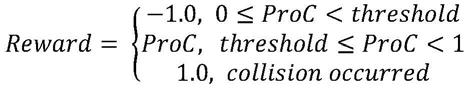
1.本发明涉及自动驾驶车辆碰撞测试方法,尤其涉及一种基于强化学习的自动驾驶车辆碰撞测试方法。
背景技术:
2.随着感知、通信、控制决策以及人工智能等相关技术的日趋成熟,自动驾驶系统已变得越来越成熟,但仍需投入大量的时间和成本对自动驾驶算法进行测试,以保证其安全性和可靠性。只有对自动驾驶算法进行全面、有效的测试和调试之后,才能更好地保障其安全性和可靠性,降低故障率,实现智慧交通。
3.自动驾驶车辆必须在复杂且动态的环境中安全运行,这种运行环境中往往存在多种不同的静态障碍物以及动态障碍物,一个好的自动驾驶算法能够有效避免与障碍物的碰撞并安全行驶到其预设的目的地。在对自动驾驶算法测试过程中,一个好的测试方法应该是能够生成更多这类复杂场景以验证自动驾驶算法在避免碰撞、安全驾驶等方面的可靠性和安全性。现有的自动驾驶测试技术往往是在预设的环境下,测试指定车辆安全完成相应驾驶任务的能力。这些测试的预设场景往往不能根据实际的驾驶任务而改变,这就导致此类场景无法更好地适应被测车辆的测试要求,即最大限度地将被测车辆至于危险状态,从而发现自动驾驶车辆的故障。
4.因此,如何制定和执行安全、高效且自适应驾驶场景的自动驾驶车辆碰撞测试策略,以生成更多复杂、有效的测试场景,实现对自动驾驶车辆碰撞的测试、校验并及时发现纠正算法的故障和可疑行为,以确保自动驾驶算法能更安全、高效地保障自动驾驶车辆的驾驶行为及乘客安全,是自动驾驶算法测试过程中亟须解决的问题。
技术实现要素:
5.发明目的:本发明的目的是提供一种实现对自动驾驶算法的测试、校验并及时发现纠正算法的故障和可疑行为的基于强化学习的自动驾驶算法测试方法。
6.技术方案:本发明的自动驾驶车辆碰撞测试方法,包括如下步骤:
7.(1)根据车辆运行状态和当前环境状态定义强化学习状态,获取车辆状态和环境状态信息,作为强化学习算法的输入;
8.(2)设计深度神经网络模型架构,预测下一个可选环境配置动作,神经网络的输入层节点数由输入状态的属性数量决定,输出层节点数由可选环境配置动作数量决定;隐含层对输入特征进行多层次的抽象;通过动作选择策略,决定下一个动作;
9.(3)根据碰撞概率计算当前环境配置动作的奖励值,高奖励值表示碰撞概率高,低奖励值表示碰撞概率低;
10.(4)一个环境配置动作执行完之后,强化学习中agent观测新的车辆状态和环境状态信息;
11.(5)一个自动驾驶测试循环结束后,将当前测试信息保存到日志文件中,建立测试
日志,日志文件按格式保存为测试用例规范;
12.(6)满足停止条件,则自动驾驶测试结束。
13.进一步,所述步骤(1)中,环境状态信息包括天气、道路结构、时间和交通规则,车辆状态信息包括自动驾驶车辆的位置、车速和驾驶方向。
14.进一步,所述步骤(2)中,采用探索
‑
利用规则设计动作选择策略,使用ε
‑
greedy算法作为动作选择策略,决定下一个动作是随机探索还是利用已有的深度神经网络模型生成,ε为随机选取的未知动作概率;当强化学习中agent观测到一个输入状态后,后续动作选择策略具体步骤如下:
15.(21)随机生成一个0到1之间的数字,如果其小于ε,则采取基于深度神经网络的预测的动作作为下一步的环境配置动作,转步骤23;否则转步骤22;
16.(22)如果随机生成的数字大于ε,则基于随机选择策略,从动作空间中选择一个环境配置动作执行;转步骤23;
17.(23)将所选动作id映射到对应的可执行rest api,通过http协议向仿真环境发送环境配置指令,对自动驾驶环境进行配置。
18.进一步,所述步骤(23)中,实现对自动驾驶环境进行配置的具体步骤如下:
19.(231)强化学习算法观测当前状态并基于动作选择策略生成一个环境配置动作id;
20.(232)将步骤231中环境配置动作id映射到预先定义的环境配置rest api上,选择相应的rest api进行调用,发送相应的http报文至仿真环境所在的服务器;
21.(233)仿真环境所在的服务器收到环境配置的http请求后,调用仿真环境内置的底层控制api,生成对应的环境配置;
22.(234)仿真环境中生成的环境配置仿真并配置当前测试环境,包括对自动驾驶车辆和车辆运行环境的仿真和配置;
23.(235)在一个环境配置动作执行结束后,将最新的车辆状态和环境状态信息经由rest api打包发送至强化学习算法端,用作下一个环境配置动作生成。
24.进一步,所述步骤(3)中,所述奖励值采用碰撞概率进行映射,计算方法如下:
[0025][0026]
其中,proc表示碰撞概率,threshold是强化学习奖励值计算阈值;
[0027]
并将碰撞概率划分为横向碰撞概率和纵向碰撞概率,碰撞概率的计算实现步骤如下:
[0028]
(31)计算自动驾驶车辆和周围物体的纵向安全距离,纵向安全距离是前后车辆之间保持安全驾驶应维持的最小距离,计算公式如下:
[0029][0030]
其中,v
f
、v
l
分别是前、后车辆的速度;α
f
、α
l
分别是前、后车辆的加速度;τ是自动驾驶车辆由正常行驶到采取刹车动作的反应时间;r
min
是前后车辆静止状态下应保持的最小距离;
[0031]
(32)计算自动驾驶车辆与周围物体的横向安全距离,横向安全距离表示的是相邻车辆之间保持安全驾驶应维持的最小距离,计算公式如下:
[0032][0033]
其中,v
ego
表示自动驾驶车辆的速度,α
ego
表示自动驾驶车辆的加速度,β表示自动驾驶车辆与障碍物所在车道之间的夹角;
[0034]
(33)计算当前自动驾驶车辆与障碍物之间的当前距离,计算公式如下:
[0035][0036]
其中,(x
e
,y
e
,z
e
)、(x
ob
,y
ob
,z
ob
)分别表示车辆和障碍物在三维空间的坐标;
[0037]
(34)当前距离与安全距离差值越大,则碰撞概率越高,所所以碰撞概率计算公式:
[0038][0039]
其中,sd表示横向安全距离或纵向安全距离,cd表示当前距离;可得横向碰撞概率和纵向碰撞概率。
[0040]
进一步,所述步骤(4)中,所述环境配置动作的执行包括环境配置日志的生成与保存和自动驾驶场景的生成与保存。
[0041]
进一步,所述步骤(5)中,所述测试日志文件的生成和应用的具体步骤为:
[0042]
(51)在测试过程中,测试脚本通过测试用例规范生成器生成测试日志,日志文件内容包括:强化学习四元组、碰撞概率以及由环境配置动作生成的测试场景;
[0043]
(52)当测试结束后,已生成的测试用例规范通过执行引擎进行单步执行,实现动态执行功能或者通过测试用例生成器生成对应的测试脚本,进而对自动驾驶系统进行静态测试;
[0044]
(53)根据用户所选功能模块,实现特定的测试功能。
[0045]
进一步,所述步骤(6)中,满足任意如下一个条件则测试循环停止:达到预定时间预算,车辆发生碰撞,到达预设驾驶终点。
[0046]
进一步,所述强化学习算法采用deep q
‑
learning算法,具体的实施步骤如下:
[0047]
s100,定义状态空间state space,其中状态空间state space的大小对应deep q
‑
learning中的神经网络输入层神经元个数;
[0048]
s101,基于request框架开发rest api,定义用于环境配置的动作;
[0049]
s102,定义动作空间action space,其中动作空间action space的大小对应deep q
‑
learning中的神经网络输出层神经元个数;
[0050]
s103,定义深度神经网络模型结构,包括输入层input layer、隐含层hidden layer、输出层output layer;对于隐含层中的神经元应用线性整流函数relu,用来加速网络参数优化的收敛速度;
[0051]
s104,基于动作选择策略选择下一步要执行的动作;
[0052]
s105,将所选动作映射到对应的rest api,执行相应的环境配置;
[0053]
s106,返回碰撞概率,计算对应的奖励值;
[0054]
s107,观测最新的车辆和环境状态,并将最新的车辆和环境状态作为下一次的强
化学习状态输入返回;
[0055]
s108,将当前测试过程记录到日志文件,更新测试用例规范。
[0056]
本发明与现有技术相比,其显著效果如下:1、通过特定策略对自动驾驶运行环境进行配置,实现对自动驾驶车辆碰撞的有效测试;2、通过传感器识别、融合算法对环境进行感知,从而生成导致最大碰撞概率的环境配置动作;3、按影响自动驾驶的环境因素对环境配置动作进行分类、构建环境配置api,满足用户对不同环境因素控制的需求;4、对强化学习动作生成频率进行调控,从而更加高效地测试自动驾驶车辆碰撞;5、通过自动生成环境配置日志,进而生成易于用户理解的基于环境配置的自动驾驶测试规范,从而实现对测试回放、故障定位以及故障分析等功能,能有效降低自动驾驶算法测试的成本,同时提升测试效率。
附图说明
[0057]
图1为本发明的总流程示意图;
[0058]
图2为本发明环境配置动作的执行流程图;
[0059]
图3为本发明测试过程所涉及的关键技术及技术工具示意图;
[0060]
图4为本发明测试日志生成和主要功能示意图;
[0061]
图5为本发明的停止条件流程示意图。
具体实施方式
[0062]
下面结合说明书附图和具体实施方式对本发明做进一步详细描述。
[0063]
本发明的自动驾驶车辆碰撞测试方法,包括步骤如下:
[0064]
(1)观测当前环境状态,当前环境状态包括描述环境状态和车辆状态的当前状态;
[0065]
(2)将步骤(1)获取的环境状态输入到强化学习模型中,基于当前环境状态和动作选择策略,生成一个环境参数配置动作;该环境配置动作通过发送http请求访问自动驾驶车辆的仿真环境,进而对车辆的运行环境进行配置;
[0066]
(3)当自动驾驶车辆在上述配置的环境中运行一段时间后,计算该环境配置动作所获得的奖励值;
[0067]
(4)观测新的环境动作作为强化学习模型的新的状态输入;
[0068]
(5)保存测试过程的环境配置日志并存储到日志文件以实现测试场景的回放。
[0069]
(6)停止条件判断,测试停止条件分为:达到预定时间预算、车辆发生碰撞、到达预设驾驶终点,三个条件满足任意一个测试循环便停止。
[0070]
在实施例中,从仿真环境中获取车辆状态、环境状态;使用部署在车辆上的传感器感知车辆以及环境信息,再借助传感器融合技术将不同种类、由不同传感器收集到的数据融合为可以被强化学习算法识别并作为输入的状态(state)。车辆状态和环境状态的获取所用到的传感器有主摄像头(main camera)、雷达(radar)、定位装置(gps)、惯性测量单元(imu),是准确感知车辆、环境状态的传感器。
[0071]
对于获取车辆状态、环境状态,环境配置动作的选择是基于探索
‑
利用策略,具体应用ε
‑
greedy算法选择当前是要进行探索(随机策略,random)还是利用已有的训练经验(深度神经网络,dnn)生成下一个动作。
[0072]
环境动作选择所用到的ε
‑
greedy是常用的贪心策略,用以权衡强化学习中探索和利用两个动作选择倾向;在强化学习中,利用指的是agent在已知的所有(状态
‑
动作)二元组分布中,本着最大化动作价值的原则选择最优的动作,也即,利用已知的动作进行选择;而探索指的是agent在已知的(状态
‑
动作)二元组之外,选择其他未知的动作,基于探索的选择常常是随机进行的。ε
‑
greedy算法正是用于权衡开发与探索二者之间的关系,在agent进行选择时,有一很小的正数ε(ε<1)的概率随机选择未知的一个动作,剩下1
‑
ε的概率选择已有动过中动作价值最大的动作。
[0073]
自动驾驶算法测试的奖励值计算是基于车辆与环境中的障碍物的碰撞概率进行,车辆与周围物体的碰撞概率分为横向碰撞概率和纵向碰撞概率,分别表示车辆在横向和纵向发生碰撞的概率大小,两种碰撞概率的计算是基于安全距离和当前距离进行的。
[0074]
当碰撞概率计算完成后,设计碰撞概率到强化学习奖励值的映射规则,在自动驾驶测试的背景下,用户更关注的是风险程度更高的事件,因此,高碰撞概率环境配置动作应该映射到更高的奖励值,基于此规则,设计强化学习的奖励值函数。
[0075]
当一个环境配置动作完成后,强化学习agent观测新的车辆状态、环境状态并作为下一个动作选择的依据,新观测的状态信息与首次观测的定义一致,只是参数值不同,表示在一个新配置后的环境下的状态。
[0076]
当完成一个自动驾驶测试循环(自动驾驶车辆从起点开到终点是一个自动驾驶测试循环,测试过程会重复多次由起点驾驶到终点的过程)后,将测试信息保存到日志文件中。这里的测试信息包括:强化学习算法的状态输入、基于此状态输入所选择的动作、奖励值、碰撞概率、环境配置动作完成后的新的观测状态。
[0077]
保存的测试日志信息采用的是测试用例规范格式,其中包含指定的测试设置、前置条件、后置条件、测试步骤和基本流程以及发现测试异常的异常处理流程。该日志通过在测试进行过程,动态地生成测试用例规范,达到记录测试日志的目的;另外,这样的测试用例规范还可以单独执行,实现对测试过程的回放,故障定位以及分析,形成高质量、可复用的测试日志,以保证测试的高效进行。
[0078]
在实施例中,按预算、成本等限制条件选择是否停止测试。
[0079]
如图5所示为测试停止条件的流程图,测试停止条件分为:达到预定时间预算、车辆发生碰撞、到达预设驾驶终点,三个条件满足任意一个测试循环便停止;其中,时间预算规定了测试需要在一定的时间成本内完成,车辆发生碰撞说明当前测试已经发现自动驾驶故障(碰撞),而到达预设终点指的是自动驾驶车辆已完成既定目标。
[0080]
如图1所示的总流程图,本发明的自动驾驶车辆碰撞测试方法的具体实现步骤如下:
[0081]
步骤1,基于车辆运行状态和当前环境状态定义强化学习状态表示,并通过预先定义的rest api从仿真环境中获取车辆状态、环境状态,作为强化学习算法的输入;例如,通过配备在车辆上的传感器观测到自动驾驶车辆正要驶过一个人行道,此时,将车辆的行驶状态以及经过人行道这一信息作为当前输入状态输入至强化学习模型中。
[0082]
一个强化学习的输入状态由以下属性组成:天气、道路结构、时间、交通规则等环境信息以及自动驾驶车辆的位置、车速、驾驶方向等车辆状态信息,如表1所示:
[0083]
表1用于定义强化学习输入状态的参数
[0084][0085]
步骤2,设计深度神经网络模型架构用于预测下一个可选环境配置动作,神经网络的输入层节点数由输入状态的属性数量决定,输出层节点数由可选环境配置动作数量决定;隐含层对输入特征进行多层次的抽象,最终的目的就是为了更好的线性划分不同类型的数据;基于探索
‑
利用规则设计动作选择策略,使用ε
‑
greedy算法作为动作选择策略,决定下一个动作是随机探索还是利用已有的深度神经网络模型生成;例如,基于步骤1所观测的状态,生成一个环境配置动作,该动作用于向自动驾驶车辆前方加入一个走人行道的行人横穿马路,执行此环境动作。
[0086]
基于ε
‑
greedy的动作选择策略可看作是一个条件判断,具体描述如下:
[0087][0088]
式(1)中,at为最终生成的动作,argmax
a
q(s,a)为强化学习算法在状态s下可获得奖励值最大的动作,random action是随机选取的一个动作,ε是ε
‑
greedy算法的超参数,作为选择由强化学习算法生成动作还是随机选择动作的阈值。
[0089]
用作动作生成策略的ε
‑
greedy算法伪代码如下:
[0090][0091]
对公式(1)进行详细说明,当强化学习中agent观测到一个输入状态后,后续动作选择策略具体步骤如下:
[0092]
步骤21,随机生成一个0到1之间的数字,如果其小于ε,则采取基于深度神经网络的预测的动作作为下一步的环境配置动作,转步骤23;否则转步骤22。
[0093]
基于深度神经网络的动作预测中,采用的神经网络架构为一个四层的全连接神经
网络,其中包括一个输入层(12个神经元)、两个隐含层(每层200个神经元)、最后一层为输出层(52个神经元),最后一层的神经元个数对应动作空间大小,即可选的动作数量,在本发明中,共定义了52个用于环境配置的rest api;另外,对于两个隐含层,对其中的网络神经元应用线性整流函数(rectified linear unit,relu),用来加速网络参数优化的收敛速度。
[0094]
步骤22,如果随机生成的数字大于ε,则基于随机选择策略,从动作空间中选择一个环境配置动作执行;转步骤23。
[0095]
步骤23,将所选动作id映射到对应的可执行rest api,通过http协议向仿真环境发送环境配置指令,对自动驾驶环境进行配置。环境配置动作的执行流程如图2所示,具体步骤如下:
[0096]
步骤231,强化学习算法观测当前状态并基于动作选择策略生成一个环境配置动作id;
[0097]
步骤232,将步骤231中环境配置动作id映射到预先定义的环境配置rest api上,选择相应的rest api进行调用,发送相应的http报文至仿真环境所在的服务器;
[0098]
步骤233,仿真环境所在的服务器收到环境配置的http请求后,调用仿真环境内置的底层控制api,生成对应的环境配置;
[0099]
步骤234,仿真环境中生成的环境配置仿真并配置当前测试环境,包括对自动驾驶车辆和车辆运行环境的仿真和配置;图2中的车辆的自动驾驶是由部署在仿真车辆上的自动驾驶算法平台实现的;
[0100]
步骤235,在一个环境配置动作执行结束后,将最新的车辆状态和环境状态信息经由rest api打包发送至强化学习算法端,用作下一个环境配置动作生成。
[0101]
步骤3,基于碰撞概率计算当前环境配置动作的奖励值,高奖励值表示在此次执行中,所选的环境配置动作可以使自动驾驶车辆达到更高的碰撞概率,有极大概率发生碰撞;低奖励值则意味着自动驾驶车辆在当前配置环境中,碰撞概率低,不能有效的发生碰撞;碰撞概率由横向碰撞概率和纵向碰撞概率加权得到;例如,在行人横穿马路过程中,如果车辆与行人发生碰撞,则在步骤1示例观测到的状态下执行步骤2示例中的动作的碰撞概率为1,基于此碰撞概率计算执行该动作相应的奖励值。
[0102]
其中,奖励值采用碰撞概率进行映射,并将碰撞概率进一步划分为横向碰撞概率和纵向碰撞概率,用二者的加权值计算奖励值,碰撞概率的计算是基于安全距离和当前距离进行的。碰撞概率的计算方法具体实现方式如下:
[0103]
步骤31,计算自动驾驶车辆和周围物体的纵向安全距离(safetydistance
longitudinal
),纵向安全距离表示的是前后车辆之间保持安全驾驶应维持的最小距离,其与车辆的驾驶速度、加速度等运动参数有关,具体计算公式如下:
[0104][0105]
式(2)中,v
f
、v
l
分别是前后车辆的速度;α
f
、α
l
分别是前后车辆的加速度;τ是自动驾驶车辆由正常行驶到采取刹车动作的反应时间;r
min
是前后车辆静止状态下应保持的最小距离。
[0106]
步骤32,计算自动驾驶车辆与周围物体的横向安全距离(safetydistance
lateral
),
横向安全距离表示的是相邻车辆之间保持安全驾驶应维持的最小距离,其于车辆的速度、加速度以及两车行驶方向的夹角有关,具体计算公式如下:
[0107][0108]
式(3)中,v
ego
表示自动驾驶车辆的速度,α
ego
表示自动驾驶车辆的加速度,β表示自动驾驶车辆与障碍物所在车道之间的夹角。
[0109]
步骤33,计算当前自动驾驶车辆与障碍物之间的当前距离,当前距离的计算是基于欧几里得公式,具体的计算公式如下:
[0110][0111]
式中,(x
e
,y
e
,z
e
),(x
ob
,y
ob
,z
ob
)分别表示车辆和障碍物在三维空间的位置(坐标)。
[0112]
步骤34,计算碰撞概率,当前距离与安全距离差值越大,碰撞概率越高,基于此,设计了碰撞概率计算方法:
[0113][0114]
式(5)中,sd、cd分别表示安全距离(横向安全距离或纵向安全距离)和当前距离;基于此,可得横向碰撞概率和纵向碰撞概率。
[0115]
其中,奖励值计算方法具体实现方式如下:
[0116][0117]
式(6)中,proc表示碰撞概率,threshold是强化学习奖励值计算阈值,在本实施例中阈值设置为0.2.
[0118]
在实施例中,可通过计算机编程语言(python)和深度学习框架(pytorch)来实现强化学习模型的训练和预测,本发明采用的强化学习算法是deep q
‑
learning算法,具体用到的关键技术及技术工具如图3所示,具体的实施步骤如下:
[0119]
s100,定义状态空间(state space);状态空间定义了deep q
‑
learning中的神经网络输入的内容,其中状态空间(state space)的大小对应deep q
‑
learning中的神经网络输入层神经元个数;
[0120]
s101,基于request框架开发rest api,定义用于环境配置的动作,包括:行人控制、车辆控制、天气以及时间的控制等,共计52个用于环境配置的rest api;
[0121]
s102,定义动作空间(action space);动作空间定义了deep q
‑
learning中的神经网络输出的内容,其中动作(action space)的大小对应deep q
‑
learning中的神经网络输出层神经元个数;
[0122]
s103,定义深度神经网络模型结构,包括:输入层(input layer)神经元12个;隐含层(hidden layer)共两层,每层神经元200个;输出层(output layer)神经元52个;对于两个隐含层中的神经元应用线性整流函数(rectified linear unit,relu),用来加速网络参数优化的收敛速度;
[0123]
s104,基于动作选择策略选择下一步要执行的动作;
[0124]
s105,将所选动作映射到对应的rest api,执行相应的环境配置;
[0125]
s106,返回碰撞概率,计算对应的奖励值;
[0126]
s107,观测最新的车辆、环境状态并将其作为下一次的强化学习状态输入返回;
[0127]
s108,将当前测试过程记录到日志文件,更新测试用例规范。
[0128]
步骤4,一个环境配置动作执行完之后,强化学习agent观测新的车辆和环境状态,最新状态与步骤1的定义方法相同,改变的是内部的参数。
[0129]
环境配置动作执行包括环境配置日志的生成与保存、自动驾驶场景的生成与保存;其中,环境配置日志包括:
[0130]
状态信息,用于描述自动驾驶车辆所处的某个环境状态及自身运行状态;
[0131]
环境配置动作,用于记录在一个特定状态下所执行的环境配置指令;
[0132]
车辆控制参数,用于描述在一个特定状态下车辆的控制参数,包括:刹车、油门、转向角等信息;
[0133]
路况信息,用于描述当前道路环境,包括:道路结构(直行、弯道、路口等)、指示灯、道路标识等信息;
[0134]
交通规则,用于描述当前所处环境下自动驾驶车辆需遵循的交通法规。
[0135]
自动驾驶场景包括:
[0136]
自动驾驶车辆属性,用于描述在某个场景下自动驾驶车辆的属性,包括:车速、当前操作等;
[0137]
环境属性,包括天气、时间、行人运动、车辆运动、障碍物等信息。
[0138]
步骤5,一个环境配置动作循环结束后,将当前测试信息保存到日志文件中,建立测试日志,用以回放测试过程、故障定位、排查以及故障分析等操作,日志文件按格式保存为测试用例规范;例如,在步骤1、2中的观测状态和配置动作执行完后,保存此观测状态和所执行的动作,以及执行该动作后观测状态的改变情况(包括车辆是否碰撞、碰撞概率等信息)。
[0139]
测试日志文件的生成和应用流程如图4所示,具体流程和功能为:
[0140]
步骤51,在测试过程中,测试脚本通过测试用例规范生成器生成测试日志,日志文件内容包括:强化学习四元组(强化学习算法的状态输入、基于此状态输入所选择的动作、奖励值、环境配置动作完成后的新的观测状态)、碰撞概率以及由环境配置动作生成的测试场景(场景由11个属性描述,详细信息见表2);
[0141]
步骤52,当测试结束后,已生成的测试用例规范可通过执行引擎进行单步执行,实现动态执行功能;或已生成的测试用例规范可通过测试用例生成器生成对应的测试脚本,进而对自动驾驶系统进行测试。
[0142]
这里的测试用例生成器区别于步骤51中的测试用例规范生成器,测试用例规范是一组基于自然语言、易于被开发者(人)理解的测试流程说明(不可执行),测试用例规范生成器用于在每次测试执行过程生成测试用例规范;测试用例是可被机器识别的基于某种特定语言编写的测试脚本(可执行),测试用例生成器可以将测试用例规范自动转化为测试用例,进而执行测试。
[0143]
步骤53,根据用户所选功能模块,可实现特定的测试功能,如:测试回放、测试用例生成、故障定位、单步执行。
[0144]
表2测试场景属性描述
[0145][0146]
步骤6,停止条件判断,在自动驾驶测试中,考虑到测试的成本和预算,需在一定条件下停止测试过程。本发明中,测试的停止条件有:达到预定时间预算、车辆发生碰撞、到达预设驾驶终点,三个条件满足任意一个则测试循环便停止。
[0147]
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于设备实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
[0148]
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合。为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。