1.本发明涉及网络安全领域,尤其涉及一种互联网重要基础设施知识图谱构建方法与装置。
背景技术:
2.网络安全态势感知并不缺乏可用的信息,但如何分析利用多源异构的数据,进而深入掌握安全态势并为决策提供支持是亟待解决的问题。针对网络空间安全构建知识图谱可以将海量碎片化的多源异构数据构建成一个整体,进行深度的关联分析和挖掘,进而掌握网络安全态势,并为辅助决策提供基础。
3.目前构建网络安全知识图谱的方法主要有两种,一类是针对局部网络进行知识图谱构建,例如2016年s.noel等人开发了一个基于neo4j图数据库的网络态势知识图谱工具cygraph,主要面向网络行动任务分析、可视化分析和知识管理。2017年simeonovski等人针对服务和供应商之间复杂的依赖关系、恶意使用的原因和攻击可能造成的影响,构建了一个属性图模型,在其上提出了一种基于污点传播的威胁评估技术。2018年贾焰等人提出了一个构建网络安全知识图谱的方法和基于五元组模型的推演规则,使用机器学习的方法抽取实体,然后创建本体,从而构建网络安全知识库。2019年najafi等人提出了一种基于图的malrank推理算法,该算法根据所构建的知识图谱中节点与其他实体的关系来推断节点的恶意程度。2019年kiesling等人将网络空间开源的各种漏洞、弱点和攻击模式的关键信息构建为知识图谱。
4.另外一种是针对网络空间相关的文本信息进行抽取,构建知识图谱。例如,2019年秦娅等人针对传统的命名实体识别难以识别网络安全领域中英文混合安全实体的问题,提出了一种结合特征模板的网络安全实体识别方法。2019年sudip mittal等人构建了一个用于知识抽取、表示和分析的
‘
cyber
‑
all
‑
intel’系统,并结合知识图谱和向量的形式提出
‘
vkg’结构,同时使用神经网络来提高知识质量,并创建了查询引擎和警报系统。
5.目前网络安全领域涉及较多的研究主要是如何从海量网络安全文本数据中提取主机、人员、网络设备和漏洞等相关安全实体及其之间的关系,并将其图谱化进行显示和利用。此类文本数据主要来源于各类网络安全论坛、博客、社区和技术报告等,网络空间结构和态势的相关信息相对匮乏。
技术实现要素:
6.为解决上述技术问题,本发明提出了一种互联网重要基础设施知识图谱构建方法及装置,所述方法及装置,用以解决现有技术中网络空间知识图谱相关技术和方法缺乏网络空间结构和态势的相关知识的问题。
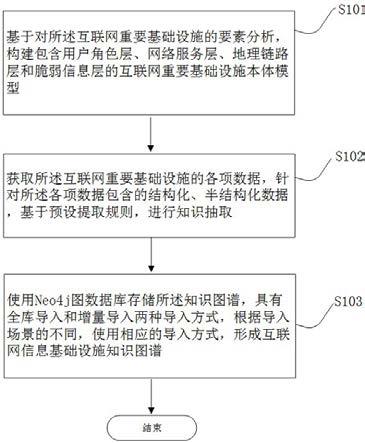
7.根据本发明的第一方面,提供一种互联网重要基础设施知识图谱构建方法,所述方法包括以下步骤:步骤s101:基于对所述互联网重要基础设施的要素分析,构建包含用户角色层、网
络服务层、地理链路层和脆弱信息层的互联网重要基础设施本体模型;所述互联网重要基础设施是包含域名系统、 web 服务和网络地址进行互联网信息交换的重要服务集合;步骤s102:获取所述互联网重要基础设施的各项数据,针对所述各项数据包含的结构化、半结构化数据,基于预设提取规则,进行知识抽取;步骤s103:使用neo4j图数据库存储所述知识图谱,具有全库导入和增量导入两种导入方式,根据导入场景的不同,使用相应的导入方式,形成互联网信息基础设施知识图谱。
8.进一步地,在所述网络服务层中,首先创建节点dns区域,而后针对该dns区域的ns记录和mx记录,创建名称服务器和邮件服务器实体节点,并创建子域名节点;结合dns和现实网络结构,确定dns区域的ns记录、mx记录的关系,dns区域和子域名之间属于控制关系;并添加子域名和子域名之间的cnmae记录和外链关系;针对开启web服务的子域名,根据使用软件服务的版本,判断其可能存在的漏洞,进而通过关系使得漏洞与漏洞节点相关联。
9.进一步地,所述步骤s102:获取所述互联网重要基础设施的各项数据,针对所述各项数据包含的结构化、半结构化数据,基于预设提取规则,进行知识抽取,包括:对alexa排名前一百万域名的记录进行查询获取,并基于正则表达式对每类数据进行知识抽取,形成网络服务层知识;采用命令获取方式,基于 linux 下 whois 命令向 whois 数据库发送查询请求,获取域名的 whois数据;whois数据存在thin和thick两种模式,其中thick模式中所有域名的whois数据格式相同;thin模式中,每个域名的whois数据没有统一的格式,针对thick模式的whois数据基于正则表达式编写知识提取规则进行数据抽取;针对thin模式的数据,使用基于条件随机场构建的模型进行抽取;基于抽取到的数据,形成用户角色层知识;基于爬虫获取每一个ip地址对应的 as 自治域和地理位置信息,形成地理链路层知识;基于爬虫获取的漏洞库的数据,包含了漏洞及与漏洞对应的相关信息,基于正则表达式构成知识抽取规则库,生成与脆弱性相关的实体及关系,通过域名的操作系统、软件版本和开放端口判断可能存在的漏洞,形成网络服务层和脆弱信息层之间的关系。
10.根据本发明第二方面,提供一种互联网重要基础设施知识图谱构建装置,所述装置包括:模型建立模块:配置为基于对所述互联网重要基础设施的要素分析,构建包含用户角色层、网络服务层、地理链路层和脆弱信息层的互联网重要基础设施本体模型;所述互联网重要基础设施是包含域名系统、 web 服务和网络地址进行互联网信息交换的重要服务集合;提取模块:配置为获取所述互联网重要基础设施的各项数据,针对所述各项数据包含的结构化、半结构化数据,基于预设提取规则,进行知识抽取;导入模块:配置为使用neo4j图数据库存储所述知识图谱,具有全库导入和增量导入两种导入方式,根据导入场景的不同,使用相应的导入方式,形成互联网信息基础设施知识图谱。
11.进一步地,在所述网络服务层中,首先创建节点dns区域,而后针对该dns区域的ns记录和mx记录,创建名称服务器和邮件服务器实体节点,并创建子域名节点;结合dns和现实网络结构,确定dns区域的ns记录、mx记录的关系,dns区域和子域名之间属于控制关系;
并添加子域名和子域名之间的cnmae记录和外链关系;针对开启web服务的子域名,根据使用软件服务的版本,判断其可能存在的漏洞,进而通过关系使得漏洞与漏洞节点相关联。
12.进一步地,所述提取模块,对alexa排名前一百万域名的记录进行查询获取,并基于正则表达式对每类数据进行知识抽取,形成网络服务层知识;采用命令获取方式,基于 linux 下 whois 命令向 whois 数据库发送查询请求,获取域名的 whois数据;whois数据存在thin和thick两种模式,其中thick模式中所有域名的whois数据格式相同;thin模式中,每个域名的whois数据没有统一的格式,针对thick模式的whois数据基于正则表达式编写知识提取规则进行数据抽取;针对thin模式的数据,使用基于条件随机场构建的模型进行抽取;基于抽取到的数据,形成用户角色层知识;基于爬虫获取每一个ip地址对应的 as 自治域和地理位置信息,形成地理链路层知识;基于爬虫获取的漏洞库的数据,包含了漏洞及与漏洞对应的相关信息,基于正则表达式构成知识抽取规则库,生成与脆弱性相关的实体及关系,通过域名的操作系统、软件版本和开放端口判断可能存在的漏洞,形成网络服务层和脆弱信息层之间的关系。
13.根据本发明第三方面,提供一种互联网重要基础设施知识图谱构建系统,包括:处理器,用于执行多条指令;存储器,用于存储多条指令;其中,所述多条指令,用于由所述存储器存储,并由所述处理器加载并执行如前所述的互联网重要基础设施知识图谱构建方法。
14.根据本发明第四方面,提供一种计算机可读存储介质,所述存储介质中存储有多条指令;所述多条指令,用于由处理器加载并执行如前所述的互联网重要基础设施知识图谱构建方法。
15.根据本发明的上述方案,为了构建具有表征网络空间安全态势能力的知识图谱,针对互联网重要基础设施,对相关数据进行收集和处理,获取其中安全实体和实体间的关系,构建形成互联网信息基础设施安全知识图谱,进而更为直观地展示现实网络安全态势,并为漏洞影响范围分析、应用分布统计等应用提供支撑,具有重要的研究价值。
16.具体实现如下效果:(1)利用所描述方法可以实现对互联网重要基础设施相关数据的数据获取和知识抽取;(2)利用所描述方法可以实现将多源异构数据和知识整合成为统一的模型进行分析和利用;(3)利用所描述方法可以实现基于知识图谱的展现方式对网络安全态势进行查询和展现。
17.上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
18.构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明提供如下附图进行说明。在附图中:图1为本发明一个实施方式的互联网重要基础设施知识图谱构建方法流程图;图2为本发明一个实施方式的互联网重要基础设施知识图谱构建法的细节实现的整体流程图;图3为本发明一个实施方式的互联网重要基础设施本体示意图;
图4为本发明一个实施方式的知识抽取规则图;图5为本发明一个实施方式的导入策略图;图6为本发明一个实施方式的互联网重要基础设施知识图谱构建装置结构框图。
具体实施方式
19.首先结合图1说明为本发明一个实施方式的互联网重要基础设施知识图谱构建方法。如图1
‑
2所示,所述方法包括以下步骤:步骤s101:基于对所述互联网重要基础设施的要素分析,构建包含用户角色层、网络服务层、地理链路层和脆弱信息层的互联网重要基础设施本体模型;所述互联网重要基础设施是包含域名系统、 web 服务和网络地址进行互联网信息交换的重要服务集合;步骤s102:获取所述互联网重要基础设施的各项数据,针对所述各项数据包含的结构化、半结构化数据,基于预设提取规则,进行知识抽取;步骤s103:使用neo4j图数据库存储所述知识图谱,具有全库导入和增量导入两种导入方式,根据导入场景的不同,使用相应的导入方式,形成互联网信息基础设施知识图谱。
20.所述步骤s101:基于对所述互联网重要基础设施的要素分析,构建包含用户角色层、网络服务层、地理链路层和脆弱信息层的互联网重要基础设施本体模型;所述互联网重要基础设施是包含域名系统、 web 服务和网络地址进行互联网信息交换的重要服务集合,包括:互联网基础设施指支撑互联网正常运行所必须的硬件和软件系统的集合,如传输线路、路由器、域名服务等。本实施例中,根据互联网测量数据和关键特征,对互联网基础设施的重要组成部分dns、web服务、ip地址及其地理位置和用户相关信息进行抽象,划分层级,进而构建与现实互联网部分一致的互联网重要基础设施本体模型,模型如图3所示。
21.基于日常的访问流程,访问一个站点首先会经过dns查询其相关的记录信息,以及站点相关的信息诸如开放端口、服务版本等相关信息。因此将web服务和dns相关信息定义为网络服务层,在所述网络服务层中,首先创建节点dns区域,而后针对该dns区域的ns、mx记录,创建名称服务器和邮件服务器实体节点,并创建子域名节点。结合dns和现实网络结构,确定dns区域的ns记录、mx记录的关系,dns区域和子域名之间属于控制关系;并添加子域名和子域名之间的cnmae记录和外链关系。针对开启web服务的子域名,根据使用软件服务的版本,判断其可能存在的漏洞,进而通过关系使得漏洞与漏洞节点相关联。
22.ip地址与域名有所不同,其具有地理位置、自治域等特征,因此将ip地址及其地理位置和自治域相结合定义为地理链路层。所述地理链路层主要涉及ip地址节点、地理位置节点和自治域节点。同时针对域名到ip地址的a记录映射添加关系a记录,ip地址对应的地理位置和自治域分别使用关系进行表示,关系包括来源关系和位于关系。
23.脆弱信息层用于评估互联网重要基础设施的相关脆弱性,所述脆弱信息层包括漏洞节点、常见攻击模式节点、用于软件安全的通用脆弱节点、脆弱产品节点、漏洞评分节点。
24.本实施例中,对互联网重要基础设施进行要素分析,整合了web服务、ip地址和域名系统的相关数据,并结合各种开源的与漏洞、脆弱性和攻击模式相关的知识库,构建了包含联系电话、组织、邮箱、名称服务器、dns区域、子域名、邮件服务器、子域名、ip地址、as自
治域、地理位置、漏洞、漏洞评分、脆弱点、脆弱产品和攻击模式的16种实体与16种关系和86种属性的知识图谱本体模型,即互联网重要基础设施本体模型。
25.所述步骤s102:获取所述互联网重要基础设施的各项数据,针对所述各项数据包含的结构化、半结构化数据,基于预设提取规则,进行知识抽取,包括:所述结构化数据为基于dig程序获取的网络服务层数据、基于爬虫获取的地理链路层和脆弱信息层数据。
26.所述半结构化数据为基于whois命令获取的用户角色层数据;本实施例中,基于dig 程序,对alexa排名前一百万域名的a、 mx、 ns 和 cname 记录进行查询获取,并基于正则表达式对每类数据进行知识抽取,形成网络服务层知识。
27.对于子域名节点,添加网站名称、标题、服务、防火墙属性;由于部分链接子域名并未添加其相关的其他信息,因此仅对该链接子域名进行标记,作为外链信息下的子域名节点;为了对web服务存在的脆弱性进行衡量和评估;采用命令获取方式,基于 linux 下 whois 命令向 whois 数据库发送查询请求,获取域名的 whois数据。whois数据存在thin和thick两种模式,其中thick模式中所有域名的whois数据格式相同;thin模式中,每个域名的whois数据没有统一的格式,针对thick模式的whois数据基于正则表达式编写知识提取规则进行数据处理;针对thin模式的数据,使用基于条件随机场构建的模型进行抽取。形成用户角色层知识。
28.基于爬虫获取每一个 ip 地址对应的 as 自治域和地理位置信息,形成地理链路层知识。基于爬虫获取了漏洞库的相关数据,包含了各种漏洞及其相关信息。并基于正则表达式构成知识抽取规则库,形成各类脆弱性相关实体与关系,并通过域名的操作系统、软件版本和开放端口等属性判断其可能存在的漏洞,进而形成网络服务层和脆弱信息层之间的关系。
29.本实施例中,知识抽取的规则如图4所示。
30.对于域名系统的数据,基于dig命令,对dns区域的a、mx、ns和cname记录进行查询获取,并基于正则表达式对每类数据进行知识抽取;对于web服务相关数据,目前互联网上已有较多网络空间资产相关数据库,本实施例中所述web服务相差数据来自zoomeye网络空间雷达系统,针对子域名的标题、服务、web应用防火墙、ip地址、外链信息进行获取;对于子域名节点,添加网站名称、标题、服务、防火墙属性;由于部分链接子域名并未添加其相关的其他信息,因此仅对该链接子域名进行标记,作为外链信息下的子域名节点;为了对web服务存在的脆弱性进行衡量和评估,本实施例中,针对获取的服务类型和版本信息生成域名可能存在的漏洞信息;本实施例中,域名whois数据库中包含与域名所有权相关的信息,包括域名创建时间、注册者信息等;基于域名所有权的信息能够将网络空间和社会空间的信息相互关联,是一种重要的网络空间实体社会信息的公开数据库。
31.对于whois数据,目前主要存在命令获取与第三方网站获取两种形式。由于第三方网站更新慢、收费高和非权威的特点,本实施例采用基于命令获取方式,基于linux下whois命令向whois数据库发送查询请求,获取whois数据,简单易用。
32.whois数据存在thin和thick两种模式,其中thick模式中所有域名的whois数据格
式相同,例如.com和.net域。thin模式中,每个域名的whois数据没有统一的格式,例如.info和.biz域。因此不能简单采用规则化的知识抽取方式。本实施例中,针对thick模式的whois数据基于正则表达式编写知识提取规则进行数据处理;针对thin模式的数据,使用基于条件随机场(conditional random field,crf)构建的模型进行抽取。
33.自治域(autonomous system, as)是自主决定内部网络协议的ip网络和路由器的集合,对于每个as,创建一个as节点,并添加一条ip地址到as自治域的originate_from关系。通过maxmind公司的geolite2数据库,查询每个ip地址对应的as自治域和地理位置信息,形成地理位置节点通过建立的位于关系和ip地址节点相连接,并加入知识图谱中。
34.对于ip地址的地理位置信息,为了避免出现多个ip地址和一个地域连接的情况,本实施例将地理位置按照geolite2数据库中唯一的经纬度作为一个节点;漏洞节点包含网络安全中已知的漏洞列表,同时将受漏洞影响的产品、与漏洞相关的弱点和漏洞的漏洞评分相关联。
35.网络安全与漏洞密切相关,本实施例使用爬虫获取了美国漏洞数据库发布的从2002年到2020年现有的漏洞数据,在知识图谱中加入漏洞节点,同时基于漏洞数据库的信息,将漏洞与脆弱产品、漏洞评分、脆弱点相关联。
36.通用漏洞评分系统(common vulnerability scoring system, cvss)提供了一个定量模型来描述漏洞的特征和影响。本实施例对所有漏洞的cvss评分按照标准2.0和标准3进行统一的整合,cvss作为漏洞的评分,是漏洞的一种属性,本实施例为了凸显不同漏洞重要程度的相关性,将漏洞的cvss基础评分和其对应的特征向量相结合作为一个漏洞评分节点,同时使用版本属性区分不同的cvss标准。
37.对于每个脆弱产品节点都表示了一个受影响的产品,包含了产品名称、版本、更新、版本、语言等信息。本实施例为了突出不同的供应商不同软件的漏洞情况。
38.用于软件安全的通用弱点枚举(common weakness enumeration, cwe)是一个软件安全弱点列表,包含检测、缓解和防御的相关信息,因此创建脆弱点节点与漏洞节点相关联。并基于常见攻击模式枚举和分类(common attack pattern enumeration and classification, capec)创建capec节点,与脆弱点节点型关联。
39.本实施例最终抽取的知识量达到千万级,在所抽取的380万节点和1090万的关系上实例化知识图谱。
40.本实施例对不同类型的数据进行针对化的收集获取,根据数据层次分别定义网络服务层、用户信息层、地理链路层和脆弱信息层。进而从获取的结构化、半结构化的数据中抽取到相应的知识。
41.所述步骤s103:使用neo4j图数据库存储所述知识图谱,具有全库导入和增量导入两种导入方式,根据导入场景的不同,使用相应的导入方式,形成互联网信息基础设施知识图谱,其中:互联网信息基础设施知识图谱采用nosql数据库neo4j进行存储,基于neo4j实现的数据模型具有灵活可变的特性。图形模式匹配查询可以用neo4j所具有的查询语言(cypher)表示。图数据通过节点表示实体,边表示实体间的关系,避免了对图数据遍历进行昂贵的连接操作或其他索引查找。在neo4j中,图形遍历速度只取决于实际遍历的查询结果的大小,与图形的总大小无关。
42.本实施例的数据导入分为两个部分,首次导入数据时,将数据以csv文件的形式使用官方提供的 neo4j
‑
import 工具进行批量导入,但是由于工具neo4j
‑
import 不支持增量导入且必须停止neo4j,为了方便数据的利用和后续维护,后续使用spring data neo4j(sdn)进行增量导入。
43.基于spring data neo4j能够通过配置来访问neo4j图形数据库,提供了neo4j客户端、neo4j template和neo4j repositories三种不同的抽象级别来访问存储。spring data neo4j提供了将带注释的实体类映射到neo4j图形数据库的特性。如图5所示的sdn架构,sdn可通过三种方式的驱动程序连接数据库,分别是bolt协议、http协议和使用官方的neo4j java嵌入式驱动程序。spring data neo4j在neo4
‑
ogm之上提供代码,帮助快速构建基于spring的neo4j应用程序。
44.本实施例通过构建互联网重要基础设施本体,设计数据获取和知识抽取框架,完成多方式知识导入方案设计,使用图数据库neo4j进行存储,最终构建形成互联网重要基础设施知识图谱。将安全相关的多源异构数据通过知识图谱形成统一的模型进行分析和利用,进而更为直观地展示现实网络安全态势。
45.本发明实施例进一步给出一种互联网重要基础设施知识图谱构建装置,如图6所示,所述装置包括:模型建立模块:配置为基于对所述互联网重要基础设施的要素分析,构建包含用户角色层、网络服务层、地理链路层和脆弱信息层的互联网重要基础设施本体模型;所述互联网重要基础设施是包含域名系统、 web 服务和网络地址进行互联网信息交换的重要服务集合;提取模块:配置为获取所述互联网重要基础设施的各项数据,针对所述各项数据包含的结构化、半结构化数据,基于预设提取规则,进行知识抽取;导入模块:配置为使用neo4j图数据库存储所述知识图谱,具有全库导入和增量导入两种导入方式,根据导入场景的不同,使用相应的导入方式,形成互联网信息基础设施知识图谱。
46.本发明实施例进一步给出一种互联网重要基础设施知识图谱构建系统,包括:处理器,用于执行多条指令;存储器,用于存储多条指令;其中,所述多条指令,用于由所述存储器存储,并由所述处理器加载并执行如前所述的互联网重要基础设施知识图谱构建方法。
47.本发明实施例进一步给出一种计算机可读存储介质,所述存储介质中存储有多条指令;所述多条指令,用于由处理器加载并执行如前所述的互联网重要基础设施知识图谱构建方法。
48.需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
49.在本发明所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如,多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示
或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
50.所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
51.另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。
52.上述以软件功能单元的形式实现的集成的单元,可以存储在一个计算机可读取存储介质中。上述软件功能单元存储在一个存储介质中,包括若干指令用以使得一台计算机装置(可以是个人计算机,实体机服务器,或者网络云服务器等,需安装windows或者windows server操作系统)执行本发明各个实施例所述方法的部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read
‑
only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
53.以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。