1.本发明涉及民用航空智能空管技术领域,具体的说是一种基于深度强化学习的航空器冲突解脱方法。
背景技术:
2.2019年,我国机场全年旅客吞吐量超过13亿人次,完成135162.9万人次,比上年增长6.9%。根据国际航空运输协会iata的预测,2037年全球航空旅客数将达到82亿,其中包含了16亿中国乘客。为了缓解巨大的交通压力,各种空中交通流量管理辅助工具和技术应运而生,如机场协同决策管理系统、aman/dman系统、远程塔台、冲突探测与解脱技术等。其中实现高效的冲突探测与解脱技术是保障飞行安全的首要任务,特别是对于复杂、高密度的空域环境尤为重要。这项工作的进行也对维护飞行秩序、防止航空器碰撞、缓解空中交通压力、保障空中交通安全具有重大意义。
技术实现要素:
3.为了克服现有技术中模型简单、算法自适应差、效率低下等问题,本发明提供了一种基于深度强化学习的航空器冲突解脱方法,通过开源空管平台openscope构建冲突场景模型,结合gym接口实现航空器智能体的通信,采用深度强化学习算法,深度确定性策略梯度ddpg训练航空器智能体完成冲突解脱任务,对比现有的启发式算法,本发明考虑了环境的不确定性,如航空器冲突解脱过程中采取机动行为的误差,同时结合open ai的强化学习接口gym平台进行仿真环境的搭建,使得训练过程具有更加简单、高效等优点。
4.为了实现上述目的,本发明采用了以下技术方案来实现:一种基于深度强化学习的航空器冲突解脱方法,包括冲突环境生成模块、智能体通讯模块、ddpg强化学习算法模块;所述冲突环境生成模块包括环境建模子模块、冲突场景设计子模块,智能体通讯模块包括gym接口通讯子模块、openscope空管子模块,ddpg强化学习算法模块包括策略网络子模块actor、价值网络子模块critic、历史数据经验池子模块。
5.所述环境建模子模块用于对强化学习的环境进行建模,包括空域范围、飞行起点、目标点、飞行速度以及航班密度等参数的设定和管理。
6.所述冲突场景设计子模块可以为智能体航空器设计不同类型的预设冲突场景,包括迎面而来对头冲突、侧向的交叉冲突,其中对头冲突实际上是交叉冲突的一种特殊情况,即当航向夹角的大小为平角时的对头冲突,冲突场景设计子模块会根据不同大小的航向夹角设计多种不同的交叉冲突,航向夹角指两架航空器的航向角的夹角,航向角指航空器载体纵轴在水平面的投影与地理子午线之间的夹角大小,规定以地理北极为起点,偏东方向为正,取值范围在正负180度之间。
7.所述gym接口通讯子模块可以完成航空器智能体与其他航空器的通讯,包括位置信息、航向信息,通过此模块也可以完成与ddpg强化学习算法模块的通讯,即gym接口通讯子模块可以从“上帝视角”将所有航空器的状态信息发送给算法模块,从而更好地训练智能
体学习冲突规避动作。
8.所述openscope空管子模块提供人机交互界面以及控制接口,同时还实现了对航空器智能体的飞行控制,如航向、速度、高度等状态的控制。空管环境主要为进近管制空域,每架航空器均受限于所属机型的飞行性能。智能体通过不断地与环境交互,获得环境的反馈值,通过ddpg算法进行解脱策略的学习。
9.策略网络子模块属于ddpg算法的一部分,主要完成智能体从状态到动作的映射的网络学习过程,常被称为策略网络,具体来说网络的输出为当前网络输入的状态的最佳动作,另外为了使得学习过程更加平稳,网络权重更稳定地迭代更新,引入目标策略网络target,原始策略网络被称为在线策略网络online,设定固定更新次数,按照此次数将online网络的权重拷贝给target网络。
10.针对价值网络子模块,主要对策略网络生成的动作进行评估,学习从状态、动作到q值的映射,随后策略网络会根据q值学习解脱策略,与策略网络子模块一致,也引入了target评估网络和online评估网络。
11.历史数据经验池子模块主要完成存储和抽样两个功能,存储是指存储智能体的历史轨迹,即状态、动作、奖励、下一状态,根据需要可以再加一个是否完成当前任务的标志量,而抽样指的是智能体在学习的过程中按照一定的批次大小输入历史轨迹进行学习。
12.智能体在t时刻通过最大化累计奖励r
t
来学习最优的解脱策略,用公式表述如下:
[0013][0014]
其中s
i
与a
i
分别表示状态和动作,r(s
i
,a
i
)为单次的奖励值,γ为折扣因子,表示未来奖励的重要程度。在策略网络模块中a
i
为确定性的行为策略,t时刻的行为a
t
通过函数直接获得确定的值,即:
[0015]
a
t
=μ(s
t
∣θ
μ
)
[0016]
其中μ表示状态到动作的分布函数,s
t
表示t时刻的状态,θ
μ
为策略网络的权重参数。求解模型采用贝尔曼方程进行迭代优化最终求得最优策略,方程表示如下:
[0017]
q
μ
(s
t
,a
t
)=e[r(s
t
,a
t
) γq
μ
(s
t 1
,μ(s
t 1
))]
[0018]
其中q
μ
(s
t
,a
t
)表示策略网络的动作价值函数,即状态s
t
下采取动作a
t
的优劣评估,r(s
t
,a
t
)表示t时刻的即时奖励。价值网络进一步通过计算t时刻每一个状态s
t
下的q值的期望来评估整体的策略,用公式表示如下:
[0019][0020]
其中,ρ
β
为状态s的分布函数,表示某一时刻智能体所处的状态的概率大小,策略的评估使用函数j
β
来表示,价值网络的参数优化通过梯度更新的方式进行,其中θ
q
和θ
μ
为价值网络的参数,n为智能体实践产生的样本数量,更新方式如下:
[0021][0022]
相比现有技术,本发明具有以下有益效果:
[0023]
1、深度强化学习技术结合了深度学习的特征拟合能力以及强化学习的自主决策能力,能够很好地解决现有模型的解脱方式单一固化、效率低下等问题。
[0024]
2、深度强化学习技术不仅考虑了水平方向上的冲突,还考虑了垂直方向上的冲突,以及航向和速度的变化调整,设计了符合实际的各类奖励值且解脱策略仅拓展到了多类冲突场景。
[0025]
3、深度强化学习技术不依赖精确的航空器动力学模型,采用多维度状态和动作的冲突解脱方法更符合空中交通管制员的实际指挥习惯且能够有效应对外界条件和航空器运行状态的不确定性。
附图说明
[0026]
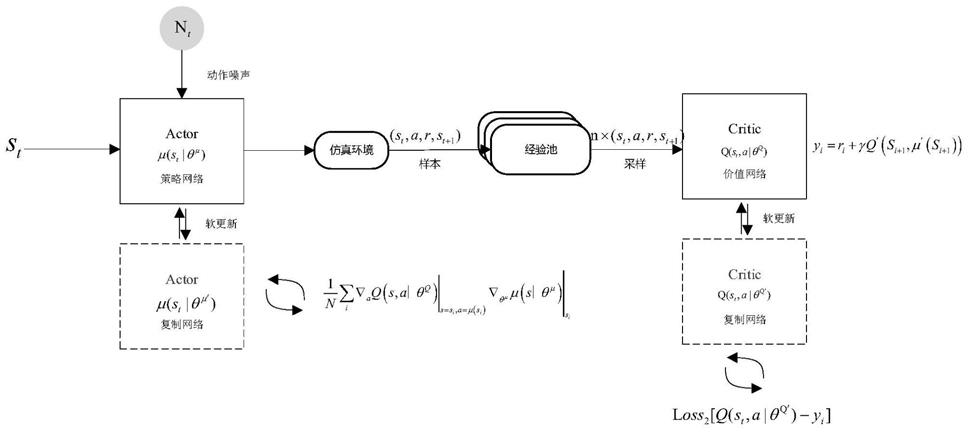
图1是本发明的算法原理示意图;
[0027]
图2是本发明中各子模块的系统工作原理图。
具体实施方式
[0028]
为了使本发明实现的技术原理得以更好地理解,下面结合附图对本发明作进一步阐述。
[0029]
如图1所示,基于ddpg算法架构的航空器冲突解脱方法,其中包括四个子模块,具体包含:策略网络子模块、价值网络子模块、历史数据经验池子模块和仿真环境模块。
[0030]
所述策略网络子模块包括在线策略网络以及复制策略网络,在线策略网络用于实时与环境交互学习,即智能体将当前状态作为输入,策略网络输出对应的动作。复制策略网络主要用于稳定训练过程,即通过定期固定网络参数,使策略网络的参数得以平稳更新。策略网络通过计算策略梯度更新网络的参数,其中包括策略网络参数的梯度和价值网络参数的梯度;
[0031]
所述价值网络子模块包括在线价值网络和复制价值网络,在线价值网络用于评估当前策略的优劣,复制价值网络用于稳定价值网络参数的更新过程,通过定期固定网络参数实现。价值网络的输入为当前状态和策略网络输出的动作构成的二元组,输出为对应的状态值函数v值或动作值函数q值,网络将贝尔曼方程计算得到目标值y
i
与价值网络的输出值的差异作为损失函数,通过梯度值优化网络参数;
[0032]
所述历史数据经验池子模块主要用于样本存储和更新样本库,其中一个样本为一个四元组,具体包含智能体的状态、智能体的动作、智能体与环境交互产生的奖励值、智能体的下一个状态。经验池的容量大小相对固定,设定样本容量上限值,随着智能体与环境不断地交互,样本数量持续增加,当样本数超过这个阈值时,自动剔除距离当前时间最久的样本,实现样本库的更新。
[0033]
所述仿真环境模块主要指构建的冲突场景。智能体学习的环境通过gym接口来实现,管制环境通过开源空管平台openscope来搭建。首先,对机场进近区的空域进行地图绘制,通过坐标转换对机场固定点的经、纬度坐标进行平面坐标的投影。其次,构建gym智能体的内部结构,包括状态集合、动作空间以及状态更新等部件的实现。最后,将构建的环境在gym中进行注册,并定义冲突库。
[0034]
如图2所示,本发明的系统工作原理图,其中包括冲突环境生成模块、智能体通讯模块、ddpg强化学习算法模块;所述冲突环境生成模块包括环境建模子模块、冲突场景设计子模块,智能体通讯模块包括gym接口通讯子模块、openscope空管子模块,ddpg强化学习算
法模块包括策略网络子模块actor、价值网络子模块critic、历史数据经验池子模块。其中冲突环境生成模块通过智能体通讯模块与算法模块联通。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。