1.本技术涉及语音信号处理的技术领域,特别是涉及语音检测模型的训练方法以及相关方法、装置、设备。
背景技术:
2.语音识别作为一种生物识别技术,由于其方便、可靠、低成本等特性已广泛应用到门禁系统、电子商务、智能产品等行业领域中,以给各行各业提供相应的便利功能,例如语音控制、人工智能对话或语音真伪检测等。
3.但是随着语音伪造技术的发展,现有的语音识别系统在面对伪造语音的攻击时是十分脆弱的,难以分辨出语音是否来自合成、录音等的伪造语音,这会给基于语音识别的具体应用造成极大的识别困难。
4.如何来检测伪造语音是语音识别应用的一个挑战,准确的语音伪造检测是保障语音识别技术可靠应用的基础。
技术实现要素:
5.本技术提供了语音检测模型的训练方法以及相关方法、装置、设备,以解决现有技术中存在的检测伪造语音的问题。
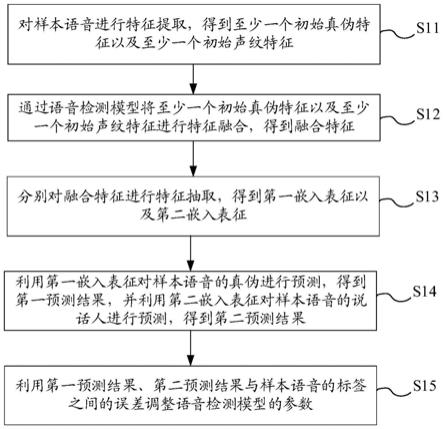
6.本技术提供了一种语音检测模型的训练方法,包括:对样本语音进行特征提取,得到至少一个初始真伪特征以及至少一个初始声纹特征;通过语音检测模型将至少一个初始真伪特征以及至少一个初始声纹特征进行特征融合,得到融合特征;分别对融合特征进行特征抽取,得到第一嵌入表征以及第二嵌入表征;利用第一嵌入表征对样本语音的真伪进行预测,得到第一预测结果,并利用第二嵌入表征对样本语音的说话人进行预测,得到第二预测结果;利用第一预测结果、第二预测结果与样本语音的标签之间的误差调整语音检测模型的参数。
7.其中,通过语音检测模型将至少一个初始真伪特征以及至少一个初始声纹特征进行特征融合,得到融合特征的步骤,包括:分别对至少一个初始真伪特征以及至少一个初始声纹特征进行深层特征提取,得到至少一个真伪语音特征以及至少一个声纹语音特征;将至少一个真伪语音特征以及至少一个声纹语音特征进行特征融合,得到融合特征。
8.其中,分别对至少一个初始真伪特征以及至少一个初始声纹特征进行深层特征提取,得到至少一个真伪语音特征以及至少一个声纹语音特征的步骤包括:通过相同网络权重的深度神经网络和非线性激活函数分别对至少一个初始真伪特征以及至少一个初始声纹特征进行帧层面的深层特征提取,得到至少一个真伪语音特征以及至少一个声纹语音特征。
9.其中,将至少一个真伪语音特征以及至少一个声纹语音特征进行特征融合,得到融合特征的步骤,包括:将至少一个真伪语音特征以及至少一个声纹语音特征进行特征拼接,得到串联特征;对串联特征进行特征转换得到融合特征。
10.其中,分别对融合特征进行特征抽取,得到第一嵌入表征以及第二嵌入表征的步骤包括:分别通过不同的网络特征层对融合特征进行特征抽取,以得到第一嵌入表征以及第二嵌入表征;其中,第一嵌入表征包括真伪嵌入特征,第二嵌入特征包括声纹嵌入特征。
11.其中,利用第一嵌入表征对样本语音的真伪进行预测,得到第一预测结果,并利用第二嵌入表征对样本语音的说话人进行预测,得到第二预测结果包括:将第一嵌入表征以及第二嵌入表征进行交叉融合,得到第一样本嵌入表征以及第二样本嵌入表征;利用第一样本嵌入表征对样本语音的真伪进行预测,得到第一预测结果,并利用第二样本嵌入表征对样本语音的说话人进行预测,得到第二预测结果。
12.其中,将第一嵌入表征以及第二嵌入表征进行交叉融合,得到第一样本嵌入表征以及第二样本嵌入表征包括:分别将第一嵌入表征以及第二嵌入表征进行加权叠加,得到第一样本嵌入表征以及第二样本嵌入表征。
13.其中,利用第一预测结果、第二预测结果与样本语音的标签之间的误差调整语音检测模型的参数步骤包括:基于第一预测结果、第二预测结果与样本语音的标签构建损失函数;利用损失函数调整语音检测模型的参数。
14.本技术还提供了一种语音检测方法,包括对待检测语音进行特征提取,得到至少一个初始真伪特征以及至少一个初始声纹特征;通过语音检测模型将至少一个初始真伪特征以及至少一个初始声纹特征进行特征融合,得到融合特征;分别对融合特征进行特征抽取,得到第一嵌入表征以及第二嵌入表征;基于第一嵌入表征以及第二嵌入表征与真实语音的第一标准嵌入表征以及第二标准嵌入表征之间的相似度确定待检测语音的真伪;其中,真实语音的第一标准嵌入表征和第二标准嵌入表征的获取方式与待检测语音的第一嵌入表征和第二嵌入表征的获取方式相同;其中,语音检测模型为采用上述任一项的语音检测方法训练得到的语音检测模型。
15.其中,基于第一嵌入表征以及第二嵌入表征与真实语音的第一标准嵌入表征以及第二标准嵌入表征之间的相似度确定待检测语音的语音类型的步骤包括:分别计算第一待检测嵌入表征与第一标准嵌入表征以及第二待检测嵌入表征与第二标准嵌入表征之间的余弦相似度;响应于第一待检测嵌入表征与第一标准嵌入表征之间的余弦相似度与第二待检测嵌入表征与第二标准嵌入表征之间的余弦相似度之间的乘积超过预设阈值,将真实语音的语音类型确定为待检测语音的语音类型。
16.本技术还提供了一种电子设备,包括相互耦接的存储器和处理器,处理器用于执行存储器中存储的程序指令,以实现上述任一项的语音检测模型的训练方法或语音检测方法。
17.本技术还提供了一种计算机可读存储介质,其上存储有程序指令,程序指令被处理器执行时实现上述任一项的语音检测模型的训练方法或语音检测方法。
18.上述方案,本技术通过先对样本语音进行特征提取,得到至少一个初始真伪特征以及至少一个初始声纹特,从而使得语音检测模型能够基于不同的声学特征进行语音检测,以得到更多区分真伪音的信息,以提高语音检测模型的检测准确性。再将至少一个初始真伪特征以及至少一个初始声纹特征进行特征融合,得到融合特征,进而分别对融合特征进行特征抽取,得到第一嵌入表征以及第二嵌入表征,利用第一嵌入表征预测得到的第一预测结果和第二嵌入表征预测得到的第二预测结果与样本语音的标签之间的误差调整语
音检测模型的参数,以对语音检测模型进行训练。本技术通过综合了初始真伪特征与初始声纹特征的融合特征进行特征抽取,能够利用更广泛的声学特征来抽取更丰富的嵌入表征,提高了通过嵌入表征进行语音预测的可靠性,从而提高了语音检测模型训练的效率和效果,进而增加训练后的语音检测模型对语音进行预测的准确性和可靠性。
附图说明
19.图1是本技术语音检测模型的训练方法一实施例的流程示意图;
20.图2是本技术语音检测模型的训练方法另一实施例的流程示意图;
21.图3是本技术语音检测方法一实施例的流程示意图;
22.图4是本技术电子设备一实施例的框架示意图;
23.图5为本技术计算机可读存储介质一实施例的框架示意图。
具体实施方式
24.下面结合说明书附图,对本技术实施例的方案进行详细说明。
25.以下描述中,为了说明而不是为了限定,提出了诸如特定系统结构、接口、技术之类的具体细节,以便透彻理解本技术。
26.本文中术语“系统”和“网络”在本文中常被可互换使用。本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,可以存在三种关系,例如,a和/或b,可以:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,一般前后关联对象是一种“或”的关系。此外,本文中的“多”两个或者多于两个。
27.请参阅图1,图1是本技术语音检测模型的训练方法一实施例的流程示意图。具体而言,可以包括如下步骤:
28.步骤s11:对样本语音进行特征提取,得到至少一个初始真伪特征以及至少一个初始声纹特征。
29.获取到样本语音,对该样本语音进行特征提取,得到至少一个初始真伪特征以及至少一个初始声纹特征。初始真伪特征可以为常用于语音真伪检测的特征,初始声纹特征可以为常用于声纹识别的特征。其中,特征提取后,获取到的初始真伪特征与初始声纹特征的具体数量可以分别为1个、3个、4个、5个等,在此不做限定。
30.本实施例的初始真伪特征的特征类型可以包括常量q倒谱系数constant
‑
q cepstral coefficient cqcc,线性频率倒谱系数linear frequency cepstral coefficient lfcc,反转梅尔频率倒谱系数inverted mel frequency cepstral coefficient imfcc,线性预测倒谱系数linear prediction cepstral coefficient lpcc,短时傅里叶变化倒谱系数short
‑
time fourier transform cepstral coefficient sftcc等。而初始声纹特征的特征类型可以包括滤波器组(filter bank fb),梅尔频率倒谱系数(mel frequency cepstral coefficient,mfcc),感知线性预测(perceptual linear predictive,plp),功率归一化倒谱系数(power
‑
normalized cepstral coefficients,pncc)等。具体提取出的初始真伪特征和初始声纹特征的类型和数量可以基于实际需求进行选择,在此不做限定。
31.其中,至少一个不同类型的声学特征在特征提取时可以经过不同的频谱转换,进
而不同类型的声学特征在不同频率上时间和频谱分辨率可以是互不相同的,所以得到不同类型的声学特征的特征提取时的重点频带可以不同。而能够分辨真实语音和伪造语音的关键频带对不同的语音合成、转换等语音伪造算法也是不同的,因此,本实施例对样本语音进行特征提取得到的不同类型的声学特征,即至少一个初始真伪特征以及至少一个初始声纹特征,在应对复杂多样的伪造语音时是具有互补性、多样性,多种类型的声学特征作为输入可以使语音检测模型得到更多用于区分真伪音的信息,进而提高语音检测模型的检测效果。
32.在一个具体的应用场景中,样本语音可以包括多条真实样本语音以及多条伪造样本语音。基于多条真实样本语音以及多条伪造样本语音对语音检测模型进行训练,以提高语音检测模型对各类型语音进行预测的准确性和可靠性。
33.步骤s12:通过语音检测模型将至少一个初始真伪特征以及至少一个初始声纹特征进行特征融合,得到融合特征。
34.将至少一个初始真伪特征以及至少一个初始声纹特征输入到语音检测模型中,以通过语音检测模型对至少一个初始真伪特征以及至少一个初始声纹特征进行特征融合,得到融合特征。
35.其中,通过将至少一个初始真伪特征以及至少一个初始声纹特征进行特征融合,能够使得融合特征融合初始声纹特征的声纹特征以及初始真伪特征的真伪特征,从而使得语音检测模型在训练过程中,能够利用包括不同的特征的融合特征学习到更丰富的对语音检测有用的信息。
36.步骤s13:分别对融合特征进行特征抽取,得到第一嵌入表征以及第二嵌入表征。
37.可以采用不同的语音检测模型对融合特征分别进行特征抽取得到第一嵌入表征以及第二嵌入表征。其中,第二嵌入表征区别于第一嵌入表征。
38.步骤s14:利用第一嵌入表征对样本语音的真伪进行预测,得到第一预测结果,并利用第二嵌入表征对样本语音的说话人进行预测,得到第二预测结果。
39.利用第一嵌入表征对样本语音的真伪进行预测得到第一预测结果,其中,第一预设结果包括样本语音为真实语音或伪造语音。利用第二嵌入表征对样本语音的说话人进行预测,得到第二预测结果,其中。第二预测结果包括样本语音的具体说话人。
40.步骤s15:利用第一预测结果、第二预测结果与样本语音的标签之间的误差调整语音检测模型的参数。
41.获取样本语音的标签,其中,样本语音的标签包括样本语音的真正的真伪类型以及真正的发音人,在一个具体的应用场景中,可以接受人工对样本语音的标注,得到样本语音的标签。在另一个具体的应用场景中,也可以通过其他已训练好的语音模型对样本语音进行标注,得到样本语音的标签。
42.将第一预测结果与样本语音的标签中的样本语音真正的真伪类型进行对比,判断第一预设结果与样本语音真正的真伪类型是否相同,如果不相同则利用第一预设结果与样本语音真正的真伪类型之间的误差调整语音检测模型的参数,以对语音检测模型进行训练。
43.以及将第二预测结果与样本语音的标签中的真正的发音人进行对比,判断第二预设结果与样本语音真正的发音人是否相同,如果不相同则利用第二预设结果与样本语音真
正的发音人之间的误差调整语音检测模型的参数,以对语音检测模型进行训练。
44.在一个具体的应用场景中,当语音检测模型预测出的第一预测结果为样本语音为真实语音,而样本语音的标签中的样本语音真正的真伪类型是伪造语音,则第一预测结果与样本语音的标签之间存在误差。因此可以利用第一预测结果与样本语音的标签之间的误差调整语音检测模型的参数,以对语音检测模型进行训练。
45.通过上述步骤,本实施例的语音检测模型的训练方法通过先对样本语音进行特征提取,得到至少一个初始真伪特征以及至少一个初始声纹特,从而使得语音检测模型能够基于不同的声学特征进行语音检测,以得到更多区分真伪音的信息,以提高语音检测模型的检测准确性。再将至少一个初始真伪特征以及至少一个初始声纹特征进行特征融合,得到融合特征,进而分别对融合特征进行特征抽取,得到第一嵌入表征以及第二嵌入表征,利用第一嵌入表征预测得到的第一预测结果和第二嵌入表征预测得到的第二预测结果与样本语音的标签之间的误差调整语音检测模型的参数,以对语音检测模型进行训练。本实施例通过综合了初始真伪特征与初始声纹特征的融合特征进行特征抽取,能够利用更广泛的声学特征来抽取更丰富的嵌入表征,提高了通过嵌入表征进行语音预测的可靠性,从而提高了语音检测模型训练的效率和效果,进而增加训练后的语音检测模型对语音进行预测的准确性和可靠性。
46.请参阅图2,图2是本技术语音检测模型的训练方法另一实施例的流程示意图。具体而言,可以包括如下步骤:
47.步骤s21:对样本语音进行特征提取,得到至少一个初始真伪特征以及至少一个初始声纹特征。
48.分别通过不同的方式对样本语音进行特征提取,得到至少一个初始真伪特征以及至少一个初始声纹特征。
49.在一个具体的应用场景中,可以通过对样本语音进行对数功率谱、离散语音变换以及常量q转换等处理,得到至少一个初始真伪特征。以及另外通过对样本语音进行对数功率谱、离散语音变换以及傅里叶变换等处理,得到至少一个初始声纹特征。其中,在对语音进行处理前,可以先对样本语音进行分帧加窗的预处理,以使样本语音在帧层面变得稳定且连续,便于对样本语音进行特征提取。
50.在本实施例中,将以提取出的初始真伪特征的数量为1且初始声纹特征的数量为1为例进行说明,初始真伪特征的数量为多个和/或初始声纹特征的数量为多个的实施方式与本实施例相似,不再赘述。
51.其中,本实施例通过对本步骤特征提取出的初始真伪特征进行表示,通过对对本步骤特征提取出初始声纹特征进行表示。其中,t表示特征的语音帧数,d和代表特征维度。也就是,本本步骤提取出的初始真伪特征和初始声纹特征为二维特征。
52.步骤s22:分别对至少一个初始真伪特征以及至少一个初始声纹特征进行深层特征提取,得到至少一个真伪语音特征以及至少一个声纹语音特征,将至少一个真伪语音特征以及至少一个声纹语音特征进行特征融合,得到融合特征。
53.分别对至少一个初始真伪特征以及至少一个初始声纹特征进行深层特征提取,得到至少一个真伪语音特征以及至少一个声纹语音特征。具体地,可以通过相同网络权重的深度神经网络和非线性激活函数分别对至少一个初始真伪特征以及至少一个初始声纹特征进行帧层面的深层特征提取,得到至少一个真伪语音特征以及至少一个声纹语音特征。
54.在一个具体的应用场景中,可以将初始真伪特征和初始声纹特征分别输入到深度神经网络中进行帧层面的特征提取。其中,该深度神经网络的权重对于不同的输入特征是共享的,即深度神经网络采用相同的网络权重分别对初始真伪特征和初始声纹特征进行深层特征提取,得到真伪语音特征以及声纹语音特征。其中通过相同网络权重的深度神经网络分别对初始真伪特征和初始声纹特征进行深层特征提取,能够减弱深度神经网络的复杂程度,提高特征提取效率,并使得初始真伪特征和初始声纹特征的深度特征提取过程能够采取相同层面的提取操作,进行类似的提取过程,最终得到相同层次的特征表示。
55.其中,本步骤中所用的深度神经网络,具体可以为时延深度网络(tdnn,time
‑
delay neural network)、卷积神经网络(cnn,convolutional neural networks)、循环神经网络(recurrent neural networks)和递归神经网络(recursive neural networks)等深度神经网络,具体的深度神经网络的类型可以基于实际需求进行设置,本实施例将以深度神经网络为时延深度网络为例进行说明。
56.具体地,将初始真伪特征输入到时延深度网络中进行线性特征提取,再通过非线性激活函数对时延深度网络提取后的初始真伪特征进行非线性特征提取,最后输出经过上述深层特征提取后的真伪语音特征以及将初始声纹特征输入到时延深度网络中进行线性特征提取,再通过非线性激活函数对时延深度网络提取后的声纹语音特征进行非线性特征提取,最后输出经过上述深层特征提取后的声纹语音特征
57.获得至少一个真伪语音特征以及至少一个声纹语音特征后,将至少一个真伪语音特征以及至少一个声纹语音特征进行特征融合,得到融合特征。具体地,可以将至少一个真伪语音特征以及至少一个声纹语音特征进行特征拼接,得到串联特征,再对串联特征进行特征转换得到融合特征。
58.在一个具体的应用场景中,可以将真伪语音特征与声纹语音特征进行特征拼接得到串联特征具体地,由于真伪语音特征e1与声纹语音特征都为包含t维度信息以及d维度信息为二维特征,因此,在一个具体的应用场景中,可以将真伪语音特征e1与声纹语音特征进行二维叠加,以将真伪语音特征e1与声纹语音特征上对应的特征值进行数值拼接,从而得到串联特征
59.得到串联特征后,再经过全连接层和池化层操作,对串联特征进行特征变换和降维处理,以将二维特征的串联特征转化成只包含d维度特征的一维的串联特征以减少信息冗余,此时的串联特征不再包含t维度的时序信息,而包含整个样本语音句子层面的d维度特征。进行特征拼接后的串联特征可以利用不同类型的声学特征在不同频率段的时间频谱分辨率的差异性,展示出更多的特征信息。
60.步骤s23:分别通过不同的网络特征层对融合特征进行特征抽取,以得到第一嵌入表征以及第二嵌入表征;其中,第一嵌入表征包括真伪嵌入特征,第二嵌入特征包括声纹嵌入特征。
61.分别通过语音检测模型的不同的网络特征层对融合特征进行特征抽取,以得到第一嵌入表征以及第二嵌入表征,从而分别使语音检测模型的不同的网络特征层进行真伪检测任务以及声纹检测任务的网络学习。其中,第一嵌入表征包括真伪嵌入特征,第二嵌入特征包括声纹嵌入特征。
62.分别将串联特征输入到语音伪造检测网络特征层和声纹识别网络特征层进行嵌入表征的抽取,其中,语音伪造检测网络特征层中包括多层全连接、dropout和非线性激活等处理方式,通过将串联特征输入到语音伪造检测网络特征层中,经多层全连接层、dropout和非线性激活等方式抽取出包含真伪音信息和声纹信息的嵌入表征而声纹识别网络特征层中包括多层全连接层、dropout和非线性激活等处理方式,通过将串联特征输入到声纹识别特征层中,经多层全连接、dropout和多个非线性激活等方式抽取出包含真伪音信息和声纹信息的嵌入表征其中,本步骤中的语音伪造检测网络特征层和声纹识别网络特征层中网络节点的参数是不相同的,以便于语音伪造检测网络特征层和声纹识别网络特征层分别沿着语音伪造检测的方向和声纹识别的方向进行嵌入表征的抽取。
63.在一个具体的应用场景中,语音伪造检测网络特征层中多层全连接层的网络全连接节点数可以为100、50、2,而声纹识别网络特征层中多层全连接层的网络全连接节点数可以为100、60、50,以区别于语音伪造检测网络特征层。
64.步骤s24:将第一嵌入表征以及第二嵌入表征进行交叉融合,得到第一样本嵌入表征以及第二样本嵌入表征,利用第一样本嵌入表征对样本语音的真伪进行预测,得到第一预测结果,并利用第二样本嵌入表征对样本语音的说话人进行预测,得到第二预测结果。
65.将第一嵌入表征以及第二嵌入表征进行交叉融合,得到包含有第一嵌入表征以及第二嵌入表征的第一样本嵌入表征以及同样包含有第一嵌入表征以及第二嵌入表征的第二样本嵌入表征。从而进一步提高第一样本嵌入表征与第二样本嵌入表征的特征广泛度与丰富度。
66.在一个具体的应用场景中,可以将上一步骤中获得的两个嵌入表征e3和e4进行交叉融合。交叉融合可以按照如下公式进行构建:
67.enew3=e3 a*e4ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
68.enew4=e4 b*e3ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
69.其中e3表示步骤s23抽取出来的第一嵌入表征,e4表示步骤s23抽取出来的第二嵌入表征,a和b表示融合的标量系数,可以设置为可学习参数,可以相同或不同,enew3和enew4分别表示交叉融合后的第一样本嵌入表征以及第二样本嵌入表征。
70.在一个具体的应用场景中,可以将第一样本嵌入表征enew3和第二样本嵌入表征enew4再经过最后的全连接层进行各自分类任务的学习。具体地,真伪检测任务利用第一样本嵌入表征enew3进行二分类训练分辨该句语音是为真实语音还是伪造语音,声纹检测任务利用第二样本嵌入表征enew4进行多分类训练分辨该句语音是属于具体哪个说话人。
71.在一个具体的应用场景中,最后的全连接层可以包括100*2的矩阵,以基于样本语音的标签的维度,将第一样本嵌入表征enew3和第二样本嵌入表征enew4的维度进行调整匹配。
72.其中,利用第一样本嵌入表征enew3对样本语音的真伪进行预测,得到第一预测结果,并利用第二样本嵌入表征enew4对样本语音的说话人进行预测,得到第二预测结果。其中,第一预测结果可以包括样本语音是真实语音的概率或样本语音是伪造语音的概率。第二预测结果可以包括样本语音是某个说话人的概率。
73.步骤s25:基于第一预测结果、第二预测结果与样本语音的标签构建损失函数,利用损失函数调整语音检测模型的参数。
74.基于第一预测结果、第二预测结果与样本语音的标签构建损失函数,利用损失函数调整语音检测模型的参数。
75.在一个具体的应用场景中,可以使用交叉熵损失函数指导整个语音检测模型学习对真伪音和声纹信息的特征抽取。交叉熵损失函数可以用如下公式表示:
[0076][0077]
其中,p(y)表示样本语音的标签的概率分布,q(y)表示第一预测结果或第二预测结果的概率分布。基于样本语音的标签的概率分布对第一预测结果或第二预测结果的概率分布进行构建损失函数,并利用损失函数调整语音检测模型的参数。
[0078]
在一个具体的应用场景中,样本语音的标签的概率分布可以为样本语音为真实语音的标准概率,而第一预测结果可以为语音检测模型预测出的样本语音为真实语音的预测概率,通过交叉熵损失函数基于标准概率与预测概率调整语音检测模型的参数。
[0079]
在一个具体的应用场景中,本步骤可以通过有监督学习方式对语音检测模型进行反向梯度求导梯度下降法并调整语音检测模型参数,在损失函数值逐渐收敛或者通过验证集由早停法(early stopping)来决定模型训练结束条件,从而完成语音检测模型的训练,得到训练完成的语音检测模型。
[0080]
本实施例采用多任务学习框架,首先将至少一个初始真伪特征以及至少一个初始声纹特征输入到权重共享的深度神经网络进行帧层面的特征学习,然后经过特征拼接、池化等操作后完成帧层面的特征融合和句子层面的特征提取,然后将该融合特征输入到语音伪造检测网络特征层和声纹识别网络特征层进行各自信息的目标学习,同时为了让语音检测模型可以同时利用声纹和真伪信息,加入交叉融合步骤,可以让各自的第一嵌入表征以及第二嵌入表征融合到对方的网络学习中,从而获得更丰富的信息去更好的进行各自的目
标学习,优化语音检测模型的训练结果。
[0081]
通过上述步骤,本实施例的语音检测模型的训练方法先对样本语音进行特征提取,得到至少一个初始真伪特征以及至少一个初始声纹特,从而使得语音检测模型能够基于不同的声学特征进行语音检测,以得到更多区分真伪音的信息,以提高语音检测模型的检测准确性,再分别对至少一个初始真伪特征以及至少一个初始声纹特征进行深层特征提取,得到至少一个真伪语音特征以及至少一个声纹语音特征,从而利用深层特征提取来增加真伪语音特征与声纹语音特征的特征丰富度,以提高语音检测模型的检测可靠性;然后将至少一个真伪语音特征以及至少一个声纹语音特征进行特征融合,得到融合特征,以综合初始真伪特征与初始声纹特征,使得融合特征包括多种声学特征,能够使语音检测模型的训练得到更广泛的特征进行学习,提高语音检测模型的训练效果;随后分别通过不同的网络特征层对融合特征进行特征抽取,以得到第一嵌入表征以及第二嵌入表征,并将第一嵌入表征以及第二嵌入表征进行交叉融合,得到第一样本嵌入表征以及第二样本嵌入表征,并利用第一样本嵌入表征以及第二样本嵌入表征进行预测,得到第一预测结果和第二预测结果,从而使得语音检测模型的预测第一预测结果的预测过程能够学习到预测第二预测结果的预测信息,以及语音检测模型的预测第二预测结果的预测过程能够学习到预测第一预测结果的预测信息,从而进一步使得语音检测模型的预测在训练过程中能够学习到更加鲁棒的本质信息,提高语音检测模型的预测可靠性。最后,本实施例基于第一预测结果、第二预测结果与样本语音的标签构建损失函数,并利用损失函数调整语音检测模型的参数,从而基于样本语音的标签对语音检测模型的参数进行调整,得到训练完成的语音检测模型。本实施例训练完成后的语音检测模型检测效果准确、鲁棒性高、检测效率高。
[0082]
请参阅图3,图3是本技术语音检测方法一实施例的流程示意图。
[0083]
具体而言,可以包括如下步骤:
[0084]
步骤s31:对待检测语音进行特征提取,得到至少一个初始真伪特征以及至少一个初始声纹特征。
[0085]
获取到待检测语音,对待检测语音进行特征提取,得到至少一个初始真伪特征以及至少一个初始声纹特征。其中,特征提取后,获取到的初始真伪特征与初始声纹特征的具体数量可以分别为1个、3个、5个等,在此不做限定。
[0086]
本实施例的特征提取过程、初始真伪特征的特征类型与初始声纹特征的类型与步骤s11或步骤s21中相同,请参阅前文,在此不再赘述。
[0087]
步骤s32:通过语音检测模型将至少一个初始真伪特征以及至少一个初始声纹特征进行特征融合,得到融合特征。
[0088]
将至少一个初始真伪特征以及至少一个初始声纹特征输入到语音检测模型中,以通过语音检测模型对至少一个初始真伪特征以及至少一个初始声纹特征进行特征融合,得到融合特征。
[0089]
步骤s33:分别对融合特征进行特征抽取,得到第一嵌入表征以及第二嵌入表征。
[0090]
通过语音检测模型对融合特征进行特征抽取得到第一嵌入表征,以及另外通过语音检测模型对融合特征再次进行特征抽取得到第二嵌入表征。其中,第二嵌入表征区别于第一嵌入表征。
[0091]
步骤s34:基于第一嵌入表征以及第二嵌入表征与真实语音的第一标准嵌入表征
以及第二标准嵌入表征之间的相似度确定待检测语音的真伪;其中,真实语音的第一标准嵌入表征和第二标准嵌入表征的获取方式与待检测语音的第一嵌入表征和第二嵌入表征的获取方式相同。
[0092]
基于第一嵌入表征以及第二嵌入表征与真实语音的第一标准嵌入表征以及第二标准嵌入表征之间的相似度确定待检测语音的真伪。其中,当第一嵌入表征以及第二嵌入表征与真实语音的第一标准嵌入表征以及第二标准嵌入表征之间的相似度超过相似度阈值时,即可确定待检测语音为真实语音;当第一嵌入表征以及第二嵌入表征与真实语音的第一标准嵌入表征以及第二标准嵌入表征之间的相似度没有超过相似度阈值时,即可确定待检测语音为伪造语音。
[0093]
其中,真实语音的第一标准嵌入表征和第二标准嵌入表征的获取方式与待检测语音的第一嵌入表征和第二嵌入表征的获取方式相同。在一个具体的应用场景中,可以将对真实语音进行特征提取,得到至少一个初始真伪特征以及至少一个初始声纹特征,再通过语音检测模型将至少一个初始真伪特征以及至少一个初始声纹特征进行特征融合,得到融合特征,分别对融合特征进行特征抽取,得到真实语音的第一标准嵌入表征以及第二标准嵌入表征。
[0094]
其中,本实施例的语音检测模型为采用上述任意一实施例的语音检测方法训练得到的语音检测模型。
[0095]
通过上述步骤,本实施例的语音检测方法通过先将至少一个初始真伪特征以及至少一个初始声纹特征进行特征融合,得到融合特征,再分别对融合特征进行特征抽取,得到第一嵌入表征以及第二嵌入表征,基于第一嵌入表征以及第二嵌入表征与真实语音的第一标准嵌入表征以及第二标准嵌入表征之间的相似度确定待检测语音的真伪。本实施例通过综合了初始真伪特征与初始声纹特征的融合特征进行特征抽取,能够利用更广泛的声学特征来抽取更丰富的嵌入表征,提高了通过嵌入表征进行语音预测的可靠性,从而提高了语音检测模型的检测效率和效果,进而提高了语音检测模型对语音进行预测的准确性和可靠性。
[0096]
在其他实施例中,基于第一嵌入表征以及第二嵌入表征与真实语音的第一标准嵌入表征以及第二标准嵌入表征之间的相似度确定待检测语音的真伪的步骤还可以包括,将待检测语音的第一嵌入表征和第二嵌入表征与真实语音的第一标准嵌入表征以及第二标准嵌入表征分别计算余弦相似度,具体地,计算待检测语音的第一嵌入表征与真实语音的第一标准嵌入表之间的余弦相似度p1,以及计算待检测语音的第二嵌入表征与真实语音的第二标准嵌入表征之间的余弦相似度p2,然后将p1与p2进行相乘得到最终的真伪音得分p3。将真伪音得分p3与相似度阈值p进行对比,当真伪音得分p3超过相似度阈值p时,确定样本语音为真实语音,否则为伪造语音。其中,通过相似度阈值p的设置高低可以控制整体语音伪造检测的虚警和漏警率的平衡,相似度阈值p的具体数值可以基于实际需求进行设置,在此不做限定。
[0097]
请参阅图4,图4是本技术电子设备一实施例的框架示意图。电子设备40包括相互耦接的存储器41和处理器42,处理器42用于执行存储器41中存储的程序指令,以实现上述任一语音检测方法实施例的步骤或语音检测模型的训练方法实施例的步骤。在一个具体的实施场景中,电子设备40可以包括但不限于:微型计算机、服务器,此外,电子设备40还可以
包括笔记本电脑、平板电脑等移动设备,在此不做限定。
[0098]
具体而言,处理器42用于控制其自身以及存储器41以实现上述任一语音检测方法实施例的步骤。处理器42还可以称为cpu(central processing unit,中央处理单元)。处理器42可能是一种集成电路芯片,具有信号的处理能力。处理器42还可以是通用处理器、数字信号处理器(digital signal processor,dsp)、专用集成电路(application specific integrated circuit,asic)、现场可编程门阵列(field
‑
programmable gate array,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。另外,处理器42可以由集成电路芯片共同实现。
[0099]
上述方案,能够提高训练后的语音检测模型对语音进行预测的准确性和可靠性。
[0100]
请参阅图5,图5为本技术计算机可读存储介质一实施例的框架示意图。计算机可读存储介质50存储有能够被处理器运行的程序指令501,程序指令501用于实现上述任一语音检测方法实施例的步骤或语音检测模型的训练方法实施例的步骤。
[0101]
上述方案,能够提高训练后的语音检测模型对语音进行预测的准确性和可靠性。
[0102]
在本技术所提供的几个实施例中,应该理解到,所揭露的方法和装置,可以通过其它的方式实现。例如,以上所描述的装置实施方式仅仅是示意性的,例如,模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性、机械或其它的形式。
[0103]
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施方式方案的目的。
[0104]
另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0105]
集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本技术各个实施方式方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read
‑
only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

