本发明涉及语音识别技术领域,尤其涉及一种发音偏误检测方法、装置及存储介质。
背景技术:
随着语音技术的发展和在线学习的推广,计算机辅助发音教学(computer-aidedpronunciationtraining,capt)在语言教学中得到越来越多的应用。其中,自动发音偏误检测作为计算机辅助发音教学的一个重要环节,主要用于检测学习者的发音错误问题,以帮助学习者在二语学习过程中及时发现其发音问题并改正。
发音偏误检测技术的主要原理是通过大量的目的语l2(second/targetlanguage,l2)语音语料库训练获得一个包含目的语l2中所有音素集的发音偏误检测系统。在检测时,通过解码输出的概率图来得到对应的音素序列,进而与参考文本比较得到偏误情况。或者通过发音偏误检测系统得到发音的置信分数(gop方法)来判断发音是否偏误。
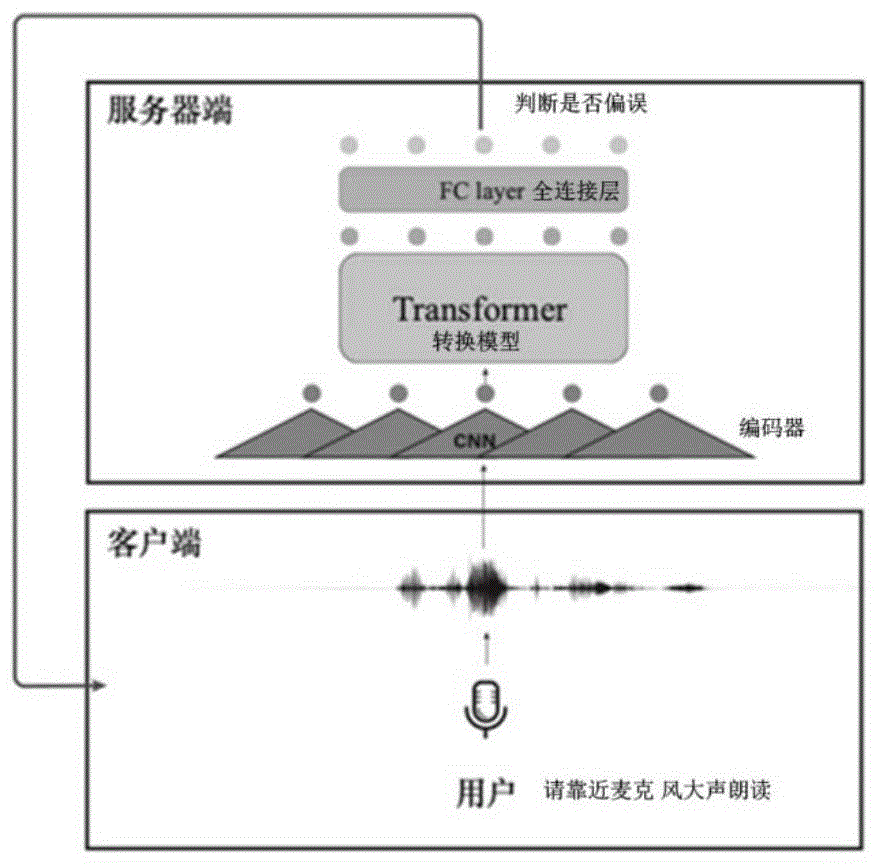
图1为现有技术中发音偏误检测交互过程,包括客户端和服务器端,其发音偏误检测系统包括:由cnn(convolutionalneuralnetworks,卷积神经网络)组成的编码器、由transformer(转换模型)组成的上下文处理器、以及一个fclayer(全连接层)。当用户通过客户端进行发音练习时,客户端记录下用户的练习音频并上传至服务器端,服务器端进行发音偏误检测后,将偏误检测结果回传至客户端,并提示用户修改意见。
但是,上述发音偏误检测常因缺少发音训练数据,即缺少目的语l2的语料而难以构建一个鲁棒性良好的发音偏误检测系统。
针对目的语l2语料短缺的问题,一些研究,例如参考文献a.baevski,y.zhou,a.mohamed,andm.auli,“wav2vec2.0:aframeworkforself-supervisedlearningofspeechrepresentations,”advancesinneuralinformationprocessingsystems,vol.33,2020.中探索了利用来自无标注语音语料库的信息来提升偏误检测性能的方法,该方法相较于带标注的语音语料库,无标注的语音语料库的获取相对容易,即,利用大规模的无标注语音数据进行预训练的模型能够得到关于语音信号的通用表示,其对应的模型参数可作为发音偏误检测任务的良好起点。例如参考文献l.yang,k.fu,j.zhang,andt.shinozaki,“pronunciationerroneoustendencydetectionwithlanguageadversarialrepresentlearning,”proc.interspeech2020,pp.3042–3046,2020.中首先尝试在日本成人普通话学习者的发音偏误检测任务上使用无标注的一语和二语数据进行预训练。
但是,上述参考文献中提到的偏误检测方法,在缺少发音训练数据的条件下,虽然通过小规模语音语料,例如150小时左右的预训练获得了目的语l2语料库,提升了偏误检测性能,但对于像中国人学习外语,语音水平跨度大、声学差异显著的发音特征来说,然存在难以构建一个鲁棒性好的发音偏误检测系统。
技术实现要素:
为此,本发明所要解决的技术问题是:提供一种发音偏误检测方法、装置及存储介质,使得在缺少发音训练数据情况下,依然可以有效提升发音偏误检测系统的性能。
于是,本发明提供了一种基于语音预训练模型的发音偏误检测方法,包括:
构建语音预训练模型,并基于无标注语音语料库对所述语音预训练模型进行预训练;
在所述语音预训练模型上添加一层随机初始化的全连接层,得到微调预训练模型,并使用带标注的发音偏误数据对所述微调预训练模型进行训练,得到发音偏误检测模型;
利用所述发音偏误检测模型对学习者的语音进行检测,以获得发音偏误信息。
其中,所述利用所述发音偏误检测模型对学习者的语音进行检测包括:
输出一个关于所述学习者的语音的音素概率序列;
将所述音素概率序列解码成音素序列,并将所述音素序列和相应的参考文本进行对比,以获得发音偏误信息;或者,基于所述音素概率序列通过发音置信分数方法获得发音偏误信息。
其中,所述构建语音预训练模型,包括:
构建语音识别模块,该模块包括编码器、上下文处理器和量化器,所述编码器用于将语音信号编码成隐向量,所述上下文处理器用于在当前音段上重新考虑整条语音上来自其他音段的信息以生成上下文相关的音段表示,所述量化器用于将生成的所述音段表示规范到有限的空间内。
所述在语音预训练模型上添加一层随机初始化的全连接层包括:将一个全连接层添加到所述上下文处理器中的transformer模块上以构建微调预训练模型。
所述使用带标注的发音偏误数据对所述微调预训练模型进行训练包括:
在训练最初的预置次数中,只更新所述全连接层,编码器和上下文处理器不进行参数更新;
在所述预置次数之后的训练中,进行全模型参数更新。
上述发音偏误检测方法,采用adam优化器,训练时长为48小时。
其中,所述预训练使用的损失函数
其对应的相似度函数sim为:
sim(a,b)=atb/||a||||b||
其中ct为当前音段对应的上下文表示,qt为量化向量表示,
基于上述发音偏误检测方法,本发明还提供了一种基于语音预训练模型的发音偏误检测装置,该装置包括语音识别模块和序列对齐模块,其中,所述语音识别模块包括编码器、上下文处理器、量化器以及全连接层,所述编码器、上下文处理器和量化器用于构建语音预训练模型,并基于无标注语音语料库对所述语音预训练模型进行预训练,在预训练后的所述语音预训练模型上添加一层随机初始化的全连接层,以得到微调预训练模型,并使用带标注的发音偏误数据对所述微调预训练模型进行训练以得到发音偏误检测模型,利用所述发音偏误检测模型对学习者的语音进行检测,输出一个关于所述学习者的语音的音素概率序列,并将所述音素概率序列解码成音素序列;所述序列对齐模块将所述音素序列和相应的参考文本进行对比,获得发音偏误信息。
基于上述发音偏误检测方法,本发明还提供了一种基于语音预训练模型的发音偏误检测装置,包括语音识别模块和发音置信分数模块,其中,所述语音识别模块包括编码器、上下文处理器、量化器以及全连接层,所述编码器、上下文处理器和量化器用于构建语音预训练模型,并基于无标注语音语料库对所述语音预训练模型进行预训练,在预训练后的所述语音预训练模型上添加一层随机初始化的全连接层,以得到微调预训练模型,并使用带标注的发音偏误数据对所述微调预训练模型进行训练以得到发音偏误检测模型,利用所述发音偏误检测模型对学习者的语音进行检测,输出一个关于所述学习者的语音的音素概率序列;所述发音置信分数模块基于所述音素概率序列通过发音置信分数方法获得发音偏误信息。
基于上述发音偏误检测方法,本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现如权利要求1至7任意一项所述的发音偏误检测方法。
本发明所述发音偏误检测方法、装置及存储介质,通过构建语音预训练模型、微调预训练模型,利用发音偏误检测模型对学习者的语音进行检测以获得发音偏误信息的方式,使得在缺少发音训练数据情况下,依然可以有效提升发音偏误检测系统的性能。
附图说明
图1为现有技术中发音偏误检测系统的交互过程示意图;
图2为本发明实施例所述发音偏误检测方法的流程示意图;
图3为本发明实施例所述发音偏误检测系统的交互过程示意图;
图4为本发明实施例所述一种发音偏误检测装置的结构示意图;
图5为本发明实施例所述又一种发音偏误检测装置的结构示意图。
具体实施方式
下面,结合附图对本发明进行详细描述。
在深度学习的迁移学习理论中,对于某一种信号,例如图像文本语音,希望通过预训练使模型能够抽取出反映其信号内在结构的通用表示。这样,同一个领域内的不同任务都能够从这个通用的表示中获益。具体到特定的任务上,直接使用这种通用表示作为特征,或者添加任务特定的模块在预训练模型上进行整体的微调都是可行的方案。预训练模型是指从大规模语料中学习得到通用的表示,并用于下游任务。
预训练模型wav2vec2.0是一个开源的预训练模型,属于wav2vec系列。预训练模型wav2vec2.0在多个语音相关任务上实现了sota(stata-of-the-art,前沿水平或者最高水平)的性能,包括音素识别,说话人/语种识别,极低资源的语音识别等。在本实施例中,我们提出应用预训练模型wav2vec2.0到发音偏误检测的任务中去。由于模型采用的是端到端的建模方式,因此服务器端的整个检测系统仅由两个模块组成,分别为:语音识别模块、序列对齐模块。可选的方案是把模型的概率输出送以gop的方式来判断偏误。当用户语音到达后,会被首先送入语音识别模块得到相应的发音音素序列。
在本实施例中,使用大规模语音语料,例如超过50000个小时的本地l2语音进行预训练。通过在预训练完成的模型上添加一层随机初始化的全连接层来构建整体的偏误检测模型。随后模型在带标注的目的语数据上进行微调并在推断时输出待测语音所对应的音素序列。通过这个音素序列可以得到发音者的发音偏误情况。本实施例提供的技术方案及技术思想适用于任何语言的发音偏误检测,能有效缓解任务相关数据不足的问题,从而进一步提高其检测性能。具体描述如下:
如图2所示,本实施例提供了一种基于语音预训练模型的发音偏误检测方法,包括:
步骤s1,构建语音预训练模型,并基于无标注语音语料库对所述语音预训练模型进行预训练;
步骤s2,在所述语音预训练模型上添加一层随机初始化的全连接层,得到微调预训练模型,并使用带标注的发音偏误数据对所述微调预训练模型进行训练,得到发音偏误检测模型;
步骤s3,利用所述发音偏误检测模型对学习者的语音进行检测,以获得发音偏误信息。
其中,步骤s3中所述利用所述发音偏误检测模型对学习者的语音进行检测包括:
输出一个关于所述学习者的语音的音素概率序列;
将所述音素概率序列解码成音素序列,并将所述音素序列和相应的参考文本进行对比,以获得发音偏误信息;或者,基于所述音素概率序列通过发音置信分数方法获得发音偏误信息。
在构建发音偏误检测模型时采用端到端建模方式,因此服务器端的整个检测系统仅由两个模块组成,分别为:语音识别模块、序列对齐模块。其中,序列对齐模块可以采用基于所述音素概率序列通过发音置信分数方法获得发音偏误信息的方式替代。具体方式如下:
如图3所示,在构建语音识别模块时,该模块包括编码器、上下文处理器和量化器,编码器包含有卷积神经网络层,用于将语音信号编码成隐向量,上下文处理器包含有transformer模块,用于在当前音段上重新考虑整条语音上来自其他音段的信息生成上下文相关的音段表示;给定一个被遮蔽的隐向量对应的上下文表示、以及多个来自未被遮蔽的隐向量对应的量化表示,在多个干扰项中找到当前的上下文表示所对应量化表示。所述量化器用于将生成的所述音段表示规范到有限的空间内,量化器是将上下文表示量化一下,来得到量化表示。
其中,量化器仅在模型预训练时使用,用于从语音得到的通用表示规范到有限的空间内q。编码器能够将采样率为16khz的语音信号每隔20ms将25ms的音段编码成一个隐向量z。上下文处理器能够在当前音段上重新考虑整条语音上来自其他音段的信息,生成上下文相关的音段表示c。
语音预训练模型具体结构为:编码器(x->z)由多个block代码块组成,每个代码块包括卷积层、layernormalization(层规范化)层 gelu(gaussianerrorlinerarunits,激活函数)激活层。每一个block代码块中的卷积层拥有512个通道。它们的步长分别为(5,2,2,2,2,2,2),kernel卷积核的大小为(10,3,3,3,3,2,2)。上下文处理器(z->c)包含24层的transformer模块,其模型的维度为1024,内维度为4096以及16个多头注意力。量化器(z->q)用于离散化隐向量,其包含两个码本,每个码本拥有320个实体。函数可导的gumbelsoftmax将被使用,用于选择与隐向量最近的那个码本实体,完成量化的过程。来自两个码本的实体向量将被连接起来作为输出q。
图3所示l-contrast预训练过程中,预训练的目的是在无标注的数据中习得语音信号的内在结构。给定一个被遮蔽的隐向量z对应的上下文表示c,多个来自未被遮蔽的隐向量z对应的量化表示q,预训练模型的任务就是在多个干扰项中找到当前的上下文表示c所对应量化表示q。
其中,所述预训练使用的损失函数
sim(a,b)=atb/||a||||b||(2)
其对应的相似度函数sim为:
sim(a,b)=atb/||a||||b||
其中ct为当前音段对应的上下文表示,qt为量化向量表示,
当预训练完成后,语音预训练模型就已经拥有对语音信号的通用的区分能力,图3所示l-ctc发音偏误任务训练过程中,此时,使用带标注的发音偏误数据对模型进行微调,使模型具有发音偏误检测的能力。模型上,一个fclayer全连接层会被添加到transformer转换模块的上面。具体地,使用人工标注好的音素序列作为目标,这个序列反映了说话人的真实产出,在微调预训练模型中,使用ctc作为损失函数l-ctc:
l-ctc:
其中x为模型的输入语音,w为该条语音对应的文本序列。c是这个文本对应的字符序列。比如语音x对应的文本为“hi”,时间步长t=3,可能的c的集合为{“hhi”,”hii”,”_hi”,”h_i”,”hi_”},其中_代表空,k(c)则是将这些c通过合并相同字符来得到w(也就是“hi”)。p是概率的意思。也就是p(c|x)代表输入语音x,字符序列c的概率。比如p(“hhi”|x)就是给定语音x,输出“hhi”的概率。
步骤s2中,所述使用带标注的发音偏误数据对所述微调预训练模型进行训练包括:
在训练最初的预置次数中,只更新所述全连接层,编码器和上下文处理器不进行参数更新;
在所述预置次数之后的训练中,进行全模型参数更新。
具体的,例如,预置次数为10000次,在前面的10000次中,模型只更新新增的fclayer全连接层,前面的编码器和上下文并不进行参数更新。在之后的训练迭代时才进行全模型的参数更新。训练时采用adam优化器。训练时长为48小时。当训练完成语音预训练模型就具有了识别目的语,即目的语学习者真实发音的能力。
当上述训练完毕后,由客户端给定学习者的话语,发音偏误检测模型将对其进行处理,输出一个关于音素的概率序列。维特比解码用于将这些概率序列解码成音素序列,而这个音素序列反映了说话人的真实发音。
在基于上述的语音识别,发音偏误检测时,在上述步骤s3中,将给定语音所识别出的音素序列和相应的参考文本进行字符串之间的对齐操作,例如编辑距离backtrace,这样就可以获得模型检测出的偏误信息。比如,如果参考文本为aba,而微调语音预训练模型对学习者的发音输出了bba的序列,那么微调语音预训练模型就认为是这位学习者第一个音发错了,其余两个音发对了。或者,也可以将所述音素概率序列通过发音置信分数方法获得发音偏误信息。其中,语音识别模块包含微调预训练模型,但是微调预训练模型不完全等同于语音识别模块。
基于上述发音偏误检测方法,如图4所示,本实施例还提供了一种发音偏误检测装置,该装置包括:语音识别模块40和序列对齐模块50,所述语音识别模块40包括:编码器41、上下文处理器42、量化器43、以及全连接层44,编码器41、上下文处理器42和量化器43用于构建语音信号的通用区分能力的语音预训练模型,在所述语音预训练模型上添加一层随机初始化的全连接层44,以构建具备目的语学习者真实发音数据库的微调预训练模型,该微调预训练模型在接收到来自客户端学习者语音时输出一个关于所述学习者语音的音素概率序列,并将所述音素概率序列解码成音素序列,序列对齐模块50将所述音素序列和相应的参考文本进行对比,获得发音偏误信息。
基于上述发音偏误检测方法,如图5所示,本实施例还提供了一种发音偏误检测装置,其与图4所示发音偏误检测装置的区别在于用发音置信分数模块60替代图6所示序列对齐模块50。微调预训练模型在接收到来自客户端学习者语音时,输出一个关于所述学习者语音的音素概率序列,发音置信分数模块30将所述音素概率序列以发音置信分数方法获得发音偏误信息。
基于上述发音偏误检测方法,本实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,当所述程序被处理器执行时实现如上述任意一项所述的发音偏误检测方法。
发音偏误检测方法、装置及存储介质,可以使用在包括但不限于计算机终端、手机、平板电脑、车载设备中。
上述发音偏误检测方法、装置及存储介质在检测多母语背景的成人二语偏误任务上,相较于现有技术中使用非预训练方案的系统在f1-score性能指标上相对改善7.8%,达到60.44%。此外在数据量较少的情况下,依然能够实现55.6%f1-score性能指标。这表明本实施例所述技术方案可以有效在目的语发音偏误检测系统中利用来自大量无标注数据抽取出的通用表示来提高发音偏误检测模型的性能以及泛化性。
本实施例所述发音偏误检测方法、装置及存储介质在和具体产品,例如英语君产品结合后,因为学习者往往对于相似的发音很容易发错,英语君能更精确地检测出来学习者发音中和母语相似的发音,让基于发音质量的打分更有据可循。从而让学习者把有限的注意力集中在最重要的偏误改正上,有利于学习者可以更为高效地更有信心地改善目的语口语能力。此外,由于上述发音偏误检测技术方案在极少数据上的表现尚可,这为提供个性化的发音偏误检测服务提供了可行性。
综上所述,本实施例所述发音偏误检测方法、装置及存储介质,通过构建语音预训练模型、微调预训练模型,利用发音偏误检测模型对学习者的语音进行检测以获得发音偏误信息的方式,使得在缺少发音训练数据情况下,依然可以有效提升发音偏误检测系统的性能。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

