1.本发明涉及一种用以提高人声品质的方法以及装置。
背景技术:
2.由于骨传导传感器对声学环境中的环境噪声具有免疫力,因此早已对骨传导传感器进行研究并用于改善通信设备中的人声(voice)品质。然而与一般的空气传声麦克风不同是,这些传感器信号或骨传导信号只能良好地表示人声信号中的低频部分,而一般的空气传声麦克风可以提取较宽频带的声音,包括人声信号或背景噪声。因此,对于在嘈杂环境中使用的通信设备,将传感器或骨传导信号与空气传导声信号相结合以提高人声品质是非常令人感兴趣的。
技术实现要素:
3.本发明在此提出用以提高人声品质的方法以及装置,在穿戴式装置中利用来自加速度检测器以及麦克风阵列的信号进行语音增强,其中穿戴式装置如耳塞式耳机、项链(neckbands)以及眼镜。来自加速度检测器以及麦克风阵列的所有信号,皆在时域以及频域中处理以利语音增强。
4.有鉴于此,本发明提出一种提高人声品质方法,包括自一麦克风阵列接收多个声学信号;自一加速度检测器接收多个检测信号;利用一波束成形器根据上述声学信号而产生一语音输出信号以及一噪声输出信号;根据上述检测信号,最佳估计上述语音输出信号而产生一最佳估计信号;根据上述语音输出信号以及上述最佳估计信号,最佳估计上述语音输出信号;以及根据上述语音输出信号以及上述最佳估计信号,产生一混和信号。
5.根据本发明的一实施例,提高人声品质方法还包括将来自上述麦克风阵列的上述声学信号的直流部分移除,并前置放大上述声学信号而产生多个前置放大声学信号;以及对上述前置放大声学信号执行快速傅立叶变换而产生多个频域声学信号。
6.根据本发明的一实施例,上述利用上述波束成形器根据上述声学信号而产生上述语音输出信号以及上述噪声输出信号的步骤还包括将一空间滤波器应用于上述频域声学信号而产生上述语音输出信号以及上述噪声输出信号。上述语音输出信号指向一目标语音的一第一方向,上述噪声输出信号指向一第二方向,其中上述第二方向与上述第一方向相反。
7.根据本发明的一实施例,上述检测信号包括一x轴检测信号、一y轴检测信号以及一z轴检测信号,上述提高人声方法还包括将来自上述加速度检测器的上述x轴检测信号、上述y轴检测信号以及上述z轴检测信号的直流部分移除,并且前置放大上述x轴检测信号、上述y轴检测信号以及上述z轴检测信号而产生一x轴前置信号、一y轴前置信号以及一z轴前置信号;以及对上述x轴前置信号、上述y轴前置信号以及上述z轴前置信号执行快速傅立叶变换,而分别产生一x轴频域信号、一y轴频域信号以及一z轴频域信号。
8.根据本发明的一实施例,上述根据上述检测信号最佳估计上述语音输出信号而产
生上述最佳估计信号的步骤还包括将一适应性算法施加于上述x轴频域信号以及上述语音输出信号而产生一第一估计信号;将上述适应性算法施加于上述y轴频域信号以及上述语音输出信号而产生一第二估计信号;将上述适应性算法施加于上述z轴频域信号以及上述语音输出信号而产生一第三估计信号;以及自上述第一估计信号、上述第二估计信号以及上述第三估计信号选择具有一最大振幅者而产生上述最佳估计信号。
9.根据本发明的一实施例,上述适应性算法为一最小均方算法。上述x轴频域信号以及上述语音输出信号之间的均方误差、上述y轴频域信号以及上述语音输出信号之间的均方误差以及上述z轴频域信号以及上述语音输出信号之间的均方误差皆为最小。
10.根据本发明的另一实施例,上述适应性算法为一最小二乘算法。上述x轴频域信号以及上述语音输出信号之间的平方误差、上述y轴频域信号以及上述语音输出信号之间的平方误差以及上述z轴频域信号以及上述语音输出信号之间的平方误差皆为最小。
11.根据本发明的一实施例,上述加速度检测器具有一最大检测频率,其中上述根据上述语音输出信号以及上述最佳估计信号产生上述混和信号的步骤还包括当上述混和信号的一第一频率范围不超过上述最大检测频率时,自上述语音输出信号以及上述最佳估计信号中选择具有一最大振幅的一个,用以表示上述第一频率范围的上述混和信号;以及当上述混和信号的一第二频率范围超过上述最大检测频率时,选择对应上述第二频率范围的上述语音输出信号,用以代表上述第二频率范围的上述混和信号。
12.根据本发明的一实施例,提高人声品质方法还包括在上述混和信号产生之后,利用上述噪声输出信号做为一参考值,通过一适应性算法消除上述混和信号中残留的噪声而产生一噪声消除混和信号;利用上述噪声输出信号做为一参考值,通过一语音增强算法抑制上述噪声消除混和信号中残留的噪声而产生一语音增强信号;将上述语音增强信号变换至时域而产生一语音增强时域信号;以及对上述语音增强时域信号执行一后处理而产生一语音信号。
13.根据本发明的一实施例,上述适应性算法包括一最小均方(least mean square,lms)算法以及一最小二乘(least square,ls)算法,其中上述语音增强算法包括一频谱相减法(spectral subtraction)、一维纳滤波器(wiener filter)以及一最小均方误差(minimum mean square error,mmse),其中上述后处理包括一去加权(de
‑
emphasis)、一均衡化以及一动态增益控制。
14.本发明更提出一种提高人声品质装置,包括一麦克风阵列、一加速度检测器、一波束成形器以及一语音估计器。上述加速度检测器具有一最大检测频率。上述波束成形器根据上述麦克风阵列的多个声学信号,产生一语音输出信号以及一噪声输出信号。上述语音估计器根据上述加速度检测器的上述检测信号最佳估计上述语音输出信号而产生一最佳估计信号,并且根据上述语音输出信号以及上述最佳估计信号而产生一混和信号。
15.根据本发明的一实施例,提高人声品质装置还包括一第一前置处理器以及一第一快速傅立叶变换分析器。上述第一前置处理器移除上述声学信号的直流部分,并且前置放大上述声学信号而产生多个前置放大声学信号。上述第一快速傅立叶变换分析器对上述前置放大声学信号执行快速傅立叶变换而产生多个频域声学信号。
16.根据本发明的一实施例,上述波束成形器将一空间滤波器施加于上述频域声学信号而产生上述语音输出信号以及上述噪声输出信号,其中上述语音输出信号指向一目标语
音的一第一方向,上述噪声输出信号指向一第二方向,其中上述第二方向与上述第一方向相反。
17.根据本发明的一实施例,上述检测信号包括一x轴检测信号、一y轴检测信号以及一z轴检测信号。上述提高人声品质装置还包括一第二前置处理器以及一第二快速傅立叶变换分析器。上述第二前置处理器移除上述x轴检测信号、上述y轴检测信号以及上述z轴检测信号的直流部分,且前置放大上述x轴检测信号、上述y轴检测信号以及上述z轴检测信号而产生一x轴前置信号、一y轴前置信号以及一z轴前置信号。上述第二快速傅立叶变换分析器对上述x轴前至信号、上述y轴前置信号以及上述z轴前置信号执行快速傅立叶变换而分别产生一x轴频域信号、一y轴频域信号以及一z轴频域信号。
18.根据本发明的一实施例,上述语音估计器还包括一第一适应性滤波器、一第二适应性滤波器、一第三适应性滤波器以及一第一选择器。上述第一适应性滤波器将一适应性算法施加至上述x轴频域信号以及上述语音输出信号而产生一第一估计信号,其中上述第一估计信号以及上述语音输出信号的差值为最小。上述第二适应性滤波器将上述适应性算法施加至上述y轴频域信号以及上述语音输出信号而产生一第二估计信号,其中上述第二估计信号以及上述语音输出信号的差值为最小。上述第三适应性滤波器将上述适应性算法施加至上述z轴频域信号以及上述语音输出信号而产生一第三估计信号,其中上述第三估计信号以及上述语音输出信号的差值为最小。上述第一选择器自上述第一估计信号、上述第二估计信号以及上述第三估计信号选择具有一最大振幅的一个而产生上述最佳估计信号。
19.根据本发明的一实施例,上述适应性算法为一最小均方算法,其中上述x轴频域信号以及上述语音输出信号之间的均方误差、上述y轴频域信号以及上述语音输出信号之间的均方误差以及上述z轴频域信号以及上述语音输出信号之间的均方误差皆为最小。
20.根据本发明的另一实施例,上述适应性算法为一最小二乘算法,其中上述x轴频域信号以及上述语音输出信号之间的平方误差、上述y轴频域信号以及上述语音输出信号之间的平方误差以及上述z轴频域信号以及上述语音输出信号之间的平方误差皆为最小。
21.根据本发明的一实施例,上述语音估计器还包括一第二选择器。当上述混和信号的一第一频率范围不超过上述最大检测频率时,上述第二选择器自上述语音输出信号以及上述最佳估计信号选择具有一最小振幅的一个,用以代表上述第一频率范围的上述混和信号。当上述混和信号的一第二频率范围超过上述最大检测频率时,上述第二选择器选择对应上述第二频率范围的上述语音输出信号,用以代表上述第二频率范围的上述混和信号。
22.根据本发明的一实施例,提高人声品质装置还包括一噪声消除器、一噪声抑制器、一快速傅立叶变换合成器以及一后处理器。上述噪声消除器利用上述噪声输出信号做为一参考值,通过一适应性算法消除上述混和信号中残留的噪声而产生一噪声消除混和信号。上述噪声抑制器利用上述噪声输出信号做为一参考值,通过一语音增强算法抑制上述噪声消除混和信号中残留的噪声而产生一语音增强信号。上述快速傅立叶变换合成器将上述语音增强信号变换至时域而产生一语音增强时域信号。上述后处理器对上述语音增强时域信号执行一后处理而产生一语音信号。
23.根据本发明的一实施例,上述适应性算法包括一最小均方(least mean square,lms)算法以及一最小二乘(least square,ls)算法,其中上述语音增强算法包括一频谱相
减法(spectral subtraction)、一维纳滤波器(wiener filter)以及一最小均方误差(minimum mean square error,mmse),其中上述后处理包括一去加权(de
‑
emphasis)、一均衡化以及一动态增益控制。
附图说明
24.图1是显示根据本发明的一实施例所述的提高人声品质装置的方块图;
25.图2是显示根据本发明的一实施例所述的语音估计器的方块图;
26.图3是显示根据本发明的一实施例所述的噪声消除器的方块图;以及
27.图4是显示根据本发明的一实施例所述的提高人声品质的方法的流程图。
28.【符号说明】
29.100:提高人声品质装置
30.101:第一前置处理器
31.102:第一快速傅立叶变换分析器
32.103:波束形成器
33.104:第二前置处理器
34.105:第二快速傅立叶变换分析器
35.106,200:语音估计器
36.107,310:噪声消除器
37.108噪声抑制器
38.109快速傅立叶变换合成器
39.110后处理器
40.210:第一适应性滤波器
41.220:第二适应性滤波器
42.230:第三适应性滤波器
43.240:第一选择器
44.250:第二选择器
45.10:麦克风阵列
46.20:加速度检测器
47.311:适应性滤波器
48.400:提高人声品质方法
49.m1(t):第一声学信号
50.m2(t):第二声学信号
51.m
1pe
(t):第一前置放大声学信号
52.m
2pe
(t):第二前置放大声学信号
53.m1(n,k):第一频域声学信号
54.m2(n,k):第二频域声学信号
55.b
s
(n,k):语音输出信号
56.b
r
(n,k):噪声输出信号
57.a
x
(t):x轴检测信号
58.a
y
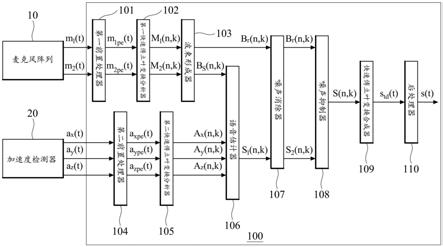
(t):y轴检测信号
59.a
z
(t):z轴检测信号
60.a
xpe
(t):x轴前置信号
61.a
ype
(t):y轴前置信号
62.a
zpe
(t):z轴前置信号
63.a
x
(n,k):x轴频域信号
64.a
y
(n,k):y轴频域信号
65.a
z
(n,k):z轴频域信号
66.s1(n,k):混和信号
67.s2(n,k):噪声消除混和信号
68.s(n,k):语音增强信号
69.s
td
(t):语音增强时域信号
70.s(t):语音信号
71.r
x
(n,k):第一估计信号
72.r
y
(n,k):第二估计信号
73.r
z
(n,k):第三估计信号
74.r(n,k):最佳估计信号
75.s410~s450:步骤流程
具体实施方式
76.以下说明为本发明的实施例。其目的是要举例说明本发明一般性的原则,不应视为本发明的限制,本发明的范围当以权利要求书所界定者为准。
77.能理解的是,虽然在此可使用用语“第一”、“第二”、“第三”等来叙述各种元件、组成成分、区域、层、和/或部分,这些元件、组成成分、区域、层、和/或部分不应被这些用语限定,且这些用语仅是用来区别不同的元件、组成成分、区域、层、和/或部分。因此,以下讨论的一第一元件、组成成分、区域、层、和/或部分可在不偏离本公开一些实施例的教示的情况下被称为一第二元件、组成成分、区域、层、和/或部分。
78.值得注意的是,以下所公开的内容可提供多个用以实践本发明的不同特点的实施例或范例。以下所述的特殊的元件范例与安排仅用以简单扼要地阐述本发明的精神,并非用以限定本发明的范围。此外,以下说明书可能在多个范例中重复使用相同的元件符号或文字。然而,重复使用的目的仅为了提供简化并清楚的说明,并非用以限定多个以下所讨论的实施例和/或配置之间的关系。此外,以下说明书所述的一个特征连接至、耦接至和/或形成于另一特征之上等的描述,实际可包含多个不同的实施例,包括该等特征直接接触,或者包含其它额外的特征形成于该等特征之间等等,使得该等特征并非直接接触。
79.图1是显示根据本发明的一实施例所述的提高人声品质装置的方块图。根据本发明的一实施例,提高人声品质装置100可应用于穿戴式装置,如用以人声(voice)通信或语音(speech)辨识的耳塞式耳机(earbud)。根据本发明的一实施例,提高人声品质装置100包括一对耳塞式耳机。
80.如图1所示,麦克风阵列10检测声音而产生多个声学信号,并表示为在任何时间瞬
间t的第一声学信号m1(t)以及第二声学信号m2(t)。根据本发明的一些实施例,麦克风阵列10可具有二或多个麦克风单元,并相应地产生二或多声学信号。在此同时,加速度检测器20检测到振动而产生3维检测信号,即x轴检测信号a
x
(t)、y轴检测信号a
y
(t)以及z轴检测信号a
z
(t)。
81.提高人声品质装置100接收第一声学信号m1(t)、第二声学信号m2(t)、x轴检测信号a
x
(t)、y轴检测信号a
y
(t)以及z轴检测信号a
z
(t),其中提高人声品质装置100包括第一前置处理器101、第一快速傅立叶变换(stft)分析器102以及波束形成器103。第一前置处理器101移除第一声学信号m1(t)以及第二声学信号m2(t)的直流部分,并前置放大(pre
‑
emphasize)来自麦克风阵列10的第一声学信号m1(t)以及第二声学信号m2(t)而产生第一前置放大声学信号m
1pe
(t)以及第二前置放大声学信号m
2pe
(t)。
82.第一快速傅立叶变换分析器102执行快速傅立叶变换(short
‑
term fourier transform)而将位于时域的第一前置放大声学信号m
1pe
(t)以及第二前置放大声学信号m
2pe
(t),划分至多个频段(frequency bins)。根据本发明的一实施例,第一快速傅立叶变换分析器102利用重叠
‑
相加的卷积法(overlap
‑
add approach)而执行快速傅立叶变换,其中重叠
‑
相加的卷积法是在具有时间窗的与前一帧重叠的一帧信号上执行dft。在快速傅立叶变换分析器102之后,产生第一声学信号m1(t)以及第二声学信号m2(t)的时间
‑
频率表示式的第一频域声学信号m1(n,k)以及第二频域声学信号m2(n,k),其中n代表一帧的数据的时间指标,k=1,
…
,k,并且k为在频带上所划分的频段的总数。
83.对于每个k,波束成形器103将空间滤波器应用于第一频域声学信号m1(n,k)以及第二频域声学信号m2(n,k),而产生语音输出信号b
s
(n,k)以及噪声输出信号b
r
(n,k),其中语音输出信号b
s
(n,k)指向目标语音的方向,噪声输出信号b
r
(n,k)指向目标语音的相反方向。换句话说,语音输出信号b
s
(n,k)为语音加权(speech weighted),噪声输出信号b
r
(n,k)为噪声加权(noise weighted)。
84.提高人声品质装置100还包括第二前置处理器104、第二快速傅立叶变换分析器105以及语音估计器106。
85.第二前置处理器104移除x轴检测信号a
x
(t)、y轴检测信号a
y
(t)以及z轴检测信号a
z
(t)的直流部分,并前置放大(pre
‑
emphasize)来自加速度检测器20的x轴检测信号a
x
(t)、y轴检测信号a
y
(t)以及z轴检测信号a
z
(t)而产生x轴前置信号a
xpe
(t)、y轴前置信号a
ype
(t)以及z轴前置信号a
zpe
(t)。
86.第二快速傅立叶变换分析器105对x轴前置信号a
xpe
(t)、y轴前置信号a
ype
(t)以及z轴前置信号a
zpe
(t)执行快速傅立叶变换(short
‑
term fourier transform),而分别产生x轴频域信号a
x
(n,k)、y轴频域信号a
y
(n,k)以及z轴频域信号a
z
(n,k),对于在时间指标n的每一个频段k。
87.语音估计器106利用x轴频域信号a
x
(n,k)、y轴频域信号a
y
(n,k)以及z轴频域信号a
z
(n,k),最佳地估计(best
‑
estimate)语音输出信号b
s
(n,k)而产生最佳估计信号,接着根据语音输出信号b
s
(n,k)以及最佳估计信号,而产生混和信号s1(n,k)。如何产生最佳估计信号以及混和信号s1(n,k),将在下文中详细解释。
88.图2是显示根据本发明的一实施例所述的语音估计器的方块图。根据本发明的一实施例,图2的语音估计器200对应至图1的语音估计器106。
89.如图2所示,语音估计器200包括第一适应性滤波器210、第二适应性滤波器220、第三适应性滤波器230以及第一选择器240。第一适应性滤波器210将适应性算法应用于x轴频域信号a
x
(n,k)以及语音输出信号b
s
(n,k)而产生第一估计信号r
x
(n,k),以最小化第一估计信号r
x
(n,k)以及语音输出信号b
s
(n,k)之间的差值。
90.第一估计信号r
x
(n,k)如公式1所示,其中w
x
(n,i),i=0,
…
,i
‑
1为具有阶层数i的有限脉冲响应(finite impulse response,fir)滤波器的权重,且会在每个时间指标n的所有频段k=1,
…
,k更新。
[0091][0092]
第二适应性滤波器220将适应性算法应用于y轴频域信号a
y
(n,k)以及语音输出信号b
s
(n,k)而产生第二估计信号r
y
(n,k),以最小化第二估计信号r
y
(n,k)以及语音输出信号b
s
(n,k)之间的差值。
[0093]
第二估计信号r
y
(n,k)如公式2所示,其中w
y
(n,i),i=0,
…
,i
‑
1为具有阶层数i的有限脉冲响应(finite impulse response,fir)滤波器的权重,且会在每个时间指标n的所有频段k=1,
…
,k更新。
[0094][0095]
第三适应性滤波器230将适应性算法应用于z轴频域信号a
z
(n,k)以及语音输出信号b
s
(n,k)而产生第三估计信号r
z
(n,k),以最小化第三估计信号r
z
(n,k)以及语音输出信号b
s
(n,k)之间的差值。
[0096]
第三估计信号r
z
(n,k)如公式3所示,其中w
z
(n,i),i=0,
…
,i
‑
1为具有阶层数i的有限脉冲响应(finite impulse response,fir)滤波器的权重,且会在每个时间指标n的所有频段k=1,
…
,k更新。
[0097][0098]
根据本发明的一实施例,第一适应性滤波器210、第二适应性滤波器220以及第三适应性滤波器230的适应性算法可为最小均方(least mean square,lms)算法,使得第一估计信号r
x
(n,k)以及语音输出信号b
s
(n,k)的均方误差、第二估计信号r
y
(n,k)以及语音输出信号b
s
(n,k)的均方误差以及第三估计信号r
z
(n,k)以及语音输出信号b
s
(n,k)的均方误差皆为最小。
[0099]
根据本发明的另一实施例,第一适应性滤波器210、第二适应性滤波器220以及第三适应性滤波器230的适应性算法可为最小二乘(least square,ls)算法,使得第一估计信号r
x
(n,k)以及语音输出信号b
s
(n,k)的最小二乘误差、第二估计信号r
y
(n,k)以及语音输出信号b
s
(n,k)的最小二乘误差以及第三估计信号r
z
(n,k)以及语音输出信号b
s
(n,k)的最小二乘误差皆为最小。
[0100]
第一选择器240自第一估计信号r
x
(n,k)、第二估计信号r
y
(n,k)以及第三估计信号r
z
(n,k)中选择具有最大振幅的一个,而产生公式4所示的最佳估计信号r(n,k)。
[0101]
r(n,k)=max{r
x
(n,k),r
y
(n,k),r
z
(n,k)}
ꢀꢀꢀꢀꢀꢀꢀꢀ
(公式4)
[0102]
如图2所示,语音估计器200还包括第二选择器250。第二选择器250根据最佳估计信号r(n,k)以及语音输出信号b
s
(n,k),产生混和信号s1(n,k)。当混和信号s1(n,k)的第一频率范围不超过图1的加速度检测器20的最大的检测频率时,第二选择器250自语音输出信号b
s
(n,k)以及最佳估计信号r(n,k)中选取具有最小振幅者,用以表示第一频率范围的混和信号s1(n,k)。
[0103]
根据本发明的一实施例,加速度检测器20的最大的检测频率为加速度检测器20所能检测到的最大频率。当混和信号s1(n,k)的第二频率范围超过图1的加速度检测器20的最大检测频率时,第二选择器250选择对应第二频率范围的语音输出信号b
s
(n,k),用以表示第二频率范围的混和信号s1(n,k)。
[0104]
混和信号s1(n,k)如公式5所示,其中min{}代表选取具有最小振幅者,k
s
是根据所使用的加速度检测器的最大检测频率所实际选择的整数的临限值。
[0105][0106]
换句话说,当混和信号s1(n,k)的频率不超过加速度检测器20的最大的检测频率时,自最佳估计信号r(n,k)以及语音输出信号b
s
(n,k)中选取的有最小振幅者来代表混和信号s1(n,k);当混和信号s1(n,k)的频率超过加速度检测器20的最大的检测频率时,则选择语音输出信号b
s
(n,k)来代表混和信号s1(n,k)。
[0107]
根据本发明的一实施例,当混和信号s1(n,k)的频率不超过加速度检测器20的最大的检测频率时,选取最佳估计信号r(n,k)以及语音输出信号b
s
(n,k)中具有最小振幅者,使得来自麦克风阵列10的噪声能够被抑制。
[0108]
参考图1,提高人声品质装置100还包括噪声消除器107、噪声抑制器108、快速傅立叶变换合成器109以及后处理器110。在图1的语音估计器106产生混和信号s1(n,k)之后,噪声消除器107利用来自波束成形器103的噪声输出信号b
r
(n,k)作为参考值,通过适应性算法消除残留于混和信号s1(n,k)的噪声而产生噪声消除混和信号s2(n,k)。根据本发明的一实施例,适应性算法包括最小均方(least mean square,lms)算法以及最小二乘(least square,ls)算法。
[0109]
噪声抑制器108利用噪声输出信号br(n,k)作为参考值并通过语音增强算法,抑制残存于噪声消除混和信号s2(n,k)中的噪声而产生语音增强信号s(n,k)。根据本发明的一些实施例,语音增强算法包括频谱相减法(spectral subtraction)、维纳滤波器(wiener filter)以及最小均方误差(minimum mean square error,mmse)。
[0110]
图3是显示根据本发明的一实施例所述的噪声消除器的方块图。如图3所示,噪声消除器310对应图1的噪声消除器107。
[0111]
如图3所示,噪声消除器310包括适应性滤波器311,其中适应性滤波器311包括有限脉冲响应(finite impulse response,fir)滤波器fir。适应性滤波器311利用来自于波束成形器103的噪声输出信号b
r
(n,k)作为参考值,消除残留于混和信号s1(n,k)的噪声而产生噪声消除混和信号s2(n,k)。噪声消除混和信号s2(n,k)如公式6所示,其中u(n,j),j=0,
…
,j
‑
1为具有j阶层的有限脉冲响应滤波器fir的权重,且由适应性算法(如,最小均方算法或最小二乘算法)更新。
[0112][0113]
根据本发明的一实施例,适应性滤波器311的适应性的步长(step
‑
size)μ可由混和信号s1(n,k)的人声活动所控制。举例来说,当混和信号s1(n,k)主要包含语音时,使用较小的数值;当混和信号s1(n,k)主要包含噪声时,使用较大的数值。
[0114]
参考图1,快速傅立叶变换合成器109将由噪声抑制器108所产生的语音增强信号s(n,k)变换至时域而产生语音增强时域信号s
td
(t),后处理器110对语音增强时域信号s
td
(t)执行后处理而产生语音信号s(t)。根据本发明的一些实施例,后处理(post
‑
processing)包括去加权(de
‑
emphasis)、均衡化以及动态增益控制。因此,通过语音增强而得语音信号s(t)后,将语音信号s(t)发送至远端通信装置。
[0115]
图4是显示根据本发明的一实施例所述的提高人声品质的方法的流程图。在以下针对图4的叙述中,将搭配图1以及图2以利详细描述。如图4所示,提高人声品质方法400启始于提高人声品质装置100自麦克风阵列10接收第一声学信号m1(t)以及第二声学信号m2(t)(步骤s410)。提高人声品质装置100也自加速度检测器20接收x轴检测信号a
x
(t)、y轴检测信号a
y
(t)以及z轴检测信号a
z
(t)(步骤s420)。
[0116]
提高人声品质装置100的波束成形器103根据第一声学信号m1(t)以及第二声学信号m2(t),而产生语音输出信号b
s
(n,k)以及噪声输出信号b
r
(n,k)(步骤s430)。语音估计器106根据x轴检测信号a
x
(t)、y轴检测信号a
y
(t)以及z轴检测信号a
z
(t),最佳地估计语音输出信号b
s
(n,k)而产生最佳估计信号r(n,k)(步骤s440),并且根据语音输出信号b
s
(n,k)以及最佳估计信号r(n,k)而产生混和信号s1(n,k)(步骤s450)。
[0117]
本发明在此提出用以提高人声品质的方法以及装置,在穿戴式装置中利用来自加速度检测器以及麦克风阵列的信号进行语音增强,其中穿戴式装置如耳塞式耳机、项链(neckbands)以及眼镜。来自加速度检测器以及麦克风阵列的所有信号,皆在时域以及频域中处理以利语音增强。
[0118]
虽然本公开的实施例及其优点已公开如上,但应该了解的是,本领域技术人员,在不脱离本公开的精神和范围内,当可作更动、替代与润饰。此外,本公开的保护范围并未局限于说明书内所述特定实施例中的工艺、机器、制造、物质组成、装置、方法及步骤,本领域技术人员可从本公开一些实施例的揭示内容中理解现行或未来所发展出的工艺、机器、制造、物质组成、装置、方法及步骤,只要可以在此处所述实施例中实施大抵相同功能或获得大抵相同结果皆可根据本公开一些实施例使用。因此,本公开的保护范围包括上述工艺、机器、制造、物质组成、装置、方法及步骤。另外,每一权利要求构成个别的实施例,且本公开的保护范围也包括各个权利要求及实施例的组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

