1.本发明涉及人工智能(ai,artificial intelligence)技术领域,尤其涉及一种智能语音助手的处理方法及装置。
背景技术:
2.人工智能是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法和技术及应用系统。
3.随着人工智能技术的发展,各种各样的智能语音助手产品得到了广泛的应用,相关技术中,开发的智能语音助手通常具有固定的虚拟形象,或者无对应的虚拟形象,仅为一个与用户之间进行语音交互的使用工具而已,不能满足用户对智能语音助手的虚拟形象的个性化需求;且智能语音助手在与用户交互的过程中,智能语音助手的虚拟形象缺乏情感表达,降低用户对应用智能语音助手产品的好感度及用户粘度。
技术实现要素:
4.有鉴于此,本发明实施例提供一种智能语音助手的处理方法及装置,能够在满足用户对智能语音助手的虚拟形象的个性化需求的同时,增强虚拟形象的人性化交互。
5.本发明实施例的技术方案是这样实现的:
6.本发明实施例提供一种智能语音助手的处理方法,所述方法包括:
7.获取对应目标用户的语音指令;
8.发送所述语音指令,以对所述语音指令进行特征提取,得到对应所述目标用户的生物特征参数,以及对所述语音指令进行情感识别,得到对应所述目标用户的当前情感类别;
9.接收返回的与所述生物特征参数对应的智能语音助手的虚拟形象标识,以及与所述目标用户的当前情感类别匹配、且对应所述虚拟形象标识的虚拟情绪;
10.呈现所述虚拟形象标识所指示的所述智能语音助手的虚拟形象;
11.响应于基于所述智能语音助手触发的交互指令,控制所述智能语音助手的虚拟形象以所述虚拟情绪的方式,播放符合所述交互指令的语音。
12.上述方案中,所述方法还包括:
13.将所述目标用户的标识,以及与所述目标用户的标识对应的所述智能语音助手的虚拟形象发送至区块链网络中,以使
14.所述区块链网络的节点将所述目标用户的标识,以及与所述目标用户的标识对应的所述智能语音助手的虚拟形象填充至新区块,且当对所述新区块取得共识一致时,将所述新区块追加至区块链的尾部。
15.本发明实施例还提供另一种智能语音助手的处理方法,所述方法包括:
16.接收客户端发送的目标用户的语音指令;
17.对所述语音指令进行特征提取,得到对应所述目标用户的生物特征参数,以及对
所述语音指令进行情感识别,得到对应所述目标用户的当前情感类别;
18.确定与所述生物特征参数对应的智能语音助手的虚拟形象标识,以及与所述目标用户的当前情感类别匹配、且对应所述虚拟形象标识的虚拟情绪;
19.发送所述虚拟形象标识及虚拟情绪至所述客户端,以使所述客户端呈现所述虚拟形象标识所指示的所述智能语音助手的虚拟形象,并响应于基于所述智能语音助手触发的交互指令,控制所述智能语音助手的虚拟形象以所述虚拟情绪的方式,播放符合所述交互指令的语音。
20.本发明实施例还提供一种智能语音助手的处理装置,所述装置包括:
21.获取单元,用于获取对应目标用户的语音指令;
22.第一发送单元,用于发送所述语音指令,以对所述语音指令进行特征提取,得到对应所述目标用户的生物特征参数,以及对所述语音指令进行情感识别,得到对应所述目标用户的当前情感类别;
23.第一接收单元,用于接收返回的与所述生物特征参数对应的智能语音助手的虚拟形象标识,以及与所述目标用户的当前情感类别匹配、且对应所述虚拟形象标识的虚拟情绪;
24.呈现单元,用于呈现所述虚拟形象标识所指示的所述智能语音助手的虚拟形象;
25.控制单元,用于响应于基于所述智能语音助手触发的交互指令,控制所述智能语音助手的虚拟形象以所述虚拟情绪的方式,播放符合所述交互指令的语音。
26.上述方案中,所述装置还包括:
27.第三接收单元,用于在所述第一接收单元接收返回的与所述生物特征参数对应的智能语音助手的虚拟形象标识之前,接收返回的语音识别指令,所述语音识别指令表征针对客户端中是否已记录所述生物特征参数的判断结果;
28.第三发送单元,用于当所述判断结果为所述客户端中已记录所述生物特征参数时,发送第一提示消息至所述目标用户,以提示所述目标用户确认自身的生物特征账号;
29.第四发送单元,用于当所述判断结果为所述客户端中未记录所述生物特征参数时,发送第二提示消息至所述目标用户,以提示所述目标用户选择所述智能语音助手的虚拟形象;
30.存储单元,用于将所选择的所述智能语音助手的虚拟形象存储于服务器的数据库中。
31.上述方案中,所述第四发送单元,还用于:
32.响应于所述目标用户基于所述第二提示消息触发的所述智能语音助手的虚拟形象的设置请求,呈现供选择所述智能语音助手的虚拟形象的虚拟形象选择界面;
33.响应于基于所述虚拟形象选择界面触发的虚拟形象选择指令,获取符合所述目标用户的偏好的所述智能语音助手的虚拟形象。
34.上述方案中,所述第一接收单元,还用于:
35.向服务器提交对应所述智能语音助手的虚拟形象获取请求,以使
36.所述服务器基于所述目标用户的生物特征参数,在数据库中查询适配于所述生物特征参数的所述智能语音助手的虚拟形象标识,所述数据库中存储有多个目标用户的生物特征参数与虚拟形象标识的对应关系;
37.接收所述服务器下发的适配于所述生物特征参数的所述智能语音助手的虚拟形象标识。
38.上述方案中,所述呈现单元,还用于:
39.基于所述虚拟形象标识的指示,确定对应所述智能语音助手的虚拟形象;
40.获取对应所述智能语音助手的虚拟形象的形象资源;
41.基于所述形象资源呈现所述智能语音助手的虚拟形象的默认形象,所述虚拟形象的默认形象包括以下至少之一:所述虚拟形象的默认皮肤;所述虚拟形象的默认道具。
42.上述方案中,所述控制单元,还用于:
43.获取所述目标用户基于所述智能语音助手触发的交互指令,并发送所述交互指令至服务器,以使
44.所述交互指令包括语音交互指令时,所述服务器对所述语音交互指令进行语音识别得到相应的文本信息,对所述文本信息进行语义识别,得到对应所述语音交互指令的意图;
45.接收返回的所述语音交互指令的意图,基于对应所述语音交互指令的意图的控制指令,控制所述智能语音助手的虚拟形象以所述虚拟情绪的方式,播放符合所述交互指令的语音。
46.上述方案中,所述装置还包括:
47.第四接收单元,用于接收返回的对应所述虚拟形象标识的情绪动画,所述情绪动画为服务器基于所述目标用户的当前情感类别生成;
48.所述呈现单元,还用于在呈现所述虚拟形象标识所指示的所述智能语音助手的虚拟形象时,呈现对应所述虚拟形象标识的情绪动画。
49.上述方案中,所述装置还包括:
50.第五发送单元,用于将所述目标用户的标识,以及与所述目标用户的标识对应的所述智能语音助手的虚拟形象发送至区块链网络中,以使
51.所述区块链网络的节点将所述目标用户的标识,以及与所述目标用户的标识对应的所述智能语音助手的虚拟形象填充至新区块,且当对所述新区块取得共识一致时,将所述新区块追加至区块链的尾部。
52.本发明实施例还提供另一种智能语音助手的处理装置,所述装置包括:
53.第二接收单元,用于接收客户端发送的目标用户的语音指令;
54.提取单元,用于对所述语音指令进行特征提取,得到对应所述目标用户的生物特征参数;
55.识别单元,用于对所述语音指令进行情感识别,得到对应所述目标用户的当前情感类别;
56.确定单元,用于确定与所述生物特征参数对应的智能语音助手的虚拟形象标识,以及与所述目标用户的当前情感类别匹配、且对应所述虚拟形象标识的虚拟情绪;
57.第二发送单元,用于发送所述虚拟形象标识及虚拟情绪至所述客户端,以使所述客户端呈现所述虚拟形象标识所指示的所述智能语音助手的虚拟形象,并响应于基于所述智能语音助手触发的交互指令,控制所述智能语音助手的虚拟形象以所述虚拟情绪的方式,播放符合所述交互指令的语音。
58.本发明实施例还提供一种智能语音助手的处理设备,所述设备包括:
59.存储器,用于存储可执行指令;
60.处理器,用于执行所述存储器中存储的可执行指令时,实现本发明实施例提供的智能语音助手的处理方法。
61.本发明实施例还提供一种计算机可读存储介质,存储有可执行指令,所述可执行指令被处理器执行时,用于实现本发明实施例提供的智能语音助手的处理方法。
62.应用本发明上述实施例具有以下有益效果:
63.客户端通过发送目标用户的语音指令至服务器,以使服务器对语音指令进行特征提取,得到对应目标用户的生物特征参数;接收服务器返回的与生物特征参数对应的智能语音助手的虚拟形象标识;如此,基于目标用户的生物特征参数的唯一性和独特性,使各目标用户都有自己专属的智能语音助手的虚拟形象,能够满足目标用户对智能语音助手的虚拟形象的个性化需求;终端呈现虚拟形象标识所指示的智能语音助手的虚拟形象,使得智能语音助手的虚拟形象具有可视化效果;
64.通过接收返回的与目标用户的当前情感类别匹配、且对应虚拟形象标识的虚拟情绪,以及响应于基于智能语音助手触发的交互指令,控制智能语音助手的虚拟形象以虚拟情绪的方式,播放符合交互指令的语音;如此,在智能语音助手与目标用户交互的过程中,增加智能语音助手的虚拟形象的情感表达,以增强虚拟形象的人性化交互,从而能够提高目标用户对应用智能语音助手产品的好感度及用户粘度,提升目标用户的使用体验。
附图说明
65.图1为本发明实施例提供的智能语音助手的处理系统10的一个可选的架构示意图;
66.图2a为本发明实施例提供的智能语音助手的处理设备40的一个可选的硬件结构示意图;
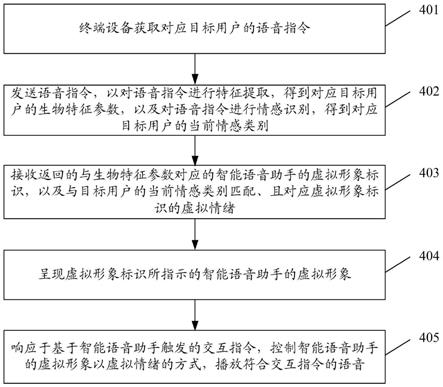
67.图2b为本发明实施例提供的智能语音助手的处理设备50的另一个可选的硬件结构示意图;
68.图3a为本发明实施例提供的智能语音助手的处理装置455的一个可选的组成结构示意图;
69.图3b为本发明实施例提供的智能语音助手的处理装置555的一个可选的组成结构示意图;
70.图4为本发明实施例提供的智能语音助手的处理方法的一个可选的流程示意图;
71.图5为本发明实施例提供的终端设备呈现语音指令编辑入口的一个可选的界面示意图;
72.图6为本发明实施例提供的终端设备呈现第二提示消息的一个可选的界面示意图;
73.图7为本发明实施例提供的呈现虚拟形象选择界面的一个可选的示意图;
74.图8为本发明实施例提供的对目标用户进行身份确认的一个可选的示意图;
75.图9为本发明实施例提供的对目标用户进行特定名称确认的一个可选的示意图;
76.图10为本发明实施例提供的区块链网络的应用架构示意图;
77.图11为本发明实施例提供的区块链网络81中区块链的一个可选的结构示意图;
78.图12为本发明实施例提供的区块链网络81的功能架构示意图;
79.图13为本发明实施例提供的智能语音助手的处理方法的另一个可选的流程示意图;
80.图14为本发明实施例提供的智能语音助手的处理方法的另一个可选的流程示意图;
81.图15为本发明实施例提供的智能语音助手的虚拟形象设置的一个可选的流程示意图;
82.图16为本发明实施例提供的虚拟形象的虚拟情绪回馈过程的一个可选的流程示意图;
83.图17为本发明实施例提供的基于声纹的个性化虚拟形象帐号系统的一个可选的流程示意图;
84.图18为本发明实施例提供的虚拟形象的虚拟情绪回馈过程的另一个可选的流程示意图。
具体实施方式
85.为了使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述,所描述的实施例不应视为对本发明的限制,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
86.在以下的描述中,涉及到“一些实施例”,其描述了所有可能实施例的子集,但是可以理解,“一些实施例”可以是所有可能实施例的相同子集或不同子集,并且可以在不冲突的情况下相互结合。
87.在以下的描述中,所涉及的术语“第一”、“第二”等仅仅是用于区别类似的对象,不代表针对对象的特定的顺序或先后次序,可以理解地,“第一”、“第二”等在允许的情况下可以互换特定的顺序或先后次序,以使这里描述的本发明实施例能够以除了在这里图示或描述的以外的顺序实施。
88.除非另有定义,本发明实施例所使用的所有的技术和科学术语与属于本发明实施例的技术领域的技术人员通常理解的含义相同。本发明实施例中所使用的术语只是为了描述具体的实施例的目的,不是旨在限制本发明。
89.在对本发明实施例进行进一步详细说明之前,先对本发明实施例中涉及的名词和术语进行说明,本发明实施例中涉及的名词和术语适用于如下的解释。
90.1)智能语音助手,是一款智能型的终端应用,通过智能对话与即时问答的智能交互,实现帮助用户解决问题,也即用户可使用自然的对话与终端中的智能语音助手进行智能语音交互,利用自然语言处理技术,实现了基于语音输入的交互模式,通过智能语音交互就可以得到反馈结果。
91.2)自然语言处理,是研究计算机处理人类语言的一门技术,包括但不限于句法语义分析、信息抽取、文本挖掘、机器翻译、信息检索、问答系统及对话系统。
92.3)皮肤,表示用于智能语音助手的虚拟形象的装饰品,可以包括衣服、装备等等,可用于装饰各个虚拟形象。
93.4)道具,表示用于搭配智能语音助手的虚拟形象所使用的武器、工具等等。
94.5)响应于,用于表示所执行的操作所依赖的条件或者状态,当满足所依赖的条件或状态时,所执行的一个或多个操作可以是实时的,也可以具有设定的延迟;在没有特别说明的情况下,所执行的多个操作不存在执行先后顺序的限制。
95.6)交易(transaction),等同于计算机术语“事务”,交易包括了需要提交到区块链网络执行的操作,并非单指商业语境中的交易,鉴于在区块链技术中约定俗成地使用了“交易”这一术语,本发明实施例遵循了这一习惯。
96.例如,部署(deploy)交易用于向区块链网络中的节点安装指定的智能合约并准备好被调用;调用(invoke)交易用于通过调用智能合约在区块链中追加交易的记录,并对区块链的状态数据库进行操作,包括更新操作(包括增加、删除和修改状态数据库中的键值(key-value)对)和查询操作(即查询状态数据库中的键值对)。
97.7)区块链(block chain),是由区块(block)形成的加密的、链式的交易的存储结构。
98.例如,每个区块的头部既可以包括区块中所有交易的哈希值,同时也包含前一个区块中所有交易的哈希值,从而基于哈希值实现区块中交易的防篡改和防伪造;新产生的交易被填充到区块并经过区块链网络中节点的共识后,会被追加到区块链的尾部从而形成链式的增长。
99.8)区块链网络(block chain network),通过共识的方式将新区块纳入区块链的一系列的节点的集合。
100.9)账本(ledger),是区块链(也称为账本数据)和与区块链同步的状态数据库的统称。
101.其中,区块链是以文件系统中的文件的形式来记录交易;状态数据库是以不同类型的键(key)值(value)对的形式来记录区块链中的交易,用于支持对区块链中交易的快速查询。
102.10)智能合约(smart contracts),也称为链码(chain code)或应用代码,部署在区块链网络的节点中的程序,该程序是根据条件而触发执行的,节点执行接收的交易中所调用的智能合约,来对状态数据库的键值对数据进行更新或查询的操作。
103.11)共识(consensus),是区块链网络中的一个过程,用于在涉及的多个节点之间对区块中的交易达成一致,达成一致的区块将被追加到区块链的尾部,实现共识的机制包括工作量证明(pow,proof of work)、权益证明(pos,proof of stake)、股份授权证明(dpos,delegated proof-of-stake)、消逝时间量证明(poet,proof of elapsed time)等。
104.本发明实施例提供的智能语音助手的处理方法涉及人工智能领域中的语音技术(speech technology)和自然语言处理(nlp,nature language processing)技术,其中,语音技术的关键技术包括自动语音识别技术(asr,automatic speech recognition)和语音合成技术(tts,text to speech)以及声纹识别技术,让计算机能听、能看、能说和能感觉,是未来人机交互的发展方向,其中语音成为未来最被看好的人机交互方式之一;自然语言处理是计算机科学领域与人工智能领域中的一个重要方向,它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学,因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以
它与语言学的研究有着密切的联系,自然语言处理技术通常包括文本处理、语义理解、机器翻译、机器人问答和知识图谱等技术。
105.本发明实施例通过人工智能技术,基于目标用户的生物特征参数的唯一性和独特性,使各目标用户都有自己专属的智能语音助手的虚拟形象,能够满足目标用户对智能语音助手的虚拟形象的个性化需求;通过终端呈现虚拟形象标识所指示的智能语音助手的虚拟形象,使得智能语音助手的虚拟形象具有可视化效果;在智能语音助手与目标用户交互的过程中,增加智能语音助手的虚拟形象的情感表达,以增强虚拟形象的人性化交互,从而能够提高目标用户对应用智能语音助手产品的好感度及用户粘度,提升目标用户的使用体验。
106.下面说明实施本发明实施例的智能语音助手的处理方法的智能语音助手的处理设备的示例性应用,本发明实施例提供的智能语音助手的处理设备可以实施为笔记本电脑,平板电脑,台式计算机,智能电视机,移动设备(例如,移动电话,便携式音乐播放器,个人数字助理,专用消息设备,便携式游戏设备)等各种类型的具有显示屏幕的终端设备,也可以实施为服务器,当然,还可以为终端设备和服务器协同实施,其中,服务器可以为云端服务器,但本发明实施例中并不仅限于云端服务器。
107.下面以终端设备和服务器协同实施为例,参考附图对本发明实施例的智能语音助手的处理系统的示例性应用进行说明。参见图1,图1为本发明实施例提供的智能语音助手的处理系统10的一个可选的架构示意图,为实现支撑的一个示例性应用,终端100(示例性示出了终端100-1和终端100-2)通过网络200连接服务器300,网络200可以是广域网或者局域网,又或者是二者的组合,使用无线链路实现数据传输。
108.在一些实施例中,终端100(如终端100-1),用于获取对应目标用户的语音指令,并向服务器300发送对应目标用户的语音指令;这里,在实际应用中,服务器300既可以为单独配置的支持各种业务的一个服务器,亦可以配置为一个服务器集群。
109.服务器300,用于对接收到的语音指令进行特征提取,得到对应目标用户的生物特征参数,以及对语音指令进行情感识别,得到对应目标用户的当前情感类别;确定并发送与生物特征参数对应的智能语音助手的虚拟形象标识,以及与目标用户的当前情感类别匹配、且对应虚拟形象标识的虚拟情绪。
110.终端100(如终端100-1),还用于接收服务器300返回的智能语音助手的虚拟形象标识,以及与目标用户的当前情感类别匹配、且对应虚拟形象标识的虚拟情绪;终端100还可以在图形界面110(例如终端100-1的图形界面110-1和终端100-2的图形界面110-2)中呈现虚拟形象标识所指示的智能语音助手的虚拟形象;以及响应于基于智能语音助手触发的交互指令,控制智能语音助手的虚拟形象以虚拟情绪的方式,播放符合交互指令的语音。通过上述方案,可以使各目标用户都有自己专属的智能语音助手的虚拟形象,另外还增加了智能语音助手的虚拟形象的情感表达,能够在满足用户对智能语音助手的虚拟形象的个性化需求的同时,增强虚拟形象的人性化交互。
111.接下来继续对实施本发明实施例的智能语音助手的处理方法的智能语音助手的处理设备的硬件结构进行说明。该智能语音助手的处理设备可以实施为终端设备,还可以实施为服务器,当然还可以为上述图1示出的终端设备和服务器的协同实施。
112.参见图2a,图2a为本发明实施例提供的智能语音助手的处理设备40的一个可选的
硬件结构示意图,可以理解,图2a仅仅示出了智能语音助手的处理设备的示例性结构而非全部结构,根据需要可以实施图2a示出的部分结构或全部结构。以智能语音助手的处理设备40为设置在终端设备中的客户端为例,本发明实施例提供的智能语音助手的处理设备40可以包括:至少一个处理器410、存储器450、至少一个网络接口420和用户接口430。智能语音助手的处理设备40中的各个组件通过总线系统440耦合在一起。可以理解,总线系统440用于实现这些组件之间的连接通信。总线系统440除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。但是为了清楚说明起见,在图2a中将各种总线都标为总线系统440。
113.处理器410可以是一种集成电路芯片,具有信号的处理能力,例如通用处理器、数字信号处理器(dsp,digital signal processor),或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等,其中,通用处理器可以是微处理器或者任何常规的处理器等。
114.用户接口430包括使得能够呈现媒体内容的一个或多个输出装置431,包括一个或多个扬声器和/或一个或多个视觉显示屏。用户接口430还包括一个或多个输入装置432,包括有助于用户输入的用户接口部件,比如键盘、鼠标、麦克风、触屏显示屏、摄像头、其他输入按钮和控件。
115.存储器450可以是可移除的,不可移除的或其组合。示例性的硬件设备包括固态存储器,硬盘驱动器,光盘驱动器等。存储器450可选地包括在物理位置上远离处理器410的一个或多个存储设备。
116.存储器450包括易失性存储器或非易失性存储器,也可包括易失性和非易失性存储器两者。非易失性存储器可以是只读存储器(rom,read only memory),易失性存储器可以是随机存取存储器(ram,random access memory)。本发明实施例描述的存储器450旨在包括任意适合类型的存储器。
117.在一些实施例中,存储器450能够存储数据以支持各种操作,这些数据的示例包括程序、模块和数据结构或者其子集或超集,下面示例性说明。
118.操作系统451,包括用于处理各种基本系统服务和执行硬件相关任务的系统程序,例如框架层、核心库层、驱动层等,用于实现各种基础业务以及处理基于硬件的任务;
119.网络通信模块452,用于经由一个或多个(有线或无线)网络接口420到达其他计算设备,示例性的网络接口420包括:蓝牙、无线相容性认证(wifi)、和通用串行总线(usb,universal serial bus)等;
120.呈现模块453,用于经由一个或多个与用户接口430相关联的输出装置431(例如,显示屏、扬声器等)使得能够呈现信息(例如,用于操作外围设备和显示内容和信息的用户接口);
121.输入处理模块454,用于对一个或多个来自一个或多个输入装置432之一的一个或多个用户输入或互动进行检测以及翻译所检测的输入或互动。
122.在一些实施例中,本发明实施例提供的智能语音助手的处理装置可以采用软件方式实现,图2a示出了存储在存储器450中的智能语音助手的处理装置455,其可以是程序和插件等形式的软件,包括一系列的软件模块,参见图3a,图3a为本发明实施例提供的智能语音助手的处理装置455的一个可选的组成结构示意图,例如,本发明实施例提供的智能语音
助手的处理装置455可以包括:获取单元4551、第一发送单元4552、第一接收单元4553、呈现单元4554和控制单元4555,这些单元的功能是逻辑上的,因此,根据各软件模块所实现的功能可以进行任意的组合或进一步的拆分。这里,需要说明的是,对于图3a所示的本发明实施例提供的智能语音助手的处理装置455中的各个单元的具体功能,将在下文进行说明。
123.参见图2b,图2b为本发明实施例提供的智能语音助手的处理设备50的另一个可选的硬件结构示意图,可以理解,图2b仅仅示出了智能语音助手的处理设备的示例性结构而非全部结构,根据需要可以实施图2b示出的部分结构或全部结构。以智能语音助手的处理设备50为服务器为例,本发明实施例提供的智能语音助手的处理设备50可以包括:至少一个处理器510、存储器550、至少一个网络接口520和用户接口530。智能语音助手的处理设备50中的各个组件通过总线系统540耦合在一起。可以理解,总线系统540用于实现这些组件之间的连接通信。总线系统540除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。但是为了清楚说明起见,在图2b中将各种总线都标为总线系统540。
124.用户接口530包括使得能够呈现媒体内容的一个或多个输出装置531,包括一个或多个扬声器和/或一个或多个视觉显示屏。用户接口530还包括一个或多个输入装置532,包括有助于用户输入的用户接口部件,比如键盘、鼠标、麦克风、触屏显示屏、摄像头、其他输入按钮和控件。
125.在一些实施例中,存储器550能够存储数据以支持各种操作,这些数据的示例包括程序、模块和数据结构或者其子集或超集,下面示例性说明。
126.操作系统551,包括用于处理各种基本系统服务和执行硬件相关任务的系统程序,例如框架层、核心库层、驱动层等,用于实现各种基础业务以及处理基于硬件的任务;
127.网络通信模块552,用于经由一个或多个(有线或无线)网络接口520到达其他计算设备,示例性的网络接口520包括:蓝牙、无线相容性认证(wifi)、和通用串行总线(usb,universal serial bus)等;
128.呈现模块553,用于经由一个或多个与用户接口530相关联的输出装置531(例如,显示屏、扬声器等)使得能够呈现信息(例如,用于操作外围设备和显示内容和信息的用户接口);
129.输入处理模块554,用于对一个或多个来自一个或多个输入装置532之一的一个或多个用户输入或互动进行检测以及翻译所检测的输入或互动。
130.在一些实施例中,本发明实施例提供的智能语音助手的处理装置可以采用软件方式实现,图2b示出了存储在存储器550中的智能语音助手的处理装置555,其可以是程序和插件等形式的软件,包括一系列的软件模块,参见图3b,图3b为本发明实施例提供的智能语音助手的处理装置555的一个可选的组成结构示意图,例如,本发明实施例提供的智能语音助手的处理装置555可以包括:第二接收单元5551、提取单元5552、识别单元5553、确定单元5554和第二发送单元5555,这些单元的功能是逻辑上的,因此,根据各软件模块所实现的功能可以进行任意的组合或进一步的拆分。这里,需要说明的是,对于图3b所示的本发明实施例提供的智能语音助手的处理装置555中的各个单元的具体功能,将在下文进行说明。
131.在另一些实施例中,本发明实施例提供的智能语音助手的处理装置455(或者智能语音助手的处理装置555)可以采用硬件方式实现,作为示例,本发明实施例提供的智能语音助手的处理装置455(或者智能语音助手的处理装置555)可以是采用硬件译码处理器形
式的处理器,其被编程以执行本发明实施例提供的智能语音助手的处理方法,例如,硬件译码处理器形式的处理器可以采用一个或多个应用专用集成电路(asic,application specific integrated circuit)、dsp、可编程逻辑器件(pld,programmable logic device)、复杂可编程逻辑器件(cpld,complex programmable logic device)、现场可编程门阵列(fpga,field-programmable gate array)或其他电子元件。
132.基于上述对本发明实施例提供的智能语音助手的处理系统及智能语音助手的处理设备的示例性应用和实施的说明,接下来对本发明实施例提供的智能语音助手的处理方法的实现进行说明。
133.参见图4,图4为本发明实施例提供的智能语音助手的处理方法的一个可选的流程示意图,在一些实施例中,该智能语音助手的处理方法可由终端设备实施,或者由服务器实施,又或者由终端设备及服务器协同实施,终端设备中设置有客户端,下面以终端设备实施为例,如通过图1中的终端100实施,结合图4示出的步骤进行说明。
134.在步骤401中,终端设备获取对应目标用户的语音指令。
135.在本发明实施例中,终端设备可通过如下方式获取对应目标用户的语音指令:响应于基于客户端的用户界面触发的语音指令输入操作,获取目标用户输入的语音指令。
136.这里,在实际实施时,终端设备通过用户界面呈现语音指令编辑入口,使得目标用户可通过该入口进行语音指令的编辑。示例性的,终端设备可通过图标的形式在用户界面中呈现语音指令编辑入口,目标用户通过点击终端设备呈现的图标触发语音指令的编辑指令,进入语音指令编辑页面。
137.参见图5,图5为本发明实施例提供的终端设备呈现语音指令编辑入口的一个可选的界面示意图,终端设备的用户页面中呈现“语音指令”的图标,目标用户可通过点击该图标触发进入语音指令编辑页面,在语音指令编辑页面执行对语音指令的输入操作,以获取目标用户输入的语音指令。
138.在步骤402中,发送语音指令,以对语音指令进行特征提取,得到对应目标用户的生物特征参数,以及对语音指令进行情感识别,得到对应目标用户的当前情感类别。
139.这里,在实际实施时,终端设备将发送语音指令至服务器,以使服务器对语音指令进行特征提取,得到对应目标用户的生物特征参数,在本发明实施例中,由于各目标用户具有差异化,可利用目标用户的生物特征参数的唯一性和独特性区分不同的目标用户;其中,生物特征参数包括但不限于声纹特征参数、人脸特征参数、虹膜特征参数等。
140.在一些实施例中,服务器在得到对应目标用户的生物特征参数后,可基于目标用户的生物特征参数生成对应的智能语音助手的虚拟形象标识,然后再将生成的智能语音助手的虚拟形象标识返回至终端设备。
141.在一些实施例中,服务器在基于目标用户的生物特征参数生成对应的智能语音助手的虚拟形象标识之前,还可以执行以下技术方案:基于生物特征参数对发起语音指令的目标用户的身份进行识别;当识别到目标用户为授权用户时,确定继续基于目标用户的生物特征参数生成对应的智能语音助手的虚拟形象标识;当识别到目标用户为非授权用户时,返回目标用户不具备操作权限的提示信息至终端设备。
142.具体来说,服务器在执行生成对应的智能语音助手的虚拟形象标识之前,将对语音指令的发起者进行授权认证,由于不同的目标用户可以使用相同的终端设备向服务器上
传语音指令,为了防止恶意用户在授权用户不知情的情形下使用该终端设备,服务器会对接收到的语音指令进行声纹识别,提取语音指令中目标用户的生物特征参数,例如声纹特征参数,通过声纹特征参数对发送语音指令的目标用户的身份进行识别,当目标用户为授权用户时,会继续基于目标用户的声纹特征参数生成对应的智能语音助手的虚拟形象标识,以确定智能语音助手的虚拟形象;当目标用户为非授权用户时,会提示该目标用户不具备操作权限,不能与智能语音助手进行交互,并在授权通过之前,不能基于声纹特征参数生成对应的智能语音助手的虚拟形象标识。
143.在实际实施时,终端设备将发送语音指令至服务器,以使服务器对语音指令进行情感识别,得到对应目标用户的当前情感类别,并生成与目标用户的当前情感类别匹配、且对应虚拟形象标识的虚拟情绪。这里,目标用户的当前情感类别可用于表示语音指令中所表达出来的目标用户的情感倾向,该情感倾向可以是三维度的特征,例如包括正面、中性及负面情感的三分类特征,当然,也可以是二维度的特征,即通过回归任务对目标用户输入的语音指令进行情感识别,直接预测目标用户的当前情感类别,是正面情感(比如开心类)还是负面情感(比如悲伤类)。
144.需要说明的是,服务器中预先存储有目标用户的情感类别与虚拟情绪的对应关系,基于该对应关系,可查询与目标用户的当前情感类别相匹配的虚拟情绪。
145.在步骤403中,接收返回的与生物特征参数对应的智能语音助手的虚拟形象标识,以及与目标用户的当前情感类别匹配、且对应虚拟形象标识的虚拟情绪。
146.在一些实施例中,终端设备可通过如下方式接收返回的与生物特征参数对应的智能语音助手的虚拟形象标识:
147.向服务器提交对应智能语音助手的虚拟形象获取请求,以使服务器基于目标用户的生物特征参数,在数据库中查询适配于生物特征参数的智能语音助手的虚拟形象标识;接收服务器下发的适配于生物特征参数的智能语音助手的虚拟形象标识。
148.在本发明实施例中,数据库中存储有多个目标用户的生物特征参数与虚拟形象标识的对应关系,在实际实施时,对于处于不同环境中的智能语音助手而言,由于智能语音助手所处环境中目标用户的用户数据有所不同,使得在同一环境中使用该智能语音助手的各目标用户,对智能语音助手的虚拟形象具有个性化的选择,将所选择的智能语音助手的虚拟形象的虚拟形象标识与目标用户的生物特征参数进行关联,并存储这两者的对应关系。
149.这里,用户数据可以是智能语音助手所处环境中至少一个维度的用户数据,其中,至少一个维度的用户数据包括以下至少之一:用户偏好、用户标签、用户角色等,例如,用户标签可以是基于目标用户的年龄段确定的,包括儿童标签、青年人标签、老年人标签;若智能语音助手所处环境为家庭,则用户角色可以是目标用户在该家庭中具有的属性,比如目标用户a为家庭中的儿童,目标用户a所对应的智能语音助手的虚拟形象标识可为小猪佩奇、美少女战士等卡通形象标识。
150.在一些实施例中,终端设备在接收返回的与生物特征参数对应的智能语音助手的虚拟形象标识之前,智能语音助手的处理方法还包括:
151.接收返回的语音识别指令,语音识别指令表征针对客户端中是否已记录生物特征参数的判断结果;当判断结果为客户端中已记录生物特征参数时,发送第一提示消息至目标用户,以提示目标用户确认自身的生物特征账号;当判断结果为客户端中未记录生物特
征参数时,发送第二提示消息至目标用户,以提示目标用户选择智能语音助手的虚拟形象,并将所选择的智能语音助手的虚拟形象存储于服务器的数据库中。
152.这里,在实际实施时,当在客户端中未找到记录的生物特征参数时,终端设备将呈现第二提示消息,或者发送第二提示消息至目标用户,该第二提示消息用于提示目标用户进行身份识别,以及选择智能语音助手的虚拟形象。示例性的,在图5的基础上还可呈现第二提示消息,参见图6,图6为本发明实施例提供的终端设备呈现第二提示消息的一个可选的界面示意图,如图6所示的第二提示消息的内容可以为“还不知道你是谁呢,可以进入个性化虚拟形象选择界面,选择心仪的智能语音助手的虚拟形象”。
153.在一些实施例中,终端设备可通过如下方式发送第二提示消息至目标用户,以提示目标用户选择智能语音助手的虚拟形象:响应于目标用户基于第二提示消息触发的智能语音助手的虚拟形象的设置请求,呈现供选择智能语音助手的虚拟形象的虚拟形象选择界面;响应于基于虚拟形象选择界面触发的虚拟形象选择指令,获取符合目标用户的偏好的智能语音助手的虚拟形象。
154.这里,在实际实施时,在虚拟形象选择界面中将呈现初始化的智能语音助手的虚拟形象(由终端系统自动设置),若目标用户对初始化的智能语音助手的虚拟形象很满意,则可将初始化的虚拟形象确定为符合目标用户的偏好的虚拟形象;若目标用户对初始化的智能语音助手的虚拟形象不是很满意,则可通过基于虚拟形象选择界面触发的虚拟形象选择指令,实现重新选择智能语音助手的虚拟形象。
155.参见图7,图7为本发明实施例提供的呈现虚拟形象选择界面的一个可选的示意图,在虚拟形象选择界面中可显示供目标用户进行搜索虚拟形象的搜索栏及搜索控件,箭头a指示的是搜索控件,箭头e指示的是搜索栏,或称为搜索框,目标用户可通过搜索栏输入虚拟形象的关键词,比如“萝莉”、“小猪佩奇”,然后通过点击搜索控件即可实现对自定义虚拟形象的搜索。在虚拟形象选择界面中还显示了左右两个方向的箭头控件,比如箭头b指示的左方向箭头控件和箭头c指示的右方向箭头控件,目标用户通过点击左方向箭头控件或右方向箭头控件,即可实现从虚拟形象列表中选择符合目标用户偏好的虚拟形象,其中,目标用户通过点击左方向箭头控件可进行向上翻页,返回上一个虚拟形象,通过点击右方向箭头控件可进行向下翻页,选择下一个虚拟形象。当目标用户对搜索的自定义虚拟形象或通过翻页选择的虚拟形象满意时,可通过点击箭头d指示的“确认”按钮,实现对搜索或选择的虚拟形象进行确认。
156.在本发明实施例中,当终端设备检测到目标用户搜索或选择好了虚拟形象后,还可对目标用户的生物特征参数如声纹特征参数进行匹配确认,以确认目标用户的身份。由于每个目标用户对应不同的声纹特征参数,那么,各目标用户专属的智能语音助手的虚拟形象将与其声纹特征参数存在对应关系。
157.示例性的,终端设备通过弹框提示目标用户输入一段语音数据,可实现对目标用户的声纹特征参数进行匹配确认。参见图8,图8为本发明实施例提供的对目标用户进行身份确认的一个可选的示意图,在终端设备的用户界面中呈现一个弹框,按照弹框的提示,目标用户通过用语音读以下文字内容“床前明月光,疑是地上霜”,当目标用户的语音与该文字内容完全一致时,则可确定目标用户的声纹特征参数匹配成功,表明目标用户的身份是合法的。
158.在实际实施时,当目标用户阅读完上述文字内容后,还可以通过语音输入的方式完成目标用户特定名称的设置。参见图9,图9为本发明实施例提供的对目标用户进行特定名称确认的一个可选的示意图,根据图9中呈现的特定名称确认的消息“你的专属助手来了,主人,你想要我怎么称呼您”,目标用户可以通过语音输入想要被称呼的名字,比如语音输入“请叫我大侠”,这样在后续的人机交互过程中,都会有专属的智能语音助手的虚拟形象与目标用户进行交互,且使用特定名称“大侠”对目标用户进行称呼。
159.在步骤404中,呈现虚拟形象标识所指示的智能语音助手的虚拟形象。
160.在一些实施例中,终端设备可通过如下方式呈现虚拟形象标识所指示的智能语音助手的虚拟形象:基于虚拟形象标识的指示,确定对应智能语音助手的虚拟形象;获取对应智能语音助手的虚拟形象的形象资源;基于形象资源呈现智能语音助手的虚拟形象的默认形象,虚拟形象的默认形象包括以下至少之一:虚拟形象的默认皮肤;虚拟形象的默认道具。
161.这里,对于虚拟形象的形象资源而言,可统一由美术资源提供方进行形象资源的开发,以保证虚拟形象的呈现质量,也就是说,终端设备获取的智能语音助手的虚拟形象的形象资源,为美术资源提供方上传的形象资源,其中,形象资源包括以下至少之一:场景资源,模型资源,皮肤资源和动作资源。这里的模型资源可以是二维的模型或是三维的模型,本发明实施例中在终端设备上呈现的是智能语音助手的虚拟形象的默认形象。
162.在一些实施例中,对于智能语音助手的虚拟形象,首次呈现在终端设备的显示界面上时,将以初始化的默认形象出现,初始化的默认形象可以包括虚拟形象首次呈现所处的默认场景,虚拟形象首次呈现所展示的皮肤,虚拟形象首次出现所佩戴的道具,以及围绕于虚拟形象的特效。
163.在一些实施例中,智能语音助手的处理方法还包括:接收返回的对应虚拟形象标识的情绪动画,情绪动画为服务器基于目标用户的当前情感类别生成;在呈现虚拟形象标识所指示的智能语音助手的虚拟形象时,呈现对应虚拟形象标识的情绪动画。
164.这里,在服务器中将存储对应虚拟形象标识的情绪动画包,比如可包括开心、庆祝、难过、安慰、撒娇等的情绪动画,当服务器基于语音指令得到对应目标用户的当前情感类别后,可查询与当前情感类别匹配的情绪动画,并将查询到的情绪动画返回至终端设备,以在终端设备的显示界面上呈现该情绪动画。需要说明的是,与当前情感类别匹配的情绪动画的数量可为一个或多个,在此不做限定。
165.在步骤405中,响应于基于智能语音助手触发的交互指令,控制智能语音助手的虚拟形象以虚拟情绪的方式,播放符合交互指令的语音。
166.在一些实施例中,终端设备可通过如下方式控制智能语音助手的虚拟形象以虚拟情绪的方式,播放符合交互指令的语音:
167.获取目标用户基于智能语音助手触发的交互指令,并发送交互指令至服务器,以使交互指令包括语音交互指令时,服务器对语音交互指令进行语音识别得到相应的文本信息,对文本信息进行语义识别,得到对应语音交互指令的意图;接收返回的语音交互指令的意图,基于对应语音交互指令的意图的控制指令,控制智能语音助手的虚拟形象以虚拟情绪的方式,播放符合交互指令的语音。
168.在本发明实施例中,对应语音交互指令的意图可包括以下至少之一:智能对话,设
备控制,车机留言,添加智能语音助手的道具,切换智能语音助手所处的场景,设置智能语音助手的活跃时间。
169.这里,终端设备向服务器上传对应智能语音助手的语音交互指令,当服务器接收到语音交互指令时,对语音交互指令进行语音识别,以将所接收到的语音转化为文本信息,在对经转化得到的文本信息进行语义分析,得到对应语音交互指令的意图,并将所得到的意图返回给终端设备。之后,终端设备就可基于对应语音交互指令的意图的控制指令,控制智能语音助手的虚拟形象以虚拟情绪的方式,播放符合交互指令的语音。
170.这里,智能对话包括聊天意图、知识问答意图、天气查询意图等;这里的设备控制包括通过车载系统上的智能语音助手客户端控制家具智能设备、在家里通过终端设备中的智能语音助手客户端控制车内的智能设备;车机留言指的是通过车载系统上的智能语音助手客户端向对应智能语音助手的智能产品发送留言。
171.这里,在实际实施时,可通过服务器中的文本转语音(tts,text-to-speech)模块对文本信息进行语义识别,以得到对应语音交互指令的意图。
172.为了便于对目标用户的专属智能语音助手的虚拟形象进行安全存储和不被篡改,在一些实施例中,智能语音助手的处理方法还包括:将目标用户的标识,以及与目标用户的标识对应的智能语音助手的虚拟形象发送至区块链网络中,以使区块链网络的节点将目标用户的标识,以及与目标用户的标识对应的智能语音助手的虚拟形象填充至新区块,且当对新区块取得共识一致时,将新区块追加至区块链的尾部。
173.这里,具体来说,在终端设备接收服务器返回的与生物特征参数对应的智能语音助手的虚拟形象标识,并确定虚拟形象标识所指示的智能语音助手的虚拟形象后,还可结合区块链技术,生成用于存储目标用户的标识,以及与目标用户的标识对应的智能语音助手的虚拟形象的交易,提交生成的交易至区块链网络的节点,以使区块链网络的节点对交易共识后存储目标用户的标识,以及与目标用户的标识对应的智能语音助手的虚拟形象至区块链网络。如此,将目标用户的标识,以及与目标用户的标识对应的智能语音助手的虚拟形象进行上链存储,实现记录的备份,从而保证目标用户的专属智能语音助手的虚拟形象的安全性。
174.接下来对本发明实施例中的区块链网络进行说明。参见图10,图10为本发明实施例提供的区块链网络的应用架构示意图,包括区块链网络81(示例性示出了共识节点810-1至共识节点810-3)、认证中心82、业务主体83和业务主体84,下面分别进行说明。
175.区块链网络81的类型是灵活多样的,例如可以为公有链、私有链或联盟链中的任意一种。以公有链为例,任何业务主体的电子设备例如用户终端和服务器(比如云端服务器),都可以在不需要授权的情况下接入区块链网络81;以联盟链为例,业务主体在获得授权后其下辖的电子设备(例如终端/服务器)可以接入区块链网络81,此时,成为区块链网络81中的客户端节点。
176.在一些实施例中,客户端节点可以只作为区块链网络81的观察者,即提供支持业务主体发起交易(例如,用于上链存储数据或查询链上数据)的功能,对于区块链网络81中的共识节点810的功能,例如排序功能、共识服务和账本功能等,客户端节点可以缺省或者有选择性(例如,取决于业务主体的具体业务需求)地实施。从而,可以将业务主体的数据和业务处理逻辑最大程度迁移到区块链网络81中,通过区块链网络81实现数据和业务处理过
程的可信和可追溯。
177.区块链网络81中的共识节点接收来自不同业务主体(例如图10中示出的业务主体83和业务主体84)的客户端节点(例如,图10中示出的归属于业务主体83的客户端节点410、以及归属于业务主体84的客户端节点510)提交的交易,执行交易以更新账本或者查询账本,执行交易的各种中间结果或最终结果可以返回业务主体的客户端节点中进行显示。
178.例如,客户端节点410/510可以订阅区块链网络81中感兴趣的事件,例如区块链网络81中特定的组织/通道中发生的交易,由共识节点810推送相应的交易通知至客户端节点410/510,从而触发客户端节点410/510中相应的业务逻辑。
179.下面以多个业务主体接入区块链网络以实现智能语音助手的虚拟形象的管理为例,说明区块链网络的示例性应用。参见图10,管理环节涉及的多个业务主体,如业务主体83可以是应用客户端,例如实施本发明实施例的智能语音助手的处理方法的客户端,从认证中心82进行登记注册获得数字证书,数字证书中包括业务主体的公钥、以及认证中心82对业务主体的公钥和身份信息签署的数字签名,用来与业务主体针对交易的数字签名一起附加到交易中,并被发送到区块链网络,以供区块链网络从交易中取出数字证书和签名,验证消息的可靠性(即是否未经篡改)和发送消息的业务主体的身份信息,区块链网络81将根据身份进行验证,例如是否具有发起交易的权限。业务主体下辖的电子设备(例如终端或者服务器)运行的客户端都可以向区块链网络81请求接入而成为客户端节点。
180.业务主体83的客户端节点410用于获取对应目标用户的语音指令,发送语音指令至服务器,以使服务器对语音指令进行特征提取,得到对应目标用户的生物特征参数;接收返回的与生物特征参数对应的智能语音助手的虚拟形象标识,并确定虚拟形象标识所指示的智能语音助手的虚拟形象,将目标用户的标识,以及与目标用户的标识对应的智能语音助手的虚拟形象发送至区块链网络81。
181.这里,将目标用户的标识,以及与目标用户的标识对应的智能语音助手的虚拟形象发送至区块链网络81,可以预先在客户端节点410设置业务逻辑,当基于目标用户的标识查找到对应的智能语音助手的虚拟形象时,客户端节点410将智能语音助手的虚拟形象自动发送至区块链网络81,也可以由业务主体83的业务人员在客户端节点410中登录,手动打包多个目标用户的标识对应的智能语音助手的虚拟形象,并将其发送至区块链网络81。在发送时,客户端节点410根据多个目标用户的标识对应的智能语音助手的虚拟形象生成对应更新操作的交易,在交易中指定了实现更新操作需要调用的智能合约、以及向智能合约传递的参数,交易中还携带了客户端节点410的数字证书、签署的数字签名(例如,使用客户端节点410的数字证书中的私钥,对交易的摘要进行加密得到),并将交易广播到区块链网络81中的共识节点810。
182.区块链网络81中的共识节点810接收到交易时,对交易携带的数字证书和数字签名进行验证,验证成功后,根据交易中携带的业务主体83的身份,确认业务主体83是否是具有交易权限,数字签名和权限验证中的任何一个验证判断都将导致交易失败。验证成功后签署节点810自己的数字签名(例如,使用节点810-1的私钥对交易的摘要进行加密得到),并继续在区块链网络81中广播。
183.区块链网络81中的共识节点810接收到验证成功的交易后,将交易填充到新的区块中并进行广播。区块链网络81中的共识节点810广播新区块时,将对新区块进行共识过
程,如果共识成功,则将新区块追加到自身所存储的区块链的尾部,并根据交易的结果更新状态数据库,执行新区块中的交易:对于提交更新目标用户的标识对应的智能语音助手的虚拟形象的交易,在状态数据库中添加包括目标用户的标识对应的智能语音助手的虚拟形象的键值对。
184.作为区块链的示例,参见图11,图11为本发明实施例提供的区块链网络81中区块链的一个可选的结构示意图,每个区块的头部既可以包括区块中所有交易的哈希值,同时也包含前一个区块中所有交易的哈希值,新产生的交易的记录被填充到区块并经过区块链网络中节点的共识后,将被追加到区块链的尾部从而形成链式的增长,各区块之间基于哈希值的链式结构,保证了区块中交易的防篡改和防伪造。
185.下面说明本发明实施例提供的区块链网络的示例性功能架构,参见图12,图12为本发明实施例提供的区块链网络81的功能架构示意图,包括应用层201、共识层202、网络层203、数据层204和资源层205,下面分别进行说明。
186.资源层205封装了实现区块链网络81中的各个节点810的计算资源、存储资源和通信资源。
187.数据层204封装了实现账本的各种数据结构,包括以文件系统中的文件实现的区块链,键值型的状态数据库和存在性证明(例如区块中交易的哈希树)。
188.网络层203封装了点对点(p2p,point to point)网络协议、数据传播机制和数据验证机制、接入认证机制和业务主体身份管理的功能。
189.其中,p2p网络协议实现区块链网络81中节点810之间的通信,数据传播机制保证了交易在区块链网络81中的传播,数据验证机制用于基于加密学方法(例如数字证书、数字签名、公/私钥对)实现节点810之间传输数据的可靠性;接入认证机制用于根据实际的业务场景对加入区块链网络81的业务主体的身份进行认证,并在认证通过时赋予业务主体接入区块链网络81的权限;业务主体身份管理用于存储允许接入区块链网络81的业务主体的身份、以及权限(例如能够发起的交易的类型)。
190.共识层202封装了区块链网络81中的节点810对区块达成一致性的机制(即共识机制)、交易管理和账本管理的功能。共识机制包括pos、pow和dpos等共识算法,支持共识算法的可插拔。
191.交易管理用于验证节点810接收到的交易中携带的数字签名,验证业务主体的身份信息,并根据身份信息判断确认其是否具有权限进行交易(从业务主体身份管理读取相关信息);对于获得接入区块链网络81的授权的业务主体而言,均拥有认证中心颁发的数字证书,业务主体利用自己的数字证书中的私钥对提交的交易进行签名,从而声明自己的合法身份。
192.账本管理用于维护区块链和状态数据库。对于取得共识的区块,追加到区块链的尾部;执行取得共识的区块中的交易,当交易包括更新操作时更新状态数据库中的键值对,当交易包括查询操作时查询状态数据库中的键值对并向业务主体的客户端节点返回查询结果。支持对状态数据库的多种维度的查询操作,包括:根据区块向量号(例如交易的哈希值)查询区块;根据区块哈希值查询区块;根据交易向量号查询区块;根据交易向量号查询交易;根据业务主体的账号(向量号)查询业务主体的账号数据;根据通道名称查询通道中的区块链。
193.应用层201封装了区块链网络能够实现的各种业务,包括交易的溯源、存证和验证等。
194.采用本发明实施例提供的智能语音助手的处理方法,一方面,基于目标用户的生物特征参数的唯一性和独特性,使各目标用户都有自己专属的智能语音助手的虚拟形象,能够满足目标用户对智能语音助手的虚拟形象的个性化需求;终端呈现虚拟形象标识所指示的智能语音助手的虚拟形象,使得智能语音助手的虚拟形象具有可视化效果;另一方面,在智能语音助手与目标用户交互的过程中,增加智能语音助手的虚拟形象的情感表达,以增强虚拟形象的人性化交互,从而能够提高目标用户对应用智能语音助手产品的好感度及用户粘度,提升目标用户的使用体验。
195.参见图13,图13为本发明实施例提供的智能语音助手的处理方法的另一个可选的流程示意图,在一些实施例中,该智能语音助手的处理方法可由终端设备实施,或者由服务器实施,又或者由终端设备及服务器协同实施,终端设备中设置有客户端,下面以服务器实施为例,结合图13示出的步骤进行说明。对于下文各步骤的说明中未尽的细节,可以参考上文而理解。
196.在步骤1201中,服务器接收客户端发送的目标用户的语音指令。
197.在一些实施例中,目标用户的语音指令可由客户端通过采用麦克风等语音采集设备实现语音指令的采集,然后客户端将采集到的目标用户的语音指令发送至服务器。
198.在步骤1202中,对语音指令进行特征提取,得到对应目标用户的生物特征参数,以及对语音指令进行情感识别,得到对应目标用户的当前情感类别。
199.在步骤1203中,确定与生物特征参数对应的智能语音助手的虚拟形象标识,以及与目标用户的当前情感类别匹配、且对应虚拟形象标识的虚拟情绪。
200.在一些实施例中,服务器在得到对应目标用户的生物特征参数后,可基于目标用户的生物特征参数生成对应的智能语音助手的虚拟形象标识,然后再将生成的智能语音助手的虚拟形象标识返回至终端设备。
201.在一些实施例中,服务器在基于目标用户的生物特征参数生成对应的智能语音助手的虚拟形象标识之前,还可以执行以下技术方案:基于生物特征参数对发起语音指令的目标用户的身份进行识别;当识别到目标用户为授权用户时,确定继续基于目标用户的生物特征参数生成对应的智能语音助手的虚拟形象标识;当识别到目标用户为非授权用户时,返回目标用户不具备操作权限的提示信息至终端设备。
202.需要说明的是,服务器中预先存储有目标用户的情感类别与虚拟情绪的对应关系,基于该对应关系,可查询与目标用户的当前情感类别相匹配的虚拟情绪。
203.在步骤1204中,发送虚拟形象标识及虚拟情绪至客户端,以使客户端呈现虚拟形象标识所指示的智能语音助手的虚拟形象,并响应于基于智能语音助手触发的交互指令,控制智能语音助手的虚拟形象以虚拟情绪的方式,播放符合交互指令的语音。
204.接下来,继续对本发明实施例提供的智能语音助手的处理方法进行说明,参见图14,图14为本发明实施例提供的智能语音助手的处理方法的另一个可选的流程示意图,在一些实施例中,该智能语音助手的处理方法可由终端设备实施,或者由终端设备及服务器协同实施,下面以终端设备及服务器协同实施为例,如通过图1中的终端100-1及服务器300协同实施,结合图14示出的步骤进行说明。对于下文各步骤的说明中未尽的细节,可以参考
上文而理解。
205.在步骤1301中,终端设备获取目标用户输入的语音指令。
206.在一些实施例中,终端设备可以采用麦克风等语音采集设备实现语音指令的采集,以获取目标用户输入的语音指令。其中,麦克风等语音采集设备可以设置在终端设备的内部,也可以是与终端设备具有通信链接的具有语音采集功能的电子设备。
207.在步骤1302中,终端设备将语音指令上传至服务器。
208.在步骤1303中,服务器对语音指令进行特征提取,得到对应目标用户的生物特征参数,基于生物特征参数生成对应的智能语音助手的虚拟形象标识。
209.在一些实施例中,服务器在基于目标用户的生物特征参数生成对应的智能语音助手的虚拟形象标识之前,还可以基于生物特征参数对发起语音指令的目标用户的身份进行识别;当识别到目标用户为授权用户时,确定继续基于目标用户的生物特征参数生成对应的智能语音助手的虚拟形象标识;当识别到目标用户为非授权用户时,返回目标用户不具备操作权限的提示信息至终端设备。
210.在本发明实施例中,由于各目标用户具有差异化,可利用目标用户的生物特征参数的唯一性和独特性区分不同的目标用户;其中,生物特征参数包括但不限于声纹特征参数、人脸特征参数、虹膜特征参数等。
211.在步骤1304中,服务器对语音指令进行情感识别,得到对应目标用户的当前情感类别,并生成与目标用户的当前情感类别匹配、且对应虚拟形象标识的虚拟情绪。
212.这里,服务器中预先存储有目标用户的情感类别与虚拟情绪的对应关系,基于该对应关系,可查询与目标用户的当前情感类别相匹配的虚拟情绪。
213.在步骤1305中,终端设备接收服务器返回的智能语音助手的虚拟形象标识,以及生成的虚拟情绪。
214.在一些实施例中,终端设备可通过如下方式接收服务器返回的智能语音助手的虚拟形象标识:
215.向服务器提交对应智能语音助手的虚拟形象获取请求,以使服务器基于目标用户的生物特征参数,在数据库中查询适配于生物特征参数的智能语音助手的虚拟形象标识;接收服务器下发的适配于生物特征参数的智能语音助手的虚拟形象标识。
216.这里,数据库中存储有多个目标用户的生物特征参数与虚拟形象标识的对应关系。
217.在一些实施例中,终端设备在接收返回的与生物特征参数对应的智能语音助手的虚拟形象标识之前,还可以接收返回的语音识别指令,语音识别指令表征针对客户端中是否已记录生物特征参数的判断结果;当判断结果为客户端中已记录生物特征参数时,发送第一提示消息至目标用户,以提示目标用户确认自身的生物特征账号;当判断结果为客户端中未记录生物特征参数时,发送第二提示消息至目标用户,以提示目标用户选择智能语音助手的虚拟形象,并将所选择的智能语音助手的虚拟形象存储于服务器的数据库中。
218.在步骤1306中,终端设备呈现虚拟形象标识所指示的智能语音助手的虚拟形象。
219.在一些实施例中,终端设备可通过如下方式呈现虚拟形象标识所指示的智能语音助手的虚拟形象:基于虚拟形象标识的指示,确定对应智能语音助手的虚拟形象;获取对应智能语音助手的虚拟形象的形象资源;基于形象资源呈现智能语音助手的虚拟形象的默认
形象,虚拟形象的默认形象包括以下至少之一:虚拟形象的默认皮肤;虚拟形象的默认道具。
220.在一些实施例中,终端设备还可以接收服务器返回的对应虚拟形象标识的情绪动画,情绪动画为服务器基于目标用户的当前情感类别生成;在呈现虚拟形象标识所指示的智能语音助手的虚拟形象时,呈现对应虚拟形象标识的情绪动画。
221.在步骤1307中,终端设备获取目标用户基于智能语音助手触发的语音交互指令。
222.在步骤1308中,终端设备发送语音交互指令至服务器。
223.在步骤1309中,服务器对语音交互指令进行语音识别得到相应的文本信息,对文本信息进行语义识别,得到对应语音交互指令的意图。
224.这里,语音交互指令的意图可包括以下至少之一:智能对话,设备控制,车机留言,添加智能语音助手的道具,切换智能语音助手所处的场景,设置智能语音助手的活跃时间。
225.在步骤1310中,服务器将语音交互指令的意图返回至终端设备。
226.在步骤1311中,终端设备基于对应语音交互指令的意图的控制指令,控制智能语音助手的虚拟形象以虚拟情绪的方式,播放符合交互指令的语音。
227.通过上述方式,基于目标用户的生物特征参数的唯一性和独特性,使各目标用户都有自己专属的智能语音助手的虚拟形象,能够满足目标用户对智能语音助手的虚拟形象的个性化需求;终端呈现虚拟形象标识所指示的智能语音助手的虚拟形象,使得智能语音助手的虚拟形象具有可视化效果;在智能语音助手与目标用户交互的过程中,增加了智能语音助手的虚拟形象的情感表达,以增强虚拟形象的人性化交互,从而能够提高目标用户对应用智能语音助手产品的好感度及用户粘度,提升目标用户的使用体验。
228.下面,将说明本发明实施例在一个实际的应用场景中的示例性应用。
229.相关技术中,在家庭中应用的智能语音助手通常都有固定的虚拟形象,或者无对应的虚拟形象,即时有固定的虚拟形象,然而由于家庭使用,家庭中的每个目标用户都有自己的喜好,因此,固定的虚拟形象并不能满足家庭中每个目标用户的个性化需求,且该虚拟形象也无法基于情感表达与目标用户进行语音交互。
230.为解决上述技术问题,本发明实施例提出适用于家庭中各目标用户针对智能语音助手的虚拟形象的个性化需求的方案,通过声纹识别确认每个目标用户,每个目标用户可以选择自己喜爱的智能语音助手的虚拟形象,比如小猪佩奇、美少女战士等其他卡通形象,作为自己专属的智能语音助手的虚拟形象;识别到具体的目标用户后,使用语音控制则对应的智能语音助手的虚拟形象就会上线;每个语音助手都会存储对应“主人”视频观看历史、喜好技能(股票、诗词等),通过情感识别以识别到目标用户的当前情感,并做出与目标用户的当前情感对应的虚拟情绪的回馈。
231.本发明的技术方案主要包括两个部分,即智能语音助手的虚拟形象设置过程,以及虚拟形象的虚拟情绪回馈的过程。下面分别进行说明。
232.参见图15,图15为本发明实施例提供的智能语音助手的虚拟形象设置的一个可选的流程示意图,终端设备采集目标用户输入的语音指令,该语音指令中携带有目标用户的声纹特征参数,判断是否从未录入该目标用户的声纹特征参数,若是,则提示目标用户进行智能语音助手的虚拟形象的选择,以及进行身份确认,若否,则获取预先设置的对应该目标用户的智能语音助手的虚拟形象。参见图16,图16为本发明实施例提供的虚拟形象的虚拟
情绪回馈过程的一个可选的流程示意图,终端设备采集目标用户输入的语音指令,发送语音指令至后台服务器,后台服务器通过情感识别对语音指令进行分析,得到目标用户的当前情感类别,查询与目标用户的当前情感类别匹配的虚拟情绪,并将查询到的虚拟情绪反馈给终端设备,在一些实施例中,后台服务器还可以反馈给终端设备对应虚拟情绪的情绪动画。
233.在本发明的技术方案中,智能语音助手的虚拟形象设置可以基于声纹的个性化虚拟形象帐号系统实现,下面对基于声纹的个性化虚拟形象帐号系统的流程进行说明。
234.参见图17,图17为本发明实施例提供的基于声纹的个性化虚拟形象帐号系统的一个可选的流程示意图,包括以下几个步骤:
235.在步骤1601中,用户a在客户端中输入语音指令;
236.在步骤1602中,客户端将获取的用户a的语音指令上传至后台服务器;
237.这里,输入的语音指令中携带有用户a的声纹特征参数。
238.在步骤1603中,后台服务器判断客户端中是否已经存在用户a的声纹特征参数,基于判断结果生成语音识别指令;
239.这里,后台服务器通过对语音指令进行特征提取,得到对应用户a的声纹特征参数。
240.在步骤1604中,后台服务器将语音识别指令返回给客户端;
241.在步骤1605中,客户端向用户a发送用于提示用户a确认自身声纹账号的提示消息;
242.在步骤1606中,用户a选择符合自身偏好的智能语音助手的虚拟形象,上传自己的声纹数据及虚拟形象标识、虚拟形象名称至客户端;
243.在步骤1607中,客户端将用户a上传的声纹数据及虚拟形象标识、虚拟形象名称发送至后台服务器;
244.在步骤1608中,后台服务器保存上述数据,并建立虚拟形象帐号;
245.在步骤1609中,后台服务器返回对应虚拟形象帐号的虚拟形象的情绪动画包;
246.这里,后台服务器中预先存储有一系列的虚拟形象的情绪动画,比如开心,庆祝,难过,安慰,撒娇等等。在后续的虚拟情绪反馈过程中,后台服务器只需要返回虚拟情绪及情绪动画,客户端中直接展示对应虚拟形象标识的情绪动画。
247.在步骤1610中,用户a向客户端发送针对情绪动画包的语音控制指令;
248.在步骤1611中,客户端将语音控制指令上传至后台服务器;
249.在步骤1612中,后台服务器响应于该语音控制指令,对情绪动画包中的情绪动画进行分类存储,以用于情感分析和推荐。
250.下面以交互的方式对虚拟形象的虚拟情绪回馈过程进行说明。参见图18,图18为本发明实施例提供的虚拟形象的虚拟情绪回馈过程的另一个可选的流程示意图,包括以下几个步骤:
251.在步骤1701中,用户a在客户端中输入语音指令;
252.在步骤1702中,客户端将获取的用户a的语音指令上传至后台服务器;
253.在步骤1703中,后台服务器通过情感识别识别到用户a的当前情感类别,生成与当前情感类别匹配的虚拟情绪id,以及情绪动画id;
254.这里,后台服务器可通过相关技术中的情感识别识别到用户a的当前情感类别,对于虚拟情绪而言,后台服务器会有一一对应的虚拟情绪回馈给客户端,比如识别到用户a的当前情感类别为开心类情感,则返回给客户端的虚拟情绪为开心。
255.在步骤1704中,后台服务器将虚拟情绪id,以及情绪动画id返回给客户端。
256.这里,客户端可根据虚拟情绪id识别出与用户a的当前情感类别匹配、且对应虚拟形象的虚拟情绪,根据情绪动画id识别出对应虚拟形象的情绪动画。
257.本发明的技术方案所提出的基于有屏设备如智能电视机、移动设备等有屏设备的具有情感表述的智能语音助手的虚拟形象方案,不仅可以使智能语音助手的虚拟形象具有可视化效果,让每个用户都有属于自己专属的智能语音助手的虚拟形象,以满足用户对智能语音助手的虚拟形象的个性化需求,还增加了虚拟形象的情感表达,使得虚拟形象更加人性化。
258.接下来继续对本发明实施例提供的智能语音助手的处理装置455的软件实现进行说明。以上述实施本发明实施例的智能语音助手的处理方法的智能语音助手的处理设备40(实施为客户端)中的存储器450所包括的软件模块为例进行说明,对于下文关于模块的功能说明中未尽的细节,可以参考上文本发明客户端侧的方法实施例的描述而理解。如图3a所示,本发明实施例提供的智能语音助手的处理装置455可以包括:
259.获取单元4551,用于获取对应目标用户的语音指令;第一发送单元4552,用于发送所述语音指令,以对所述语音指令进行特征提取,得到对应所述目标用户的生物特征参数,以及对所述语音指令进行情感识别,得到对应所述目标用户的当前情感类别;第一接收单元4553,用于接收返回的与所述生物特征参数对应的智能语音助手的虚拟形象标识,以及与所述目标用户的当前情感类别匹配、且对应所述虚拟形象标识的虚拟情绪;呈现单元4554,用于呈现所述虚拟形象标识所指示的所述智能语音助手的虚拟形象;控制单元4555,用于响应于基于所述智能语音助手触发的交互指令,控制所述智能语音助手的虚拟形象以所述虚拟情绪的方式,播放符合所述交互指令的语音。
260.在一些实施例中,智能语音助手的处理装置还包括:
261.第三接收单元,用于在所述第一接收单元接收返回的与所述生物特征参数对应的智能语音助手的虚拟形象标识之前,接收返回的语音识别指令,所述语音识别指令表征针对客户端中是否已记录所述生物特征参数的判断结果;
262.第三发送单元,用于当所述判断结果为所述客户端中已记录所述生物特征参数时,发送第一提示消息至所述目标用户,以提示所述目标用户确认自身的生物特征账号;
263.第四发送单元,用于当所述判断结果为所述客户端中未记录所述生物特征参数时,发送第二提示消息至所述目标用户,以提示所述目标用户选择所述智能语音助手的虚拟形象;
264.存储单元,用于将所选择的所述智能语音助手的虚拟形象存储于服务器的数据库中。
265.在一些实施例中,就第四发送单元发送第二提示消息至所述目标用户,以提示所述目标用户选择所述智能语音助手的虚拟形象来说,可以采用以下方式实现:
266.响应于所述目标用户基于所述第二提示消息触发的所述智能语音助手的虚拟形象的设置请求,呈现供选择所述智能语音助手的虚拟形象的虚拟形象选择界面;响应于基
于所述虚拟形象选择界面触发的虚拟形象选择指令,获取符合所述目标用户的偏好的所述智能语音助手的虚拟形象。
267.在一些实施例中,就第一接收单元接收返回的与所述生物特征参数对应的智能语音助手的虚拟形象标识来说,可以采用以下方式实现:
268.向服务器提交对应所述智能语音助手的虚拟形象获取请求,以使所述服务器基于所述目标用户的生物特征参数,在数据库中查询适配于所述生物特征参数的所述智能语音助手的虚拟形象标识,所述数据库中存储有多个目标用户的生物特征参数与虚拟形象标识的对应关系;接收所述服务器下发的适配于所述生物特征参数的所述智能语音助手的虚拟形象标识。
269.在一些实施例中,就呈现单元呈现所述虚拟形象标识所指示的所述智能语音助手的虚拟形象来说,可以采用以下方式实现:
270.基于所述虚拟形象标识的指示,确定对应所述智能语音助手的虚拟形象;获取对应所述智能语音助手的虚拟形象的形象资源;基于所述形象资源呈现所述智能语音助手的虚拟形象的默认形象,所述虚拟形象的默认形象包括以下至少之一:所述虚拟形象的默认皮肤;所述虚拟形象的默认道具。
271.在一些实施例中,就控制单元响应于基于所述智能语音助手触发的交互指令,控制所述智能语音助手的虚拟形象以所述虚拟情绪的方式,播放符合所述交互指令的语音来说,可以采用以下方式实现:
272.获取所述目标用户基于所述智能语音助手触发的交互指令,并发送所述交互指令至服务器,以使所述交互指令包括语音交互指令时,所述服务器对所述语音交互指令进行语音识别得到相应的文本信息,对所述文本信息进行语义识别,得到对应所述语音交互指令的意图;
273.接收返回的所述语音交互指令的意图,基于对应所述语音交互指令的意图的控制指令,控制所述智能语音助手的虚拟形象以所述虚拟情绪的方式,播放符合所述交互指令的语音。
274.在一些实施例中,智能语音助手的处理装置还包括:
275.第四接收单元,用于接收返回的对应所述虚拟形象标识的情绪动画,所述情绪动画为服务器基于所述目标用户的当前情感类别生成;
276.呈现单元,还用于在呈现所述虚拟形象标识所指示的所述智能语音助手的虚拟形象时,呈现对应所述虚拟形象标识的情绪动画。
277.在一些实施例中,智能语音助手的处理装置还包括:
278.第五发送单元,用于将所述目标用户的标识,以及与所述目标用户的标识对应的所述智能语音助手的虚拟形象发送至区块链网络中,以使所述区块链网络的节点将所述目标用户的标识,以及与所述目标用户的标识对应的所述智能语音助手的虚拟形象填充至新区块,且当对所述新区块取得共识一致时,将所述新区块追加至区块链的尾部。
279.以上述实施本发明实施例的智能语音助手的处理方法的智能语音助手的处理设备50(实施为服务器)中的存储器550所包括的软件模块为例进行说明,对于下文关于模块的功能说明中未尽的细节,可以参考上文本发明服务器侧的方法实施例的描述而理解。如图3b所示,本发明实施例提供的智能语音助手的处理装置555可以包括:
280.第二接收单元5551,用于接收客户端发送的目标用户的语音指令;提取单元5552,用于对所述语音指令进行特征提取,得到对应所述目标用户的生物特征参数;识别单元5553,用于对所述语音指令进行情感识别,得到对应所述目标用户的当前情感类别;确定单元5554,用于确定与所述生物特征参数对应的智能语音助手的虚拟形象标识,以及与所述目标用户的当前情感类别匹配、且对应所述虚拟形象标识的虚拟情绪;第二发送单元5555,用于发送所述虚拟形象标识及虚拟情绪至所述客户端,以使所述客户端呈现所述虚拟形象标识所指示的所述智能语音助手的虚拟形象,并响应于基于所述智能语音助手触发的交互指令,控制所述智能语音助手的虚拟形象以所述虚拟情绪的方式,播放符合所述交互指令的语音。
281.本发明实施例还提供了一种计算机可读存储介质,存储有可执行指令,该可执行指令被处理器执行时,用于实现本发明实施例提供的智能语音助手的处理方法。
282.在一些实施例中,计算机可包括智能终端和服务器在内的各种计算设备,计算机可读存储介质,例如可以是铁电随机存取存储器(fram,ferromagnetic random access memory)、rom、prom、可擦除可编程只读存储器(eprom,erasable programmable read-only memory)、电可擦除可编程只读存储器(eeprom,electrically erasable programmable read-only memory)、快闪存储器(flashmemory)、磁表面存储器、光盘或只读光盘(cd-rom,compact disc read-only memory)等存储器;也可以是包括上述存储器之一或任意组合的各种设备。
283.在一些实施例中,可执行指令可以采用程序、软件、软件模块、脚本或代码的形式,按任意形式的编程语言(包括编译或解释语言,或者声明性或过程性语言)来编写,并且其可按任意形式部署,包括被部署为独立的程序或者被部署为模块、组件、子例程或者适合在计算环境中使用的其它单元。
284.作为示例,可执行指令可以但不一定对应于文件系统中的文件,可以可被存储在保存其它程序或数据的文件的一部分,例如,存储在超文本标记语言(html,hyper text markup language)文档中的一个或多个脚本中,存储在专用于所讨论的程序的单个文件中,或者,存储在多个协同文件(例如,存储一个或多个模块、子程序或代码部分的文件)中。
285.作为示例,可执行指令可被部署为在一个计算设备上执行,或者在位于一个地点的多个计算设备上执行,又或者,在分布在多个地点且通过通信网络互连的多个计算设备上执行。
286.以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

