一种arm侧离线语音合成的方法、装置及存储介质
技术领域
1.本发明涉及语音合成技术领域,尤其涉及一种arm侧离线语音合成的方法、装置及存储介质。
背景技术:
2.语音合成(text to speech,tts)即“从文本到语音”,是人机对话的一部分,其目的是让机器能够将文本输出转化为自然的语音输出。
3.语音合成同时运用了语言学和机器学习,通过神经网络的设计,把文字智能地转化为自然语音流。tts技术对文本文件进行实时转换,转换时间之短可以秒计算,文本输出的语音音律流畅,使得听者在听取信息时感觉自然,毫无机器语音输出的冷漠与生涩感。tts 是语音合成应用的一种,它将储存于电脑中的文件,如帮助文件或者网页,转换成自然语音输出。tts不仅能帮助有视觉障碍的人阅读计算机上的信息,更能增加文本文档的可读性。tts应用包括语音驱动的邮件以及声音敏感系统,并常与声音识别程序一起使用。
4.现有的语音合成方法通常是基于前后端的语音合成系统,申请号为:cn201210093481.6 发明申请提出了一种语音合成方法及系统,所述方法包括:对输入文本进行文本分析和语言分析,生成包含相应语音单元的前端脚本,获取和校验所述前端脚本,修正所述前端脚本;以及获取所述修正后的前端脚本并合成修正语音,本发明能够纠正前端脚本的错误如分词错误和多音字注音错误,从而提高合成语音的易理解性和用户的可接受程度,弥补传统tts对韵律的预测准确度不足的缺点,提高了合成语音的自然度和表现力。
5.但是该发明申请提出的语音合成方法及系统依赖于建立前后端网络联系,后端也需要建立强大的服务器集群才能满足实际运用的网络负载量,且在脱离网络时便无法正常使用,其局限性较大,无法运用到无网络或者网络较差环境中。
6.申请号为cn201911174434.2的发明申请公开了一种分布式语音合成方法,旨在将传统 tts系统一般处理流程中的各个处理环节按先后顺序划分为前后两个部分,所述的前端处理环节和语音合成后端处理环节之间通过数据交换标准和协议标准进行通信,共同完成整个tts处理过程,为在资源敏感的移动终端设备上合成出与pc上大型tts系统相同自然度的自然语音,尽可能地利用自身的空闲资源,以最大化的释放网络和服务器的负载,使得其它用户可以方便地接入。
7.该发明申请缓解了设备的网络压力,云端服务器的负载也相应降低,能在网络较差环境下进行很好的工作,但是其原理还是基于前后端的语音合成的方法,在无网络的情况下便无法进行很好的运用推广。
8.现有阶段,对于语音合成需求最高的场景便是arm侧设备场景,由于arm侧设备便于携带,故可以结合tts组合成智能翻译,智能导航,智能助手,智能变声等功能进行使用,而arm侧设备很多场景下是无网络跟随的,故基于前后端的语音合成不能完全满足arm侧设备的运用场景。
9.因此,我们有必要提出一种arm侧离线语音合成的方法来解决上述问题。
技术实现要素:
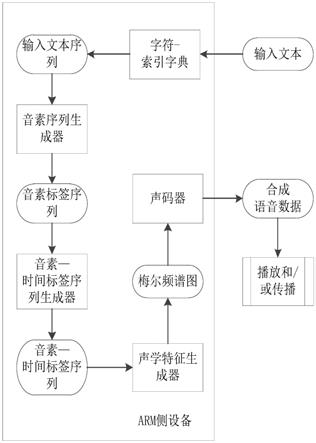
10.为解决上述技术问题之一,本发明一种arm侧离线语音合成的方法,运用于具备音频处理、播放和/或传播功能的arm侧设备中,在arm侧部署音素序列生成器、音素—时间标签序列生成器、声学特征生成器和声码器;采集需要进行离线语音合成的输入文本;将输入文本通过字符
‑
索引字典转化为以索引为序列元素的输入文本序列;通过所述音素序列生成器将输入文本序列转化为所对应音素标签序列;通过音素—时间标签序列生成器将输入音素标签序列转化为对应音素—时间标签序列;通过声学特征生成器将音素—时间标签序列转化成所对应的梅尔频谱图;通过声码器将梅尔频谱图合成并转换成对应的语音数据;所述arm侧设备对生成的语音数据进行播放和/或传播操作。
11.作为更进一步的解决方案,所述音素序列生成器、音素—时间标签序列生成器、声学特征生成器和声码器通过模型训练端产生;所述模型训练端包括机器学习语言学音素序列模型、神经网络时间标签模型、神经网络声学特征生成模型和神经网络声码模型,并通过语音合成训练数据对模型训练端进行训练。作为更进一步的解决方案,所述语音合成训练数据包括训练用待带合成语音文本、训练用待带合成语音文本序列、训练用音素标签参考序列、训练用音素—时间标签参考序列、训练用梅尔频谱参考图和训练用合成语音参考数据;
12.所述机器学习语言学音素序列模型通过训练用待带合成语音文本序列和训练用音素标签参考序列进行文本序列音素标注训练,得到能够根据输入文本序列输出对应音素标签序列的音素序列生成器;
13.所述神经网络时间标签模型通过训练用音素—时间标签参考序列和训练用音素标签参考序列进行音素—时间标注训练,得到能够根据输入音素标签序列输出对应音素—时间标签序列的音素—时间标签序列生成器;
14.所述神经网络声学特征生成模型通过训练用音素—时间标签参考序列和训练用梅尔频谱参考图进行时频图谱转化训练,得到能够根据输入音素—时间标签序列输出对应的梅尔频谱图的声学特征生成器;
15.所述神经网络声码模型通过训练用梅尔频谱参考图和训练用合成语音参考数据进行图谱
‑
语音转化合成训练,得到能过根据输入梅尔频谱图合成并输出对应语音数据的声码器。
16.作为更进一步的解决方案,所述语音合成训练数据均为先验数据,并通过以下步骤进行生成:
17.所述训练用待带合成语音文本通过人工/机器进行编写生成;
18.将所述训练用待带合成语音文本通过字符
‑
索引形式进行序列生成,得到训练用待带合成语音文本序列;
19.将所述训练用待带合成语音文本进行人工朗读并音频采集,得到训练用合成语音参考数据;
20.对训练用合成语音参考数据进行梅尔频谱图转换,得到训练用梅尔频谱参考图;
21.对训练用合成语音参考数据通过人工进行音速级标注,得到训练用音素标签参考
序列;
22.将训练用音素标签参考序列与训练用合成语音参考数据进行时间向对齐并标注,得到训练用音素—时间标签参考序列。
23.作为更进一步的解决方案,所述音素序列生成器通过机器学习语言学音素序列模型训练迁移产生,所述音素序列生成器包括文字
‑
拼音转换层和拼音
‑
音素转换层;
24.所述文字
‑
拼音转换层通过隐马尔可夫模型将输入文本序列转化为输入文本拼音序列;
25.所述拼音
‑
音素转换层对拼音序列进行分割和因素转换;通过对文字
‑
拼音转换层提供对的输入文本拼音序列进行声韵母分割得到输入文本拼音分割序列;将输入文本拼音分割序列中每个分割单元通过拼音
‑
因素词典进行查找映射,得到对应的音素标签序列。
26.作为更进一步的解决方案,所述声学特征生成器通过神经网络声学特征生成模型训练迁移产生,所述神经网络声学特征生成模型为fastspeech 2模型,包括编码器与查分适配器;
27.所述编码器通过多层残差卷积网络组成,并用于提取训练用梅尔频谱参考图的高维特征信息,所述高维特征信息包括音素持续时间信息、力度信息和能量信息;
28.所述差分适配器包括conv1d relu层、ln dropout层和linear layer层;通过将音素持续时间信息、力度信息和能量信息输入差分适配器进行训练,得到音素持续时间预测层、力度预测层和能量预测层;通过音素持续时间预测层、力度预测层和能量预测层对音素—时间标签参考序列进行预测,并得到对应的梅尔频谱图。
29.作为更进一步的解决方案,所述声码器通过神经网络声码模型训练迁移产生,所述神经网络声码模型为melgan模型,所述神经网络声码模型包括上采样层、残差块和卷积层,所述残差块包括多个用于调整卷积层中膨胀率的膨胀卷积层,通过调整膨胀率来获得更大的卷积野。
30.作为更进一步的解决方案,所述机器学习语言学音素序列模型、神经网络时间标签模型、神经网络声学特征生成模型和神经网络声码模型均通过基于python的tensorflow平台进行构建,通过对tensorflow平台搭建的训练模型进行训练,并得到对应的32位float 型模型浮点参数,所述模型浮点参数用于生成对应的音素序列生成器、音素—时间标签序列生成器、声学特征生成器和声码器;
31.在arm侧部署前,还需进行重编译和量化压缩操作,所述重编译和量化压缩操作步骤包括:
32.通过基于python的tensorflow平台构建训练模型并进行模型训练,得到float型模型浮点参数;
33.将模型浮点参数进行量化压缩,得到整型参数;
34.将基于python的训练模型进行python to c/c porting重编译,得到基于c和/或 c 的训练模型;
35.将整型参数迁移至基于c和/或c 的训练模型中,得到对应的arm侧部署文件。
36.作为更进一步的解决方案,一种arm侧离线语音合成的装置,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述任一所述一种 arm侧离线语音合成的方法的步骤。
37.作为更进一步的解决方案,一种arm侧离线语音合成的计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现如上述任一所述一种arm侧离线语音合成的方法的步骤。
38.与相关技术相比较,本发明提供的一种arm侧离线语音合成的方法、装置及存储介质具有如下有益效果:
39.1、本发明通过对arm侧设备部署音素序列生成器、音素—时间标签序列生成器、声学特征生成器和声码器来进行离线语音合成,
40.2、本发明通过对arm侧设备部署的各生成器进行进行python to c/c porting重编译和对tensorflow平台的32位float型模型浮点参数进行量化压缩,使arm侧设备能够快速进行离线语音合成且达到节省arm侧设备所需部署空间、降低arm侧设备运算要求的目的;
41.3、本发明通过通过将melgan模型作为神经网络声码模型,达到了提升训练速率,在没有额外的蒸馏和感知损失的引入下仍能产生高质量的语音合成模型;将fastspeech 2模型神经网络声学特征生成模型能达到升模型训练速率和增加了数据的丰富度避免过多的信息损失的目的。
附图说明
42.图1为本发明提供的一种arm侧离线语音合成的方法的较佳实施例语音合成流程图;
43.图2为本发明提供的一种arm侧离线语音合成的方法的较佳实施例模型训练流程图。
具体实施方式
44.下面结合附图和实施方式对本发明作进一步说明。
45.如图1所示,本发明一种arm侧离线语音合成的方法,运用于具备音频处理、播放和/ 或传播功能的arm侧设备中,在arm侧部署音素序列生成器、音素—时间标签序列生成器、声学特征生成器和声码器;采集需要进行离线语音合成的输入文本;将输入文本通过字符
‑ꢀ
索引字典转化为以索引为序列元素的输入文本序列;通过所述音素序列生成器将输入文本序列转化为所对应音素标签序列;通过音素—时间标签序列生成器将输入音素标签序列转化为对应音素—时间标签序列;通过声学特征生成器将音素—时间标签序列转化成所对应的梅尔频谱图;通过声码器将梅尔频谱图合成并转换成对应的语音数据;所述arm侧设备对生成的语音数据进行播放和/或传播操作。
46.需要说明的是:通过文本合成对应的语音需要通过文本到序列的转换、序列到音素的转换、音素到时间标签序列的转换并得到音素—时间标签序列、通过加入声学特征来将音素—时间标签序列拟声化,通过声码器将带有声学特征数据、音素
‑
时间数据合称成输出语音的原始波形,并用于播放和/或传播操作,此处声学特征选择梅尔频谱图进行提取。
47.作为更进一步的解决方案,所述音素序列生成器、音素—时间标签序列生成器、声学特征生成器和声码器通过模型训练端产生;所述模型训练端包括机器学习语言学音素序列模型、神经网络时间标签模型、神经网络声学特征生成模型和神经网络声码模型,并通过
语音合成训练数据对模型训练端进行训练。
48.需要说明的是:通过对不同模型进行训练可以得到能生成音素标签序列、音素—时间标签序列、梅尔频谱图和对应的语音数据生成器,仅需将各生成器部署于arm侧设备上就能实现离线语音合成,其难点在于模型的构建和训练材料的选用。对于训练数据主要分为训练用待带合数据和训练用待参考数据,通过训练用待带合数据对模型进行训练并得到初步的输出数据,再通过训练用待参考数据对输出数据进行校准评分,模型通过损失函数来逼近训练用待参考数据直至最后达到精度要求,训练完成。
49.作为更进一步的解决方案,所述语音合成训练数据包括训练用待带合成语音文本、训练用待带合成语音文本序列、训练用音素标签参考序列、训练用音素—时间标签参考序列、训练用梅尔频谱参考图和训练用合成语音参考数据;
50.所述机器学习语言学音素序列模型通过训练用待带合成语音文本序列和训练用音素标签参考序列进行文本序列音素标注训练,得到能够根据输入文本序列输出对应音素标签序列的音素序列生成器;
51.所述神经网络时间标签模型通过训练用音素—时间标签参考序列和训练用音素标签参考序列进行音素—时间标注训练,得到能够根据输入音素标签序列输出对应音素—时间标签序列的音素—时间标签序列生成器;
52.所述神经网络声学特征生成模型通过训练用音素—时间标签参考序列和训练用梅尔频谱参考图进行时频图谱转化训练,得到能够根据输入音素—时间标签序列输出对应的梅尔频谱图的声学特征生成器;
53.所述神经网络声码模型通过训练用梅尔频谱参考图和训练用合成语音参考数据进行图谱
‑
语音转化合成训练,得到能过根据输入梅尔频谱图合成并输出对应语音数据的声码器。
54.作为更进一步的解决方案,所述语音合成训练数据均为先验数据,并通过以下步骤进行生成:
55.所述训练用待带合成语音文本通过人工/机器进行编写生成;
56.将所述训练用待带合成语音文本通过字符
‑
索引形式进行序列生成,得到训练用待带合成语音文本序列;
57.将所述训练用待带合成语音文本进行人工朗读并音频采集,得到训练用合成语音参考数据;
58.对训练用合成语音参考数据进行梅尔频谱图转换,得到训练用梅尔频谱参考图;
59.对训练用合成语音参考数据通过人工进行音速级标注,得到训练用音素标签参考序列;
60.将训练用音素标签参考序列与训练用合成语音参考数据进行时间向对齐并标注,得到训练用音素—时间标签参考序列。
61.作为更进一步的解决方案,所述音素序列生成器通过机器学习语言学音素序列模型训练迁移产生,所述音素序列生成器包括文字
‑
拼音转换层和拼音
‑
音素转换层;所述文字
‑ꢀ
拼音转换层通过隐马尔可夫模型将输入文本序列转化为输入文本拼音序列。
62.具体的,文字
‑
拼音转换层,主要是将中文文字序列转换为拼音序列,使用的是隐马尔可夫模型(hidden markov model,hmm)。选用此模型是为了解决中文文字中存在多音
字的问题,而多音字映射中文——拼音字库时,会存在的映射错误的情况。例如,句(xxxx调整xxxxx)中的词调整,原音是tiao2 zheng3。但由于调有多个发音,diao4、tiao2存在,而字库中diao4的优先级更高,所以会出现diao4 zheng3的情况发生,为此我们训练了基于hmm的模型以解决多音字映射错误的情况。
63.所述拼音
‑
音素转换层对拼音序列进行分割和因素转换;通过对文字
‑
拼音转换层提供对的输入文本拼音序列进行声韵母分割得到输入文本拼音分割序列;将输入文本拼音分割序列中每个分割单元通过拼音
‑
因素词典进行查找映射,得到对应的音素标签序列。
64.拼音转换音素中,由于拼音中包含了省略声母的情况,但如不加判断的话,会出现字省略的情况。例如,句“xxxxx搭啊”,音素是“d a1 a1”,由于“搭”的“a1”和“啊”的“a1”一致,所以有可能会导致音素的重叠省略,为此需要做分割处理判断。通过声韵母的分割处理判断便能避免这种情况发生。
65.作为更进一步的解决方案,所述声学特征生成器通过神经网络声学特征生成模型训练迁移产生,所述神经网络声学特征生成模型为fastspeech 2模型,包括编码器与查分适配器;所述编码器通过多层残差卷积网络组成,并用于提取训练用梅尔频谱参考图的高维特征信息,所述高维特征信息包括音素持续时间信息、力度信息和能量信息;所述差分适配器包括conv1d relu层、ln dropout层和linear layer层;通过将音素持续时间信息、力度信息和能量信息输入差分适配器进行训练,得到音素持续时间预测层、力度预测层和能量预测层;通过音素持续时间预测层、力度预测层和能量预测层对音素—时间标签参考序列进行预测,并得到对应的梅尔频谱图。
66.具体的,所述conv1d层即一维卷积层,其主要目的是通过卷积计算,得出当前层的音素特征。由于音素特征伴随着时序信息,有着许多变化,为此为了得出当前帧的音素特征,需要通过带有音素序列信息的卷积操作计算得出。而为了能够使得卷积层的参数更适应所学习的训练样本,需要通过relu层进行梯度激活。
67.ln层即layer normalization,其主要目的是为了让各种分布不同的训练数据在经过神经网络层后,获得更加接近的特征分布,以使得网络获得更高的拟合度与泛化性,而 dropout层同理。
68.linear layer即线性层。线性层主要是为了让conv1d所输出的特征获得更深层、细节的特征。其中就包含了深度的音素持续时间信息、力度信息和能量信息。
69.需要说明的是:本实施采用的fastspeech 2模型相较于fastspeech模型来讲,
70.fastspeech模型的训练依赖自回归的teacher model、duration prediction以及 knowledge distillation的模块;而模块对应的teacher
‑
student、distillation和 pipeline复杂而且耗时;teacher model提取的duration不准确;而且由于数据简化, teacher model提取的mel
‑
spec会有信息的损失;而fastspeech 2采用ground
‑
truth作为训练模型;引入pitch、energy和more accurate duration等speech变量作为条件输入;从而提升了模型训练速率和增加了数据的丰富度,避免过多的信息损失。
71.作为更进一步的解决方案,所述声码器通过神经网络声码模型训练迁移产生,所述神经网络声码模型为melgan模型,所述神经网络声码模型包括上采样层、残差块和卷积层,所述残差块包括多个用于调整卷积层中膨胀率的膨胀卷积层,通过调整膨胀率来获得更大的卷积野。
72.具体的,由于在wav生成的过程中,需要把深层的特征信息还原成细节更为细致的波形。为此设置了上采样层、残差块和卷积层的顺序形式对波形进行还原。这些层各有分工,其中,上采样层主要是为了让深层信息进行模糊还原。而残差块能够使得在前层模糊还原后,依旧能够保留部分未还原的深层信息,以防止在还原过程中信息的丢失。而卷积层则是为了让还原的波形更为真实,其主要是通过卷积操作的特性完成的。由于卷积操作时,每个卷积核的大小相同,但通过卷积核之间操作特征点的远近可以实现卷积野大小的改变,这就是膨胀卷积的实现原理。
73.需要说明的是:传统的声码器是通过对抗网络(gan)模型进行实现,但是由于声音数据具有较高的时间分辨率(通常为每秒16,000个样本),并且在不同时间尺度上存在具有短期和长期依赖性的结构,故本实施例通过melgan模型来进行声音的生成。melgan相较于传统对抗网络(gan)模型的区别在于采用非自回归前馈卷积架构,并通过第一个gan去实现原始音频的生成,在没有额外的蒸馏和感知损失的引入下仍能产生高质量的语音合成模型。此外,melgan模型的速度明显快于其他梅尔频谱图转换到音频的方法,在保证音频质量没有明显下降的情况下比迄今为止最快的可用模型快10倍左右。
74.作为更进一步的解决方案,所述机器学习语言学音素序列模型、神经网络时间标签模型、神经网络声学特征生成模型和神经网络声码模型均通过基于python的tensorflow平台进行构建,通过对tensorflow平台搭建的训练模型进行训练,并得到对应的32位float 型模型浮点参数,所述模型浮点参数用于生成对应的音素序列生成器、音素—时间标签序列生成器、声学特征生成器和声码器;
75.在arm侧部署前,还需进行重编译和量化压缩操作,所述重编译和量化压缩操作步骤包括:
76.通过基于python的tensorflow平台构建训练模型并进行模型训练,得到float型模型浮点参数;
77.将模型浮点参数进行量化压缩,得到整型参数;
78.将基于python的训练模型进行python to c/c porting重编译,得到基于c和/或 c 的训练模型;
79.将整型参数迁移至基于c和/或c 的训练模型中,得到对应的arm侧部署文件。
80.需要说明的是:将模型部署于arm侧需要对空间进行进一步压缩以匹配arm侧设备的存储特性,本实施例是通过两方面来进行模型压缩的,一方面是通过对基于python的训练模型进行python to c/c porting重编译来进行,由于现阶段的基于python的 tensorflow平台为开源平台,其底层代码可以通过其他语言进行重构,本实施例是通过 c/c 进行重构,由于c/c 是比python更接近底层的语言,故通过c/c 对训练模型进行重编译能进一步压缩空间,且能对不必要的模组进行删减,只保留执行语音合成所必要的组建,通过对编译前的基于python的tensorflow平台进行训练可以得到相应的float型模型浮点参数,将这些参数移至基于c和/或c 的训练模型中,便能得到对应的基于c和 /或c 的arm侧部署文件。
81.另一方面,由于tensorflow平台的参数均为32位float型模型浮点参数,而浮点参数所占用空间大,占用运算资源严重,故本实施对32位float型模型浮点参数进行量化压缩,本实施例提出的量化压缩分为精度型量化压缩和空间型量化压缩。所述精度型量化压
缩为int8量化压缩,将32位float型模型浮点参数压缩为8位int整型参数,所述空间型量化压缩为三值量化压缩,将32位float型模型浮点参数压缩为2位int整型参数。
82.所述精度型量化压缩运用于arm侧资源相对充沛的情况下进行,int8量化压缩能充分保证模型的精度,本实施采用的是nvidia的量化方案,该方案为公开方案,为原理公开但代码未开源的方案,故在此不做赘述。
83.所述空间型量化压缩运用于arm侧资源相对不充沛的情况下进行,三值量化压缩相较于int8量化压缩其精度有所下降,但能节省极大的空间,将原参数w通过三值参数w
t
与比例系数α相乘近似表示,所述三值参数w
t
表示为:
[0084][0085]
其中:阈值δ从原参数w中产生,所述阈值δ为:
[0086][0087]
其中:i表示参数对应序列数,n表示参数总数;
[0088]
缩放因子α为:
[0089][0090]
其中:i
δ
={1≤i≤n||w
i
>δ|},|i
δ
|表示i
δ
中的元素。
[0091]
本实施例选用三值量化,与二值量化相比,三值量化在1和
‑
1两种值的基础上再加入 0值进行构成三值网络,且不增加计算量。
[0092]
作为更进一步的解决方案,一种arm侧离线语音合成的装置,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述任一所述一种 arm侧离线语音合成的方法的步骤。
[0093]
作为更进一步的解决方案,一种arm侧离线语音合成的计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现如上述任一所述一种arm侧离线语音合成的方法的步骤。
[0094]
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

