本发明涉及中文语音识别技术,具体涉及一种居家老人呼救设备。
背景技术:
从现在到本世纪中叶是中国人口老龄化高速发展的时期,积极、科学、有效应对人口老龄化至关重要。到2022年左右,中国65岁以上人口将占到总人口的14%,由老龄化社会进入老龄社会。而居家养老是目前老人养老的主要模式,但对于高龄患病老人,在日常生活中往往会遇到突发的紧急情况,需要救助。目前的老人呼救设备多以按键或手机为主,需要手动操作,老人在遭遇紧急情况下,可能没有行动能力来手动操作,则亟需进行语音呼救。
目前,语音识别技术已经深入到生活的方方面面,如语音助手、语音检索、智能穿戴设备等应用。而作为联合国六种工作语言之一,已有17亿人以上使用中文作为日常交流的语言,中文语音识别应用领域广泛,具有很大的实用价值。当前,虽然有大量深度学习方法应用于中文语音识别领域,但语音识别方法在识别速度和识别精度上有很大的局限性,且过分依赖于高性能处理器,为了克服上述问题,将语音识别模型的训练过程与识别过程分离,分别在云端和客户端进行。
技术实现要素:
针对现有技术中的不足,本发明提供一种基于龙芯派的居家老人呼救设备,通过在服务器端对声纹识别模型和语音识别模型进行训练,再将服务器端训练完成的模型和环境下载部署到以龙芯2k1000处理器基础的客户端,在客户端完成声纹模型参数微调和语音识别以及拨打电话功能。
为实现上述目的,本发明采用了以下技术方案:
一种居家老人呼救设备,包括用于部署声纹识别模型、语音识别模型训练环境及训练的服务器端、用于声纹识别、语音识别和拨打电话的客户端,所述客户端包括微处理器、拾音设备、电话卡和扬声器,所述拾音设备与微处理器的音频输入接口连接,将捕捉到的语音输入微处理器,所述微处理器上部署维纳滤波器,对接收到的语音信号进行降噪处理;所述电话卡和扬声器与微处理器音频输出接口连接,用以执行电话功能;所述服务器端训练完成的声纹识别模型、语音识别模型和训练环境打包部署到客户端的微处理器,采集经降噪处理的目标用户语音信号,对客户端声纹识别模型进行参数微调,录入目标用户声纹,从而构成本地声纹识别模型、本地语音识别模型及运行环境;经降噪处理的语音信号输入本地声纹识别模型和语音识别模型,根据声纹识别结果进行目标用户的判断,当声纹识别结果为目标用户,则将语音信号输入本地语音识别模型,获取识别语音结果,根据语音识别结果,微处理器执行对应的执行指令;当声纹识别结果为非目标用户,则不进行语音识别,微处理器控制扬声器发出用户不匹配的指令。
进一步地,所述客户端的微处理器为嵌入式龙芯2k1000处理器。
再进一步地,所述服务器端的声纹识别模型为基于gmm(高斯混合模型)的声纹识别模型,是通过以下步骤获取的:
步骤s1、语音提供者标注:将st-cmds数据中语音提供者的语音信号进行标注,对同一语音提供者的普通wav语音信号打上相同标签;
步骤s2、特征提取:将普通wav语音信号通过mfcc特征提取方法转换为卷积神经网络需要的二维频谱图像信号,即语音信号特征矩阵;
步骤s3、非目标用户声纹模型训练:将语音信号特征矩阵输入gmm(高斯混合模型)中,进行gmm模型的参数估计;
步骤s4、模型参数固定:基于最大似然估计算法,通过em算法进行迭代,得到gmm模型的最优参数,将不同语音提供者的语音特征分簇。
更进一步地,所述客户端的本地声纹识别模型为基于gmm-ubm的声纹识别模型,是通过以下步骤获取的:
步骤k1:客户端部署gmm模型:将在服务器端经过非目标用户训练的gmm模型和运行环境部署到客户端。
步骤k2:目标用户语音信号录入:启动基于gmm的声纹识别模型,通过客户端拾音设备录入目标用户语音信号,存储为模型训练数据。
步骤k3:声纹识别模型参数微调:通过背景模型ubm,使用目标用户训练数据,利用最大后验概率算法,经过自适应训练,得到本地声纹识别模型。
步骤k4:本地声纹识别模型保存:在客户端保存训练完成的本地用户声纹模型。
更进一步地,所述服务器端的语音识别模型为基于卷积神经网络的语音识别模型,是通过以下步骤获取:
步骤y1、特征提取:将st-cmds数据集中的普通wav语音信号通过mfcc特征提取方法转换为卷积神经网络需要的二维频谱图像信号,即语音信号特征矩阵;
步骤y2、基于卷积神经网络的语音识别模型的构建:使用卷积神经网络对mfcc处理后的语音信号特征矩阵进行提取,建立语音识别模型;
步骤y3、使用st-cmds数据集进行语音识别模型训练;随机将st-cmds数据集的80%划分为训练集,20%划分为测试集,重复五次,实验结果取五次实验平均值;经过验证,所述语音识别模型的准确率在0.95以上;
步骤y4、语音识别模型的保存:在服务器端保存训练完成的语音识别模型。
更进一步地,所述st-cmds数据集中包含10万余条语音文件,语音文件数据内容为日常语音聊天和智能语音控制语句,语音提供者为855个。
更进一步地,所述mfcc特征由静态mfcc系数、动态差分参数、帧能量共同构成。
更进一步地,所述步骤y2中的基于卷积神经网络的语音识别模型是由2层卷积层和5层全连接层组成,初始的输入尺寸为40*11*3,第二个卷积层的输入为第一个卷积层的输出,卷积核大小分别8*9*3、3*1*3,卷积核数分别为16、32,得到规格更小的语音信号特征矩阵;引入池化处理,简化卷积层的输出;经过全连接层,将最终语音信号特征与语料库匹配,得到语音的识别结果。
更进一步地,所述微处理器执行对应的执行指令,其执行指令中至少包括启动或关闭语音识别程序、拨打报警及急救电话功能,当语音识别模型识别的语音为启动语音识别程序的口令时,默认等待10s,之后若接收不到其它口令,则关闭语音识别程序;当语音识别模型识别的语音为报警口令时,则由微处理器通过电话卡和扬声器拨打报警电话与语音交流;当语音识别模型识别的语音为拨打急救电话口令时,则由微处理器通过电话卡和扬声器拨打急救电话与语音交流。
与现有技术相比,本发明具有以下有益效果:
1、本发明使用语音识别技术实现老人呼救,相比起传统的按键、打电话方法,更加便捷,人性化。
2、本发明使用声纹识别模型实现特定人员使用,防止无关人员操作,提高了安全性。
3、本发明将声纹识别模型、语音识别模型的训练过程与识别过程分离,降低了客户端对算力的要求,大幅度减小了本地硬件的成本。
3、本发明在通过客户端微调声纹识别模型参数,获取目标用户声纹,降低了客户端运算成本。
4、本发明在语音识别之前,进行降噪处理,提升信噪比,有力提升了识别的准确度。
5、本发明的客户端采用国产龙芯微处理器实现了语音识别的应用,具有很好的泛化能力。
6、本发明语音识别模型,可以实现高于80%的中文语音识别准确率,且识别速度较快,应用前景广泛。
附图说明
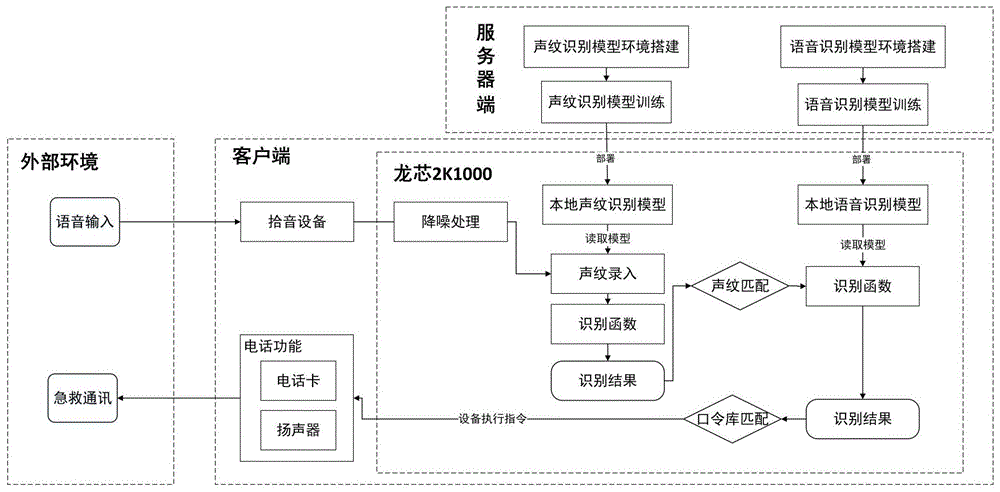
图1为本发明的一种居家老人呼救设备的整体流程图。
图2为本发明中mfcc特征提取流程图。
具体实施方式
下面结合附图并通过具体实施例来进一步说明本发明的技术方案。本领域技术人员应该明了,所述具体实施方式仅仅是帮助理解本发明,不应视为对本发明的具体限制。
如图1-2所示,一种居家老人呼救设备,包括用于部署声纹识别模型、语音识别模型训练环境及训练的服务器端、用于声纹识别、语音识别和拨打电话的客户端,所述客户端包括微处理器、拾音设备、电话卡和扬声器,所述拾音设备与微处理器的音频输入接口连接,将捕捉到的语音输入微处理器,所述微处理器上部署维纳滤波器,对接收到的语音信号进行降噪处理;所述电话卡和扬声器与微处理器音频输出接口连接,用以执行电话功能;所述服务器端训练完成的声纹识别模型、语音识别模型和训练环境打包部署到客户端的微处理器,采集经降噪处理的目标用户语音信号,对客户端声纹识别模型进行参数微调,录入目标用户声纹,从而构成本地声纹识别模型、本地语音识别模型及运行环境;经降噪处理的语音信号输入本地声纹识别模型和语音识别模型,根据声纹识别结果进行目标用户的判断,当声纹识别结果为目标用户,则将语音信号输入本地语音识别模型,获取识别语音结果,根据语音识别结果,微处理器执行对应的执行指令;当声纹识别结果为非目标用户,则不进行语音识别,微处理器控制扬声器发出用户不匹配的指令。本实施例中的拾音设备为麦克风,微处理器为嵌入式龙芯2k1000处理器。
微处理器执行指令中至少包括启动或关闭语音识别程序、拨打报警及急救电话功能,当语音识别模型识别的语音为启动语音识别程序的口令时,启动语音识别程序,默认等待10s,之后若接收不到其它口令,则关闭语音识别程序;当语音识别模型识别的语音为报警口令时,则由微处理器通过电话卡和扬声器拨打报警电话与语音交流;当语音识别模型识别的语音为拨打急救电话口令时,则由微处理器通过电话卡和扬声器拨打急救电话与语音交流。
在客户端进行声纹识别的流程为:拾音设备将捕捉到的语音信号经维纳滤波器降噪处理后将语音信号声纹录入,读取本地声纹识别模型,根据识别函数,通过对语音信号声纹进行识别,若声纹匹配目标用户声纹,则将语音信号输入到本地语音识别模型中,若不匹配,则扬声器发出口令“用户不匹配,无法使用”。
在客户端进行语音识别的流程为:经过声纹匹配的语音信号输入到本地语音识别模型,通过本地语音识别模型中的识别函数进行识别,得到识别结果,再将识别的语音与模型中的口令库匹配,当匹配为启动语音识别程序的口令时,如设置启动语音识别程序的口令为“你好龙芯”,2k1000处理器则启动语音识别程序,默认等待10s,之后若接收不到其它口令,则关闭语音识别程序;当识别的语音匹配为“请报警”语音后,则由微处理器通过电话卡和扬声器拨打报警电话与语音交流;当识别的语音匹配为“拨打急救电话”,则由微处理器通过电话卡和扬声器拨打急救电话与语音交流。
本实施例中,所述服务器端的声纹识别模型为基于gmm(高斯混合模型)的声纹识别模型,是通过以下步骤获取的:
步骤s1、语音提供者标注:将st-cmds数据中语音提供者的语音信号进行标注,对同一语音提供者的普通wav语音信号打上相同标签;
步骤s2、特征提取:将普通wav语音信号通过mfcc特征提取方法转换为卷积神经网络需要的二维频谱图像信号,即语音信号特征矩阵;
步骤s3、非目标用户声纹模型训练:将语音信号特征矩阵输入高斯混合模型gmm中,进行gmm模型的参数估计;
步骤s4、模型参数固定:基于最大似然估计算法,通过em算法进行迭代,得到gmm模型的最优参数,将不同语音提供者的语音特征分簇。
所述服务器端的基于gmm的声纹训练模型由协方差矩阵、混合分量均值向量、混合权重共同组成。
本实施例中,所述客户端的目标用户声纹识别模型为基于gmm-ubm的声纹识别模型,是通过以下步骤获取的:
步骤k1、客户端部署gmm模型:将在服务器端经过非目标用户训练的基于gmm的声纹识别模型和运行环境部署到客户端;
步骤k2、目标用户语音信号录入:启动基于gmm的声纹识别模型,通过客户端拾音设备录入目标用户语音信号,存储为模型训练数据;
步骤k3、声纹识别模型参数微调:通过背景模型ubm,使用目标用户训练数据,利用最大后验概率算法,经过自适应训练,得到本地声纹识别模型;
步骤k4、本地声纹模型识别保存:在客户端保存训练完成的本地声纹识别模型。
本实施例中,所述服务器端的语音识别模型为基于卷积神经网络的语音识别模型,是通过以下步骤获取:
步骤y1、特征提取:将st-cmds数据集中的普通wav语音信号通过mfcc特征提取方法转换为卷积神经网络需要的二维频谱图像信号,即语音信号特征矩阵;所述mfcc特征由静态mfcc系数、动态差分参数、帧能量共同构成。所述st-cmds数据集中包含10万余条语音文件,语音文件数据内容为日常语音聊天和智能语音控制语句,语音提供者为855个。
特征提取流程如图2所示:
预加重处理即将语音信号通过一个高通滤波器,提升高频部分,保持在低频到高频的整个频带中,能用同样的信噪比求频谱,同时突出高频的共振峰。经分帧后,将每一帧乘以汉明窗以增加帧左端和右端的连续性。再将各帧进行快速傅立叶变换得到各帧的频谱,并对频谱取模平方得到语音信号的功率谱。
将功率谱通过一组mel尺度的三角形滤波器组,对频谱进行平滑化,并消除谐波,突出语音的共振峰。每个滤波器输出经离散余弦变换得到mfcc系数,通过动态差分参数,最后得到语音信号特征。
步骤y2、基于卷积神经网络的语音识别模型的构建:使用卷积神经网络对mfcc处理后的语音信号特征矩阵进行提取,建立基于卷积神经网络的语音识别模型;
所述基于卷积神经网络的语音识别模型是由2层卷积层和5层全连接层组成,初始的输入尺寸为40*11*3,第二个卷积层的输入为第一个卷积层的输出,卷积核大小分别8*9*3、3*1*3,卷积核数分别为16、32,得到规格更小的语音信号特征矩阵;引入池化处理,简化卷积层的输出;经过全连接层,将最终语音信号特征与语料库匹配,得到语音的识别结果。
步骤y3、使用st-cmds数据集进行语音识别模型训练;随机将st-cmds数据集的80%划分为训练集,20%划分为测试集,重复五次,实验结果取五次实验平均值;经过验证,所述语音识别模型的准确率在0.95以上;
步骤y4、语音识别模型的保存:在服务器端保存训练完成的语音识别模型。
本实施中的嵌入式处理器龙芯2k1000提供了包括usb、gmac、sata、pcie在内的主流接口,可以满足多场景的产品化应用,也是进行国产化开发的入门级硬件的首选。该开发板的参数如下:
cpu:龙芯2k1000处理器;内存:板载2gddr3,主频400mhz;bios:8mbspiflash;gpio:2.54间距27个可配置gpio插针排;网络:2个千兆自协商网口(2个标准接口);pcie:1路x1夹板接口pcie;ejtag:1个ejtag调试接口,可用于程序下载、单步调试;接口:3路usb2.0标准接口(typeausb*2,microusb*1),2路can接口,4路串口(ttl*3,rs232*1);显示和音频接口:1路typeahdmi接口,dvo接口适配飞凌嵌入式触摸屏,1路3.5mm标准音频输入/输出接口;存储:m2接口支持ssd硬盘;电源:12v3a圆柱电源;尺寸:120mm*120mm。
软件环境:客户端安装ubuntu或centos或loongnix系统、python、tensorflow、keras、librosa、wav、portaudio、sklearn支撑环境。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,可以根据本发明所提到的技术方案进行通同等替换或是改进。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

