dna表观修饰的建库方法、测序方法及其建库试剂盒
技术领域
1.本发明属于基因测序领域,具体涉及一种dna表观修饰的建库方法、测序方法及其建库试剂盒。
背景技术:
2.表观遗传修饰是指在不改变dna序列本身的情况下,引起可遗传表型的遗传物质的变化。dna甲基化和羟甲基化作为一个重要的表观遗传学标记,在基因表达调控、发育和疾病中起着重要作用。尽管甲基化可以在任何碱基的多个位置发生,但5-甲基胞嘧啶(5mc)是脊椎动物中最丰富的甲基化dna碱基,胞嘧啶甲基化通常发生在富含cpg二核苷酸dna序列上。甲基化胞嘧啶突变为胸腺嘧啶的趋势导致基因组中cpg的频率远低于预期,cg二核苷酸通常聚集在cpg密集区,称为cpg岛(cgi)。cgi通常与启动子相关,cgi启动子的甲基化可以顺式调节相关基因的转录。dna甲基化已被证明参与各种细胞过程,包括x染色体失活、基因组印记和转座因子沉默。
3.作为如此重要的修饰,dna甲基化异常与包括癌症在内的许多疾病有关,因此dna甲基化是热点研究领域,同时也使得探索这种表观遗传标记的技术方法不断增加。然而现阶段检测dna甲基化的方法是基于获取全基因的信息后再分析表观遗传修饰,而具有甲基化的dna只占全基因组不到10%,这就造成了实验流程繁琐、建库成本浪费以及需要巨大测序量等问题。
技术实现要素:
4.本发明的目的在于提供一种dna表观修饰的建库方法、测序及其建库试剂盒,旨在提供可以只获取表观修饰dna信息的方式,节约表观修饰dna的检测成本。
5.为达到上述目的,本发明提供一种dna表观修饰的建库方法,包括以下步骤:提供待测dna;将所述待测dna与多肽接触,得到被定位dna,所述多肽可与dna表观修饰位点特异性结合,所述dna表观修饰位点包括甲基化位点和/或羟甲基化位点;采用转座酶与所述被定位dna进行转座反应,得到片段化的表观修饰dna体系,所述转座酶可靶向所述多肽并切割与所述多肽结合的dna;将所述片段化的表观修饰dna体系与多个标签体进行连接反应,得到标记表观修饰dna体系,多个所述标签体可与多个dna片段一一对应连接,所述多个dna片段经过所述转座酶的切割得到;将所述标记表观修饰dna体系采用扩增引物进行扩增反应,得到所述dna表观修饰的文库,所述扩增引物可特异性地扩增连接所述标签体的所述dna片段并引入文库标签。
6.可选地,所述提供待测dna包括:提供集成有多个操作区域的操作体,多个操作区域间隔设置;将多个所述单细胞样品一一对应地沉积在多个所述操作区域中,以此实现细胞隔
离,具体地,在一些实施例中,所述操作体为集成有多个细胞孔的微孔芯片。细胞孔直径在10-200 mm之间,优选的在20-50 mm之间,便于后续放入合适尺寸的具有独特细胞标签的微珠。该技术将细胞自然沉降至细胞数量十倍以上的微孔阵列中保证单细胞入孔率。
7.可选地,所述提供待测dna包括:将多个所述单细胞样品制备成多个油包水体系,各油包水体系含有一个单细胞样品。
8.可选地,所述多肽选自5-甲基胞嘧啶单克隆抗体、mbd2b蛋白、5-羟甲基胞嘧啶单克隆抗体中的一种;和/或,所述转座酶为protein a/g融合的转座酶;和/或,多个所述标签体包括相同的第一接头结合标签和接头1’,所述转座酶含有第一接头和第二接头,所述第一接头可与所述接头1’连接,多个所述标签体包括相同的第一接头结合标签和接头1’,所述转座酶含有第一接头和第二接头,所述第一接头可与所述接头1’连接,所述扩增引物包括第一引物和第二引物,其中,所述第一引物包含与所述第一接头结合标签相同的序列,所述第二引物包含与结合序列以及文库标签,所述结合序列与所述第二接头的序列部分或全部相同。
9.可选地,所述提供待测dna的步骤包括:提供待检测细胞样品,所述待检测细胞样品包括待检测全细胞和/或待检测细胞核;将所述待检测细胞样品进行固定和透化,得到透化细胞;采用分离试剂去除所述透化细胞中dna的核小体,得到所述待测dna。
10.可选地,所述待检测细胞样品由多个隔离的单细胞样品共同构成,所述单细胞样品为单细胞或单细胞核。
11.可选地,所述待测dna由多个单细胞的dna共同构成,其中:各所述标签体还包括细胞标签,在多个所述标签体中,与来自同一所述单细胞的dna片段连接的多个所述标签体的所述细胞标签相同,与来自不同所述单细胞的dna片段连接的多个所述标签体的所述细胞标签不同。
12.可选地,所述待测dna由多个单细胞的dna共同构成,其中:所述转座酶含有接头1;所述转座酶与所述被定位dna进行转座反应,得到由多个单细胞片段化的表观修饰dna体系共同构成的所述片段化的表观修饰dna体系,且多个所述单细胞片段化的表观修饰dna体系与多个所述单细胞一一对应;所述将所述片段化的表观修饰dna体系与多个标签体进行连接反应,得到标记表观修饰dna体系的步骤包括:提供多个细胞标签载体,各所述细胞标签载体包括载体本体以及多条标签体,各所述标签体含有细胞标签和与所述细胞标签一端连接的接头1’,所述载体本体与所述细胞标签的另一端连接且与所述细胞标签可条件性断裂,所述接头1’可与所述接头1连接,同一所述载体本体连接的所述标签体的所述细胞标签相同,不同所述载体本体连接的所述标签体的所述细胞标签不同;将多个所述细胞标签载体与多个所述单细胞片段化的表观修饰dna体系一一对应
混合,进行连接反应,所述连接反应可使所述接头1’可与所述接头1连接;施加条件,所述条件可使所述细胞标签与所述载体本体条件性断裂,得到所述标记表观修饰dna体系。
13.可选地,所述将所述标记表观修饰dna体系采用扩增引物进行扩增反应,得到所述dna表观修饰的文库的步骤包括:将所述标记表观修饰dna体系进行延伸反应;进行转化操作,所述转化操作可将进行所述延伸反应后的片段中的5-甲基化胞嘧啶和/或5-羟甲基化胞嘧啶转化成二氢尿嘧啶;采用扩增引物进行index pcr,得到所述表观修饰dna文库。
14.可选地,所述转化操作的步骤包括:加入氧化剂进行反应,所述氧化剂可使5-甲基化胞嘧啶和/或5-羟甲基化胞嘧啶氧化为羧基胞嘧啶;加入还原剂进行反应,所述还原剂可将羧基胞嘧啶碱基还原为二氢尿嘧啶。
15.此外,本发明提供一种用于dna表观修饰的建库的试剂盒,所述用于dna表观修饰的建库的试剂盒包括:多肽,所述多肽用于与dna中的甲基化位点和/或羟甲基化位点特异性结合;转座酶,所述转座酶可靶向所述多肽后对dna进行片段化;标记体系,所述标记体系包括多个标签体,所述多个标签体可与多个dna片段一一对应连接,多个所述dna片段经过所述转座酶的切割得到;扩增体系,所述扩增引物可特异性地扩增连接所述标签体的所述dna片段。
16.此外,本发明提供一种dna表观修饰的测序方法,包括以下步骤:采用上述dna表观修饰的建库方法构建表观修饰dna文库;对所述表观修饰dna文库进行测序。
17.本发明提供的建库方法操作流程简单,构建出的数据库测序快速,极大的提高了检测效率。通过特异性切割,完成表观修饰的信息筛选,之后通过特异性扩增,以此实现对筛选出的表观修饰信息的提取,并对提取的信息进行建库,减少构建文库中的非表观修饰信息,以此降低后续检测的数据量,且能简化操作步骤。
附图说明
18.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。
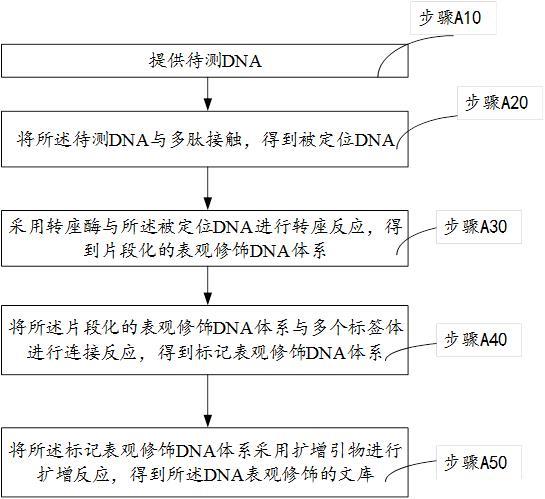
19.图1为本发明dna表观修饰的建库方法的一实施方式;图2为本发明特异性切割反应原理示意图;图3为本发明细胞标签载体示意图;图4为细胞标签连接原理示意图;图5为文库构建及产物示意图;图6为构建成功的单细胞甲基化文库质控图;图7为构建成功的单细胞羟甲基化文库质控图。
具体实施方式
20.为使本发明实施例的目的、技术方案和优点更加清楚,下面将对本发明实施例中的技术方案进行清楚、完整地描述。需要说明的是,实施例中未注明具体条件者,按照常规条件或制造商建议的条件进行。所用试剂或仪器未注明生产厂商者,均为可以通过市售购买获得的常规产品。另外,全文中出现的“和/或”的含义,包括三个并列的方案,以“a和/或b”为例,包括a方案、或b方案、或a和b同时满足的方案。此外,各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
21.鉴于现有的表观修饰dna检测方式是基于全基因信息获取后再对其进行检测,加大了检测成本,此外,本发明提供一种dna表观修饰的建库方法,参见图1,包括以下步骤:步骤a10:提供待测dna;步骤a20:将所述待测dna与多肽接触,得到被定位dna,所述多肽可与dna表观修饰位点特异性结合,所述dna表观修饰位点包括甲基化位点和/或羟甲基化位点;步骤a30:采用转座酶与所述被定位dna进行转座反应,得到片段化的表观修饰dna体系,所述转座酶可靶向所述多肽并切割与所述多肽结合的dna;步骤a40:将所述片段化的表观修饰dna体系与多个标签体进行连接反应,得到标记表观修饰dna体系,多个所述标签体可与多个dna片段一一对应连接,所述多个dna片段经过所述转座酶的切割得到;步骤a50:将所述标记表观修饰dna体系采用扩增引物进行扩增反应,得到所述dna表观修饰的文库,所述扩增引物可特异性地扩增连接所述标签体的所述dna片段并引入文库标签。
22.本发明提供的建库方法操作流程简单,构建出的数据库测序快速,极大的提高了检测效率。通过转座酶完成特异性切割,完成表观修饰的信息筛选,之后通过特异性扩增,以此实现对筛选出的表观修饰信息的提取,并对提取的信息进行建库,减少构建文库中的非表观修饰信息,以此降低后续检测的数据量,且能简化操作步骤。
23.在一些实施例中,所述步骤a10包括:步骤a101:提供待检测细胞样品,所述待检测细胞样品包括待检测全细胞和/或待检测细胞核;步骤a102:将所述待检测细胞样品进行固定和透化,得到透化细胞;步骤a103:采用分离试剂去除所述透化细胞中dna的核小体,得到所述待测dna。
24.通过分离核小体与dna,可以使碱基甲基化位点充分暴露,使其后续与多肽顺利结合。且需要说明的是,在可以去除核小体的前提下,其分离试剂不受限制,可以具体为酸类试剂如盐酸、乙酸等或者能溶解蛋白的去垢剂如十二烷基磺酸钠(sds)、甘胆酸钠、季胺类化合物和3,5-二碘水杨酸锂等。
25.在一些实施例中,所述待检测细胞样品由多个隔离的单细胞样品共同构成,所述单细胞样品包括单细胞或单细胞核。通过提供隔离的单细胞样品,可以完成高通量的单细胞层面检测,且不会产生不同细胞的遗传信息污染。
26.进一步的,在步骤a101包括:步骤a1011:提供集成有多个操作区域的操作体,多个操作区域间隔设置;步骤a1012:将多个所述单细胞样品一一对应地沉积在多个所述操作区域中。以此实现细胞隔离,具体地,在一些实施例中,所述操作体为集成有多个细胞孔的微孔芯片。细胞孔直径在10-200 mm之间,优选的在20-50 mm之间,便于后续放入合适尺寸的具有独特细胞标签的微珠。该技术将细胞自然沉降至细胞数量十倍以上的微孔阵列中保证单细胞入孔率。
27.或,步骤a101包括:将多个所述单细胞样品制备成多个油包水体系,各油包水体系含有一个单细胞样品。进一步地,基于油包水的液滴区隔技术可现有的由10x genomics、drop-seq平台或indrop平台实现。
28.在一些实施例中,步骤a102包括:步骤a1021:采用固定液将所述待检测细胞样品进行固定;步骤a1022:将固定后的所述待检测细胞样品采用透膜试剂进行透化。
29.通过细胞固定可以便于后序操作,而透化则可以使后续试剂进入细胞与其中的dna进行反应。
30.需要说明的是,步骤a1022中,所述透膜试剂不做具体限定,在一些实施例中可以是tritonx-100、tween20、np40(乙基苯基聚乙二醇)等表面活性剂或者包括甲醇和乙醇在内的醇类试剂以及它们之间的混合物;步骤a1021中,所述固定液包括10%(v/v)甲醛固定液、4%(v/v)多聚甲醛固定液、3%(v/v)乙二醛固定液、醇类固定液、afa(抗纤维蛋白抗体)中的至少一种。
31.在步骤a20中,需要说明的是,本发明中的多肽,以特异性结合为原则,根据具体的位点进行选择。在一些实施例中,所述多肽选自5-甲基胞嘧啶单克隆抗体、mbd2b蛋白或5-羟甲基胞嘧啶单克隆抗体中的一种;可以理解的是,所述转座酶根据与多肽特异性结合的原则进行挑选,在一些实施例中,所述多肽为5-甲基胞嘧啶单克隆抗体或5-羟甲基胞嘧啶单克隆抗体时,所述转座酶为protein a/g融合的转座酶,具体为protein a/g融合的tn5转座酶。
32.可以理解的是,上述多肽有些能够识别双链dna状态下的表观修饰碱基,但有些多肽只能识别单链dna状态的表观修饰碱基,因此在结合多肽前需要对固定细胞或细胞核进行高温处理以变性dna并使修饰碱基进一步暴露,对此不再一一说明。
33.考虑到protein a/g-转座酶与非抗体fc段的非特异结合会打断非表观修饰碱基附近的dna,此时,所述步骤a30包括:步骤a301:往含有所述被定位dna的样品中加入所述转座酶;步骤a302:将所述转座酶与所述多肽结合后,去除多余的转座酶;步骤a303:激活与所述多肽结合的转座酶,使所述被定位dna片段化,得到片段化的表观修饰dna体系。以此,对转座酶进行条件性地激活后,避免非特异性的切割。进一步地,在可以激活的情况下,可以选择对应的反应缓冲液进行激活,如二价阳性镁离子等。
34.参见图2,本发明采用转座酶结构含有两个19 bp大小的末端核心序列3和4。
35.在一些实施例中,所述转座酶含有分别与两个所述末端核心序列连接的第一接头2和第二接头5,接头可以直接引入或间接接入特异性模板,便于后续的特异性扩增,提取筛选出的表观修饰片段。具体地,直接引入可以在接头中设计特异的引物结合序列,在扩增阶段,采取与之配合的扩增引物进行扩增;间接引物则是通过接头接入特异的引物结合序列后,在扩增阶段,采取与之配合的扩增引物进行扩增。
36.在一些实施例中,第一接头和第二接头中分别包含全部或部分read 1 sequencing primer和read 2 sequencing primer序列。
37.所述转座酶含有第一接头2和第二接头5,在所述转座酶进行特异性的切割后,得到的多个所述片段化的dna,便含有所述第一接头2和第二接头5;多个所述标签体包括相同的第一接头结合标签和接头1’,所述第一接头的远离末端核心序列的端部含有接头1,接头1可与所述接头1’连接,而靠近所述末端核心序列的端部包括read 1 sequencing primer;所述第二接头则设计为read 2 sequencing primer。
38.所述扩增引物包括第一引物和第二引物,其中,所述第一引物包含与所述第一接头结合标签相同的序列,所述第二引物包含结合序列以及文库标签,所述结合序列与所述第二接头相同。
39.进一步,所述第一接头结合标签设计成测序平台可识别的p5,所述第二引物还包括第二测序接头,且所述文库标签设于所述第二测序接头与所述结合序列之间,所述第二测序接头设计成测序平台可识别的p7。
40.进一步地,所述第一接头2被磷酸化修饰,该磷酸化修饰可用于与特定序列的连接,如标签序列。
41.当所述待测dna来自多个单细胞时,各所述标签体还包括细胞标签;在多个所述标签体中,与来自同一所述单细胞的dna片段连接的多个所述标签体的所述细胞标签相同,与来自不同所述单细胞的dna片段多个所述标签体的所述细胞标签不同。当所述待测dna来自多个单细胞中,可以通过接入不同的细胞标签完成对于细胞信息的标记,以此,完成单细胞层面高通量的检测。
42.与此同时,所述转座酶与所述被定位dna进行转座反应,得到由多个单细胞片段化的表观修饰dna体系共同构成的所述片段化的表观修饰dna体系,且多个单细胞片段化的表观修饰dna体系与多个单细胞dna一一对应;而对应地,在一些实施例中,步骤a40包括:步骤a401:参见图3,提供多个细胞标签载体,各所述细胞标签载体包括载体本体7以及多条标签体8,各标签体含有所述细胞标签801和与所述细胞标签一端连接的接头1’802,所述载体本体与所述细胞标签的另一端连接且与所述细胞标签可条件性断裂,所述接头1’可与所述接头1连接,同一所述载体本体1连接的所述细胞标签相同,不同所述载体本体连接的所述细胞标签不同;步骤a402:将多个所述细胞标签载体与多个所述单细胞片段化的表观修饰dna体系一一对应混合,进行连接反应,所述连接反应可使所述接头1’可与所述接头1连接;步骤a403:施加条件,所述条件可使所述细胞标签与所述载体本体条件性断裂,得到所述标记表观修饰dna体系,其反应原理参加图4;通过采用上述方法,可以高效的引入细胞标签,再经过特异性扩增后,以此,构建出高通量单细胞文库。
43.进一步,在步骤a401中,参见图3,所述功能序列还包括第一接头结合标签803和断
点804,且所述断点804、所述第一接头结合标签、所述细胞标签和所述接头1’顺次连接,所述载体本体与所述断点连接于远离所述第一接头结合标签的一端。其中,断点为pclinker或被还原剂断裂的s-s键。其中,引物结合序列可以与后续的扩增引物配合,进行特异性扩增。
44.在本发明中,单个载体本体上标记10^
5-10^
10
个有相同细胞标签的标签体,不同的载体本体标记有不同种类的细胞标签核酸序列,细胞标签序列可以有100-100000000种,优选的细胞标签种类有100000-10000000种,对于载体本体的材质不做具体限定,可以为柔性材质也可以为硬性材质,例如ps磁珠或者水凝胶微珠。
45.若使用的所述转座酶接头1未被磷酸修饰时,所述步骤a402中,加入磷酸激酶后,进行连接反应;需要说明的是,磷酸激酶的种类不受限制,如t4 pnk。
46.参见图5,步骤a50包括:步骤a501:将所述标记表观修饰dna体系进行延伸反应;步骤a502:进行转化操作,所述转化操作可将进行所述延伸后的片段中的5-甲基化胞嘧啶和/或5-羟甲基化胞嘧啶转化成二氢尿嘧啶;步骤a503:采用扩增引物进行index pcr,得到所述表观修饰dna文库。通过延伸将转座子反应的缺口补平,将其5-甲基化胞嘧啶和/或5-羟甲基化胞嘧啶转化成二氢尿嘧啶,在后续的pcr中,二氢尿嘧啶被识别为t,通过测序结合参考基因组序列比对,就可以得到相应的甲基化信息,而引入的文库标签,则可以对样品进行区分。
47.在一些实施例中,所述步骤a501包括:将所述标记表观修饰dna体系纯化后使用聚合酶延伸。
48.具体地,在采用微孔芯片进行隔离时,在微孔芯片中直接裂解细胞溶解蛋白后纯化游离的dna片段;而在采用油包水的形式进行隔离时,可以使用破乳剂打破油包水液滴后在高盐条件下使用磁珠吸附。
49.在一些实施例中,所述聚合酶为具有链替代活性的dna聚合酶或具有5
’→3’
外切酶活性的聚合酶,或者是普通dna聚合酶在特定温度下延伸。在一些实施例中,所述步骤a502包括:加入氧化剂进行反应,将所有5-甲基化胞嘧啶(5mc)和/或5-羟甲基化胞嘧啶(5hmc)氧化为羧基胞嘧啶(5cac);加入还原剂进行反应,所述还原剂可将羧基胞嘧啶碱基(5cac)还原为二氢尿嘧啶(dhu),而基因组dna片段上非5mc和/或5hmc碱基不受影响。在可还原的前提下,其还原剂种类不限,具体地可为吡啶硼烷。
50.在一些实施例中,以甲基化修饰胞嘧啶碱基为例,使用tet酶将所有5-甲基化胞嘧啶(5mc)氧化为羧基胞嘧啶(5cac)。
51.使用上述建库方法,所得产物的结构为p5 (测序接头)9、细胞标签801、含read 1 sequencing primer 序列的第一接头2、待测序的dna片段(3和4之间)、含read 2 sequencing primer 序列的第二接头5、sample index序列(文库标签)11以及p7 (测序接头)10。由于是靶向后切割,因此待测序的dna片段均为表观修饰碱基附近的dna片段,且经过转化操作后所有甲基化/羟甲基化胞嘧啶都已转变为碱基t。
52.此外,本发明还提供一种用于dna表观修饰的建库的试剂盒,所述用于dna表观修
饰的建库的试剂盒包括:多肽,所述多肽用于与dna中的甲基化位点或羟甲基化位点特异性结合;转座酶,所述转座酶可靶向所述多肽后对dna进行片段化;标记体系,所述标记体系包括多个标签体,所述多个标签体可与多个dna片段一一对应连接,多个所述dna片段经过所述转座酶的切割得到;扩增体系,所述扩增引物可特异性地扩增连接所述标签体的所述dna片段并引入文库标签。
53.在一些实施例中,所述多肽选自5-甲基胞嘧啶单克隆抗体、mbd2b蛋白或5-羟甲基胞嘧啶单克隆抗体中的一种。
54.可以理解的是,所述转座酶根据与多肽特异性结合的原则进行挑选,参见图2,在一些实施例中,所述转座酶为protein a/g融合的转座酶,具体为protein a/g融合的tn5转座酶和/或为protein a/g融合的mua转座酶。
55.可以理解的是,参见图2,本发明采用转座酶含有两个19 bp大小的末端核心序列3和4,同时含有protein a/g 1用于结合与表观修饰位点6 结合的多肽。
56.在一些实施例中,所述转座酶含有分别与两个所述末端核心序列连接的第一接头2和第二接头5,第一接头和第二接头中分别包含read 1 sequencing primer 和read 2 sequencing primer 序列。进一步地,接头可以直接引入或间接接入特异性模板,便于后续的特异性扩增,提取筛选出的表观修饰片段。具体地,直接引入可以在接头中设计特异的引物结合序列,在扩增阶段,采取与之配合的扩增引物进行扩增;间接引物则是通过接头接入特异的引物结合序列后,在扩增阶段,采取与之配合的扩增引物进行扩增。
57.例如,所述转座酶含有第一接头2和第二接头5,在所述转座酶进行特异性的切割后,得到的多个所述片段化的dna,便含有所述第一接头2和第二接头5。
58.在一些实施例中,多个所述标签体包括相同的第一接头结合标签和接头1’,所述第一接头的远离末端核心序列的端部含有接头1,接头1可与所述接头1’连接,而靠近所述末端核心序列的端部包括read 1 sequencing primer;所述第二接头设计为read 2 sequencing primer。
59.在一些实施例中,所述第一接头2被磷酸化修饰,该磷酸化修饰可用于与特定序列的连接,如标签序列。
60.在一些实施例中,所述用于dna表观修饰的建库的试剂盒还包括微孔芯片或油包水隔离体系,用于将样品进行细胞隔离;对应地,各所述标签体还包括细胞标签,在多个所述标签体中,与来自同一所述单细胞的dna片段连接的多个所述标签体的所述细胞标签相同,与来自不同所述单细胞的dna片段连接的多个所述标签体的所述细胞标签不同。
61.在一些实施例中,所述标记体系包括:多个细胞标签载体,各所述细胞标签载体包括载体本体以及多条标签体,各标签体含有所述细胞标签和与所述细胞标签一端连接的接头1’,所述载体本体与所述细胞标签的另一端连接且与所述细胞标签可条件性断裂,所述接头1’可与所述接头1连接,同一所述载体本体连接的所述细胞标签相同,不同所述载体本体连接的所述细胞标签不同;在一些实施例中,所述标签体还包括第一接头结合标签和断点,且所述断点、所述第一接头结合标签、所述细胞标签和所述接头1’顺次连接,所述载体本体与所述断点连接
于远离所述第一接头结合标签的一端。其中,断点为pclinker或被还原剂断裂的s-s键。其中,所述第一接头结合标签可以与后续的扩增引物配合,进行特异性扩增。
62.在一些实施例中,单个载体本体上标记10^
5-10^
10
个有相同细胞标签的标签体,细胞标签序列可以有100-100000000种,优选的细胞标签种类有100000-10000000种,对于载体本体的材质不做具体限定,可以为柔性材质也可以为硬性材质,例如ps磁珠或者水凝胶微珠。
63.在一些实施例中,所述扩增引物包括第一引物和第二引物,其中,所述第一引物包含与第一接头结合标签相同的序列,所述第二引物包含与第二接头相同的序列以及文库标签。采用上述扩增引物,可以用于后续的特异性扩增,并引入文库标签。
64.进一步,所述第一接头结合标签设计成测序平台可识别的p5,所述第二引物还包括第二测序接头,且所述文库标签设于所述第二测序接头与所述结合序列之间,所述第二测序接头设计成测序平台可识别的p7。
65.此外,本发明还提供一种dna表观修饰的测序方法,包括以下步骤:步骤b10:采用上述dna表观修饰的建库方法构建表观修饰dna文库;步骤b20:对所述表观修饰dna文库进行测序。所得文库可以用illumina测序平台或者mgi测序平台进行测序。
66.所述dna表观修饰的检测方法还包括:步骤b30:使用生物信息学软件对表观修饰位点进行分析。
67.所述步骤b30包括;步骤b301:对测序数据进行质控,根据细胞标签进行分类,归属同个细胞的测序数据,确定所有所归属的细胞标签;步骤b302:将测得的待测序的dna片段和参考基因组进行比对,根据比对结果查找碱基c变异为碱基t的基因组位点即为表观修饰位点,最后根据细胞标签可推算出原始细胞基因组中所有表观修饰的碱基位置。
68.以下结合具体实施例和附图对本发明的技术方案作进一步详细说明,应当理解,以下实施例仅仅用以解释本发明,并不用于限定本发明。
69.实施例1本实施例提供了一种人慢性骨髓性白血病细胞系k562单细胞dna 5mc表观修饰检测的方法。以下为整个流程的详细流程及参数:1、细胞的交联和透化取2
×
105~1
×
10
6 k562细胞(中国科学院典型培养物保藏委员会细胞库,scsp-5054),经pbs清洗后,向细胞中加入10ml含终浓度4%(v/v)多聚甲醛的rpmi 1640培养基,室温孵育20 min。而后向上述反应液中加入终浓度200 mm甘氨酸冰上孵育5 min终止交联反应。
70.2、去除与核酸结合的核小体上述交联后的细胞经预冷的10 ml pbs清洗一次,使用800 ml含0.3%(w/v)sds的nebuffer2.1重悬细胞,42℃振荡孵育30 min。反应结束后,向上述反应液中加入200 ml 10% tritonx-100,42℃振荡孵育30 min终止反应。使用2%(w/v)bsa-pbs清洗三次。
71.3、dna甲基化位点的定位
将细胞重悬于2%(w/v)bsa-pbs中,室温孵育1小时;将细胞与5-mc抗体(33d3 in 2%(w/v)bsa-pbs,1:500)在37℃下孵育1小时,然后使用0.05%(v/v)tween 20-pbs洗涤四次去除非特异结合抗体。
72.4、pa/pg-tn5与甲基化抗体的特异性结合及dna片段化,此步骤采用诺唯赞cut&tag试剂盒(td903 )完成。
73.4.1 取2 ml pa/g-tnp加入98 ml dig-300 buffer混合,终浓度为0.04 mm,每个样本100 ml。
74.4.2 向细胞中加入100 ml 稀释好的pa/g-tnp转座子,上下颠倒数次,使转座子与细胞混合均匀,室温下旋转孵育1 h,1000 g离心5 min后去除上清。
75.4.3 向细胞中加入200 ml dig-300 buffer上下颠倒数次确保buffer与细胞充分混合均匀以去除未结合转座酶,1000 g离心5 min后去除上清;重复清洗共3次。
76.4.4 取40 ml dig-300 buffer,加入10 ml 5
×
ttbl,混合均匀后重悬清洗后的细胞,置于pcr仪中37℃孵育60 min,1000 g离心5 min后去除上清。
77.4.5 向细胞中加入200 ml dig-300 buffer上下颠倒数次确保buffer与细胞充分混合均匀, 重复清洗共3次。
78.5、cell barcode与转座子序列的连接标记5.1 对4.5中清洗完成的细胞计数,取1万细胞按照如下体系配制油包水水相:5.2 使用seekone
®ꢀ
dd中的商业化cell barcode微珠作为油包水中的珠子相,其cell barcode核酸序列如下表所示,其中可裂解基团可以是可被光断裂的pclinker,也可以是被还原剂断裂的s-s键,这两种核酸修饰均可在上海生工引物合成商合成;5.3 在seekone
®ꢀ
dd中的商业化油包水芯片中加入配制好的78 ml水相和38 ml珠子相,覆盖上橡胶垫之后使用seekone
®ꢀ
dd数字液滴仪进行油包水生成16万左右的液
滴,平均液滴直径110 mm;80%左右的液滴里面含单个细胞标签凝胶珠,平均5000-7000个液滴中同时含有单个细胞和单个凝胶珠,在油包水液滴中细胞标签从凝胶珠上断裂后在下一步可与细胞中的转座子进行连接;5.4 油包水完成后从收集孔收集100 ml乳液至pcr管中,置于pcr仪上20℃反应50 min以完成连接反应。
79.6、解除细胞交联释放dna6.1 在步骤5.4的pcr管中加入100 ml破油剂静置2分钟后完全去除下层氟化油;6.2 将上层细胞悬浮液加入1 ml pbs,1000 g离心5 min后去除上清以洗涤细胞;重复此步骤2次;6.3 使用39 ml pbs重悬细胞,向细胞中加入10 ml 诺唯赞5xtab和1 ml tae,置于pcr仪中72℃反应5 min补齐tn5片段化缺口;6.4 向步骤6.3反应体系中加入50 ml lysis buffer(20 mm tris (ph8.0), 400 mm nacl, 100 mm edta(ph8.0), 4.4%sds)和5 ml proteinase k(20 mg/ml),置于pcr仪中55℃反应2 h以解除细胞交联,释放dna;6.5 向步骤6.4中的dna样本中加入210 ml 纯化磁珠(138.9 ml rlt buffer,64.6 ml异丙醇,6.5 ml dynabeads),吹打混匀,37℃振荡10 min,然后将pcr管置于磁力架上至溶液澄清后去除上清,加入300 ml 80%(v/v)乙醇清洗两遍,室温静置2 min待乙醇挥发后加入 20 ml nuclease-free water充分悬浮磁珠,室温静置2 min,将上清转移至新的ep管中。
80.7、高通量文库的构建7.1 按照下表配制氧化反应液,向步骤6.5的样本中加入30 ml tet1氧化反应液,置于pcr仪中37℃反应80 min,反应结束后向样本中加入1 ml proteinase k(0.8 u),置于pcr仪中50℃反应60 min;7.2 向样本中加入1.8x ampure xp beads纯化dna,35 ml nuclease-free water洗脱dna;7.3 按照下表配制还原反应液,将15 ml还原反应液加入至35 ml dna洗脱液中,37℃,850 rpm孵育反应16 h;
7.4 向样本中加入1.8x ampure xp beads纯化dna,35 ml nuclease-free water洗脱dna;7.5 向上述dna中加入如下扩增反应体系混匀后进行扩增以添加文库接头和样本标签:7.6 将pcr产物用dna clean beads 0.45
×
0.55
×
进行分选得到文库,使用agilent 4200 tapestation对所得文库进行质控,结果如图6所示。
81.结果显示,合格文库片段大小介于100-2000 bp,主峰在200-1000 bp之间。
82.实施例2本实施例提供了一种人慢性骨髓性白血病细胞系k562单细胞dna羟甲基化 5hmc表观修饰检测的方法。整个流程与实施例1相同,主要区别在于步骤3:dna甲基化位点的定位中使用的是特异性识别羟甲基化5hmc的抗体而非5mc抗体。本实施例中的步骤如下:步骤1-2:与实施例1相同,省略;步骤3:dna羟甲基化位点的定位将细胞重悬于2%(w/v)bsa-pbs中,室温孵育1小时;将细胞与5-hmc抗体(rm236 in 2%(w/v)bsa-pbs,1:500)在37℃下孵育1小时,然后使用0.05%(v/v)tween 20-pbs洗涤四次去除非特异结合抗体。
83.步骤4-6:与实施例1中基本相同,区别在于其中步骤6.3中pcr程序为16 cyles,而实施例1中的12 cycles。使用agilent 4200 tapestation对所得文库进行质控,结果如图7所示,结果显示,合格文库片段大小介于100-2000 bp,主峰在200-1000 bp之间。
84.以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包括在本发明的专利保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。