本发明涉及一种窄带前馈型主动噪声控制系统及方法,属于主动噪声控制技术领域。特别地,本发明涉及一种基于声反馈和次级通道在线辨识的窄带前馈型主动噪声控制系统及方法。
背景技术:
鉴于工业噪声污染带来听力健康恶化、生产安全隐患等诸多不利影响,开发有效的噪声抑制技术正在凸显出其迫切性。传统的被动噪声控制技术主要有吸声、隔声、声屏障等,具有良好的高频噪声抑制性能,能够在较宽的频带范围内有效降低高频噪声,但由于其受控制装置的体积、成本等因素的制约,导致对低频噪声的抑制性能不足。与之相比,主动噪声控制技术利用声波的相消干涉原理,具有良好的低频噪声抑制性能。该技术具有体积小、成本低等优点,适用于控制低频谐波噪声和音频范围内的噪声,是对传统的被动噪声控制技术的有利补充(s.m.kuoandd.r.morgan,“activenoisecontrol:atutorialreview,”proc.ieee,vol.87,no.6,pp.943-973,jun.1999.)。
实际工况中存在大量的旋转设备产生的周期性有害噪声(如风机噪声,切割机噪声等),其窄带分量占主导成分,传统的窄带前馈型anc系统采用非声学传感器(如转速计等)获取参考信号时,可能存在频率失调的问题,严重影响控制系统的降噪性能。主动噪声控制系统若采用声学传感器获取参考信号,可有效避免非声学传感器可能存在的频率失调的问题,但同时引入声反馈。因此,开发高性能的含有声反馈的窄带前馈型anc系统,具有重要实际应用价值。
国内外许多学者围绕含有声反馈的窄带前馈型anc系统的结构和算法优化开展了大量的研究工作。传统的声反馈通道辨识方法往往采用长度较大的预测滤波器来降低参考噪声对声反馈通道在线辨识精度的影响,而且通常采用与声反馈通道估计和预测滤波器有关的信号进行辅助噪声的幅值调整,具有局部最优、计算成本高的缺点(s.ahmed,m.t.akhtar.gainschedulingofauxiliarynoiseandvariablestep-sizeforonlineacousticfeedbackcancellationinnarrowbandactivenoisecontrolsystems[j].ieeetransactionsonaudio,speech,andlanguageprocessing,2017,25(2):333-343.)。传统的次级通道在线辨识方法往往采用自适应线性增强器或预测滤波器来降低残余噪声中窄带分量对次级通道辨识环节的输入,以改善控制器与次级通道在线辨识环节之间的独立性,但其对残余误差的分离性能较差,且计算成本较高、运行效率低,难以保证控制器与次级通道在线辨识环节之间的独立性,进而影响系统的收敛性能,不利于强非平稳噪声场合下的降噪应用(c.y.chang,s.m.kuo,c.w.huang.secondarypathmodelingfornarrowbandactivenoisecontrolsystems[j].appliedacoustics,2018,131:154-164.)。
2019年,xiao等人开发了一种基于声反馈和次级通道同步在线辨识的多通道主动噪声控制系统,可有效克服声反馈的影响,同时可应对次级通道的时变性,降低了残余噪声能量(t.bai,z.wang,y.xiao,y.ma,l.ma,andk.khorasani.amulti-channelnarrowbandactivenoisecontrolsystemwithsimultaneousonlinesecondary-andfeedback-pathmodeling.ieeeapccas,pp.289-292,2019.)。但是,上述传统的基于声反馈和次级通道在线辨识的主动噪声控制系统存在的问题主要包括:1)采用自适应线性增强器或预测滤波器用于声反馈通道在线辨识和次级通道辨识环节,计算成本高、运行效率低;2)该系统直接采用与残余噪声有关的函数表达式来调整辅助噪声,进而用作声反馈和次级通道同步在线辨识环节的参考输入,导致当系统达到稳态后辅助噪声对残余噪声仍有较大的贡献量,严重制约系统整体降噪性能;3)该系统直接采用残余噪声,一方面用作次级通道在线辨识环节的期望输入,由于残余噪声中含有窄带分量将影响所述期望输入;另一方面用作窄带控制器的误差输入,由于残余噪声中宽带白噪声将影响所述误差输入;以上两方面将导致窄带控制器和次级通道在线辨识环节之间的独立性较差,影响系统的收敛性能和降噪速度。
技术实现要素:
为解决上述问题,本发明提供一种更有效更实用的基于声反馈和次级通道在线辨识的窄带前馈型主动噪声控制系统及方法。具体而言,本发明提供了一种基于声反馈和次级通道在线辨识的窄带前馈型主动噪声控制系统及方法,技术方案如下所述。
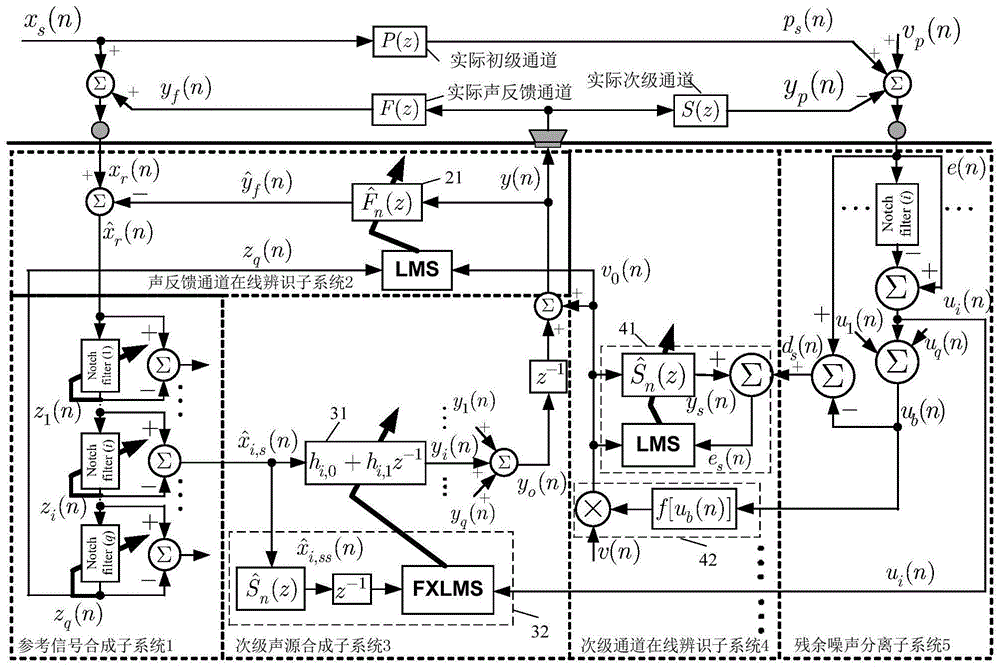
本发明提供一种基于声反馈和次级通道在线辨识的窄带前馈型主动噪声控制系统,所述窄带前馈型主动噪声控制系统包括参考信号合成子系统(1)、声反馈通道在线辨识子系统(2)、次级声源合成子系统(3)、次级通道在线辨识子系统(4)和残余噪声分离子系统(5);其中,参考信号合成子系统(1)包括串型自适应带通滤波器,用于合成宽带参考分量和窄带参考分量,并将宽带参考分量用作所述声反馈通道在线辨识子系统(2)的误差输出,将窄带参考分量用作次级声源合成子系统(3)的参考输入;声反馈通道在线辨识子系统(2)利用最小均方算法通过在线方式估计声反馈通道模型(21),并用于补偿声反馈;次级声源合成子系统(3)用于合成次级声源;次级声源合成子系统(3)包括窄带控制器(31)和带一阶延迟的滤波-x最小均方算法模块(32);次级通道在线辨识子系统(4)包括次级通道在线辨识模块(41)和辅助噪声幅值调整模块(42);次级通道在线辨识子系统(4)利用次级通道在线辨识模块(41)对实际次级通道进行实时地在线估计,得到的次级通道估计模型用作次级声源合成子系统(3)中滤波-x最小均方算法模块(32)的滤波环节;残余噪声分离子系统(5)包括并型带通滤波器,用于从残余噪声中分离出宽带分量和窄带分量,宽带分量用作次级通道在线辨识模块(41)的期望输入,窄带分量分别用作辅助噪声幅值调整模块(42)的输入和窄带控制器的滤波-x最小均方算法模块(32)的误差输出。
本发明还提供一种基于声反馈和次级通道在线辨识的窄带前馈型主动噪声控制方法,所述方法采用根据本发明的基于声反馈和次级通道在线辨识的窄带主动噪声控制系统,所述方法包括:
步骤一:次级声源合成子系统(3)合成次级声源窄带分量,并同时与辅助噪声幅值调整模块(42)产生的辅助噪声v0(n)相加,合成次级声源y(n);
步骤二:次级声源y(n)通过实际声反馈通道,产生实际声反馈信号yf(n);实际参考信号xs(n)减去实际声反馈信号yf(n)得到参考信号xr(n);参考信号xr(n)减去声反馈通道估计模型(21)产生的声反馈信号后得到的信号
步骤三:残余噪声e(n)经过残余误差分离子系统(5)分离成宽带分离ds(n)和窄带分量ui(n);
步骤四:参考信号合成子系统(1)中与iir陷波器的中心频率有关的系数更新迭代;同时,声反馈通道在线辨识子系统(2)中声反馈通道估计模型(21)的系数利用lms算法更新迭代;同时,次级通道在线辨识子系统(4)中次级通道估计模型(41)的系数利用lms算法更新迭代;同时,次级声源合成子系统(3)中窄带控制器(31)的系数利用带一阶延迟的滤波-x最小均方算法模块(32)更新迭代;
步骤五:返回到步骤一,重复上述步骤一到步骤四,直至系统收敛并达到稳态。
在本发明的一种实施方式中,所述次级声源合成子系统(3)中,窄带控制器(31)用于合成次级声源窄带分量为
在本发明的一种实施方式中,次级声源y(n)经过实际次级通道模型的输出为
在本发明的一种实施方式中,所述声反馈通道在线辨识子系统(2),利用辅助噪声幅值调整模块(42)得到的有色噪声v0(n)用作声反馈通道在线辨识子系统(2)中最小均方算法的参考输入,完成声反馈通道模型估计,进而补偿声反馈。次级声源y(n)经过声反馈通道估计模型
在本发明的一种实施方式中,所述残余噪声分离子系统(5)为由q个带通滤波器按照并联方式构成的带通滤波器组,每个带通滤波器均由二阶iir陷波器构成,其中第i个二阶iir陷波器的z域模型为
式中,ρ为极半径参数,其取值在0到1之间;ci=-2cos(ωi)为与二阶iir陷波器的中心频率有关的系数,由参考信号合成子系统(1)来确定。相应第i个带通滤波器的z域模型为:
在本发明的一种实施方式中,所述残余噪声分离子系统(5)用于从残余噪声e(n)中分离出宽带分量ds(n)和窄带分量
在本发明的一种实施方式中,所述次级通道在线辨识模块(41)采用残余噪声分离子系统(5)分离出的宽带分量ds(n)作为期望输入,提升次级通道在线辨识子系统的性能,降低残余噪声中窄带分量对次级通道在线辨识子系统性能的影响;辅助噪声幅值调整模块(42)为与残余噪声分离子系统(5)分离出的q个窄带分量之和ub(n)有关的关系式,表示为:
f[ub(n)]=αf[ub(n-1)] (1-α)|ub(n-1)|λ,λ=1,2,3,4
式中,α为收敛因子,其取值在0到1之间;q为窄带频率通道数目;n是时刻,n≥0;f[ub(n)]对均值为零、方差为
在本发明的一种实施方式中,所述次级通道在线辨识子系统(4)中,残余噪声分离子系统(5)分离出的窄带分量
在本发明的一种实施方式中,带一阶延迟的滤波-x最小均方算法模块(32)采用残余噪声分离子系统(5)分离出的第i个窄带分量ui(n)作为误差输出,相应的窄带控制器系数的更新公式为:
式中,μh为窄带控制器系数的更新步长;
在本发明的一种实施方式中,利用最小均方算法更新声反馈通道在线辨识子系统(2)中声反馈通道估计模型(21),其系数为
式中,μf为声反馈通道估计模型(21)的更新步长,通常取小于1的正值。
在本发明的一种实施方式中,辅助噪声幅值调整模块(42)输出的有色噪声v0(n)分别输入到实际次级通道和次级通道在线辨识模块(41)中,进一步降低有色噪声v0(n)对残余噪声的贡献量。利用最小均方算法更新次级通道在线辨识模块(41)中的次级通道估计模型,其系数为
式中,μs为次级通道在线辨识模块(41)的更新步长,通常取小于1的正值;es(n)(=ds(n) ys(n))为次级通道在线辨识模块(41)的误差输出。
本发明有益效果是:
一、本发明利用残余噪声分离子系统(5)分离出的宽带分量作为次级通道在线辨识模块(41)的期望输入,降低了残余噪声中窄带分量对次级通道在线辨识子系统性能的影响,改善了次级通道在线辨识子系统(4)的性能,提升了整体系统的稳定性;
二、本发明利用残余噪声分离子系统(5)分离出的窄带分量,用作带一阶延迟的滤波-x最小均方算法模块(32)的误差输出,提升次级声源合成子系统(3)和次级通道在线辨识子系统(4)之间的独立性,提升了整体系统的收敛性和应对强非平稳噪声的性能;
三、本发明利用残余噪声分离子系统(5)分离出的窄带分量
四、本发明利用残余噪声分离子系统(5)分离出的窄带分量
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是实施例一的基于声反馈和次级通道在线辨识的窄带主动噪声控制系统的原理图;
图2(a)是实施例二中的系统残余噪声均方误差数据图;
图2(b)是实施例二的声反馈通道和次级通道的估计均方误差数据图;
图2(c)是实施例二中的窄带参考分量的频率有关系数的动态变化曲线图;
图3(a)是实施例三的系统残余噪声均方误差数据图;
图3(b)是实施例三的窄带参考分量的频率有关系数的动态变化曲线图;
其中:1参考信号合成子系统,2声反馈通道在线辨识子系统,3次级声源合成子系统、4次级通道在线辨识子系统,5残余噪声分离子系统,21声反馈通道估计模型,31窄带控制器,32带一阶延迟的滤波-x最小均方算法模块,41次级通道在线辨识模块,42辅助噪声幅值调整模块。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
实施例一:
本实施例提供一种基于声反馈和次级通道在线辨识的窄带前馈型主动噪声控制系统,参见图1,所述主动噪声控制系统包括参考信号合成子系统(1)、声反馈通道在线辨识子系统(2)、次级声源合成子系统(3)、次级通道在线辨识子系统(4)和残余噪声分离子系统(5);其中,参考信号合成子系统(1)包括串型自适应带通滤波器,用于合成宽带参考分量和窄带参考分量,并分别用作声反馈通道在线辨识子系统(2)的误差输出和次级声源合成子系统(3)的参考输入;声反馈通道在线辨识子系统(2)利用最小均方算法通过在线方式估计声反馈通道模型(21),并用于补偿声反馈;次级声源合成子系统(3)用于合成次级声源;次级声源合成子系统(3)包括窄带控制器(31)和带一阶延迟的滤波-x最小均方算法模块(32);次级通道在线辨识子系统(4)包括次级通道在线辨识模块(41)和辅助噪声幅值调整模块(42);次级通道在线辨识子系统(4)利用次级通道在线辨识模块(41)对实际次级通道进行实时地在线估计,得到的次级通道估计模型用作次级声源合成子系统(3)中滤波-x最小均方算法模块(32)的滤波环节;残余噪声分离子系统(5)包括并型带通滤波器,用于从残余噪声中分离出宽带分量和窄带分量,宽带分量用作次级通道在线辨识模块(41)的期望输入,窄带分量分别用作辅助噪声幅值调整模块(42)的输入和窄带控制器的滤波-x最小均方算法模块(32)的误差输出。
根据本实施例的窄带前馈型主动噪声控制系统,本发明还提供一种基于声反馈和次级通道在线辨识的窄带前馈型主动噪声控制方法,所述方法包括:
步骤一:次级声源合成子系统(3)合成次级声源窄带分量,并同时与辅助噪声幅值调整模块(42)产生的辅助噪声v0(n)相加,合成次级声源y(n);
步骤二:次级声源y(n)通过实际声反馈通道,产生实际声反馈信号yf(n);实际参考信号xs(n)减去实际声反馈信号yf(n)得到参考信号xr(n);参考信号xr(n)减去声反馈通道估计模型(21)产生的声反馈信号后得到的信号
步骤三:残余噪声e(n)经过残余误差分离子系统(5)分离成宽带分离ds(n)和窄带分量ui(n);
步骤四:参考信号合成子系统(1)中与iir陷波器的中心频率有关的系数更新迭代;同时,声反馈通道在线辨识子系统(2)中声反馈通道估计模型(21)的系数利用lms算法更新迭代;同时,次级通道在线辨识子系统(4)中次级通道估计模型(41)的系数利用lms算法更新迭代;同时,次级声源合成子系统(3)中窄带控制器(31)的系数利用带一阶延迟的滤波-x最小均方算法模块(32)更新迭代;
步骤五:返回到步骤一,重复上述步骤一到步骤四,直至系统收敛并达到稳定。
图1为根据本实施例的基于声反馈和次级通道在线辨识的窄带前馈型主动噪声控制系统的原理示意图。
参考信号为
次级声源合成子系统(3)中,窄带控制器(31)用于合成次级声源窄带分量为
次级声源y(n)经过实际次级通道模型的输出为
辅助噪声幅值调整模块(42)输出的有色噪声v0(n)分别输入到实际次级通道和次级通道在线辨识模块(41)中,进一步降低有色噪声v0(n)对残余噪声的贡献量。
声反馈通道在线辨识子系统(2),利用辅助噪声幅值调整模块(42)得到的有色噪声v0(n)用作声反馈通道在线辨识子系统(2)中最小均方算法的参考输入,完成声反馈通道模型估计,进而补偿声反馈。次级声源y(n)经过声反馈通道估计模型
参考信号合成子系统(1)包括串型自适应带通滤波器,用于合成宽带参考分量和窄带参考分量。经声反馈补偿后的信号
zi(n)=-ρci(n)zi(n-1)-ρ2zi(n-2) zi-1(n) ci(n)zi-1(n-1) zi-1(n-2)],i>1
式中,ci(n)为与第i个iir陷波器的中心频率有关的系数,稳态时收敛于-2cosωs,i,其更新公式为:
gi(n)=-ρzi(n-1) zi-1(n-1),i>1
式中,μc为ci(n)的更新步长;ε为保证分母非零的参数;β为收敛因子,其取值在0到1之间。参考信号合成子系统(1)合成窄带参考分量为
次级通道在线辨识子系统(4)中,残余噪声分离子系统(5)分离出的窄带分量
残余噪声分离子系统(5)为由q个带通滤波器按照并联方式构成的带通滤波器组,每个带通滤波器均由二阶iir陷波器构成,其中第i个二阶iir陷波器的z域模型为:
式中,ρ为极半径参数,其取值在0到1之间;ci=-2cos(ωi)为与二阶iir陷波器的中心频率有关的系数,由参考信号合成子系统(1)来确定。相应第i个带通滤波器的z域模型为:
所述残余噪声分离子系统(5)用于从残余噪声e(n)中分离出宽带分量ds(n)和窄带分量
ui(n)=-ρui(n-1)-ρ2ui(n-2)-(1-ρ)[ci(n)e(n-1) (1 ρ)e(n-2)]
其中,宽带分量ds(n)用作次级通道在线辨识模块(41)的期望输入,窄带分量
次级通道在线辨识模块(41)采用残余噪声分离子系统(5)分离出的宽带分量ds(n)作为期望输入,提升次级通道在线辨识的性能,降低残余噪声中窄带分量对次级通道在线辨识子系统性能的影响;辅助噪声幅值调整模块(42)为与残余噪声分离子系统(5)分离出的q个窄带分量之和ub(n)有关的关系式,表示为:
f[ub(n)]=αf[ub(n-1)] (1-α)|ub(n-1)|λ,λ=1或2
式中,α为收敛因子,其取值在0到1之间;f[ub(n)]对均值为零、方差为
带一阶延迟的滤波-x最小均方算法模块(32)采用残余噪声分离子系统(5)分离出的第i个窄带分量ui(n)作为误差输出,相应的窄带控制器系数
式中,μh为窄带控制器系数的更新步长;
利用最小均方算法更新次级通道在线辨识模块(41)中的次级通道估计模型,其系数为
式中,μs为次级通道在线辨识模块(41)的更新步长,通常取小于1的正值;es(n)(=ds(n) ys(n))为次级通道在线辨识模块(41)的误差输出。
利用最小均方算法更新声反馈通道在线辨识子系统(2)中声反馈通道估计模型(21),其系数为
式中,μf为声反馈通道估计模型(21)的更新步长,通常取小于1的正值。
下面将结合仿真次级通道和实际次级通道两种情况,验证本发明具有良好的主动噪声控制效果。
实施例二:仿真次级通道情况下的理论验证
参考信号包括五个频率分量和加性高斯白噪声,其窄带分量的五个频率分别为100、150、300、400、450hz,采样率为2khz;相应的五个频率分量的幅度均为
如图2(a)、图2(b)及图2(c)所示,由本实施例在仿真噪声及次级通道情况下的系统残余噪声均方误差、声反馈通道和次级通道的估计均方误差、以及与窄带参考分量的频率有关系数的动态变化曲线图可知,当系统达到稳态后,系统残余噪声均方误差约为0.1054,该值趋近于目标噪声的加性高斯白噪声的方差,表明本发明主动噪声控制系统具有良好的噪声抑制性能;从声反馈通道和次级通道的估计均方误差的动态曲线,表明本发明主动噪声控制系统具有良好的声反馈通道在线辨识和次级通道在线辨识性能;从与窄带参考分量的频率有关系数的动态曲线,可知本发明主动噪声控制系统具有良好的窄带参考分量合成性能。
实施例三:实际次级通道情况下的实验验证
实际次级通道模型为iir模型(s.m.kuoandd.r.morgan.activenoisecontrolsystems-algorithmsanddspimplementation,newyork:wiley,1996.)。次级通道估计模型长度为32;窄带控制器的更新步长为0.001;与中心频率有关的系数的更新步长为0.0025;α、ε分别为0.9995和0.03;其它实验条件和用户参数均与实施例二相同。
如图3(a)及图3(b)所示,由本实施例在实际次级通道情况下的系统残余噪声均方误差和与窄带参考分量的频率有关系数的动态变化曲线图可知:当系统达到稳态后,系统残余噪声均方误差约为0.1023,该值趋近于目标噪声的加性高斯白噪声的方差,表明本发明的系统在实际次级通道情况下仍具有良好的噪声抑制性能,同时间接反映了本发明的系统仍具有良好的声反馈通道的在线辨识和次级通道的在线辨识性能;从与窄带参考分量的频率有关系数的动态曲线,可知本发明主动噪声控制系统能够有效合成窄带参考分量,为次级声源合成提供准确输入。
实施例2和实施例3分别从理论和实验两种情况,共同验证了本发明提供的基于声反馈和次级通道在线辨识的窄带主动噪声控制的有效性和实用性,将推进主动噪声控制技术的实际应用进程。
本发明实施例中的部分步骤,可以利用软件实现,相应的软件程序可以存储在可读取的存储介质中,如光盘或硬盘等。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

