压。然后使用vi对该单元进行编程。当i=1时,使用来自步骤2804的电压v1。当i>=2时,使用电压vi=vi-1 vincrement。vincrement可从存储vincrement值与目标电流值的查找表中确定。然后,进行验证操作,其中对所选择的单元执行读取操作,并且测量通过所选择的单元消耗的电流(icell)(步骤2806)。如果icell小于或等于ict(此处其为阈值),则绝对校准方法2800完成,并且可开始精确编程方法2206。如果icell不小于或等于ict,则重复步骤2805至2806,并且i递增。图29示出了用于实施绝对校准方法2800的步骤2803的电路2900。电压源(未示出)生成vcgr,该vcgr从初始电压开始并向上斜升。此处,n 1个不同的电流源2901(2901-0、2901-1、2901-2、...、2901-n)生成量值递增的不同电流io0、io1、io2、…ion。每个电流源2901连接到反相器2902(2902-0、2902-1、2902-2、...、2902-n)和存储器单元2903(2903-0、2903-1、2903-2、...2903-n)。当vcgr向上斜升时,每个存储器单元2903消耗增加量的电流,并且到每个反相器2902的输入电压降低。由于io0<io1<io2<...<ion,因此反相器2902-0的输出将随着vcgr增加而首先从低电平切换到高电平。接着,反相器2902-1的输出将从低电平切换到高电平,然后是反相器2902-2的输出进行切换,依此类推,直到反相器2902-n的输出从低电平切换到高电平。每个反相器2902控制开关2904(2904-0、2904-1、2904-2、...、2904-n),使得当反相器2902的输出为高电平时,开关2904闭合,这将使vcgr被电容器2905(2905-0、2905-1、2905-2、...、2905-n)采样。因此,开关2904和电容器2905可形成采样保持电路。在图28的绝对校准方法2800中,io0、io1、io2、...、ion的值被用作itarget的可能值,并且相应的采样电压被用作相关联值vcgrx。曲线图2906示出了vcgr随时间推移而向上斜升,并且反相器2902-0、2902-1和2902-n的输出在不同时间从低电平切换到高电平。图30示出了用于在自适应校准方法2600或绝对校准方法2800期间对所选择的单元编程的示例性累进3000。在一个实施方案中,电压vcgp被施加到所选择行的存储器单元的控制栅。所选择行中的所选择存储器单元的数量例如=32个单元。因此,可并行编程所选择行中的多达32个存储器单元。每个存储器单元被允许通过位线使能信号联接到编程电流iprog。如果位线使能信号为非活动的(意味着正电压被施加到所选择的位线),则存储器单元被抑制(未被编程)。如图30所示,位线使能信号en_blx(其中x在1和n之间变化,其中n为位线的数量)在不同时间被允许具有该位线(从而所述位线上的所选择存储器)所需的vcgp电压电平。在另一个实施方案中,可使用位线上的使能信号来控制施加到所选择的单元的控制栅的电压。每个位线使能信号使得对应于该位线的所需电压(诸如图28中所述的vi)作为vcgp被施加。位线使能信号还可以控制流入位线的编程电流。在该示例中,每个后续控制栅电压vcgp高于先前电压。另选地,每个后续控制栅电压可低于或高于先前电压。vcgp的每个后续增量可等于或不等于先前增量。图31示出了用于在自适应校准方法2600或绝对校准方法2800期间对所选择的单元编程的示例性累进3100。在一个实施方案中,位线使能信号使得所选择的位线(意指所述位线中的所选择的存储器单元)能够用对应的vcgp电压电平编程。在另一个实施方案中,可使用位线使能信号来控制施加到所选择单元的增量斜升控制栅的电压。每个位线使能信号使得对应于该位线的所需电压(诸如图28中所述的vi)被施加到控制栅电压。在该示例中,每个后续增量等于先前增量。图32示出了用于实施利用vmm阵列进行读取或验证的输入和输出方法的系统。输入功能电路3201接收数字位值并将这些数字值转换成模拟信号,该模拟信号继而用于将电压施加到阵列3204中所选择的单元的控制栅,该控制栅通过控制栅解码器3202来确定。同时,字线解码器3203还用于选择所选择的单元所在的行。输出神经元电路块3205执行阵列3204中的单元的每列(神经元)的输出动作。输出电路块3205可使用积分型模数转换器(adc)、逐次逼近型(sar)adc、或σ-δ型adc来实现。在一个实施方案中,例如,提供给输入功能电路3201的数字值包括四个位(din3、din2、din1和din0),并且不同位值对应于施加到控制栅的不同数量的输入脉冲。较大数量的脉冲将导致该单元的较大输出值(电流)。位值和脉冲值的示例在表11中示出:表11:数字位输入与生成的脉冲din3din2din1din0生成的脉冲00000000110010200113010040101501106011171000810019101010101111110012110113111014111115在上述示例中,对于4位数字值存在最多16个脉冲以用于读出单元值。每个脉冲等于一个单位的单元值(电流)。例如,如果icell单位=1na,则对于din[3-0]=0001,icell=1*1na=1na;并且对于din[3-0]=1111,icell=15*1na=15na。在另一个实施方案中,数字位输入使用数字位位置求和来读出单元值,如表12所示。此处,仅需要4个脉冲来评估4位数字值。例如,第一脉冲用于评估din0,第二脉冲用于评估din1,第三脉冲用于评估din2,第四脉冲用于评估din3。然后,根据位位置对来自四个脉冲的结果求和。实现的数字位求和公式如下:输出=2^0*din0 2^1*din1 2^2*din2 2^3*din3)*icell单位。例如,如果icell单位=1na,则对于din[3-0]=0001,icell总数=0 0 0 1*1na=1na;并且对于din[3-0]=1111,icell总数=8*1na 4*1na 2*1na 1*1na=15na。表12:数字位输入求和图33示出了电荷求和器3300的示例,该电荷求和器可用于在验证操作期间对vmm的输出进行求和以获得单个模拟值,该模拟值表示输出并且随后可被任选地转换为数字位值。电荷求和器3300包括电流源3301和采样保持电路,该采样保持电路包括开关3302和采样保持(s/h)电容器3303。如针对4位数字值的示例所示,存在4个s/h电路以保持来自4个评估脉冲的值,其中这些值在过程结束时相加。s/h电容器3303被选择为具有与该s/h电容器的2^n*dinn位位置相关联的比例;例如,c_din3=x8cu,c_din2=x4cu,c_din1=x2cu,din0=x1cu。电流源3301也被相应地赋予比例。图34示出了可用于在验证操作期间对vmm的输出进行求和的电流求和器3400。电流求和器3400包括电流源3401、开关3402、开关3403和3404以及开关3405。如针对4位数字值的示例所示,存在电流源电路以保持来自4个评估脉冲的值,其中这些值在过程结束时相加。电流源基于2^n*dinn位位置被赋予比例;例如,i_din3=x8icell单位,i_din2=x4icell单位,i_din1=x2icell单位,i_din0=x1icell单位。图35示出了数字求和器3500,该数字求和器接收多个数字值,将它们求和并且生成表示输入的总和的输出dout。数字求和器3500可在验证操作期间使用。如针对4位数字值的示例所示,存在数字输出位以保持来自4个评估脉冲的值,其中这些值在过程结束时相加。基于2^n*dinn位位置对数字输出进行数字缩放;例如,dout3=x8dout0,_dout2=x4dout1,i_dout1=x2dout0,i_dout0=dout0。图36a示出了应用于输出神经元以将单元电流转换成数字输出位的积分型双斜率adc3600。由积分型运算放大器3601和积分型电容器3602组成的积分器对单元电流icell与参考电流iref进行积分。如图36b所示,在固定时间t1期间,单元电流被上积分(vout上升),然后在时间t2内施加参考电流以下积分(vout下降)。电流icell=t2/t1*iref。例如,对于t1,对于10位数字位分辨率,使用1024个周期,并且对于t2,周期数根据icell值从0到1024个周期而变化。图36c示出了应用于输出神经元以将单元电流转换成数字输出位的积分型单斜率adc3660。由积分型运算放大器3661和积分型电容器3662组成的积分器对单元电流icell进行积分。如图36d所示,在时间t1期间,单元电流被上积分(vout上升直到其达到vref2),并且在时间t2期间,另一单元电流被上积分。单元电流icell=cint*vref2/t。脉冲计数器用于计数在积分时间t期间的脉冲数(数字输出位)。例如,如图所示,t1的数字输出位小于t2的数字输出位,这意味着t1期间的单元电流大于t2积分期间的单元电流。进行初始校准以利用参考电流和固定时间来校准积分型电容器值cint=tref*iref/vref2。图36e示出了应用于输出神经元以将单元电流转换成数字输出位的积分型双斜率adc3680。积分型双斜率adc3680不使用积分型运算放大器。单元电流或参考电流直接针对电容器3682积分。脉冲计数器用于对在积分时间期间的脉冲(数字输出位)进行计数。电流icell=t2/t1*iref。图36f示出了应用于输出神经元以将单元电流转换成数字输出位的积分型单斜率adc3690。积分型单斜率adc3680不使用积分型运算放大器。单元电流直接针对电容器3692积分。脉冲计数器用于对积分时间期间的脉冲(数字输出位)进行计数。单元电流icell=cint*vref2/t。图37a示出了应用于输出神经元以将单元电流转换成数字输出位的sar(逐次逼近寄存器)adc。单元电流可在电阻器两端下降以转换成vcell。另选地,单元电流可使s/h电容器充电以转换成vcell。二进制搜索用于计算从msb位(最高有效位)开始的位。基于来自sar3701的数字位,dac3702用于向比较器3703设置适当的模拟参考电压。比较器3703的输出继而反馈到sar3701以选择下一个模拟电平。如图37b所示,对于4位数字输出位的示例,存在4个评估周期:第一脉冲通过将模拟电平设置在中间来评估dout3,然后第二脉冲通过将模拟电平设置在上半部的中间或下半部的中间来评估dout2,等等。图38示出了应用于输出神经元以将单元电流转换成数字输出位的σ-δ型adc3800。由运算放大器3801和电容器3805组成的积分器对来自所选择的单元电流的电流和来自1位电流dac3804的参考电流的总和进行积分。比较器3802将积分输出电压与参考电压进行比较。时钟控制的dff3803根据比较器3802的输出来提供数字输出流。数字输出流通常在输出到数字输出位之前进入数字滤波器。应当指出,如本文所用,术语“在…上方”和“在…上”两者包容地包含“直接在…上”(之间未设置中间材料、元件或空间)和“间接在…上”(之间设置有中间材料、元件或空间)。类似地,术语“相邻”包括“直接相邻”(之间没有设置中间材料、元件或空间)和“间接相邻”(之间设置有中间材料、元件或空间),“安装到”包括“直接安装到”(之间没有设置中间材料、元件或空间)和“间接安装到”(之间设置有中间材料、元件或空间),并且“电联接至”包括“直接电联接至”(之间没有将元件电连接在一起的中间材料或元件)和“间接电联接至”(之间有将元件电连接在一起的中间材料或元件)。例如,“在衬底上方”形成元件可包括在两者间没有中间材料/元件的情况下在衬底上直接形成元件,以及在两者间有一个或多个中间材料/元件的情况下在衬底上间接形成元件。权利要求书(按照条约第19条的修改)1.一种对所选择的非易失性存储器单元进行编程以存储n个可能值中的一个可能值的方法,其中n是大于2的整数,所述所选择的非易失性存储器单元包括浮栅,所述方法包括:执行粗略编程过程,包括:选择m个不同电流值中的一个电流值作为第一阈值电流值,其中m<n;向所述浮栅添加电荷;并且重复所述添加步骤,直到在验证操作期间通过所述所选择的非易失性存储器单元的电流小于或等于所述第一阈值电流值;以及执行精确编程过程,直到在验证操作期间通过所述所选择的非易失性存储器单元的电流小于或等于第二阈值电流值。2.根据权利要求1所述的方法,所述方法还包括:执行第二精确编程过程,直到在验证操作期间通过所述所选择的非易失性存储器单元的电流小于或等于第三阈值电流值。3.根据权利要求1所述的方法,其中所述精确编程过程包括向所述所选择的非易失性存储器单元的控制栅施加量值递增的电压脉冲。4.根据权利要求1所述的方法,其中所述精确编程过程包括向所述所选择的非易失性存储器单元的所述控制栅施加持续时间递增的电压脉冲。5.根据权利要求2所述的方法,其中所述第二精确编程过程包括向所述所选择的非易失性存储器单元的所述控制栅施加量值递增的电压脉冲。6.根据权利要求2所述的方法,其中所述第二精确编程过程包括向所述所选择的非易失性存储器单元的所述控制栅施加持续时间递增的电压脉冲。7.根据权利要求1所述的方法,其中所述所选择的非易失性存储器单元包括浮栅。8.根据权利要求7所述的方法,其中所述所选择的非易失性存储器单元为分裂栅闪存存储器单元。9.根据权利要求1所述的方法,其中所述所选择的非易失性存储器单元在模拟存储器深度神经网络中的矢量-矩阵乘法阵列中。10.根据权利要求1所述的方法,所述方法还包括:在执行所述粗略编程过程之前:将所述所选择的非易失性存储器单元编程至“0”状态;以及将所述所选择的非易失性存储器单元擦除至弱擦除电平。11.根据权利要求1所述的方法,所述方法还包括:在执行所述粗略编程过程之前:将所述所选择的非易失性存储器单元擦除至“1”状态;以及将所述所选择的非易失性存储器单元编程至弱编程电平。12.根据权利要求1所述的方法,所述方法还包括:对所述所选择的非易失性存储器单元执行读取操作;使用积分型模数转换器对在所述读取操作期间由所述所选择的非易失性存储器单元消耗的所述电流进行积分以生成数字位。13.根据权利要求1所述的方法,所述方法还包括:对所述所选择的非易失性存储器单元执行读取操作;使用σ-δ型模数转换器将在所述读取操作期间由所述所选择的非易失性存储器单元消耗的所述电流转换为数字位。14.一种对所选择的非易失性存储器单元进行编程以存储n个可能值中的一个可能值的方法,其中n是大于2的整数,所述所选择的非易失性存储器单元包括浮栅和控制栅,所述方法包括:执行粗略编程过程,包括:基于所述所选择的非易失性存储器单元的所述控制栅的电压变化和所述所选择的非易失性存储器单元消耗的电流的变化来确定斜率值;基于所述斜率值确定下一个编程电压值;从所述所选择的非易失性存储器单元的所述浮栅添加电荷量,直到在验证操作期间通过所述所选择的非易失性存储器单元的电流小于或等于第一阈值电流值;以及执行精确编程过程,直到在验证操作期间通过所述所选择的非易失性存储器单元的电流小于或等于第二阈值电流值。15.根据权利要求14所述的方法,所述方法还包括:执行第二精确编程过程,直到在验证操作期间通过所述所选择的非易失性存储器单元的电流小于或等于第三阈值电流值。16.根据权利要求14所述的方法,其中所述精确编程过程包括向所述所选择的非易失性存储器单元的所述控制栅施加量值递增的电压脉冲。17.根据权利要求14所述的方法,其中所述精确编程过程包括向所述所选择的非易失性存储器单元的所述控制栅施加持续时间递增的电压脉冲。18.根据权利要求15所述的方法,其中所述精确编程过程包括向所述所选择的非易失性存储器单元的所述控制栅施加量值递增的电压脉冲。19.根据权利要求15所述的方法,其中所述精确编程过程包括向所述所选择的非易失性存储器单元的所述控制栅施加持续时间递增的电压脉冲。20.根据权利要求14所述的方法,其中所述确定斜率值的步骤包括:向所述所选择的非易失性存储器单元的所述控制栅施加编程电压;通过所述所选择的非易失性存储器单元施加第一电流并确定所述控制栅的第一电压;通过所述所选择的非易失性存储器单元施加第二电流并确定所述控制栅的第二电压;并且通过将所述第二电压和所述第一电压之间的差值除以所述第二电流和所述第一电流之间的差值来计算所述斜率值。21.根据权利要求14所述的方法,其中所述所选择的非易失性存储器单元为分裂栅闪存存储器单元。22.根据权利要求14所述的方法,其中所述所选择的非易失性存储器单元在模拟存储器深度神经网络中的矢量-矩阵乘法阵列中。23.根据权利要求14所述的方法,所述方法还包括:在执行所述粗略编程过程之前:将所述所选择的非易失性存储器单元编程至“0”状态;以及将所述所选择的非易失性存储器单元擦除至弱擦除电平。24.根据权利要求14所述的方法,所述方法还包括:在执行所述粗略编程过程之前:将所述所选择的非易失性存储器单元擦除至“1”状态;以及将所述所选择的非易失性存储器单元编程至弱编程电平。25.根据权利要求14所述的方法,所述方法还包括:对所述所选择的非易失性存储器单元执行读取操作;使用积分型模数转换器对在所述读取操作期间由所述所选择的非易失性存储器单元消耗的所述电流进行积分以生成数字位。26.根据权利要求14所述的方法,所述方法还包括:对所述所选择的非易失性存储器单元执行读取操作;使用σ-δ型模数转换器将在所述读取操作期间由所述所选择的非易失性存储器单元消耗的所述电流转换为数字位。27.一种对所选择的非易失性存储器单元进行编程以存储n个可能值中的一个可能值的方法,其中n是大于2的整数,所述所选择的非易失性存储器单元包括浮栅和控制栅,所述方法包括:执行粗略编程过程,包括:向所述所选择的非易失性存储器单元的所述控制栅施加编程电压;每当执行所述施加步骤时重复所述施加步骤并将所述编程电压增大增量电压,直到在验证操作期间通过所述所选择的非易失性存储器单元的电流小于或等于所述阈值电流值;以及执行精确编程过程,直到在验证操作期间通过所述所选择的非易失性存储器单元的电流小于或等于第二阈值电流值。28.根据权利要求27所述的方法,所述方法还包括:执行精确编程过程,直到在验证操作期间通过所述所选择的非易失性存储器单元的电流小于或等于第三阈值电流值。29.根据权利要求27所述的方法,其中所述精确编程过程包括向所述所选择的非易失性存储器单元的所述控制栅施加量值递增的电压脉冲。30.根据权利要求27所述的方法,其中所述精确编程过程包括向所述所选择的非易失性存储器单元的所述控制栅施加持续时间递增的电压脉冲。31.根据权利要求28所述的方法,其中所述精确编程过程包括向所述所选择的非易失性存储器单元的所述控制栅施加量值递增的电压脉冲。32.根据权利要求28所述的方法,其中所述精确编程过程包括向所述所选择的非易失性存储器单元的所述控制栅施加持续时间递增的电压脉冲。33.根据权利要求27所述的方法,其中所述所选择的非易失性存储器单元包括浮栅。34.根据权利要求33所述的方法,其中所述所选择的非易失性存储器单元为分裂栅闪存存储器单元。35.根据权利要求27所述的方法,其中所述所选择的非易失性存储器单元在模拟存储器深度神经网络中的矢量-矩阵乘法阵列中。36.根据权利要求27所述的方法,所述方法还包括:在执行所述粗略编程过程之前:将所述所选择的非易失性存储器单元编程至“0”状态;以及将所述所选择的非易失性存储器单元擦除至弱擦除电平。37.根据权利要求27所述的方法,所述方法还包括:在执行所述粗略编程过程之前:将所述所选择的非易失性存储器单元擦除至“1”状态;以及将所述所选择的非易失性存储器单元编程至弱编程电平。38.根据权利要求27所述的方法,所述方法还包括:对所述所选择的非易失性存储器单元执行读取操作;使用积分型模数转换器对在所述读取操作期间由所述所选择的非易失性存储器单元消耗的所述电流进行积分以生成数字位。39.根据权利要求27所述的方法,所述方法还包括:对所述所选择的非易失性存储器单元执行读取操作;使用σ-δ型模数转换器将在所述读取操作期间由所述所选择的非易失性存储器单元消耗的所述电流转换为数字位。40.一种读取存储有n个可能值中的一个可能值的所选择的非易失性存储器单元的方法,其中n是大于2的整数,所述方法包括:向所述所选择的非易失性存储器单元施加数字输入脉冲;响应于所述数字输入脉冲中的每个数字输入脉冲,基于所述所选择的非易失性存储器单元的输出来确定存储在所述所选择的非易失性存储器单元中的值。41.根据权利要求40所述的方法,其中所述数字输入脉冲的数量对应于二进制值。42.根据权利要求40所述的方法,其中所述数字输入脉冲的数量对应于数字位位置值。43.根据权利要求40所述的方法,其中所述确定步骤包括接收积分型模数转换器中的输出神经元以生成指示存储在所述非易失性存储器单元中的所述值的数字位。44.根据权利要求40所述的方法,其中所述确定步骤包括接收逐次逼近寄存器模数转换器中的输出神经元以生成指示存储在所述非易失性存储器单元中的所述值的数字位。45.根据权利要求40所述的方法,其中所述输出是电流。46.根据权利要求40所述的方法,其中所述输出是电荷。47.根据权利要求40所述的方法,其中所述输出是数字位。48.根据权利要求40所述的方法,其中所述所选择的非易失性存储器单元包括浮栅。49.根据权利要求48所述的方法,其中所述所选择的非易失性存储器单元为分裂栅闪存存储器单元。50.根据权利要求40所述的方法,其中所述所选择的非易失性存储器单元在模拟存储器深度神经网络中的矢量-矩阵乘法阵列中。51.一种读取存储有n个可能值中的一个可能值的所选择的非易失性存储器单元的方法,其中n是大于2的整数,所述方法包括:向所述所选择的非易失性存储器单元施加输入;响应于所述输入,使用模数转换器电路基于所述所选择的非易失性存储器单元的输出来确定存储在所述所选择的非易失性存储器单元中的值。52.根据权利要求51所述的方法,其中所述输入是数字输入。53.根据权利要求51所述的方法,其中所述输入是模拟输入。54.根据权利要求51所述的方法,其中所述确定步骤包括接收积分型单斜率或双斜率模数转换器中的输出神经元,并且生成指示存储在所述非易失性存储器单元中的所述值的数字位。55.根据权利要求51所述的方法,其中所述确定步骤包括接收sar模数转换器中的输出神经元以生成指示存储在所述非易失性存储器单元中的所述值的数字位。56.根据权利要求51所述的方法,其中所述确定步骤包括接收σ-δ型模数转换器中的输出神经元以生成指示存储在所述非易失性存储器单元中的所述值的数字位。57.根据权利要求51所述的方法,其中所述所选择的非易失性存储器单元包括浮栅。58.根据权利要求51所述的方法,其中所述所选择的非易失性存储器单元为分裂栅闪存存储器单元。59.根据权利要求51所述的方法,其中所述所选择的非易失性存储器单元在模拟存储器深度神经网络中的矢量-矩阵乘法阵列中。60.根据权利要求51所述的方法,其中所述所选择的非易失性存储器单元在亚阈值区域中工作。61.根据权利要求51所述的方法,其中所述所选择的非易失性存储器单元在线性区域中工作。当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。